
1. 데이터관찰
- sklearn dataset 활용
from sklearn.datasets import load_iris
iris = load_iris()
data, feature_names, target, target_names 등을 key 값으로 갖는 dictionary 로 반환
pd.Dataframe(iris.data, columns=iris.feature_names)로 치환하여 사용
2. 데이터의 분리
-
과적합 문제 발생 해결을 위한 데이터 분리
-
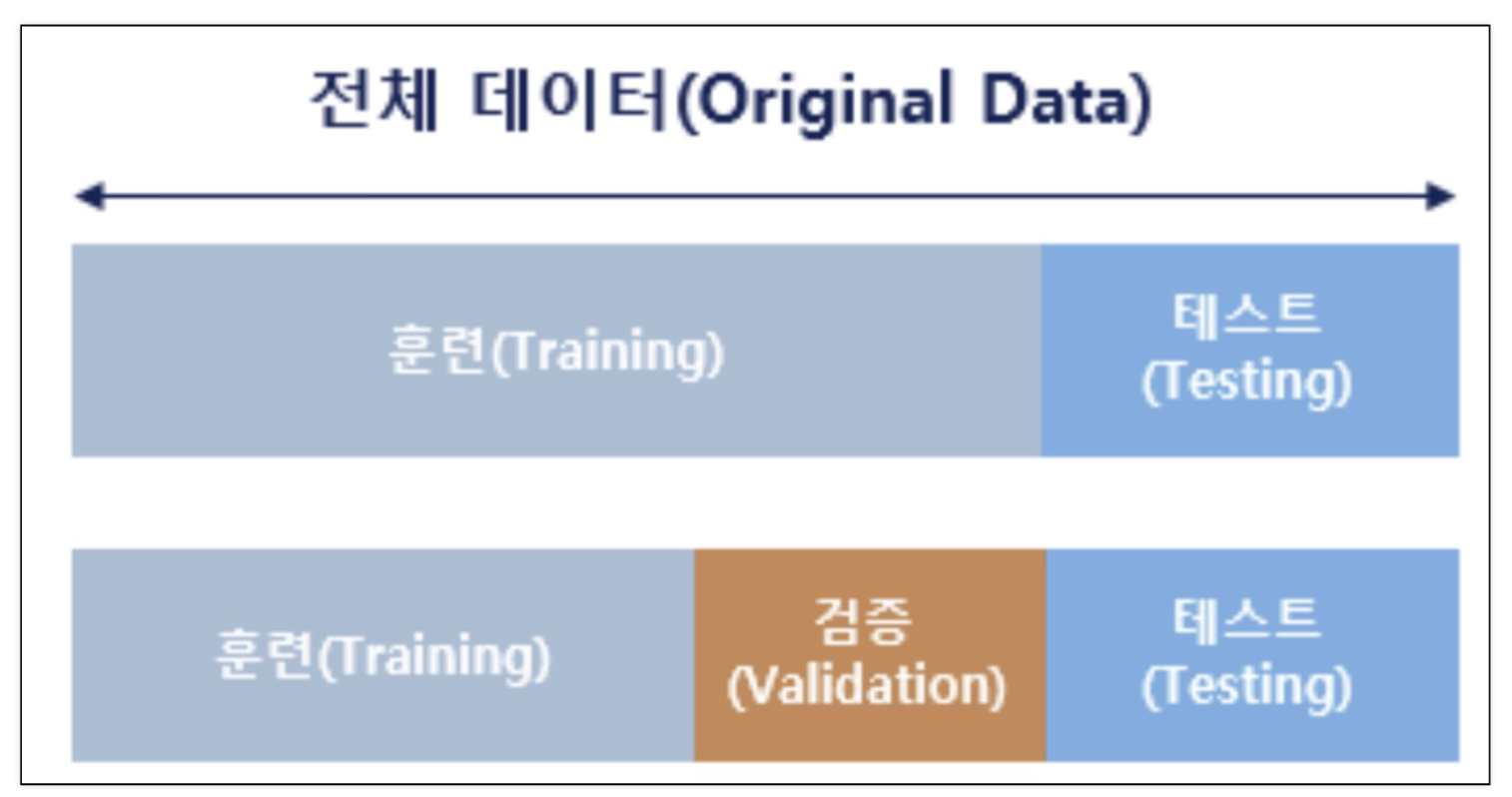
-
Scikit Learn
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, stratify=labels, random_state=13)
* stratify : 클래스별 분포를 맞추기 위한 옵션 -
Decision Tree 적용
tree = DeicisionTreeClassifier(max_depth = n, random_state=n)
tree.fit(X_train, y_train)
※ 한눈에 보기

3. encoder와 scaler
- encoder
- label encoder
- 정의
숫자 데이터로 변환 - Scikit Learn
from skelarn.preprocessiong import LabelEncoder
le = LabelEncoder()
le.fit(column)
le.transform(column)
혹은
le.fit_transform(column)
* 그 외
le.classes_: 클래스 보기
le.inverse_transform(column): 숫자를 문자로 다시 변환
- 정의
- label encoder
- scaler
- min-max scaler
- 정의
: min=0, max=1, 크기=1로 변환하는 스케일러 - Scikit Learn
from sklearn.preprocessing import MinMacSclaer
mms = MinMaxScaler()
mms.fit(df)
mms.transform(df)
혹은
mms.fit_transform(df)
* 그 외
mms.data_min_: 최소값 보기
mms.data_max_: 최대값 보기
mms.data_range_: 크기 보기
mms.inverse_transform(df): 숫자를 문자로 다시 변환
- 정의
- standard scaler
- 정의
: 평균 =0 으로 변환 - Scikit Learn
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(df)
ss.transform(df)
혹은
ss.fit_transform(df)
* 그 외
ss.mean_: 평균 보기
ss.scale_: 표준편차 보기
ss.inverse_transform(df): 숫자를 문자로 다시 변환
- 정의
- robust scaler
- 정의
: median = 0, 데이터의 길이/2 = 1으로 변환 - Scikit Learn
from sklearn.preprocessing import RobustScaler
rs = RobustScaler()
rs.fit(df)
rs.transform(df)
혹은
rs.fit_transform(df)
* 그 외
ss.mean_: 평균 보기
ss.scale_: 표준편차 보기
ss.inverse_transform(df): 숫자를 문자로 다시 변환
- 정의
- min-max scaler
4. Pipeline
-
Scikit Learn
-
설정
from sklearn.pipeline import Pipeline
estimators = [('scaler', : Scaler()), ('clf' : Classifier())]
pipe = Pipeline(estimators) -
속성값 지정
pipe.set_params(step__max_depth = n)
pipe.set_params(step__random_satate=n) -
학습
pipe.fit(X, y) -
추론
pipe.predict(X, y)* 그 외
pipe.steps: 파이프 스텝확인
pipe[step1]: 첫번째 파이프라인 스텝 확인
-
5.교차 검증
-
k-fold / stratified k-fold
-
개념
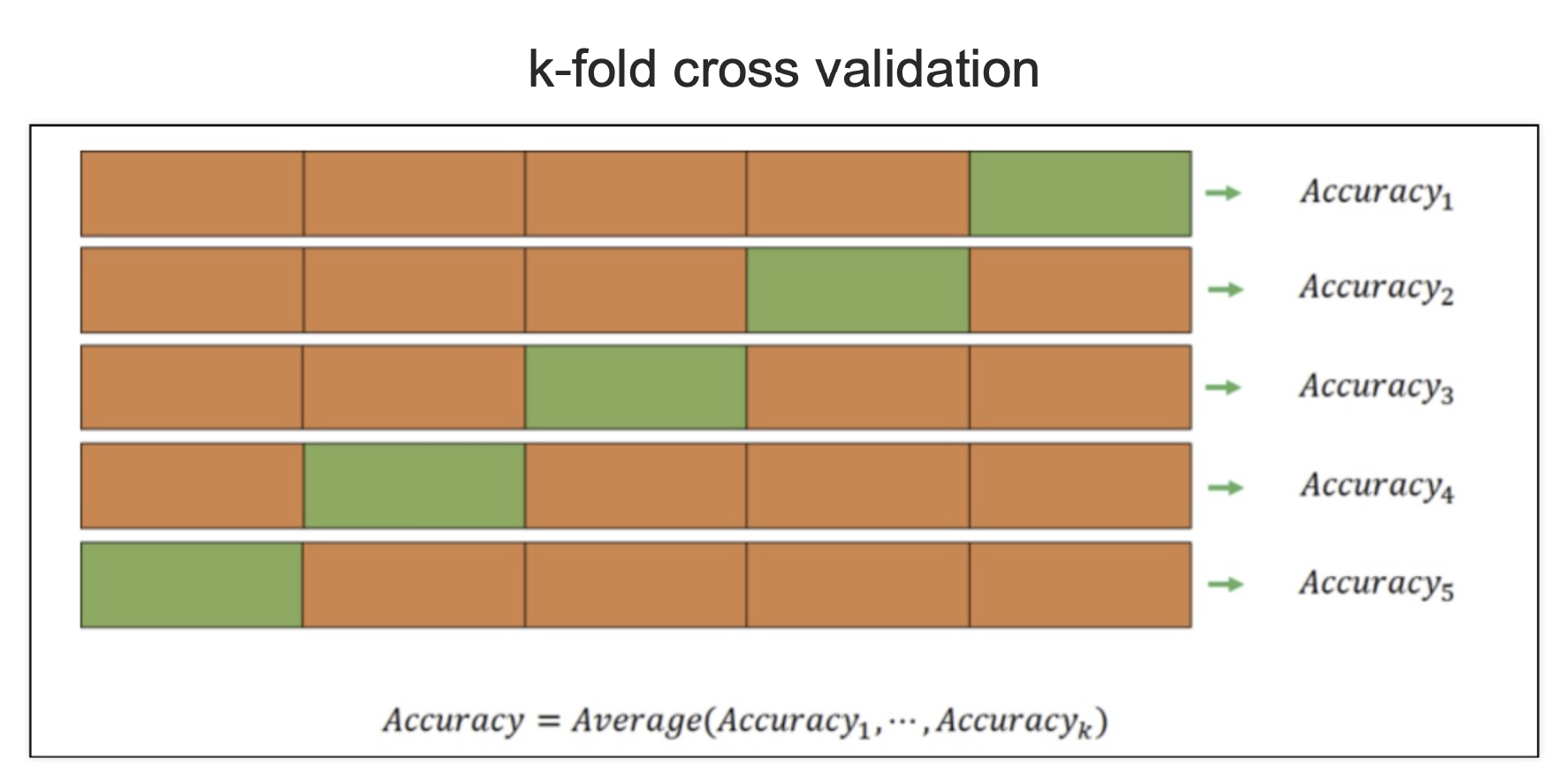
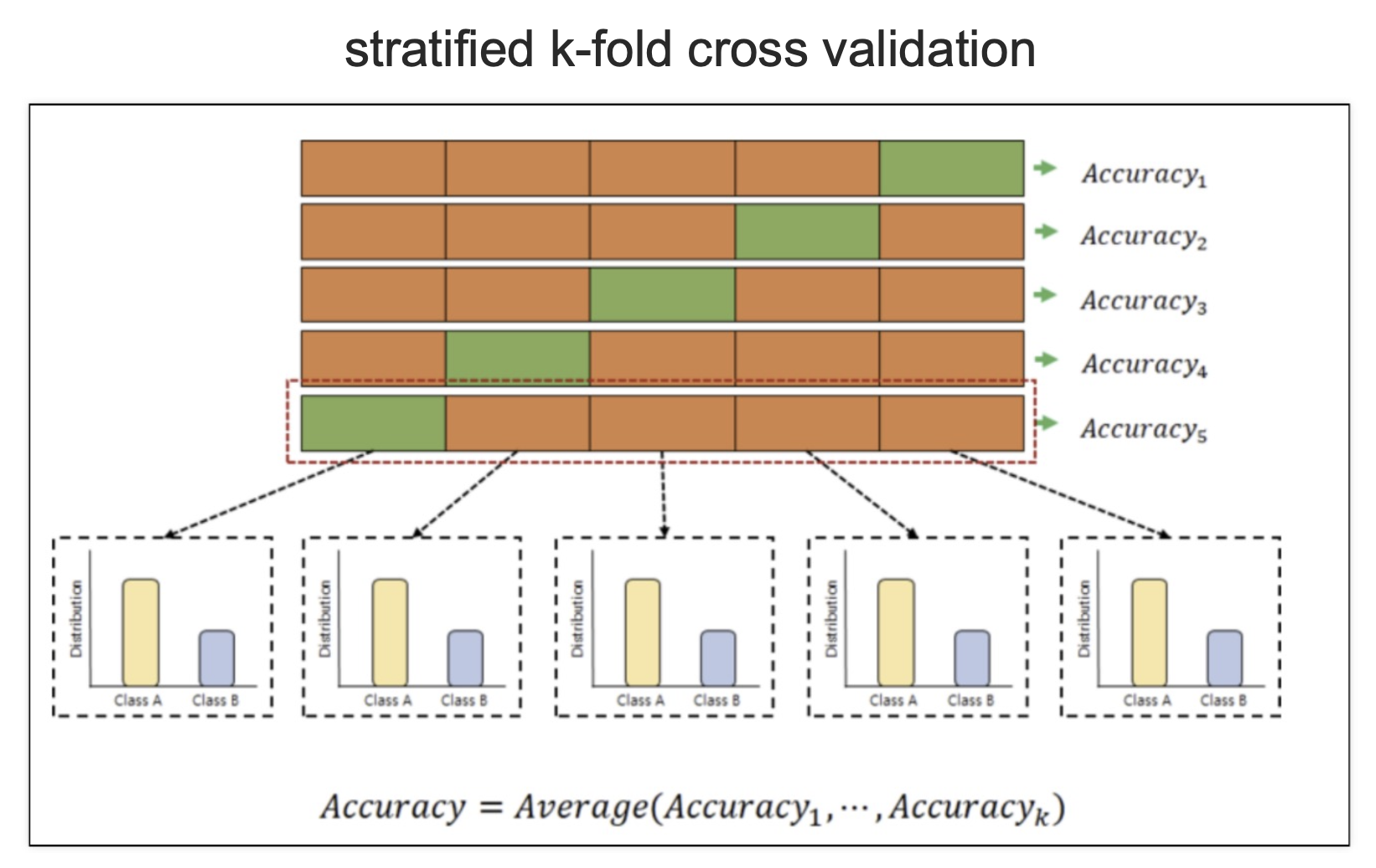
-
Scikit Learn 코드
from sklearn.model_selection import KFold
kfold = KFold(n_splits = 5)cv_accuracy = [] for train_idx, text_idx in kfold.split(X): X_train, X_test = X.iloc[train_idx], X.iloc[test_idx] y_train, y_test = y.iloc[train_idx], y.iloc[test_idx] tree.fit(X_train, y_train) y_pred = tree.predict(X_test) cv_accuracy.append(accuracy_score(y_test, y_pred) np.mean(cv_accuracy)
from sklearn.model_selection import cross_val_score
cross_val_score(tree, X, y, cv=skfold)train_score와 같이볼 때
from sklearn.model_selection import cross_validate
cross_validate(tree, X, y, cv=skfold, return_train_score = True)
-
6. 하이퍼 파라미터 튜닝
- GridSearch CV
- Scikit Learn 코드
from sklearn.model_selection import GridSearchCV
params = {parameter : []}
gridsearch = GridSearchCV(tree, param_grid = params, cv= 5)
gridsearch.fit(X, y)
gridsearch.cv_results_
* 그 외
gridsearch.best_estimator_: 최고 성능의 모델
gridsearch.best_score: 최고 성능 값
gridsearch.best_params_: 최고 성능 파라미터 - 파이프라인에 적용
params = [{step__parameter : []}]
gridsearch = GridSearchCV(pipe ,param_grid
- Scikit Learn 코드
7. 모델 평가
-
이진 분류 모델의 평가 요소
- TP True Positive : 실제 Positive를 Positive라고 맞춘 경우 - FN False Negative : 실제 Positive를 Negative라고 틀리게 예측한 경우
- TN True Negative : 실제 Negative를 Negative라고 맞춘 경우
- FP False Positive : 실제 Negative를 Positive라고 틀리게 예측한 경우
-
모델 평가의 종류
- Accuracy
- Precision (정밀도)
- 양성이라고 예측한 것 중에서 실제 양성의 비율
- ex) 스팸메일
- Recall(재현율, TPR True Positive Ration)
- 참인 데이터들 중에서 참이라고 예측한 것
- ex) 암환자 판별
- Fall out (FPR False Positive Ration)
- 실제 양성이 아닌데, 양성이라고 잘못 예측한 경우
- Accuracy
-
threshold
- 분류 모델에서 결과에 속할 비율(이진 분류에서 0.5)
-
F1 - Score
이면, F-1 score 임.
-
ROC 곡선과 AUC
-
FPR(False Positive Rate/Fall out) 이 변할 때, TPR(True Positive Rate/Recall)의 변화를 그린 그림
-
직선에 가까울 수록 모델 성능이 떨어짐
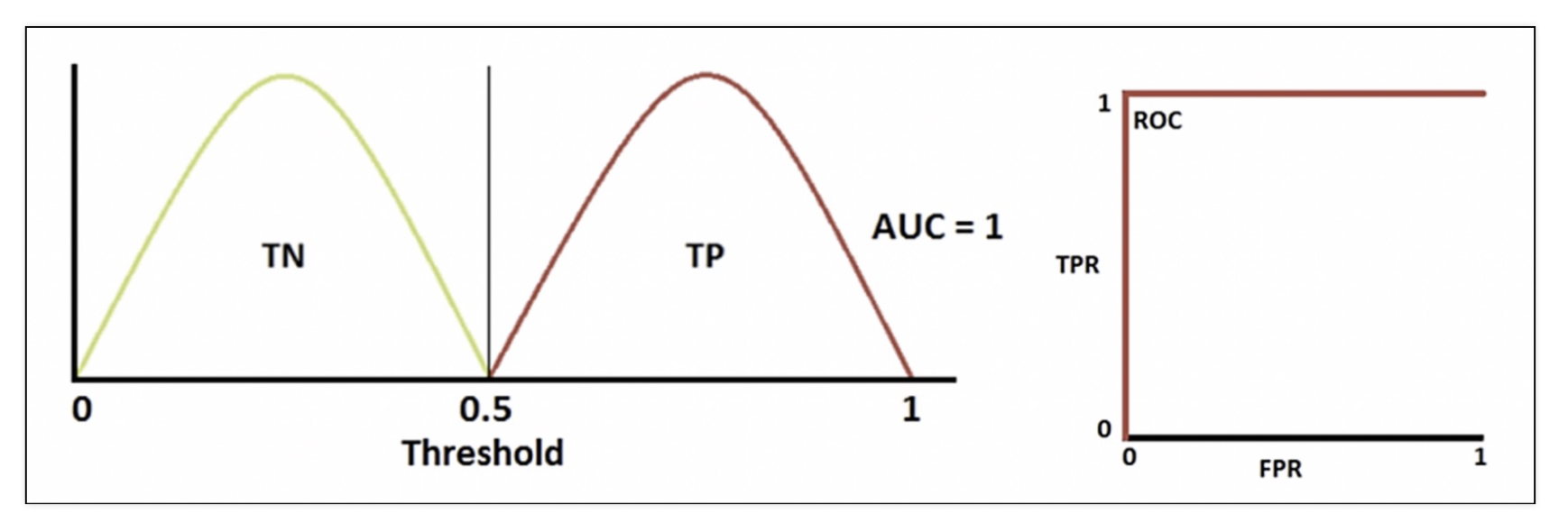
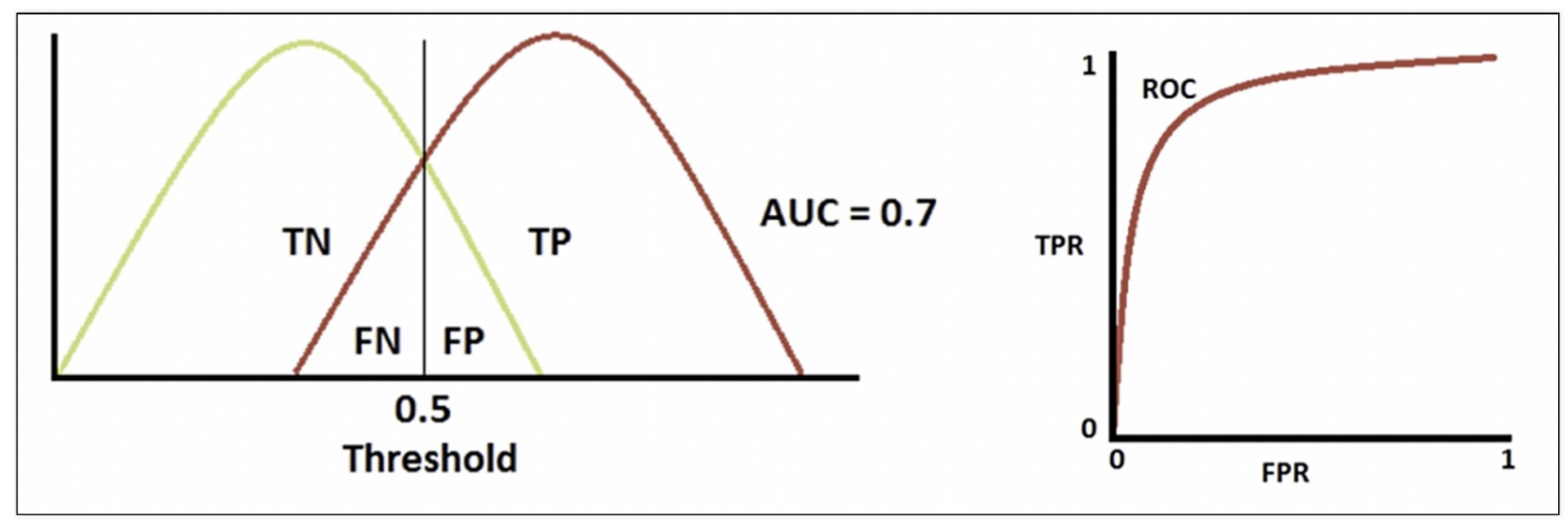
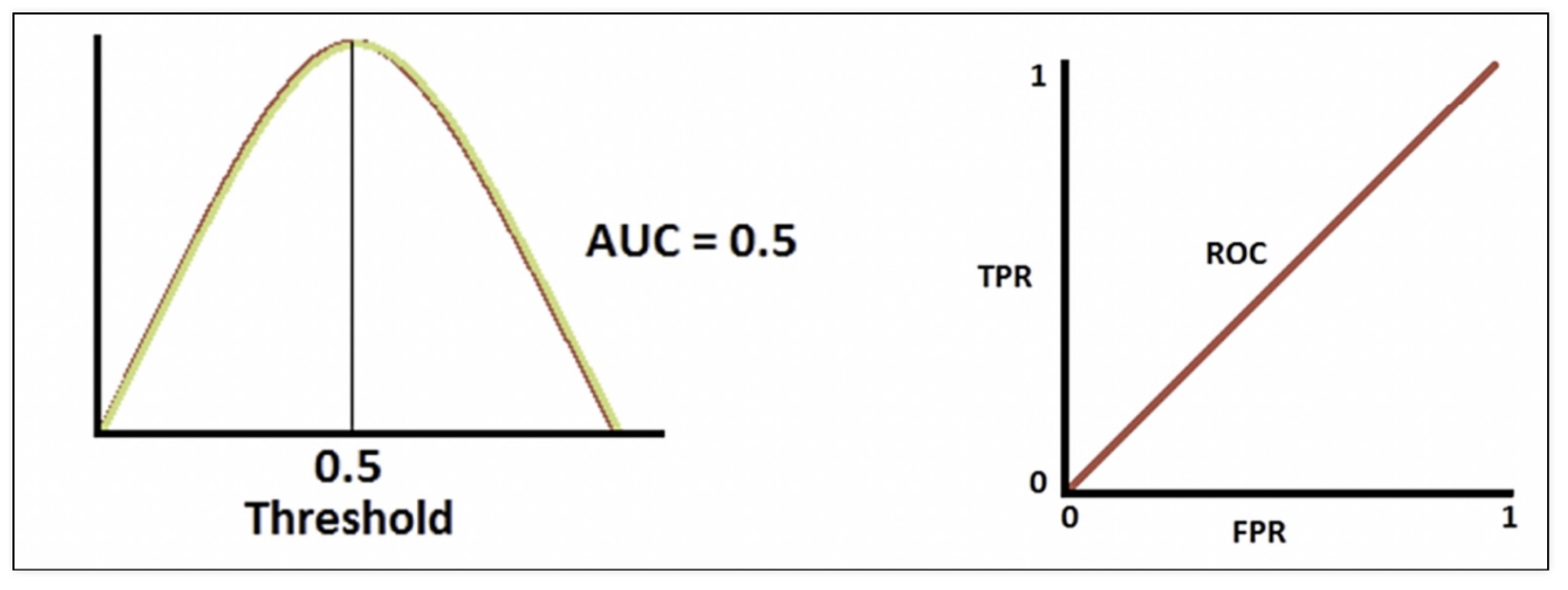
-
AUC
- ROC 곡선 아래의 면적
- 1에 가까울 수록 좋은 수치
-
ROC 커브 그리기
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)plt.plot(fpr, tpr)
-
-
모델 평가 보기
- classification_report
from sklearn.metrics import classification_report
print(classification_report(y_test, model.predict(X_test)) - confusion_matrix
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, model.predict(X_test))
- classification_report
-
Threshold 조정하기
from sklearn.preprocessing import Binarizer
binarizer = Binarizer(threshold = n).fit(pred_proba)
pred_bin = binarizer.transform(pred_proba)
8. Box Plot의 처리
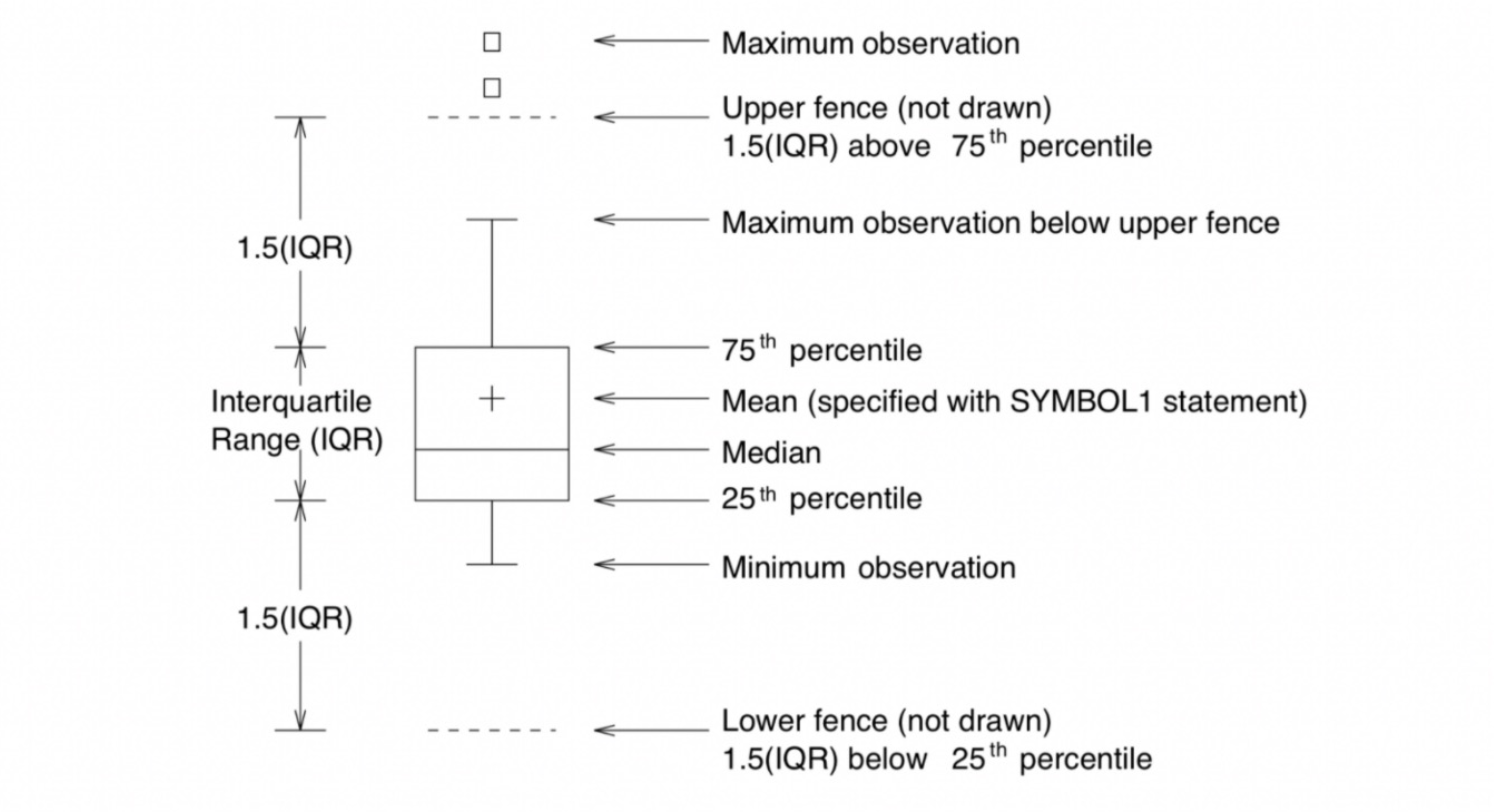
- Q1 :
np.percentile(x, 25)
Q2 :np.median(x)
Q3 :np.median(x, 75)
