
Shopify 블로그 중 write-fast-code-ruby-rails를 보면서 궁금해진 부분이 있다. 루비에서 bang method들은 일반적으로
- 예외를 발생시키거나 (
ActiveRecord#find랑find!처럼) - 원본을 파괴하는 메서드이다.
1의 경우 성능 향상이 없는 건 자명해보이고, 2의 경우에도 메모리 효율은 있겠지만 성능 차이가 클까? 라는 생각이 들었다. 그래서 정말 그럴지 벤치마크를 돌려보기로 했다.

벤치마크 코드
TIMES = 100_000
bench = Benchmark.bm do |x|
map = x.report("map") do
TIMES.times.map do |_|
xs = (0...1000).to_a
xs.map { |i| i + 1 }
end
end
map_bang = x.report("map!") do
TIMES.times.map do |_|
xs = (0...1000).to_a
xs.map! { |i| i + 1 }
end
end
end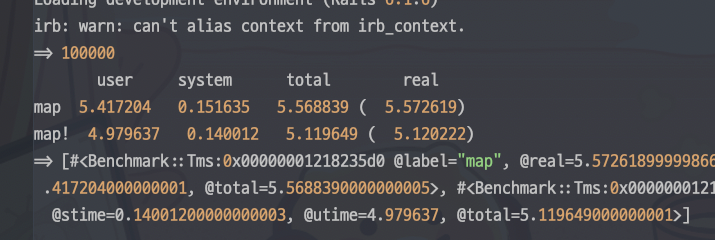
100,000회 기준 벤치마크 (속도)
Array#map!이 Array#map보다 10% 성능 향상이 있는 걸 볼 수 있다.
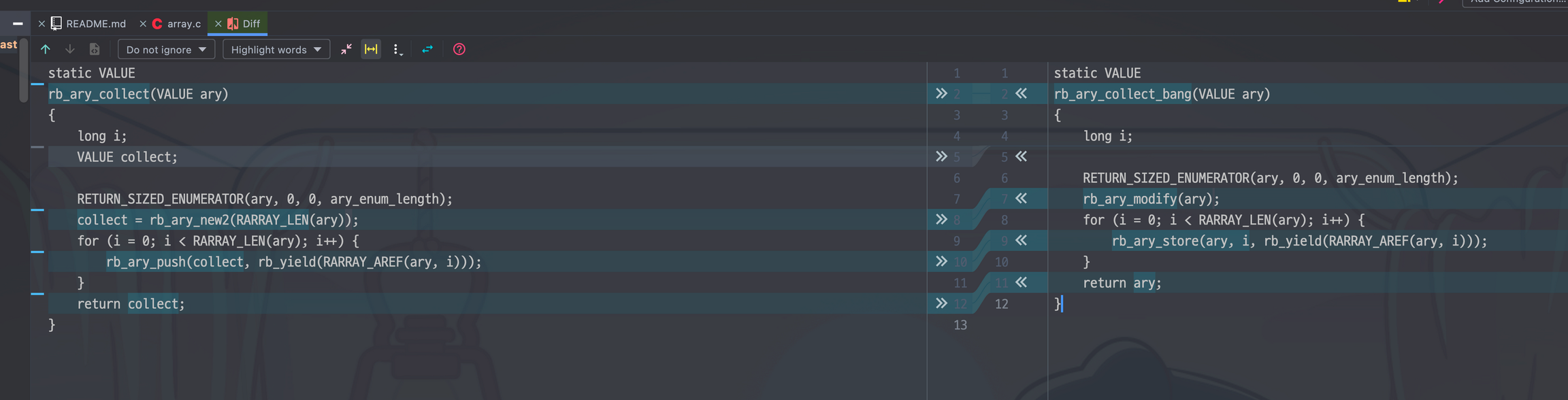
https://github.com/ruby/ruby/blob/e199ae3edcead0271c6da3410eb02acd927739b7/array.c#L3839-L3850
MRI의 구현을 까보면 push 대신 store를 사용하도록 구현되어 있다.(좌측이 map, 우측이 map!)
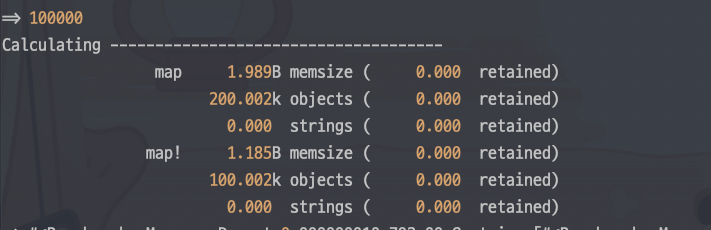
메모리 효율은 다음과 같다.
다시 현실로
그런데, 현실에서는 얼마나 차이가날까? 이런 저수준의 최적화가 현실적인 예제에서도 쓸모가 있을까?
ActiveRecord까지 갈 것도 없이 좀 더 간단한 예시를 위해 다음과 같은 벤치마크를 준비했다.
hashids = Hashids.new "this is my salt"
def encode(hashid)
hashids.encode(hashid)
end
TIMES = 100
bench = Benchmark.memory do |x|
map = x.report("map") do
TIMES.times.map do |_|
xs = (0...100).to_a
xs.map { |i| encode(i) }
end
end
map_bang = x.report("map!") do
TIMES.times.map do |_|
xs = (0...100).to_a
xs.map! { |i| encode(i) }
end
end
end- 참고용
encode의 내부 구현
def encode(*numbers)
numbers.flatten! if numbers.length == 1 numbers.map! { |n| Integer(n) } # raises if conversion fails return '' if numbers.empty? || numbers.any? { |n| n < 0 }
internal_encode(numbers)
end
def internal_encode(numbers)
ret = ""
alphabet = @alphabet
length = numbers.length
hash_int = 0
length.times do |i|
hash_int += (numbers[i] % (i + 100))
end
lottery = ret = alphabet[hash_int % alphabet.length]
length.times do |i|
num = numbers[i]
buf = lottery + salt + alphabet
alphabet = consistent_shuffle(alphabet, buf[0, alphabet.length])
last = hash(num, alphabet)
ret += last
if (i + 1) < length
num %= (last.ord + i)
ret += seps[num % seps.length]
end
end
if ret.length < min_hash_length
ret = guards[(hash_int + ret[0].ord) % guards.length] + ret
if ret.length < min_hash_length
ret += guards[(hash_int + ret[2].ord) % guards.length]
end
end
half_length = alphabet.length.div(2)
while(ret.length < min_hash_length)
alphabet = consistent_shuffle(alphabet, alphabet)
ret = alphabet[half_length .. -1] + ret + alphabet[0, half_length]
excess = ret.length - min_hash_length
ret = ret[excess / 2, min_hash_length] if excess > 0
end
ret
end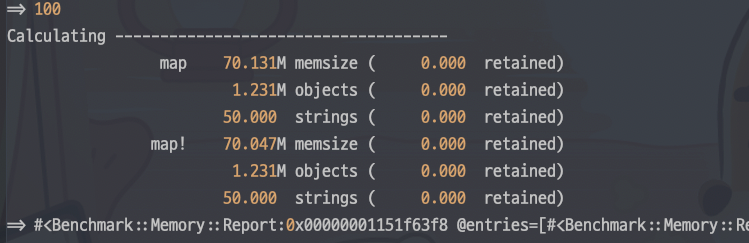
별 차이가 없는 걸 확인할 수 있다. 물론 차이는 있지만, 극히 미미하다.
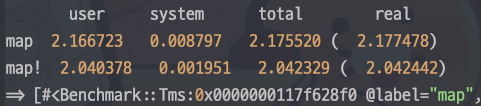
성능의 경우 1,000회 기준으로 돌렸다. 약 5% 정도의 성능 향상이 있었다. 오히려 메모리 할당보다 성능 측면에서 이득을 확인할 수 있었다.
Best-Practice?
If used improperly, dangerous methods can lead to unwanted side effects in your code.
A best practice to follow is to avoid mutating global state while leveraging mutation on local state.Shopify의 언급처럼, 결국 인자로 넘어온 값처럼 외부에서 제공된 객체에 대한 self-mutating 하는 메소드를 안 쓰려고 하고 메소드 내에서 생성하는 객체들은 self-mutating을 하는 식으로 쓰는게 좋을 거 같다.
