

AWS 에서 서버 스트리밍 Upload를 버리고, 2GB 파일을 안정적으로 전송한 방법에 대해서 설명합니다.
1) 스트리밍(서버 중계) 업로드의 문제점
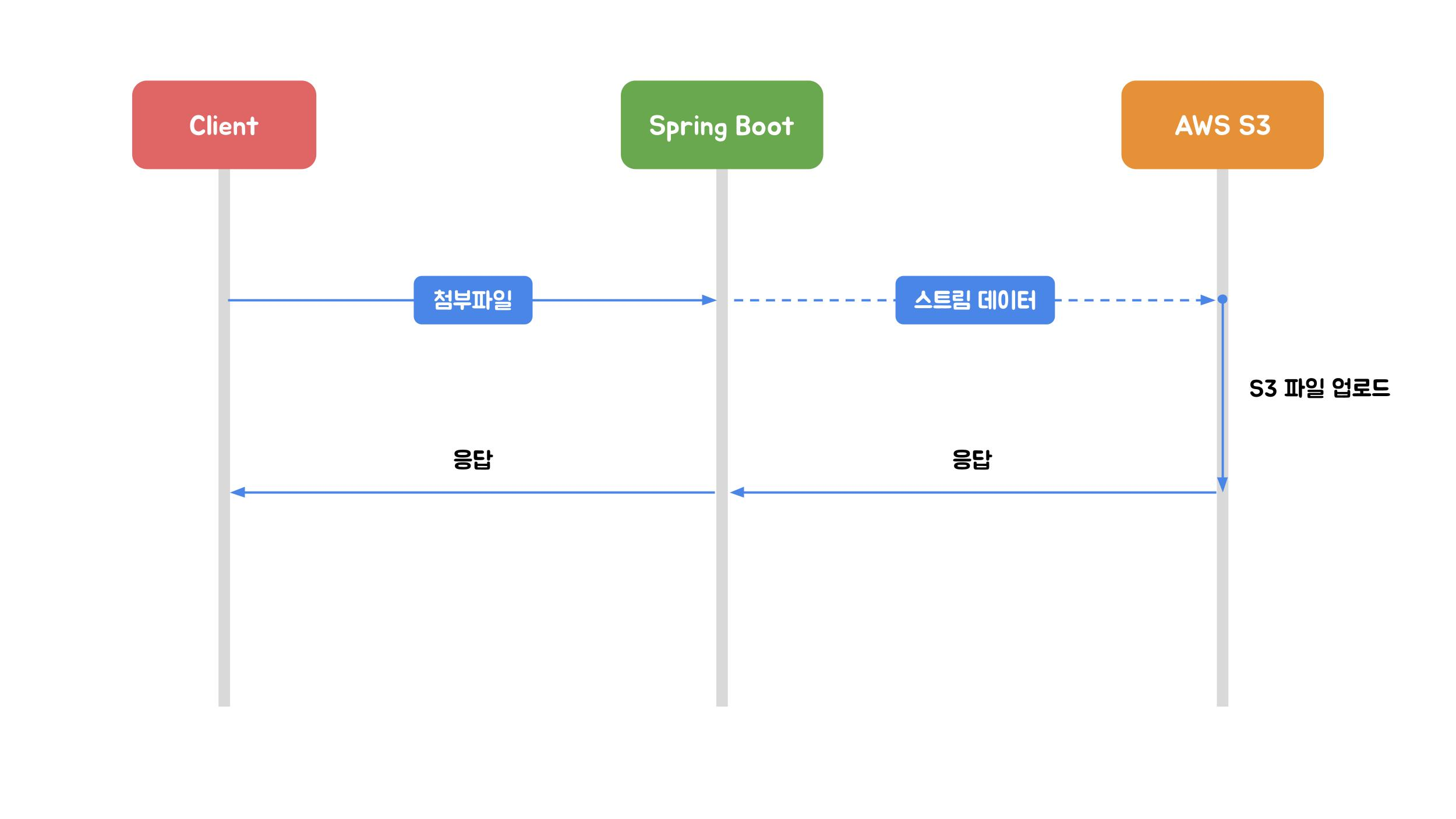
출처 : https://techblog.woowahan.com/11392/
하지만 제가 진행한 프로젝트에서의 파일 BMP는 최대 2GB에 달했고, 이 구조는 서버 네트워크 대역폭/커넥션이 병목 발생, 업로드가 길어질수록 타임아웃/중단 가능성 증가 등 곧바로 한계를 드러났습니다....
즉, 클라이언트와 AWS S3 사이에 spring boot가 중간에 역할을 수행하며 업로드/다운로드 때 두번의 과정을 거쳐 성능 부담이 발생할 수 있습니다.
Presigned URL
그래서 Presigned URL 방향으로 바꿨습니다.
API 서버는 파일을 받지 않고 업로드 권한만 발급합니다.
이렇게 하면 서버는 파일을 저장하지 않고 파일을 중계하지 않으며 트래픽 폭탄을 맞지 않습니다.
하지만… 단일 Presigned 업로드는 2GB에서 또 한계
Presigned URL로 “직접 업로드”는 해결했지만, 여전히 긴 업로드 시간 → 업로드 실패로 이어졌습니다...
Multipart 업로드 (+ presigend URL)
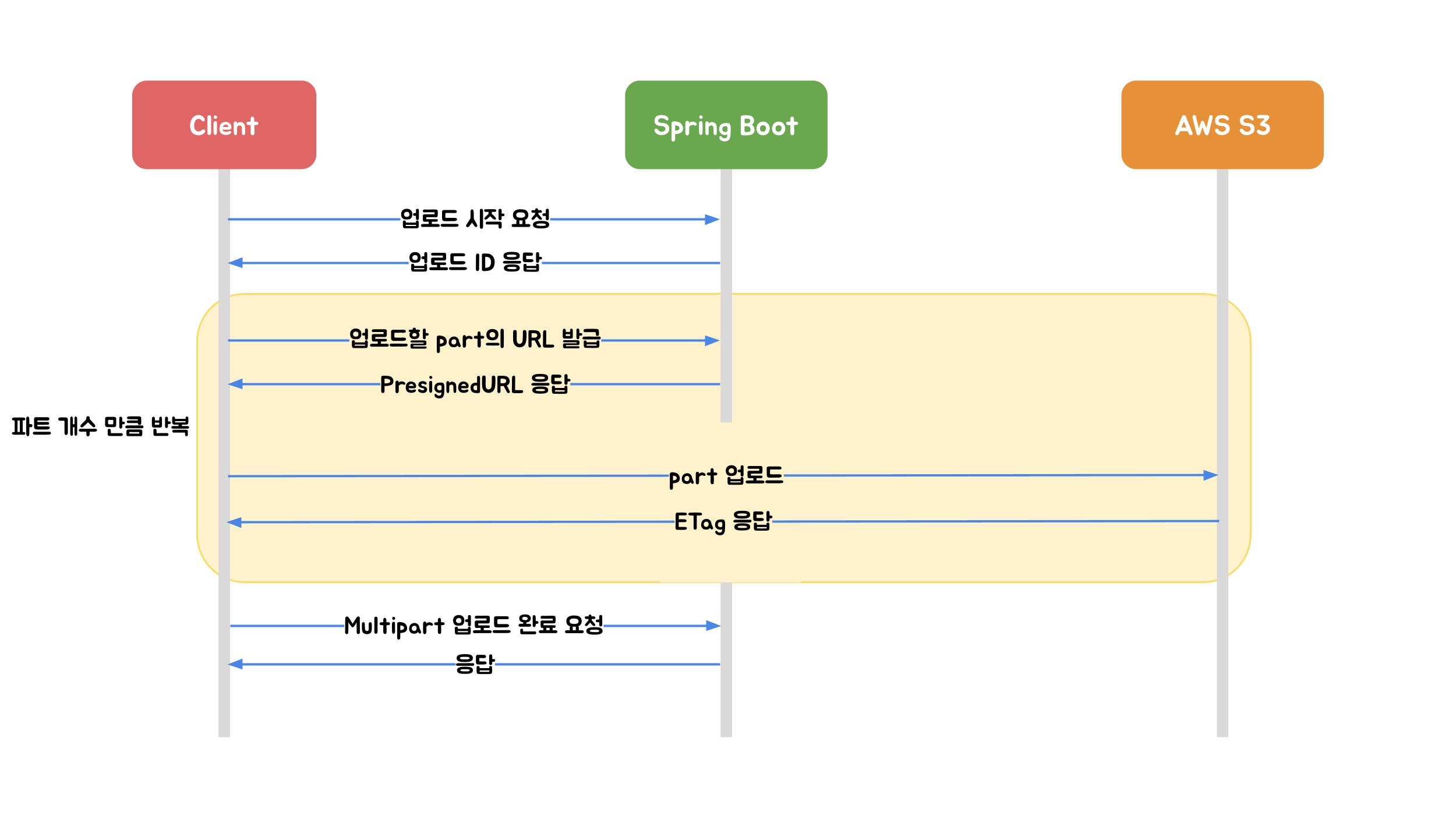
출처 : https://techblog.woowahan.com/11392/
Multipart Upload는 파일을 여러 파트로 나눠 올립니다.
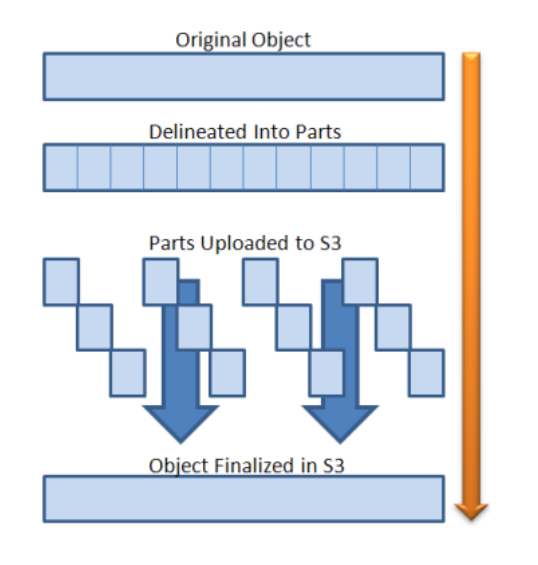
대용량에 유리한 이유는
- 부분 재시도 가능: 실패한 파트만 다시 업로드
- 병렬 업로드 가능: 여러 파트를 동시에 업로드 → 체감 시간 단축
- Spring Boot를 거치지 않고 AWS S3에 다이렉트로 업로드되기 때문에 서버의 부하를 고려하지 않아도 된다.
- 업로드 진행사항을 제공할 수 있습니다.
최종 흐름
1) API 서버: Multipart Init (uploadId 발급)
2) API 서버: part 개수 계산
3) API 서버: part별 Presigned URL 발급
4) C++ 서버: BMP 생성
5) C++ 서버: part별 병렬 PUT 업로드 + ETag 수집
6) API 서버: Multipart Complete 요청
7) C++ 서버: 완료 콜백(/bmp/{uuid}/complete) → DB 상태 갱신 + SSE
1️⃣. 백엔드 워커: Multipart Init + Presigned URL 리스트 발급
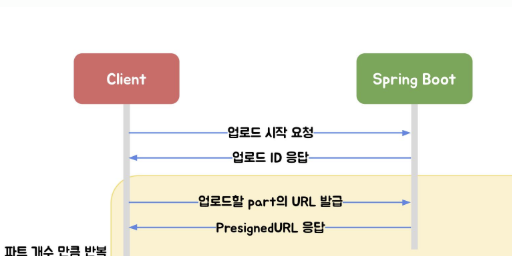
위 그림처럼
API 서버는 파일을 받지 않고 업로드 준비만 합니다.
@Async("imageGenerationExecutor")
public void createBmpImageAsync(Long generationHistoryId, UUID userUuid, String accessToken) {
try {
txService.markRunning(generationHistoryId);
GenerationHistory generationHistory = generationHistoryRepository.findById(generationHistoryId)
.orElseThrow(() -> new BusinessException(ErrorCode.NOT_FOUND));
String bmpFileName = generationHistory.getUuid().toString() + ".bmp";
// 1) Multipart Init
InitMultipartUploadResponse initMultipartUploadResponse = filePresignedService.initMultipartUpload(
"bmp", bmpFileName);
String uploadId = initMultipartUploadResponse.uploadId();
String objectName = initMultipartUploadResponse.objectName();
String bmpKey = S3Util.extractKeyFromUrl(initMultipartUploadResponse.imageUrl());
txService.setBmpKey(generationHistoryId, bmpKey);
// 2) Part 개수 계산(2GB 대비)
long volumeBytes = generationHistory.getBmpVolume();
int partCount = (int) Math.ceil((double) volumeBytes / S3_PART_SIZE);
if (partCount == 0) {
partCount = 1;
}
// 3) Part별 Presigned URL 리스트 생성
PresignedUrlListResponse presignedUrlListResponse = filePresignedService.createPartPresignedUrls(
objectName, uploadId, partCount);
List<String> partUploadUrls = presignedUrlListResponse.urls();
Auth auth = new Auth("Bearer", accessToken);
// 4) C++ 연산 서버에 업로드 정보 포함해 요청
GenerateImageApiRequest apiRequest = GenerateImageApiRequest.from(
partUploadUrls,
uploadId,
objectName,
auth,
generationHistory
);
externalApiClient.requestGenerate(apiRequest);
log.info("[BMP 생성 요청] C++ API 호출 완료 (멀티파트 {}개), historyId={}", partCount,
generationHistoryId);
} catch (Exception e) {
log.error("[BMP 생성 실패] historyId={}, userUuid={}", generationHistoryId, userUuid, e);
handleFailure(generationHistoryId, userUuid, e);
}
} 서버는 uploadId, objectName, partUploadUrls를 만들고 실제 업로드는 C++ 서버가 한다는 점입니다.
2️⃣. 백엔드 → C++ 연산 서버 호출(업로드 정보 전달)
public GenerateImageApiResponse requestGenerate(GenerateImageApiRequest generateImageRequest) {
return rest.post()
.uri("/generate")
.contentType(MediaType.APPLICATION_JSON)
.body(generateImageRequest)
.retrieve()
.onStatus(HttpStatusCode::isError, (r, res) ->
new ResponseStatusException(res.getStatusCode(), "API 호출 실패"))
.body(GenerateImageApiResponse.class);
}API 서버는 여기서 요청만 보냅니다.
3️⃣. C++ 서버: /generate로 job enqueue (비동기 큐)
C++ 서버는 요청을 받으면 job 파라미터를 파싱해 큐에 넣습니다.
svr.Post("/generate", [](const httplib::Request& req, httplib::Response& res) {
json j = json::parse(req.body);
conv::GenerateJob job;
job.partUploadUrls = j.at("partUploadUrls").get<std::vector<std::string>>();
job.uploadId = j.at("uploadId").get<std::string>();
job.objectName = j.at("objectName").get<std::string>();
job.generationUuid = j.at("generationUuid").get<std::string>();
job.bmpWidth = j.at("bmpWidth").get<uint32_t>();
job.bmpHeight = j.at("bmpHeight").get<uint32_t>();
job.bmpVolume = j.at("bmpVolume").get<uint64_t>();
// (생략) RGB 패턴 파라미터들...
conv::enqueueGenerateJob(std::move(job));
res.status = 202;
res.set_content(R"({"ok":true,"status":"ACCEPTED"})", "application/json");
});4️⃣. C++ 워커: BMP 생성 → Part별 업로드 → Complete 호출

CUDA 커널로 픽셀을 채워 BMP를 만든 뒤,
Multipart URL 리스트로 파트를 업로드하고 ETag를 수집합니다.
if (!job.partUploadUrls.empty()) {
std::vector<std::pair<int, std::string>> parts;
// 1) Part별 업로드 + ETag 수집
if (!io->uploadFileWithMultipartUrls(bmpPath.string(), job.partUploadUrls, parts)) {
throw std::runtime_error("multipart upload failed");
}
// 2) Complete에 필요한 parts(partNumber, eTag) 배열 구성
nlohmann::json partArray = nlohmann::json::array();
for (auto& p : parts) {
partArray.push_back({ {"partNumber", p.first}, {"eTag", p.second} });
}
// 3) Backend로 complete 요청(/s3/complete)
nlohmann::json body = {
{"uploadId", job.uploadId},
{"objectName", job.objectName},
{"parts", partArray}
};
std::string completeUrl = std::string(std::getenv("CALLBACK_BASE_URL")) + "/s3/complete";
io->postJson(completeUrl, body.dump(), headers, &httpCode, &resp);
}(ETag HTTP 응답 헤더는 특정 버전의 리소스를 식별하는 식별자입니다.)
파트 업로드 중 일부만 실패하면 그 파트만 재시도 가능하고 병렬 업로드로 전체 업로드 시간을 줄일 수 있습니다!!
5️⃣. 완료 콜백: DB 상태 갱신 + SSE 알림

업로드가 끝나면 C++ 서버는 백엔드에 완료 콜백을 날립니다.
json body = {
{"isSuccess", true},
{"errorMessage", nullptr},
{"generationUuid", job.generationUuid},
{"bmpVolume", bmpVolume}
};
const std::string cb = callbackBase + "/bmp/" + job.generationUuid + "/complete";
io->postJson(cb, body.dump(), headers, &code, &resp);백엔드는 콜백을 받아 상태를 COMPLETED/FAILED로 바꾸고, SSE로 사용자에게 알립니다.
