[LLaMA 관련 논문 리뷰] 01-FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS (Instruction Tuning)
논문리뷰

LLaMA: Open and Efficient Foundation Language Models
LLaMA는 Open and Efficient Foundation 언어 모델입니다. 오픈소스를 제공하지 않는 closed source 모델들로 인해 점차 ai업계가 폐쇄적으로 변해가는데요, Meta는 open source 모델을 공개하고 있습니다. LLaMA 역시 open source 모델이며 공개 데이터만으로 학습되었습니다. 여기서 open이라는 수식어가 설명되네요.
그렇다면 Efficient Foundation은 어떻게 이해하면 될까요?
그동안의 Large Language Models(LLMs)들은 주로 Transformer를 backbone으로 하여 대규모 데이터셋을 대규모 컴퓨팅 리소스로 학습하여 그 성능을 경쟁하였습니다. 실상 그만큼의 budget이 없다면 이 시장에 뛰어들 수가 없겠죠. 학습 뿐만 아니라 추론 시에도 마찬가지입니다. 모델을 서비스하는 입장에서 생각해봅시다. 모델의 학습 성능은 좋은데, 얘를 서비스하기에는 budget이 부족한 상황에 직면하게 됩니다. 학습 비용보다 추론 비용이 더 큰 상황이 됩니다. 역시나 현실적으로 모델을 채택하기엔 어렵겠죠. 이런 문제로 인해 compute budget을 고려한 연구가 진행되고 있는데요, LLaMA는 특히 추론 시 budget을 고려한 Foundation 모델입니다.
LLaMA 논문에는 LLaMA로 instruction tuning을 진행한 파트가 짧게 있는데요, Instrunction Tuning은 중요한 개념이기 때문에, 본격적으로 LLaMA 논문을 읽기 전에 Instruction tuning을 제안한 논문을 리뷰하겠습니다.
FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS (Instruction Tuning)
FineTuning은 익숙합니다. 근데 Instruction Tuning은 뭘까요?
논문에서는 Instruction Tuning을 이렇게 설명합니다.
Instruction tuning is a simple method that, as depicted in Figure 2, combines appealing aspects of both the pretrain–finetune and prompting paradigms by using supervision via finetuning to improve language model’s responses to inference-time text interactions.
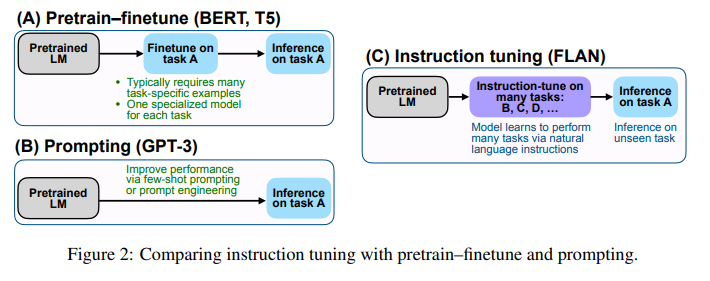
fine tuning이란 pretrained된 언어 모델을 다운스트림 태스크에 맞춰 supervised 방식으로 데이터셋을 학습시키는 튜닝방법입니다. 튜닝이라는 단어에서도 보이듯이, pretrain 단계에서의 가중치가 task specific한 추가 데이터셋을 학습하면서 업데이트됩니다.
반면 prompt learning은 task-specific한 데이터를 추가로 학습시키지 않습니다. 사전학습을 진행할 때 모델에게 prompt(문제에 대한 설명)를 제공하여 학습시키는 방법입니다. 따라서 pretrained 모델의 추가적인 가중치 업데이트가 이뤄지지 않습니다.
prompt learning은 모델에게 예시를 몇 개를 주느냐에 따라서 zero-shot, one-shot, few-shot learning으로 구분됩니다. zero-shot은 모델에게 예시를 주지 않습니다. one-shot은 1개의 예시만을 제공하는 방법이고 few-shot은 몇 개의 예시를 보도록 허용하는 방법입니다.
Instruction tuning은 prompt learning의 prompt 방식과 finetuning의 가중치 업데이트를 결합한 튜닝 방법입니다. 모델에게 지시사항(instructions)으로 기술된 태스크를 supervised 방식으로 가르치는 것인데요, 이렇게 가르친다면 모델이 지시사항을 따르는 방식을 학습하게 될 것이고, 따라서 unseen task를 마주했을 때도 지시사항을 따르는 방식을 이미 배웠기 때문에 unseen task의 지시사항에 따라 잘 추론할 수 있을 것이라는 아이디어에서 착안하였습니다. 모티베이션은 모델을 지시사항(instructions)에 응답하도록 함으로써 모델의 제로샷 성능을 향상시키는 것입니다.
왜 zero-shot?
왜 제로샷 성능인지 궁금할 수도 있겠습니다. GPT-3와 같은 LLM은 few-shot learning에 있어서 좋은 성능을 보였습니다. 그러나 여전히 zero-shot 성능은 few-shot 성능에 비해 낮습니다.
본 논문에서는 이를 설명할 수 있는 가장 가능성 있는 원인으로, 훈련에 사용된 데이터 형식과 프롬프트의 형식이 유사하지 않다는 것을 언급합니다.
만약 저희가 처음 보는 문제, 심지어 그 유형조차 처음 본다면 사실 답과 관련된 지식을 알고 있다고 하더라도 문제를 이해하는 것 조차 어렵겠죠. 이럴 때 그 문제를 보충 설명해주는 예시(few-shot)가 있는 경우와 그러한 예시가 하나도 없는 경우(zero-shot)의 난이도를 비교한다면, 당연히 후자가 더 어렵습니다.
그래서 프롬프트와 비슷한 형식(지시사항-instructions)으로 데이터를 변환시켜 모델을 가르칩니다.
Instruction Tuning
본 논문에서는 LaMDA-PT(decoder-only, BPE 알고리즘, pretrained, 137B parameters) 모델로 instruction tuning을 진행합니다. 먼저 성능 비교 표를 보겠습니다.
gpt-3와의 성능 비교
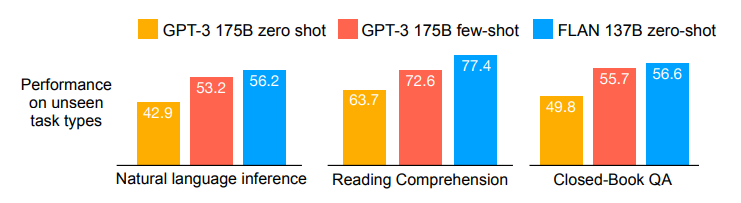
GPT-3와 비교했을 때 zero-shot, few-shot 성능 모두 Instruction-tuned 모델(FLAN)이 더 높은 성능을 보입니다. 논문에서는 LaMDA-PT를 instruction tuning한 모델을 FLAN으로 지시합니다.
Instruction tuning datasets & task clusters
파인튜닝을 진행할때는 task-specific한 데이터셋을 선정하고 모델에 학습시켜 가중치를 업데이트합니다. 그것처럼 instruction tuning을 진행할 때에는 instruction 형식으로 변환된 instruction tuning dataset 여러개를 모델에게 학습시켜 가중치를 업데이트해야합니다.
instruction tuning용 데이터셋을 처음부터 만드는 것은 resource-intensive하기 때문에, 기존의 데이터셋을 instruction 포맷으로 변환합니다.
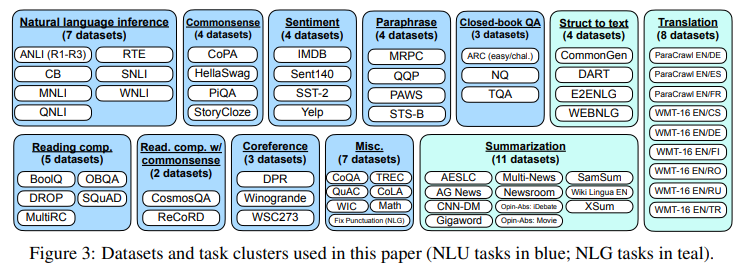
그러기 위해서는 먼저 튜닝에 사용할 데이터셋을 선정해야하는데요, 본 논문에서는 먼저 자연어처리(NLU+NLG)에 사용되는 데이터셋을 태스크 유형 별로 전부 클러스터링하여 총 12개의 클러스터를 구성합니다.
templates
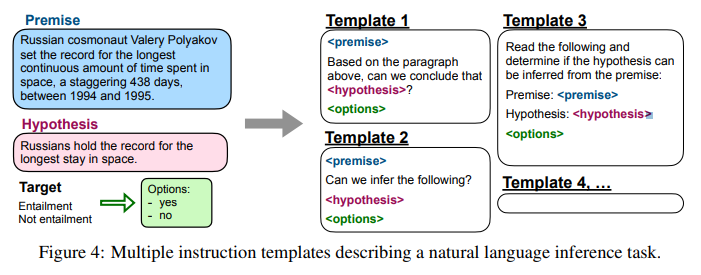 각 데이터셋마다, 해당 데이터셋의 태스크를 설명하는 10개의 고유 템플릿(natural language instructions)을 구성합니다. 주목할 점은, 템플릿의 다양성을 위해 작업-반전 템플릿을 포함시킨 것입니다.
각 데이터셋마다, 해당 데이터셋의 태스크를 설명하는 10개의 고유 템플릿(natural language instructions)을 구성합니다. 주목할 점은, 템플릿의 다양성을 위해 작업-반전 템플릿을 포함시킨 것입니다.
10개의 템플릿 중 대부분은 원래의 태스크에 부합하는, 원래의 태스크를 설명하는 템플릿입니다. 그러나 그 중 최대 3개의 템플릿은 작업을 반전시킨 템플릿입니다. 예를 들어, sentiment classification은 감정 분류로 NLU(자연어이해) 태스크입니다. 해당 데이터셋의 템플릿에 작업이 반전된 NLG(자연어생성) 성격의 템플릿("Generate a movie review")을 포함시킨 것입니다.
tuning and inference
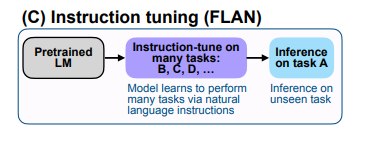
이렇게 튜닝 데이터셋과 함께 각 데이터셋을 설명하는 템플릿(10개)이 마련되었습니다. 사전학습된 LM(LaMDA-PT)을 튜닝 데이터셋으로 istruction tuning을 진행합니다. 이때 지시어 템플릿은 랜덤하게 선택되며, 이 템플릿에 맞춰서 데이터셋이 포맷팅됩니다.
inference on unseen task
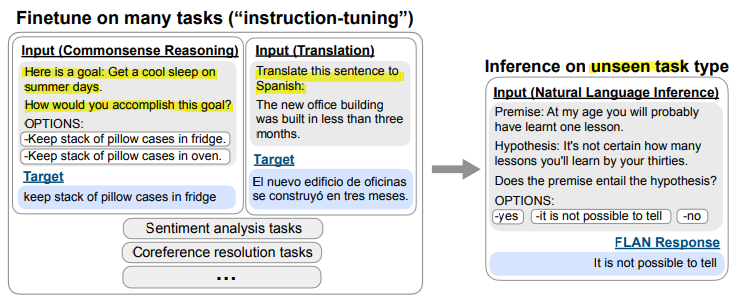
본 논문의 초점은 unseen task에 대한 FLAN의 제로샷 성능을 확인하는 데 있습니다. 그렇기에 unseen task를 어떻게 정의하고 어떻게 확인하느냐가 중요합니다.
연구에서는 unseen task에 대한 제로샷 성능을 평가하기 위해 다음의 방식을 사용합니다.
- 데이터셋D를 unseen task로 선정
- instruction tuning을 진행할 때, 데이터셋 D가 포함된 클러스터를 제외한 나머지 클러스터에 속한 데이터셋을 학습시켜 튜닝 > unseen task가 속한 클러스터 전부를 학습시키지 않음
- zero-shot 성능을 평가하기 위해 데이터셋D로 inference 진행
평가
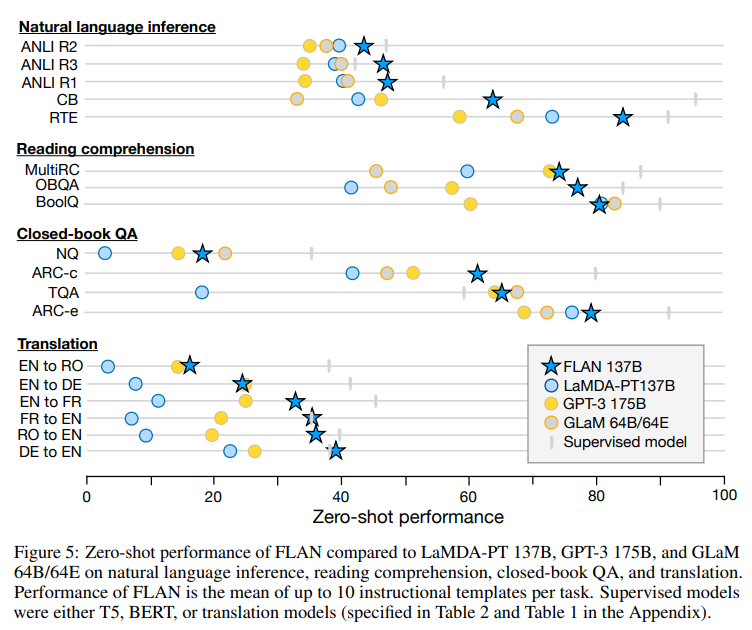
Ablation Studies
model size
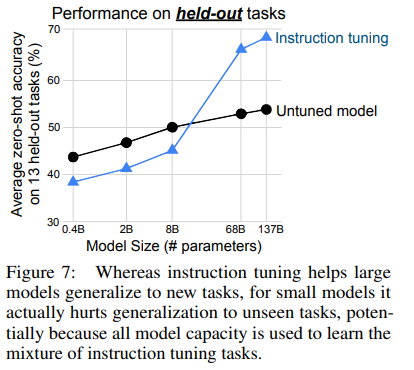
모델의 사이즈가 클 수록 instruction tuning의 효과가 두드러지게 나타났습니다. 모델 사이즈 8B일 때는 instruction tuning을 진행한 모델의 성능이 더 낮지만, 그 이상의 사이즈 모델부터는 확연히 우세한 성능을 보이고 있습니다.
few shot performance
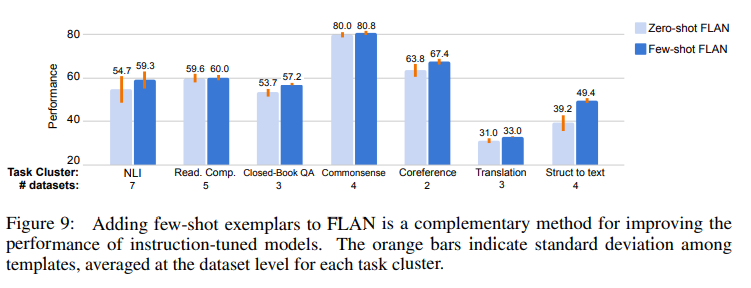
FLAN 모델 또한 zero-shot 성능보다는 역시 few-shot 성능이 더 좋게 나타납니다.
다음 글도 Instruction Tuning 논문 리뷰입니다. 다음 글에서 리뷰할 논문은 2022년에 공개되었습니다.
