
브라우저가 어떻게 동작하나요?
음... 주소창에 url을 입력하고.. 입력하면 서버에 요청하고,,, 서버에서 html js 파일을 받아서 그걸 랜더링하고...화면에 배치해서... 어쩌고,,,,음... 잘?
이렇게 얼레벌레 알고 있어서 한번 정리해보려고 합니다.
브라우저가 동작되는 방법은 이러합니다.😎
1. 주소창에 url을 입력하고 Enter를 누르면, 서버에 요청이 전송됨
2. 서버에서 해당 페이지에 존재하는 여러 자원들(text, image 등등)이 보내줌
3. 이제 브라우저(크롬,파이어폭스,엣지...)는 해당 자원이 담긴 html과 스타일이 담긴 css를 W3C 명세에 따라 해석. 이 역할을 하는 것이 '렌더링 엔진'(웹킷,게코,블링크...)
4. 렌더링 엔진은 우선 html 파싱 과정을 시작함. html 파서가 문서에 존재하는 어휘와 구문을 분석하면서 DOM 트리를 구축
다음엔 css 파싱 과정 시작. css 파서가 모든 css 정보를 스타일 구조체로 생성
5. 이 2가지를 연결시켜 렌더 트리를 만듬. 렌더 트리를 통해 문서가 시각적 요소를 포함한 형태로 구성된 상태
6. 화면에 배치를 시작하고, UI 백엔드가 노드를 돌며 형상을 그림
이때 빠른 브라우저 화면 표시를 위해 '배치와 그리는 과정'은 페이지 정보를 모두 받고 한꺼번에 진행되지 않음. 자원을 전송받으면, 기다리는 동시에 일부분 먼저 진행하고 화면에 표시함
이걸 보고 한번에 이해하신다면 음 이렇게 동작하는구나~ 하고 나가시면 됩니다..
이걸 보고 저처럼 브라우저..크롬..인데... 음...파싱...? DOM트리..?DOM은 알지... 렌더트리..? 렌더링을 해주는건가...?
🤔...?
의문을 느끼신다면 저와 같이 여러가지 개념들을 살펴보시죠..😇
브라우저?
먼저 브라우저란 무엇인가?
다들 아시다시피 우리가 흔하게 알고있는 것들 크롬, 파이어폭스, 지금은 종료되었지만 익스플로러.. 등등등 여러가지가 있죠.
웹 브라우저(영어: web browser), 인터넷 브라우저(영어: internet browser) 또는 웹 탐색기(web探索機, 문화어: 열람기)는 웹 서버에서 이동하며(navigate) 쌍방향으로 통신하고 HTML 문서나 파일을 출력하는 그래픽 사용자 인터페이스 기반의 응용 소프트웨어이다. 웹 브라우저는 대표적인 HTTP 사용자 에이전트의 하나이기도 하다.주요 웹 브라우저로는 모질라 파이어폭스, 구글 크롬, 인터넷 익스플로러/마이크로소프트 엣지, 오페라, 삼성 인터넷, 사파리가 있다.
출처 : 위키백과 웹_브라우저
즉, 인터넷 연결을 돕는 프로그램입니다.
그렇다면 기능은 무엇일까요?
브라우저의 주요 기능
-
사용자가 선택한 자원을 서버에 요청, 브라우저에 표시
-
보통 HTML 문서지만 PDF나 이미지 또는 다른 형태일 수 있다.
-
자원의 주소는
URI(Uniform Resource Identifier)에 의해 정해짐 -
브라우저는 HTML과 CSS 명세에 따라 HTML 파일을 해석해서 표시함.
이 명세는 웹 표준화 기구인W3C(World Wide Web Consortium)에서 정합니다.
=> 과거에는 브라우저들이 일부만 이 명세에 따라 구현하고 독자적인 방법으로 확장함으로써 웹 제작자가 심각한 호환성 문제를 겪었지만 최근에는 대부분의 브라우저가 표준 명세를 따릅니다.
브라우저의 요소들
브라우저의 사용자 인터페이스는 표준 명세가 없음에도 불구하고 수 년간 서로의 장점을 모방하면서 현재에 이르게 되었습니다.
- URI를 입력할 수 있는 주소 표시 줄
- 이전 버튼과 다음 버튼
- 북마크
- 새로 고침 버튼과 현재 문서의 로드를 중단할 수 있는 정지 버튼
- 홈 버튼
HTML5 명세는 주소 표시줄, 상태 표시줄, 도구 모음과 같은 일반적인 요소를 제외하고 브라우저의 필수 UI를 정의하지 않았다. 물론 파이어폭스의 다운로드 관리자와 같이 브라우저에 특화된 기능도 있다.
브라우저의 기본구조
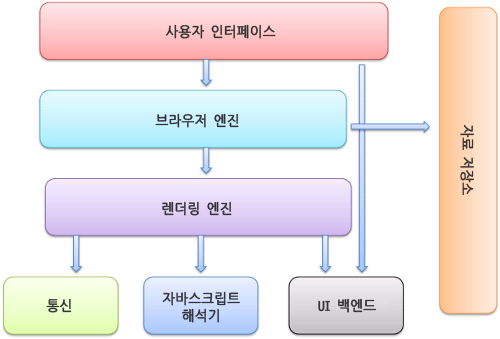
-
사용자 인터페이스 - 주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등. 요청한 페이지를 보여주는 창을 제외한 나머지 모든 부분이다.
-
브라우저 엔진 - 사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어.
-
렌더링 엔진 - 요청한 콘텐츠를 표시. 예를 들어 HTML을 요청하면 HTML과 CSS를 파싱하여 화면에 표시함.
-
통신 - HTTP 요청과 같은 네트워크 호출에 사용됨. 이것은 플랫폼 독립적인 인터페이스이고 각 플랫폼 하부에서 실행됨.
-
UI 백엔드 - 콤보 박스와 창 같은 기본적인 장치를 그림. 플랫폼에서 명시하지 않은 일반적인 인터페이스로서, OS 사용자 인터페이스 체계를 사용.
-
자바스크립트 해석기 - 자바스크립트 코드를 해석하고 실행.
-
자료 저장소 - 이 부분은 자료를 저장하는 계층이다. 쿠키를 저장하는 것과 같이 모든 종류의 자원을 하드 디스크에 저장할 필요가 있다. HTML5 명세에는 브라우저가 지원하는 '웹 데이터 베이스'가 정의되어 있다.
렌더링 엔진?
브라우저 엔진 ( 레이아웃 엔진 또는 렌더링 엔진 이라고도 함 ) 은 모든 주요 웹 브라우저 의 핵심 소프트웨어 구성 요소 입니다 . 브라우저 엔진의 주요 작업은 HTML 문서 및 웹 페이지 의 기타 리소스를 사용자 장치 의 대화형 시각적 표현으로 변환하는 것 입니다.
출처 : 위키백과_브라우저 엔진
- 요청 받은 내용을 브라우저 화면에 표시해줍니다.
- 기본적으로 HTML 및 XML 문서와 이미지를 표시할 수 있습니다.
- 플러그인이나 브라우저 확장 기능을 이용해 PDF와 같은 다른 유형도 표시할 수 있습니다.(이러한경우, 팝업창이 떠서 확장여부를 물어봅니다.)
렌더링 엔진 종류
- 웹킷(Webkit): 크롬, 사파리 / KHTML에서 파생된 레이아웃 엔진
- 게코(Gecko) : 파이어폭스 / 모질라 재단에서 만든 레이아웃 엔진
- 블링크(Blink) : 크롬, 오페라 / 웹키트에서 파생된 레이아웃 엔진
등등... 여러가지 종류의 렌더링엔진이 많습니다. 렌더링엔진의 종류를 더 알고 싶다면 위키백과 브라우저엔진 을 참조바랍니다.
자 그렇다면 어떻게 작동하는가..
동작과정
렌더링 엔진은 통신으로부터 요청한 문서의 내용을 얻는 것으로 시작하는데 문서의 내용은 보통 8KB 단위로 전송됩니다.

먼저 html 문서를 파싱한다.
콘텐츠 트리 내부에서 태그를 DOM 노드로 변환한다.
그 다음 외부 css 파일과 함께 포함된 스타일 요소를 파싱한다.
스타일 정보와 html 표시 규칙은 렌더 트리라고 부르는 또 다른 트리를 생성한다.
이렇게 생성된 렌더 트리는 정해진 순서대로 화면에 표시되는데,
생성 과정이 끝났을 때 배치가 진행되면서
노드가 화면의 정확한 위치에 표시되는 것을 의미한다.
이후에 UI 백엔드에서 렌더 트리의 각 노드를 가로지으며
형상을 만드는 그리기 과정이 진행된다.
이러한 과정이 점진적으로 진행되며, 렌더링 엔진은 좀 더 나은 사용자 경험을 위해 가능하면 빠르게 내용을 표시하는데 모든 HTML을 파싱할 때까지 기다리지 않고 배치와 그리기 과정을 시작한다.
전송을 받고 기다리는 동시에 받은 내용을 먼저 화면에 보여준다.
우리가 웹페이지에 접속할 때, 한꺼번에 뜨지 않고 점점 화면에 나오는 것이 이러한 과정을 거치기 때문입니다.
(요즘은 한꺼번에 땅! 뜨는것 처럼 보이지만, 인터넷이 느린 환경에서 발견할 수 있습니다..)
동작과정 예 (웹킷 동작과정)
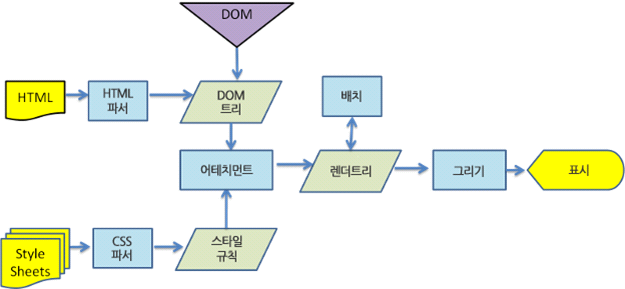 어태치먼트 : 웹킷이 렌더 트리를 생성하기 위해 DOM 노드와 스타일 정보를 연결하는 과정
어태치먼트 : 웹킷이 렌더 트리를 생성하기 위해 DOM 노드와 스타일 정보를 연결하는 과정
Document Object Model(문서 객체 모델)
웹페이지 소스를 보면 <html>, <body>와 같은 태그들이 존재합니다. 이를 Javascript가 활용할 수 있는 객체로 만들면 문서 객체가 됩니다.
모델은 말 그대로, 모듈화로 만들었다거나 객체를 인식한다라고 해석하면 됩니다.
즉, DOM은 웹 브라우저가 html 페이지를 인식하는 방식을 말합니다. (트리구조)
파싱과 DOM 트리 구축
파싱은 렌더링 엔진에서 매우 중요한 과정입니다.
파싱(parsing)
문서 파싱은 브라우저가 코드를 이해하고 사용할 수 있는 구조로 변환하는 것을 의미합니다. 파싱 결과는 보통 문서 구조를 나타내는 노드 트리인데 파싱 트리(parse tree) 또는 문법 트리(syntax tree)라고 부릅니다.
파서는 보통 두 가지 일을 하는데
1. 자료를 유효한 토큰으로 분해하는 어휘 분석기(토큰 변환기 라고도 부름)어휘 분석기는 공백과 줄 바꿈 같은 의미 없는 문자를 제거합니다.
2.언어 구문 규칙에 따라 문서 구조를 분석함으로써 파싱 트리를 생성하는 파서
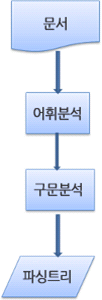
파싱 과정은 반복됩니다. 파서는 보통 어휘 분석기로부터 새 토큰을 받아서 구문 규칙과 일치하는지 확인합니다. 규칙에 맞으면 토큰에 해당하는 노드가 파싱 트리에 추가되고 파서는 또 다른 토큰을 요청합니다.
규칙에 맞지 않으면 파서는 토큰을 내부적으로 저장하고 토큰과 일치하는 규칙이 발견될 때까지 요청합니다. 맞는 규칙이 없는 경우 예외로 처리하는데 이것은 문서가 유효하지 않고 구문 오류를 포함하고 있다는 의미입니다.
😎요약
주소창에 url을 입력하고 Enter를 누르면, 서버에 요청이 전송됨
서버에서 해당 페이지에 존재하는 여러 자원들(text, image 등등)이 보내줌
이제 브라우저(크롬,파이어폭스,엣지...)는 해당 자원이 담긴 html과 스타일이 담긴 css를 W3C 명세에 따라 해석
이 역할을 하는 것이 '렌더링 엔진'(웹킷,게코,블링크...)
렌더링 엔진은 우선 html 파싱 과정을 시작함. html 파서가 문서에 존재하는 어휘와 구문을 분석하면서 DOM 트리를 구축
다음엔 css 파싱 과정 시작. css 파서가 모든 css 정보를 스타일 구조체로 생성
이 2가지를 연결시켜 렌더 트리를 만듬. 렌더 트리를 통해 문서가 시각적 요소를 포함한 형태로 구성된 상태
화면에 배치를 시작하고, UI 백엔드가 노드를 돌며 형상을 그림
이때 빠른 브라우저 화면 표시를 위해 '배치와 그리는 과정'은 페이지 정보를 모두 받고 한꺼번에 진행되지 않음. 자원을 전송받으면, 기다리는 동시에 일부분 먼저 진행하고 화면에 표시합니다.
아래의 내용을 참조하여 작성하였습니다.
사실 내용이 거의 비슷한데요..ㅋㅋ 그치만 제가 이해한걸로 정리를 해본 글입니다😎
Naver D2 브라우저는 어떻게 동작하느냐?
