
모델 등록 전 서버 실행
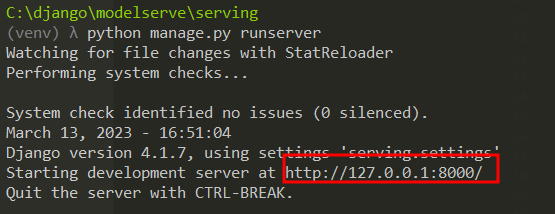
모델을 본격적을 등록하기 전에, 로컬 서버를 실행해보겠습니다.
별 다른 문제없이 서버가 실행되는 걸 확인할 수 있습니다.
모델 및 추론 코드 등록
일단 저는 views.py에 모델을 불러오는 코드와 추론하는 코드를 한 번에 때려넣었습니다.
from infer.models import Post
import time
import torch
import numpy as np
from transformers import BertTokenizerFast, BertModel
device = torch.device('cpu')
tokenizer= BertTokenizerFast.from_pretrained("beomi/kcbert-base")
# model class > instance object
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.model = BertModel.from_pretrained("beomi/kcbert-base")
self.linear_model = torch.nn.Linear(768,3)
def forward(self, batch):
out = self.model(**batch)
return self.linear_model(out[1])
# tokenize
def tokenize(text) :
inputs = tokenizer(text, add_special_tokens=True, padding="max_length", truncation=True)
for k, v in inputs.items():
inputs[k] = torch.LongTensor([v])
return inputs
# model inference
def model_serve(device, input_submit):
start = time.time()
model = Model().to(device)
state_dict = torch.load(r"C:\django\modelserve\serving\model_serve_pytorch.pth", map_location=device)
model.load_state_dict(state_dict)
model.eval()
model_input = tokenize(input_submit)
out = model(model_input.to(device)).detach().cpu().numpy()
label = np.argmax(out)
if label == 0 :
result = "긍정"
elif label == 1 :
result = "부정"
else :
result = "중립"
end = time.time()
service_time = end-start
return result, service_time
def input(request) :
return render(request, 'infer/input.html')
def predict(request):
if request.method == 'POST' :
form = request.POST
input_submit = form['input']
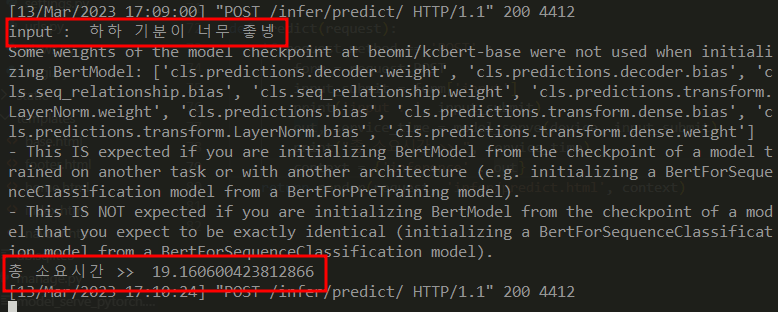
print('input : ', input_submit)
out, service_time = model_serve(device, input_submit)
print("총 소요시간 >> ", service_time)
context = {'inference' : out}
return render(request, 'infer/predict.html', context)
모델 추론 테스트
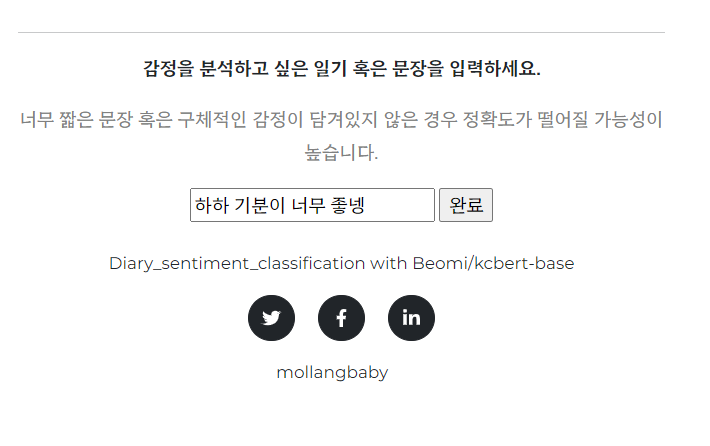
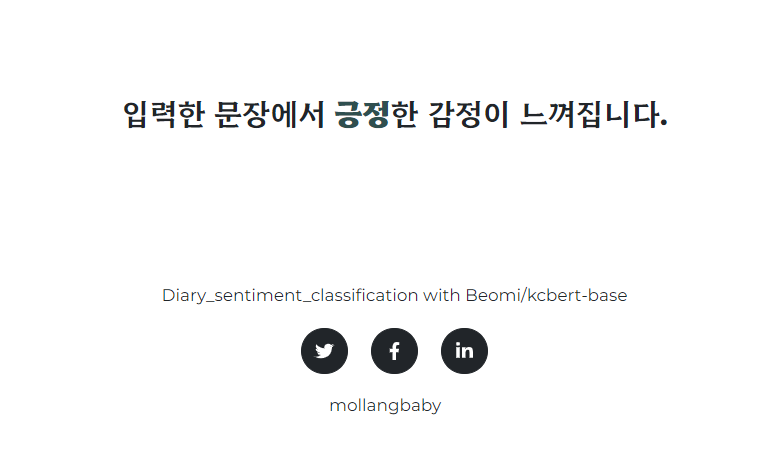
입력페이지와 추론페이지 스크린샷입니다.
입력 페이지
추론 페이지
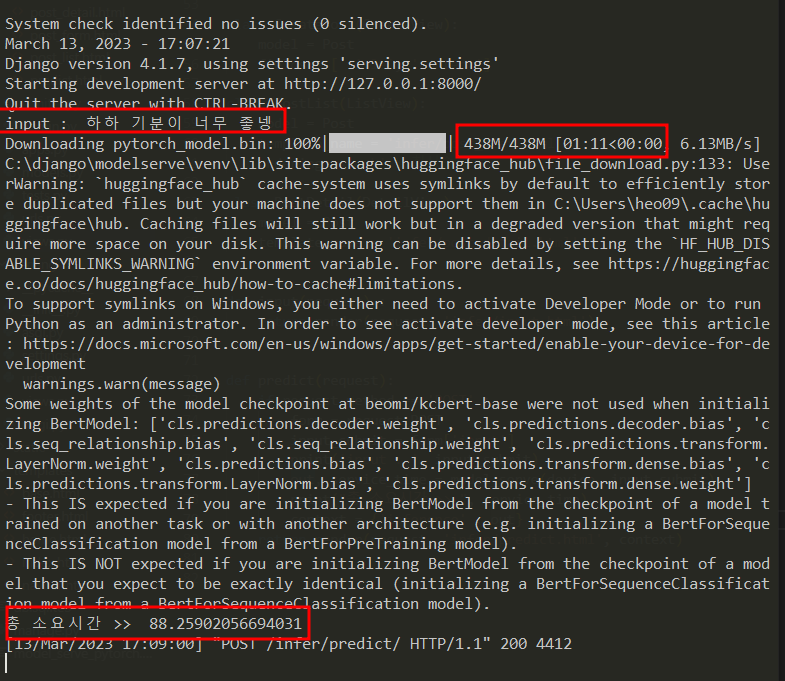
첫번째 테스트 소요 시간 : 약 88초
두번째 테스트 소요 시간 : 약 19초
💁♀️다음글에서는 제가 모델을 등록 및 추론 코드에서 서비스딜레이를 일으킨 주요 코드와 그에 대한 이유를 설명하고, 모델 등록과 추론을 효율적으로 시행할 수 있도록 재배치하는 내용을 다루겠습니다.
