서론
sLLM을 특정 도메인에 맞게 fine-tuning 하기 위해서 알아보던 중에 LLaMa Factory를 알게 됐다.
LLaMa Factory

대형 언어 모델(LLM) 을 학습 및 파인튜닝하기 위한 플랫폼
LLaMa Factory를 사용하면 코드를 작성하지 않고도 수백 개의 사전학습(pre-trained) 모델을 로컬 환경에서 파인튜닝 할 수 있음
- Models (지원하는 모델) : LLaMA, LLaVA, Mistral, Mixtral-MoE, Qwen, Yi, Gemma, Baichuan, ChatGLM, Phi 등
- Trainers : (점진적) 사전학습, (멀티모달) 명령어 기반 지도학습 파인 튜닝, 보상 모델 학습, PPO 학습, DPO학습, KTO 학습, ORPO 학습
- 연산 정밀도 지원 : 16비트 전파라미터(full-parameter) 파인튜닝, 파라미터 고정(frozen) 파인튜닝, LoRA 파인튜닝, AQLM / AWQ / GPTQ / LLM.int8 / HQQ / EETQ 기반의 2/3/4/5/6/8비트 QLoRA 파인튜닝
- 최적화 알고리즘 : GaLore, BAdam, DoRA, LongLoRA, LLaMA Pro, Mixture-of-Depths, LoRA+, LoftQ, PiSSA
- 가속 연산(Acceleration) : FlashAttention-2, Unsloth
- 추론 엔진: HuggingFace Transformers, vLLM
- 모니터링 도구 : LlamaBoard, TensorBoard, Weights & Biases(Wandb), MLflow, SwanLab 등
LLaMa Factory GUI
- CLI 외에 GUI를 제공하고 있어서 마음대로 핸들링이 가능하다는 것이 특장점이다. 설치해서 터미널에서 GUI 켜는 명령어만 켜주면 아래와 같은 GUI가 나온다.
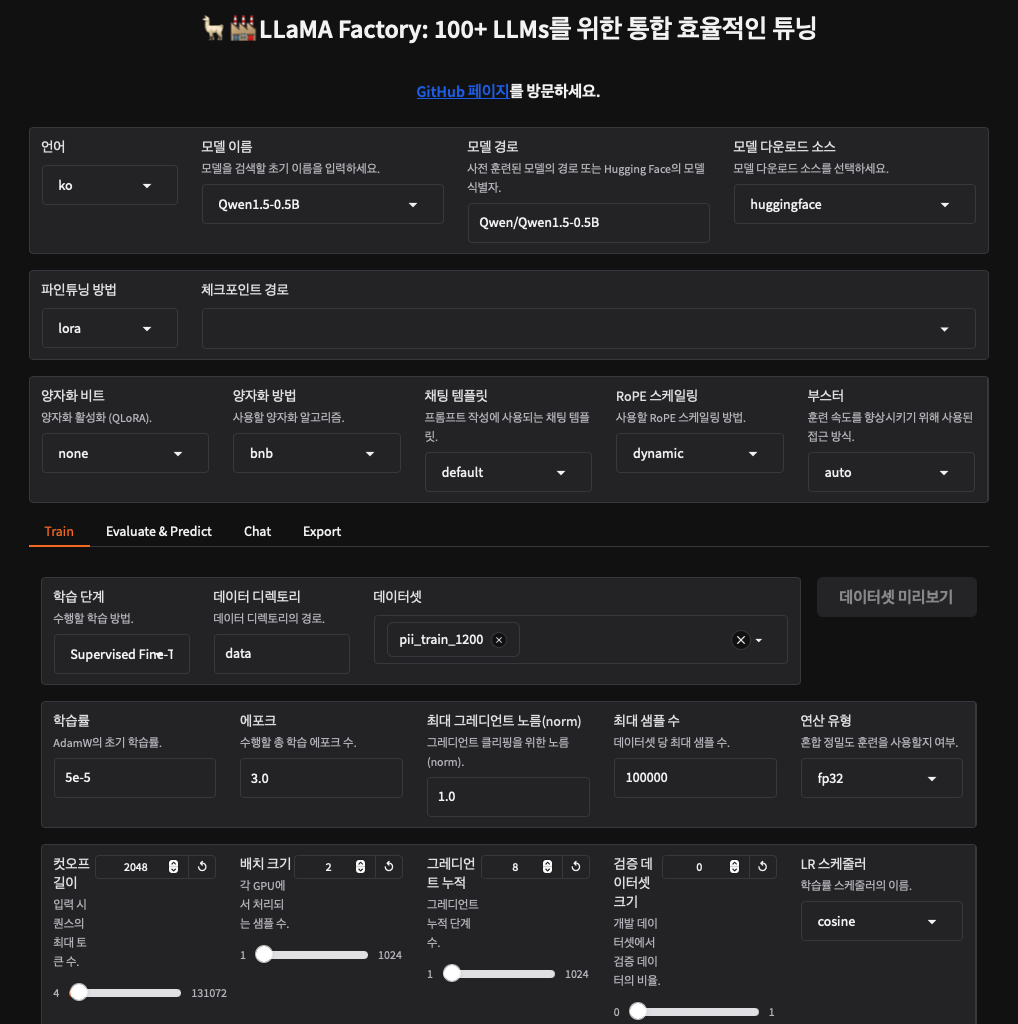
추후에 다시 자세히 언급해보도록 하겠다.
Data Preparation
일단 LLaMa Factory에 맞춰서 fine-tuning 하기 위해서 데이터셋을 만들어줘야 하는데,dataset_info.json 로 전처리된 로컬 데이터셋과 온라인 데이터셋에 대한 정보를 모두 포함한다.
사용자 정의 데이터셋을 사용하려면, 반드시 이 파일에 해당 데이터셋과 필드 구조를 정의해야 한다.
현재 LLaMA-Factory는 두 가지 포맷을 지원하고 있다.
(1) Alpaca 포맷 (2) ShareGPT 포맷
1. Alpaca 포맷
- 명렁어 기반 미세조정(Instruction Tuning), 사전학습(Pre-training), 선호도 학습(Preference Learning), KTO 학습, 멀티모달 학습(이미지/비디오/오디오)
[Instruction Tuning 데이터셋]
{
"instruction": "계산해줘: 자동차 - $3000, 옷 - $100, 책 - $20",
"input": "",
"output": "총 비용은 $3000 + $100 + $20 = $3120입니다."
}instruction: 인간이 내린 지시 (필수)input: 추가 입력 (선택)output: 모델의 답변 (필수)system: 시스템 프롬프트 (선택)history: 이전 대화 기록 (질문, 답변) 쌍의 리스트
👉 실제 입력: instruction\ninput 을 결합한 형태가 모델에 주어짐
👉 출력: output 값이 모델의 예측값
multi turn (history 포함)
[
{
"instruction": "오늘 날씨 어때?",
"input": "",
"output": "오늘은 맑아요.",
"history": [
["비 올까?", "아니요, 맑아요."],
["산책해도 될까?", "공기 좋고 좋아요."]
]
}
]dataset_info.json 구성 예시
"데이터셋명": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}[Pretraining dataset]
사전학습은 레이블 없는 텍스트를 모델이 언어적 패턴을 학습하도록 사용함
일반적으로 웹에서 크롤링한 도메인별 텍스트로 구성함
[
{"text": "문서 내용"},
{"text": "또 다른 문서 내용"}
]
dataset_info.json 예시
"데이터셋명": {
"file_name": "data.json",
"columns": {
"prompt": "text"
}
}[Preference dataset]
보상모델, DPO, ORPD 학습시 사용
하나의 질문에 대해 더 나은 답변(shosen)과 덜 나은 답변(rejected)을 함께 제공
[
{
"instruction": "질문",
"input": "추가 입력",
"chosen": "더 나은 답변",
"rejected": "덜 나은 답변"
}
]dataset_info.json 예시
"데이터셋명": {
"file_name": "data.json",
"ranking": true,
"columns": {
"prompt": "instruction",
"query": "input",
"chosen": "chosen",
"rejected": "rejected"
}
}[KTO dataset]
output에 대한 true/false 피드백 (kto_tag)을 함께 제공
chosen/rejected가 아닌 단일 답변 평가
[
{
"instruction": "질문",
"input": "입력",
"output": "답변",
"kto_tag": true
}
]dataset_info.json 예시
"데이터셋명": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"kto_tag": "kto_tag"
}
}[multi-modal dataset]
image
{
"instruction": "이미지를 설명해줘",
"input": "",
"output": "이건 고양이야",
"images": ["images/cat.jpg"]
}
video
{
"instruction": "이 영상에서 무슨 일이 벌어지고 있나?",
"input": "",
"output": "사람이 춤추고 있어",
"videos": ["videos/dance.mp4"]
}
audio
{
"instruction": "이 음성을 텍스트로 변환해줘",
"input": "",
"output": "안녕하세요",
"audios": ["audios/hello.wav"]
}각각 datset_info.json 구성은 images, videos, audios 키만 바뀌며 동일한 패턴
2. ShareGPT 포맷
역할 구분이 명확 (e.g. human gpt, function_call, observation)
멀티턴 대화 표현에 용이
conversations 컬럼 안에 턴 리스트가 들어감
[Instruction Tuning 데이터셋] - ShareGPT 포맷
{
"conversations": [
{ "from": "human", "value": "1990년 5월 15일에 태어났어. 몇 살이야?" },
{ "from": "function_call", "value": "{\"name\": \"calculate_age\", \"arguments\": {\"birthdate\": \"1990-05-15\"}}" },
{ "from": "observation", "value": "{\"age\": 35}" },
{ "from": "gpt", "value": "오늘 기준으로 35세입니다." }
],
"system": "시스템 프롬프트 (선택)",
"tools": "[{함수 정보}]"
}human과 observation은 홀수 인덱스, gpt와 function_call은 짝수 인덱스여야 함.
dataset_info.json 예시
"데이터셋명": {
"file_name": "data.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
}
}[Preference 데이터셋] - (ShareGPT 포맷)
{
"conversations": [
{ "from": "human", "value": "호랑이는 풀을 먹나요?" }
],
"chosen": {
"from": "gpt",
"value": "호랑이는 육식 동물입니다. 주로 고기를 먹습니다..."
},
"rejected": {
"from": "gpt",
"value": "호랑이는 풀을 먹지 않아요."
}
}dataset_info.json
"데이터셋명": {
"file_name": "data.json",
"formatting": "sharegpt",
"ranking": true,
"columns": {
"messages": "conversations",
"chosen": "chosen",
"rejected": "rejected"
}
}OpenAI 포맷이라고 해서 SharedGPT 포맷의 변형으로 messages키에 role/content 쌍을 포함하는 포맷이다.
[
{
"messages": [
{ "role": "system", "content": "너는 친절한 도우미야." },
{ "role": "user", "content": "안녕?" },
{ "role": "assistant", "content": "안녕하세요! 무엇을 도와드릴까요?" }
]
}
]
dataset_info.json
"데이터셋명": {
"file_name": "data.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant",
"system_tag": "system"
}
}
Every tap in chicken jockey clicker upgrades your bird, your speed, and your hilarious domination over the farm world.