A brief history of LLaMA models
원글 링크 : A brief history of LLaMA models
LLaMA 기본 모델은 2023년 2월에 출시되었습니다. 이제 fine-tuned된 새로운 LLaMA 모델이 몇 가지 출시되었습니다.
말 그대로 짧은 역사이지만 확실히 많은 일이 일어났습니다. 그럼 간략하게 살펴보겠습니다.
모델의 발전과 툴에 대해 간략히 살펴보겠습니다.
- LLaMA base model
- Alpaca model
- Vicuna model
- Koala model
- GPT4-x-Alpaca model
- WizardLM model
- OpenAssistant model
- Software to run LLaMA models locally
아래는 모델에 대한 개요입니다.
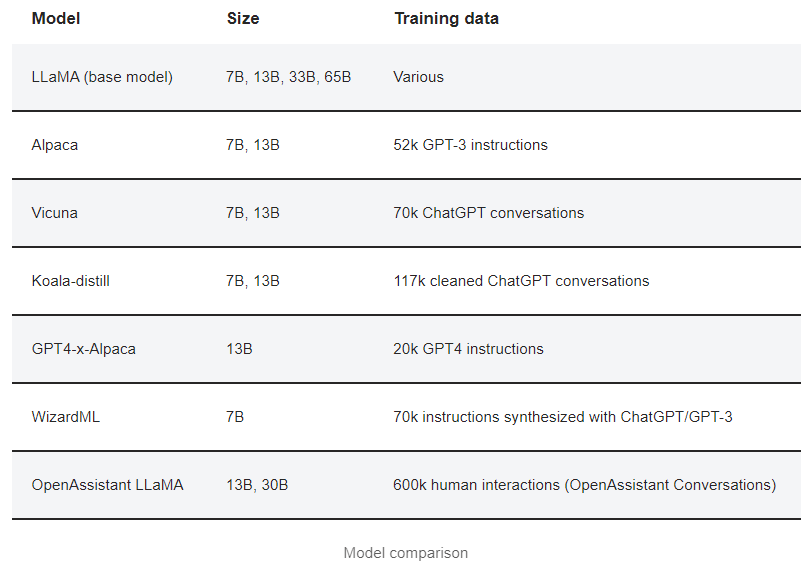
LLaMA base model
- Paper: LLaMA: Open and Efficient Foundation Language Models
- Release blog post
- Release date: February 2023
LLaMA(대규모 언어 모델 Meta AI)는 Meta(Facebook)에서 출시한 언어 모델입니다. OpenAI의 GPT 모델에 대한 Meta의 답변입니다.
GPT와 마찬가지로 LLaMA는 추가 미세 조정에 적합한 범용 기본 모델로 고안되었습니다.
LLaMA 모델에는 다음과 같은 종류가 있습니다.
Accessibility
GPT와 달리 LLaMA는 오픈 소스 모델입니다. 로컬에서 다운로드하여 학습하고 실행할 수 있습니다. 공식적으로 모델 가중치를 요청하려면 Google Form을 사용해야 합니다.
그러나 이 모델은 출시 후 한 달도 채 되지 않은 2023년 3월에 토렌트에서 유출되었습니다.
Objective
LLaMA의 목표는 주어진 추론 예산에 가장 적합한 모델을 구축하는 것입니다(예: 10GB 미만의 VRAM을 사용하는 NVIDIA 3090에서 실행).
Model architecture
LLaMA는 GPT와 유사한 transformer model이지만 다음과 같은 수정 사항이 있습니다.
- 각 transformer sub-layer의 입력을 정규화하여 훈련 안정성을 개선합니다.
- 성능을 개선하기 위해 ReLU 대신 SwiGLU를 사용합니다.
- absolute positioning 대신 rotary embedding을 사용하여 성능을 개선합니다.
아래 표에는 모델 파라미터가 요약되어 있습니다.
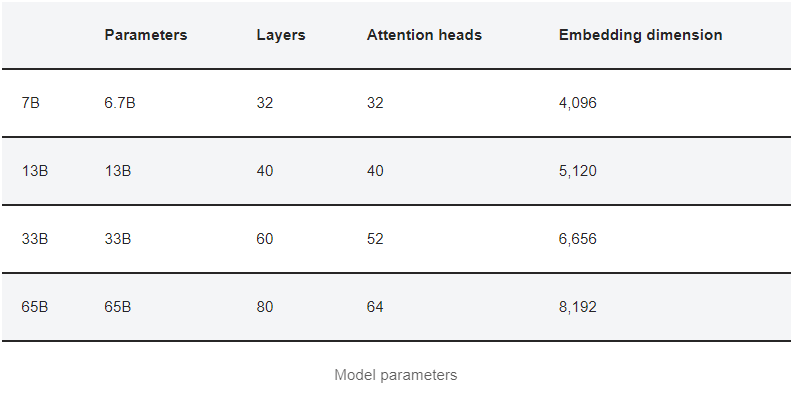
참고로 GPT-3에는 175B 매개변수가 있습니다. LLaMA 모델은 작습니다.
Training
The pre-training data used in LLaMA are
- English CommonCrawl(67%): 영어가 아닌 텍스트와 중복된 콘텐츠를 제거했습니다. Wikipedia에서 참조로 사용된 페이지만 포함합니다.
- C4 (15%): 커먼크롤의 클린 버전. 동일한 필터가 적용되었습니다.
- Github(4.5%): Google BigQuery에서 사용할 수 있는 공개 GitHub 데이터 세트입니다.
- Wikipedia(4.5%): 2022년 6월부터 8월까지 20개 언어를 대상으로 합니다.
- Gutenberg 및 Books3(4.5%): 둘 다 도서 데이터 세트입니다.
- ArXiv(45%): 과학 데이터.
- StackExchange(2%): 과학 및 엔지니어링 주제를 다루는 고품질 Q&A입니다.
The tokenizer is with byte-pair encoding using SentencePiece.
학습 데이터에는 1.4T 토큰이 있습니다.
Performance
상식 추론, 독해력, 코드 생성 등의 과제를 통해 모델을 평가했습니다.
성능 요약:
- 클수록 좋습니다: 모델이 클수록 대부분의 작업에서 더 나은 성능을 발휘합니다.
- 프롬프트에 예제가 많을수록 좋습니다: Natural Questions 과제에서 LLaMA 7B 모델에 5개의 예제를 제공하는 것은 65B 모델에 예제를 제공하지 않는 것과 거의 비슷합니다.
- 더 작은 성능의 모델. LLaMA 13B의 성능은 10배 더 작지만 GPT-3와 비슷합니다. (13B 대 175B 매개변수)
- LLaMA는 정량적 추론, 특히 더 작은 7B 및 13B 모델에서 그다지 능숙하지 않습니다.
- LLaMA는 ChatGPT와 같은 명령어 추종에 맞게 튜닝되지 않았습니다. 그러나 65B 모델은 기본 지침을 따를 수 있습니다. Alpaca를 기다리겠습니다(오래 걸리지 않을 것입니다).
Model size comparison
더 큰 LLaMA 모델을 사용하면 얼마나 많은 이득을 얻을 수 있을까요? 다음 표는 다양한 카테고리의 작업 성과를 요약한 것입니다. 이는 선형 척도를 가정하여 연구 문서에 제공된 점수를 기반으로 계산한 것입니다.
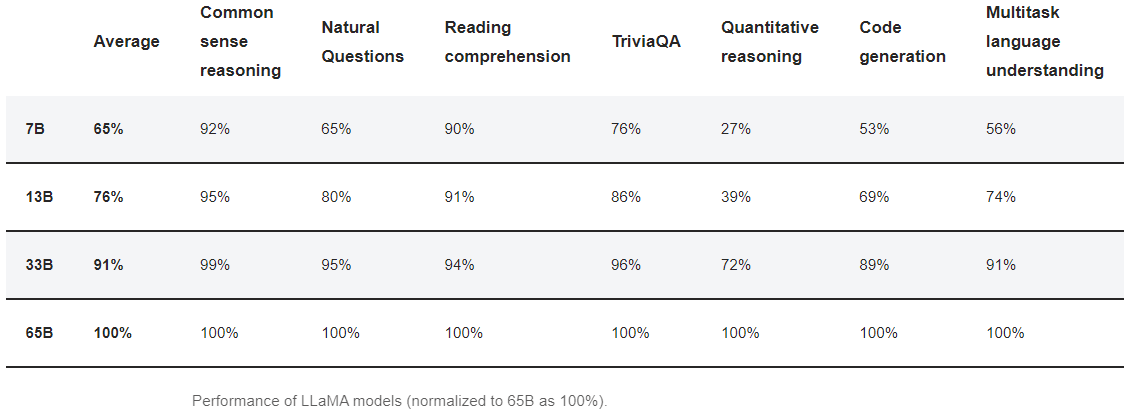
더 큰 모델을 사용할 가치가 있나요? 7B에서 65B 모델로 전환하면 일반적으로 약 50%의 성능 향상을 기대할 수 있습니다.
하지만 이는 모델을 사용하는 용도에 따라 달라집니다. 상식 추론 및 독해 작업에서는 약간의 이득만 볼 수 있습니다. 코드 생성 및 기술 독해 작업에서는 큰 이득을 볼 수 있습니다.
Summary for LLaMA
이 연구의 핵심 메시지는 충분한 데이터로 훈련하면 작은 모델도 좋은 성능을 낼 수 있다는 것입니다. 이는 PC에서 '로컬 ChatGPT'를 실행할 수 있는 가능성을 열어줍니다.
하지만 LLaMA 기본 모델은 지침을 따르도록 훈련되지 않았습니다. 이는 추후 개발을 위해 저장됩니다.
요약하자면, LLaMA는 추가 미세 조정을 위한 기본 모델로 설계되었습니다. 다음과 같은 장점이 있습니다.
- 작은 크기
- 뛰어난 성능 - 광범위한 훈련 덕분에 가능
- 오픈 소스
Alpaca model
Alpaca는 미세 조정된 LLaMA 모델로, 모델 아키텍처는 동일하지만 가중치가 약간 다릅니다. Alpaca는 LLaMA 모델의 명령 추종 기능 부족을 해결하기 위한 것입니다.
ChatGPT처럼 작동하며 대화와 지시를 따를 수 있습니다.
7B 및 13B Alpaca 모델을 사용할 수 있습니다.
Training
ChatGPT와 같은 지시를 따르도록 훈련되었습니다.
저자들은 먼저 OpenAI의 GPT-3을 사용하여 학습 데이터를 생성한 다음, Self-Instruct 파이프라인을 사용하여 52,000개의 명령어를 따르는 대화 데이터로 변환했습니다.

그 결과, Alpaca는 ChatGPT처럼 대화에 응답하도록 미세 조정되었습니다.
Performance
일부 저자들이 실시한 instruction-following 능력에 대한 블라인드 평가에서 Alpaca 7B와 GPT-3(특히text-davinci-003은 지시에 따라 훈련받았습니다)의 반응은 거의 동일하게 나타났습니다.
Alpaca는 GPT-3보다 26배나 작기 때문에 이는 놀라운 결과입니다.
물론 이것은 성능의 좁은 측면일 뿐입니다. 이 연구에서 테스트하지 않은 코드 생성 및 과학 지식과 같은 다른 영역에서 Alpaca가 GPT-3와 동등한 성능을 보인다는 의미는 아닙니다.
Summary
Alpaca는 LLaMA 모델을 fine-tuning하는 좋은 첫 단계입니다. 다음 섹션에서 살펴보겠지만, 비슷한 fine-tuning 작업인 Vicuna보다 성능이 뛰어납니다.
Vicuna model
- Vicuna 모델 페이지
- Mac 설치 가이드.
Vicuna는 ShareGPT.com에서 수집한 사용자 공유 대화에 대해 LLaMA 기본 모델을 fine-tuning하여 학습합니다. 따라서 기본적으로 ChatGPT 대화로 fine-tuning됩니다.
두 가지 크기로 제공됩니다: 7B와 13B.
Training
이 모델은 UC 버클리, CMU, 스탠포드, UC 샌디에이고의 학계 팀이 fine-tuned했습니다.
이 모델은 사용자가 제공한 ChatGPT 대화로 학습되었습니다. 따라서 ChatGPT를 모방한 동작을 기대할 수 있습니다. 정확히 말하자면, 사용자가 ShareGPT.com에서 공유한 70,000개의 ChatGPT 대화로 훈련되었습니다.
70억 모델을 훈련하는 데는 140달러, 130억 모델을 훈련하는 데는 300달러의 비용이 들었습니다.
Performance
Vicuna는 얼마나 좋은가요? 웹사이트에 따르면 출력 품질(GPT-4...로 판단)은 ChatGPT의 약 90%로 로컬에서 실행할 수 있는 최고의 언어 모델이라고 합니다.

저자들은 모델의 성능을 평가하기 위해 흥미로운 방법을 사용했습니다: 바로 GPT-4를 평가자로 사용하는 것이죠. GPT-4에게 몇 가지 까다로운 질문을 생성하도록 요청하고 Vicuna와 다른 최고의 언어 모델들이 이에 답하도록 했습니다.
그런 다음 GPT-4에게 유용성, 정확성 등 다양한 측면에서 답변의 품질을 평가하도록 요청했습니다.
다음은 LLaMA, Alpaca, Bard, ChatGPT를 비교한 결과입니다. GPT-4의 눈에 비친 Vicuna는 ChatGPT와 거의 비슷한 수준으로 LLaMA와 Alpaca를 큰 차이로 앞섰습니다.

Summary
Vicuna 모델은 로컬에서 실행할 수 있는 최고의 LLaMA 모델 중 하나로 간주됩니다. 하지만 앞으로 몇 주 안에 상황이 바뀐다고 해도 놀라지 않을 것입니다.
Koala
- Koala model page
- Release date: April 2023
Koala는 UC Berkeley의 학술 팀이 공개적으로 사용 가능한 대화 데이터로 미세 조정한 LLaMA 7B 및 13B 모델입니다.
Training
학습 데이터에는 여러 데이터 세트의 필터링된 데이터가 포함됩니다.
- ShareGPT – 30k
- Human ChatGPT Comparison Corpus – 87k
- Open Instruction Generalist – 30k
- Stanford Alpaca (Training dataset for Alpaca) – 52k
- Anthropic HH – 50k
- OpenAI WebGPT – 20k
- OpenAI summarization – 93k
두 가지 모델을 학습시켰습니다.
1. Koala-All: 모든 데이터 세트 사용
2. Koala-Distill: 처음 두 데이터 세트(즉, ChatGPT에서 추출한 데이터)를 사용했습니다.
Performance
평가자들은 Koala-All과 Koala-Distill의 성능을 Alpaca 및 ChatGPT와 비교하여 평가했습니다. Amazon Mechanical Turk의 평가자 100명이 동일한 프롬프트에서 두 모델의 응답을 평가했습니다.
결과는 다음과 같습니다.
- Koala-All은 알파카보다는 낫지만 ChatGPT보다는 나쁩니다.
- Koala-Distill은 Koala-All보다 약간 낫습니다. - 이는 Koala-All이 더 많은 데이터로 fine-tuned되었기 때문에 놀라운 결과입니다.
Summary
결론은 데이터의 양보다 질이 더 중요하다는 것입니다. ChatGPT 데이터로만 미세 조정된 Koala-Distll은 추가 데이터로 학습된 Koala-All보다 성능이 뛰어납니다.
앞으로는 LLaMA 모델을 미세 조정하기 위해 고품질 데이터를 찾거나 생성하는 것이 중요해질 것입니다.
GPT4-x-Alpaca
- HuggingFace page
- Release date: April 2023
GPT4-x-Alpaca는 GPT4 대화 모음인 GPTeacher로 미세 조정된 LLaMA 13B 모델입니다. 이 모델의 훈련과 성능에 대한 정보는 많지 않습니다.
다음은 이 모델을 평가하기 위한 커뮤니티의 노력입니다.
WizardLM
- WizardLM Paper
- WizardLM GitHub Page
- Released date: April 2023.
WizardLM은 fine-tuned된 7B LLaMA 모델입니다. 이 모델은 다양한 난이도를 가진 대량의 명령어 후속 대화로 fine-tuned되었습니다. 이 모델의 새로운 점은 LLM을 사용하여 학습 데이터를 자동으로 생성한다는 것입니다.
Training
WizardLM 모델은 Evol-Instruct라는 새로운 방법을 사용하여 7만 개의 computer-generated 명령어로 학습되었습니다. 이 방법은 다양한 수준의 난이도를 가진 명령어를 생성합니다.
Evol-Instruct는 다음 다섯 가지 연산으로 프롬프트를 확장합니다.
- 제약 조건 추가
- 심화
- 구체화
- 추론 단계 늘리기
- 입력 복잡화
이러한 연산을 초기 명령에 순차적으로 적용하여 더 복잡하게 만들었습니다.
응답은 LLM에 의해 생성되었습니다.
Performance
저자들은 Alpaca 7B, Vicuna 7B, ChatGPT와 WizardLM의 성능을 비교했습니다. 10명을 모집하여 5가지 측면에서 WizardLM과 다른 모델의 응답을 맹목적으로 평가했습니다: 관련성, 지식, 추론, 계산, 정확성입니다.
저자들은 다음과 같은 결론을 내렸습니다:
- Evol-Instruct에 의해 생성된 명령은 ShareGPT(Vicuna에서 사용)보다 우수합니다.
- WizardLM은 Alpca와 Vicuna보다 성능이 훨씬 뛰어납니다.
- ChatGPT가 전반적으로 더 우수하지만, 난이도가 높은 질문에서는 WizardLM이 더 뛰어납니다.

커뮤니티에서는 일반적으로 WizardLM이 현재 7B 모델에 가장 적합한 최신 기술이라는 데 동의합니다.
OpenAssistant
- OpenAssistant Project page
- OpenAssistant LLaMA 30B HuggingFace page
- GitHub page
- Launch video
- Dataset Paper
- Demo
- Release date: April 2023
OpenAssistant는 누구나 무료로 사용할 수 있는 AI 챗봇을 개발하기 위한 오픈 소스 프로젝트입니다. 훈련 데이터 세트인 OpenAssistant Conversations에는 다양한 모델을 훈련하기 위한 다양한 주제에 대한 60만 개 이상의 상호 작용이 포함되어 있습니다.
인스트럭션이 튜닝된 LLaMA 13B 및 30B 모델과 동일한 데이터셋으로 훈련된 다른 모델도 함께 공개했습니다. 아직 웹에는 많은 성능 정보가 제공되지 않습니다.
Software tools
소프트웨어 엔지니어링 측면의 발전도 놀랍습니다. 현재 PC에서 LLaMA 모델을 실행하는 두 가지 주요 방법은 다음과 같습니다.
- llama.cpp (for Mac or CPU only)
- Oobabooga text-generation-webui
llama.cpp
llama.cpp는 처음부터 C++로 작성되었습니다. 목표는 맥북에서 LLaMA 모델을 실행할 수 있도록 하는 것입니다. Apple Silicon M1/M2에 최적화되어 있습니다.
4비트 양자화를 지원하여 LLaMA 모델에 필요한 리소스를 줄입니다. 모델을 정량화하면 품질이 약간 저하되는 대신 스토리지 및 RAM 사용량이 줄어듭니다.
7B 모델은 원래 로드하는 데 13GB의 디스크 공간과 RAM이 필요합니다. 4비트 양자화 후에는 약 4GB만 소요됩니다.
기본 Apple Silicon 지원으로 인해 llama.cpp는 Mac M1/M2에서 LLaMA 모델을 실행하는 데 탁월한 선택입니다.
하지만 텍스트 터미널에서의 사용만 지원합니다. 기술적으로는 텍스트 생성 웹ui를 llama.cpp의 GUI로 사용할 수 있습니다. 하지만 이 글을 쓰는 현재로서는 훨씬 느릴 수 있습니다.
Mac의 설치 가이드를 참조하세요.
text-generation-webui
Oobabooga text-generation-webui is a GUI for using LLaMA models. It can be run on Windows, Linux and Mac.

Windows 또는 Linux에 GPU 카드가 있는 경우 이 GUI를 사용해야 합니다.
llama.cpp와 마찬가지로 모델 크기 축소를 위해 4비트 양자화(파일 형식은 다르지만)를 지원합니다.
