Motivation & Direction
자연어 데이터 특징
- 이미지 : 이미지 안의 의미있는 정보는 위치에 무관/ convolution 연산은 위치에 무관한 지역적인 정보를 추출하기 좋은 연산
- 자연어 :문장을 구성하고 있는 단어들의 위치가 변해서는 안됨/ 단어들간의 관계가 중요하고 하나의 단어만 바뀌거나 추가되어도 전혀 다른 의미(index)를 가질 수 있음
자연어 데이터의 토큰화
- hugging face와 같은 대중적인 공유 라이브러리가 존재하기 전까지 연구자들이 각각 토큰화를 임의로 진행했음.
- 이에 따라서 모델을 다운받아 실행시킬 경우 전혀 다른 결과가 나타남.
- 즉, 자연어에서의 토큰처리 과정에 대해 아는 것은 매우 중요함.
자연어 처리 Task
- 하나의 문장을 여러 개로 나누고 나눈 토큰들의 결합분포로 문장에 대해서 확률을 계산
자연어 처리 Metrics(평가지표)
- BLEU(단어를 한번에 몇개 볼지 정함(n-gram))
- Rouge(BLEU보다 더 fluency를 고려)
- METEOR
세 지표 모두 길이에 의존적인지 아닌지 먼저 판단한다
- Human Based Measures : 사람에게 시켜서 직접 측정하게 하기도 한다. 이렇듯 전처리(특히 번역문)는 정량적인 분석이 어렵다. (감정분석도 마찬가지)

자연어 처리 모델 기존 연구들
-
어떤 한 문장을 분류하거나 혹은 이 문장을 내포하고 있는 어떤 벡터로 표현하고자 함
-
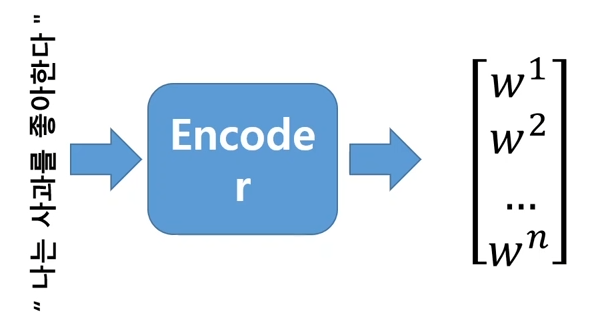
문장의 문맥을 하나의 벡터로 표현하기 위해서 인코딩
-
인코딩 전 tokenizing 진행
-
각 token을 숫자로 표현하고 벡터로 표현
-
각 token의 벡터를 encoding 시키면 n차원의 context vector가 됨.
-
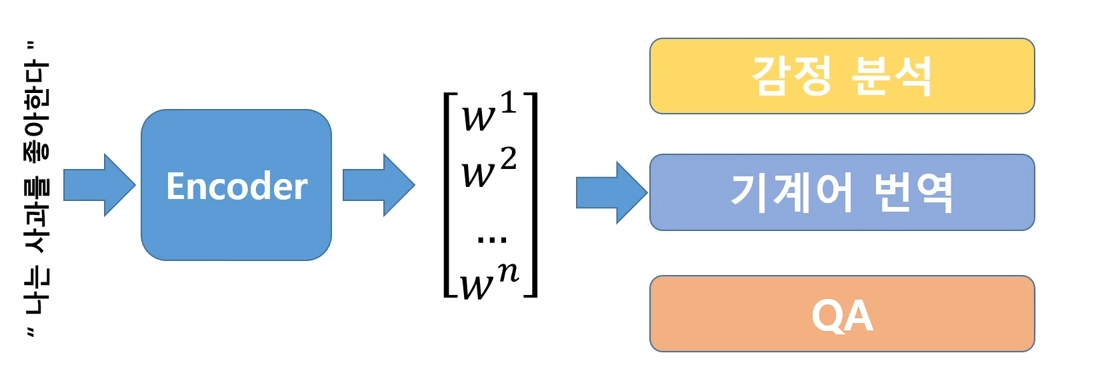
문맥을 알아내는 Enconder를 학습했다면 다양한 Task에 적용이 가능하다.
-
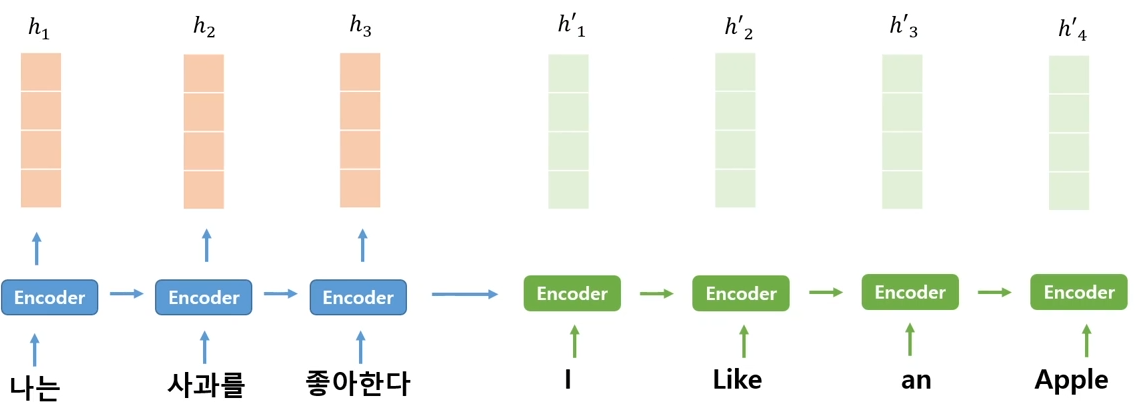
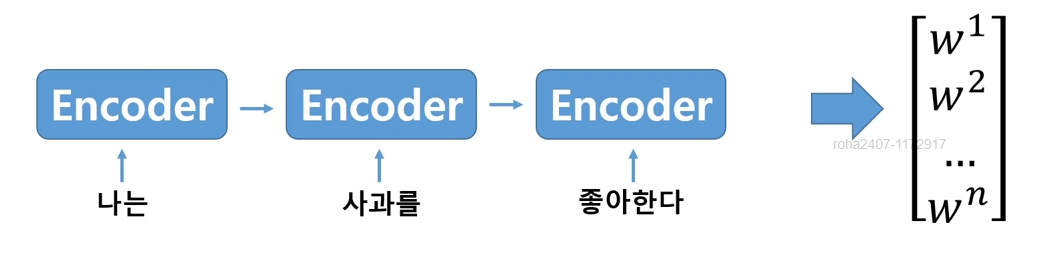
문장은 순서를 가지고 있으니, 문장의 처음부터 끝까지 순서대로 입력을 받아서 최종적으로 벡터를 생성.
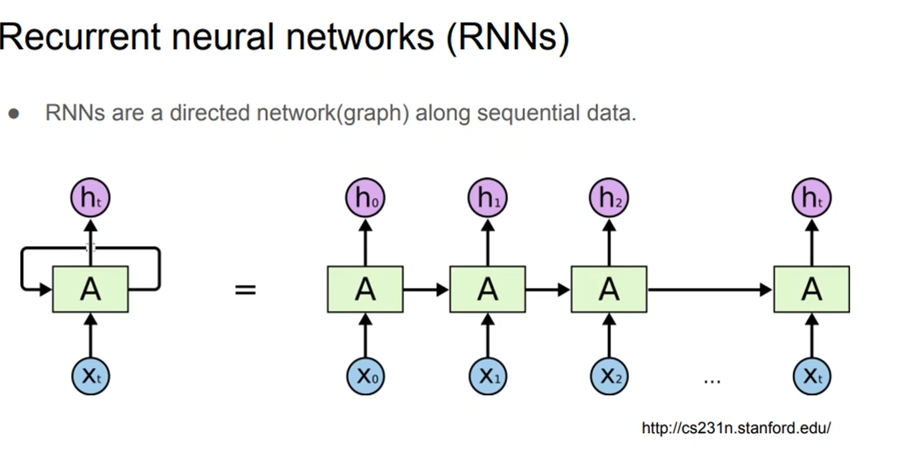
RNN
Recurent Neural Net: RNN, LSTM의 핵심 방법
- input x_t가 들어가면 output은 h_t와 다음 A에게 들어간다.
- 문장은 단어들이 순서를 가지고 있는데, 중요한 단어들이 처음 부분에 있다면 정보 손실이 발생할 수 있지 않을까?(정보손실) 에 대한 의문 제기 -> 각각의 단어에 대해서 Attention을 줄 수 있다면 좋겠다!
- 즉, I 를 번역할때는 "나는"에 attention score 줌.
- 아래에서 나는/ 사과를 / 좋아한다 h1,h2,h3를 h'_ j 와 각각 결합시켜 유사도 점수(attention score)를 구하고 softmax를 시켜 확률적 수치를 출력