
개요
이전 포스팅에서 Java8 에서 등장한 람다에 대해서 배워 보았고, 람다식을 대폭적용시킨 Stream API 에 대해 공부해보았습니다. Stream API는 Collection을 Pipe 구조를 통해 데이터를 처리하고, 기존에 여러 줄로 처리해야하는 로직을 간편한 코드 형식으로 구현할 수 있게끔(가독성 향상) 해주었습니다. 또한 병렬 연산(Parallel Method)까지 지원하였는데요. 병렬 연산을 지원하는 Parallel() 메서드는 Thread Pool 을 공유하여 사용되어지기 때문에 성능장애를 야기할 수 있기 때문에 이를 인지하고 사용하는 것이 중요한데요. 이번 포스팅에선 병렬 데이터 처리와 성능에 대해서 학습해보는 시간을 가져보도록 하겠습니다 😄
0. Stream 병렬 데이터 처리
0-1) Parallel 연산 : Pre Java 8 vs Post Java 8
Java 8 이전의 병렬처리 방식으로 Thread를 생성하여 하는 방식과 ExecutorService 를 사용하는 방식이 있었는데, 주로 사용하는 ExecutorService로 예시 코드를 작성해보겠습니다.
Java 8 이전 코드
List<Integer> numList = Arrays.asList(new Integer[]{1,2,3,4,5,6,7,8,9,10,11,12});
ExecutorService executor = Executors.newFixedThreadPool(4);
for (int i = 0; i < numList.size(); i++) {
final int index = i;
executor.submit(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()
+ ", index=" + index + ", ended at " + new Date());
});
}
executor.shutdown();결과
pool-1-thread-1, index=0, ended at Mon Aug 23 16:39:50 KST 2021
pool-1-thread-3, index=2, ended at Mon Aug 23 16:39:50 KST 2021
pool-1-thread-4, index=3, ended at Mon Aug 23 16:39:50 KST 2021
pool-1-thread-2, index=1, ended at Mon Aug 23 16:39:50 KST 2021
pool-1-thread-2, index=6, ended at Mon Aug 23 16:39:56 KST 2021
pool-1-thread-3, index=4, ended at Mon Aug 23 16:39:56 KST 2021
pool-1-thread-4, index=5, ended at Mon Aug 23 16:39:56 KST 2021
pool-1-thread-1, index=7, ended at Mon Aug 23 16:39:56 KST 2021
pool-1-thread-4, index=10, ended at Mon Aug 23 16:40:01 KST 2021
pool-1-thread-3, index=9, ended at Mon Aug 23 16:40:01 KST 2021
pool-1-thread-2, index=8, ended at Mon Aug 23 16:40:01 KST 2021
pool-1-thread-1, index=11, ended at Mon Aug 23 16:40:01 KST 202112개의 데이터가 들어가있는 리스트에 대해서 for문을 Thread 4개를 이용하여 수행하였습니다.
Java 8 이후 코드
List<Integer> numList = Arrays.asList(new Integer[]{1,2,3,4,5,6,7,8,9,10,11,12});
numList.parallelStream().forEach(index -> {
System.out.println("Starting " + Thread.currentThread().getName()
+ ", index=" + index + ", " + new Date());
try {
Thread.sleep(5000);
} catch (InterruptedException e) { }
});결과
Starting ForkJoinPool.commonPool-worker-15, index=10, Mon Aug 23 17:22:50 KST 2021
Starting main, index=8, Mon Aug 23 17:22:50 KST 2021
Starting ForkJoinPool.commonPool-worker-11, index=2, Mon Aug 23 17:22:50 KST 2021
Starting ForkJoinPool.commonPool-worker-7, index=7, Mon Aug 23 17:22:50 KST 2021
Starting ForkJoinPool.commonPool-worker-5, index=11, Mon Aug 23 17:22:50 KST 2021
Starting ForkJoinPool.commonPool-worker-9, index=9, Mon Aug 23 17:22:50 KST 2021
Starting ForkJoinPool.commonPool-worker-3, index=4, Mon Aug 23 17:22:50 KST 2021
Starting ForkJoinPool.commonPool-worker-13, index=6, Mon Aug 23 17:22:50 KST 2021
Starting ForkJoinPool.commonPool-worker-15, index=12, Mon Aug 23 17:22:55 KST 2021
Starting ForkJoinPool.commonPool-worker-9, index=5, Mon Aug 23 17:22:55 KST 2021
Starting ForkJoinPool.commonPool-worker-7, index=1, Mon Aug 23 17:22:55 KST 2021
Starting ForkJoinPool.commonPool-worker-3, index=3, Mon Aug 23 17:22:55 KST 2021결과는 메인 스레드를 포함해서 모두 8개의 스레드가 실행됨을 확인할 수 있었습니다.
8개의 스레드가 사용된 이유는 다음과 같습니다.
Parallel Stream 은 내부적으로 Common fork join pool 을 사용하는데, fork-join pool 은 1 프로세서 당 1 스레드를 사용하도록 설계되어 있기 때문입니다.
필자의 실행환경은 m1 8코어 칩이기 때문에, 8개의 스레드가 생성되어 동작되는 것을 확인할 수 있었습니다.
0-2) Thread 크기 제어 : Pre Java 8 vs Post Java 8
Java 8이전의 병렬 처리 방식인 ExecutorService의 Thread 크기의 제어 방식은 아래와 같았습니다.
Java 8 이전 코드
ExecutorService executor = Executors.newFixedThreadPool(5);Java 8 이후의 Parallel Stream에서 개발자가 Thread의 크기를 제어할 수 있는 방법은 2가지가 있습니다.
- System property 설정
Java 8 이후 코드
1.Property 값 설정
java.util.concurrent.ForkJoinPool.common.parallelism 의 property 값을 6으로 설정해보도록 하겠습니다.
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","6");결과
Starting ForkJoinPool.commonPool-worker-5, index=4, Mon Aug 23 17:30:15 KST 2021
Starting ForkJoinPool.commonPool-worker-9, index=9, Mon Aug 23 17:30:15 KST 2021
Starting ForkJoinPool.commonPool-worker-3, index=11, Mon Aug 23 17:30:15 KST 2021
Starting ForkJoinPool.commonPool-worker-13, index=12, Mon Aug 23 17:30:15 KST 2021
Starting ForkJoinPool.commonPool-worker-11, index=10, Mon Aug 23 17:30:15 KST 2021
Starting ForkJoinPool.commonPool-worker-7, index=7, Mon Aug 23 17:30:15 KST 2021
Starting main, index=8, Mon Aug 23 17:30:15 KST 2021
Starting ForkJoinPool.commonPool-worker-13, index=6, Mon Aug 23 17:30:20 KST 2021
Starting ForkJoinPool.commonPool-worker-11, index=5, Mon Aug 23 17:30:20 KST 2021
Starting ForkJoinPool.commonPool-worker-9, index=2, Mon Aug 23 17:30:20 KST 2021
Starting ForkJoinPool.commonPool-worker-3, index=1, Mon Aug 23 17:30:20 KST 2021
Starting ForkJoinPool.commonPool-worker-5, index=3, Mon Aug 23 17:30:20 KST 2021main Thread를 포함해 6개의 스레드가 동작하는 것을 확인할 수 있습니다.
2.ForkJoinPool 사용
ForkJoinPool을 생성할 때 스레드의 크기 값을 입력하여 스레드의 크기를 5로 설정하여 실습을 진행해 보았습니다.
List<Integer> numList = Arrays.asList(new Integer[]{1,2,3,4,5,6,7,8,9,10,11,12});
ForkJoinPool forkjoinPool = new ForkJoinPool(5);
forkjoinPool.submit(() -> {
numList.parallelStream().forEach(index -> {
System.out.println("Thread : " + Thread.currentThread().getName()
+ ", index + " + new Date());
try{
Thread.sleep(5000);
} catch (InterruptedException e){
}
});
}).get();결과
Thread : ForkJoinPool-1-worker-7, index + Mon Aug 23 17:34:23 KST 2021
Thread : ForkJoinPool-1-worker-11, index + Mon Aug 23 17:34:23 KST 2021
Thread : ForkJoinPool-1-worker-5, index + Mon Aug 23 17:34:23 KST 2021
Thread : ForkJoinPool-1-worker-3, index + Mon Aug 23 17:34:23 KST 2021
Thread : ForkJoinPool-1-worker-9, index + Mon Aug 23 17:34:23 KST 2021
Thread : ForkJoinPool-1-worker-3, index + Mon Aug 23 17:34:29 KST 2021
Thread : ForkJoinPool-1-worker-7, index + Mon Aug 23 17:34:29 KST 2021
Thread : ForkJoinPool-1-worker-9, index + Mon Aug 23 17:34:29 KST 2021
Thread : ForkJoinPool-1-worker-5, index + Mon Aug 23 17:34:29 KST 2021
Thread : ForkJoinPool-1-worker-11, index + Mon Aug 23 17:34:29 KST 2021
Thread : ForkJoinPool-1-worker-11, index + Mon Aug 23 17:34:34 KST 2021
Thread : ForkJoinPool-1-worker-7, index + Mon Aug 23 17:34:34 KST 20211. ForkJoinPool의 동작 방식
Parallel Stream 에서 사용되는 ForkJoinPool은 Java 7 에서 등장하였고, fork를 통해 수행해야할 Task를 분할하고, 분할된 Task의 결과를 join 을 통해 합치는 방식으로 동작합니다. 밑에 그림을 보게 되면 분할-정복 알고리즘 방식과 비슷하게 동작하는 ForkJoinPool의 모습을 확인할 수 있습니다.
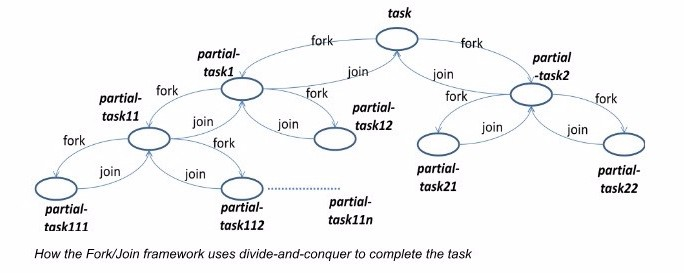
ForkJoinPool.class 동작방식
밑의 코드에서 알 수 있다시피, ForkJoinPool은 AbstractExecutorService에 대한 구현체입니다.

ForkJoinPool.class
ForkJoinPool은 스레드마다 개별 큐(Queue)를 가지며, 만약 하나의 스레드가 가진 Task가 없으면, Task가 있는 스레드의 Task를 가져와 처리하여 CPU 자원의 낭비를 줄이고 성능을 향상시켰습니다.

ForkJoinPool Thread 동작 방식
2. 병렬 연산시 고려 사항
병렬 연산을 수행하기 위해선 고려해야 할 점이 많습니다.
크게 2가지 고려 사항에 대해서 다뤄보도록 하겠습니다.
2-1) ForkJoinPool을 통해 Task를 나누는 비용이 작아야 합니다.
Parallel Stream 은 Task를 분할 하기 위해 Spliterator<T> trySplit() 를 사용하는데 , 이 메서드를 통해 분할되어지는 데이터의 구조가 분할에 대한 비용을 적게 발생시켜야 병렬 연산에 대한 효과를 찾아볼 수 있습니다.
Spliterator trySplit() 메서드
public Spliterator<T> trySplit() {
int lo = index, mid = (lo + fence) >>> 1;
return (lo >= mid)
? null
: new ArraySpliterator<>(array,
lo, index = mid,
characteristics);
}예를 들어, 분할되어지는 데이터 구조가 LinkedList 인 것 보다, Array, ArrayList 일 경우 분할에 대한 비용을 줄일 수 있고 병렬 연산에 대한 효과를 볼 확률이 높습니다.
2-2) 병렬로 처리 되는 작업이 독립적이어야 합니다.
이 점은 수행 성능에서 속도 뿐만 아니라 정확도에서도 성능 장애를 야기할 수 있습니다. 예를 들어, Stream의 중간 연산인 sorted(), distinct() 메서드를 수행하게 되면 스레드 간 변수를 공유(Synchronized) 하기 때문에 정확한 결과 값을 도출하지 못할 수 있습니다. 즉, 스레드가 여러 개일 경우엔 가변 객체에 대한 접근은 하지 않는 것이 좋은데요, 이 점은 요 포스팅(:Java에서의 Multi-Thread 환경 개발) 을 확인해보시면 좋을 것 같습니다.🤭
3. 병렬 연산을 사용해야 할 때
위에서 말한 2가지 조건을 빌리면,
- Task를 나누는 작업에 대한 비용이 적어야 한다.
- 병렬로 처리 되는 작업이 독립적으로 수행되어야 한다.
이럴 경우 병렬 연산에 대해서 이점을 챙길 수 있을 것입니다. 하지만 이 경우 외에도 다양한 병렬 연산 시 고려사항들이 많으니, 만약 병렬 연산을 사용할 때는 여러 고려 사항을 짚어보고 사용하는 것이 좋을 것입니다.
예제 코드
static int cnt = 0;
public static void main(String[] args) throws ExecutionException, InterruptedException {
List<Integer> numList = Arrays.asList(new Integer[]{1,2,3,4,5,6});
ForkJoinPool forkjoinPool = new ForkJoinPool(3);
forkjoinPool.submit(() -> {
numList.parallelStream().forEach((index) -> {
for (int i = 0; i < 10000; i++) {
cnt++;
}
});
}).get();
System.out.println(cnt);
}
Thread 3개를 통해 numList의 데이터의 요소의 갯수 만큼 전역 변수인 cnt의 값을 증가시켜 마지막에 출력하는 코드를 작성해보았습니다.
결과
53631스레드가 싱글 스레드일 경우엔 정상적으로 60000이 출력하는 반면에, 스레드가 3개일 경우에는 다음과 같이 정확하지 않은 결과가 출력되어지는 것을 확인할 수 있었습니다.
4. 회고
Parallel 연산에 대해서 당연히 Parallel하게(병렬적으로) 하는 것이 성능이 좋은 거 아니야? 라고 생각했었던 내게 꿀밤을 놔준 학습이었던 것 같습니다. 🤨
개인적으로 느꼈던 점은 그냥 데이터가 많지 않을 땐 지양하자..
그리고 굳이 사용해본다하면 꼭 실행 속도 테스트를 하고 사용해보자.. 등 이었던 것 같습니다. 그래도 당연시 여겼던 개념에 대한 비판적인?! 고찰을 하게되어 좋았던 것 같습니다 ☺️
