[2024] Day25. 1143. Longest Common Subsequence
2024년부터 새롭게 다시 시작하는 코딩테스트
2024년 1월 25일 (목)
Leetcode daily problem
1143. Longest Common Subsequence
Problem
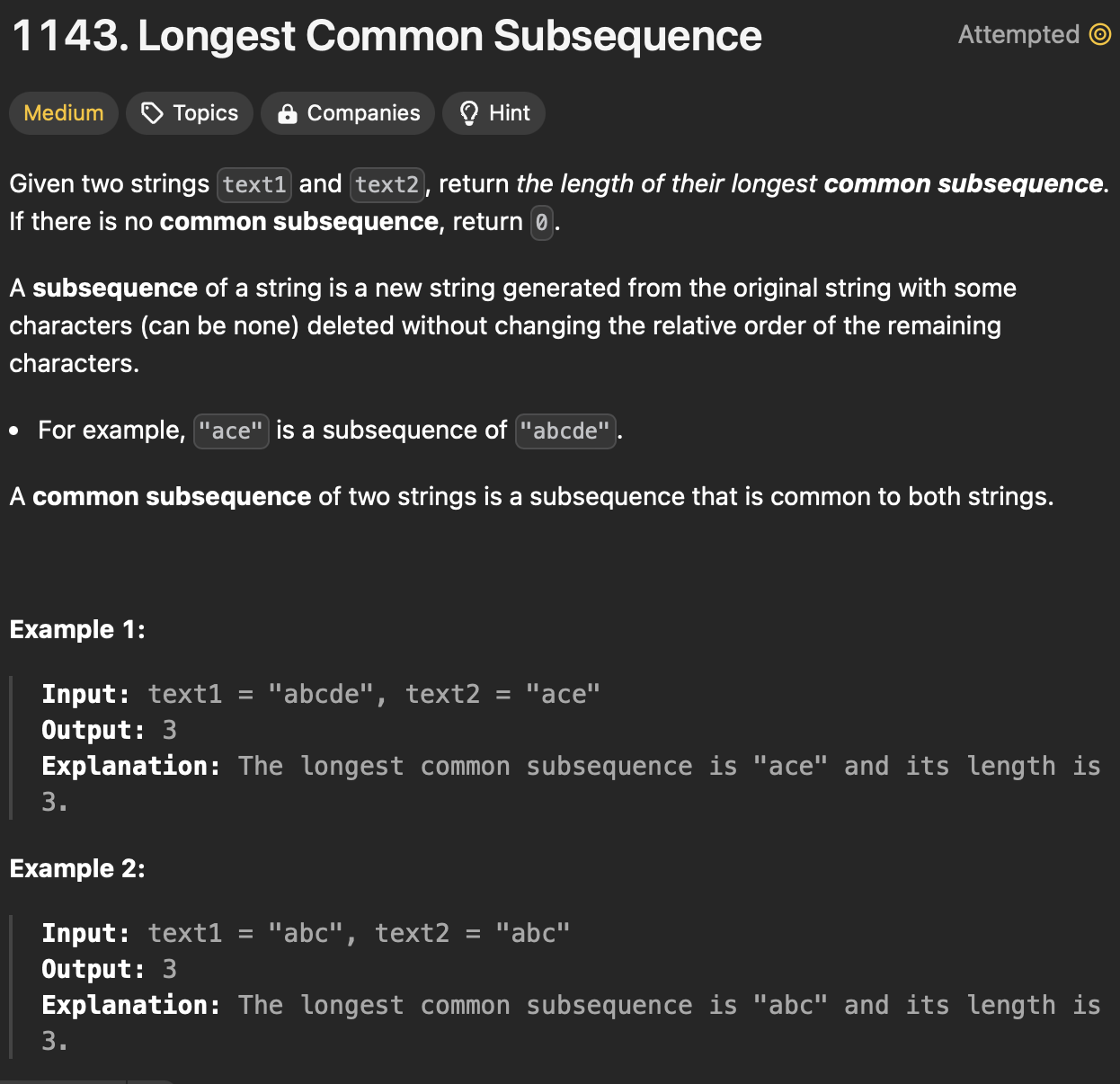

두 문자열의 가장 긴 공통 부분 수열을 찾는 문제이다.
부분 수열은 주어진 문자열에서 일부 문자들을 제거하지 않고 남겨둔 순서대로의 문자열이다.
Solution
dynamic programming
주어진 문자열 text1, text2에 해당하는 길이를 각 n,m이라고 했을 때 (n+1) x (m+1) 크기의 2차원 배열인tmp를 만들어 초기화한다.
문자에 대한 LCS의 길이를 구하기 위해 초기화한 것으로 text1, text2를 탐색해 가면서 해당 배열을 업데이트 해나간다.
만약 text1[row-1]과 text2[col-1]이 같다면
현재 위치의 LCS 길이는 이전 위치의 대각선 원소에 1을 더한 값으로 즉, tmp[row][col] = 1 + tmp[row-1][col-1]이다.
만약 text1[row-1]과 text2[col-1]이 다르다면, 현재 위치의 LCS 길이는 이전 행의 값 또는 이전 열의 값 중 큰 값으로 산정한다. 즉, tmp[row][col] = max(tmp[row-1][col], tmp[row][col-1])이다.
이렇게 두 문자열을 차례대로 하나씩 훑어가는 (n*m) 수 만큼 탐색하다 보면 tmp[row][col]에 text1, text2의 부분 문자로 업데이트가 된다.
Code
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
n, m = len(text1), len(text2)
tmp = [[0 for _ in range(m+1)] for _ in range(n+1)]
for row in range(1, n+1):
for col in range(1, m+1):
if text1[row-1] == text2[col-1]:
tmp[row][col] = 1+tmp[row-1][col-1]
else:
tmp[row][col] = max(tmp[row][col-1], tmp[row-1][col])
return tmp[row][col]Complexicity
시간 복잡도
이중 포문을 사용하고 있고 각각 n,m에 따라 실행되기 때문에
전체 시간복잡도는 O(n*m)이다.
공간 복잡도
2차원인 tmp 배열을 생성하고 사용하는데, 해당 배열 크기는 (n+1) (m+1) 이므로 공간 복잡도는 O(n m)이다.
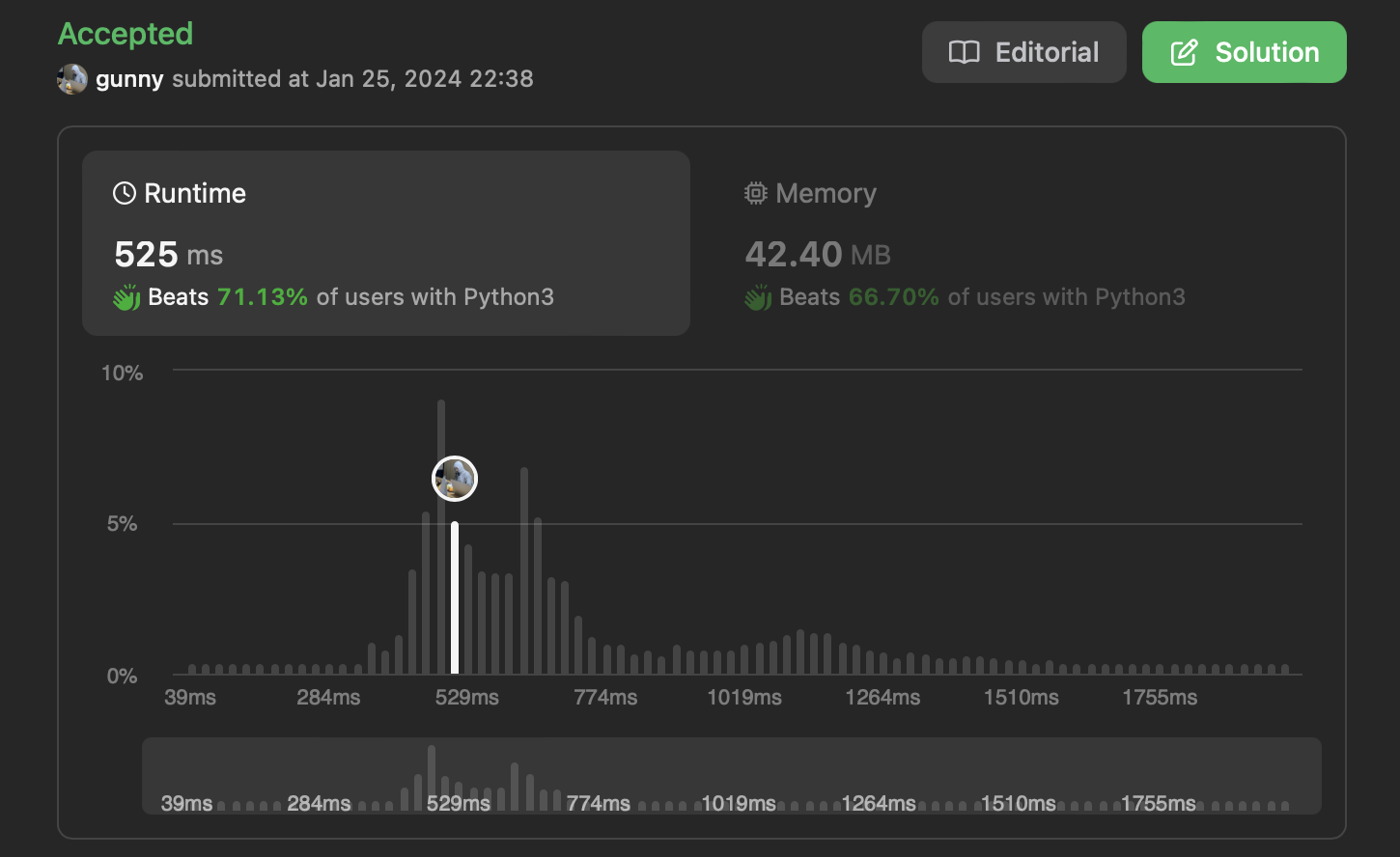
감도 안와서 답변 보고 이해 한 나 레전드
최적화고 나발이고 이런 식으로 푸는 구나 이해 완
