[2025] leetcode 1408. String Matching in an Array

2024년 1월 7일 (화)
Leetcode daily problem
leetcode 1408. String Matching in an Array

문자열로 구성된 words 배열이 주어질 때, 배열 내에서 다른 문자열과 비교해서 해당 문자열이 포함되어 있다면, 그 문자열을 찾아 반환한다.
Solution
두 문자열의 비교해서 포함관계 확인, 중복 방지
문자열 배열을 순차적으로 두 번 비교 한다.
각 문자열이 다른 문자열을 포함하는지 확인하고, 포함하면 결과 배열에 추가한다.
Code
방법 1
class Solution:
def stringMatching(self, words: List[str]) -> List[str]:
result = []
for i in range(len(words)):
for j in range(len(words)):
if i != j and words[i] in words[j]:
result.append(words[i])
break
return result
방법 2
길이 기준으로 정렬해서 짧은 문자열이 긴 문자열에 포함될 가능성을 먼저 검사하고, 이미 포함 관계를 확인한 문자열에 대해서는 추가 적인 비교를 하지 않도록 set을 활용해서 중복을 방지한다.
class Solution:
def stringMatching(self, words: List[str]) -> List[str]:
ans = []
words.sort(key=len)
seen = set()
for i in range(len(words)):
for j in range(i+1, len(words)):
if words[i] in words[j]:
if words[i] not in seen:
ans.append(words[i])
seen.add(words[i])
return ans
Complexicity
시간 복잡도
첫 번째 방법은 이중 for 루프를 사용해서, 문자열 배열의 길이를 n 이라고 했을 때 O(n^2) 가 소요되고, 각 문자열에 대해서 포함관계를 확인하는데 문자열의 평균 길이를 m 이라고 했을 때 O(m) 시간이 포함된다. 즉, 시간복잡도는 O(n^2 * m)이 소요된다.
두 번째 방법은 문자열을 길이 기준으로 정리하는데 O(nlogn)이 소요되고, 두 문자열을 비교하는데 이중 루프가 비교하고 각 비교는 O(m)의 시간이 걸린다. 최악의 경우 두 문자열이 길이가 다른 문자열이라면 O(n^2*m)의 시간이 소요된다.
공간 복잡도
첫 번째 방법은 ans 배열에 저장되는 문자열의 최대 개수인 n개와 각 문자열의 최대 길이인 m 으로 (n*m)이다.
두 번째 방법은 seen 집합을 사용해서 추가적인 공간이 필요하고, 배열과 같을수 있어 O(n)이 필요하다. 첫 번째 방법보다는 공간복잡도가 O(n)으로 개선된다.
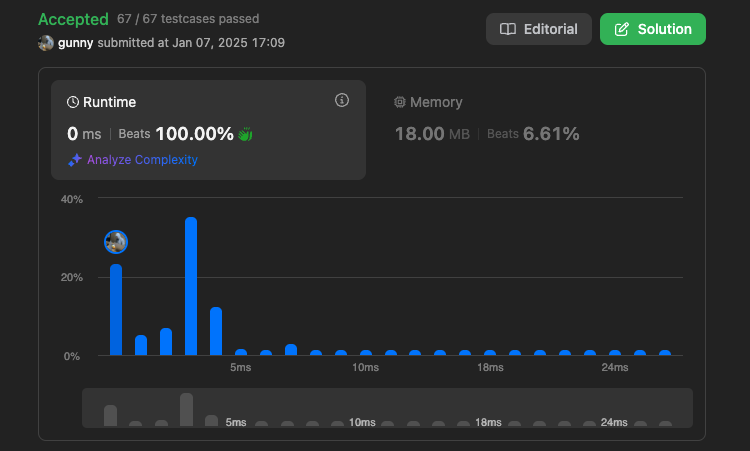
첫 번째
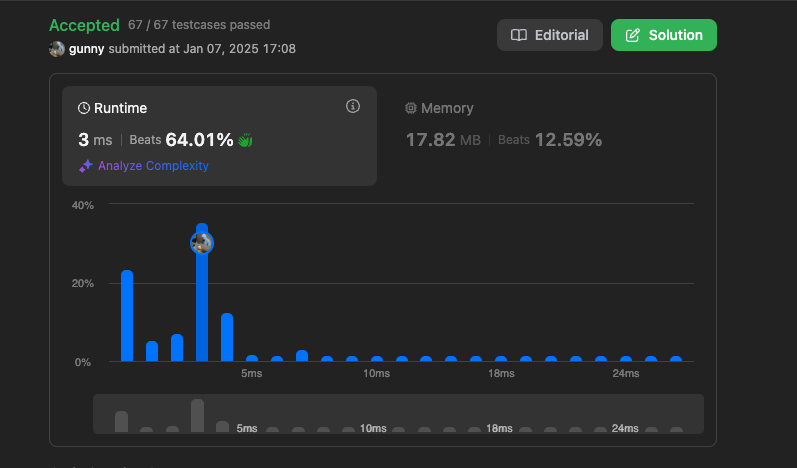
두 번째