이전 글 : [Pytorch] 이미지 분류 with ViT
이미지 분류를 위해 google vit 모델을 학습했습니다. 1 에폭도 다 학습하지 못하고 중단되었습니다.
일단 사용 모델을 변경하도록 하겠습니다.
DeIT
DeIT(Data-efficient Image Transformers)은 21년도에 Facebook에서 공개한 모델입니다.
이름에서 알 수 있듯이, Transformer Encoder를 Image 처리에 사용한 모델입니다.
Tiny, Small, Base, Large 네 가지 버전이 있습니다.
제가 사용할 버전은 DeIT Small입니다. 작은 크기의 이미지 데이터셋에서도 높은 성능을 보인다고 합니다. 기존 ResNet보다 파라미터 수가 적다고 하네요.
HuggingFace에서 모델 가져오기
일단 모델을 불러옵니다.
from transformers import DeiTFeatureExtractor, DeiTForImageClassification
extractor = DeiTFeatureExtractor.from_pretrained('facebook/deit-small-distilled-patch16-224')
model = DeiTForImageClassification.from_pretrained( 'facebook/deit-small-distilled-patch16-224')모델의 분류기를 확인하여 이 모델의 기본 분류기가 몇 개의 라벨(클래스)로 이미지를 분류하는지 확인하겠습니다.
model.classifier
1000개의 라벨로 이미지를 분류하고 있네요.
제가 수행할 태스크는 1000개가 아닌 159개의 클래스로 이미지를 분류해야합니다.
태스크에 맞게 클래스 개수를 변경하겠습니다.

변경된 것을 확인할 수 있습니다.
망을 더 쌓거나, 특정 망을 동결시키지 않을 것이기 때문에 모델 작업은 여기까지 하겠습니다.
Data Preprocessing
중간에 학습이 중단된 원인 중 하나는 이미지 증강으로 인한 자원 사용량 증가일 것입니다.
지금은 성능점수를 확인조차 못하고 있으니, 증강 코드는 패스하고 이미지 스케일링과 같은 필수 전처리만 수행하겠습니다.
필수 전처리는 간단하게 HuggingFace에서 제공하는 FeatureExtractor를 사용하면 됩니다.
FeatureExtractor의 기능은 여기에서 확인하시면 됩니다.
class Dataset(torch.utils.data.Dataset) :
def __init__(self, img_path_np, target, extractor):
self.imgs = img_path_np
self.target = target
self.extractor = extractor
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
item = {}
item['img'] = self.extractor(images= Image.open(self.imgs[idx]).convert('RGB'), return_tensors="pt")
item['y'] = self.target[idx] # len 159
return item이미지 분류 모델은 input shape으로 batch_size, channel, Height, weight를 입력받습니다.
위와 같이 데이터셋을 작성하고 데이터로더에 넣어 batch를 뽑아내봅시다.
모델이 학습하는 데이터는 img 데이터인 pixel_values입니다.
한 번 batch['img']를 model에 넣어 테스트를 해보겠습니다.
model(**batch['img'].to(device)).to(device)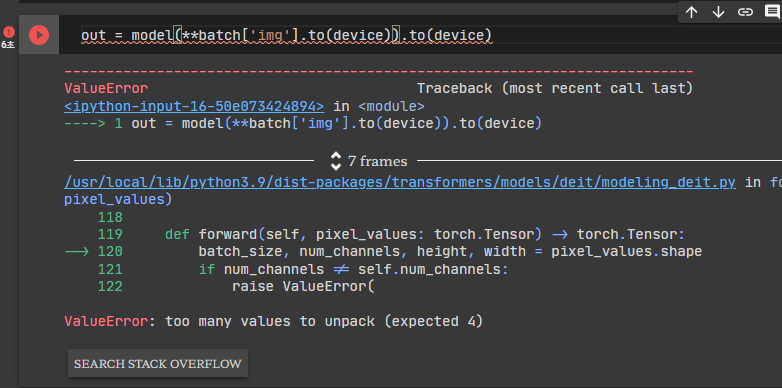
왜 에러가 났을까요? 에러 메시지가 친절하게 알려주고있습니다.
model의 input값은 batch_size, num_channels, height, width의 shape을 가진 텐서여야하는데, 지금 더 많은 값이 들어와있다는 거죠.
실제로 batch['img']의 차원을 확인해보겠습니다.

(batch_size, ? , num_channels, height, width)의 shape을 갖고있네요.
데이터로더에서 batch_size만큼 데이터가 로드되는 과정에서 불필요한 1차원이 추가되어서 발생한 에러입니다.
모델이 요청한 형식에 맞게 차원을 변경해주면 금방 해결됩니다.
저는 데이터로더에 collate_fn 함수를 전달하여 해결하겠습니다.
def collate_fn(examples):
batch = {}
batch['img'] = torch.stack([x['img']['pixel_values'] for x in examples]).squeeze(1)
batch['y'] = torch.tensor([x['y'] for x in examples])
return batch변경된 부분은 두 가지입니다.
(1) 불필요한 차원 제거
- 1차원에 값이 들어가기 때문에 squeeze 메소드를 사용하여 1차원을 제거합니다.
(2) 미리 pixel_values값만 가져오기
- 위 코드로 학습할 경우 모델에 데이터를 넣을 때 batch['img']를 언패킹해서 넣는데요, 그 과정도 없애기 위해 애초에 collate_fn 내부에서 미리 pixel_values값만 가져오도록 설정해두었습니다.
다시 테스트를 해보면, 정상적으로 잘 나온 걸 확인할 수 있습니다.

폴드 별 분리 학습
본 글의 목적이죠. 폴드 별 분리학습에 대해 설명하겠습니다.
폴드 별 분리 학습은 제가 큰 모델을 학습할 때 자주 사용하는 방법입니다.
자주 사용한다기 보단 다른 방안이 없어서 사용한다는 게 더 적합할 것 같네요(로컬 학습 불가능합니다..하하하..).
이 방법을 사용하면 1에폭 당 드는 학습 소요 시간을 줄일 수 있습니다.
코랩에서 학습하시는 분들에게만 추천하는 방법입니다. 보통 코랩에서 큰 모델을 큰 데이터 크기로 학습할 경우 중간에 런타임이 끊기거나, cuda oom에러가 떠서 중단되는 경우가 빈번히 발생합니다.
1 에폭 당 학습 시간을 줄인다면, 이런 경우를 대비할 수 있겠죠?
폴드 별 분리 학습은 seed를 고정하여 어떤 환경에서든 동일하게 데이터셋이 분리되도록 설정한뒤,
n개로 분리된 데이터셋을 각각의 다른 환경에서 학습하도록 하는 것입니다.
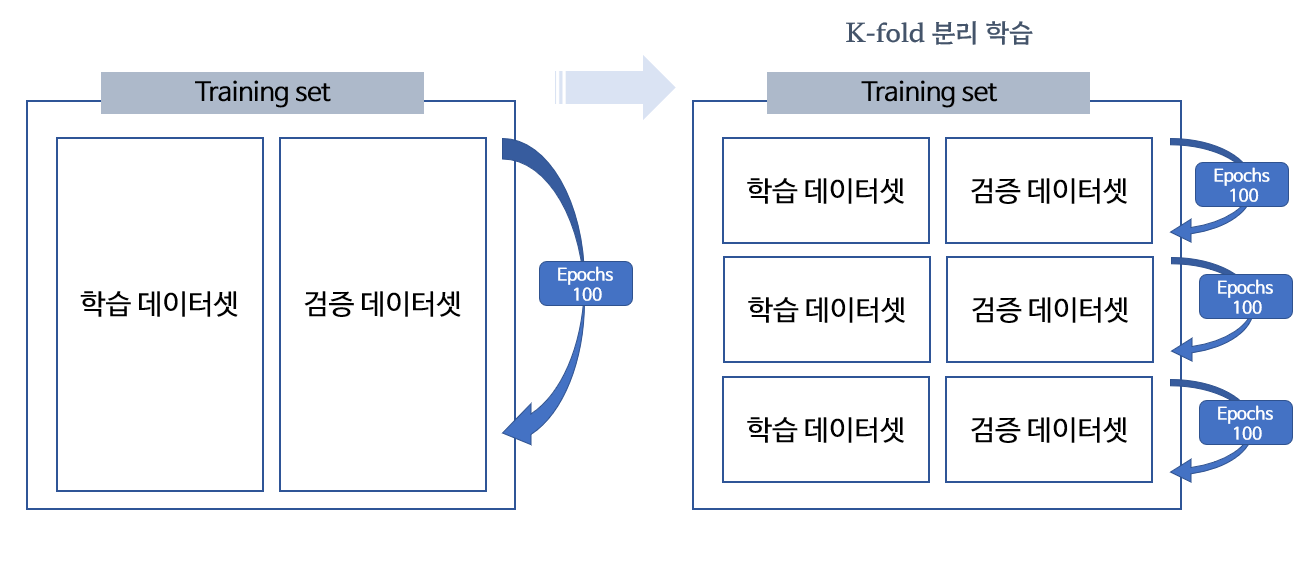
- 좌측 이미지는 기존의 학습 방법이고, 우측 박스는 폴드별 분리학습 방법입니다.
보통의 학습 코드는 아래와 같은 구조를 갖게 됩니다.
데이터셋을 단순하게 train, valid셋으로 분리한 뒤 에폭 수만큼 학습을 진행합니다.
총 학습 횟수는 에폭 수와 동일합니다.
train_dt = Dataset(train, target_t)
valid_dt = Dataset(valid, target_v)
train_dl = torch.utils.data.DataLoader(train_dt, batch_size=32, shuffle=true)
valid_dl = torch.utils.data.DataLoader(valid_dt, batch_size=32, shuffle=true)
for e in range(epochs) :
for batch in train_dl :
train ...
model.eval()
for batch in valid_dl :
valid ...
폴드 별 학습은 kfold를 이용하여 데이터셋을 n개로 분리합니다.
n개의 데이터셋이 별도의 환경에서 에폭 수 만큼 학습하게 됩니다.
모든 환경 seed를 고정하였기에 각각의 데이터셋은 중복되는 값없이 깔끔하게 분리됩니다.
총 학습 횟수는 kfold 개수 * 에폭 수입니다.
from sklearn.model_selection import KFold
cv = KFold(n_splits=3,shuffle=True, random_state=77) # 3개의 폴드로 분리
seed_everything(77)
optimizer = torch.optim.Adam(model.parameters(), lr = 0.00001)
loss_fn = torch.nn.CrossEntropyLoss()
batch_size = 8
for i,(tri,vai) in enumerate(cv.split(train)):
if i == 0 : # 0번쨰 폴드만 학습 진행하겠다
model = model.to(device)
optimizer = torch.optim.RAdam(model.parameters(),lr=0.00001)
train_dt = Dataset(train[tri],target[tri], extractor)
valid_dt = Dataset(train[vai],target[vai], extractor)
train_dl = torch.utils.data.DataLoader(train_dt, batch_size=batch_size, shuffle=True, collate_fn = collate_fn)
valid_dl = torch.utils.data.DataLoader(valid_dt, batch_size=batch_size,shuffle=False, collate_fn = collate_fn)
best_score = 0
patience = 0
num_epochs = 10
for epoch in range(num_epochs):
train... # 학습 진행
valid... # 검증 진행
if patience == 3:
break
print(f" Epoch ({epoch}), BEST F1: {best_score}")
print(f"Fold ({i}), BEST F1: {best_score}")
torch.cuda.empty_cache()
즉, 학습하는 데이터셋의 크기를 줄여서 에폭 당 학습 시간을 줄이는 단순한 접근입니다.
train
학습 코드입니다. 에폭 하나 약 4시간 정도 소요된다고 보면 될 것 같습니다.
어제 학습을 진행한 ViT는 거의 8시간 정도로 측정되었던 것과 비교하면 훨씬 속도가 빠르긴 합니다.
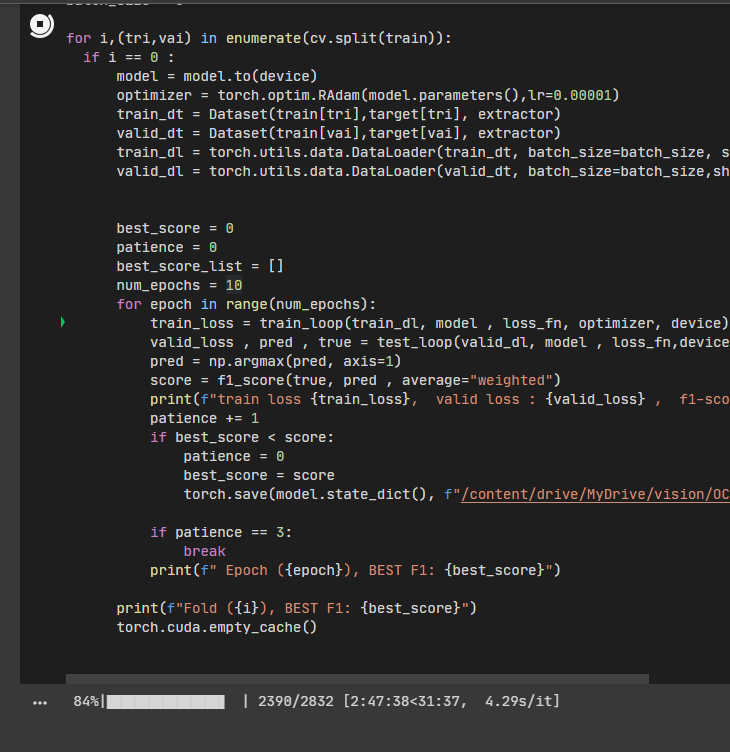
다시 말씀드리지만, 한 번에 학습하는 데이터의 개수가 줄었기 때문에, 학습 성능은 더 낮을 가능성이 있습니다. 분류태스크에서 클래스 개수가 많거나 전체 데이터 크기가 작다면 비추합니다.
