What is Confusion Matrix and Advacd Classification Metrics?
영어가 짧아서 번역기 돌린거 저장해놓은 페이지
원본페이지
What is Confusion Matrix and Advacd Classification Metrics?
Confusion Matrix(오차행렬) 및 Advacd Classification Metrics?
데이터 준비와 모델 교육 후, 앞서 제가 Simple Picture of Machine Learning Modelling Process. 에서 언급한 모델 평가 단계가 있습니다.
일단 모델이 개발되면, 다음 단계는 일부 평가 지표를 사용하여 개발된 모델의 성능을 계산하는 것입니다. 이 기사에서는 분류 지표가 많지만 Confusion Matrix에 대해 알아봅니다.
주로 아래 사항에 초점을 맞추고 있습니다.
- Confusion Matrix(오차 행렬)이란 무엇인가?
- Confusion Matrix(오차 행렬)의 출력 4개
- Advacd Classification Metrics
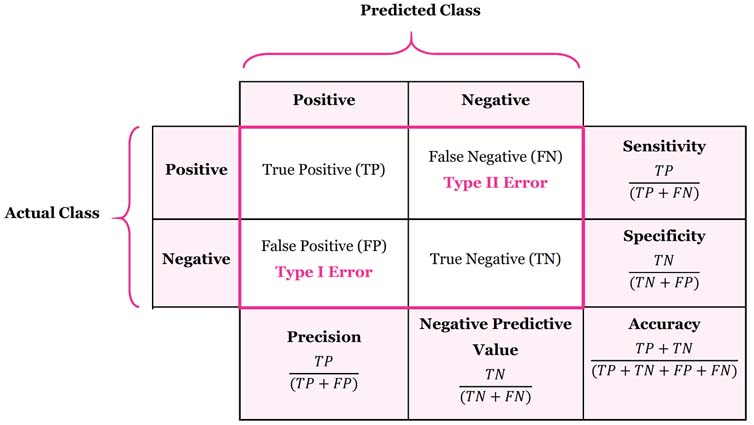
Confusion Matrix는 분류기의 성능을 결정하는 도구입니다. 여기에는 실제 및 예측 분류에 대한 정보가 포함되어 있습니다. 아래 표는 스팸 및 비스팸 분류자의 Confusion Matrix를 보여줍니다.

Confusion Matrix에서 4개의 출력을 이해합시다.
-
True Positive (TP)(참 양성) 은 예가 positive라는 정확한 예측의 수이며, positive으로 올바르게 식별된 positive class를 의미합니다.
예: 지정된 클래스가 스팸이며 분류자가 스팸으로 올바르게 예측되었습니다. -
False Negative (FN)(거짓 음성) 은 예가 negative인 잘못된 예측의 수를 말하며, 이는 positive class가 negative로 잘못 식별되었음을 의미합니다.
예: 그러나 클래스가 스팸인 경우 분류자가 비스팸으로 잘못 예측되었습니다. -
False positive (FP)(거짓 양성) 은 예가 positive이라는 잘못된 예측의 수이며, 이는 negative class가 positive으로 잘못 식별되었음을 의미합니다.
예: 그러나 클래스가 스팸이 아닌 경우 분류자가 스팸으로 잘못 예측되었습니다. -
True Negative (TN)(참 음성) 은 예가 negative인 정확한 예측의 수를 말하며, negative의 분류가 negative으로 정확하게 식별됨을 의미합니다.
예: 지정된 클래스는 스팸이며 분류자는 negative로 올바르게 예측되었습니다.
이제 Confusion Matrix를 기반으로 한 advanced classification metrics를 살펴보겠습니다. 이러한 측정 기준은 표 2에 나와 있는 이메일 분류의 예와 함께 표 1에 수학적으로 표현되어 있습니다. 분류 문제에는 스팸 및 비스팸 클래스가 있으며 데이터 집합에는 100개의 예가 포함되어 있으며, 65개는 스팸이고 35개는 스팸이 아닙니다.
Sensitivity는 True Positive Rate or Recall이라고도 합니다. 이것은 분류기에 의해 positive으로 분류된 positive examples에 대한 척도입니다. 더 높아야 해요. 예를 들어, 모든 스팸 전자 메일 중 스팸인 전자 메일의 비율입니다.

Sensitivity = 45/(45+20) = 69.23%.
69.23%의 스팸 전자 메일이 올바르게 분류되고 모든 비스팸 전자 메일에서 제외됩니다.
Specificity은 True Negative Rate로도 알려져 있습니다. 분류기에 의해 negative으로 분류된 negative examples의 척도이다. specificity이 높아야 합니다. 예를 들어, 모든 비스팸 전자 메일 중 비스팸인 전자 메일의 비율입니다.

specificity = 30/(30+5) = 85.71% .
85.71%의 비스팸 전자 메일이 정확하게 분류되고 모든 스팸 전자 메일에서 제외됩니다.
Precision는 정확하게 분류된 positive examples와 예측된 positive examples의 총 수에 대한 비율입니다. 그것은 positive prediction에서 달성된 정확성을 보여줍니다.

Precision = 45/(45+5)= 90%
스팸으로 분류되는 사례의 90%는 실제로 스팸입니다.
Accuracy는 총 예측 수 중 정확한 수의 비율입니다.

Accuracy = (45+30)/(45+20+5+30) = 75%
예시의 75%는 분류자에 의해 올바르게 분류됩니다.
F1 score는 recall (sensitivity)과 precision의 가중 평균이다. Precision and Recall 사이의 균형을 맞추려는 경우 F1 score가 좋은 선택이 될 수 있습니다.
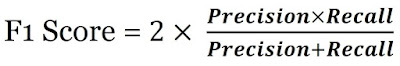
한 방정식에서 recall and precision를 계산해 recall이 낮고 precision가 높은 모델을 구분하는 문제를 해결하거나 그 반대의 문제를 해결할 수 있도록 돕는다.
이메일을 통해 제 블로그를 팔로우해 주시고, 회귀 조치에 대한 더 발전된 게시물을 계속 시청해 주십시오.
감사해요!
