Summary
CFG가 나온 배경
Classifier Guidance에서는 Noisy Image로 학습한 Classifier의 gradient를 사용함.
효과적으로 Class Guidance를 할 수는 있었지만, 추가로 Classifier를 학습해야한다는 단점 존재.
또한 FID와 IS를 의도적으로 증가시키기 위한 gradient-based adverarial attack 이기도 함.
그래서 저자들은 별도의 Classifier 없이 한 번에 Class Guidance를 할 수 있는 방법 제안.
CFG 간단 설명
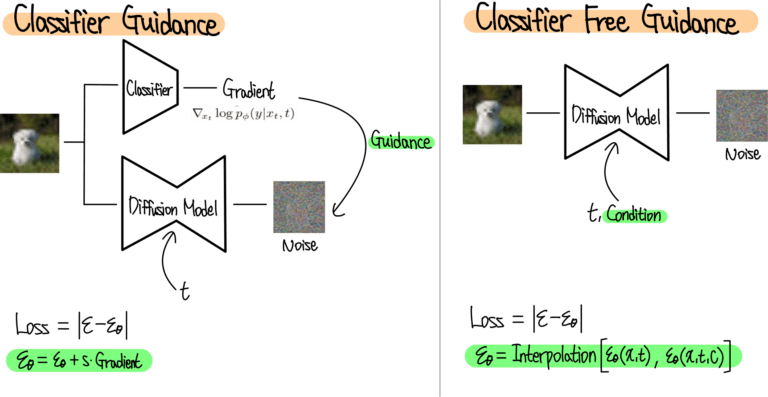
-
Classifier Guidance
Noisy Image를 학습한 Classfier로부터 gradient를 계산함.
이 gradient를 사용하여 Diffusion model이 원하는 class에 도달하도록 함. -
Classifier Free Guidance
Classifier 자체를 사용하지 않고, Class에 해당하는 Condition 정보를 forward process 정보인 t와 함께 diffusion model에 줌.
받은 정보를 통해 Diffusion Model은 Condition을 받았을 때와 받지 않았을 때 두 가지의 Noise를 예측함. 이 두 Noise의 interpolation을 통해 최종 예측 Noise를 계산함.
classifieer free guidance 수식
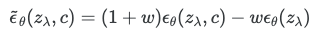
w에 따른 결과 변화. w(guidance strength)가 커질 수록 특정한 class의 이미지만 생성함을 볼 수 있음.

Discussion
- CFG의 가장 실용적인 점은 매우 단순하다는 것. 학습과 샘플링을 위해 코드를 한 줄만 변경하면 됨.
- 추가 훈련된 classifier 없이 IS와 FID를 절충할 수 있기 때문에, pure generative model로 guide할 수 있음.
- gudiance가 작동하는 방식을 conditional likelihood를 높이면서 샘플의 unconditional likelihood를 줄이는 것으로 직관적인 설명이 가능.
- 단점은, 샘플링 속도에 있음. CFG의 경우 conditional score용과 unconditional score용으로 두가지 forward pass를 실행해야하므로, 더 느릴 수 있음.
Guidance
GAN의 경우, 샘플링 시에 분산이나 입력 noise의 범위를 줄여 truncated sampling이나 low temperature sampling을 수행. 이 방법들은 샘플의 다양성을 줄이면서 각 샘플의 품질을 높임. 하지만, diffusion model의 경우 이러한 방법들이 효과적이지 않음.
why?
1. 생성 과정의 차이:
GAN은 한 번의 forward pass로 latent space에서 직접 이미지를 생성함. 따라서 입력 노이즈의 분포를 조절하면 출력 이미지의 특성을 직접적으로 제어할 수 있음.
반면 diffusion 모델은 점진적인 노이즈 제거 과정을 통해 이미지를 생성함. 각 단계에서 모델은 이전 결과를 기반으로 노이즈를 제거함. 이에 입력 노이즈를 조절하는게 큰 영향을 끼치지 않을 수 있음.
2. 잠재 공간의 특성:
Diffusion 모델의 latent space는 GAN에 비해 더 복잡하고 시간에 따라 변화함. 이로 인해 단순한 truncation이나 temperature 조절이 효과적이지 않을 수 있음.
3. 학습 목표의 차이:
GAN은 실제 데이터 분포와 유사한 분포를 생성하는 것이 목표. Diffusion 모델은 likelihood를 최대화하는 방향으로 학습되어 전체 데이터를 더 잘 포착함. 따라서 단순히 샘플링 과정을 조절하는 것만으로는 품질 향상이 제한적일 수 있음.
1. Classifier guidance
Diffusion models beat GANs on image synthesis(classifier diffusion)에서는 Truncated sampling과 비슷한 효과를 얻기 위해 classifier guidance를 제안함.
별도의 Classifier 모델 의 log-likelihood의 기울기를 diffusion score 에 다음과 같이 추가한다.
여기서의 는 classifier guidance의 강도를 조절하는 파라미터. 샘플링 할 때 대신 를 사용함. 이는 결과적으로
에서 샘플링하는 것과 동일. classifier가 알맞은 레이블에 높은 likelihood를 할당하도록 가중치를 높게 조정. 으로 설정하면, 다양성은 감소하지만 IS가 개선.

위 그림은 class가 3개인 샘플에 대한 guidance의 효과. 오른쪽으로 갈수록 guidance의 강도가 세짐.
2. Classifier-Free Guidance
diffusion score인 를 수정하여, classifier없이 classifier guidance와 같은 효과를 얻는 방법.

- 학습:
별도의 classifier를 학습시키는 대신, 로 parameterize된 unconditional model 와 로 parameterize된 conditional model 를 함께 학습시킴. 두 모델을 따로 두는 것이 아니라, unconditional model의 경우 null token()를 c에 대입하는 방식. 즉, . 학습 시에는 의 확률로 c가 가 됨.
- 샘플링:
