HashMap
HashMap은 해시 테이블 기반으로 키-값 쌍을 저장하는 Map 인터페이스의 구현 클래스다.
HashMap 내부 구현
기본 구조
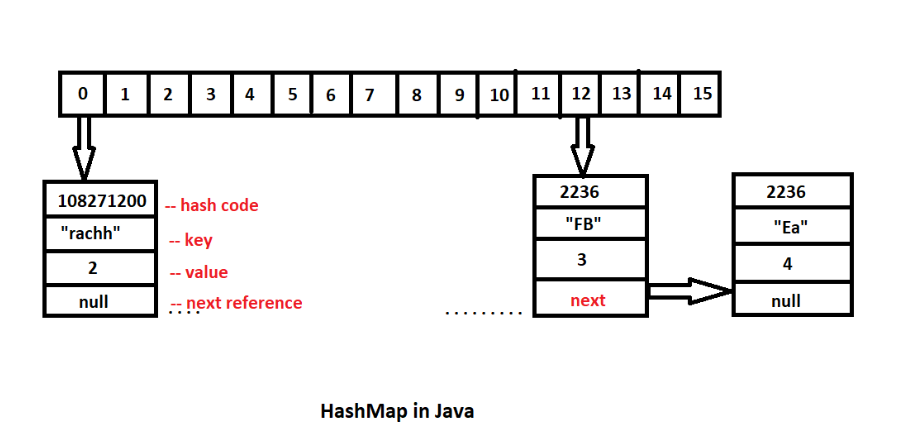
내부적으로 Node<K,V>[] table이라는 배열을 가지고 있고, 이 배열의 각 요소를 버킷이라고 한다.
아래 필드는 HashMap의 정체성과 성능을 결정하는 최소 요소이다.
// 내부 필드
transient Node<K,V>[] table; // 실제 데이터를 저장하는 배열
transient int size; // 현재 저장된 Entry 개수
int threshold; // 리사이징 임계값 (capacity * loadFactor)
final float loadFactor; // 로드 팩터 (기본값: 0.75)각 버킷은 Node 객체를 가리키고, Node 구조는 아래와 같다.
static class Node<K,V> {
final int hash; // 해시 값 (캐싱)
final K key; // 키
V value; // 값
Node<K,V> next; // 다음 노드 (충돌 시 연결 리스트)
}
배열을 사용하는 이유
HashMap은 키를 해시값으로 변환해 배열 인덱스로 바로 접근함으로써 O(1) 조회를 하기 때문에, 내부 저장 구조로 배열을 사용한다.
키의 해시 값 계산
-
HashMap은 키 객체의 hashCode()를 호출한다.
-
그 다음 Java는 그냥 hashCode()를 쓰지 않고 hashCode 상위 비트가 버려지는 문제 방지와 충돌 방지를 위해 비트 섞기를 한다.
이 과정을 거쳐 최종 해시 값이 나오게 된다.
해시값 -> 배열 인덱스 변환
해시 값은 매우 큰 정수인데, 배열 크기는 제한적이다.
그래서
HashMap은 배열 크기를 항상 2의 거듭제곱으로 유지하고 다음 공식을 사용한다.
index = hash & (capacity - 1)
ex)
배열 크기: 16 (10000)
capacity - 1 = 15 (01111)
hash = 29 (11101)
11101
& 01111
------
01101 → 13초기 용량과 로드 팩터
HashMap을 생성할 때 두 가지 중요한 값을 설정할 수 있다.
초기 용량(initial capacity): 기본값 16
로드 팩터(load factor): 기본값 0.75
로드 팩터는 배열이 얼마나 차면 리사이징을 할 것인가를 결정한다.
(0.75라면 75% 차면 배열을 확장한다.)
threshold = capacity * loadFactor = 16 * 0.75 = 12
기본 설정에서는 12개의 Entry가 들어가면 리사이징이 발생한다.
0.75인 이유
너무 낮으면 메모리 낭비, 너무 높으면 해시 충돌이 많아져서 성능 저하,
0.75가 가장 균형 잡힌 값이어서 0.75를 사용한다.
HashMap의 초기 용량 16은 비트 연산 최적화, 리사이징 비용, 메모리 사용을 모두 고려한 최소한의 합리적 기본값이다.
해시 충돌
해시 충돌은 서로 다른 키가 같은 버킷에 매핑되는 상황이다.
배열 크기가 16이면 인덱스는 0~15 사이인데, 키는 무한히 많을 수 있다. (당연히 충돌이 발생할 수 있음.)
해시 충돌은 체이닝 방식으로 해결한다.
체이닝
HashMap은 체이닝 방식으로 충돌을 해결한다.
같은 버킷에 여러 개의 Entry가 들어가면 연결 리스트로 연결한다.
bucket[13]: Node(key1) → Node(key2) → Node(key3)
그래서 검색할 때는
- 해시 값으로 버킷 찾고, (O(1))
- 버킷 내의 연결 리스트 순회하며 키 비교한다. (O(체인 길이))
배열 크기가 2의 제곱수인 이유
HashMap의 배열 크기는 항상 2의 제곱수인 이유는 비트 연산 최적화 때문이다.
// 나눗셈 연산 (느림)
index = hash % capacity
// 비트 AND 연산 (빠름, capacity가 2의 제곱수일 때만 가능)
index = hash & (capacity - 1)2의 제곱수에서 1을 빼면 하위 비트가 모두 1이 된다.
16 = 0001 0000
15 = 0000 1111따라서 hash & 15는 hash % 16과 같은 결과를 내지만, 수십 배 빠르다.
동적 리사이징
Entry를 추가할 때마다 size를 1씩 증가시키고, size > threshold가 되면 리사이징이 발생한다. (리사이징은 배열을 2배로 확장함. 16 → 32 → 64 → ..)
리사이징의 비용
리사이징의 시간복잡도는 O(n)이다. (n = Entry 개수).
하지만 자주 일어나지 않는다. 배열이 2배씩 커지므로, n개의 Entry를 넣는 동안 리사이징은 log n번만 일어난다.
-> 분할상환 시간복잡도는 O(1)이다.
리사이징 최적화: 비트 트릭
리사이징할 때 모든 Entry의 해시를 다시 계산할 필요는 없다.
배열 크기가 2배가 되면, 각 Entry는 아래 두 위치 중 하나로만 갈 수 있다.
- 원래 인덱스
- 원래 인덱스 + 구 배열 크기
ex) 16 → 32로 확장할 때 인덱스 13의 Entry들은
- 13으로 유지
- 또는 13 + 16 = 29로 이동
if ((hash & oldCapacity) == 0) {
// 인덱스 유지
} else {
// 인덱스 + oldCapacity
}이 비트 트릭 덕분에 리사이징이 매우 빠르다.
초기 용량을 미리 설정하는 이유
만약 100,000개의 Entry를 넣을 것을 안다면, 초기 용량을 설정하는 것이 좋다.
int expectedSize = 100000;
int capacity = (int) (expectedSize / 0.75 + 1);
Map<String, Integer> map = new HashMap<>(capacity);이렇게 하면 리사이징이 발생하지 않아서 50% 정도 빠르다.
트리화
해시 충돌 공격
Java 7까지 HashMap의 최악의 경우 시간복잡도는 O(n)이었다.
만약 악의적으로 같은 버킷에 모든 Entry가 들어가도록 키를 만들면
// 모든 객체가 같은 해시 값을 반환
public int hashCode() {
return 0; // 모두 0번 버킷으로!
}이렇게 되면 하나의 버킷에 n개의 Entry가 연결 리스트로 매달리고, 검색 시간은 O(n)이 된다.
(실제로 이런 방식의 DoS 공격이 가능했음)
해결책: 레드-블랙 트리
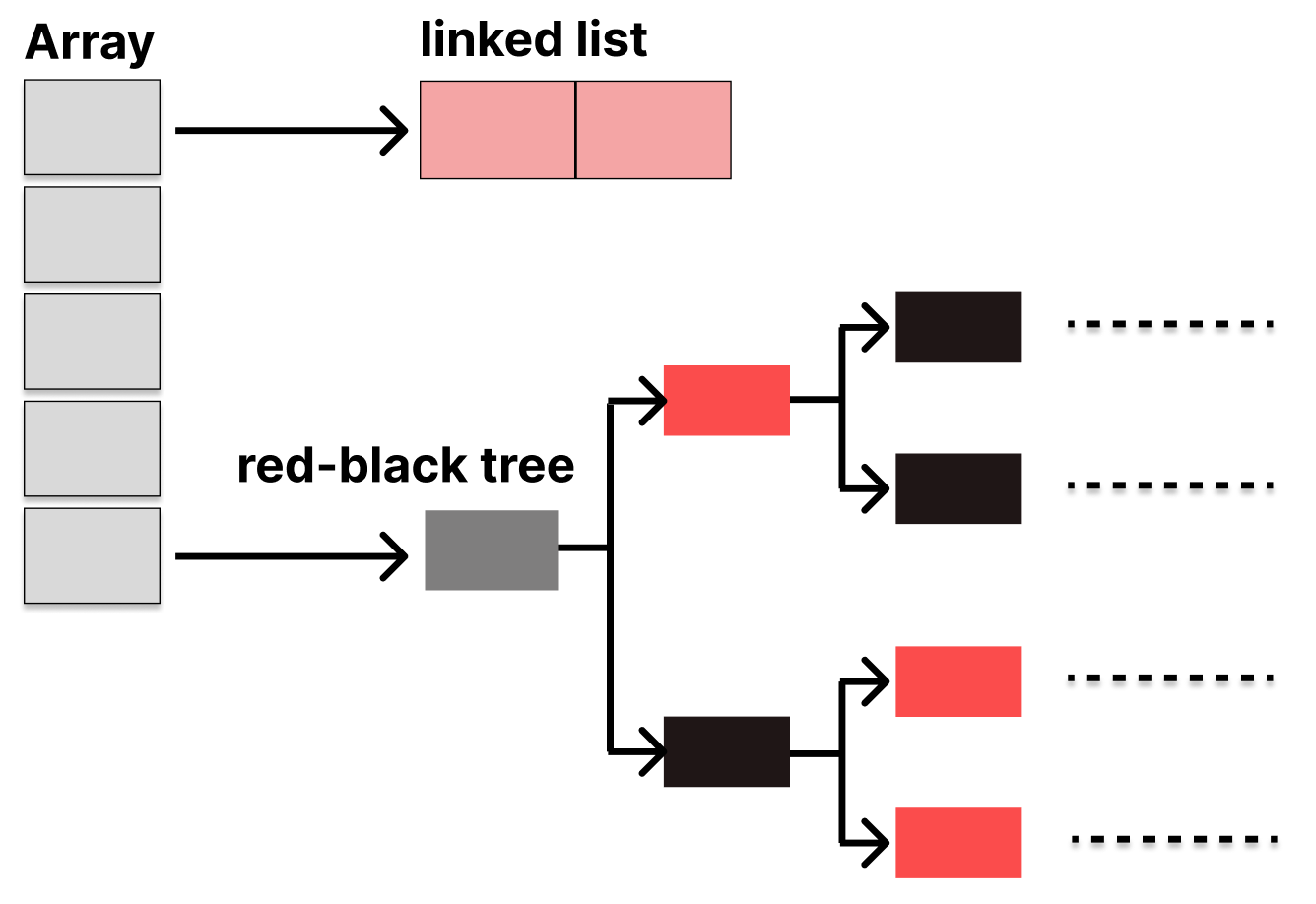
Java 8부터는 버킷의 체인 길이가 8 이상이 되면, 연결 리스트를 레드-블랙 트리로 변환한다.
레드-블랙 트리는 균형 이진 탐색 트리로, 검색 시간이 O(log n)이다.
따라서
Java 7: 최악의 경우 O(n)
Java 8이후: 최악의 경우 O(log n)
트리화 조건
트리화는 아래 두 조건을 모두 만족해야 발생한다.
- 버킷의 Entry 개수 ≥ 8
- 전체 배열 크기 ≥ 64
배열이 작을 때는 트리화 대신 리사이징을 한다. 왜냐하면, 배열을 키우면 Entry들이 분산되어 자연스럽게 충돌이 줄어들기 때문이다.
8개가 기준인 이유
로드 팩터가 0.75일 때, 무작위 해시 함수로 한 버킷에 8개 이상의 Entry가 들어갈 확률은 P(X ≥ 8) ≈ 0.00000006 이렇다.
-> 거의 안 일어남
레드-블랙 트리인 이유
균형 이진 탐색 트리로는 AVL 트리도 있는데, 왜 레드-블랙 트리???
- AVL 트리: 완벽한 균형, 검색이 약간 빠름, 삽입/삭제 시 회전이 많다.
- 레드-블랙 트리: 느슨한 균형, 검색이 약간 느림, 삽입/삭제 시 회전이 적다.
HashMap은 삽입/삭제가 빈번하니까, 레드-블랙 트리가 더 적합하다.
트리 → 리스트 복원
트리화된 버킷은 Entry가 6개 이하로 줄어들면 다시 연결 리스트로 돌아간다.
6개인 이유는 8개에서 트리화하고 8개에서 복원하면, 7-8 사이를 왔다갔다하면서 계속 변환이 일어날 수 있다.
-> 이를 방지하기 위한 히스테리시스(hysteresis) 효과이다.
주요 메서드 시간복잡도
| 메서드 | 평균 | 최악 (Java 7) | 최악 (Java 8+) |
|---|---|---|---|
put(K, V) | O(1) | O(n) | O(log n) |
get(Object) | O(1) | O(n) | O(log n) |
remove(Object) | O(1) | O(n) | O(log n) |
containsKey(Object) | O(1) | O(n) | O(log n) |
containsValue(Object) | O(n) | O(n) | O(n) |
size() | O(1) | O(1) | O(1) |
clear() | O(n) | O(n) | O(n) |
containsKey는 해시를 통해 바로 버킷을 찾을 수 있지만, containsValue는 모든 버킷을 순회해야 한다.
따라서 값으로 검색해야 한다면 HashMap은 적합하지 않고, 이런 경우에는 양방향 맵을 고려해야 한다. (Guava의 BiMap 등)
참고 자료
https://medium.com/codex/understanding-hashmap-in-java-4bb2f839adea
https://medium.com/%40hxu0407/how-hashmap-works-in-java-why-thresholds-are-8-and-64-9b2f78d369a4
