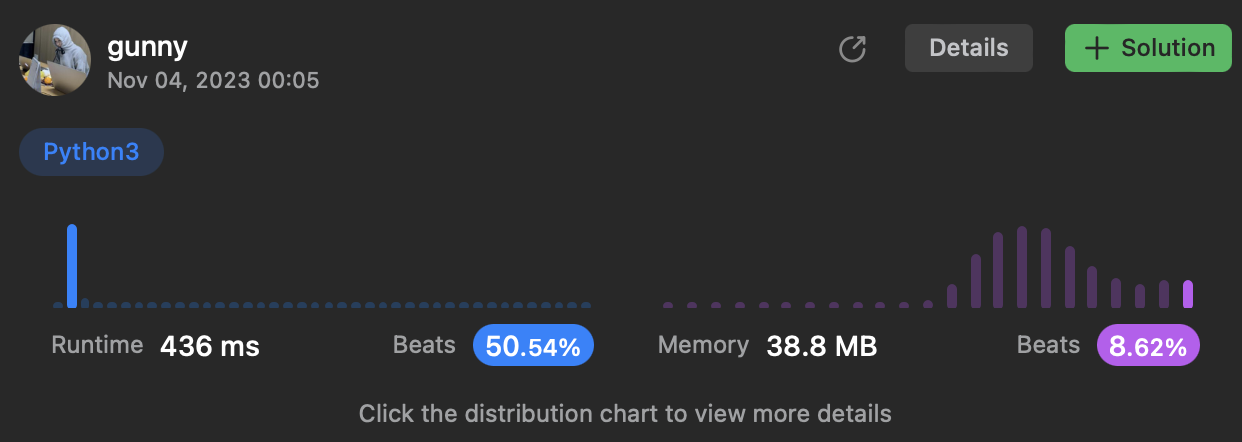
[4코3파] #303. Leetcode Heap/Priority Queue
[4코3파] 1명의 스위프트 개발자가 도망가고 4명의 코틀린 개발자, 3명의 파이썬 개발자의 코딩 테스트 스터디 : 4코3파
START :
[3코1파] 2023.01.04~ (303일차)
[4코1파] 2023.01.13~ (295일차)
[4코3파] 2023.10.01 ~ (33일차)
Today :
2023.11.02 [303일차]
Leetcode Heap/Priority Queue
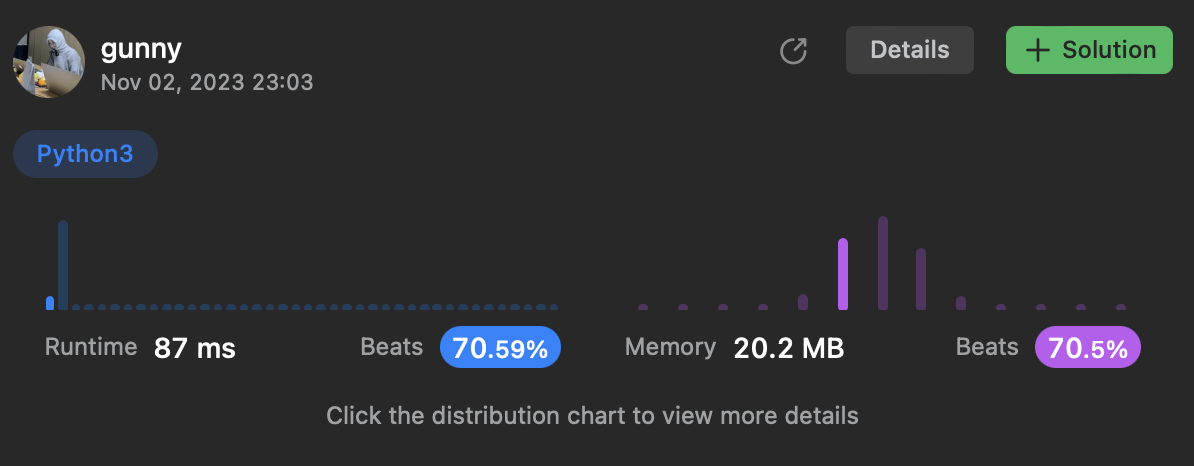
[1] 703. Kth Largest Element in a Stream
https://leetcode.com/problems/kth-largest-element-in-a-stream/
문제 설명
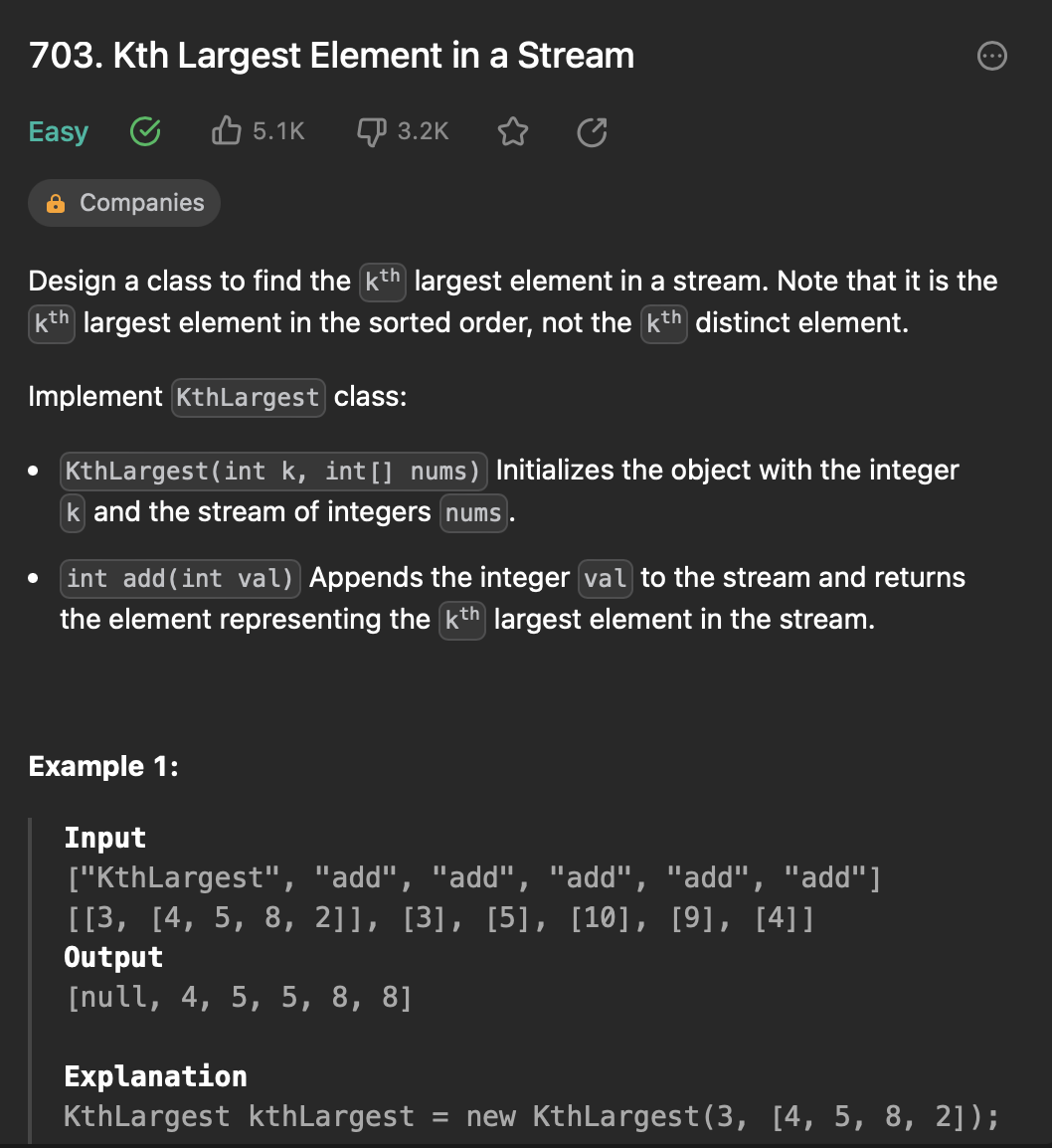
스트림에서 K번째로 큰 요소를 리턴하는 KthLargest 클래스를 구현하는 문제이다.
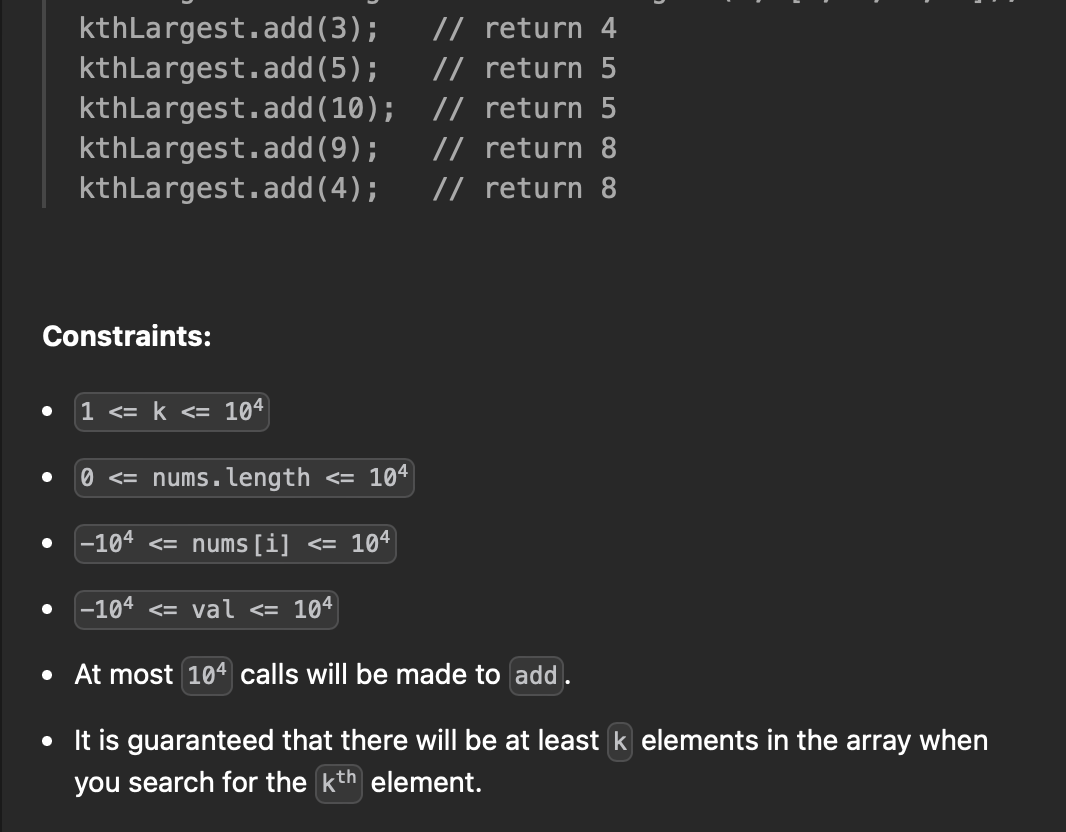
thLargest(int k, int[] nums): 클래스 생성자로, 초기에 주어진 정수 배열 nums와 K값을 기반으로 KthLargest 객체를 생성한다.
int add(int val): 이 메소드는 데이터 스트림에 새로운 요소 val을 추가하고, 현재까지 데이터 스트림에서 K번째로 큰 요소를 반환한다. 즉, add 메소드를 호출할 때마다 현재 데이터 스트림에서 K번째로 큰 요소를 업데이트해야 한다.
문제 풀이 방법
K번째로 큰 요소를 추적하기 위해 Min Heap을 사용한다.
클래스 생성자에서 주어진 nums 배열을 사용하여 초기 Min Heap을 생성하고, 이 Min Heap은 K개의 요소만을 유지하도록 해야 한다. 이렇게 하면 Min Heap의 루트 노드에는 현재 데이터 스트림에서 K번째로 큰 요소가 저장된다.
add 메소드를 호출할 때마다 Min Heap에 요소를 추가하고, Min Heap의 크기가 K를 초과하는 경우, 가장 작은 요소를 제거하여 Min Heap의 크기를 K로 유지한다.
add 메소드를 호출할 때마다 Min Heap의 루트 노드에는 현재 데이터 스트림에서 K번째로 큰 요소가 저장되고, 이 값을 반환하면 된다.
내 코드
class KthLargest:
def __init__(self, k: int, nums: List[int]):
self.k, self.minHeap = k, nums
heapq.heapify(self.minHeap)
while len(self.minHeap) > k:
heapq.heappop(self.minHeap)
def add(self, val: int) -> int:
heapq.heappush(self.minHeap, val)
while len(self.minHeap) > self.k:
heapq.heappop(self.minHeap)
return self.minHeap[0]
[2] 1046. Last Stone Weight
문제 설명
돌을 이용한 연산을 하고, 마지막 돌의 무게를 계산하는 문제이다.
주어진 돌 목록 stones에 대해, 마지막 돌의 무게를 반환한다.
주어진 돌 목록에서 가장 무거운 돌 두 개를 선택하고, 두 돌을 합치고, 새 돌의 무게는 두 돌의 무게 차이로 갱신된다. 이 과정을 반복하여 더 이상 돌이 남지 않을 때까지 진행한다.
마지막으로 남은 돌의 무게가 0이면 0을 반환하고, 그렇지 않으면 해당 무게를 반환해야 한다.
문제 풀이 방법
maxheap을 이용해서 돌 목록인 stones를 pop하면서 가장 무거운 돌을 꺼내온 후,
연산하고 다시 heap에 push하면서 돌 목록을 갱신시켜 나가면된다.
주의할 사항은 가장 무거운 돌을 만들기 위해서 stones에 있는 돌 원소에 -1을 곱해주는 연산을 했기 때문에 두 돌을 반환해왔을때 계산 할 때 a,b 중 둘 중 큰 돌을 빼주는 연산을 해야한다는 것이다.
마지막에 돌이 없을 경우를 처리해주기 위해서, maxheap에 0을 넣어주고 maxheap에 있는 루트 노드의 원소를 반환해주면 된다.
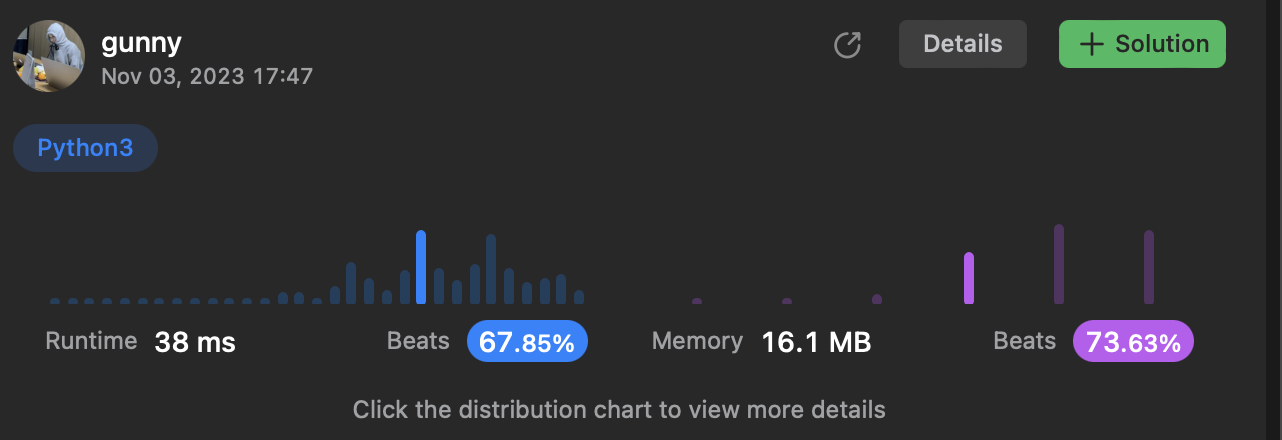
내 코드
class Solution:
def lastStoneWeight(self, stones: list[int]) -> int:
stones = [-1*(stone) for stone in stones]
heapq.heapify(stones)
while len(stones)>1:
a,b = heapq.heappop(stones), heapq.heappop(stones)
if a<b:
heapq.heappush(stones, a-b)
heapq.heappush(stones,0)
return abs(stones[0])
[3] 973. K Closest Points to Origin
문제 설명
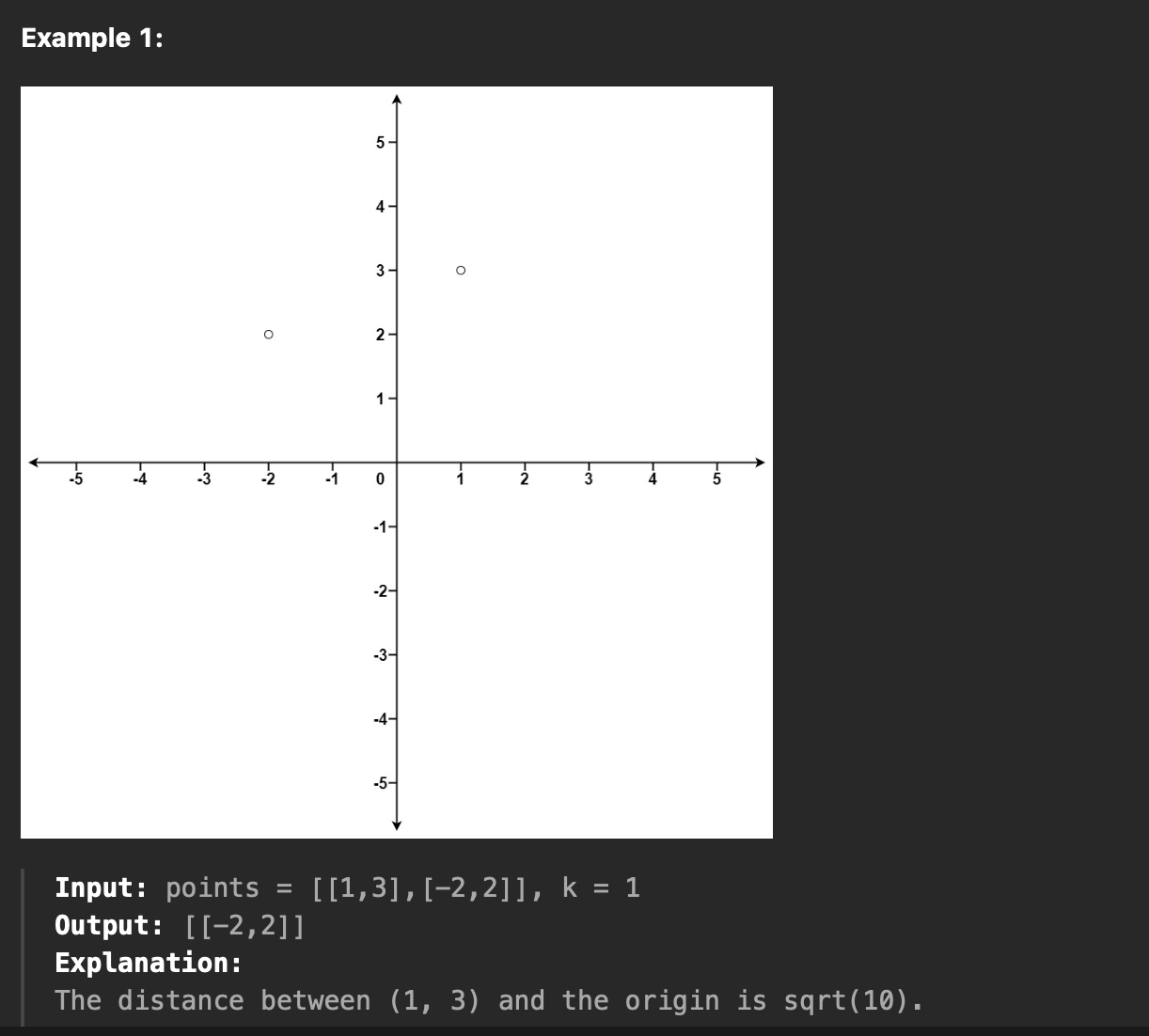
원점(0,0)으로부터 가장 가까운 점들을 찾는 문제로, 주어진 점들의 배열과 원점에서의 거리를 기준으로 가장 가까운 K개의 점을 찾아 해당 좌표를 반환한다.
문제 풀이 방법
차원 평면 상에 주어진 점들의 배열 points와의 원점 (0,0)에서 각 점까지의 거리를 계산한다. (유클리드 거리: √(x^2 + y^2)) 해당 거리와 좌표를 쌍으로 해서 minHeap에 저장한다.
이 거리를 기준으로 가장 가까운 K개까지 minHeap의 루트를 pop해서 (꺼내와서) 해당 좌표인 점을 찾아 반환한다.
내 코드
시간 복잡도는 O(N log K)
class Solution:
def kClosest(self, points: list[list[int]], k: int) -> List[List[int]]:
minHeap = []
for x,y in points:
dist = (x**2) + (y**2)
minHeap.append([dist, x, y])
heapq.heapify(minHeap)
ans = []
while k>0:
dist, x, y = heapq.heappop(minHeap)
ans.append([x,y])
k-=1
return ans
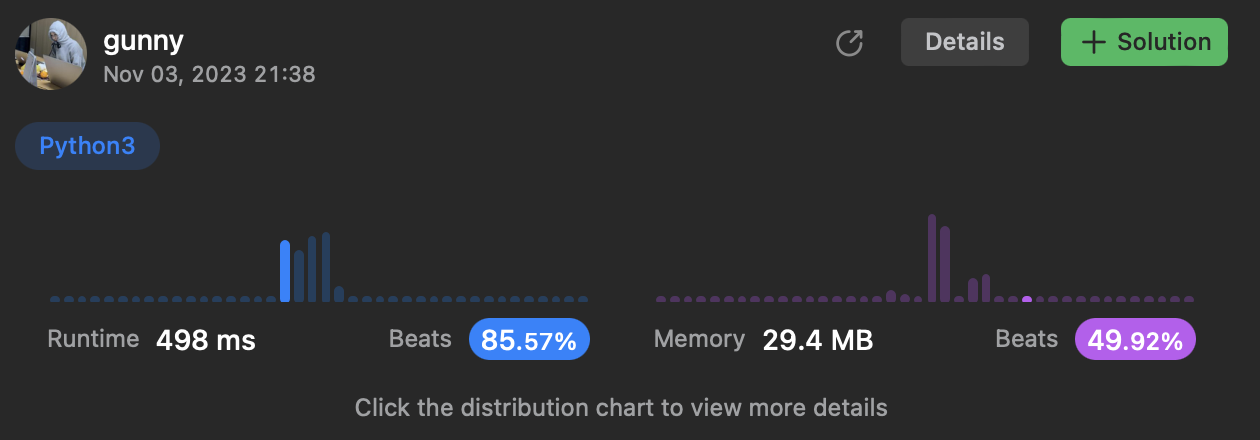
[4] 215. Kth Largest Element in an Array
https://leetcode.com/problems/kth-largest-element-in-an-array/
문제 설명

정수 배열에서 K번째로 큰 요소를 찾아 반환한다.
문제 풀이 방법
최소 힙(Min Heap)을 사용해서 배열을 한 번 탐색해 K번째로 큰 요소를 찾는다.
703. Kth Largest Element in a Stream 와 유사하게, 배열에서 k번째 까지의 요소로만 min heap을 구성하고, 나머지 k 번째 배열을 탐색하면서, min heap의 루트 노드와 크기를 비교해서 크기가 k 개 만큼인 heap 사이즈를 유지하면서 루트 노드를 갱신해 나가면 된다.
내 코드
class Solution:
def findKthLargest(self, nums: list[int], k: int) -> int:
minHeap = nums[:k]
heapq.heapify(minHeap)
for num in nums[k:]:
if num > minHeap[0]:
heapq.heappop(minHeap)
heapq.heappush(minHeap, num)
return minHeap[0]
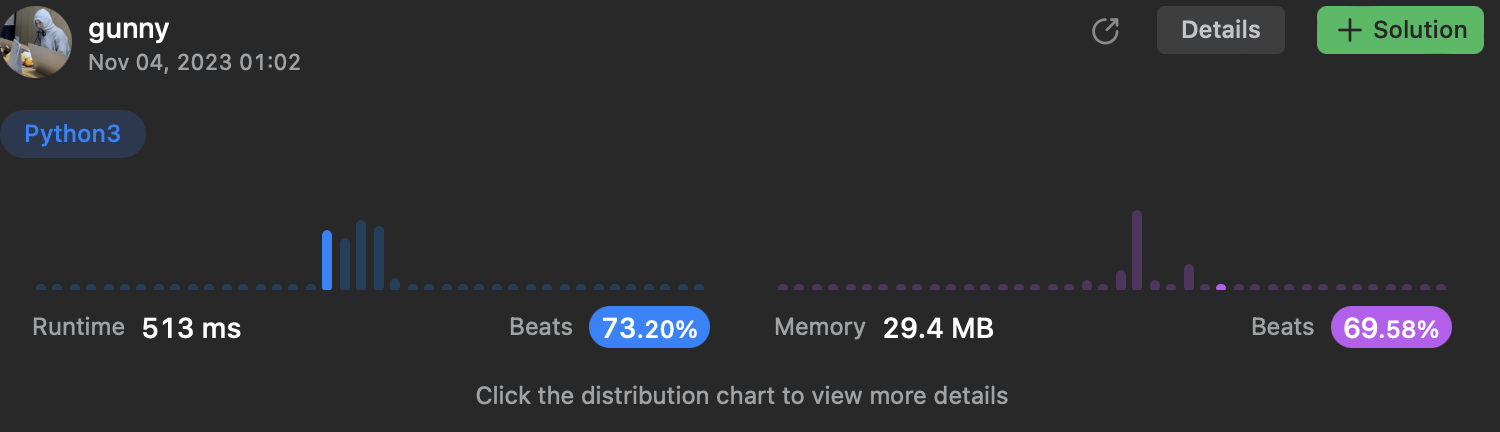
[5] 621. Task Scheduler
문제 설명
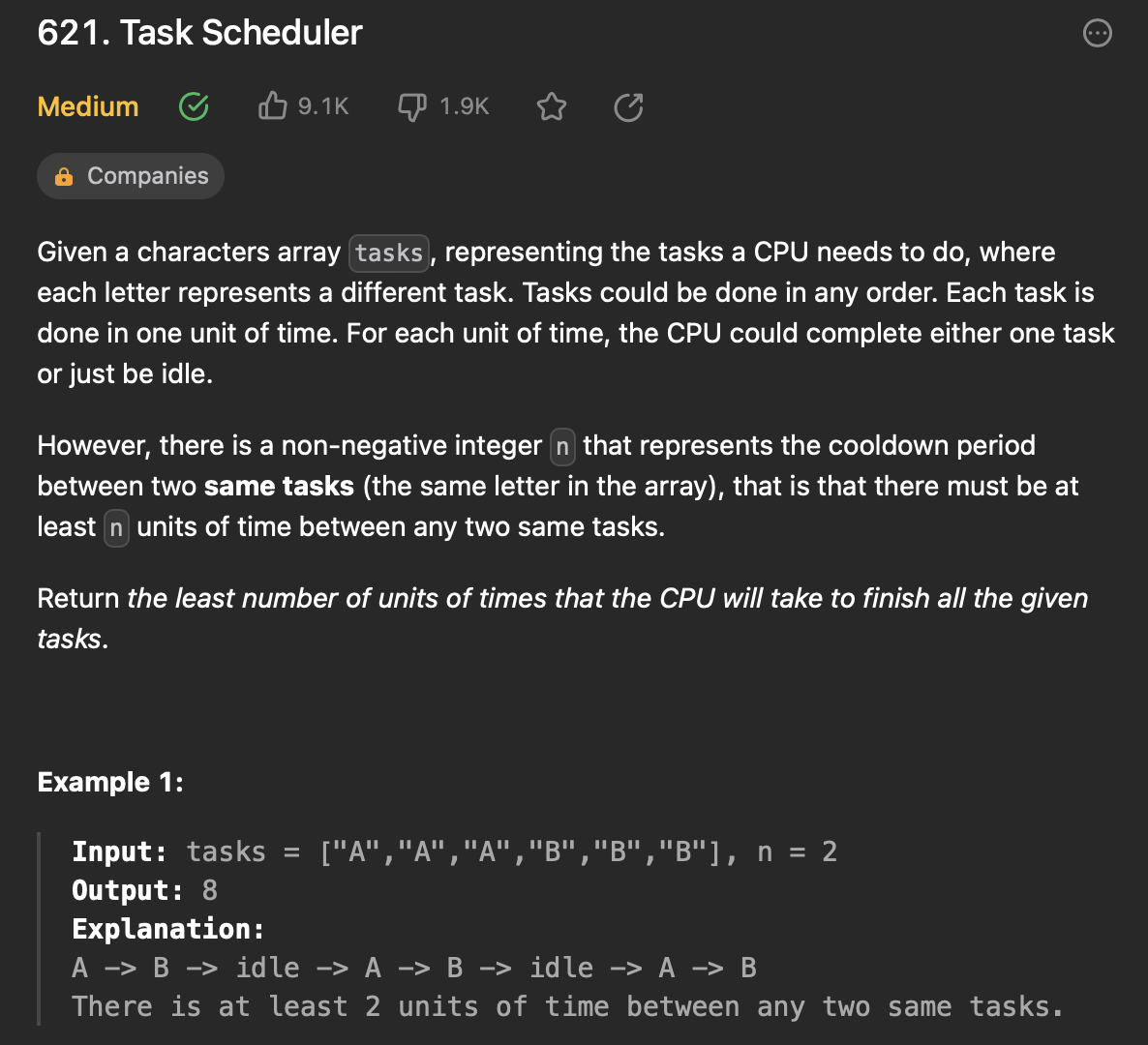
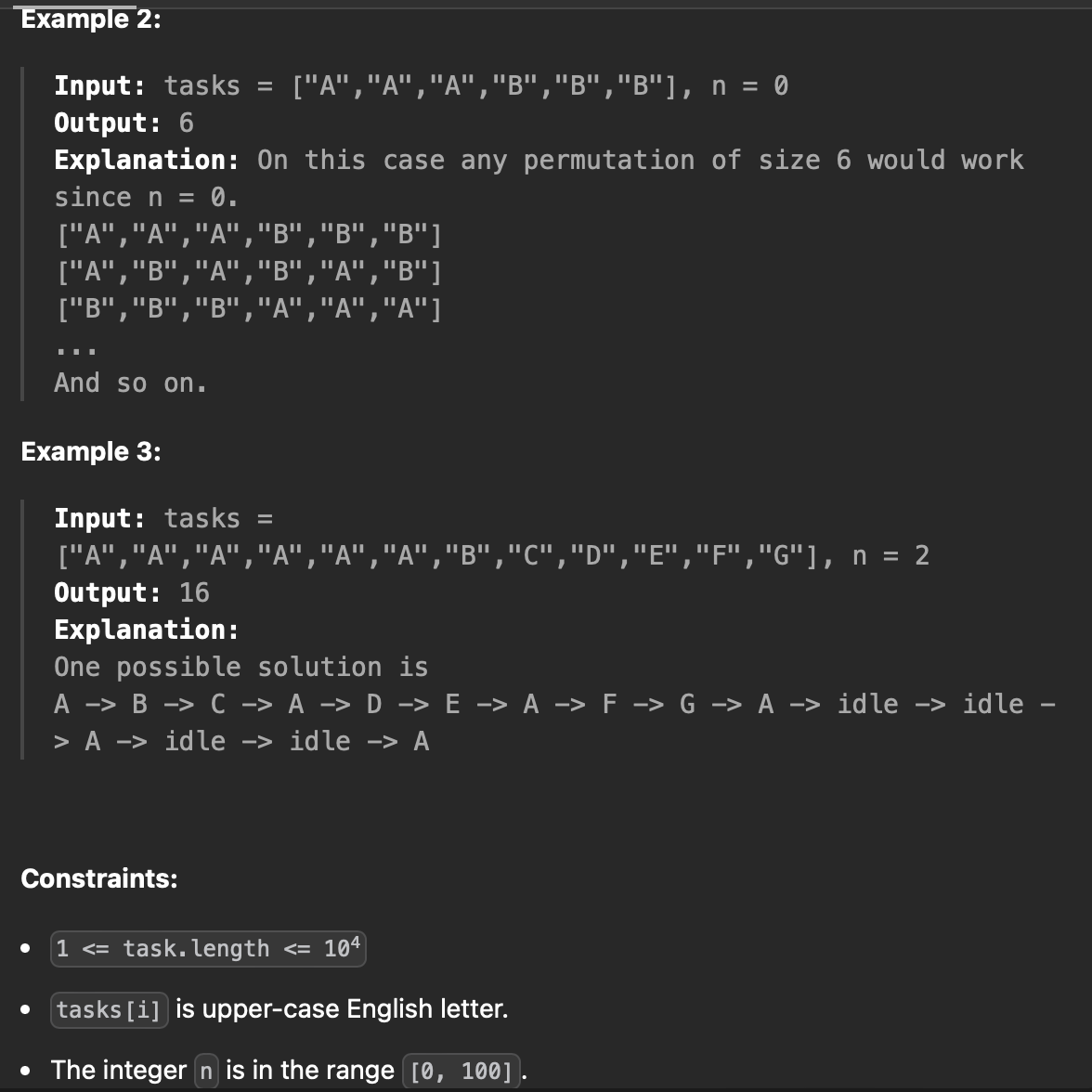
작업을 수행하는 스케줄러를 모델링하고, 주어진 작업 배열을 처리하기 위한 최소 시간을 계산한다.
작업은 정확히 1 단위 시간 동안 수행되고, 두 번 연속으로 같은 작업을 수행할 수 없다.
스케줄러는 작업 사이에 idel time(유후 시간)인 n을 사용할 수 있다. n 단위 시간 동안에는 어떤 다른 작업을 수행할 수 있다.
문제 풀이 방법
해당 문제를 푸는 가장 핵심 아이디어는 가장 많은 빈도로 나타나는 작업을 우선적으로 처리하여 idel time을 최대한 활용해야 한다. 예를 들어, 작업 A가 가장 많이 나타나는 경우, idel time 내에 여러 번 작업 A를 수행하고, 다른 작업은 idel time이 끝나기 전까지 대기했다가 다시 처리할 수 있는 작업 중에서 가장 빈도가 높은 작업을 선택하여 처리를 반복한 후 마지막 걸린 시간을 반환한다.
내 코드
class Solution:
def leastInterval(self, tasks: list[str], n: int) -> int:
count = Counter(tasks)
maxHeap = [-cnt for cnt in count.values()]
heapq.heapify(maxHeap)
queue = deque()
time = 0
while queue or maxHeap:
time +=1
if not maxHeap:
time = queue[0][1]
else:
cnt = 1+heapq.heappop(maxHeap)
if cnt:
queue.append([cnt, time+n])
if queue and queue[0][1]==time:
heapq.heappush(maxHeap, queue.popleft()[0])
return time
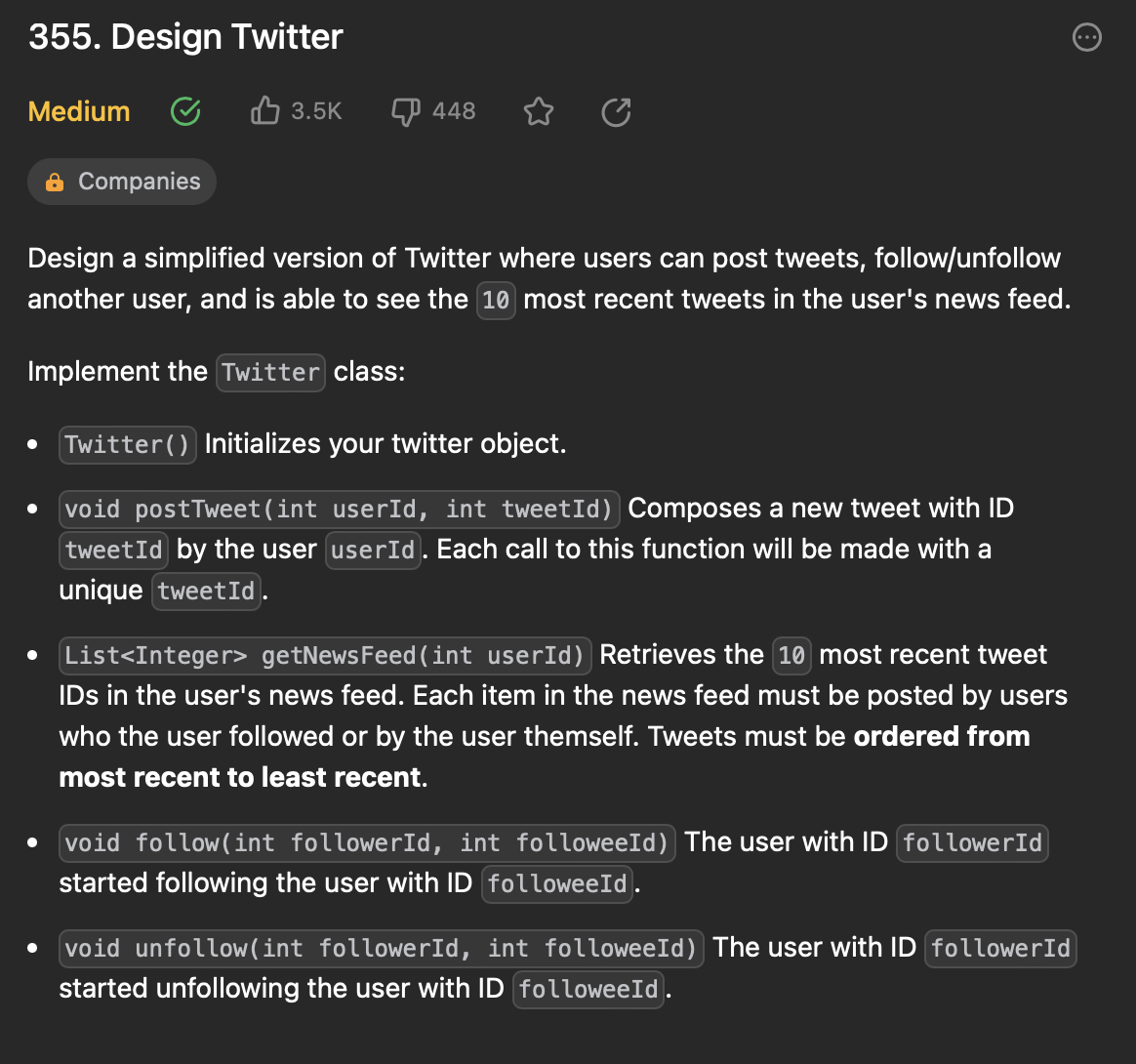
[6] 355. Design Twitter
문제 설명
Twitter의 기능을 디자인하고 구현하는 클래스를 설계한다.
사용자들이 메시지를 작성하고 팔로우하며, 최근의 트윗을 볼 수 있는 기능을 구현한다.
- User (사용자): 각 사용자는 고유한 식별자와 자신이 팔로우하는 사용자 목록, 자신이 작성한 트윗을 가짐
- Tweet (트윗): 각 트윗은 고유한 식별자와 작성자를 가지며, 트윗의 내용을 포함함. 각 트윗은 타임스탬프를 가지고 있어서 작성 순서를 기록함
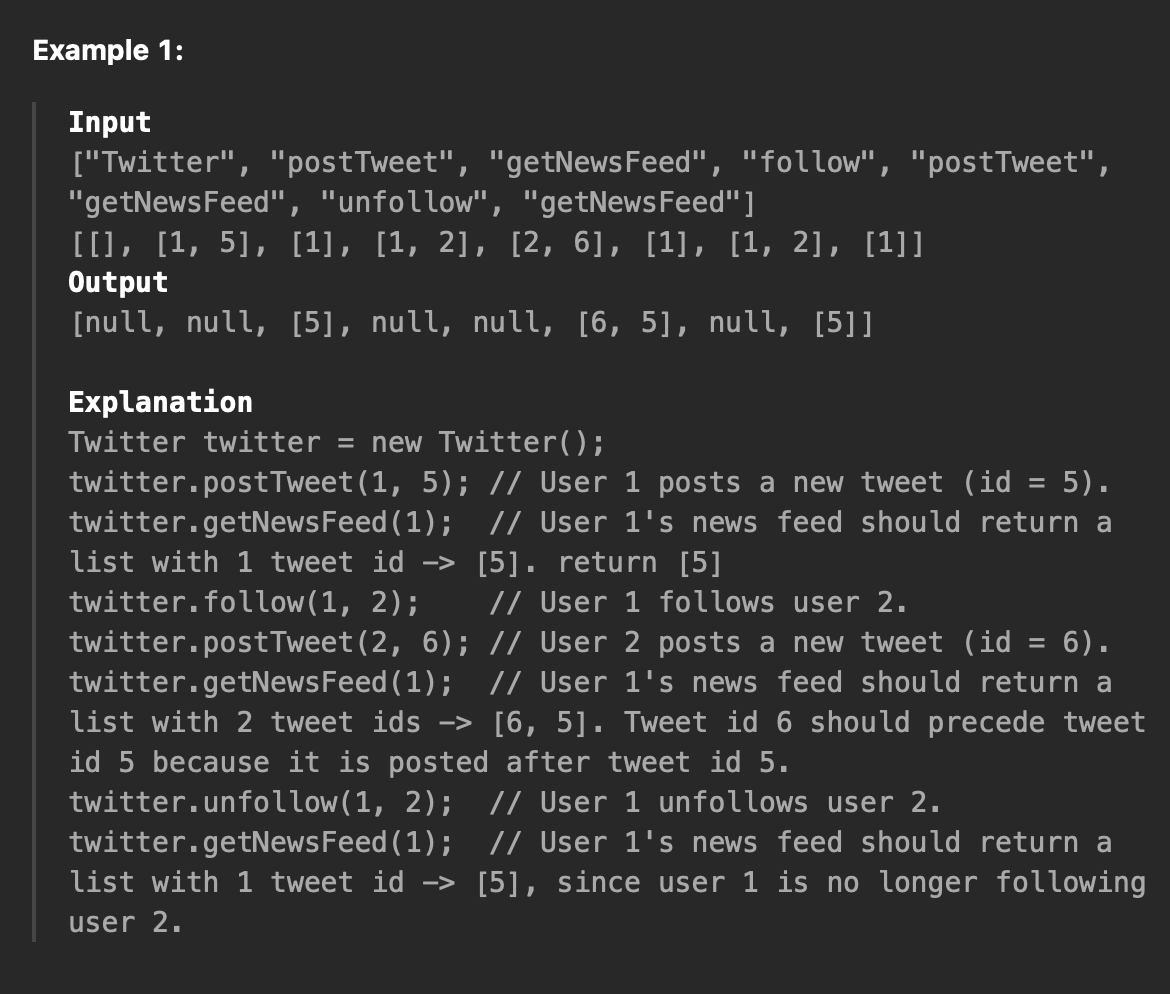
- Design Twitter (Twitter 디자인): Twitter 클래스는 다음과 같은 주요 기능을 제공
- postTweet(userId, tweetId): 사용자가 트윗을 작성함
- getNewsFeed(userId): 사용자가 팔로우하는 사용자들의 최근 트윗을 최대 10개까지 반환하고, 타임스탬프를 기반으로 정렬됨
- follow(followerId, followeeId): 사용자가 다른 사용자를 팔로우함
- unfollow(followerId, followeeId): 사용자가 다른 사용자의 팔로우를 취소함
문제 풀이 방법
내 코드
[7] Find Median From Data Stream
문제 설명
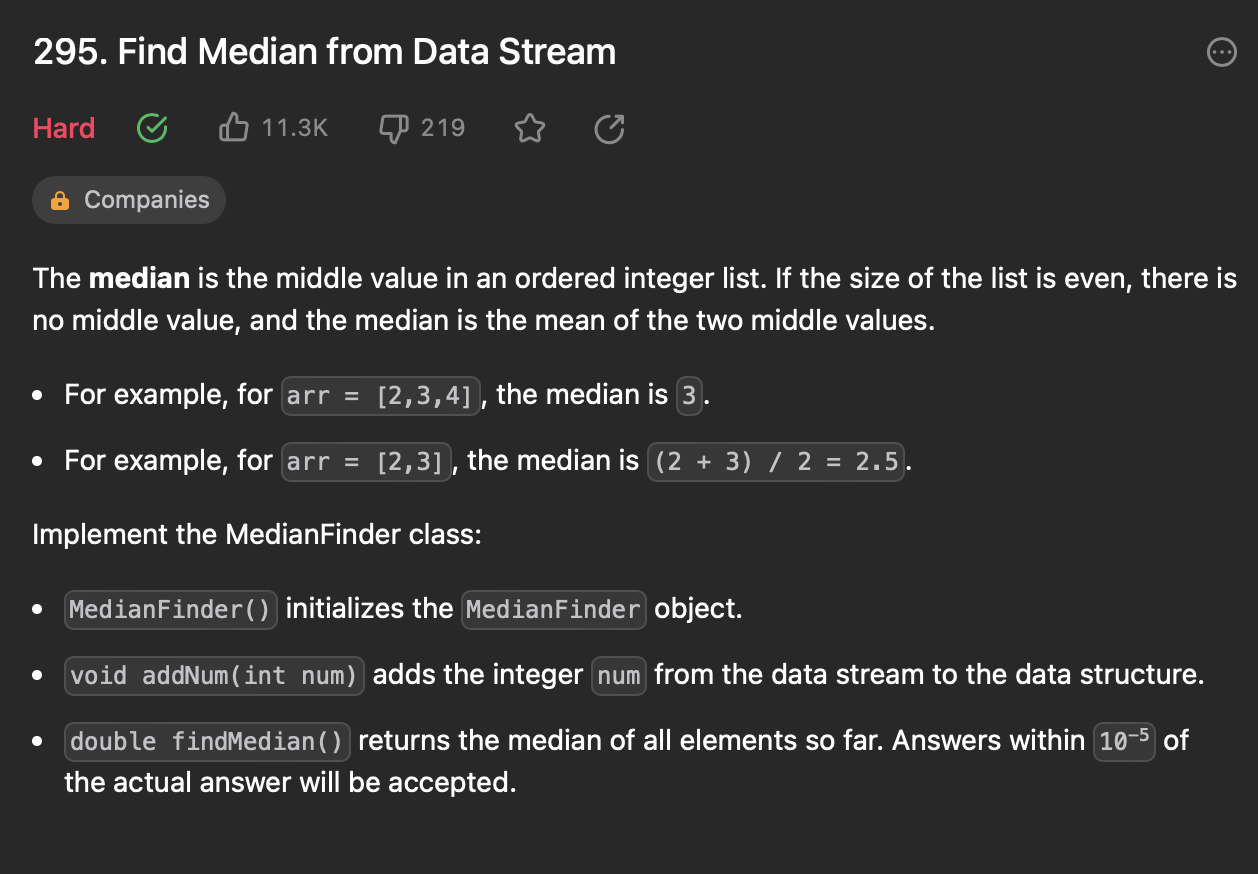
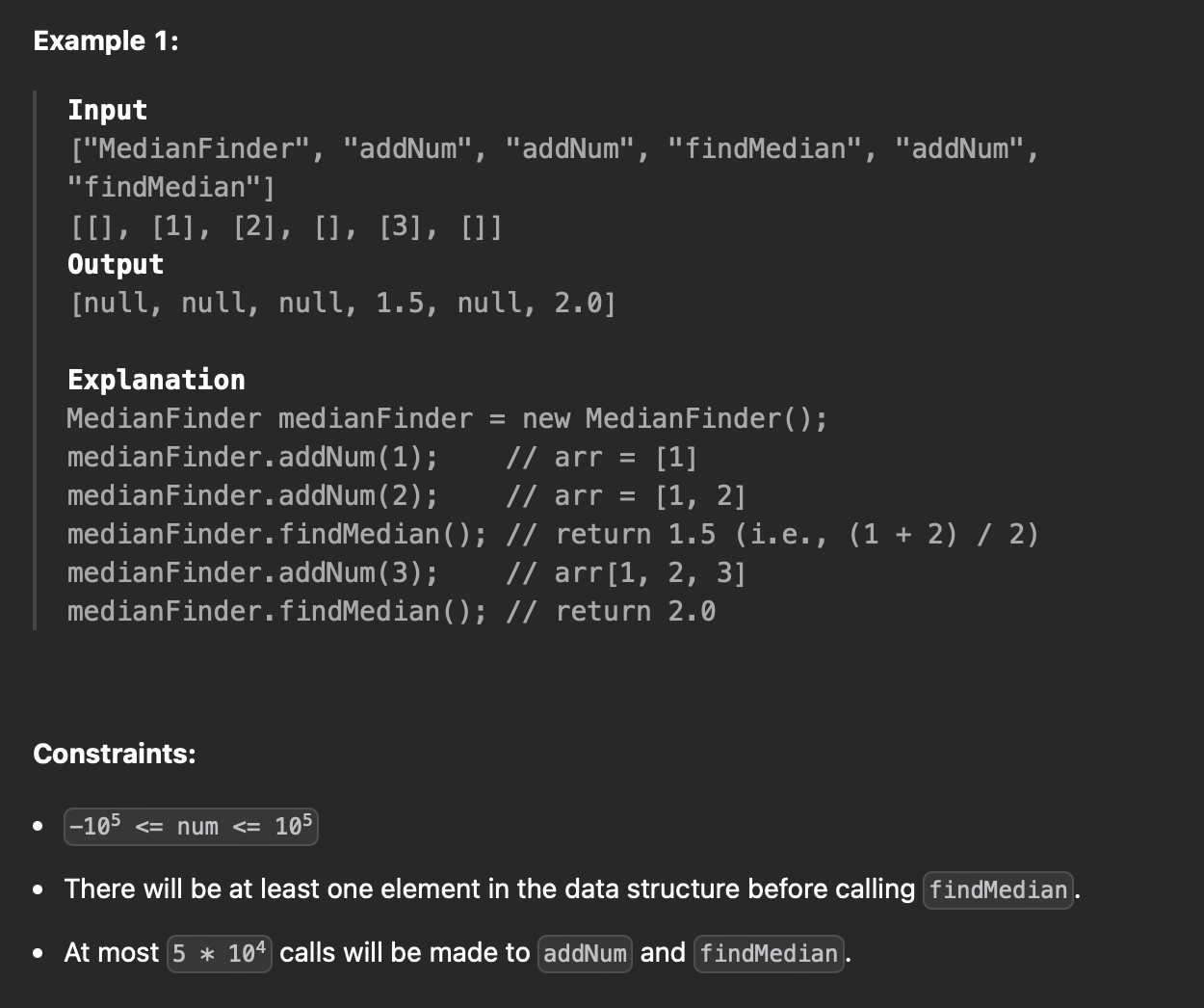
주어진 정수 배열에서 middle value, 배열의 중간에 있는 값(중앙값)을 반환한다.
배열이 홀수라면 가장 가운데에 있는 원소를 반환 예) arr = [2,3,4] median = 3
배열이 짝수라면 n/2번째 값과 (n/2)+1번째 값을 합한 값을 둘로 나눈 값이다. 예) arr = [2,3] median = (2+3)/2
문제 풀이 방법
배열을 넣을 때마다 sort하고 찾으므로 O(nlogn)이 걸리게 된다.
해당 문제를 푸는 방법은 heap 2개를 가지고 푸는 방법으로 효율적으로 풀 수 있다.
min heap, max heap 두 힙을 생성한다.
min heap에는 중앙값보다 작은 수, max heap에는 중앙값보다 큰 수를 넣는 다고 생각하고
모든 데이터를 다 넣었을 때 min heap에서 가장 큰 수와 max heap에서 가장 작은 수를 이용해서 중앙값을 고를 수 있다.
두 힙의 크기가 같다면, 두 힙의 루트 값들을 가져와서 평균을 계산하고,
두 힙의 크기가 다르다면, 크기가 더 큰 힙의 루트 원소로 중앙값을 계산하면 된다.
데이터를 추가하는 과정에서, 새로운 데이터를 적절한 힙에 추가하면 되는데
두 힙의 크기(size) 차이가 2 이상이 되면, 두 힙의 크기를 조절하여 균형을 유지해야 한다.
데이터를 min heap에 추가하고, 이때의 max heap 과의 사이즈를 비교하면서
max heap의 루트 노드의 원소와의 크기를 비교하면서 pop, push를 통해서
min heap, max heap의 루트 노드의 값들을 업데이트 해야 한다.
addNum 메소드에서 조건 넣는 순서가 중요한 것 같다.
사이즈 확인 전에 min heap과 max heap의 루트 노드의 크기 비교를 제일 먼저 해야 한다.
내 코드
class MedianFinder:
def __init__(self):
self.small, self.large = [],[]
def addNum(self, num: int) -> None:
heapq.heappush(self.small, -1*num)
if self.small and self.large and -1 * self.small[0] > self.large[0]:
val = heapq.heappop(self.small)
heapq.heappush(self.large, -1*val)
if len(self.small) > len(self.large)+1:
val = heapq.heappop(self.small)
heapq.heappush(self.large, -1*val)
if len(self.large)> len(self.small)+1:
val = heapq.heappop(self.large)
heapq.heappush(self.small, -1*(val))
def findMedian(self) -> float:
if len(self.small) > len(self.large):
return -1 * self.small[0]
if len(self.small) < len(self.large):
return self.large[0]
return (-1*self.small[0]+self.large[0])/2