💬 잡담
좋은 코드 나쁜 코드 완독 후기, 나의 Spring 학습법, 미션 회고, 바이브 코딩 등등 학습하면서 블로그로 작성하고 싶은 주제들이 쌓여가는데, 밀린 일을 처리하느라 바빠서 도저히 글 쓸 시간이 나지 않는다. 🥲
❓코어와 멀티코어에 대해 설명해 주세요.
이전 챕터까지 명령어를 실행하는 부품을 CPU라고 불렀다면, 이제부터는 코어라는 용어를 사용해야 한다.
- 코어: 명령어를 실행하는 부품
- CPU: 여러 개의 코어를 포함하는 부품
코어를 2개 이상 포함하고 있는 CPU를 멀티코어 프로세서(=멀티코어 CPU)라고 부른다.
프로세서는 비단 CPU만을 말하는 용어는 아니다. GPU도 프로세서의 한 종류다. 그러나 일반적으로 컴퓨터 구조, 운영체제에서 말하는 프로세서는 CPU를 의미한다.
❓ 스레드와 멀티 스레드에 대해 설명해 주세요.
✅ 스레드란?
In computer science, a thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler, which is typically a part of the operating system. In many cases, a thread is a component of a process.
출처: https://en.wikipedia.org/wiki/Thread_(computing)
스레드는 하나의 프로그램 안에서 명령어를 순차적으로 실행하는 독립적인 흐름을 담당하는 실행 단위다. 프로그래밍 관점에서 스레드는 특정 코드 블록이 다른 실행 흐름과 독립적으로 실행될 수 있도록 보장해주는 기능이라 보면 될 것 같다.
✅ 하드웨어 스레드와 소프트웨어 스레드
CPU에서 사용되는 스레드는 하드웨어 스레드(=논리 프로세서), 프로그램에서 사용하는 스레드는 소프트웨어 스레드라고 부른다. 소프트웨어 스레드는 운영체제에 의해 하나 이상의 하드웨어 스레드에 매핑되어 실행된다.
하나의 코어는 여러 개의 하드웨어 스레드를 가질 수 있다. 하나의 코어가 2개의 하드웨어 스레드를 이용해서 명령어를 동시에 처리하는 기술을 intel사에서는 하이퍼스레딩이라고 한다.
하이퍼스레딩과 같이 한 개의 코어가 둘 이상의 하드웨어 스레드를 실행할 수 있는 기능이 탑재된 코어를 멀티스레드 프로세서라고 한다.
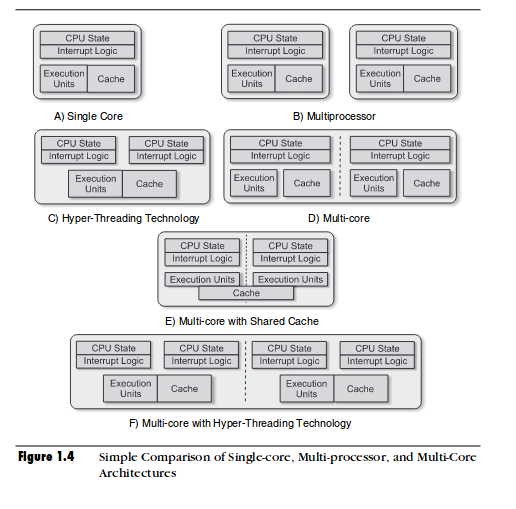
📌 용어 정리
포함 관계: 시스템 ⊃ 프로세서 = CPU ⊃ 코어 ⊃ 하드웨어 스레드
- 멀티프로세서(Multiprocessor)
- 하나의 시스템에 CPU가 2개 이상 존재하는 경우를 의미한다.
- 프로세서(Processor)
- 프로세서는 여러 개의 코어를 가질 수 있다.
- 멀티 코어(Multi-Core)
- 하나의 CPU 칩에 2개 이상의 물리 코어가 내장된 경우를 의미한다.
- 하이퍼스레딩
- 하나의 물리 코어가 동시에 2개의 하드웨어 스레드를 처리할 수 있게 설계된 기술
- 논리 코어 수를 2배로 보이게 한다.
- ex. 물리 코어 4개에 하이퍼스레딩 기술을 적용하면, OS가 논리 코어 개수를 8개로 인식한다.
- 멀티스레드 프로세서
- 하나의 물리 코어 내부에서 둘 이상의 하드웨어 스레드를
동시에 실행할 수 있도록 설계된 프로세서 - ex. 하이퍼스레딩 기능이 탑재된 코어
- 하나의 물리 코어 내부에서 둘 이상의 하드웨어 스레드를
❓ 명령어 파이프 라인에 대해 설명해 주세요.
명령어 처리 과정(Instruction Cycle)을 여러 단계로 나누고, 각 단계가 서로 독립적으로 실행될 수 있는 환경이 갖추어졌다고 가정해보자.
그리고 명령어 처리 과정을 Fetch, Decode, Excute, Memory Access, Write Back 5개의 단계로 나누어 처리한다고 해보자. (단계를 나누는 방식은 전공 서적마다 조금씩 다를 수 있다.)
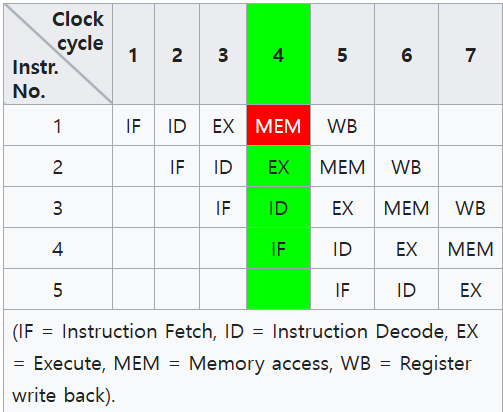
출처: https://en.wikipedia.org/wiki/Instruction_pipelining
하나의 하드웨어 스레드가 각 클럭 사이클마다 여러 명령어의 다른 단계를 동시에 수행하는 방식을 명령어 파이프라이닝이라고 한다.
❓ 슈퍼스칼라가 무엇인가요?
앞서 설명한 방식은 CPU가 한 번에 하나의 단계만 처리하는 단일 파이프라이닝 방식이고, CPU가 한 번에 여러 단계를 처리하는 방식도 존재한다.
✅ 슈퍼스칼라(Superscalar)
슈퍼스칼라는 CPU가 한 클럭 사이클 동안 여러 개의 명령어 처리 단계를 동시에 실행할 수 있는 구조를 의미한다. x86, ARM이 슈퍼스칼라 구조로 설계되어 있다.
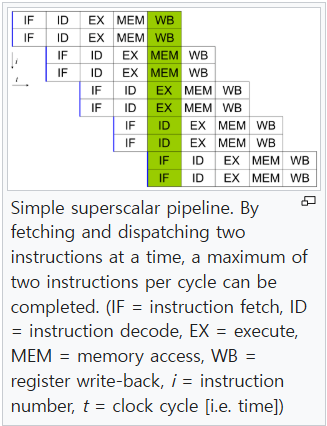
출처: https://en.wikipedia.org/wiki/Superscalar_processor
❓ RISC와 CISC에 대해 설명해 주세요.
✅ 명령어 집합(Instruction Set)
CISC와 RISC를 설명하기 전에 먼저 명령어 집합에 대해 알아야 한다.
세상에는 여러 CPU 제조사가 존재하고 각 CPU는 설계 철학에 따라 다른 명령어 집합을 사용한다.
Intel CPU에서 사용하는 x86 아키텍처는 CISC 명령어 집합을 사용하고, 맥부기에서 사용하는 ARM 아키텍처는 RISC 명령어 집합을 사용한다. 둘은 메모리 접근 방식, 명령어의 표현 방식, 명령어 실행 구조가 서로 다르다.
프로그래머의 관점에서 알아야 하는 점만 설명하면, 본인이 작성한 소스 코드를 기계어로 된 실행 파일로 만들었을 때 그 기계어는 특정 CPU 아키텍처에서만 사용할 수 있는 실행 파일이라는 것이다.
📌 Cross Compile
특정 아키텍처에서 컴파일된 기계어 파일을, 다른 아키텍처의 하드웨어 상에서 실행하기 위해서는 크로스 컴파일(Cross Compile)을 통해 변환하는 과정을 거쳐야 한다.
✅ CISC(Complex Instruction Set Computer)
A complex instruction set computer (CISC) is a computer architecture in which single instructions can execute several low-level operations (such as a load from memory, an arithmetic operation, and a memory store) or are capable of multi-step operations or addressing modes within single instructions
출처: https://en.wikipedia.org/wiki/Complex_instruction_set_computer
ex. x86
'복잡한 명령어 집합을 활용하는 컴퓨터'를 의미한다. 명령어 1개가 여러 저수준의 작업(ex. 메모리 접근/저장, 수학적 연산)을 처리할 수 있게 묶어 놓았다고 생각하면 된다. 복잡한 연산을 하나의 명령어로 처리하기 위해 다양한 명령어를 추가하다 보니 명령어 집합이 크고, 각 명령어 마다 복잡한 정도에 차이가 있어, 실행 시간이 일정하지 않을 수 있다.
📌 micro-ops(micro-operations)
현대의 x86은 CISC와 RISC의 혼용 방식을 사용하고 있다. 컴파일 시에는 CISC 아키텍처를 따르고, CISC 명령어를 CPU 내부에서 RISC 형태의 micro-op으로 변환해서 실행한다. micro-op은 RISC 스타일로 명령어 파이프라인에서 빠르게 실행된다.
✅ RISC(Reduced Instruction Set Computer)
In electronics and computer science, a reduced instruction set computer (RISC) is a computer architecture designed to simplify the individual instructions given to the computer to accomplish tasks.
출처: https://en.wikipedia.org/wiki/Reduced_instruction_set_computer
ex. ARM, MIPS, RISC-V
RISC는 단순하고 빠르게 실행할 수 있는 명령어 집합을 기반으로 설계된 컴퓨터를 의미한다. 파이프라이닝 최적화와 명령어 실행의 효율성을 극대화하는 것을 목표로 설계되었다. 보통 하나의 명령어가 4byte 고정길이기 때문에 각 명령어를 실행하는 시간이 일정하기 때문에 파이프라이닝에 매우 효율적이다.
✅ CISC vs RISC 요약
| 구분 | CISC | RISC |
|---|---|---|
| 명령어 집합 | 복잡하고 다양한 명령어를 제공 | 단순하고 제한된 명령어 집합 |
| 명령어 실행 시간 | 여러 클럭 사이클에 걸쳐 실행 | 한 클럭 사이클에 대부분 실행 |
| 명령어 길이 | 가변적 (다양한 길이의 명령어 존재) | 고정적 (일반적으로 4byte) |
| 메모리 접근 | 명령어 자체에서 메모리 접근 가능 | load/store 명령어만 메모리 접근 가능 |
| 레지스터 사용 | 메모리 접근 빈도가 높음 | 대부분 연산이 레지스터 내에서 이루어짐 |
| decode 복잡도 | 복잡한 decode 필요 | 단순한 decode로 빠르게 실행 |
| 프로그램 크기 | 고수준의 언어 한 줄을 적은 수의 명령어로 표현 가능 -> 프로그램 크기가 작은 편 | 고수준의 언어 한 줄을 많은 수의 명령어로 표현해야 함 -> 프로그램 크기가 큰 편 |
❓ DRAM, SRAM에 대해 설명해 주세요.
RAM의 종류에는 크게 DRAM, SRAM이 있다. 일반적으로 가정에서 사용하는 컴퓨터에 들어가는 RAM은 DRAM의 일종인 SDRAM(Synchronous Dynamic RAM)이다.
ex. Samsung DDR 시리즈
✅ DRAM vs SRAM 요약
| 구분 | DRAM | SRAM |
|---|---|---|
| 재충전(Refresh) | 시간이 지나면 방전되어 저장된 데이터가 점차 사라지므로, 재충전이 필요함 | 전원이 유지되는 한 데이터가 사라지지 않으므로, 재충전이 필요하지 않음 |
| 속도 | 느림 (50~70ns) | 빠름 (10ns 이하) |
| 가격 | 비교적 저렴함 | 비쌈 |
| 집적도 | 높음 -> 대용량으로 설계하기 좋음 | 낮음 |
| 소비 전력 | 낮음 | 높음 |
| 사용 용도 | RAM | CPU 캐시 (L1, L2, L3), 레지스터 |
❓ 물리 주소와 논리 주소에 대해 설명해 주세요.
- 물리 주소(Physical Address): 실제 RAM 상의 주소를 의미한다.
- 논리 주소(Logical Address = Virtual Address): 각 실행 중인 프로그램이 인식하는 논리적인 주소를 의미한다. 이 논리 주소가 실제 RAM의 어느 주소에 대응되는지는 운영 체제가 해석하고 관리한다.
CPU가 RAM에 적재된 데이터와 상호작용하기 위해서는 결국 논리 주소가 아닌 물리 주소를 알아야 하는데, 논리 주소로부터 물리 주소로 변환하는 과정은 MMU(Memory Management Unit)라는 하드웨어에 의해 수행된다.
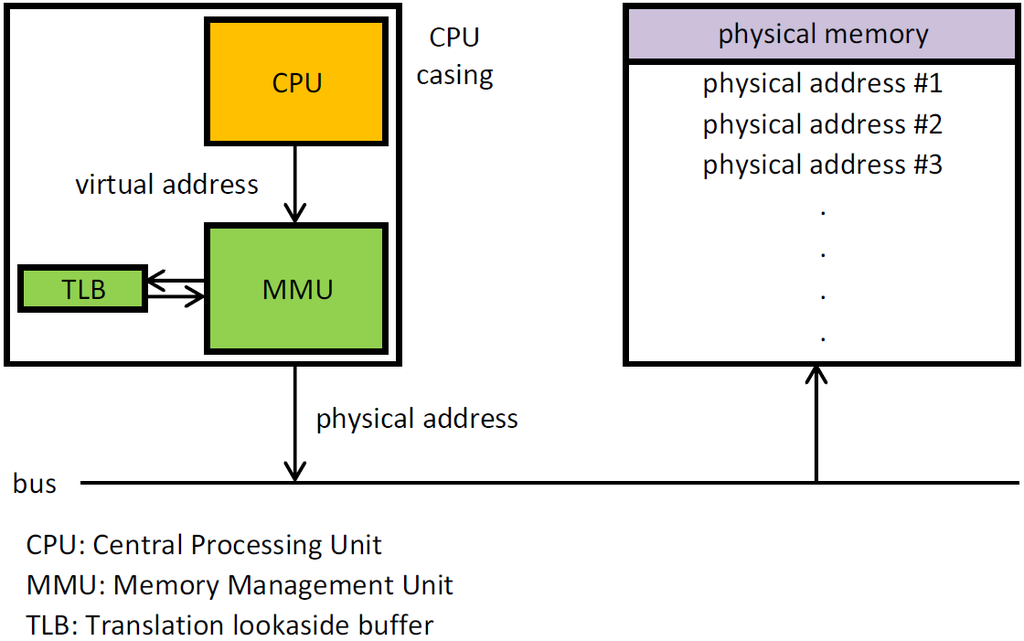
출처: https://en.wikipedia.org/wiki/Memory_management_unit
구체적인 논리 주소 -> 물리 주소 변환 과정은 추후 운영 체제의 페이지, 프레임 개념이 나오는 챕터(14챕터) 때 살펴보자.
❓ 캐시 메모리에 대해 설명해 주세요.
CPU는 프로그램을 실행하는 과정에서 RAM에 빈번하게 접근해야 한다. 보통 CPU가 메모리에 접근하는 데 걸리는 시간은 CPU의 연산 속도보다 느리다. 이를 보완하기 위한 저장 장치가 캐시 메모리다.
✅ Memory Architecture
모든 사용자는 접근이 빠르고 용량이 큰 저장 장치를 원하겠지만, "접근이 빠른 것"과 "용량이 큰 것"은 양립할 수 없다. 접근이 빠른 집적 회로는 열 설계, 전력 소모 등의 제약으로 더 고급 공정 기술이 필요하기 때문에 비용이 매우 비싸다.
우리가 알고 있는 저장 장치들을 종류에 따라 피라미드로 분류하면 아래의 그림과 같다.
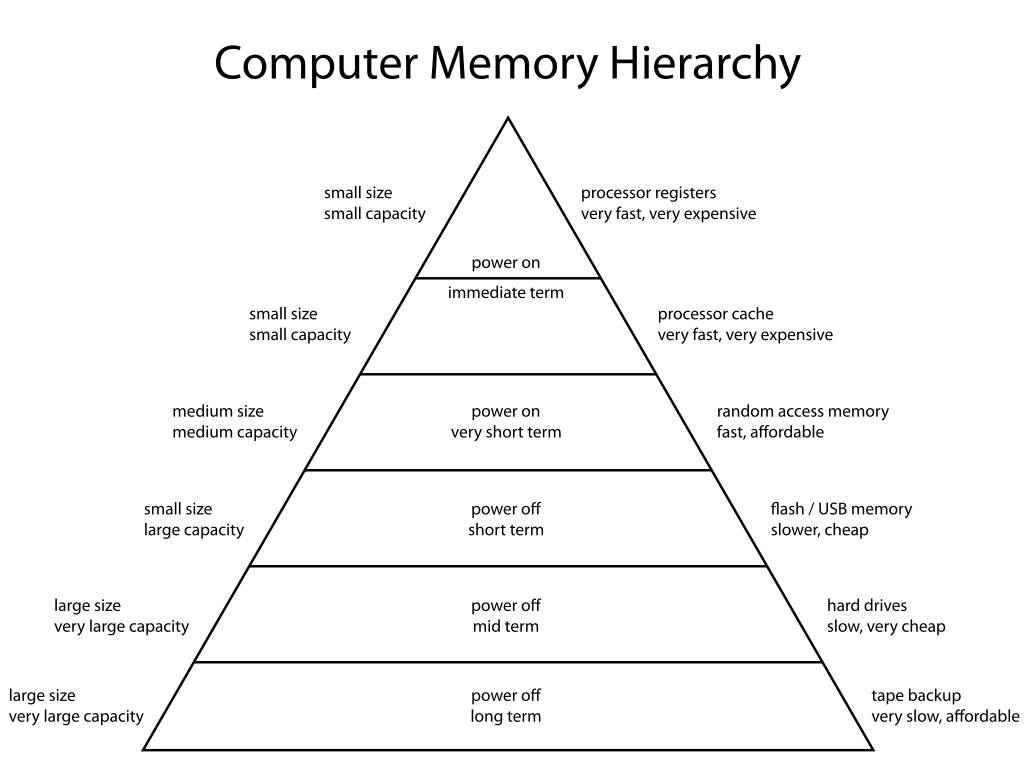
출처: https://en.wikipedia.org/wiki/Memory_hierarchy
일반적으로 "접근이 빠른 것"은 CPU와 물리적 거리가 가까운 것을 의미한다.
레지스터가 CPU와 가장 가까이 위치해 있으며 가장 접근이 빠르고, 용량이 가장 작다.
보조기억장치(ex. 하드디스크)가 가장 접근이 느리고, 용량이 가장 크다.
❓ 캐시 히트와 캐시 미스에 대해 설명해 주세요.
캐시 메모리는 RAM보다 용량이 작기 때문에 RAM의 모든 내용을 복사해올 수 없으므로 효율적으로 사용해야 한다. CPU가 캐시 메모리에 저장된 데이터를 사용하는 경우를 캐시 히트라고 부르고, CPU가 RAM으로부터 직접 데이터를 갖져와야 하는 경우를 캐시 미스라고 부른다.
즉, CPU에서 메모리의 데이터에 접근하는 행위는 모두 캐시 히트와 캐시 미스로 나누어 분류할 수 있고, 캐시 히트할 확률이 높도록 설계해야 한다. 캐시 히트의 비율을 캐시 적중률(cache hit ratio)라고 부른다.
캐시 적중률 = 캐시 히트 횟수 / (캐시 히트 횟수 + 캐시 미스 횟수)📌 참조 지역성의 원리(principle of locality)
- 공간 지역성: 최근 접근했던 메모리 주소 근처가 자주 참조된다.
- 시간 지역성: 최근에 사용되었던 주소가 자주 참조된다. 특정 변수, 상수에 접근하는 경우가 그렇다.
- 순차 지역성: 프로그램 실행 흐름에 따라 순차적으로 참조될 확률이 높다. CPU가 실행할 다음 명령어를 찾아 PC 레지스터에 넣는 과정에서 메모리의 Text 영역에서 순차적으로 접근할 가능성이 높다.
Reference
- 혼자 공부하는 컴퓨터 구조+운영체제, 강민철
- 하이퍼스레딩
