DNS (Domain Name Service)
- L1 ~ L4: Infra Structure
- L5 ~ L7: Application
인터넷을 이루고있는 서비스, 실제로 체감할 수 있는 것들의 대다수는 Application 수준에 존재한다.
Application에 존재하는 서비스 중에서도 인프라에 해당하는 것들이 있는데 그것이 DNS체계이다.
www.naver.com 으로 TCP/IP 방식으로 접속할 때, 네이버의 IP 주소를 알아야 접속할 수 있다. 이 IP주소를 알고있는 데이터 베이스가 DNS이다.
도메인 네임(이름)으로 IPv4 주소를 검색해 알려주는 서비스가 DNS이다.
DNS가 잘못되면 인터넷 전체가 멈춰버리는 문제가 발생할 수 있다.
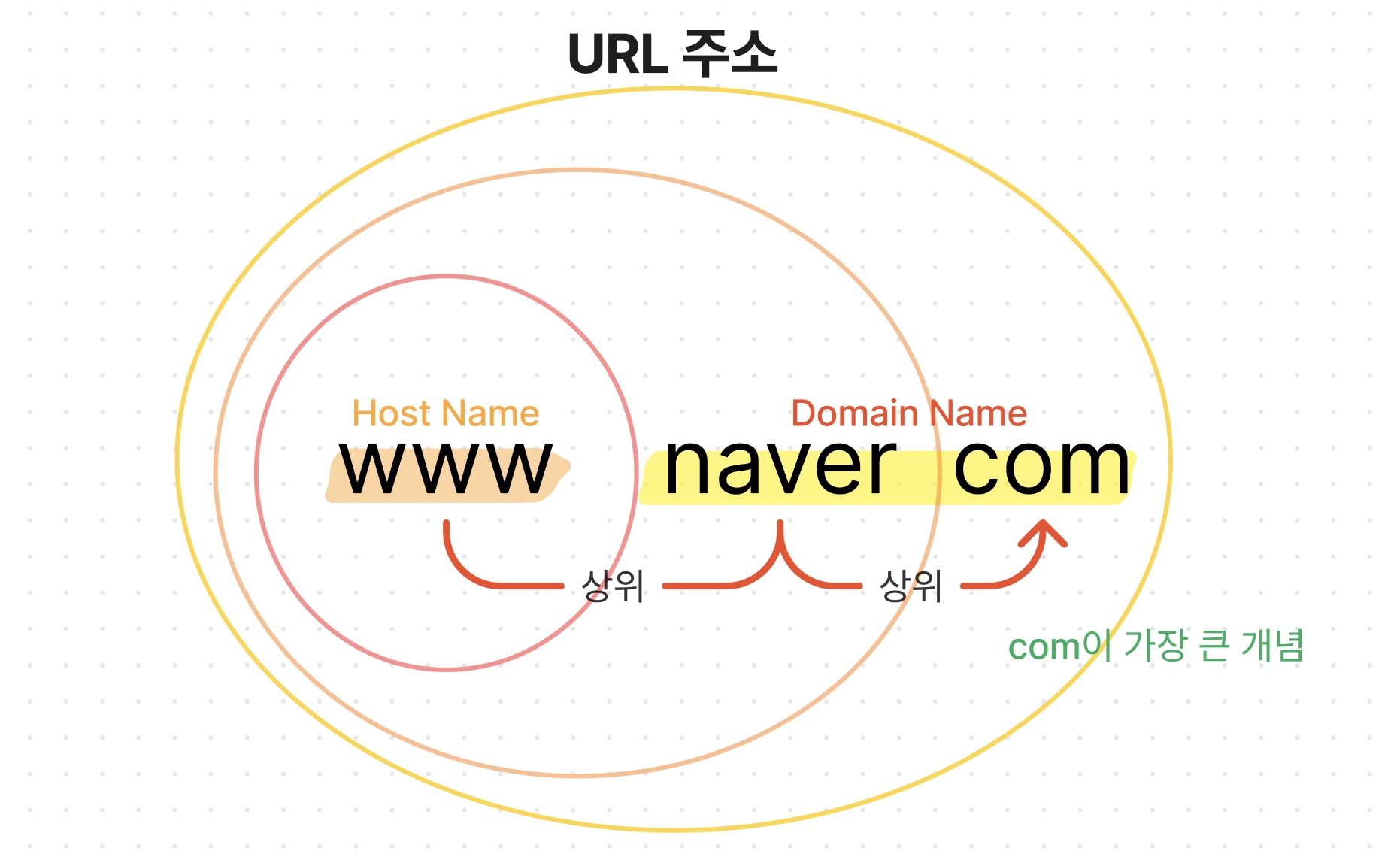
도메인 네임
www.naver.com
DNS 동작 흐름
ISP(Internet Service Provider) (KT, SKT, U+)로 인터넷을 사용할 수 있다.
공유기를 사용해 동시에 여러 디바이스가 인터넷을 사용할 수 있다.
https://www.naver.com 를 브라우저에 입력하는 경우
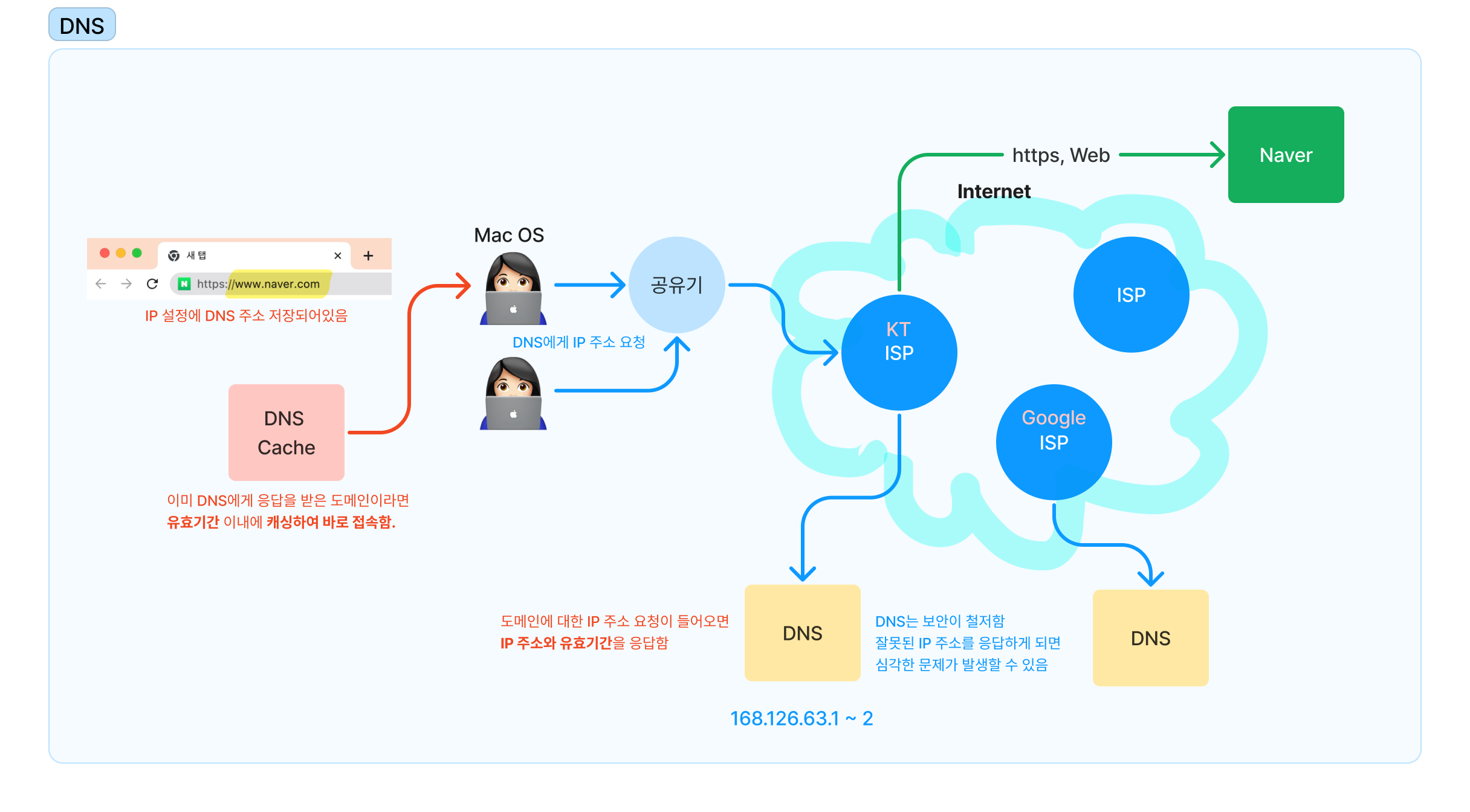
window PC의 IP 설정을 기반으로 DNS 서버 주소가 포함되어 있다. KT 네트워크를 사용하는 경우엔 DNS 서버 주소가 168.126.63.1 ~ 2 로 설정되어있다. 윈도우 운영체제 내부에서 DNS에게 www.naver.com 의 IP 주소를 요청하면 그 주소를 받아서 접속할 수 있다. (물론 네이버는 로드벨런싱 같은 복잡한 과정을 통해서 접속한다. 자세한건 생략한다.)
DNS 주소는 보통 ISP에서 정해진 것을 사용한다. DNS 응답이 느려지면 인터넷 전체가 느려지는 문제가 생긴다. 네이버가 느리지 않고 DNS가 느리더라도 사용자는 네이버가 느리다고 느낄것이다.
만약 다른 ISP에서 Google DNS를 사용하고 싶다면, 네이버를 접속할 때 마다 Google DNS에게 요청해야한다. 이 경우엔 내가 원래 사용하던 ISP가 아니라 다른 ISP의 DNS를 사용하는 것이기 때문에 응답 속도가 더 느려진다.
알아낸 IP 주소를 통해서 네이버를 접속할 수 있다. 이때는 https 통신을 수행하게 된다.
DNS로부터 한번이라도 PC가 IP주소를 전달받은 경우엔 메모리에 저장해서 가지고 사용한다. 이런 기능을 DNS Cache라고 한다. DNS에서 받은 IP 주소 응답은 항상 유효기간이 함께 담겨 내려온다. 운영체제는 유효시간이 지나면 다시 DNS에게 주소 요청을 한다. 만약 유효기간 이내라면, 브라우저에 URL을 입력하면 DNS에게 물어보지 않고 DNS Cache에서 읽어서 바로 접속할 수 있다.
PC에서 DNS에게 IP 주소를 물어보지 않는 경우가 있다.
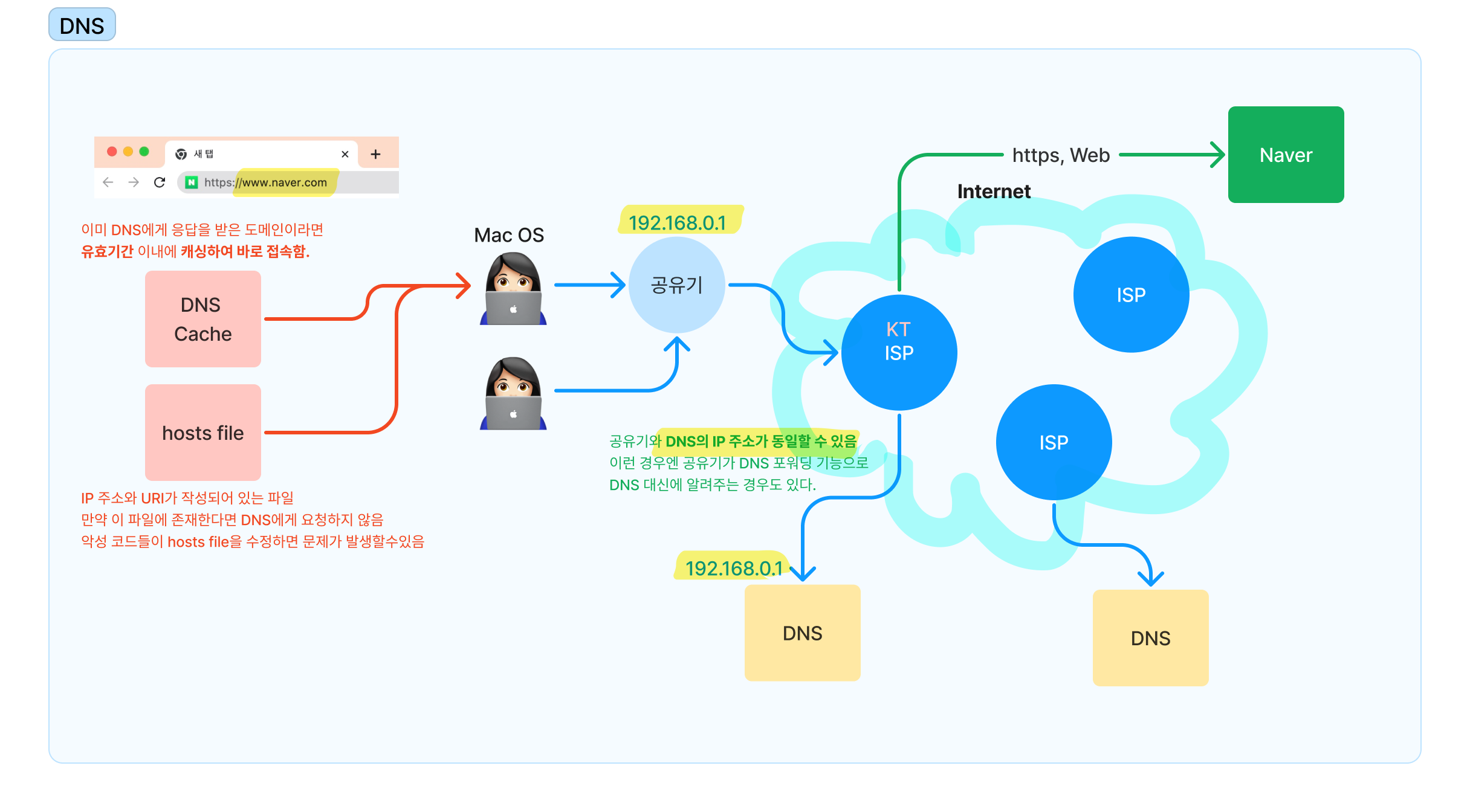
- DNS Cache: 이미 DNS에게 응답을 받은 도메인이라면 유효기간 이내에 캐싱하여 바로 접속함.
- hosts file: IP 주소와 URI가 작성되어 있는 파일. 만약 이 파일에 존재한다면 DNS에게 요청하지 않음. 악성 코드들이 hosts file을 수정하면 문제가 발생할수있음
- 공유기와 DN가 IP 주소가 동일할 수 있다. 이 경우엔 DNS 포워딩 기능으로 공유기가 DNS 대신 기능하는 경우도 있다.
Root DNS
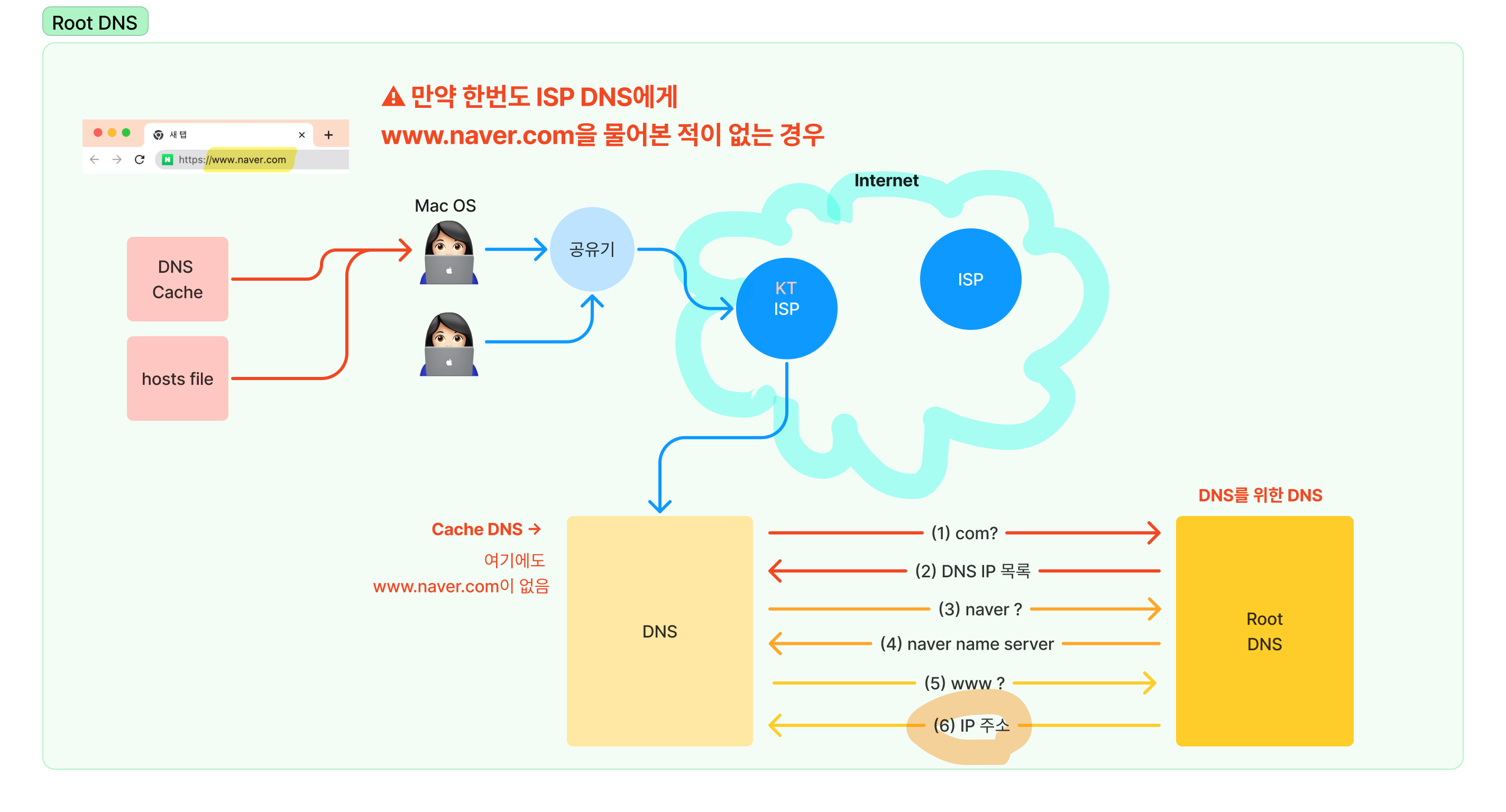
만약 한번도 ISP DNS에게 www.naver.com을 물어본 적이 없는 경우 ISP의 DNS에게 해당 도메인의 ip 주소가 없을 것이다. 이 경우엔 Root DNS에게 도메인의 com > naver > www 순으로 검색해가며 IP 주소를 알아낸 뒤, ISP DNS Cache에 캐싱한다.
분산 구조형 데이터베이스
- 데이터베이스 시스템(DNS 네임서버)의 분산 구성
- 데이터의 영역별 구분(Domain Zone) 및 분산관리
- 도메인의 네임서버 및 도메인 데이터는 해당 관리주체에 의해 독립적으로 관리됨
트리(tree) 구조의 도메인 네임(Domain Name) 체계
- Domain: 영역, 영토를 의미
- 도메인 네임의 자율적 생성
- 생성된 도메인 네임은 언제나 유일(Unique)하도록 네임 체계 구성
웹 기술의 창시자
- CERN(입자물리연구소)에서 컨설턴트로 근무
- 정보검색 시스템 구축, 문서와 문서간의 연결을 하이퍼링크로 표현
- 이를 바탕으로 현재의 웹 기술을 창안
- HTML(문서), HTTP의 창시자
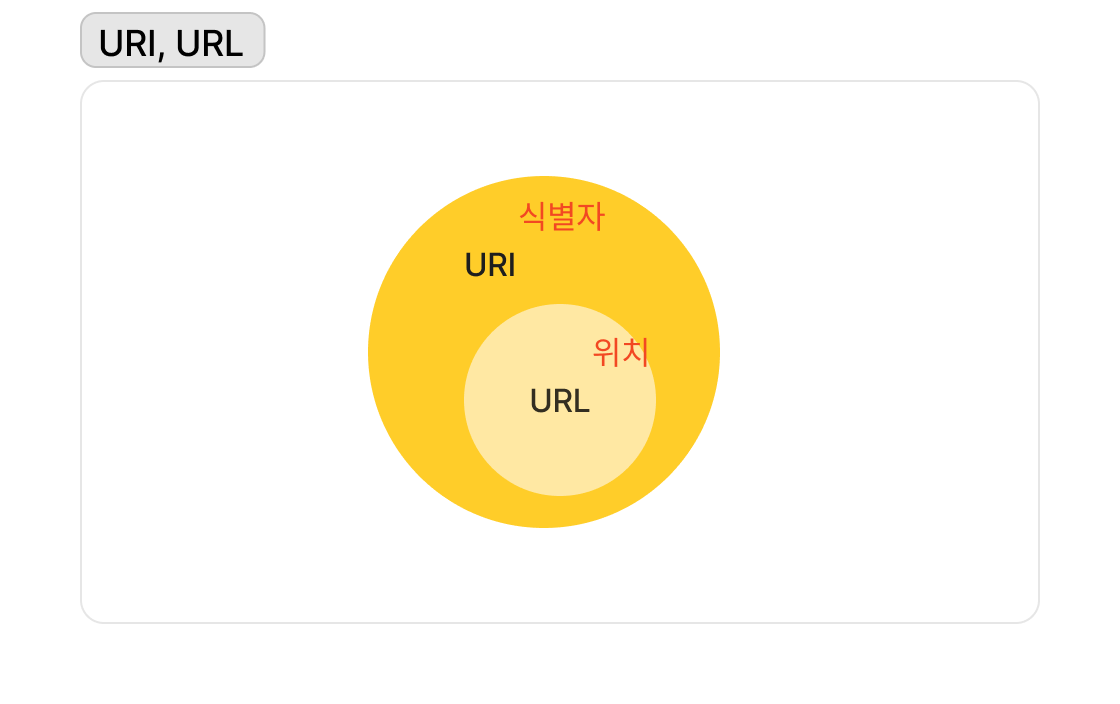
URL과 URI
- URL (Uniform Resource Locator): 위치 지정자
- URI (Uniform Resource Identifier): 식별자
Resource란 무엇일까?
웹 기술에 한정지어 생각하면, 웹의 본질은 HTML 문서를 나르기 위한 HTTP 프로토콜이다.
문서 파일이 저장된 위치를 Resource Locator이라고 한다.
HTML뿐 아니라 CSS, JPG, JS 파일들을 Resource라고 한다.
URL은 URI 하위의 개념이다. 식별자가 포괄적 개념이고, 위치는 파일을 특정하는 수준까지 디테일해지기 때문이다.
일반적으로 다음과 같은 형식을 가지고 있다.
Protocol://Address:Port/Path(filename)?Parameter=value
Protocol://도메인/경로?키=값&키=값
예시를 들면 다음과 같다.
http://www.test.co.kr/course.do?cmd=search&search_keyword=test
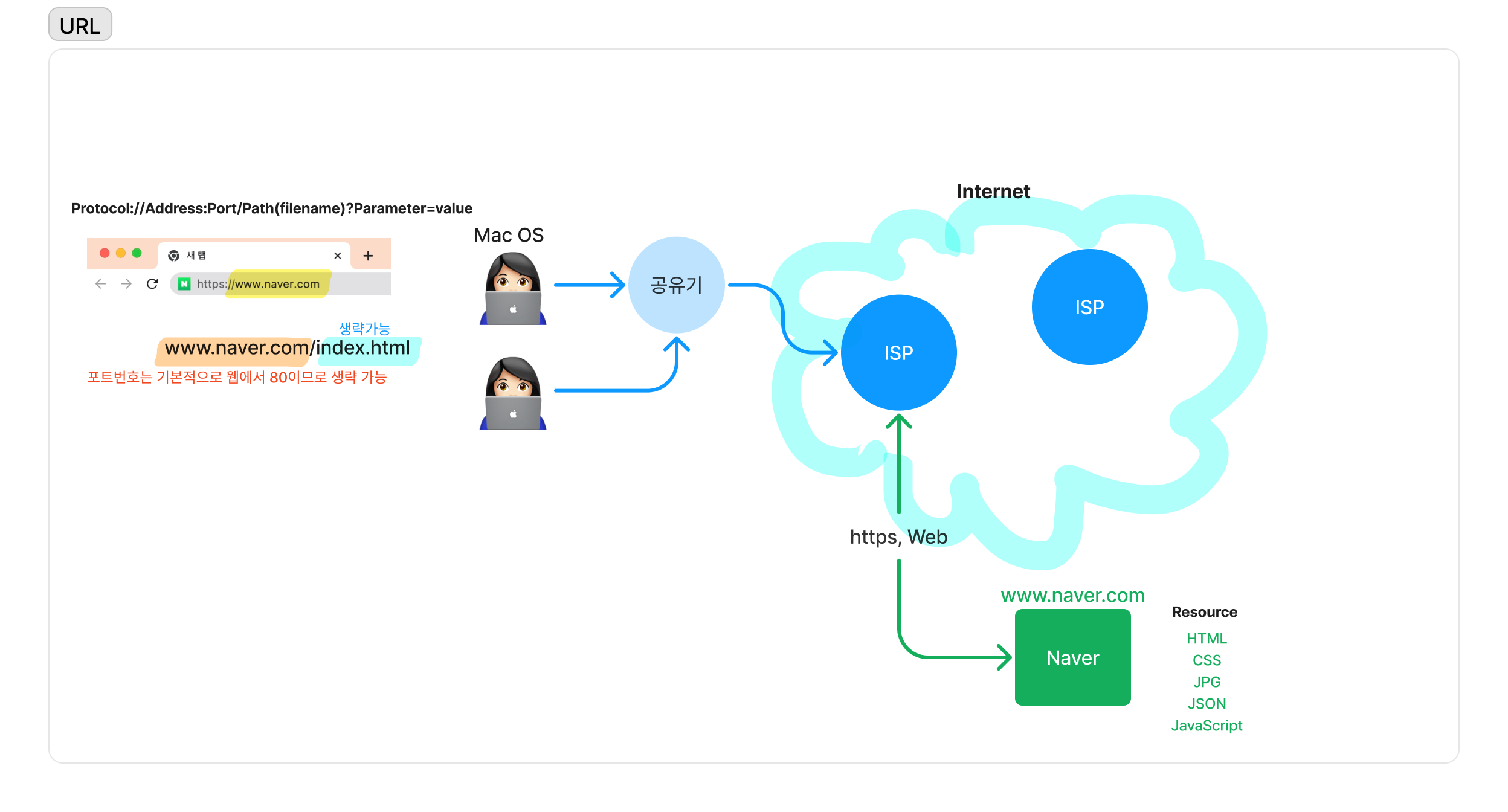
만약 http://www.test.co.kr 으로만 접속한다면 index.html이 생략된 것이다. 즉 http://www.test.co.kr/index.html 로 요청된다.
HTTP
HTTP는 HTML 문서를 전송 받기 위해 만들어진 응용 프로그램 계층(L7) 통신 프로토콜이다.
L5 이상은 Socket 통신이다. 즉 Stream 데이터 이므로 시작이 있지만 끝이 어딘지 알기 어렵다. 따라서 HTTP 프로토콜에서 끝을 지정해준다.
HTTP는 문자열로 구성되어 있어서 헤더를 읽어서 이해 가능하다.
헤더는 다음과 같이 분류된다.
- 일반 헤더
- 요청 헤더
- 응답 헤더
- 엔티티 헤더
기본적으로 클라이언트의 요청과 그에 대응하는 응답으로 동작한다. 리소스를 요청하면, 리소스를 응답한다.
요청하기 위한 방법을 메서드라고 한다.
요청에 사용되는 메서드는 주로 GET, POST이다.
HTTP 응답 코드

HTTP method
GET
리소스를 다운로드 받을 때 사용
POST
리소스를 업로드 할 때
ID/PW 입력해 로그인 할 때
PUT
리소스를 새로 업로드 할 때
DELETE
리소스를 삭제할 때
HEAD
TRACE
OPTIONS
CONNECT
웹 서비스 기본 구조
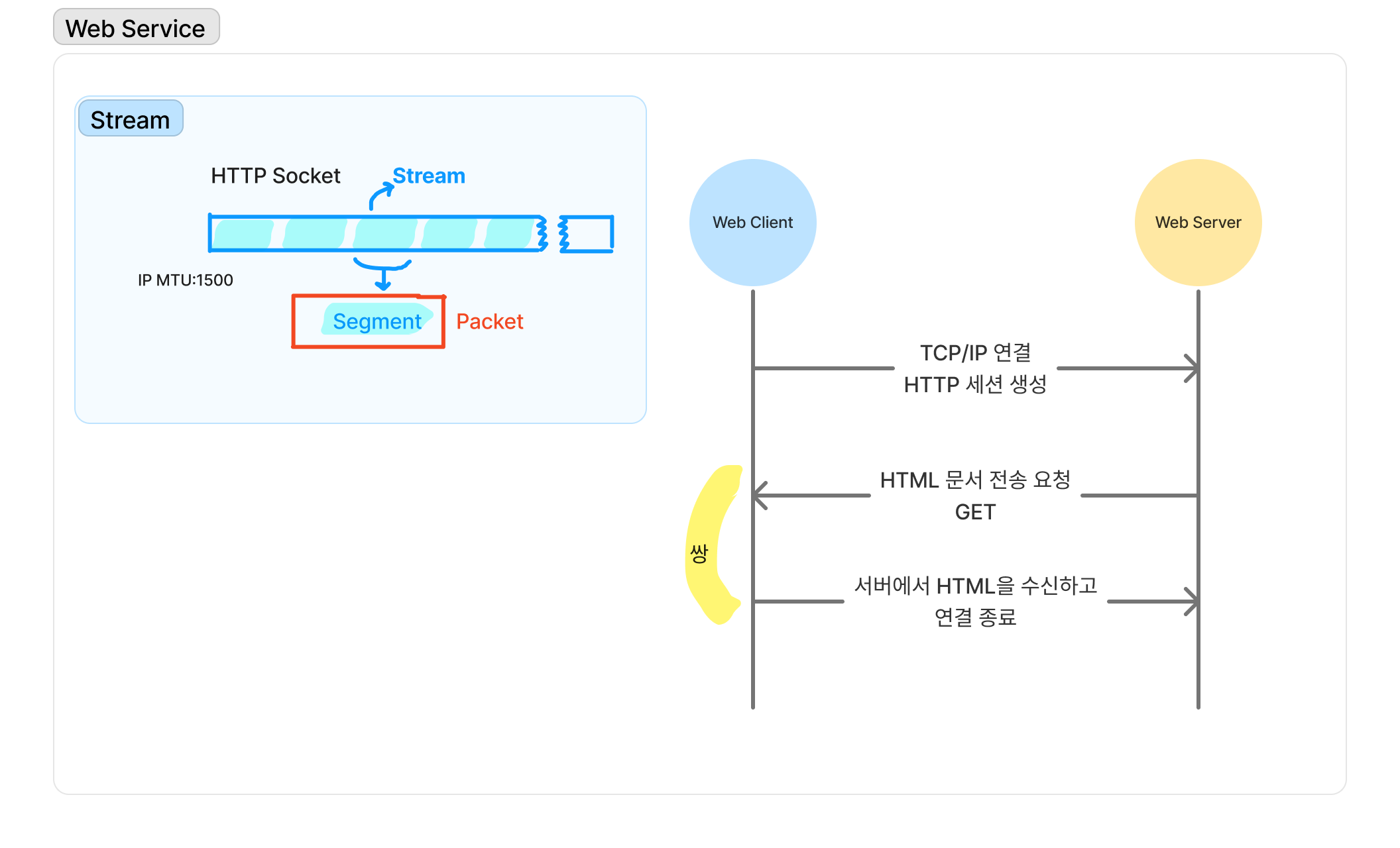
HTTP 트래픽은 Socket 수준에서 만들어짐으로 끝을 알기 어려운 데이터(Stream)으로 표현된다.
IP에서 MTU가 1500밖에 안돼서 TCP에서 스트림을 일정 단위(Segment)로 자른다.
이 세그먼트를 Packet으로 encapsulation해서 전송한다.
HTTP는 문자열로 구성되어 있어서 기본 구조는 간단하다. 항상 문서를 요청/응답 하는 쌍으로 구성되어 있다.
웹 서비스 기본 구조
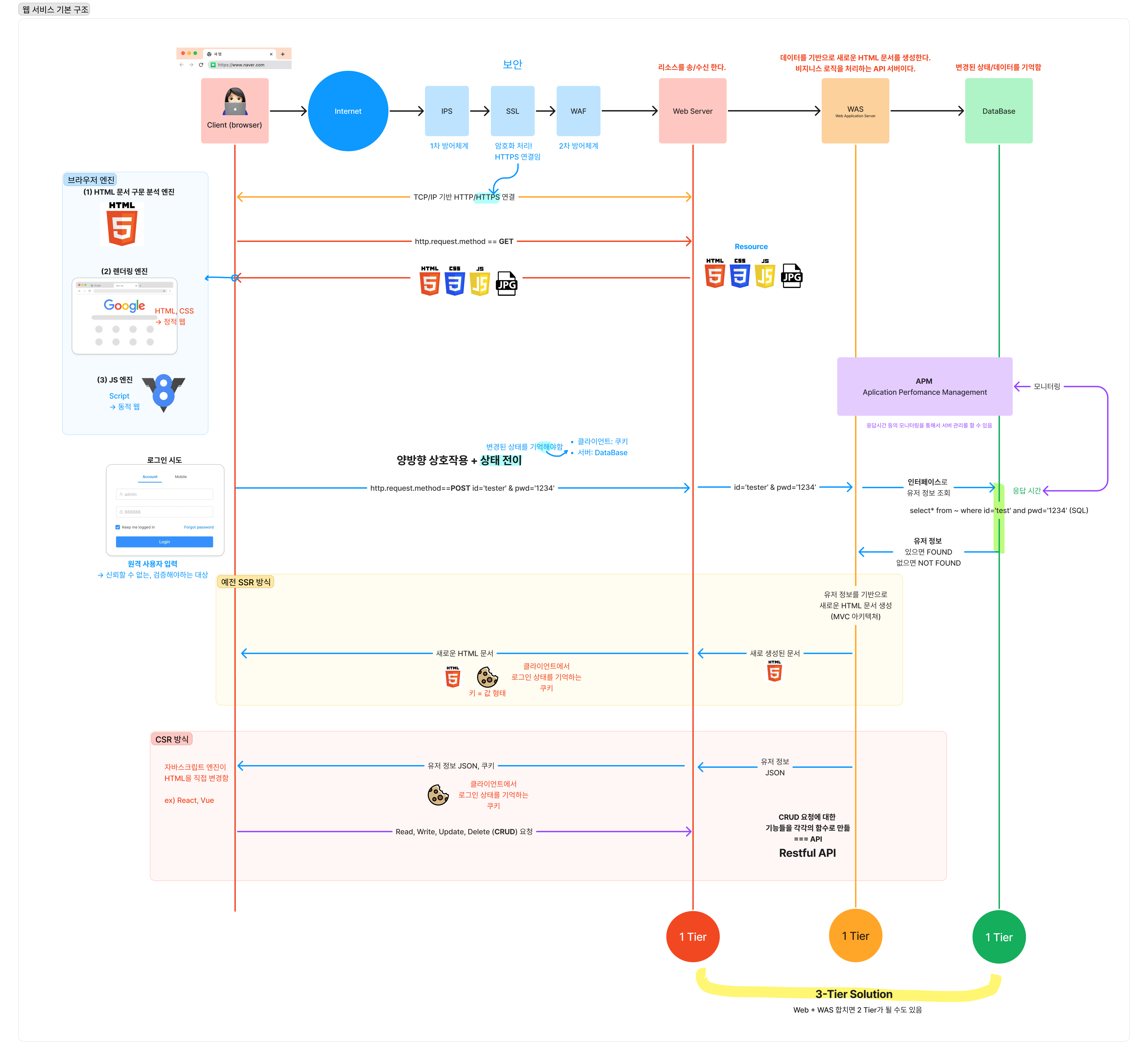
웹 서비스를 이루고 있는 기술을 종합해서 설명해보면 다음과 같다.
웹이란 HTML문서와 그를 전송하기 위한 HTTP프로토콜로 구성되어 있다.
웹서버 앞에 보통 라우터 같은 기본적인 장비를 빼고서도 3개 정도가 앞단에 존재한다.
웹 클라이언트와 웹 서버 간의 TCP/IP 의 연결을 기반으로 HTTP 통신이 이루어진다.
TCP 연결은 상태랑 관련이 있는데, HTTP는 상태 개념이 없는 Stateless이다. (이런 Stateless한 특징 때문에 로그인 상태를 기억하지 않아서 로그인 상태를 기억하는 쿠키가 만들어졌다.)
브라우저의 본질적인 역할은 문서를 볼 수 있는 문서(HTML) 뷰어이다. 이 리소스를 받기 위해선 브라우저 창에서 도메인을 입력하면 DNS에게 IP주소를 물어보고 그 IP 주소로 TCP/IP연결을 실시하고 그 연결을 기반으로 HTTP 통신을 수행한다.
http.request.method==GET 문서 라는 요청을 클라이언트에서 보내고, 서버는 이를 수신해서 HTML Resource를 응답한다. 브라우저에서는 받은 HTML을 받아서 화면에 표시한다.
MVC 프로그래밍 방식은 UI와 Data를 분리하고, 이 둘을 제어하는 로직 또한 분리해야한다. 이 원칙은 유지보수를 위해 따르는 것이 좋다.
이 관점 때문에 HTML 문서를 꾸미기 위한 문법을 HTML과 분리한 CSS 파일로 따로 생성한다.
정적인 웹에서 동적인 제어를 반영하기 위해서 스크립트가 탄생하였다.
최초에 Mocha Script가 탄생하고 이름을 Live Script 으로, 또 후에는 JavaScript로 변경하게 되었다.
HTML을 화면에 렌더링 하기 위해서는 HTML 문서를 구문 분석 해야한다. text와 tag를 분리해야 한다. 따라서 (1)구문 분석 엔진, (2) 렌더링 엔진, 더해서 스크립트까지 추가되면서 (3) 자바스크립트 엔진 까지 추가되었다.
웹 서비스를 구성하는 HTML, CSS, JS 등의 리소스들은 서버에 존재하고 클라이언트의 요청에 전송된다.
하지만 GET 방식 만으론 클라이언트는 문서 리소스를 제작하는 데에 동적으로 참여할 수 없어서 한계가 존재했다.
http.request.method==POST id='tester' & pwd='1234' 을 수행하면 로그인을 위해 ID, PWD를 서버에 전송할 수 있다. POST 메서드 탄생으로 의해 양방향으로 상호작용할 수 있게 되었다. 그렇게 상태 전이가 가능해졌고 상태를 기억해둘 필요가 생겼다.
이런 상태는 클라이언트에서 쿠키의 형태로 기억된다. 만약 이 상태를 서버에서 기억하게 된다면 기억해야 할 클라이언트들의 상태가 많기 때문에, 클라이언트에서 기억할 수 있도록 쿠키를 생성한다.
그럼에도 서버에서 클라이언트의 상태를 기억하고 싶은 경우엔 데이터베이스에 저장한다.
서버 관점에서 http.request.method==POST id='tester' & pwd='1234'는 원격지 사용자 입력이다. 이는 신뢰할 수 없고 검증해야 하는 대상이다.
상태를 저장하는 데이터베이스에서 select* from ~ where id='test' and pwd='1234' SQL문이 실행된다.
이때, 웹 서버는 데이터베이스에 직접 접근하지 않고, 웹서버와 데이터베이스 중간에 중개해주는 역할을 담당하는 서버가 존재한다.
웹 서버의 역할은 리소스를 송/수신 이다. 데이터베이스는 데이터를 저장하는 역할을 수행한다. 중간 서버(WAS - Web Application Server)는 어떤 연산을 담당한다.
WAS는 클라이언트로 부터 받은 데이터를 기반으로 새로운 HTML 문서를 생성한다. 이는 동적인 웹이 해당한다.
WAS와 데이터베이스는 여러 인터페이스로 연결되어있다.
이 인터페이스를 통해서 데이터베이스에서 SQL문이 실행된다.
WAS에서 데이터베이스에 로그인한 유저의 정보를 인터페이스로 조회했을 때, 존재하는 유저이면 Found 가 되며, 존재하지 않는다면 Not Found이다.
이렇게 조회한 데이터를 기반으로 새로 생성된 문서를 전달받은 클라이언트는 새로운 문서를 화면에 렌더링한다.
WAS에서는 새로운 문서를 생성하기 때문에 유지보수를 위해서 MVC 아키텍쳐를 기반으로 구성되어있다.
하지만 다양한 클라이언트에게 각각 환경에 맞춰 다른 HTML을 내려주는 것이 부담이 되었고, 무엇보다 SSR 방식이 새로운 문서를 받아서 처음부터 새롭게 그려주다보니 사용성이 좋지 않아서 CSR방식으로 변화하게 되었다.
CSR 방식은 화면을 그리는 HTML, CSS, JS를 먼저 로드한 다음, API로 CRUD 요청
을 보내 응답을 받아 클라이언트 단에서 HTML을 직접 조작하여 변경한다. 이때 사용하는 API는 Restful API 라고도 부른다.
그리고 WAS는 이런 CRUD 비지니스 로직을 처리하는 API서버이기도 하다.
클라이언트에서 인터넷을 통해 웹 서버로 HTTP 요청을 보낼때, SSL이 중간에서 암호화 처리를 수행한다면 HTTPS 방식이 된다.
또한 중간에서 IPS, WAF 가 보안을 위해 방어를 수행한다.
