- 어셈블리어는 심볼릭언어이다. 고로 아래의 코드들은 컴퓨터에 따라 동작 유무가 달라질수 있다. 아래 예제는 Intel Core i5, 카탈리나 버전에서 예제를 진행하였다.
- 64비트, intel, 맥 운영체제라면 잘 실행 될것으로 예상된다.(만약 윈도우나, 32비트라면 안될거에요!)
어셈블리 특징 짚고 넘어가기
1. 똑같은 로직이여도 컴퓨터 아키텍쳐에 따라 어셈블리어 코드가 다르다.(이식성이 낮다)
2. 심볼릭 머신코드 특징을 가진다. (1대 1대응이 되는코드)
Assembly란?
cpu 에는 해당 프로세서에 명령을 내리기 위한, 고유의 명령어가 마련되어 있는데, 이 명령어들을 기계어 라고 한다. 기계어는 각 기계마다 규약된 숫자들의 규칙 조합으로, 기계어로 프로그래밍을 하기엔 매우 난해함. 가독성이 떨어지는 숫자를 대체하고자 기계어와 일대일 대응관계를 형성한 언어가 어셈블리 언어이다
우리가 어셈블리를 알면 좋은점, 찾아보기....... 디버거를 쓰기 마련이다.
그떄, 작성한 언어가 어떤 언어이든, 기계에 입력되어을때, 어셈블리어로 변환 되게 되는데, 이 기계어를 다시 어셈블리어로 바꿀수 있다.
0. 어셈블리 공부전, 기본 지식.
기계어는 cpu에 따라 다르게 동작되는데, 이 cpu가 어떤일을 하는지 짚어보고 가기를 권한다.
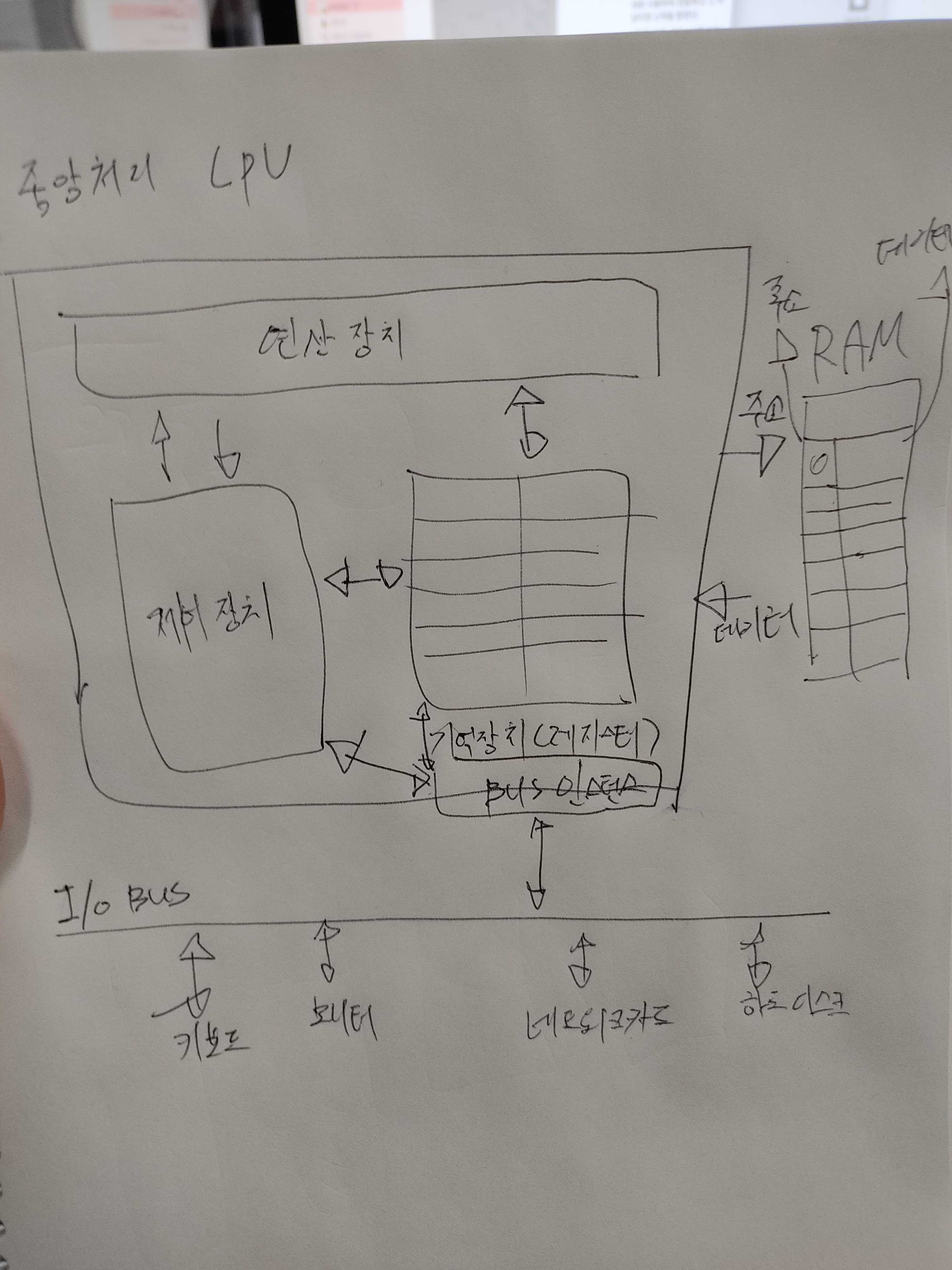
중앙처리장치(cpu)의 구성요소
-
제어기능, 연산기능, 기억기능 3가지를 가지고 있다.
-
제어기능(intel core i7) : 컴퓨터의 모든 장치들의 동작을 지시하고 제어함, 주기억장치에서 읽어 들인 명령어를 해독 해당 장치에게 제어신호 보냄.
(제어장치의 구성요소 : 명령 해독기, 부호기,제어 주소 레지스터, 제어버퍼레지스터, 제어기억자치 등이 있다.) -
연산기능(alu) : 제어장치의 명령을 받아 실제 연산을 수행하는 장치(가산기, 누산기, 보수기, 데이터 레지스터 등이 잇다.)
-
기억기능 : 제어,연산 기능을 사용할떄 연산의 중간 결과값등을 일시적으로 저장할 공간이 필요하다.
레지스터
eax(32비트) == rax(64비트) 는 같은 주소의 레지스터이다, 다만 비트수가 다르기때문에, 사용될 비트 값에 따라 eax 또는 rax를 선택해서 사용하면 된다.
- 처리중인 데이터나 처리 결과를 임시 보관하는 cpu내의 기억장치.
- 범용레지스터 : EAX(산술 연산에 사용), EBX(특정 주소저장), ECX(숫자를 카운터 할때 사용되거나, 계산할떄 임시 저장소로 사용되기도 한다.), EDX(일반 자료저장)
- 포인트 레지스터 : 프로그램 실행 과정에서 사용되는 주요 메모리 주소값을 저장.(EBP,ESP,EIP)
- 인덱스 레지스터 : 데이터를 복사할 때 출발지와 목적지 주소를 가리키는 레지스터 (EDI,ESI,EFLAGS)
- rdi, rsi, rdx, rcx, r8 ~ r15를 순서대로 사용하길 권장하며, 그 이상의 매개변수가 전달돼야 할 땐 스택을 통해 전달한다.
문법 종류
- CPU 종류마다 고유한 어셈블리어를 사용한다.
- 어셈블러 종류에 따라 채택 가능한 문법이 다르다.
- GAS(GNU Assembler) - AT&T 문법
- NASM(Netwide Assembler) - Intel 문법
- MASM(Microsoft Macro Assembler) - Intel 문법
이외에도 어셈블러는 TASM, YASM 등 여러 종류가 있다.
필자가 사용할 문법은 nasm이다.
그 외
가볍게 이런게 있다고 넘어가고 예제 보면서 이해하면 좋아요!
- 어셈블리에서 하드웨어에 직접적으로 접근할 떄, syscall이라는 명령어를 사용한다. syscall 정리
- c에서 strdup, write, read함수를 사용하다. 에러가 발생하면, 자동으로 전역변수 errno 에러 번호가 담기는데. 이러한 처리는 어셈블리어에서 직접 errno변수에 에러넘버를 넣어주어야한다.
1. 어셈블리 특징
어셈블리어 형식
intel cpu 점유율이 가장높기에 확률적으로 intel일 경우가 많겠지만. 혹시 모르니, 시작전에 확인을 해보고 넘어가자.
cpu가 다르면, 문법이 다를 수 있다. 참고하세요!

- 형식 : opcode,오퍼맨드1,오퍼랜드2
- intel 문법 : opcode [Destination][Source]
- AT&T 문법 : opcode [Source][Destination]
문법은, (opcode = mov) 라는 이동 명령을 받았을 때 source파일을 destination에 넣어준다. 라고 이해하고 넘어가면 쉽게 이해가 된다.
- opcode : mov,add,cmp 등 명령어들
- 어셈블리가 끝날 때 반환값(return값)은 항상 rax레지스터의 값으로 반환한다.(rax는 함수는 syscall을 호출할떄도 syscall 할 주소를 넣어주는데 사용하기도 한다.)
- 함수 호출 규약에 따라 Callee(호출당하는 함수)는 RBX, RSI, RDI, RBP를 사용 후 초기값으로 돌려놓아야 한다. (다른분들 블로그를 보니, 초기화해야한다고 하던데 아무리 찾아봐도 왜 초기화 해야하는지 이유를 알수 없었음.. 어셈블리를 다룰때 따로 초기화 안하는거 같은데, 저는 이거 무시하고 넘어갔어요.)
- 참고사이트
ASM이란?
ASM은 데이터베이스 구성 시 기본이 되는 디스크를 효율적으로 관리하기 위하여 오라클 10g에서 새로 선보인 데이터베이스 서비스이다.
2. 어셈블리 자료형 이름
- BYTE 1byte char
- WORD 2byte short
- DWORD 4byte int
- QWORD 8byte double
3. 어셈블리어 레지스터 및 스택
어셈블리어에서 사용되는 변수.
레지스터의 변수들은 cpu에 따라 64bit라면 rax, eax같이 64비트와 더 작은 비트의 레지스터까지 사용할 수 있고, 32 bit라면,rax같이 64비트 레지스터는 사용할 수 없다. 또한 컴퓨터의 운영체제 따라 리눅스의 호출규약과 윈도우의 호출규약 같은 것들도, cpu 회사별로 특징이 나뉘어 진다. (이식성이 낮다.)
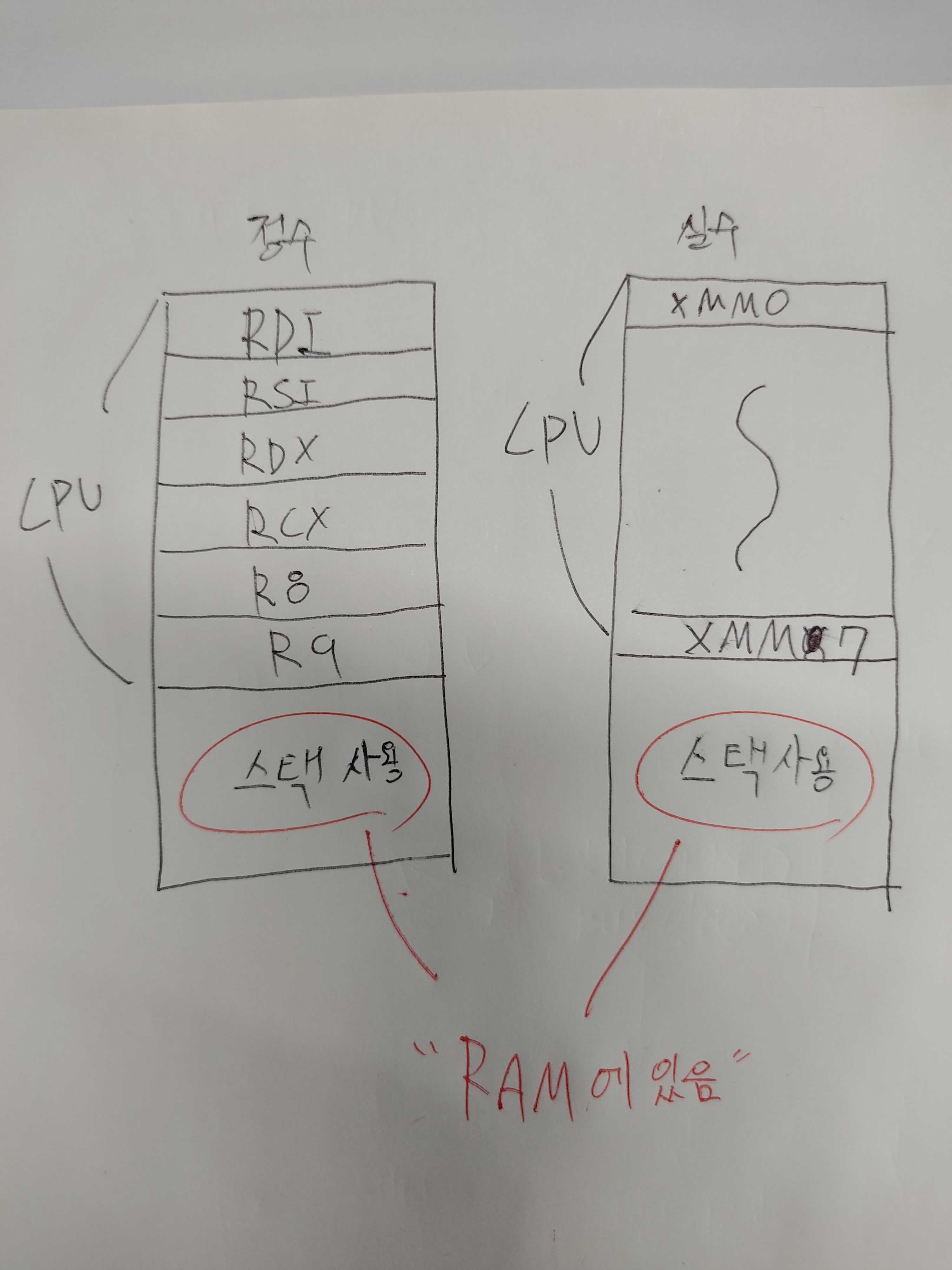
1). 64비트 리눅스의 호출 규약
정수 타입의 파라미터를 전달할 때(mov해서 레지스터에 값넣어줄떄를 말함.) 는 순서대로 RDI, RSI, RDX, RCX, R8, R9까지 6개의 레지스터를 사용하고 7개 이상이면 스택을 통해 전달하고, 실수 타입의 파라미터의 경우는 XMM0 ~ XMM7까지 8개를 순서대로 사용하고 그 이상이면 스택으로 전달한다.
r12, r13, r14, r15, rbx, rsp, rbp은 비휘발성 나머지는 휘발성!
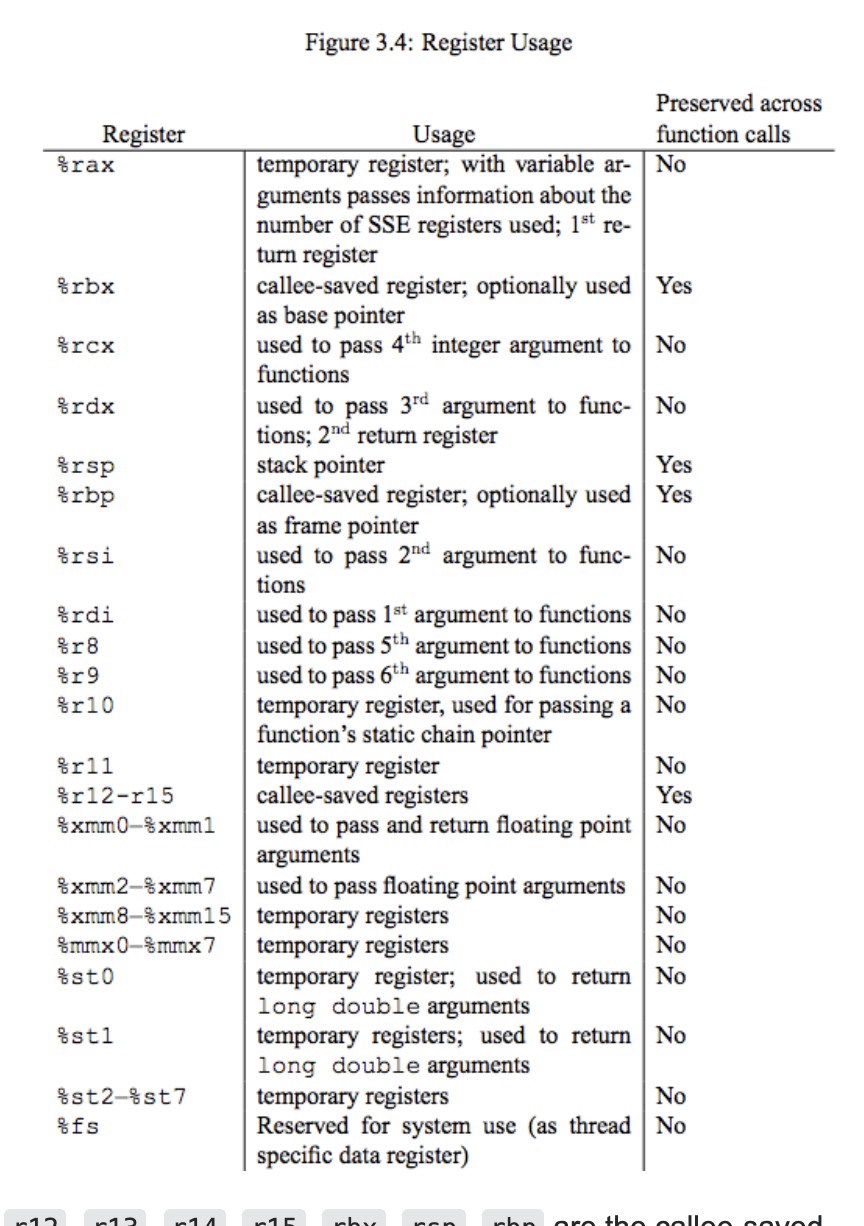
2). 64비트 윈도우의 호출규약
반면, 윈도우는 64비트 모드에서 파라미터를 전달할 때 레지스터 4개만 사용합니다. 정수 타입의 경우는 순서대로 RCX, RDX, R8, R9를 사용하고 나머지는 스택으로 전달합니다. 실수의 경우는 XMM0 ~ XMM3까지 4개를 순서대로 사용하며 나머지는 스택으로 전달합니다.
아래 그림처럼, 레지스터들은 cpu에 있지만 스택은 램에 있기때문에 상대적으로 스택의 속도가 느리다.
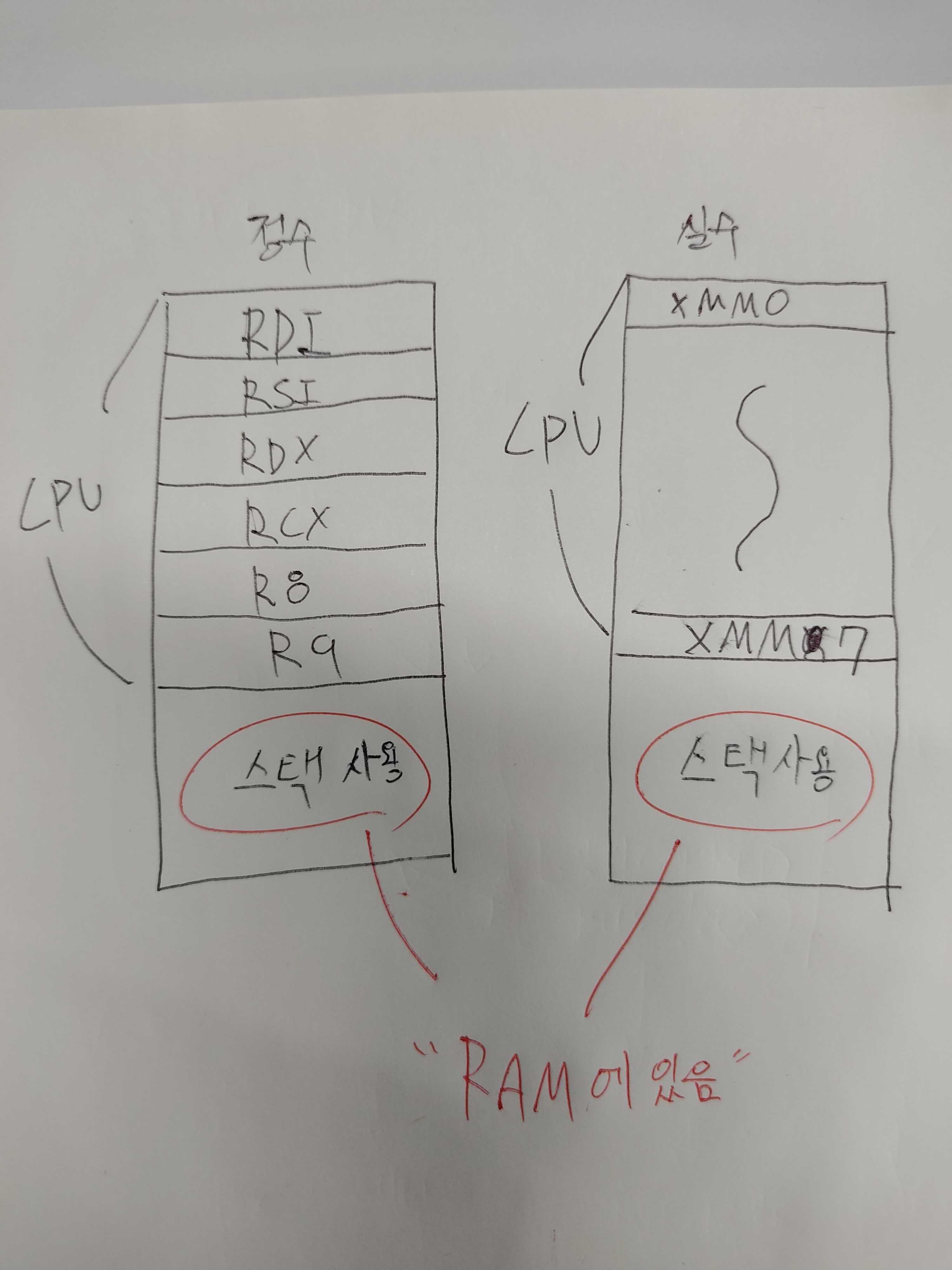
중요한 내용임 : 레지스터를 사용 하는게 더 빠르겠지만, call이나, syscall을 할때 r12, r13, r14, r15, rbx, rsp, rbp을 제외한 나머지 레지스터들은, 비휘발성의 특징을 가진다. 그리고 콜 한 함수들을 disassemble해서 뜯어보니, 그 안에서도 많은 레지스터들을 사용하기 때문에 call을 한순간 부터 레지스터에 저장한 값들이 언제 사라져도 이상한 일이 아니다, 바로 사용하는 값들이 아니라면, push해서 스택에 저장하는게 혹시모를 에러를 방지하는데 도움이 될거같다.**
4. 비트 별 레지스터 변수
위에서도 설명했듯이 저장될 값의 비트수에 따라 사용되는 레지스터가 다르다.
- 아래 표는 레지스터의 비트별 규정된 변수이름아이다.
| 레지스터 | accumulator | base | counter | data | stack pointer | stack base pointer | src | dest |
|---|---|---|---|---|---|---|---|---|
| 16bit | AX | BX | CX | DX | SP | BP | SI | DI |
| 32bit | EAX | EBX | ECX | EDX | ESP | EBP | ESI | EDI |
| 64bit | RAX | RBX | RCX | RDX | RSP | RBP | RSI | RDI |
1) 64비트의 레지스터
1. 범용 레지스터
- RAX (Extended Accumulator Register)(Accumulator) : 더하기, 빼기 등 산술/논리 연산을 수행하기도 하며 함수의 return값이 저장되고 syscall 할때 불러올 함수 주소도 저장된다.
시스템콜 함수를 사용하려면 RAX에 함수의 syscall 번호를 넣어준다. - RBX (Extended Base Register)(Base) : 메모리 주소를 저장하기 위한 용도로 사용된다.
- RCX (Extended Counter Register)(Count) : 반복문에서 카운터로 사용되는 레지스터. 고급언어 for문의 i 와 같은 역할이지만, 다만 ECX는 미리 반복 값을 정해두고 명령어를 사용할 때마다 값이 하나씩 줄어든다는 점이 다르다.
syscall을 호출했던 사용자프로그램의 return 주소를 가진다. - RDX (Extended Data Register)(Data) : 다른 레지스터를 서포트하는 여분의 레지스터. 큰 수의 곱셈이나 나눗셈 연산에서 EAX와 함께 사용된다.
2. 인덱스 레지스터
- 인덱스로 사용, 그 외에도 메개변수로써의 역활도 한다.(예제를 보면 이해쉬움)
- RDI (Destination Index) : 문자열 관련 Instruction 사용 시, Destination
- RSI (Extended Source Index) : 문자열 관련 Instruction 사용 시, Source
3. 포인터 레지스터
RSP (Stack Point) : 스택프레임에서 스택의 끝 지점 주소(현재 스택 주소)가 저장된다.
(즉, 데이터가 계속 쌓일 때 스택의 가장 높은 곳을 가리킨다.
push, pop 명령을 통해 RSP 값이 위아래로 8바이트씩 이동하면서 스택프레임의 크기를 변경하게 된다.)
RBP (Base Point) : 함수가 호출되면 스택프레임이 형성 되는데 이 스택스레임의 시작 지점 주소(스택 복귀 주소)가 저장된다.
5. 섹션별 정리
data section
- 데이터,상수 선언을 위한 공간
- 런타임에 변하지 않는 데이터들
- 상수, 파일 이름 ,버퍼 사이즈를 여기서 선언함.
section.databss section(Block starting Symbol)
- 변수 선언을 위한 공간
section.bsstext section
- 실제코드를 실행하는 공간.
section.text
global _start
_start:global : 기본적으로 어셈블리어는 모든 코드가 private 이다. 다른 모듈이 해당 코드에 접근할 수 있게 하기 위해서 global instruction을 이용하여 심볼에 다른 코드가 접근할 수 있도록 해 준다.
주석
- 세미클론으로 주석 처리
5. 어셈블리 명령어
push
- push : 스텍에 데이터를 저장하는데 많이 쓰인다.
- 사용법 : push eax (스택에 eax의 값을 스택에 저장한다.), push 20 (즉석값인 20을 스택에 저장한다.), push 401F47(메모리 오프셋 401F47의 앖을 스택에 저장한다.)
pop
- pop : push와 반대로 스택에서 데이터를 꺼내는데 쓰인다.
- 사용법 : pop eax (스택에 가장 상위에 있는 값을 꺼내 eax에 저장함)
mov == 기계로 대칭
- mov : 메모리나 레지스터의 값을 옮길때 쓰인다.
- 사용법 : Mov eax,ebx(ebx 레지스터의 값을 eax로 옮긴다.), Mov eax,20(즉석값인 20을 eax레지스터에 옮긴다.), Mov eax,dword ptr[401F47] (메모리 오프셋 401F47의 갑슬 eax에 옮긴다.)
Lea
- (레지스터만 사용가능) 주소값을 입력하는데 사용된다.
- mov도 주소값을 이용할 수 있지만 lea가 따로 있는 이유는 아래와 같다.
mov eax, ebp sub eax, 4lea eax, dword ptr ss:[ebp-4] - mov두줄로 할거, 한줄로 해결할수 있음.
Inc
- 레지스터의 값을 1 증가 시킨다.
- Inc eax : eax 레지스터의 값을 1 증가 시킨다.
Dec
- 레지스터의 값을 1감소 시킨다.
- Dec eax (Eax 레지스터의 값을 1감소 시킨다.)
Add
- 레지스터나 메모리의 값을 덧셈할때 쓰임.
- Add eax,ebx (eax레지스터에 ebx를 더함.)
- Add eax,50 (eax레지스터에 50을 더함.)
- Add eax,dword ptr[401F47] (Eax 레지스터에 메모리 오프셋 401F47의 값을 더한다.)
Sub
- 레지스터나 메모리의 값을 뺄셈할때 쓰임.
- Sub eax,ebx (eax레지스터에서 ebx값을 뻄)
- Sub eax,50 (eax레지스터에 즉석값 50을 뺀다.)
- Sub eax,dword ptr[401F47] (Eax레지스터에서 메모리 오프셋 401F47의 값을 뺀다.)
Call
- 프로시저 호출할떄 사용.
- 프로시저란, 함수라고 생각하면 편하다. (함수의 이름 같은 느낌.)
- Call dword ptr[401F47] (메모리 오프셋 401F47)을 콜한다.
Ret
- 콜한 지점으로 돌아간다.
Cmp
- 레지스터와 레지스터 혹은 레지스터 값을 비교 하기 위하여 씅니다.
- 사용법 : Cmp eax,ebx(Eax레지스터와 Ebx레지스터의 값을 비교한다.), Cmp eax,50 (Eax와 50 을 비교함.), Cmp eax,dword ptr[401F47](Eax 레지스터와 메모리 오프셋 401F47의 값을 비교함.)
cmp 플레그 조건
Jmp
- 특정한 메모리 오프셋으로 이동할때 쓰인다.
- 사용법 Jmp dword ptr[4017F47] 메모리 오프셋 4017F47로 점프함.
- 조건부 점프를 할수도 잇음. (필요하면 찾아보길.)
and, or, xor, not연산자
- and : AND EAX,10(EAX의 1010중 양쪽다 1인 부분만 저장됨.)
- or : OR EAX,10 (EAX중 1인 부분과 1010 중 한쪽이라도 1이면 1로 저장 )
- xor : XOR EAX,10 (둘중 하나만 1일때 저장됨.)
- not : NOT EAX,10 (0과 1 의 ㄱ저장 값들을 반전 시킴.)
xor의 예제 :
이런식으로 하게 되면, eax의 값들은 모두 0으로 초기화 되게 된다.xor eax,eax
보다 빨라서 0으로 초기화 시킬떄 많이 사용된다고 한다.mov eax,0레지스터가 뭐지???
컴퓨터에서 데이터를 영구적으로 저장하기 위해서는 하드디스크를 이용해야하고, 임시적으로 저장하는 장소를 메모리(ram)을 이용한다. 하지만, 메모리로 연산의 결과를 보내고, 영구적으로 저장할 데이터를 하드디스크에 저장해야하는 등의 명령을 처리하기 위해서는 이들에 대한 주소와 명령의 종류를 저장할 수 있는 기억 공간이 하나더 필요하다. 그리고 이 공간은 무리 없이명령을 수행하기 위해 메모리보다 빨라야한다. 바로 이런 역활을 하는게,cpu옆에 붙어 있는 레지스터이다. CPU 처리를 위해 데이터를 레지스터라는 기억 공간에 저장해두었다가 CPU에서 처리를 하고 해당 결과값 역시 레지스터에 저장하게 된다.
레지스터는 공간은 작지만, cpu와 직접 연결되어 있으므로 연산 속도가 메모리 보다 실제 수십배에서 수백배 까지 빠르다.
그리고 cpu는 자체적으로 데이터를 저장할 방법이 없기 떄문에 메모리로 직접 데이터를 전송할수 없다.
떄문에 연산을 위해서는 반드시 레지스터를 거쳐야 하며, 이를 위해서는 레지스터는 특정 주소를 가리키거나 값을 읽어올 수 잇다.
프로시저 vs 함수
함수(function) : 특정 계산을 수행하며 리턴값이 있다. 반드시 수식 내에서만 사용할 수 있으며 함수 단독으로 문장을 구성할 수 없다.
함수는 기능을 수행해서 어떠한 목적(결과)을 도출해 내는 것이다.
프로시저(procedure) : 특정 작업을 수행하며 리턴값이 없다. 리턴값이 없기 때문에 수식 내에서는 사용할 수 없으며 단독으로 문장을 구성할 수는 있다.
프로시저는 수행하는 절차 그 자체를 목적으로 하는 것이다.
따라서 함수는 프로시저를 포함하고 있는 개념이다. 이러한 프로시저를 포함한 함수들이 여러개 모여 하나의 프로그램을 구성하는 것을 절차지향적 프로그래밍이라고 한다.
