
"A high tech solarpunk utopia in the Amazon rainforest"
.
.
"아마존 밀림에 있는 고도화된 솔라펑크 유토피아"

이 한 문장을 입력한 순간, Stable Diffusion은 고화질의 이미지를 생성해냈습니다. 뿐만 아니라, 원한다면 영상 배경 합성, 여러 이미지의 콜라주 생성, 심지어 단순한 스케치를 바로 이미지로 변환해주기도 합니다.
※ 이 포스트는 Stability사에서 공개한 Stable Diffusion의 original version 기준으로 작성되었으며, 포스트의 중/후반부에서 활용 모델 및 10초 사용법까지 모두 소개합니다.
또한, deep learning에 대한 지식이 전혀 없으신 분께서는 What is Stable Diffusion? 파트를 읽고, 바로 Try It! 파트로 넘어가주셔도 좋습니다. 하지만 조금이라도 알고 계시거나 이 기술에 대해 잘 알아보고 싶으시다면, 꼭 꼭 꼭 다 읽어보시길 권장합니다!!
What is Stable Diffusion?
Stable Diffusion AI
가장 기본적인 형태의 Stable Diffusion은, 자연어 설명으로부터 이미지를 생성해내는 deep learning AI 입니다. 전형적인 Text-to-Image task를 위한 모델로, 이는 computer vision 분야와 natural language processing 분야가 결합된 task입니다.
Deep learning은 기본적으로 학습과 테스트의 과정을 겪습니다. 즉, 우리가 학창 시절 공부를 아무리 해도 시험에서 완전히 새로운 유형이 나오면 잘 풀지 못하는 것처럼, Stable Diffusion도 학습된 이미지와 잘 맞지 않는 이미지는 잘 생성하지 못합니다.
쉽게 말해서, 세상에 상어 두 마리가 해변에서 춤을 추는 사진은 거의 존재하지 않겠죠. 따라서 input으로 "two sharks dancing on the beach"를 입력한다면, 결과는 그다지 좋지 않을 것입니다.
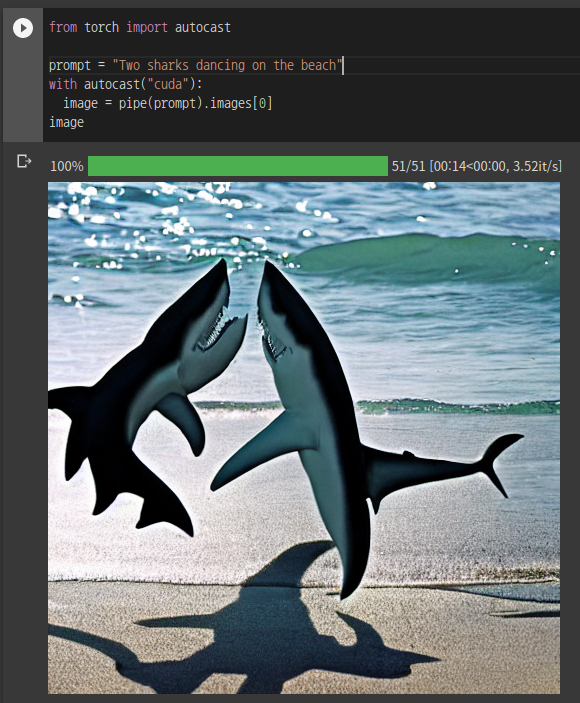
반면, 현실에 존재할 법한 이미지는 매우 그럴 듯하게 생성해는 것을 볼 수 있습니다.
Text to Image
위에서 말했듯이, Stable Diffusion AI는 텍스트를 input으로 받고, 이미지를 output으로 내는 deep learning model입니다. 이와 같은 text-to-image task가 어떻게 deep learning을 통해서 구현될 수 있는지, 간단한 예시를 통해서 설명드리겠습니다.
※ Text to image는 VAE 기반, GAN 기반, diffusion 기반 등등 여러가지 방법이 있기 때문에, diffusion 기반 방식으로 설명하겠습니다. (슬라이드 출처 : Vox youtube - The AI that creates any picture you want, explained)
(슬라이드 출처 : Vox youtube - The AI that creates any picture you want, explained)
전체 과정은 training data - deep learning - latent space - generation (diffusion) - output으로 나눌 수 있습니다. 우선, training - deep learning 파트를 살펴보겠습니다.
Training & Deep learning

Deep learning이 학습할 데이터는 1) 이미지 2) 이미지에 대한 caption 혹은 description <- 이 두 가지의 pair로 이루어집니다.
 그래야 이렇게 deep learning이 discriminator part를 통해서, 숫자로 변환된 이미지를 정답 description에 맞춰 학습할 수가 있게 됩니다.
그래야 이렇게 deep learning이 discriminator part를 통해서, 숫자로 변환된 이미지를 정답 description에 맞춰 학습할 수가 있게 됩니다.
Latent space
이제 latent space를 구성해야 합니다. Latent space란, 잠재 공간 혹은 임베딩 공간으로 불리는 것으로, 쉽게 말해서 데이터를 n가지 특성에 따라 분류해놓은 n-dimensional space입니다.
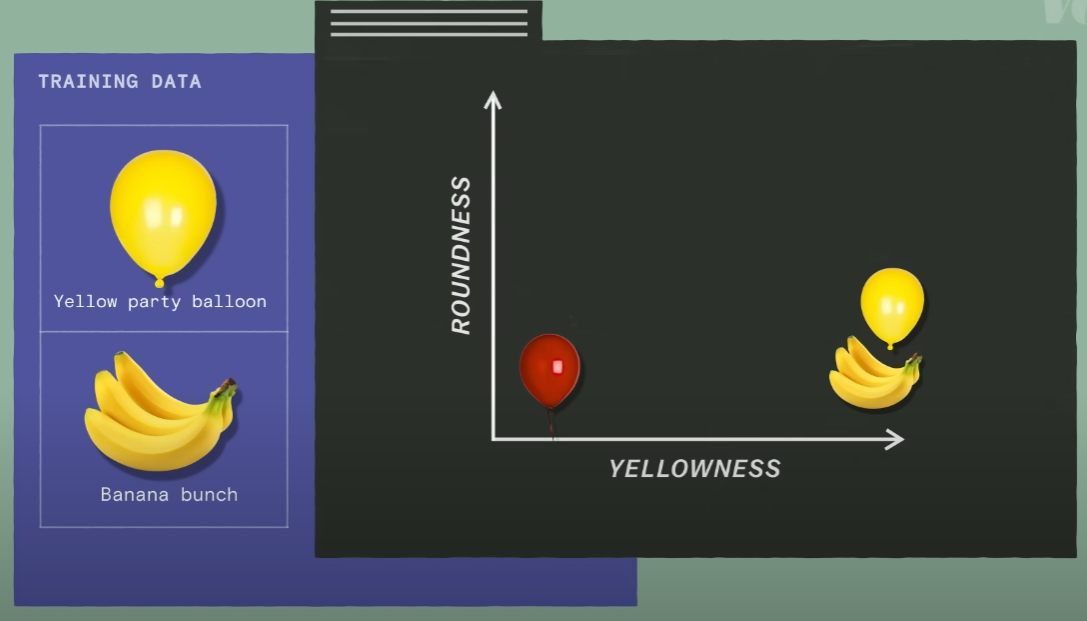 위 사진은 x-axis에는 yellowness를, y-axis에는 roundness를 놓고 red balloon, yellow party ballon 그리고 banana bunch를 latent space에 각각 배치한 것입니다.
위 사진은 x-axis에는 yellowness를, y-axis에는 roundness를 놓고 red balloon, yellow party ballon 그리고 banana bunch를 latent space에 각각 배치한 것입니다.
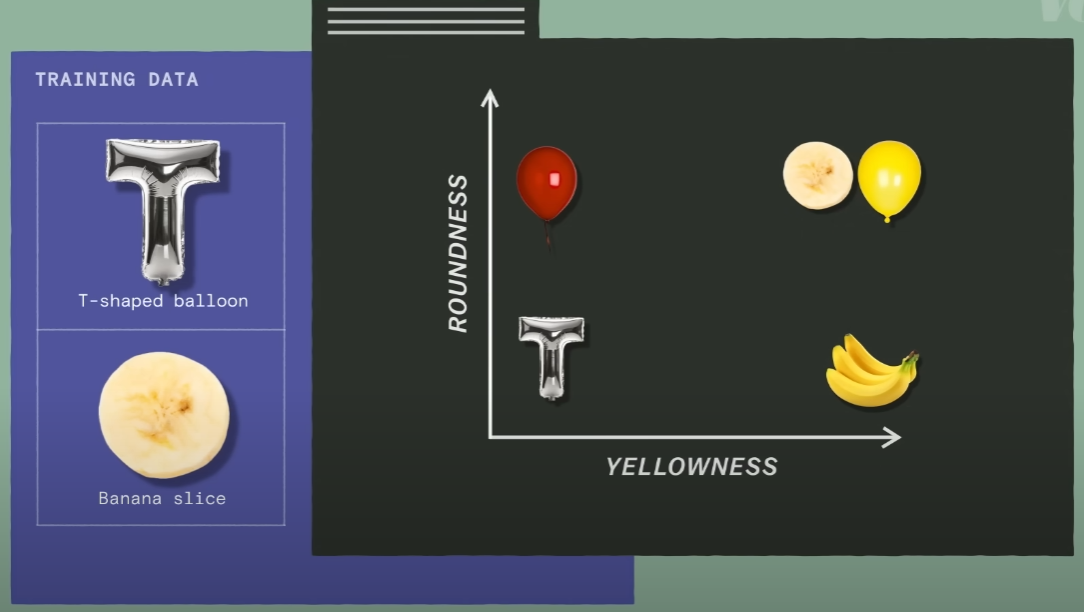 이번에는 T-shaped ballon과, Banana slice 두 개의 데이터가 latent space에 추가되었습니다. 하지만, axis가 두 개 뿐이어서 다른 데이터 포인트들과 잘 구별이 되지 않는 모습입니다.
이번에는 T-shaped ballon과, Banana slice 두 개의 데이터가 latent space에 추가되었습니다. 하지만, axis가 두 개 뿐이어서 다른 데이터 포인트들과 잘 구별이 되지 않는 모습입니다.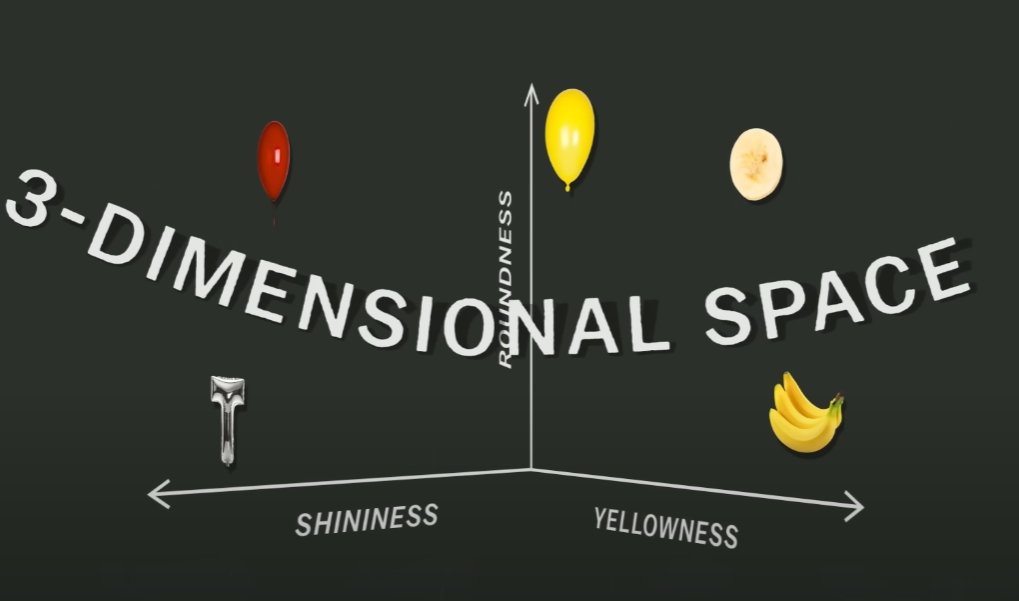 이때 shininess라는 feature를 추가해준다면, 단 세 개의 feature를 통해서 모든 데이터를 latent space에 잘 구별시켜 배치할 수가 있습니다.
이때 shininess라는 feature를 추가해준다면, 단 세 개의 feature를 통해서 모든 데이터를 latent space에 잘 구별시켜 배치할 수가 있습니다.
하지만, text to image 모델들은 그 어떤 text를 넣어도 이미지를 잘 생성해내야 합니다. 예를 들어서, 하마를 입력했을 때, 비슷하게 생긴 곰이 나오지 않도록 latent space를 잘 구성해야 한다는 이야기이고, 이는 feature의 개수가 늘어난다는 것과 같습니다.
따라서 Stable Diffusion의 latent space는 인간이 인지할 수 있는 3D space를 넘어서, 수천 수만의 dimension을 가진 space가 되는 것입니다.
Generation & Output
이제, generation part에서 diffusion model이 어떻게 작동하는지 알아보겠습니다. 이전 세대의 이미지 생성은 대부분 GAN (추후에 설명)을 통해서 이뤄졌던 반면, diffusion method를 통해 이미지를 생성합니다.
핵심 개념은 'diffusion'이라는 키워드에 있습니다.  만약 잉크가 물에 diffuse된다면, 최초로 diffusion이 시작된 점에서 퍼져나가다가 equillibrium (평형 상태)에 도달하게 됩니다. 하지만, 그 도달 시점에서 다시 시작 시점으로 되돌릴 수는 없습니다. Diffusion model은, 이러한 현상에서 착안되었으나 시작 지점으로 되돌아가는 계산법을 학습하는 것을 목표로 하고 있습니다.
만약 잉크가 물에 diffuse된다면, 최초로 diffusion이 시작된 점에서 퍼져나가다가 equillibrium (평형 상태)에 도달하게 됩니다. 하지만, 그 도달 시점에서 다시 시작 시점으로 되돌릴 수는 없습니다. Diffusion model은, 이러한 현상에서 착안되었으나 시작 지점으로 되돌아가는 계산법을 학습하는 것을 목표로 하고 있습니다.
 컴퓨터는 강아지 이미지를 결국 숫자 배열로 인식합니다. 그리고, 이 숫자 배열은 어떠한 조건부 행렬 연산의 연속 (혹은 markov chain)을 통해서 noise image로 바뀔 수 있습니다.
컴퓨터는 강아지 이미지를 결국 숫자 배열로 인식합니다. 그리고, 이 숫자 배열은 어떠한 조건부 행렬 연산의 연속 (혹은 markov chain)을 통해서 noise image로 바뀔 수 있습니다.
 시작 이미지에서 계속 곱해진 markov 연산을 안다면, 반대로 noise 이미지에서 inverse function을 통해 시작 이미지로 되돌릴 수도 있습니다. Diffusion model은 이러한 선형대수적 성질을 이용하여, 나중에 어떠한 이미지를 생성해야 할 때가 되면 이전에 학습했던 noise -> image 연산을 이용해서 무에서 유를 창조하게 되는 것입니다.
시작 이미지에서 계속 곱해진 markov 연산을 안다면, 반대로 noise 이미지에서 inverse function을 통해 시작 이미지로 되돌릴 수도 있습니다. Diffusion model은 이러한 선형대수적 성질을 이용하여, 나중에 어떠한 이미지를 생성해야 할 때가 되면 이전에 학습했던 noise -> image 연산을 이용해서 무에서 유를 창조하게 되는 것입니다.
학습 과정과는 달리 실제로 이용할때는 noise에서 시작하게 됩니다. 물론 어떤 연산을 하게 될지는 input으로 들어왔던 text가 어떤 latent space에 속하는지에 따라서 달라지기 때문에 noise에서 시작을 해도 완전히 다른 이미지가 나오게 되는 것입니다.
Summary
아주 간단히 몇 문장으로 Stable Diffusion의 작동 원리를 요약해보겠습니다.
많은 deep learning model이 그러하듯, 학습의 과정이 필요한데 이 때 학습 데이터는 1) image 2) caption or description for that image 쌍입니다.
데이터들을 학습하면서, 데이터 텍스트 속 객체 단위에 대한 latent space를 구성합니다. 예를 들어, input이 "Apes with bananas"라면, NLP 기법을 이용해 적당히 tokenize과정을 통해 ape와 banana를 latent space에 안착시킵니다.
학습이 끝난 모델에게 "A Korean boy with a glock"이라는 input을 준다면, NLP를 통해서 Korean boy, glock 정도를 분리한 뒤 각각이 속하는 latent space location에 따라 noise로부터 이미지 (output 이미지, 학습 과정에서는 시작 이미지의 역할)를 생성해내기 위해 inverse markov 연산을 계속합니다.
※ 많은 것을 생략하고 축약한 문장이기 때문에 큰 그림만 이해하시면 됩니다.
Diffusion model beats GAN
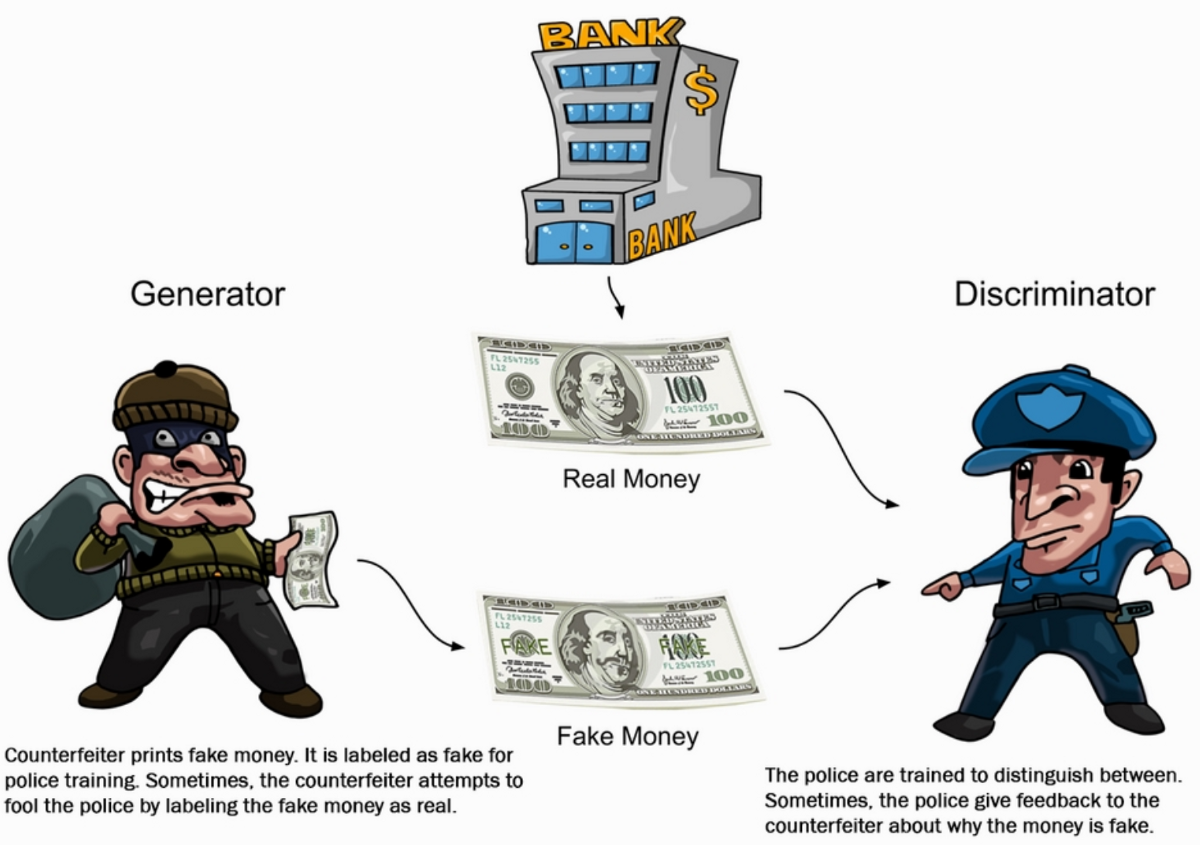
GAN이란 Generative Adversarial Network의 약자로, 한글로는 생성적 적대 네트워크입니다. Generator(생성자)과 discriminator(판별자)로 이루어졌고, 쉽게 생각해서 도둑이 위조 지폐를 만드려고 하면, 경찰은 이를 찾아내려 하기 때문에 도둑은 계속해서 더 잘 위조하게 되면서 생성된 모조품의 성능이 올라간다는 이론에서 착안된 기술입니다.
Deep learning을 아주 크게 나누면 computer vision과 NLP분야로 나눌 수 있는데, computer vision에서 영상 처리 관련하면 거의 99% 활용되던 기술입니다. 여러분이 잘 아시는 딥페이크도 GAN이 활용된 기술입니다.
하지만 2021년에 발표된 Diffusion Models Beat GANs on Image Synthesis라는 논문에서는 Diffusion Model이 GAN을 이겼다고 공언하고 있습니다. 조금 섣부른 말일 수도 있으나, 그만큼 이전 세대에 이미지 생성을 지배했던 GAN을 누를 만큼 압도적인 기법이 등장했다는 표현이 될 것 같네요 :)
What's different from others?
이전 문단에서 여러번 설명 드렸지만, 기존의 기술들은 대부분 GAN기반인 반면 Stable Diffusion은 diffusion 기법을 쓴다는 것이 가장 큰 차이점입니다.
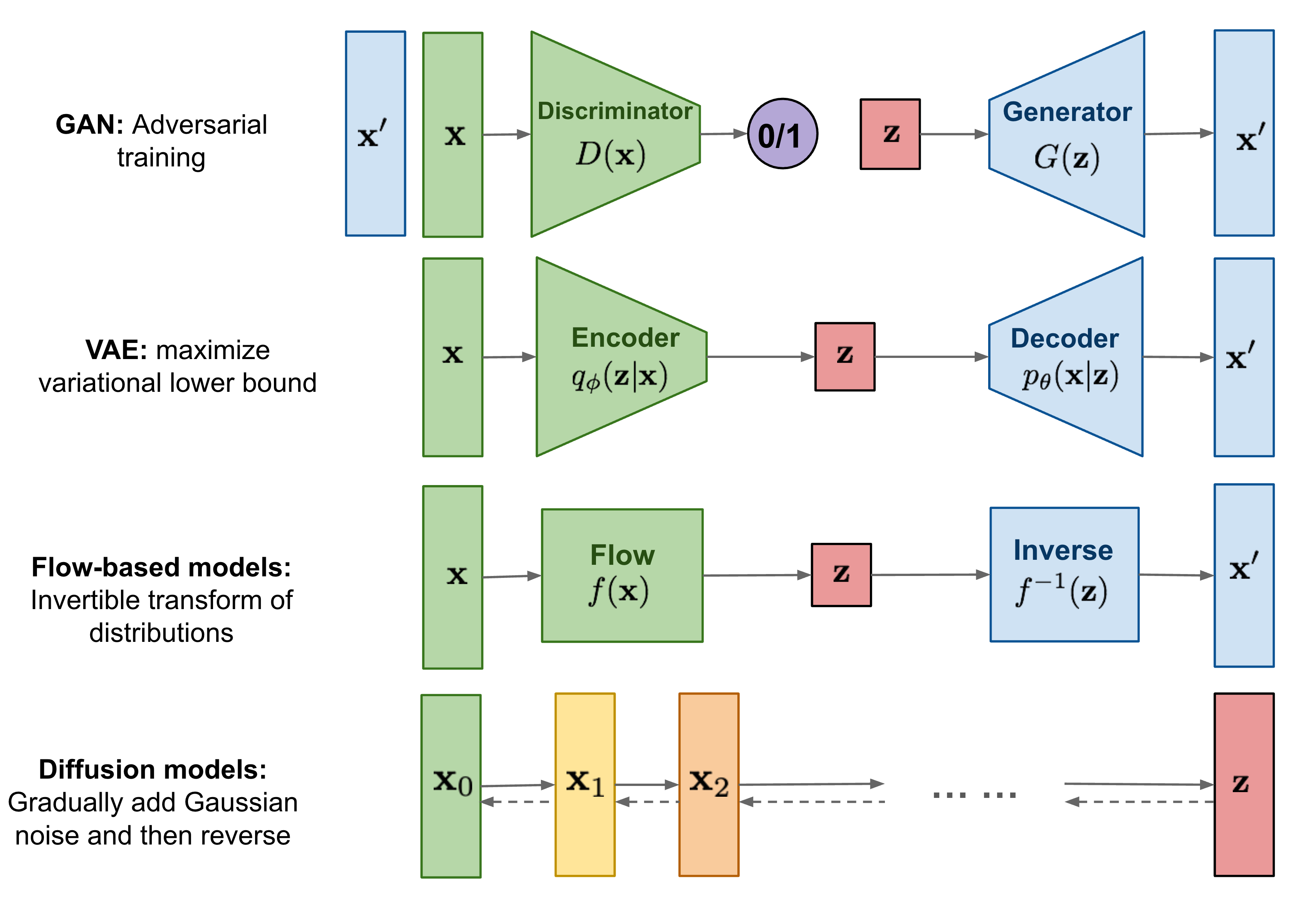
위에서 간단히 설명드린 GAN 외에도, VAE(Variational AutoEncoder)라고 하는 굉장히 유명한 network를 기반한 이미지 생성 방식도 존재합니다. 또, Flow-based는 저도 이 사진을 찾으면서 처음 알게된 모델이지만, 도식상 분포 자체의 역행렬을 이용해서 noise로부터 이미지를 생성해내는 방법인 것 같습니다.
자세히 보셔야 할 것은 빨간 박스모양의 'z' 입니다. GAN에서의 Z-vector는 랜덤 벡터를 뜻하는 것으로, 위에서 설명했던 noise 이미지에 해당하는 벡터입니다. (아주 중요한 파트입니다!)
다른 기법들과 달리 diffusion 기법만 z-vector가 중앙에 위치하지 않고 x0 이미지와 정 반대편에 있습니다. Diffusion은 최초의 이미지에서 Gaussian noise를 계속 더하면 결국 noise 이미지에 도달하고, 이 연산을 반대로 하면 원래 이미지로 돌아간다는 원리를 이용했음이 포인트입니다.
OpenAI사가 공개한 또다른 SOTA(the state of the art) 모델인 DALL-E와도 명백한 차이점이 있습니다. DALL-E는 GPT-3를 이용해서 input text를 NLP를 분석한 뒤 이에 상응하는 가장 가능성이 높은 image를 예측하는 전형적인 deep learning의 방식이라면, Diffusion은 Gaussian noising의 역연산을 통해 이미지를 생성합니다.
Structure
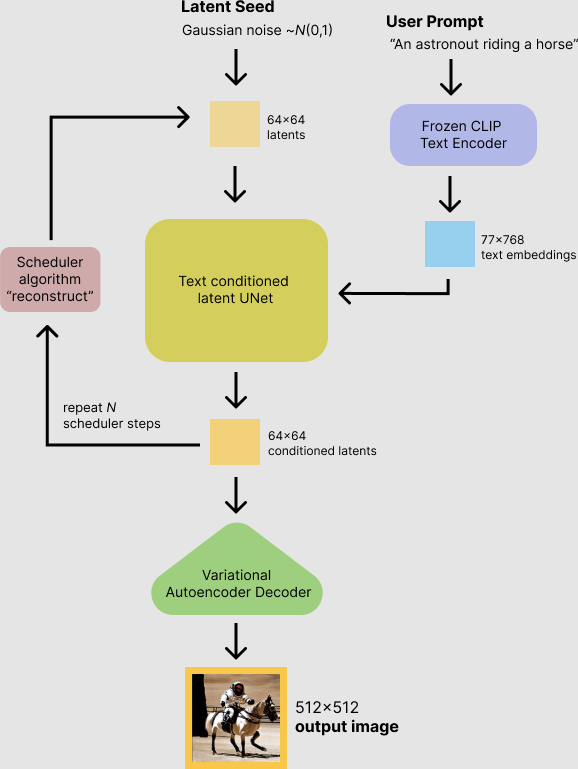
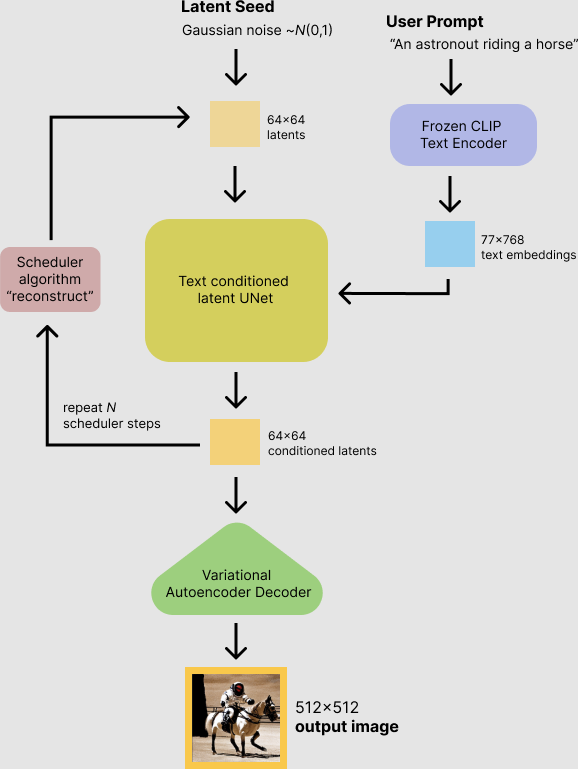
지금까지 diffusion model에 대해서 정말 많은 힘을 썼지만, 사실 Stable Diffusion은 그 중에서도 latent diffusion model입니다. Diffusion의 원리에 대해 이해하셨다면, 이 또한 어렵지 않습니다.
위에서 latent space를 설명하면서, 많은 데이터들을 특징별로 구분짓는 공간이라고 했습니다. Latent는 어떤 데이터의 속성 정도를 의미한다고 보시면 됩니다. 따라서, latent diffusion model은 원본 이미지에 대해서 diffuse하는 것이 아니라, 원본 이미지의 latent vector에 대해서 diffuse를 하게 되는 것입니다.
연산의 대상이 이미지의 원본이 아닌, 원본 이미지의 latent vector라는 점을 제외하면 방식 자체에는 큰 차이가 없습니다. 다만, 연산 대상이 다른 만큼 중간 과정에 조금 추가되는 것이 있습니다.
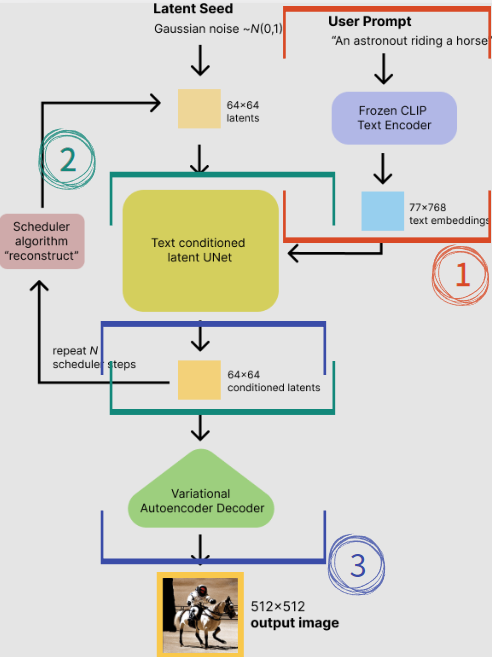
수학적으로 깊이 들어가면 어려우나, 그것만 배제한다면 절대로 어렵지 않습니다. 제가 매우 straightforward하게 설명해보겠습니다.
① User Prompt
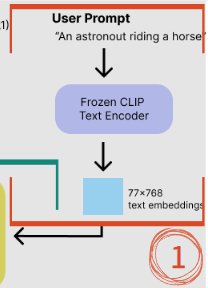
빨간색 박스 부분입니다. 사용자가 input으로 친 text를 NLP를 통해 word embedding을 진행합니다. 이 때 embedding하기 위해 CLIP이라는 text encoder를 사용합니다.
결국 컴퓨터는 한글, 영어같은 문자를 알아들을 수 없기 때문에, 숫자로 변환해야 하기 때문입니다. 또한, 예시처럼 input이 "An astronout riding a horse"인 경우, "An" / "a"와 같은 조사는 이미지 생성에 있어서 불필요하기 때문에 자연어 처리를 해주는 것이 필수적입니다.
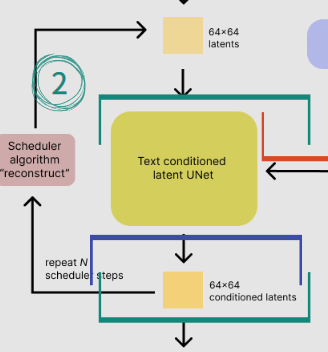
② Text Conditioned Latent UNet
UNet은 본래 bioinformatics에서 semantic segmentation을 위해 개발된 network입니다. (아주 유명하고 중요한 network니 이에 대해 잘 모르시는 분들은 UNet에 대해서도 공부해보시는 것을 추천드립니다.)
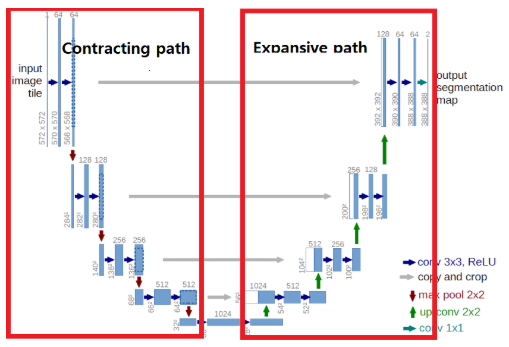
UNet에는 논문 내에서는 각각 Contracting / Expansive path라고 하는 결국 Encoder / Decoder part가 존재합니다. 중간에 둘 사이를 가로지는 화살표는 encoder part에서 손실되는 정보를 살려주기 위해 decoder part에 concatenation시켜주는 부분입니다.
UNet은 텍스트 임베딩에 따라 조건화된 채로, random latent vector를 반복적으로 denoise합니다.
여기서 조건화란, 수학에서 말하는 조건부확률과 비슷한 이치입니다. 만약 UNet이 ①에서 처리된 text embedding과 완전히 별개로 noise를 denoise하는 작업을 한다면, 우리가 원하는 이미지가 아닌 형체를 알아볼 수 없는 완전히 무작위의 이미지가 생성될 것입니다.
Text embedding을 연산 전에 고려해야, latent space에서 어디에 해당하는지를 찾고 그에 따른 적절한 denoise 연산을 실행할 것 (Summary 바로 위 설명 참고)입니다.
UNet의 output인 noise residual (노이즈 잔차)는 denoised latent image를 계산하기 위해 사용됩니다. 그림 ②의 좌측을 보시면, output이 처음 UNet의 입력으로 다시 들어가는 것을 보실 수 있습니다. 이 과정에서 그대로 들어가는 것이 아닌 scheduler algorithm을 사용하는데, 이번 포스트의 범위에서는 벗어나는 것으로 궁금하신 분들은 따로 찾아보시길 바랍니다.
PNDM 스케줄러(기본적으로 사용)
DDIM 스케줄러
K-LMS 스케줄러
③ VAE (Variational AutoEncoder)
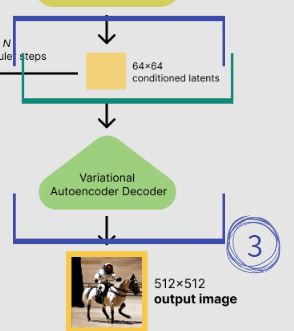
UNet을 통한 수 차례의 denoise가 끝나면, 만약 일반 diffusion model이라면 여기서 끝나야 할 것입니다.
하지만 latent diffusion model은 input과 output이 전부 원본이 아닌 latent이기 때문에, output vector (= latent)를 이미지로 decode해주어야합니다. 여기서 사용되는 것이 VAE입니다.
What's Different from Others?에서 잠깐 설명하고 지나갔었는데, 여기서 decoder part만 사용하는 것으로, z는 latent, 즉 직전까지 ②에서 UNet의 output으로 나왔던 latent에 해당하게 됩니다.
이렇게 VAE의 decoder를 이용해서 latent를 우리가 원하는 이미지 사이즈로 decode하면, 이것이 바로 생성된 이미지가 되는 것입니다.
짜잔!
Try It!
Web demo
모든 동기부여와 흥미는 직접 해보는 것에서 시작됩니다.
HuggingFace.co <- 이 링크를 클릭하시면, 온라인에서 바로 Stable Diffusion을 사용해보실 수 있습니다.
빈 칸에 원하는 영어 문장 (되도록 명사형으로)을 작성하고, 오른쪽의 Generate Image 버튼을 클릭하면 끝입니다.

Code template
만약 python에서 직접 구동시키고 싶으시다면, 아래에 있는 코드를 실행시키시면 됩니다. diffusers 패키지를 사용한 것으로, 실습 환경은 google colab입니다.
주의할 점
1) Google colab으로 진행할 경우, 런타임 -> 런타임 유형 변경 -> None이 아닌 GPU로 설정해야 합니다. 만약 google colab을 이용하시지 않는 경우, google colab 관련 코드는 제외하고 실행시키셔야 합니다.
2) HuggingFace에서 token을 받아야 합니다. 최초 실행 시
위와 같은 창이 발생하면, 파란색 링크로 들어가 회원가입을 한 뒤 프로필에서 토큰을 만들어 복사 / 붙여넣기하면 됩니다.
중간에 에러 화면이 발생하면, 1)과 2)를 모두 해결한 후에 다시 실행시키면 됩니다.
Stable Diffusion python code with diffusers package
!nvidia-smi
!pip install diffusers==0.3.0
!pip install transformers scipy ftfy
!pip install "ipywidgets>=7,<8"
from google.colab import output
output.enable_custom_widget_manager()
from huggingface_hub import notebook_login
notebook_login()
import torch
from diffusers import StableDiffusionPipeline
# make sure you're logged in with `huggingface-cli login`
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16, use_auth_token=True)
pipe = pipe.to("cuda")
from torch import autocast
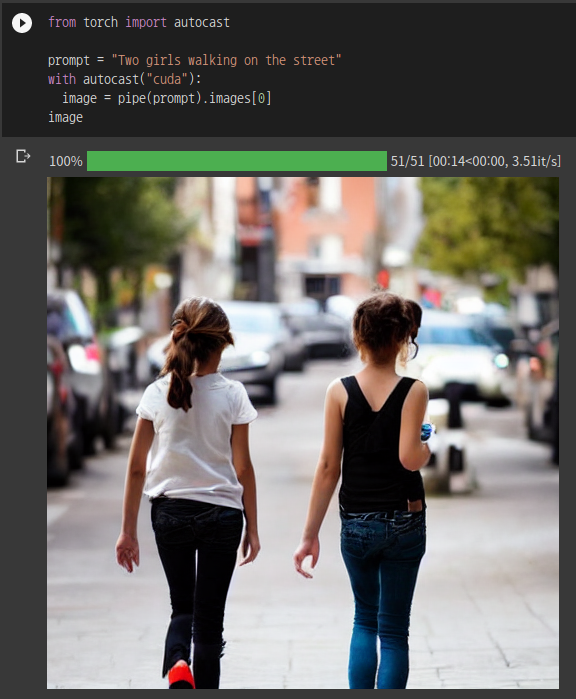
prompt = "Two girls walking on the street" # enter the prompt you want
with autocast("cuda"):
image = pipe(prompt).images[0]
imageStructure에서 볼 수 있듯이, 맨 위를 보면 Latent Seed가 주어지는데, 이 seed는 random입니다. 따라서, 매번 실행할 때마다 같은 텍스트여도 다른 결과가 만들어집니다.
만약 같은 결과를 보고 싶다면, 아래 코드를 통해 seed를 수동으로 설정할 수 있습니다.
또한 pipe에서 num_inference_steps argument는 말 그대로 추론 횟수입니다. Default값은 50이고, 더 작아질수록 속도는 빨리지지만 정확도는 낮아지고 더 커질수록 속도는 느려지나 더욱 정교해집니다.
from torch import autocast
generator = torch.Generator("cuda").manual_seed(1026)
# enter the prompt as you want
prompt = "A high tech solarpunk utopia in the Amazon rainforest"
with autocast("cuda"):
image = pipe(prompt, num_inference_steps=60, generator=generator).images[0]
imageConclusion
Stable Diffusion 자체는 공개된지가 꽤 되었으나, stability사에서 공식적으로 공개한 것은 무척 최근입니다. 맨 처음 공개 사실을 알고 유튜브를 봤을땐 정말 많이 놀랐고, 또 세상의 여러 사람들이 변형해서 딥페이크나 inpainting, collage 등의 기능을 구현한 것을 보고는 더더욱 놀랐습니다.
DALL-E랑은 다르게 코드를 오픈소스로 공개하니 이런 선영향이 금방 AI계의 퍼진 것 같네요 :) 너무나 기쁜 일입니다.
최근 동료와 sketch를 image로 변환해주는 AI를 웹에서 쓸 수 있게 해주는 프로젝트를 진행하고 있는데, 우연히 이 과정에서 알게 된 기술을 소개하게 되면서 더욱 흥미가 붙어 열심히 쓴 포스트가 된 것 같습니다.
수많은 사람들이 수많은 시간을 들여 완성한 AI를 방에서 클릭 한 번으로 사용할 수 있다는 사실은 정말 감사한 일입니다. 모두 행복한 AI 공부 되셨으면 좋겠습니다 ~~!

14개의 댓글

안녕하세요, 글 잘 읽었습니다. 덕분에 Stable diffusion에 대한 직관과 개념을 얻을 수 있어서 좋았습니다. 그런데 Latent Stable Diffusion을 Stable Diffusion의 발전된 형태라고 봐도 될까요? 어떤 문서에서는 Latent Stable Diffusion이 기존 Stable Diffusion보다 더 빠르거나 성능이 좋다는(speed boost) 이야기가 있었던 것 같은데 그렇게 이해해도 괜찮을지 한번 여쭙고 싶습니다.




알기 쉽게 설명해주셔서 감사합니다^^