참고 링크
-
https://jakevdp.github.io/PythonDataScienceHandbook/01.07-timing-and-profiling.html
-
https://j0e1in.github.io/dev_notes/ml/tools/jupyter-tips.html#magics
-
https://i10x.notion.site/Python-Memory-Exec-Time-Profiler-dfab9d62dba24b3ea9ba3d83f6539781
메모리 및 시간 프로파일링
conda install memory_profiler
conda install line_profiler%%file mprun_all.py
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import MinMaxScaler
from surprise import NMF, SVDpp, SVD
from surprise import Dataset
from surprise import Reader
from surprise.model_selection import train_test_split
from surprise import accuracy
from surprise.model_selection import GridSearchCV, RandomizedSearchCV
from sklearn.metrics import confusion_matrix, precision_score, recall_score,classification_report, f1_score
def fit():
ratings = pd.read_csv('r.csv')
ratings = ratings[['user_id','product_id','rating']]
rating_0=ratings[ratings['rating']==0].index
ratings=ratings.drop(rating_0)
scaler = MinMaxScaler()
scaled = scaler.fit_transform(ratings['rating'].values.reshape(-1,1))
ratings.insert(0, 'scaled', scaled)
ratings.drop(['rating'], axis=1, inplace=True)
ratings=ratings[["user_id",'product_id','scaled']]
ratings.rename(columns={'scaled':'rating'}, inplace=True)
reader = Reader(rating_scale=(0.0, 1.0))
# load_from_df사용해서 데이터프레임을 데이터셋으로 로드
# 인자에 userid-itemid-ratings 변수들이 포함된 데이터프레임형태로 넣어주면 됨!
data = Dataset.load_from_df(ratings[['user_id','product_id','rating']],
reader=reader)
train, test = train_test_split(data, test_size=0.25, random_state=42)
param_distributions = {'n_factors': list(range(10,110,2)),'reg_pu': np.arange(0.01,0.2,0.01),'reg_qi': np.arange(0.01,0.2,0.01), 'n_epochs' : list(range(1,51))}
rs = RandomizedSearchCV(NMF, param_distributions, measures=['rmse'], return_train_measures = True, cv = 5, n_iter = 20)
rs.fit(data)
a= rs.best_params['rmse']
b=list(a.values())
print(rs.best_params['rmse'])
# tuned_model = SVD(n_factors=18, reg_pu = 0.01, reg_qi = 0.11, n_epochs = 26, random_state = 42)
tuned_model = NMF(n_factors= b[0], reg_pu= b[1], reg_qi= b[2], n_epochs=b[3], random_state = 42)
tuned_model.fit(train)
train_predictions = tuned_model.test(train.build_testset())
test_predictions = tuned_model.test(test)
print("RMSE on training data : ", accuracy.rmse(train_predictions, verbose = False))
print("RMSE on test data: ", accuracy.rmse(test_predictions, verbose = False))
print("RMSE on training data : ", accuracy.mae(train_predictions, verbose = False))
print("RMSE on test data: ", accuracy.mae(test_predictions, verbose = False))
%load_ext memory_profiler
from mprun_all import fit
%mprun -f fit fit()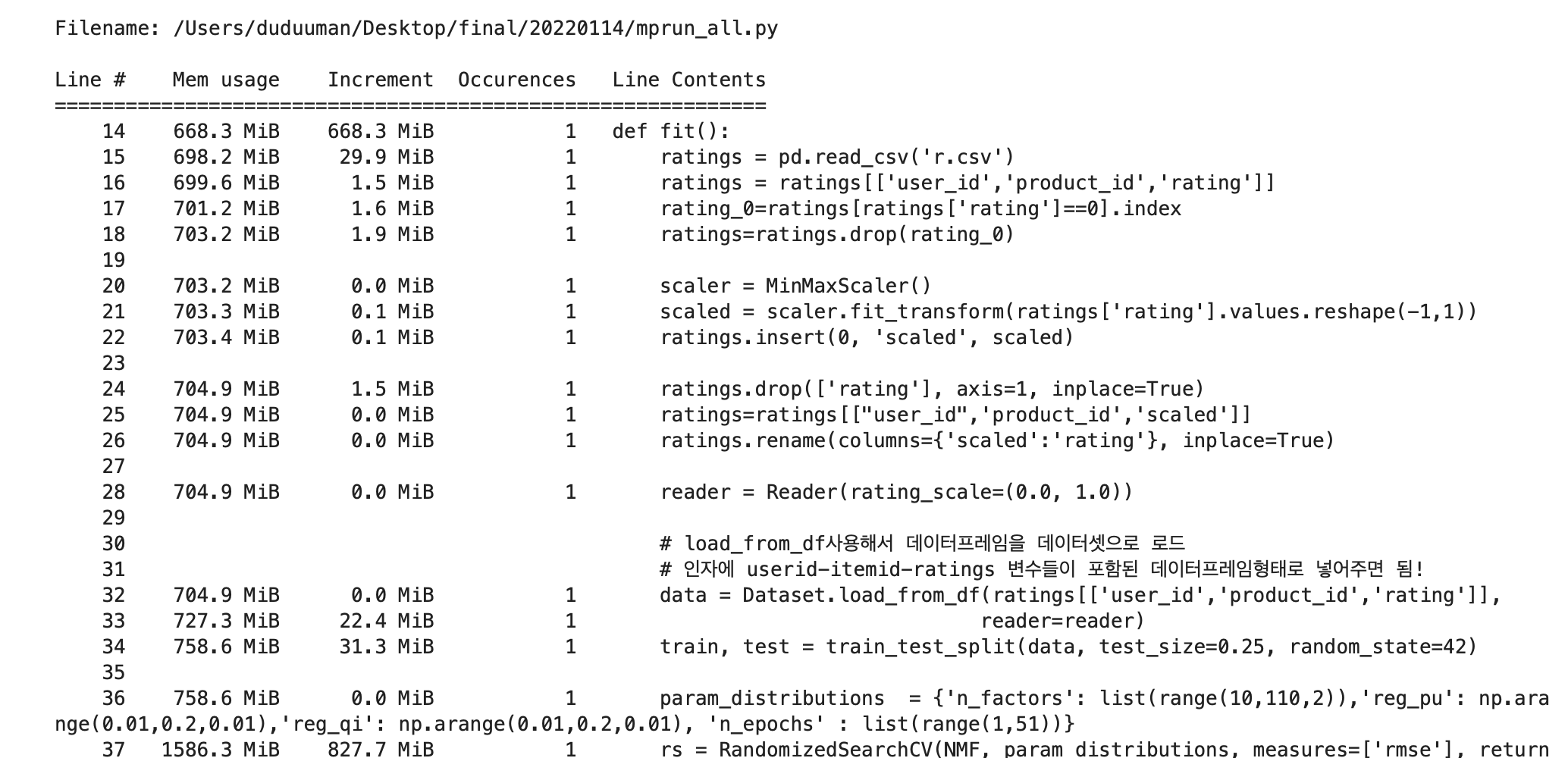
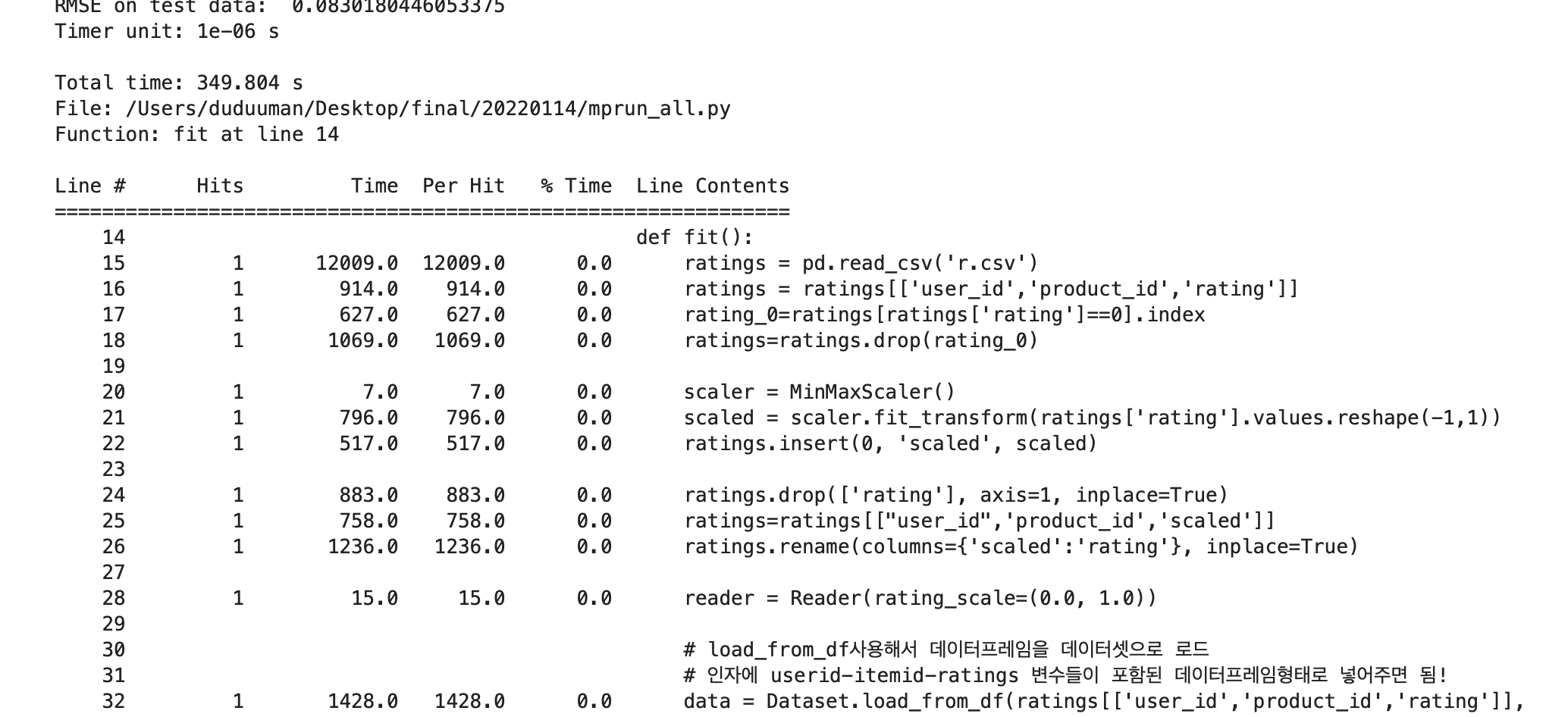
%load_ext line_profiler
%lprun -f fit fit()