개요
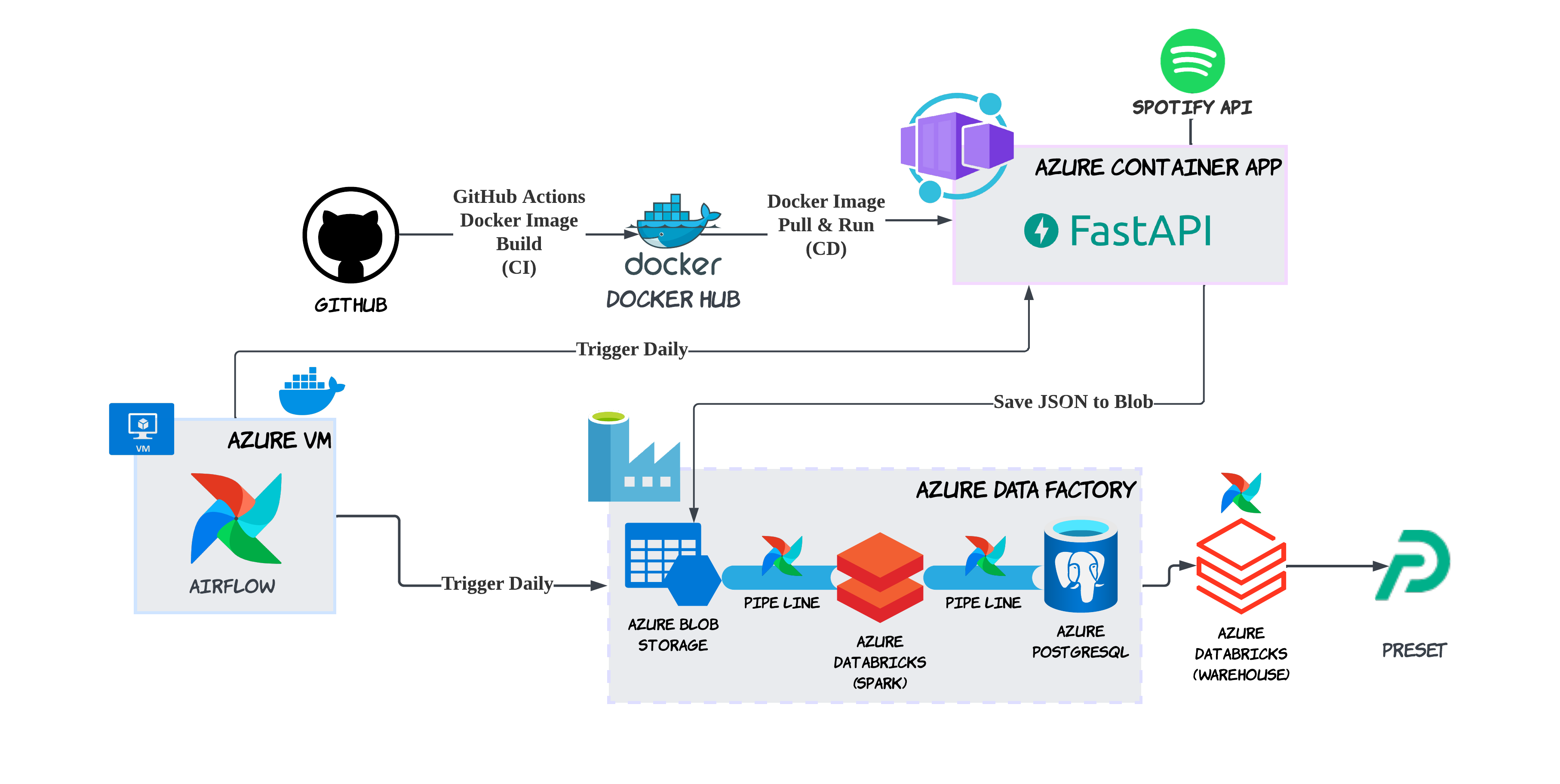
Spotify API를 활용해서 데이터를 꾸준히 모으고, 이를 시각화해서 볼 수 있는 대시보드를 구축하는 프로젝트를 했다. MLSA가 된 덕분에 매달 Azure $150 크레딧이 생겨서 평소에는 꿈도 못 꿨던 비싼 거 써봤다.
이 중에서 제일 비싼 서비스는 Databricks. 특히 웨어하우스를 쓰려면 Premium으로 사용해야 했는데, 14일 DBU 무료 체험을 할 수 있다. 가격이 얼마나 나올까 궁금해서 하루만 Standard로 써봤는데, Spark job 돌리면 DBU 가격이 2만원 나왔다. ㅎㅎ 심지어 Premium도 DBU만 무료고 VM 가격은 따로 받는다. 사용하지 않을 때 종료시켜놓고, 자동 종료시간 맞춰놔야 불필요한 돈이 나가지 않는다.
Azure Data Factory
전반적으로 Airflow로 스케줄링을 했는데, 사실 간단하게 하려면 Azure Data Factory만 써도 됐을 것 같다.
Pipelines
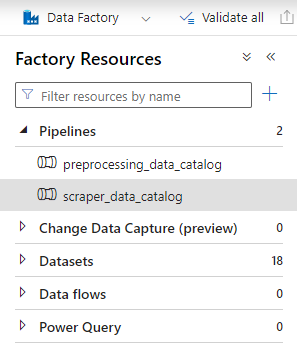
아키텍처처럼 데이터 팩토리 안에 파이프라인 2개를 만들었다. 이 파이프라인의 역할은, 내가 의도한 건 사실 AWS Glue의 catalog 같은 느낌이었다. 그래서 파이프라인 이름도 catalog로 지었다.
AWS와 Azure 서비스 비교에 관해 Azure에서 공식적으로 정리해둔 문서가 있다. Azure Purview 아니면 Data Factory라길래 Purview부터 사용해봤는데, 내 스타일이 아니었다.. 그래서 Data Factory로 갈아탔는데 가격도 저렴하고 마음에 든다.
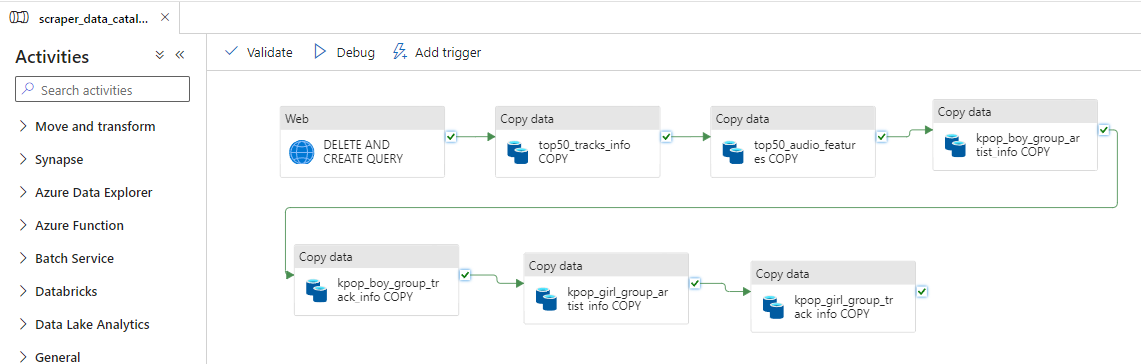
파이프라인 하나만 예시를 들자면 이렇게 구성했다.
PostgreSQL 서버에 쿼리를 날리기 위해 Web Activity를 추가했다. 쿼리 날리는 작업은 따로 구성해둔 백엔드 서버에서 수행한다. 그냥 이 Activity는 요청을 날려서 성공 응답을 받으면 다음으로 넘어간다.
나머지는 모두 Copy Data Activity다. Blob에 있는 *.json 파일을 읽어들여 Sink - Mapping 사전 세팅에 따라 PostgreSQL에 복사한다.
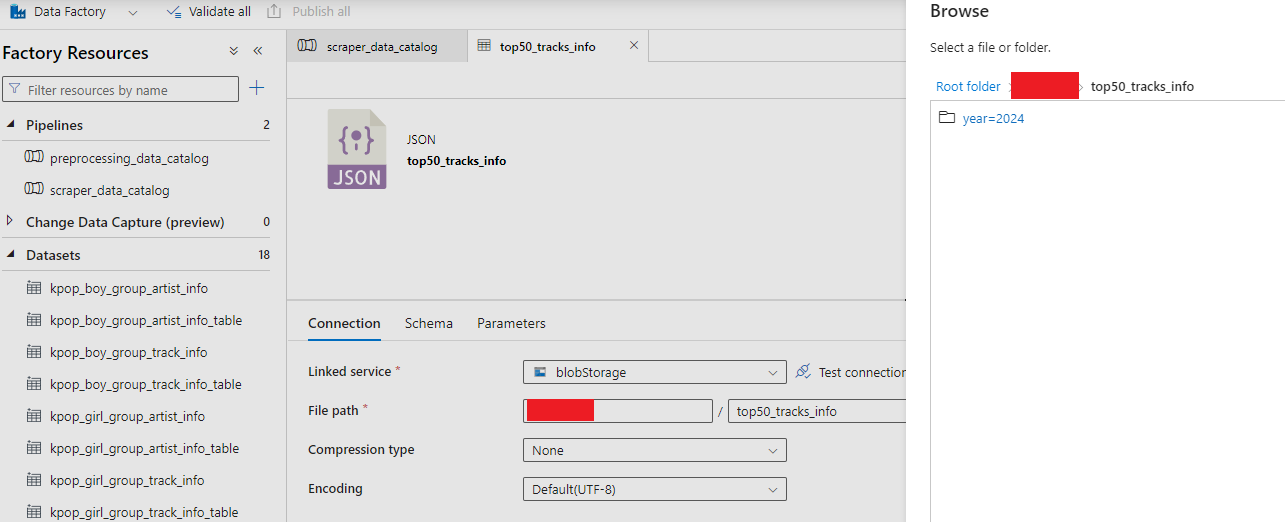
특히 *.json이나 *.parguet의 Copy Data Activity의 경우 이렇게 구성하면 AWS Glue의 카탈로그와 비슷한 느낌을 낼 수 있었다. AWS는 S3에서 날짜 파티션을 year=2024/...의 바로 바깥 폴더로 지정해 주면 알아서 파티션을 인식한다.
Azure Data Factory에서도 마찬가지다. 다만 두 번 작업을 해줘야 한다. 먼저 이렇게 year=2024 바깥 폴더를 지정해서 데이터셋을 만들어준다.

데이터셋을 불러오고 추가로 와일드카드 경로 입력을 통해 불러올 파일을 확정 지어야 한다. File path type 옵션에서 기본 값인 File path in dataset하면 와일드카드 지정하라고 오류가 뜨기 때문이다.
Spark
데이터 전처리를 위해 Spark를 쓰고 싶었는데, AWS의 경우 Glue 안에서 노트북, 파이썬으로 Spark 작업이 가능하지만 Data Factory는 다른 서비스에서 작성한 노트북, 파이썬을 Activity로 연결해야 했다.
Spark를 위한 Activity 선택지는 많았다.
1. Databricks
2. Synapse (이건 Data Lake Storage를 안 써봐서 아직도 잘 모르겠음)
3. HDInsight
이 과정에서 제일 시간을 많이 잡아먹었다. Spark 코드 자체는 금방 짰는데, 어떤 서비스를 써야 가장 좋을까 고민하면서 많이 시도해봤기 때문에 🙂
처음에는 HDInsight 쓰려고 했다. 그래서 quota 요청도 해서 부족한 만큼 받아내고, 설레는 마음으로 서비스를 시작했는데 세상에... 너무 느렸다. 시작될 때까지 계속 기다리는데, 이러다가는 매일 수행되는 작업이 이렇게 오래 걸려서 되겠나 싶었다.
Databricks
그래서 Databricks로 갈아탔다. ㅋㅋㅋ 몰랐는데 Azure에만 있는 게 아니라 AWS, GCP에도 서비스 되고 있더라. 공식문서가 Authentication 관련 내용 제외하고는 똑같은 내용으로 Microsoft, AWS 두 Document에 존재한다.
Databricks를 사용하게 된 계기는 다음과 같다.
1. Data Factory에 Spark Activity를 넣어야하는데 제일 만만했다.
2. 14일 무료체험해서 개인 프로젝트 수준인 나에게는 가격 부담이 덜했다.
3. 프리미엄이라면 Spark뿐만 아니라 Warehouse도 사용할 수 있었다.
그리고 이 댓글이 가장 나를 Databricks로 입문하게 만들었다.
Spark
Compute에 Cluster를 사용하면 PySpark 코드를 돌릴 수 있었다.
SQL Warehouse
Amazon Redshift Spectrum의 외부 테이블 느낌을 내고 싶었는데, 잘한 건가 모르겠다. 좀 산으로 간 느낌?
아키텍처 그림에서처럼 PostgreSQL에 있는 데이터를 SQL Warehouse로 주기적으로 옮기기 위해 정말 많은 사전 세팅을 했다.
Fivetran을 이용해 데이터를 주기적으로 sync 했다. 회원가입 따로 해야 한다.
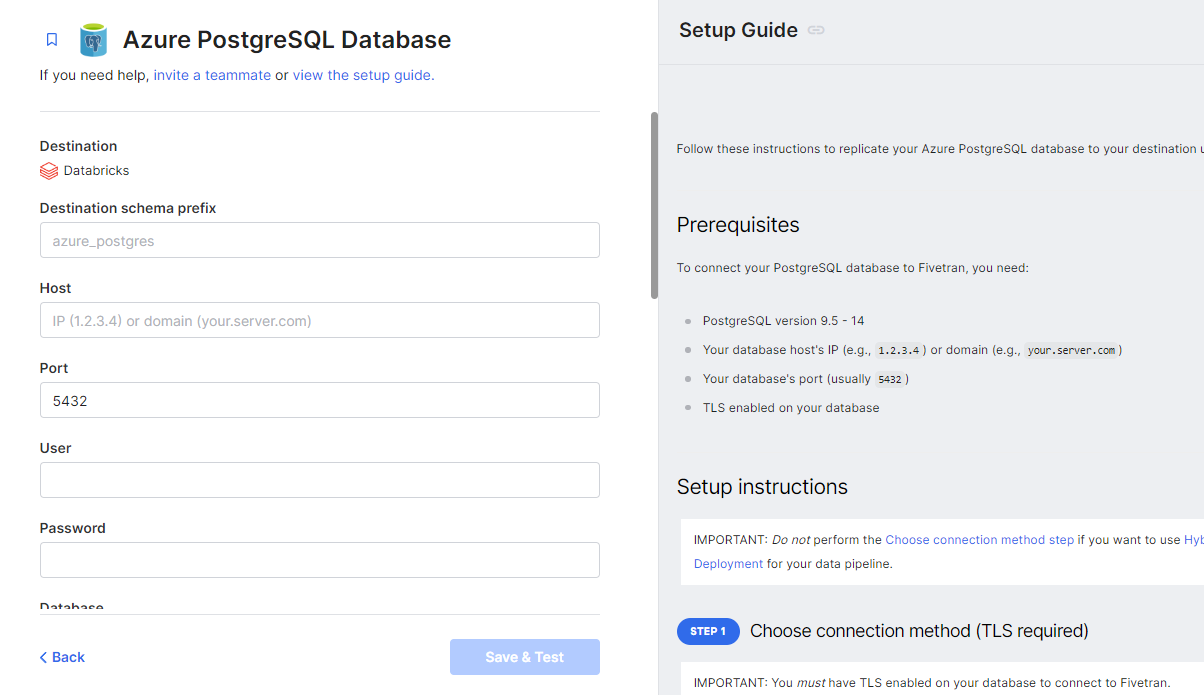
처음 연결하기 위해서 PostgreSQL 서버 정보를 입력해야 한다. 그리고 제일 중요한 작업. Setup Guide 못 보고 저장하려 하면 계속 실패한다. 왜 실패할까 고민하며 정말 많은 시간을 들였는데, 등잔 밑이 어둡다고... 각자 선택하고 싶은 Update Method에 맞는 Setup Guide를 읽고 따라 한 뒤에 저장해야 했었다. 앞으로는 글을 잘 읽자.
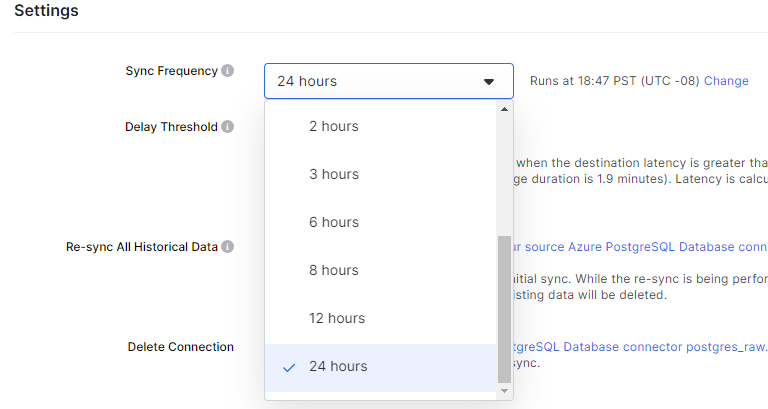
sync 시간을 지정할 수 있었다. 24hours를 고른 다음에 시간을 지정할 수 있다. 시간 지정하려고 API까지 써서 했는데, 홈페이지에서 할 수 있었다. 한참 찾았다. UTC 아니고 PST니까 조심하자.
Airflow Connections
나의 경우 지금 기준 가장 최신 버전인 Airflow 2.8.1을 사용했는데, Data Factory는 Connection Type 목록에 기본으로 있었지만, Databricks는 없었다.
그래서 docker-compose.yaml파일에 다음과 같이 추가했다. _PIP_ADDITIONAL_REQUIREMENTS: ${_PIP_ADDITIONAL_REQUIREMENTS:- apache-airflow-providers-databricks}
# 일부만 가져옴
from airflow.providers.databricks.operators.databricks_sql import DatabricksSqlOperator
from airflow.models import Variable
databricks_sql_endpoint = Variable.get("databricks_sql_endpoint")
create_schema_task = DatabricksSqlOperator(
databricks_conn_id='databricks_conn',
sql_endpoint_name=databricks_sql_endpoint,
task_id='run_dw_create_schema',
sql='create_schema.sql',
dag=dag,
)
Databricks SQL 웨어하우스 설정에서 아무리 찾아봐도 엔드포인트는 없었다. 알고 보니 그냥 내가 지정한 SQL 웨어하우스 이름 그 자체가 엔드포인트였다..🤦♀️
그리고 만약 토큰 관련 오류가 난다면 이 글을 참고하면 좋을 것 같다. token을 이미 한 번 Connections에서 지정했어도, Extra field에서 한 번 더 지정해 줘야한단다. (왜일까...?)
고찰
이 프로젝트를 기점으로 Azure 서비스를 많이 써봐서, 내게 여러모로 도움이 되었다. AWS랑 비교하기도 해보고, Azure 서비스에 관한 자료가 많이 없어서 계속 찾아보고 이것저것 다 시도하고😏 고생은 많이 했지만 다 해결해서 뿌듯하다.

안녕하세요 데이터엔지니어링 데브코스 관련해서 여쭙고싶은게 있는데 오픈카톡이라던지 연락 가능할까요?