안녕하세요, :)입니다.
이번 포스팅은 제가 1학년 2학기 AI Capstone 수업에서 Whatflix팀으로 만들었던 영화 추천 시스템 (간단하게 '추시'라고 하겠습니다)에 대해 다뤄보도록 하겠습니다.
모든 수업이 영어로 이뤄졌기 때문에, 단기간에 공들인 작품인 만큼 머릿속에서도 빠르게 떠나갈까봐.. 급하게 한글로 정리하려 합니다 ㅎㅎ 이 수업을 맡아주셨던 (지금은 떠나신) Benjamin Weiss 교수님이 갑자기 생각나네요. 제가 첫날 grading에서 점수를 좀 못받아서 이의제기를 하면서 정확한 피드백을 부탁드렸는데, 저렇게 장문으로 써주셔서 "아 진짜 합리적으로 채점하려고 노력하셨구나"라는걸 느꼈던 기억이 있네요.
이 수업을 맡아주셨던 (지금은 떠나신) Benjamin Weiss 교수님이 갑자기 생각나네요. 제가 첫날 grading에서 점수를 좀 못받아서 이의제기를 하면서 정확한 피드백을 부탁드렸는데, 저렇게 장문으로 써주셔서 "아 진짜 합리적으로 채점하려고 노력하셨구나"라는걸 느꼈던 기억이 있네요. 교수님 안녕 ㅠㅠ
(어릴 때부터 점수에 크게 연연하지 않아서 이의제기같은건 안해봤는데, 완벽하다고 생각했는데 이유없이 깎이면 기분 나쁘잖아요 ㅎㅎ 그래서 피드백도 얻을 겸 굉장히 정중하게 보냈답니다)
Schema
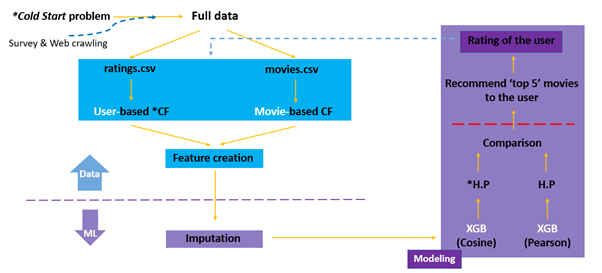
Step을 조금 간소화시키면 이렇습니다.
- Cold Start의 해결
- Collaborative Filters 구성
- ML Stages
사실 Collaborative Filtering이라는 것이 생소하실텐데, 추시에서는 꽤나 보편적인 기술입니다. 그래서 저희 추시의 uniqueness를 자랑하기 위함이 아니라, 업계에서 AI를 이용해서 보통 추시를 어떻게 구성하는가에 대한 흐름을 보여드리기 위해 작성하는 포스트라고 이해하시면 되겠습니다.
GANTT Chart
 Details는 모두 생략한 schedule이라고 보시면 됩니다! 약 3주 동안 진행했네요.
Details는 모두 생략한 schedule이라고 보시면 됩니다! 약 3주 동안 진행했네요.
Cold Start의 해결
Cold Start Problem
Wikipedia에서는 cold start를 이렇게 정의하고 있습니다.

쉽게 말해서, '이용자에 대한 데이터가 충분하지 않아서 추천에 여러움을 겪에 되는 문제'를 일컫는 용어입니다.
물론 movielens 데이터가 주어져서 굳이 다루지 않아도 되는 문제였으나, 저는 real world application을 굉장히 중시하는 편이기 때문에 :)
Solution 1
이에 대한 해결책으로 boxofficemojo.com에서 20년간 월별 Top 10 영화를 crawling해서 우선 추천하는 방법을 제시했습니다.
Codes
import pandas as pd
from requests import get
from bs4 import BeautifulSoup as Soup
months = ['january', 'february', 'march', 'april', 'may', 'june', 'july', 'august', 'september', 'october', 'november', 'december']
years = [ "{}".format(i) for i in range(2000,2021) ]
rankings = []
for i in years:
for j in months:
url = get("https://www.boxofficemojo.com/month/{}/{}/?ref_=bo_ml_table_1".format(j,i))
request = url.text
soup_data = Soup(request, 'html.parser')
movie_container = soup_data.find('div', {'class':'a-section imdb-scroll-table-inner'})
rankings.append([movie_name_container.get_text() for movie_name_container in movie_container.findAll('td', {'class':'a-text-left mojo-field-type-release mojo-cell-wide'})])
rankings = list(map(pd.Series, rankings))
box_office = pd.concat([rankings[i][0:10] for i in range(len(months)*len(years))] , axis=1)
box_office.set_index(pd.Index([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]), inplace = True)
index_list = ["{} {}".format(j, i) for i in years for j in months]
box_office.columns = index_list
box_office.to_csv('box_office.csv')Solution 2
Fast-survey를 진행하는 것으로 빠르게 personalize를 위한 정보를 모을 수 있도록 했습니다.
Fast-survey의 질문 내용은 대략,
- 가장 재밌었던 영화 3개
- 가장 좋아하는 장르 2개
- 좋아하는 영화 배우
등으로 구성함으로써 초기 추천을 효율적으로 진행할 수 있도록 구상했습니다.
Collaborative Filters 구성
Wikipedia에서는 Collaborative Filtering (이하 CF)를 이렇게 정의하고 있습니다.
 쉽게 말해서, '이용자들의 취향 및 선호도를 분석하여 예측'하는 것입니다!
쉽게 말해서, '이용자들의 취향 및 선호도를 분석하여 예측'하는 것입니다!
(사실 CF는 추시에서 main idea이면서도 가장 직관적으로 이해하기 쉬운 파트라고 생각해요)
User-Based CF
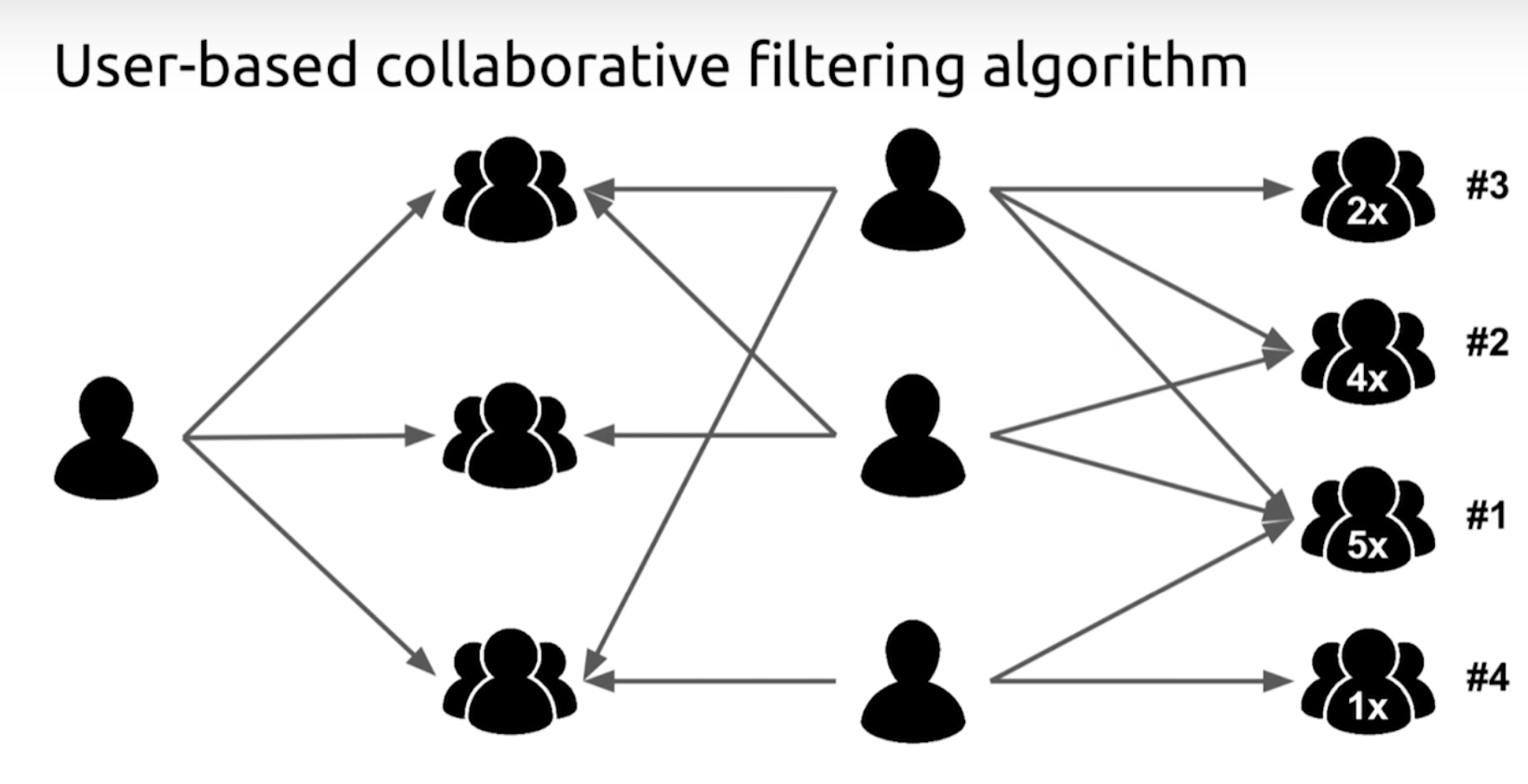
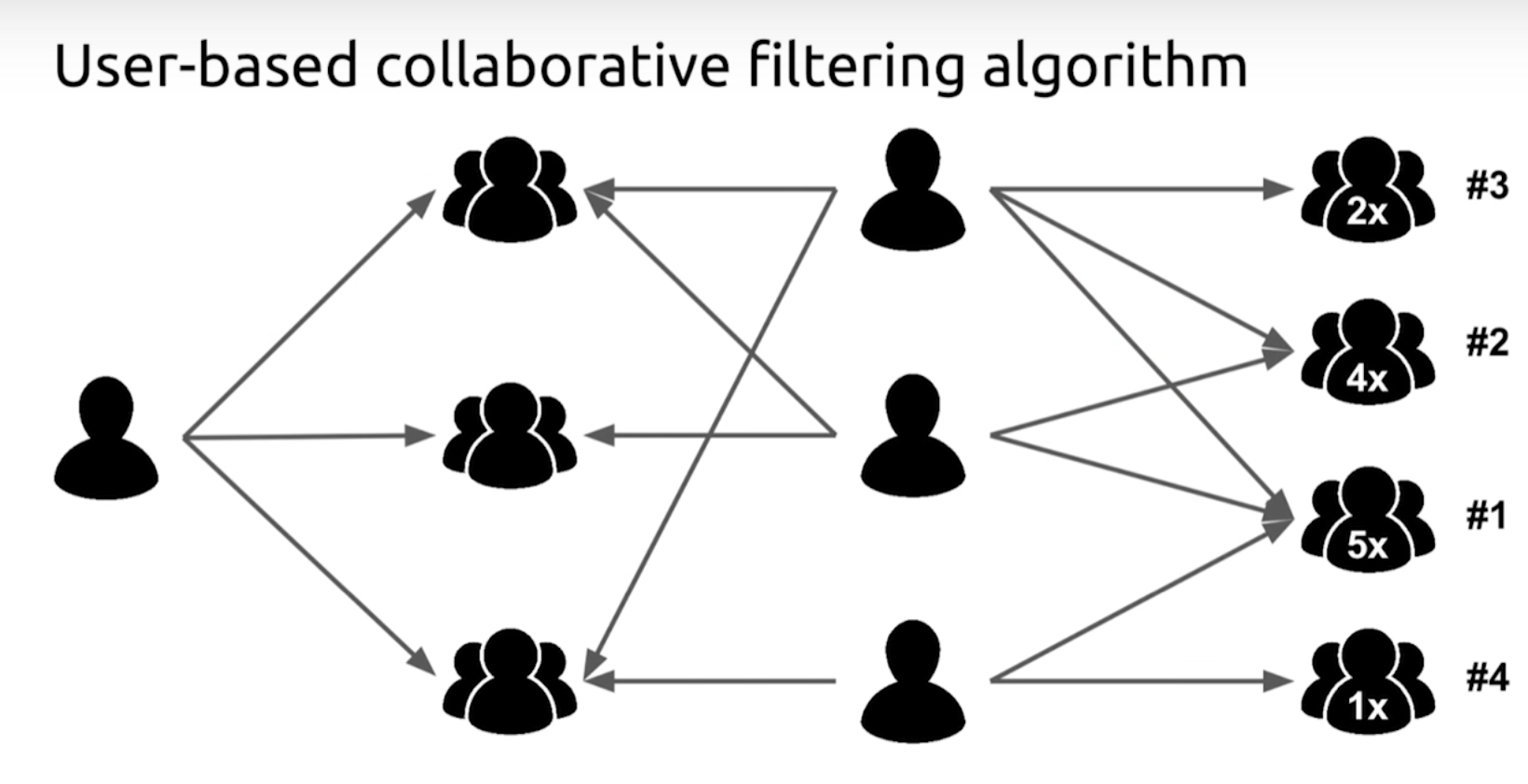
User-Based라는 말 그대로 비슷한 User간 분석을 통한 CF입니다.
CF가 처음이신 분들을 위해, 아주 쉬운 예시를 들겠습니다.
A라는 사람이 다음 영화에 대해서 이런 식으로 rating했다고 가정합시다.
A : 어벤져스 - 4.0
아바타 - 3.5
겨울왕국 - 4.5
해리포터 - 1.5
반지의 제왕 - 2.5
이제 A에게 다른 영화를 추천해야 하는데요, User-Based CF에서는 A와 비슷한 이용자를 참고할 생각입니다.
B : 어벤져스 - 4.5
아바타 - 3.5
겨울왕국 - 3.5
해리포터 - 2.0
반지의 제왕 - 2.5
반 헬싱 - 4.5
트와일라잇 - 3.0
...
B는 이미 이렇게 rating 했구요,
C : 어벤져스 - 3.5
아바타 - 2.5
겨울왕국 - 3.5
해리포터 - 4.0
반지의 제왕 - 3.5
반 헬싱 - 4.0
트와일라잇 - 4.0
...
C는 이미 이렇게 rating 했습니다.
어벤져스, 아바타, 겨울왕국, 해리포터, 반지의 제왕 이 다섯 개의 영화에 대한 rating을 보아하니, A는 B보다는 C라는 이용자와 좀 더 '비슷'한 것 같습니다.
그럼 이제 B가 평점을 좋게 줬던 영화 중에서 A가 보지 않은 영화를 A에게 추천한다면, A가 기뻐할 확률이 높네요.
<B의 rating 中>
반 헬싱 - 4.5
트와일라잇 - 3.0
아마도 반 헬싱을 추천해주면 좋아할 것 같습니다:)
Codes
import pandas as pd
import numpy as np
from scipy.sparse import csr_matrix
from sklearn.metrics.pairwise import cosine_similarity
user = pd.read_csv("./ratings.csv")
sparse_matrix_user = csr_matrix((user['rating'], (user['userId'], user['movieId'])))
row_index_user, col_index_user = sparse_matrix_user.nonzero()
data_user = sparse_matrix_user.data
rows_user = np.unique(row_index_user)
length = max(rows_user)+1
sim_matrix = []
for row in range(1, length):
sim = cosine_similarity(sparse_matrix_user.getrow(row), sparse_matrix_user).ravel()
sim = np.array(sim)
s = sim.argsort()[-50:]
a=sim[s]
sim_matrix.append(s)
print(row/length*100, "% is done")
sim_matrix = pd.DataFrame(sim_matrix)
sim_matrix.to_csv("C:/Users/JihongJeong/capstone/simliaritymatrix_user.csv", mode = 'w')※ 본 코드에선 유사도 계산에 Cosine similarity를 이용했으나, 실제 project에선 추후 비교를 위해 Pearson correlation도 사용하여 한 번 더 구했습니다.
Content-Based CF
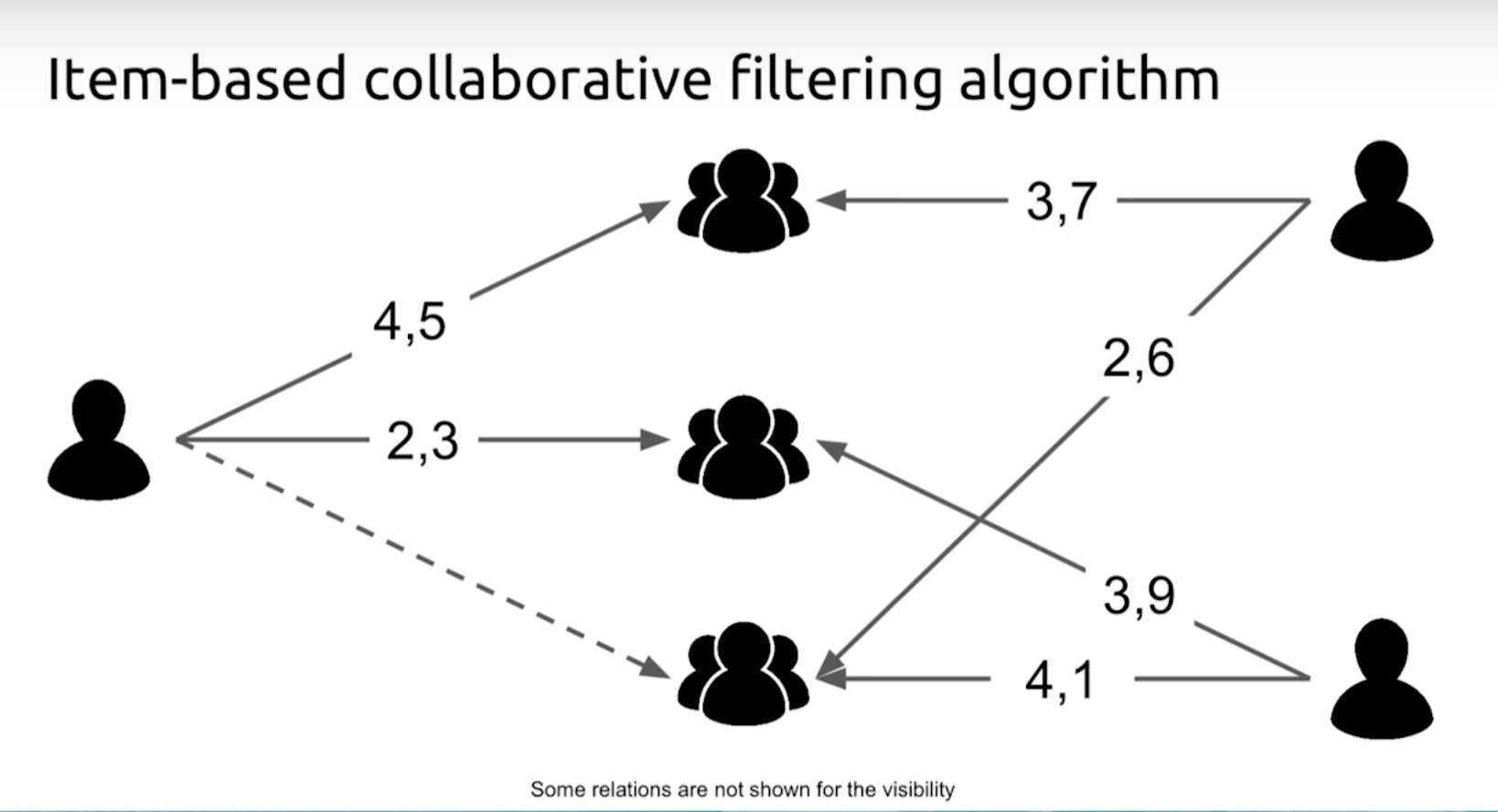
Content-Based라는 말 그대로 비슷한 Content(여기선 Movie겠죠)간 분석을 통한 CF입니다.
Codes
import pandas as pd
import numpy as np
movie = pd.read_csv("./movies.csv")
def cosine_sim(a, b):
return np.dot(a, b)/(np.linalg.norm(a)*np.linalg.norm(b))
add_genre = []
for i in range(len(movie)):
add_genre.append(movie['genres'][i].split("|"))
movie['genre']=add_genre
movie=movie.drop(['genres'],axis=1)
genre_list = []
for i in range(len(movie)):
genre_list=genre_list+movie['genre'][i]
make_set=set(genre_list)
genre_list=list(make_set)
genre_list.sort()
print(genre_list)
movie_matrix = [[0 for col in range(len(genre_list))] for row in range(len(movie))]
for i in range(len(movie)):
for j in range(len(genre_list)):
if set([genre_list[j]])&set(movie['genre'][i]):
movie_matrix[i][j]=1
movie_matrix = np.array(movie_matrix)
sim_matrix = []
for i in range(len(movie)):
sim = []
for j in range(len(movie)):
sim.append(cosine_sim(movie_matrix[i], movie_matrix[j]))
sim = np.array(sim)
s = sim.argsort()[-50:]
a=[]
for j in range(50):
a.append(movie['movieId'][s[j]])
sim_matrix.append(a)
print(i/len(movie)*100, "% is done")※ 마찬가지로 Cosine similarity를 이용했으나, 실제 project에선 추후 비교를 위해 Pearson correlation도 사용하여 한 번 더 구했습니다.
Uniqueness
저희 system의 uniqueness라고 한다면 바로 'CF에서 끝내지 않고 ML까지 연결했다는 점'입니다.
보통은 위의 두 CF를 통해서 추천을 시작하곤 하는데요, 저희는 CFs의 결과를 수치화한 뒤 ML을 돌리기 위한 feature로 만들었습니다.

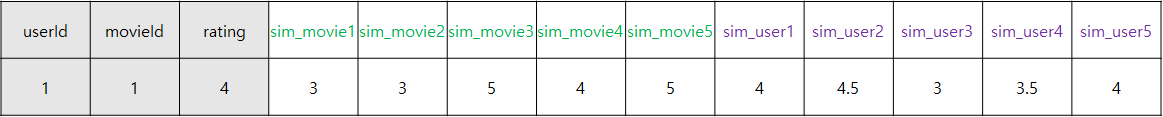
정의는 이렇습니다.
sim_user1~5 : Ratings given to this Movie by top 5 similar users with this User
sim_movie1~5 : Ratings given by this User to top 5 similar movies with this Movie
한국어로는
sim_user1~5 : 비슷한 이용자 Top 5 유저에 의해 이 영화에 매겨진 평점
sim_movie1~5 : 이 이용자에 의해 매겨진 이 영화와 비슷한 Top 5 영화에 대한 평점
이 되겠네요.
이로써 userID를 기준으로 movieID, rating에 더불어 총 8개의 column이 feature로 추가된 final data가 완성되었습니다. (5개, 5개 총 10개였지만, sim_user1과 sim_movie1은 자기 자신에 대한 정보가 선택되어 버리기 때문에 제외했습니다.)
ML Stages
※ 이 파트는 일반적인 추시에 해당하는 과정이 아닌 저희 시스템에 대한 이야기입니다.
이제 일반적인 ML의 stage를 밟게 됩니다.
XGBoost에서 performance에 영향을 많이 준다고 알려진 다음 네 개의 파라미터를 grid search를 통해 hyperparameter tuning하게 됩니다.
Eta(learning rate) : 0.1 / 0.3 / 0.5 / 0.7
Gamma(regularization parameter) : 0 / 1 / 3 / 5
Max_depth(maximum depth of each added tree) : 4 / 6 / 8 / 10
Min_child_weight(minimum sum of weights in child nodes) : 1 / 3 / 5 / 7
그러나 저희는 evaluation metrices가 RMSE와 MAE 두 개로, 단일 score를 통해 optimal combination을 찾아내는 grid search를 사용할 순 없었습니다.
따라서, for loop를 네 번 돌려서 RMSE가 가장 낮은 순으로 5개의 조합, MAE가 가장 낮은 순으로 5개의 조합 총 10개를 DataFrame에 저장하여 직접 판단하기로 했습니다 (presentation에서는 semi-grid search라고 소개함).
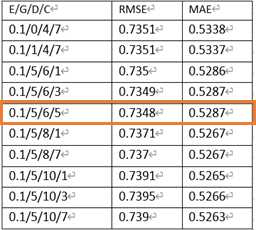
Cosine Similarity + XGBoost의 Top 10 Parameter Combination
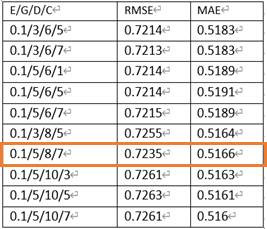
Pearson Correlation + XGBoost의 Top 10 Parameter Combination
각 similarity calculation method의 대표 조합을 비교해보겠습니다.
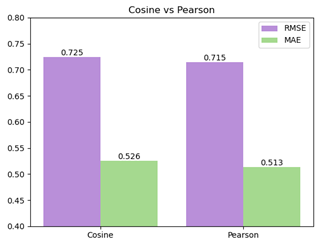
예상 외로 Pearson Correlation을 이용한 XGBoost가 추천시 rating 0.7 정도의 평균 오차로 더 좋은 예측을 보여줬습니다.
0.7정도면 영화가 재밌다 / 재미없다 정도만 가를 수 있다는 점에서 아쉬움이 있지만, 굉장히 한정된 정보인 'rating'과 'genre'만 이용한 분석의 결과라는 점에서 개선의 여지가 많습니다.
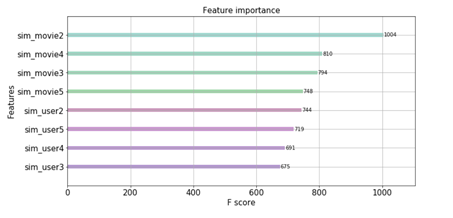 Tree-based ensemble model의 꽃인 feature importance plot을 그려봤습니다.
Tree-based ensemble model의 꽃인 feature importance plot을 그려봤습니다.
예상대로 2가 가장 중요하게 나왔는데, 특히 movie based feature 자체가 user based feature 전체보다 중요하게 나왔다는 점에서, genre similarity가 user similarity보다 성공적인 추천에 있어서 더 중요한 역할을 했다고 볼 수 있겠네요.
Codes
from xgboost import XGBRegressor, plot_importance
import pandas as pd
import numpy as np
import math
from sklearn.metrics import mean_squared_error, mean_absolute_error
from sklearn.model_selection import train_test_split
from sklearn import metrics
import matplotlib.pyplot as plt data = pd.read_csv('features.csv')
data = data.drop(data.columns[3], axis=1)
data = data.drop(data.columns[3], axis=1)
data = data.drop(data.columns[7], axis=1)
data = data.fillna(data.mean())
display(data.head())
x = data[['sim_user2','sim_user3','sim_user4','sim_user5', 'sim_movie2','sim_movie3','sim_movie4','sim_movie5']]
col_names = ['sim_user2','sim_user3','sim_user4','sim_user5', 'sim_movie2','sim_movie3','sim_movie4','sim_movie5']
y = data['rating']
rgr = XGBRegressor()
rgr.fit(x, y)
#importance = rgr.feature_importances_
#print(importance)
ax = plot_importance(rgr,color=['#8fd9a6', '#8fd9b8', '#8fd9c4', '#8fd9cf', '#b895d3', '#c195d3', '#d295d3', '#d395bd'])
ax.figure.set_size_inches(12,6)
#plot_importance(rgr,color=['#a5d98f', '#8fd9b6', '#8fd9cf', '#8fc7d9', '#8fa0d9', '#a28fd9', '#b98fd9', '#c78fd9'])
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.title('Feature importance',fontsize=15)
plt.xlabel('F score', fontsize=15)
plt.ylabel('Features', fontsize=15)
plt.show()
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2)
rgr = XGBRegressor()
rgr_train = rgr.fit(x_train, y_train)
pred_train = rgr_train.predict(x_train)
pred_test = rgr_train.predict(x_test)
train_rmse = math.sqrt(metrics.mean_squared_error(y_train, pred_train))
train_mae = mean_absolute_error(y_train, pred_train)
test_rmse = math.sqrt(metrics.mean_squared_error(y_test, pred_test))
test_mae = mean_absolute_error(y_test, pred_test)
print("\n")
print("="*50, "\n")
print("train RMSE :", train_rmse, "\n")
print("train MAE :", train_mae)
print("-"*50)
print("test RMSE :", test_rmse, "\n")
print("test MAE :", test_mae, "\n")
print("="*50, "\n")Future Work

 당시 report에 썼던 전문 캡쳐입니다. Future Work까지 봐주시는 분들은 이 정도의 영어를 쉽게 읽으실 수 있을 거라는 가정 하에.. 해석은 하지 않겠습니다 :)
당시 report에 썼던 전문 캡쳐입니다. Future Work까지 봐주시는 분들은 이 정도의 영어를 쉽게 읽으실 수 있을 거라는 가정 하에.. 해석은 하지 않겠습니다 :)
결론
Movielens data (latest version)에 다른 data도 꽤 있었습니다 (meta data 포함).
하지만 deadline도 꽤 짧았고, 중간에 CFs 구성에서 한 파일을 돌리는데에 데스크탑 기준 18시간이 걸리는 불상사가 일어나기도 해서 완성에 조금 의의를 뒀던 것 같아요.
몇 가지 프로젝트를 했었지만, 그래도 뭔가 '의미있는 완성'의 느낌을 받았던 첫 작품입니다.
블로그에 첫 포스트를 남겼을 때 했던 생각인데요,
"내가 5시간을 투자해서 쓴 글을 통해서 단 한 명이라도 4시간을 아낀다면 성공이다."
저 한 사람이 이 내용을 까먹은 미래의 저가 될 수도 있기 때문에, 결론적으로 모든 글은 '저'를 위한 저장소의 느낌입니다.
그래도 혹시나 여러분이 포스트를 읽고 궁금하신 부분이 생기신다면, 언제든지 댓글 환영입니다! 감사합니다 :)
Referrence
F. Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: History and Context. ACM Transactions on Interactive Intelligent Systems (TiiS) 5, 4: 19:1–19:19. https://doi.org/10.1145/2827872
Team Whatflix
