1. 데이터 리터러시
☑️ 데이터 리터러시의 정의
- 데이터를 읽는 능력
- 데이터를 이해하는 능력
- 데이터를 비판적으로 분석하는 능력
- 결과를 의사소통에 활용할 수 있는 능력
데이터 리터러시는 1)데이터 수집과 데이터 원천을 이해하고 2)주어진 데이터에 대한 다양한 활용법을 이해하고 3)데이터를 통한 핵심지표를 이해하는 것
-> 데이터 리터러시는 올바른 질문을 던질 수 있도록 만들어 준다
데이터를 잘 분석하면, 가공하면 유의미한 결과값이 나온다는 착각을 하기 쉽다. 또 분석에 실패하면 방법론, 스킬(SQL, 태블로, 파이썬)이 부족하다고 생각한다.
☑️ 데이터 해석 오류 사례
심슨의 역설
심슨의 패러독스란 '부분'에서 성립한 대소 관계가 그 부분들을 종합한 '전체'에 대해서는 성립하지 않는 모순적인 경우를 말한다.
시각화를 활용한 왜곡
자료의 표현 방법에 따라서 해석의 오류 여지가 존재
샘플링 편향
전체를 대표하지 못하는 편향된 샘플 선정으로 인해 오류가 발생
상관관계와 인과관계
- 상관관계
- 두 변수가 얼마나 상호 의존적인지를 파악하는 것을 의미
- 파악 방법은 한 변수가 증가하면 다른 변수도 따라서 증가/감소하되 그 추이를 따름
- 인과관계
- 실질적으로 하나의 요인으로 인해 다른 요인의 수치가 변하는 형태를 의미
- 원인과 결과가 명확한 것
- 상관관계는 인과관계가 아닌 것을 항상 유의해야 함
- 상관관계만으로 섣불리 의사결정 하지 않기
- 양쪽을 모두 활용하여 합리적인 의사판단 하기
☑️ 데이터 분석에 대한 접근법
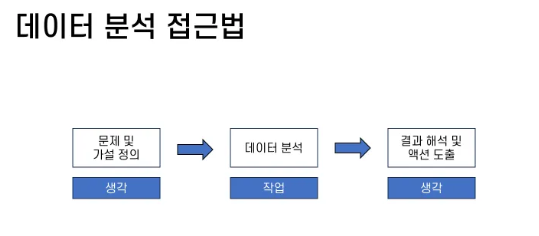
- 위 단계 중 ‘생각’이 주요한 단계에서 데이터 리터러시가 필요
- 데이터 분석이 목적이 되지 않도록 ‘왜?’를 항상 생각해야 함
2. 문제 정의
☑️ 문제 정의란?
- 데이터 분석 프로젝트의 성공을 위한 초석
- 분석하려는 특정 상황이나 현상에 대한 명확하고 구체적인 진술
- 프로젝트의 목표를 설정하고 분석 방향을 설정
✍ 문제 정의 예제
Q. 아래와 같은 상황에서 문제는 무엇일까? 정의해보아요.
🧐 상황: 3개월 전부터 자사 제품의 사용자 수가 감소하고 있다.
사용자 수를 늘리기 위한 포인트 이벤트를 하고 있지만,
효과가 없어 보인다. 또한 자사 제품 내 서비스 중 A 보다 B가
더 안 좋은 상황이다. 사용자가 줄었기 때문에, 수입도 감소하고 있다. 문제1) 사용자 수가 감소하고 있다
문제2) 이벤트 효과가 없다
문제3) A서비스 보다 B 서비스가 상황이 안 좋아진 이유를 살펴보아야 한다
문제4) 수입이 감소한 것이 문제다.
☑️ 문제 정의 방법론
MECE(Mutually Exclusive, Collectively Exhaustive)
- 문제 해결과 분석에서 널리 사용되는 접근 방식
- 문제를 상호 배타적(mutually exclusive)이면서, 전체적으로 포괄적(collectively exhaustive)인 구성요소로 나누는 것
- MECE를 통해 복잡한 문제를 체계적으로 분해하고, 구조화된 방식으로 분석할 수 있음
로직 트리(Logic Tree)
- MECE 원칙을 기반으로 복잡한 문제를 더 작고 관리하기 쉬운 하위 문제로 분해하는데 사용
- 상위 문제로부터 시작하여 하위 문제로 계층적 접근
- 일반적으로 도표 형식으로 표현되어 쉽게 파악할 수 있음
- 로직트리를 활용하여 문제정의 해보기
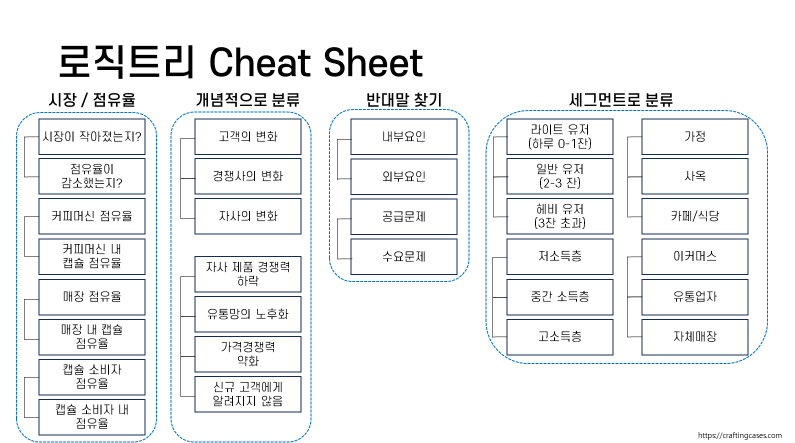
해당 자료는 캡슐커피로 유명한 nescafe의 로직트리 자료로, 산업군, 기업의 규모 등 상황에 따라 알맞게 가공하여 활용할 수 있습니다. - 앱 서비스에 적용하기 위해 변경해 본다면? (비즈니스에 따라서 정의가 달라짐!)
- 세그먼트 분류
- 라이트유저, 일반유저, 헤비유저 > 구매 전 고객, 재구매 고객, VIP 고객
ex) 배달의 민족 고마운분, 귀한분, 더귀한분, 천생연분
- 라이트유저, 일반유저, 헤비유저 > 구매 전 고객, 재구매 고객, VIP 고객
- 캡슐 점유율
- 해당 서비스 시장 점유율로 변화
- 세그먼트 분류
- So what?
- 수집한 정보와 소재에서 ‘결국 어떻다는 것인지’를 알아내는 작업
- 그래서, 따라서, 이렇듯 앞에 오는 정보나 소재에서 과제의 답변에 맞는 중요한 핵심을 추출하는 작업
- 나타난 현상을 바탕으로 과제에 비추어 말할 수 있는 내용의 핵심을 추출하는 작업
- Why So?
- 왜 그렇게 말할 수 있는지
- 구체적으로 무슨 뜻인지를 검증하고 확인하는 작업
- So what?한 요소의 타당성을 자료 전체 혹은 그룹핑한 요소로 증명할 수 있다는 사실을 검증하는 작업
- 도식화한 로직 트리가 위 법칙에 맞는지 확인해보기
3. 데이터의 유형
☑️ 데이터 유형별 비교
정성적 데이터 (Qualitative Data)
- 비수치적인 정보로 사람의 경험, 관점, 태도와 같은 주관적인 요소를 포함해요
- 대부분 텍스트, 비디오, 오디오 형태로 존재해요
- 정형되지 않고 구조화 되어있지 않아요
- 데이터를 구조화하기 어려워요
- 새로운 현상이나 개념에 대한 이해를 심화하는데 사용해요
정량적 데이터 (Quantitative Data)
- 수치적으로 표현되는 정보로 양적인 측정과 분석을 통해 얻을 수 있어요
- 데이터가 숫자 형태로 존재하기 때문에 통계적으로 분석하기 쉬워요
- 개인의 해석이나 주관이 적게 작용하는 객관성을 가지고 있어요
- 지표로 만들기에 용이해요
- 설문조사, 실험, 인구 통계, 지표 분석 등에 활용해요
✍ 데이터의 유형 예제
- 문제
- Q1. 한 레스토랑에서 하루에 판매되는 햄버거 세트의 수는 150개 입니다. 정량
- Q2. 한 고객이 카페 이용 리뷰에 "커피 맛이 너무 좋았고, 분위기가 아늑했다"고 말했습니다. 정성
- Q3. 한 온라인 쇼핑몰의 지난 달의 평균 구매 금액은 10만원입니다. 정량
- Q4. 어떤 서비스를 이용한 유저가 "사용하기 쉽고, 인터페이스가 직관적이다"라는 평가를 남겼습니다. 정성
- Q5. 고객 설문 조사에서, 고객들이 서비스에 대해 "만족한다", "매우 만족한다", "만족하지 않는다"와 같이 응답했습니다. 정성
- Q6. 어떤 연구자가 인터뷰를 통해 수집한 데이터에는 참가자들의 나이, 성별, 직업과 더불어 그들의 생각과 느낌이 포함되어 있습니다. 정량, 정성
☑️ 정량적 데이터의 활용
- 정량적 데이터는 객관적이고 측정가능한 지표를 만들기에 적합합니다.
- 일일 활성 사용자수(DAU, Daily Active User), 재방문 비율(Retention) 등 서비스의 건강 상태를 나타내는 중요한 지표들을 확인할 수 있습니다.
- 수치형 설문조사 데이터를 정량적인 기준으로 나눈 사례, 추천 지수(NPS)를 만들 수 있음
통계적 분석 적용
- 분포, 평균, 중앙값 등을 계산해서 데이터의 경향성과 패턴을 파악할 수 있습니다.
- 해당 내용을 근거로 의사결정 과정에서 중요한 판단을 내립니다.
- 여행 키워드 검색 및 예약 시계열 그래프
다양한 데이터 분석 방법 적용
- 비즈니스 분석, 예측 모델링, 추세 분석을 포함한 머신러닝과 같은 현대적 데이터 분석 기법에 활용할 수 있습니다.
- 이를 통해 미래 예측, 효율적 자원 배분, 시장 변화에 대한 적응이 가능해집니다.
이러한 정량적 데이터를 바탕으로 "지표"가 만들어집니다. 다음 정리에서 지표설정과 결론도출까지 살펴보고 마무리 하도록하겠습니다.

It's a, it's the Pleasure Shop