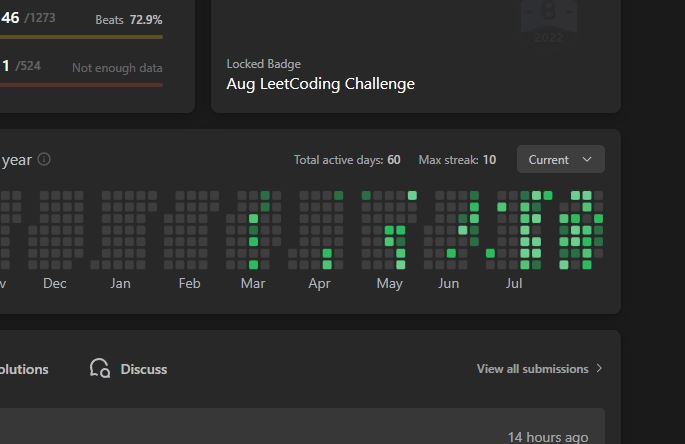
※ 7월 29일을 기준으로 작성된 포스트입니다.
안녕하세요, 아직도 군대에 수감되어있는 JJun입니다 :) 석방까지 2달도 안남은 오늘, 제 2년 공부 인생에서 중요한 milestone을 지나게 되어 학술 포스트보다 가벼운 내용으로 작성하게 되었습니다.
오늘은 바로 제가 LeetCode에서 처음으로 Hard 문제 (1028. Recover a Tree From Preorder Traversal)를 푼 날입니다. 3개월 전(예열 기간까지 합치면 4개월 전 정도겠네요), 처음으로 CS 공부를 제대로 시작해야겠다고 마음을 먹고.. 없는 시간을 쪼개서 달려왔는데 여기까지 도착한 제 자신이 처음으로 자랑스러운 순간입니다 ㅎㅎ
이번 포스트에서는 제가 3개월동안 어떻게 효율적으로 CS 공부를 해서 Hard problem에까지 도전할 수 있었는지 과정과 공부법을 공유하겠습니다.
😥시작하기 전의 나
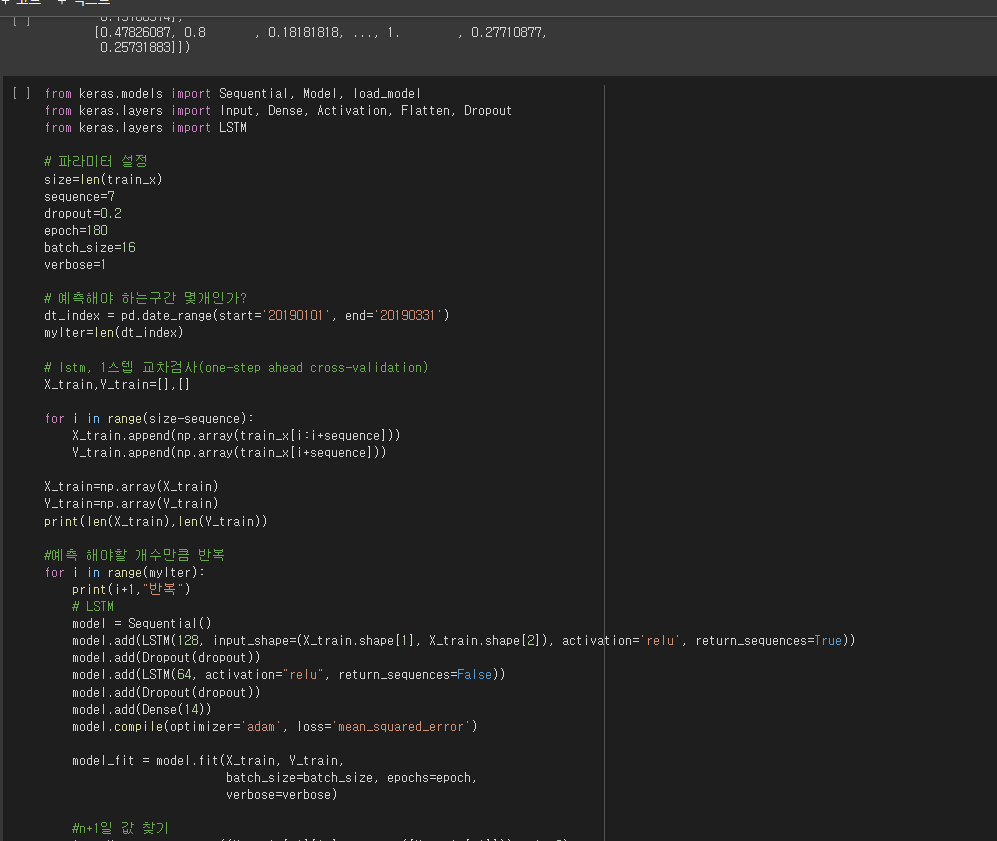
저는 데이터사이언스학과 학생으로, CS에 대한 깊은 공부는 한 적이 없이 ML/DL 위주로만 공부해왔습니다. 특히 Deep Learning 단계로 들어간 이후로부터는 논문 읽기나 유튜브 영상 시청 등 이론적인 지식 위주로 쌓고, MLops 단계를 따른 미니 프로젝트 및 code template 제작에 신경을 많이 썼습니다.
사실 이런 방식으로 공부하면서도 전혀 문제를 못느꼈는데, 데이터사이언스는 많은 머신러닝 패키지를 python에서 지원하고 있어서 이것들만 잘 사용해도 대회 입상까지도 가능했었기 때문입니다.
위의 코드 사진만 보셔도, 필수적인 ML steps를 밟기 위한 패키지의 기본적인 절차는 모두 밟았으나, 그 이상의 노력 - running time 개선이나 memory usage 개선을 위한 - 은 하지 않았습니다.
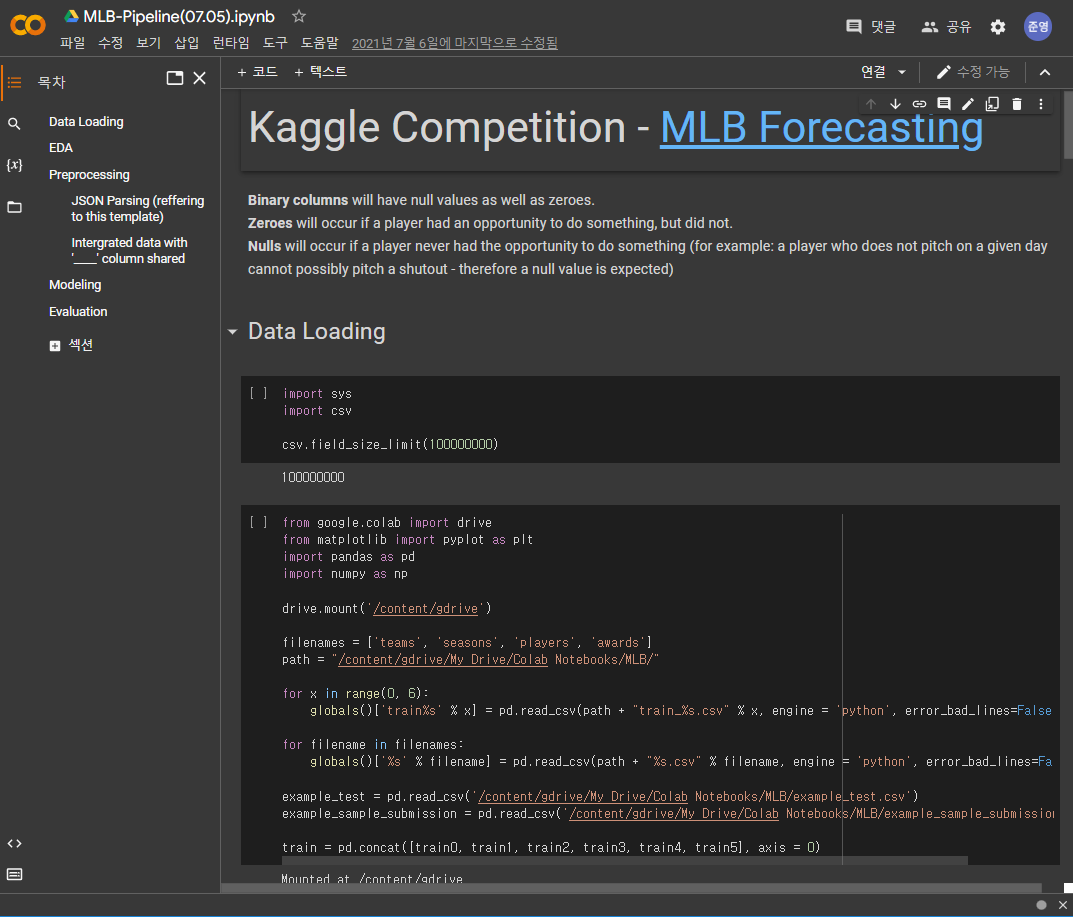
작년 7월 부대에 구비되어있는 저성능의 컴퓨터로 동기들과 kaggle 대회를 준비하다가 심각성을 알게 되었는데요, 집의 desktop으로 3GB 이상의 데이터를 편하게 불러와 다루던 제가, 저성능의 컴퓨터로 열게 되니 데이터를 불러오는 것부터가 어려웠습니다.
결국 컴퓨터의 메모리 사용 제한을 풀고 나눠서 불러온 뒤, parsing하는 데에만 몇 일을 날려버리다가 아직 기본적인 데이터를 다루는 CS skill이 너무 부족하다는 것을 깨닫게 되었습니다.
이 당시에 바로 공부를 시작했으면 좋았겠지만, 이후 개인적으로 다른 DS 대회에 참가하거나 AI 논문 읽기, 통계학 공부를 이어하면서 기억속으로 잊혀지게 되었습니다.
🤸♂️첫 시작
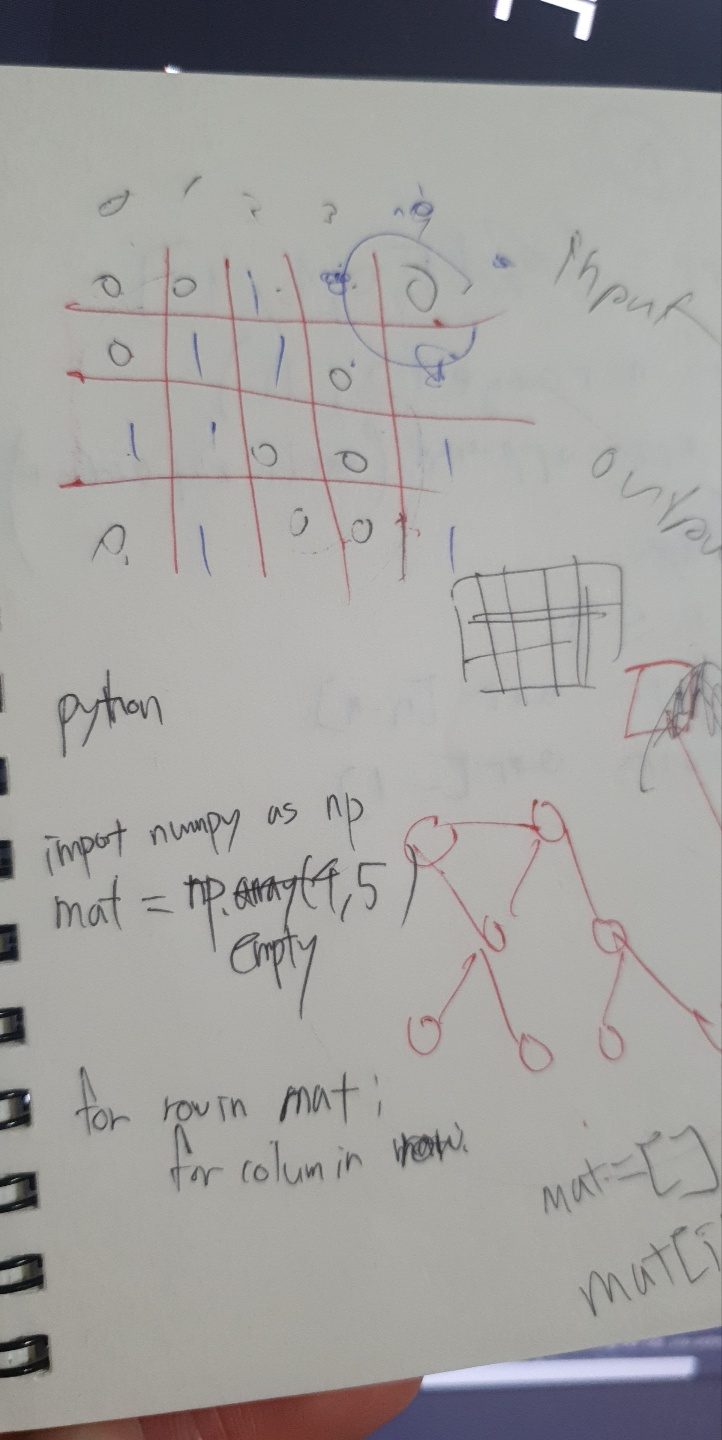
| 1년 4개월 전 훈련소에서 DFS, 심지어 graph가 뭔지 몰라서 설명받았던 종이 |
같은 날 DP(Dynamic Programming)이 뭔지 아예 몰라서 설명받았던 종이 |
 |
 |
과거의 제 무지함을 증명하기 위해 과한 방법을 사용했습니다.. ㅎㅎ 말 그대로 프로그래밍 자체를 제대로 못했다고 봐야겠죠.
부끄럽지만 왼쪽 사진 아래에 보시면, DFS 문제를 듣고나서 제가 쓴건 for loop 두 개가 끝이었습니다.
이번 년도 초, 입대 전 계획했던 수학공부와 DS 논문읽기 등등이 어느정도 마무리되면서 새로운 무언가를 위해 방황하던 중, 사진에 있는 종이를 오랜만에 발견하면서 CS 공부를 해보기로 마음먹었습니다.
Youtube


전 정말 상상 이상으로 기본 지식이 없었고, 무엇보다 처음 공부해보는 분야였기 때문에 마땅히 공부하는 방법을 몰랐습니다. 그래서 생각해낸 방법이, 어디서 주워들었던 기본적인 stack이나, data structure같은 키워드에 언어 (제가 그나마 할 줄 아는 python이나 javascript)를 함께 유튜브에 검색했습니다.
인스턴트성으로 어찌어찌 stack, queue, binary tree 등에 대한 개념은 갖췄지만, 전혀 일관성이 있는 공부방식도 아니었고 무엇보다도 제가 제대로 아는지 확인할 길도 없었습니다.
그래서 저는 뭔가 해보면서 부딪쳐보고자 LeetCode라는 해외 알고리즘 문제 사이트를 풀어보려 시도했지만 (당시에도 알게 된지는 2년도 넘었네요 ...), 정말 말 그대로 풀 수 있는 문제가 하나도 없어 정석적인 강의를 들어보기로 결심했습니다.
GeeksforGeeks
 또 GeeksforGeeks라는 사이트가 있는데, 여기에서 data structure 메뉴얼을 조금씩 읽긴 했었습니다. 그런데 솔직히 어떤 흐름을 잡고 있던 상황은 아니었다보니까, 말 그대로 모르는게 생기면 확인하러만 들어오고, 통시적으로 쭉 공부하진 않았었네요.
또 GeeksforGeeks라는 사이트가 있는데, 여기에서 data structure 메뉴얼을 조금씩 읽긴 했었습니다. 그런데 솔직히 어떤 흐름을 잡고 있던 상황은 아니었다보니까, 말 그대로 모르는게 생기면 확인하러만 들어오고, 통시적으로 쭉 공부하진 않았었네요.
🚴1~2개월차
Coursera
Coursera는 입대 전 외국인 친구가 아이디를 만들어서 잠깐 빌려달라고 부탁했을 때 알게된 강의 사이트입니다. 저는 미국 대학원 진학을 목표로 하고있어서 미국 top tier 대학의 강의를 유튜브에서 몇 번 들은 적 있는데, (Stanford의 CS231n, MIT의 6.S191 등등), Coursera에 들어와보니 이것들이 우스워질 정도로 Course나 Specialization 개념으로 잘 정립된 강의가 무척 많았습니다.
저는 그 중에서도 Stanford의 algorithm specialization 과정을 선택했습니다.
(원래 Stanford를 좋아하는건 안비밀)
 저도 현재 총 4개의 코스 중 3개를 수료했는데요, 4번째는 지금 당장 들을 수가 없습니다. 무료 재정 지원 신청서를 넣어놨는데, 아직 승인이 안나서 대기중이랍니다.
저도 현재 총 4개의 코스 중 3개를 수료했는데요, 4번째는 지금 당장 들을 수가 없습니다. 무료 재정 지원 신청서를 넣어놨는데, 아직 승인이 안나서 대기중이랍니다.
Specialization을 통해서 Big Oh / Theta / Omega, graph basics, DFS / BFS, divide and conquer, SCC, cut, Kosaraju's algorithm, Dijkstra's algorithm, heap, median maintenance, MST, Prim's algorithm, Kruskal's algorithm, Tarjan's algorithm, Huffman coding, .... 배운게 정말 많습니다.
어떻게 보면 시작 1개월 차에 듣기에 조금 어려운 강의이긴 했는데, 그만큼 이해하는데에 강사가 시간을 많이 써서 그런지 제가 노력하면서 잘 따라잡을 수 있었던 것 같네요 :)
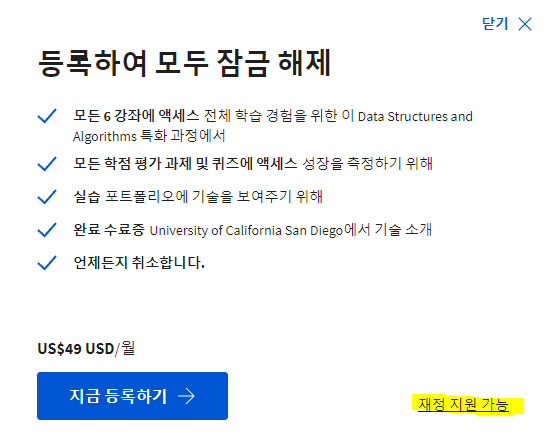 대부분의 강의가 등록하려고 하면 이런 식으로 돈을 내라고 (그것도 매월 49$ ...) 하는데요, 사실 오른쪽에 있는 재정 지원 버튼을 누르면 신청서를 작성하고 무료로 들을 수가 있습니다. 신청서를 제출한 이후로 14일 뒤부터 승인이 되는데, 알고보니 대충 작성해도 통과시켜 준다고 하네요.
대부분의 강의가 등록하려고 하면 이런 식으로 돈을 내라고 (그것도 매월 49$ ...) 하는데요, 사실 오른쪽에 있는 재정 지원 버튼을 누르면 신청서를 작성하고 무료로 들을 수가 있습니다. 신청서를 제출한 이후로 14일 뒤부터 승인이 되는데, 알고보니 대충 작성해도 통과시켜 준다고 하네요.

전 바보같이 열심히 영어로 세 번을 썼지만 여러분들은 제발 한국어로 대충 쓰시길 바랍니다 ㅜ
다만 한 코스에 보통 30일 조금 덜 걸리는데, 대기하는 기간이 14일이니 공부하는데에 공백이 많이 생기긴 합니다. "어라 이러면 제대로 공부가 안되니까 결제를 하거나 다른걸 들어야 하나?"
걱정 안하셔도 됩니다. 강의 수준이 상당히 높고 무엇보다도 programming assignment가 꽤 (많이) 어려워서 마감기한에 닥쳐 허겁지겁 제출한 코드와 학습 자료를 다시 돌이켜 볼 수 있는 좋은 시간입니다. 혹시 강의 내용이나 대략적인 난이도가 궁금하신 분은 제 깃허브를 참고하세요 :)
 사진과 같이 1주일 단위로 나뉘어있고, 대부분이 영상 강의로 진행되다가 마지막 assignment에서 배운 내용을 토대로 프로그래밍을 하는 방식입니다.
사진과 같이 1주일 단위로 나뉘어있고, 대부분이 영상 강의로 진행되다가 마지막 assignment에서 배운 내용을 토대로 프로그래밍을 하는 방식입니다.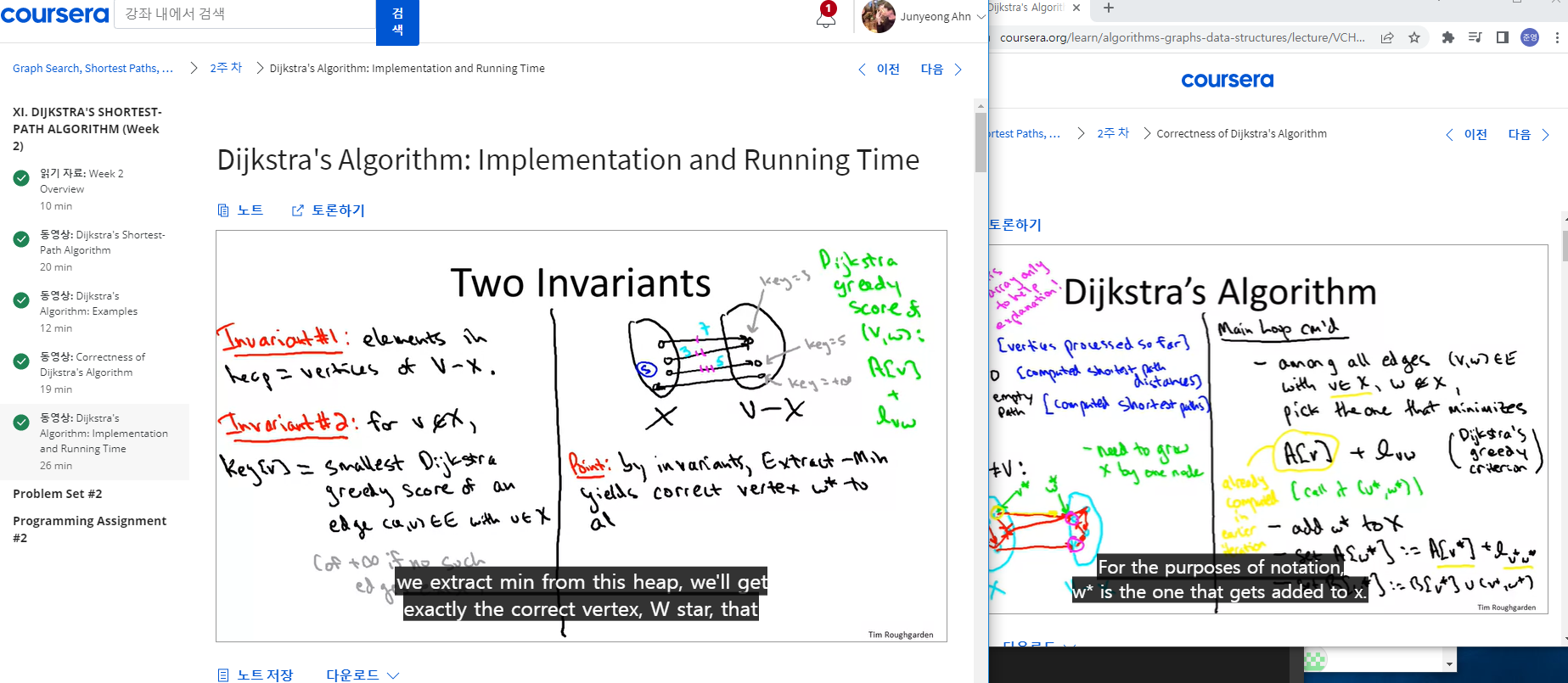 이 강의의 장점은, 강사가 프로그래밍한 코드를 그대로 따라가거나 하는 과정이 일절 없습니다.
이 강의의 장점은, 강사가 프로그래밍한 코드를 그대로 따라가거나 하는 과정이 일절 없습니다.
심지어, 강사가 코딩을 하는 장면은 4개의 course 그 어디에서도 나오지 않습니다. 프로그래밍 언어를 특정하지도 않고, 그저 개념에 대한 충실한 이해와 탐구로만 강의를 진행해나갑니다.
다만, 이렇다보니 가끔 과하게 갈 때도 있긴 합니다 (correctness proof가 거의 매번 나오는데, 솔직히 저같은 뉴비는 대충 이해만 하고 넘어가는게 좋았던 것 같아요).
또, 너무 이론적인 부분이 자주 나올땐 집중력이 흐트러질 수 있어서, 군대 하루 공부 2시간 중 1시간만 투자하고, 남은 1시간은 course 1에서 배운 graph계열 개념을 써먹을 수 있는 알고리즘 문제를 조금씩 풀어보기 시작했습니다.
주의할 점 : 이 강의뿐만 아니라, Coursera는 대부분의 수준 높은 강의가 (아마도) 한국어 자막이 없습니다. 그래도 영어 자막까진 제공하니까, 영어가 수월하시거나 어느정도 되시는 분들은 참고하시면 좋을 것 같아요 !
🏋️♀️중반 ~ 3.5개월차 (현재)
이전보다 아는게 점점 많아진다는 생각이 들면서, 제 현재 실력이 어느 정도인지가 궁금해지기 시작했습니다. 또한 저는 어떤 공부를 할 때 제 실력의 발자취를 남기는걸 좋아하는데, CS 공부는 특히나 실력 변화가 생긴다면 눈에 띌 거라고 생각해서 알고리즘 문제 사이트를 찾아보았습니다.
 한국 사이트로 유명한 백준, 프로그래머스 등등이 있었고 해외 사이트인 LeetCode, HackerRank 등이 있었는데요, 저는 해외 대학원 및 취업을 목표로 하고 있어서 LeetCode를 선택했습니다.
한국 사이트로 유명한 백준, 프로그래머스 등등이 있었고 해외 사이트인 LeetCode, HackerRank 등이 있었는데요, 저는 해외 대학원 및 취업을 목표로 하고 있어서 LeetCode를 선택했습니다.
실제로 해외는 coding interview를 LeetCode 프로필로 대체하는 경우도 무척 많을 정도로 선구자적인 문제풀이 사이트입니다. 다만 한국의 코딩 문제와는 스타일이 많이 달라서, 신중하게 결정해서 풀어보시는걸 추천드립니다 :)
LeetCode
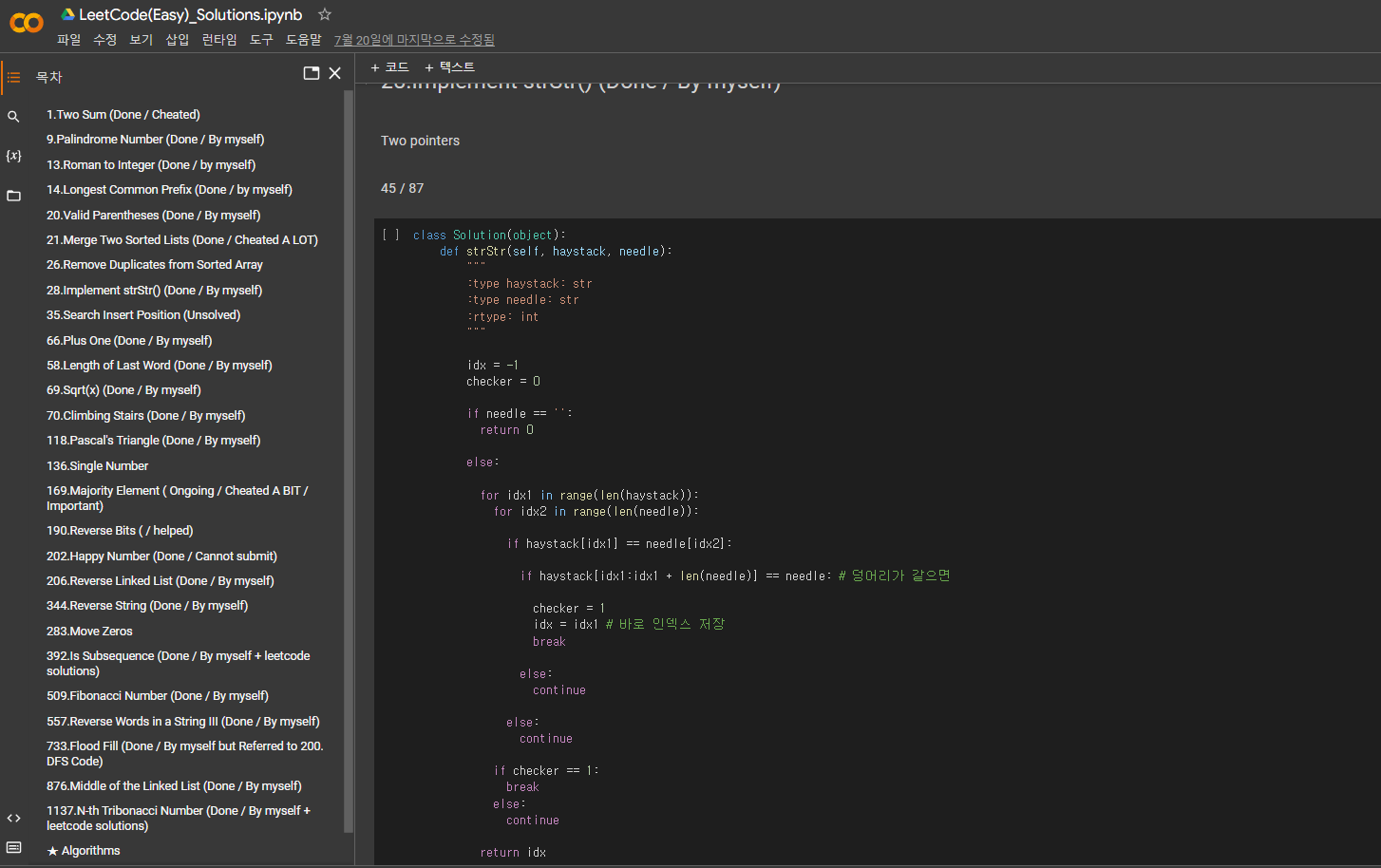 제 당시 colab 파일의 목차를 보면, 문제별로 나누어놓고 comment를 달아놓은 것을 확인하실 수 있습니다 - 예시 : Done / by myself, Done / cheated a lot, Unsolved / runtime error 등등
제 당시 colab 파일의 목차를 보면, 문제별로 나누어놓고 comment를 달아놓은 것을 확인하실 수 있습니다 - 예시 : Done / by myself, Done / cheated a lot, Unsolved / runtime error 등등
이러한 습관 중 가장 좋았던 방식은, 한 문제를 두 가지 이상의 방식으로 풀어보는 것이었습니다. 모든 DFS 문제를 recursive / iterative approach 둘 다 써보거나, tree traversal에서 divide and conquer / simple recursive / iterative 세 개를 써보는 등 배운걸 최대한 활용하고 기록하려고 노력했습니다.
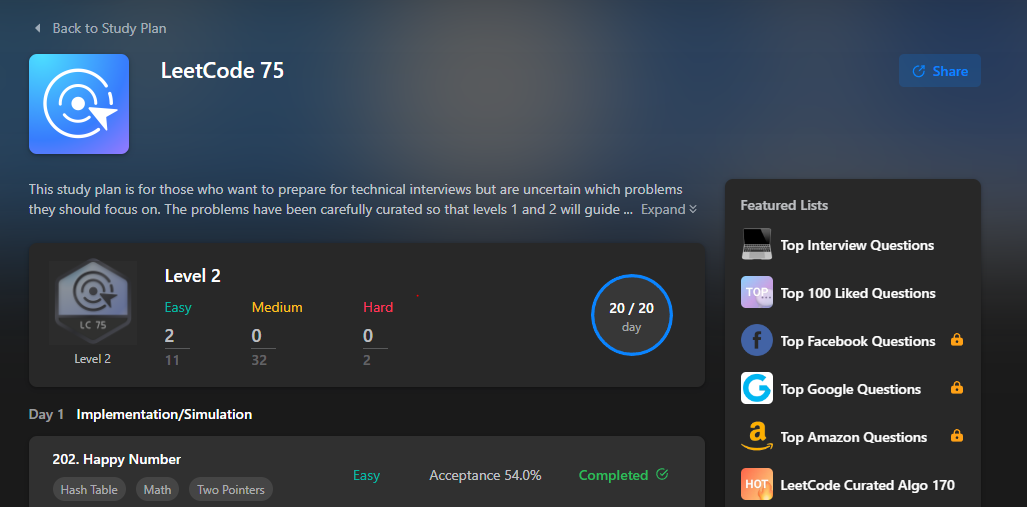 몇 분야 별로 정말 기초적인 문제를 풀고 나서는, LeetCode 75라는 study plan을 등록해서 매일 다양한 분야의 문제를 점진적인 난이도에 걸쳐 풀어보았습니다. 이렇게 하다보면, 다 잘풀려도 꼭 잘 안풀리는 분야 (sliding window, two pointers 등등)가 있는데, 이런 분야는 놓치지 않고 기록해둔 뒤 시간이 있을 때마다 추가로 공부해주는게 좋았던 것 같습니다.
몇 분야 별로 정말 기초적인 문제를 풀고 나서는, LeetCode 75라는 study plan을 등록해서 매일 다양한 분야의 문제를 점진적인 난이도에 걸쳐 풀어보았습니다. 이렇게 하다보면, 다 잘풀려도 꼭 잘 안풀리는 분야 (sliding window, two pointers 등등)가 있는데, 이런 분야는 놓치지 않고 기록해둔 뒤 시간이 있을 때마다 추가로 공부해주는게 좋았던 것 같습니다.
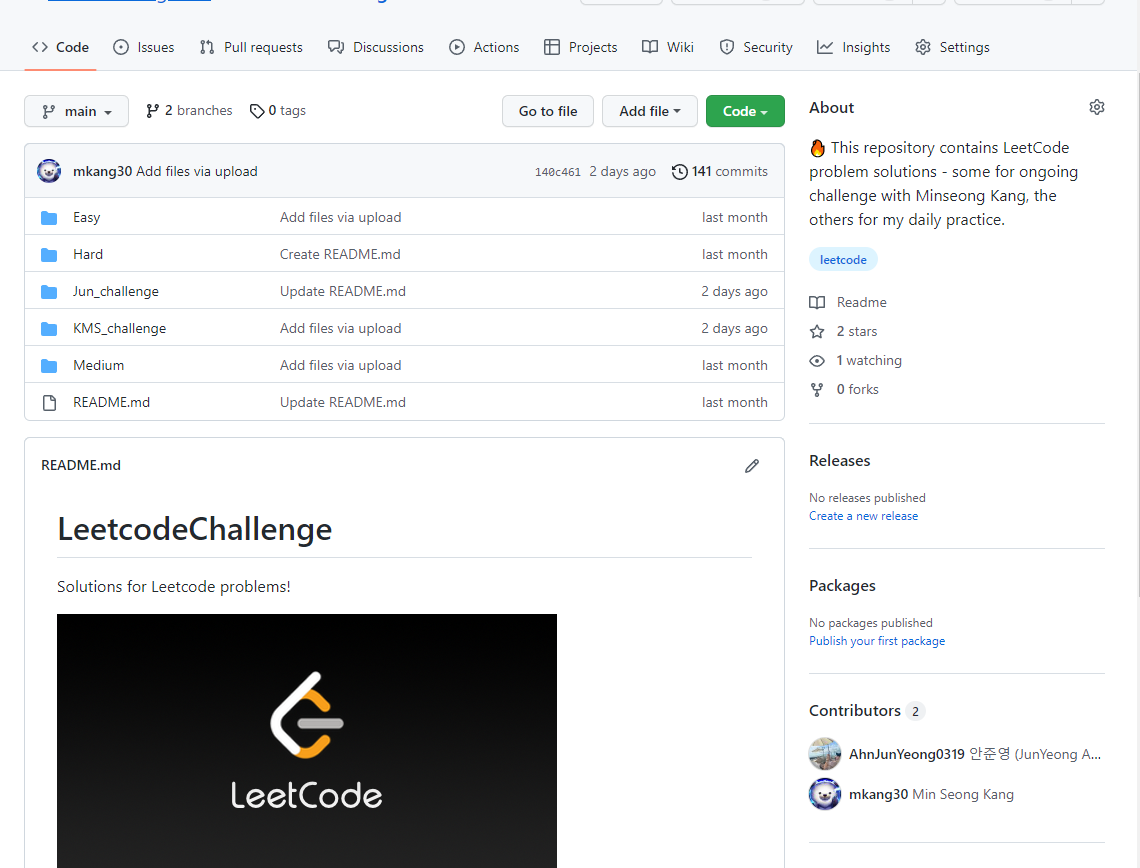 그러다가 휴가를 나와서 친구와 얘기를 하다가, 이틀에 3문제를 풀어서 github repository에 올려보자는 얘기가 나왔습니다. 이전에는 불규칙적으로 coursera와 병행하면서 풀고 싶은 문제만 풀다보니 어떤 변화를 눈에 보기 어려웠는데, 꾸준히 하다보면 이전과는 다른 것을 얻게 될 것 같아서 시작했습니다.
그러다가 휴가를 나와서 친구와 얘기를 하다가, 이틀에 3문제를 풀어서 github repository에 올려보자는 얘기가 나왔습니다. 이전에는 불규칙적으로 coursera와 병행하면서 풀고 싶은 문제만 풀다보니 어떤 변화를 눈에 보기 어려웠는데, 꾸준히 하다보면 이전과는 다른 것을 얻게 될 것 같아서 시작했습니다.
허수에 가까운 쉬운 문제들이 금방 소진되고 나니, 첫 날과 다르게 정말 'challenge'처럼 느껴지기 시작했습니다. 생각이 많아지는 문제나, 당장은 전혀 풀 수 없는 문제도 있었습니다. 그래서 예전처럼 문제별로 comment를 달기로 했는데, 푼 문제가 너무 많아지니 제가 체감했던 난이도를 ★ 개수로 나눠서 기록해두었습니다.
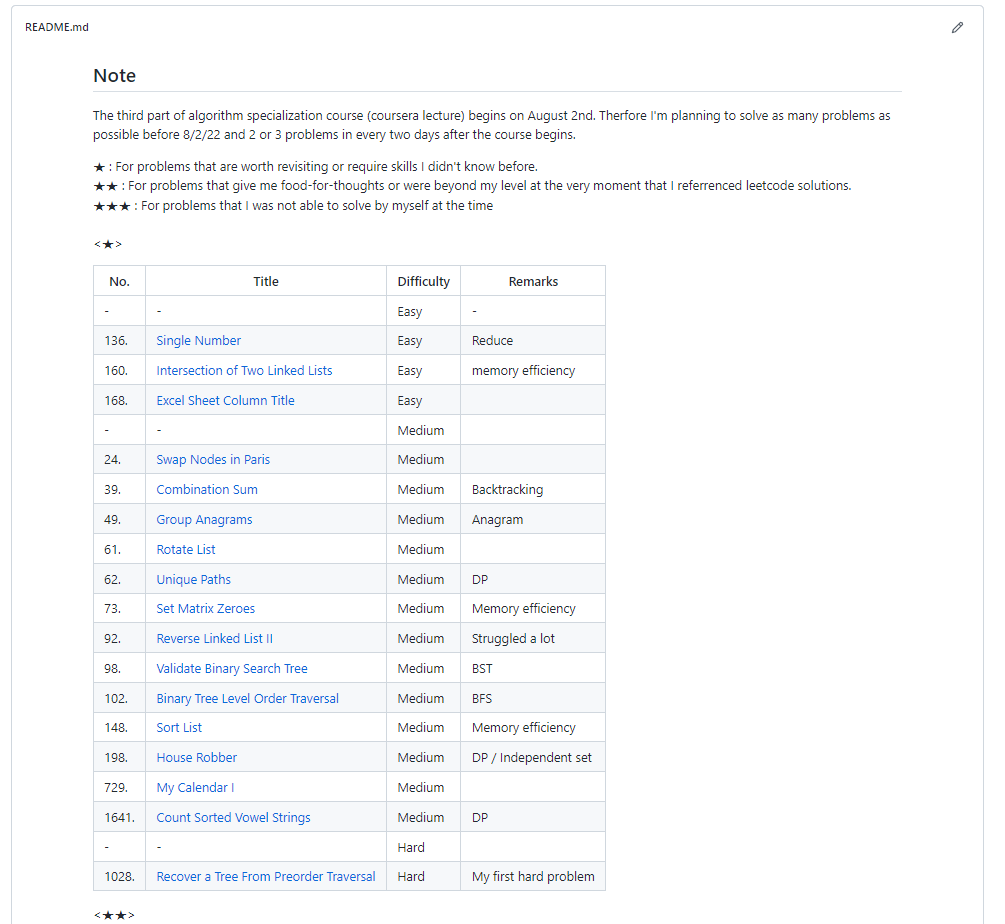 옆에 Remarks는 비고인데, 이렇게 약점이 있었던 부분을 키워드로 정리해놓으니 보완하는데에 걸리는 시간이 현저히 줄어들면서 빠른 속도로 성장하기 시작했습니다.
옆에 Remarks는 비고인데, 이렇게 약점이 있었던 부분을 키워드로 정리해놓으니 보완하는데에 걸리는 시간이 현저히 줄어들면서 빠른 속도로 성장하기 시작했습니다.
(여전히 잘 못하지만 예전에 비해서는요 .. ㅎㅎ)
No. 1028
이렇게 꾸준히 푼 결과, CS 공부를 시작한지 3.5개월이 된 오늘 드디어 첫 hard 문제를 풀게 되었습니다 !!!
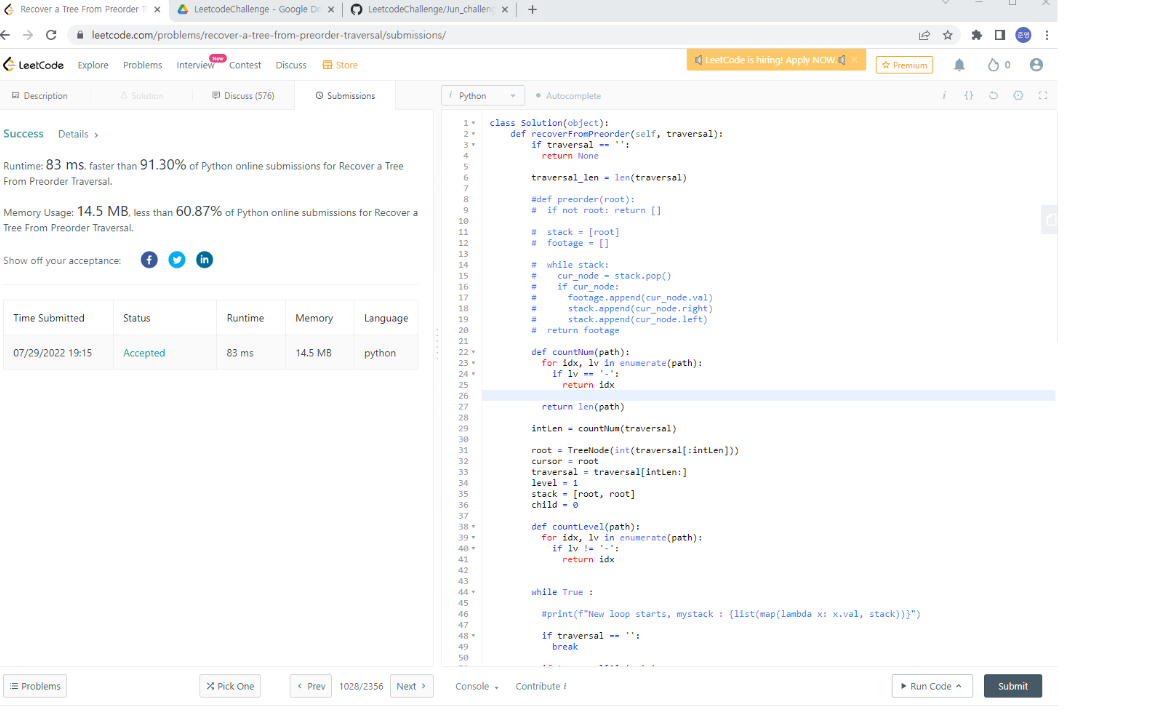
솔직히 acceptance도 굉장히 높은 문제고, 이 당시에는 코드를 깔끔하게 쓰는 것보단 time / space complexity를 개선하는 것에 치중해서 (둘 다 잡을 실력은 안됐네요 ㅜㅜ) 코드도 굉장히 깁니다.
심지어 4시간인가 걸려서 풀었는데, 뭔가 아무것도 몰랐던 상태가 엊그제같은데 결국 해냈다는게 너무 자랑스러운 순간이었네요.
Solution Code
No. 1026 Recover a Tree From Preorder Traversal 문제에 대한 제 solution입니다. 설명을 위해 comment도 많고, 중간에 과정 확인을 위한 print도 많아서 실제 코드 길이는 절반 정도입니다. Runtime이 상위 10%이니 참고해보실만한 코드라고 생각됩니다.
### NOTE. ###
#A preorder traversal travels in the priority of leftmost nodes.
#So if we are #already done with nodes to the left of the current node,
#we don't have to care #those nodes.
#The key point is to make sure the size of the stack is equal to the
#destination level (= 'curLv') that can be eqaul to,
#higher than or lower than #previous level (='level').
class Solution(object):
def recoverFromPreorder(self, traversal):
if traversal == '':
return None
traversal_len = len(traversal)
#def preorder(root):
# if not root: return []
# stack = [root]
# footage = []
# while stack:
# cur_node = stack.pop()
# if cur_node:
# footage.append(cur_node.val)
# stack.append(cur_node.right)
# stack.append(cur_node.left)
# return footage
def countNum(path):
for idx, lv in enumerate(path):
if lv == '-':
return idx
return len(path)
def countLevel(path):
for idx, lv in enumerate(path):
if lv != '-':
return idx
#### Initiate variables ####
intLen = countNum(traversal) # if a piece of 'traversal' corresponds to a treenode, count its digit lenght (ex.for '101-2---1')
root = TreeNode(int(traversal[:intLen])) # root node
cursor = root # cursor will move back and forth in an order of preorder traversal
traversal = traversal[intLen:] # cut out digits for nodes
level = 1 # the level (=phase) that 'cursor' are currently in
stack = [root, root] # stack for previous route to current cursor (with special conditions)
child = 0 # child counter for a level upshifting case
while True :
print(f"New loop starts, mystack : {list(map(lambda x: x.val, stack))}")
if traversal == '': # ending condition
break
if traversal[0] != '-': # 1) when the head of the 'traversal' is digit
intLen = countNum(traversal)
stack.append(TreeNode(int(traversal[:intLen]))) # put it in our stack such that we can backtrace later when upshifting
if cursor.left == None: # 1 - 1) if left child doest not exist (= no child node)
cursor.left = stack[-1] # we already stack this node in our 'stack' so use this fact
print(f'Left child added / parent : {cursor.val}, left child : {cursor.left.val}')
child = 1 # appending to the left means that one child is appended
else: # 1- 2_
cursor.right = stack[-1]
print(f'Right child added / parent : {cursor.val}, right child : {cursor.right.val}')
child = 1 # appending to the right means that we should remove one more node from our stack when upshifting.
traversal = traversal[intLen:]
else: # 2) when the head of the 'traversal' is '-'
curLv = countLevel(traversal)
traversal = traversal[curLv:]
if curLv > level: # 2 - 1) go deeper
print(f"condition 1_ go deeper")
if cursor.right == None:
cursor = cursor.left
else:
cursor = cursor.right
level = curLv # current level becomes previous level in the next loop
child = 0 # child be reset to 0 when go deeper since there is no child node right after incrementing level
elif curLv == level: # 2 - 2) no change of phase
print(f"condition 2_ no change of phase")
stack.pop() # !!! WHY POP? Because no change of level means appending two lateral nodes in a row, which means that they are children of the same parent
# !!! and that left child has no children nodes of it (=left nodes are done, check the NOTE. above this code cell.)
pass
else: # 2 - 3) upshifting level
print(f"condition 3_ upshifting")
print(f"stack before popping is {list(map(lambda x: x.val, stack))}")
print(f"child : {child}")
print(f"level gap : {level - curLv}")
for iter in range(level - curLv): # upshift phase by the level gap
stack.pop()
if child == 1: # If current cursor has a child, pop one more node from 'stack'
stack.pop()
cursor = stack[len(stack)-1] # update the current node
print(f"current cursor after shifting level is {cursor.val}")
print(f"stack after popping is {list(map(lambda x: x.val, stack))}")
print(f"constructed tree so far is {preorder(root)}")
level = curLv # current level becomes previous level in the next loop
child = 0 # child be reset to 0 when go deeper since there is no child node right after incrementing level
return root
ans = Solution().recoverFromPreorder(traversal)마치며
제 블로그에선 늘 학술적인 데이터 사이언스 관련 내용만 다뤘는데요, 이번 포스트는 처음으로 제 얘기를 하면서 컴퓨터 사이언스에 대해서 얘기하게된 것 같습니다.
이 모든 기록은 첫 번째로 저 자신을 위해서, 두 번째가 읽어주시는 고마운 분들을 위해서입니다. 그래서 조금 쓸데없어 보일 수도 있는 스토리가 중간에 있는 것 같지만, 제가 생각했을 때 이 글을 읽으신 분들은 아마 저처럼 초보이시거나 혹은 아직도 공부를 시작하지 못하신 분들이실 거라고 생각해요.
 군대에서 남들 모두가 자는 시간에 매일 2시간씩 1년 6개월을 공부한다는건 참 어려운 일이었습니다. 그 중에서도 이번 3개월이 가장 힘들었습니다. 전역이 다가오면서 한동안 잊고 지냈던 미래에 대한 고민으로 머리가 아파졌었어요.
군대에서 남들 모두가 자는 시간에 매일 2시간씩 1년 6개월을 공부한다는건 참 어려운 일이었습니다. 그 중에서도 이번 3개월이 가장 힘들었습니다. 전역이 다가오면서 한동안 잊고 지냈던 미래에 대한 고민으로 머리가 아파졌었어요.
부끄럽긴 하지만 인터넷 일기장에 스스로를 욕하면서 지나간 날도 있었습니다. Kosaraju's algorithm을 처음 접한 날, LeetCode challenge를 하다가 거의 한 문제도 제대로 풀지 못한 날.. 재밌는 점은 매번 그러고 나서 이틀 정도 뒤에 풀고 웃고있더라라는 것입니다.
군대에서 3개월간 공부하면서 생각했는데, 정말 열정만 있으면 다 되더라구요. 많은 분들이 자극받고 저와 함께 앞으로 나아가주셨으면 하는 바람이네요 ^-^ 긴 글 읽어주셔서 감사합니다!




열정과 수준 높은 글에 잘 배우고 갑니다 ^^ 화이팅!