[CI/CD] 무중단 배포로 전환하기
다운 타임이 존재
기존 workflow는 기존 도커 컨테이너를 중단 후 ECR로 부터 pull 을 받아서 재실행하는 구조였다. workflow 는 다음과 같다.
name: Deploy to EC2
on:
push:
branches:
- master
jobs:
Deploy:
runs-on: ubuntu-latest
steps:
- name: Github Repository 파일 불러오기
uses: actions/checkout@v4
- name: JDK 17버전 설치
uses: actions/setup-java@v4
with:
distribution: temurin
java-version: 17
- name: Grant execute permission for gradlew
run: chmod +x ./gradlew
- name: 테스트 및 빌드하기
run: ./gradlew clean build
- name: AWS Resource 에 접근할 수 있게 AWS credentials 설정
uses: aws-actions/configure-aws-credentials@v4
with:
aws-region: ap-northeast-2
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
- name: ECR에 로그인
id: login-ecr
uses: aws-actions/amazon-ecr-login@v2
- name: Docker 이미지 생성
run: docker build -t meeteam-server .
- name: Docker 이미지에 Tag 붙이기
run: docker tag meeteam-server ${{ steps.login-ecr.outputs.registry }}/meeteam-server:latest
- name: ECR에 Docker 이미지 Push
run: docker push ${{ steps.login-ecr.outputs.registry }}/meeteam-server:latest
- name: SSH 로 EC2 에 접속하기
uses: appleboy/ssh-action@v1.0.3
with:
host: ${{ secrets.EC2_HOST }}
username: ${{ secrets.EC2_USERNAME }}
key: ${{ secrets.EC2_PRIVATE_KEY }}
script_stop: true
script: |
set -e
cd /home/ubuntu/meeteam
docker stop meeteam-server || true
docker rm meeteam-server || true
docker compose pull meeteam-server
docker compose up -d meeteam-server
docker stop meeteam-server || true
여기서 서비스가 중단되고
docker compose up -d meeteam-server
에서 서비스가 다시 시작되는 구조이다.
해당 타임에는 중단타임이 존재하여 사용자는 서비스 이용을 못하는 구조였다.
중단타임을 측정해보니 대략 5분 정도의 시간 동안은 서버에 내려가 있다.
Blue/ Green 무중단 배포로 전환
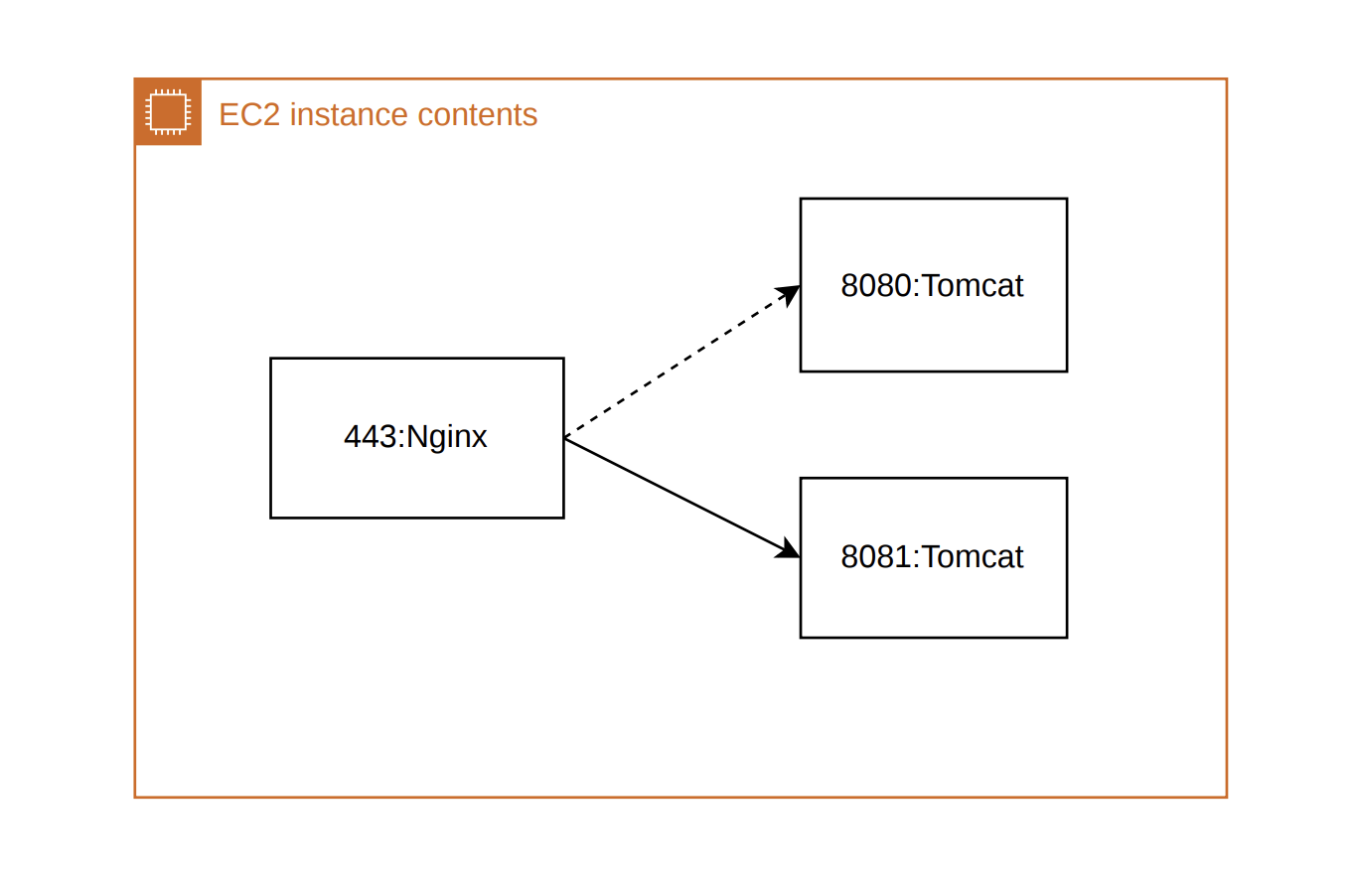
무중단 배포 방식에는 여러 방식이 존재하지만, 미팀에서는 단일 인스턴스를 사용하므로
Blue / Green 배포를 통해 무중단 배포로 전환을 하기로 했다.
배포 전에는 443포트에 바인딩된 Nginx 프로세스와 8080 포트에 바인딩된 톰캣 프로세스가 실행중이다.
Nginx로 들어온 요청은 8080 포트로 포트포워딩 한다. 배포가 시작되고, 새로운 톰캣 프로세스를 실행하고
8081로 바인딩한다. 이후 Nginx 는 포트포워딩을 8080 포트에서 8081 포트로 전환한다.
Nginx 가 포트전환을 위해서는 설정 변경이 필요하다. 설정 변경을 위해서 Nginx 가 Reload를 해야한다.
Reload는 ReStart 와 다르게 설정만 다시 읽는 과정으로 서비스는 끊기지 않고 설정만 바뀐다.
Reload 하는 과정에서는 프로세스 내부에서
기존 worker ---- 요청 처리 중
↓
새 설정 로드
↓
새 worker 생성
↓
기존 worker 종료 (요청 끝나면)
다음과 같은 과정이 일어난다. 여기서 worker 교체 순간이 완전 0ms 는 아니다. 즉 아주 짧은 타이밍에 실패가 발생할 수 있다. 아주 찰나에 순간이지만 다운 타임이 얼마나 발생하고, 사용자의 요청이 얼마나 실패하는지 확인하기 위해 테스트를 진행해 보았다.
테스트는 Jmeter 를 이용하여 300개의 동시 요청을 배포 전부터 배포 후까지 무한히 반복했다.
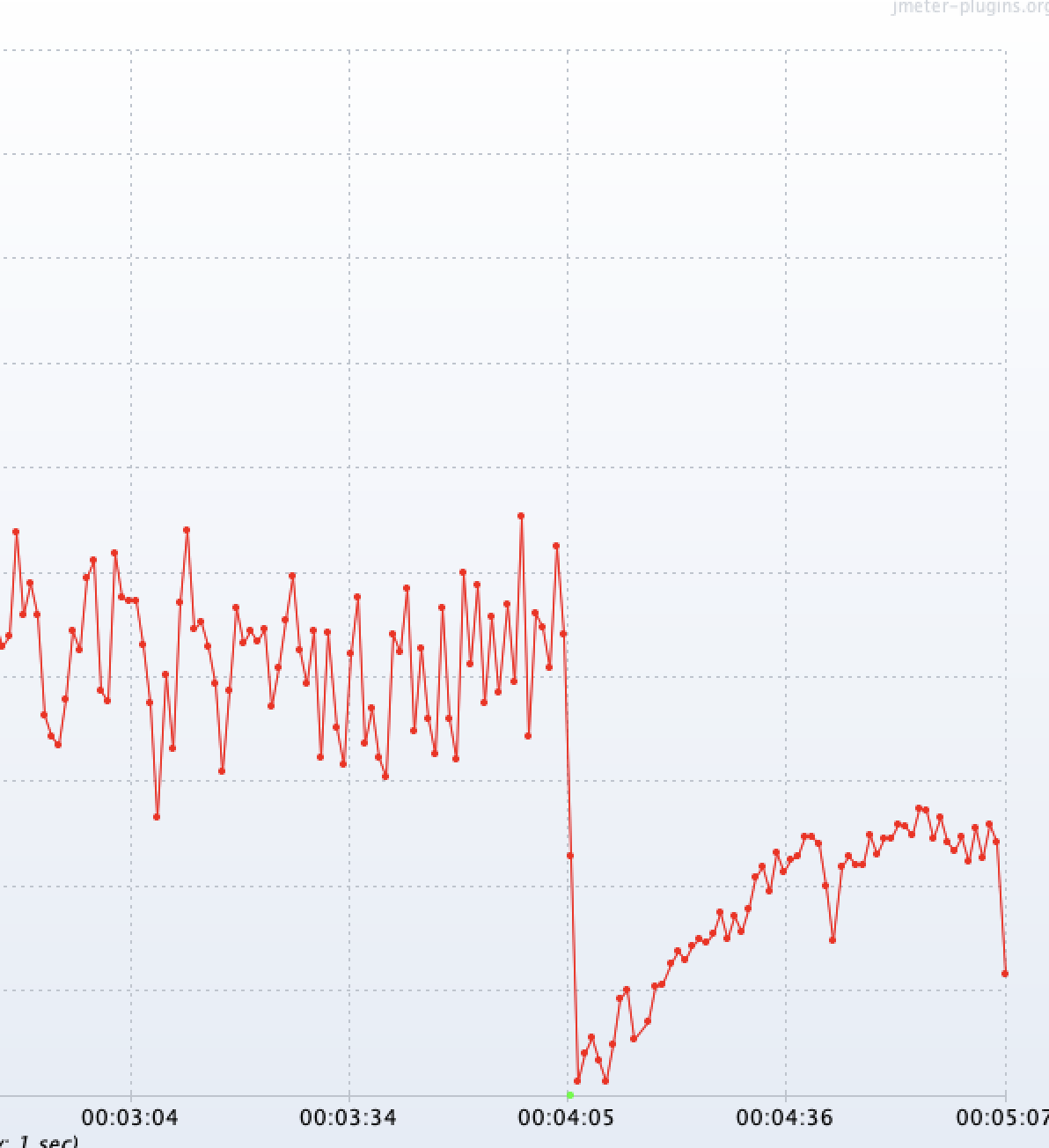
빨간색 점은 성공한 요청이고 초록색은 실패한 요청이다.
아주 짧은 찰나의 순간에 하나의 요청만 실패했다. 이는 사용자 경험에 크게 영향을 미치지 않을것이라고 생각했다.
단 하나의 요청만 실패한 요청이였기에, 언제 사용자의 요청을 실패하는지 찾아보았지만, 너무 많은 요청이 존재해서 찾지 못했다.
추가적인 고민
프로세스가 전환되는 과정에서 새로운 톰캣 프로세스가 올라가고 기존 프로세스는 종료 될때, 순간적으로 N개 의 톰캣이 올라가 있다.
여기서 DB 의 Connection 이 부족해 새로운 프로세스가 올라갈때
커넥션풀을 생성하지 못할수도 있을것이다.
예를들어, DB의 Max connection 이 40 일때, 각각의 커넥션 풀의 기본값이 30이면 2개의 프로세스가 올라가 있는 동안, 일시적인 순간에는 60개의 커넥션이 필요할텐데, 그럼 30 * 2 < 50 이므로 새로운 프로세스가 커넥션 풀 생성에 실패할수도 있을것이다.
미팀 프로젝트에서는 minimum pool size 가 크지 않고, 배포시에 2개의 프로세스 밖에 존재하지 않으므로 문제가 없을것이지만, 많은 프로세스가 올라갈 경우에는
스레드풀의 개수또한 신경써야할것이라고 생각한다.
