
문제

나의 풀이
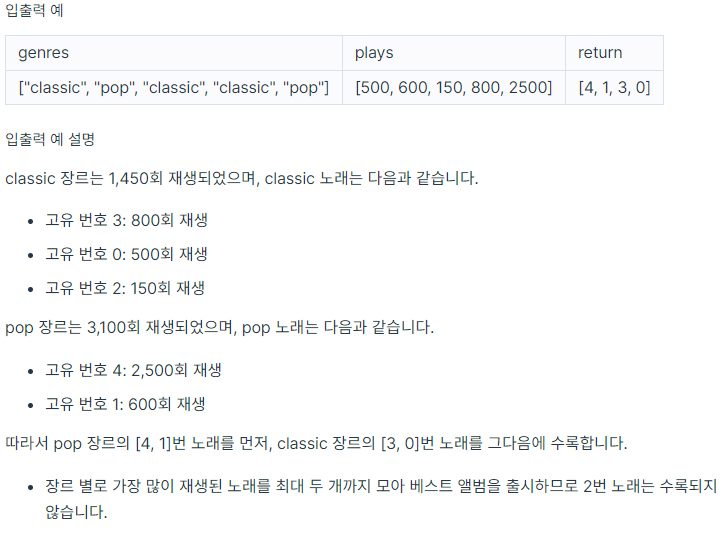
- 속한 노래가 많이 재생된 장르를 먼저 수록합니다.
- 장르 내에서 많이 재생된 노래를 먼저 수록합니다.
- 장르 내에서 재생 횟수가 같은 노래 중에서는 고유 번호가 낮은 노래를 먼저 수록합니다.
def solution(genres, plays):
answer = list()
songs = dict()
for genre in set(genres):
songs[genre] = list()
for i in range(len(genres)):
songs[genres[i]].append(plays[i])
genres_sum = list()
for genre in songs.keys():
genres_sum.append((genre, sum(songs[genre])))
genres_sum.sort(reverse=True, key=lambda x : x[1])
for genre_sum in genres_sum:
genre = genre_sum[0]
play_list = sorted(songs[genre])
idx = plays.index(play_list.pop())
answer.append(idx)
plays[idx] = -1
if len(play_list) == 0:
continue
idx = plays.index(play_list.pop())
answer.append(idx)
return answersongs에 genres와 plays에 대한 정보를 딕셔너리 형태로 담았다. 예시는 아래와 같다.
songs = {
"classic" : [500, 150, 800],
"pop" : [600, 2500]
}genres_sum에는 튜플 (genre, 재생된 횟수 총합)의 리스트 형태로 담았다.
재생된 횟수 총합을 기준으로 정렬하여 노래 수록의 1번 기준을 따르도록 했다.
마지막 for문을 통해 2번과 3번 기준을 따르도록 했다.
재생된 횟수 리스트를 오름차순 정렬 후 pop()함으로써 최대 두 개의 앨범을 뽑았다.
두 앨범의 재생 횟수가 동일한 경우 같은 index를 출력할 수 있기에 뽑힌 후 -1로 값을 수정했다.
또한, 장르에 속한 곡이 한 곡인 경우를 고려해 중간 과정에 if문을 삽입하였다.
다른 풀이
def solution(genres, plays):
answer = []
dic1 = {}
dic2 = {}
for i, (g, p) in enumerate(zip(genres, plays)):
if g not in dic1:
dic1[g] = [(i, p)]
else:
dic1[g].append((i, p))
if g not in dic2:
dic2[g] = p
else:
dic2[g] += p
for (k, v) in sorted(dic2.items(), key=lambda x:x[1], reverse=True):
for (i, p) in sorted(dic1[k], key=lambda x:x[1], reverse=True)[:2]:
answer.append(i)
return answer- genres와 plays는 같은 인덱스를 접근하므로
zip()사용 - 인덱스도 함께 필요하므로
enumerate()사용 - 하나의 for문으로 나의 songs와 genres_sum 을 함께 만듦
- genre와 sum에 대해 1차 정렬, 그 안에서 plays 순서대로 정렬
깔끔하고 가독성도 좋은 코드... 짱이다! 나도 꾸준히 연습해야지.
얻어가기
모두 아는 문법이었지만 알고리즘의 차이.
코드를 최적화하는 연습을 하자.

성장 중독 | 서버, 데이터, 정보 보안을 공부합니다.