[Tensorflow] 1. TensorFlow for Artificial Intelligence, Machine Learning, and Deep Learning Paradigm(2 week Introduction to Computer Vision) : Programming (1)
Tensorflow_certification(텐서플로우 자격증)
[Tensorflow] 1. TensorFlow for Artificial Intelligence, Machine Learning, and Deep Learning Paradigm(2 week Introduction to Computer Vision) : Programming (1)
컴퓨터 비전 programming 예시
- 이전 장에서는 해결하려는 문제를 파악하는 신경망을 만드는 방법을 살펴봤다.
x와 y 사이의 관계를 학습하기 위해 기계 학습을 사용하는 대신 y=2x-1 함수를 직접 작성하는 것이 더 쉬웠을 것이다. - 하지만 그러한 규칙을 작성하는 것이 훨씬 더 어려운 시나리오(예: 컴퓨터 비전 문제)는 어떨까?
- 10가지 유형이 포함된 데이터 세트에서 학습된 다양한 의류 품목을 인식하는 신경망을 구축하는 시나리오를 살펴보자.
[1] data load
먼저 tensorflow를 로드한다.
import tensorflow as tf
print(tf.__version__)keras의 datasets의 fahsion_mnist 데이터셋을 불러온다.
이 객체에 대해 load_data()를 호출하면 각각 두 개의 목록이 있는 두 개의 튜플이 제공된다.
해당 데이터는 의류 항목과 해당 라벨이 포함된 그래픽 사진에 대한 훈련 및 테스트 값이다.
fmnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = fmnist.load_data()Fashion MNIST 데이터 세트는 회색조 28x28 픽셀 의류 이미지 모음이다.
각 이미지는 이 표에 표시된 라벨과 연결되어 있다.
[2] data visualization
이 값들이 어떤 형태로 구성되어 있는지 확인하기 위해서,
학습 이미지(이미지 및 numpy 배열 모두)와 학습 라벨을 출력해보자.
배열의 다양한 인덱스를 실험할 수 있는데, 예를 들어 인덱스 42를 살펴보자.
import matplotlib.pyplot as plt
import numpy as np
index = 0
np.set_printoptions(linewidth=320)
#print the label and image
print(f'LABEL: {training_labels[index]}')
print(f'\nIMAGE PIXELE ARRAY:\n {traning_images[index]}')
# visualize the image
plt.imshow(training_images[index])[3] data normalization
숫자의 모든 값이 0에서 255 사이에 있다는 것을 볼 수 있다.
특히 이미지 처리에서 신경망을 훈련하는 경우 여러 가지 이유로 모든 값을 0에서 1 사이로 조정하면 일반적으로 더 잘 학습할 수 있.
이를 '정규화'라고 한다.
이러한 정규화 프로세스를 Python에서는 반복 없이 진행할 수 있다.
training_images = training_images /255.0
test_images = test_images / 255.0[4] traning data / test data split
이제 데이터 세트가 훈련과 테스트라는 두 가지로 분할한다.
모델을 학습할 때는 훈련용 데이터 세트 1개와 모델이 아직 확인하지 못한 또 다른 데이터 세트를 활용한다.
훈련용으로 사용하지 않은 또 다른 데이터는 값을 분류하는 데 얼마나 좋은지 평가하는 데 사용된다.
[5] model build
이제 모델을 디자인해 보겠자.
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.summary()
Flatten: 28x28 픽셀을 가진 2차원의 데이터를 Flatten은 1차원 배열로 변환한다.
Dens : 뉴런 레이어를 추가한다.
뉴런의 각 층에는 무엇을 해야 할지 알려주는 활성화 함수가 필요하다.
활성화 함수(activation function)에는 다양한 옵션이 있다.
현재는 relu, softmax를 각 각 사용했다.
ReLU
- ReLU : x > 0인 경우: x를 반환하고 그 외에 0을 반환한다.
즉, 0보다 큰 값만 네트워크의 다음 계층으로 전달함
Softmax
- 값 목록을 가져와 모든 요소의 합이 1이 되도록 스케일링한다.
모델 출력에 적용할 때 스케일링된 값을 해당 클래스의 확률로 생각할 수 있다.
예를 들어, 출력 밀집 레이어에 10개의 단위가 있는 분류 모델에서 인덱스 = 4에서 가장 높은 값을 갖는 것은 모델이 입력 의류 이미지가 코트라고 가장 확신한다는 것을 의미한다. 인덱스 = 5이면 샌들이 된다.
Softmax 함수와 값이 계산되는 방법에 대해 더 알고 싶다면 아래의 강의를 참고하면된다.
inputs = np.array([[1.0, 3.0, 4.0, 2.0]])
inputs = tf.convert_to_tensor(inputs)
print(f"input to sofrtmax function: {inputs.numpy()}")
model compile
모델을 정의했다면 다음으로 할 일은 모델을 실제로 구축하는 것이다.
이전처럼 옵티마이저와 손실 함수를 사용하여 컴파일한 다음, 학습 데이터를 훈련 레이블에 맞추도록 요청하는 model.fit()을 호출하여 학습한다.
학습 데이터와 실제 레이블 사이의 관계를 파악하므로 나중에 학습 데이터와 유사한 입력이 있으면 해당 입력에 대한 레이블이 무엇인지 예측할 수 있다.
model.compile(optimizer = tf.optimzers.Adam(),
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images, training_labels, epocsh=5)
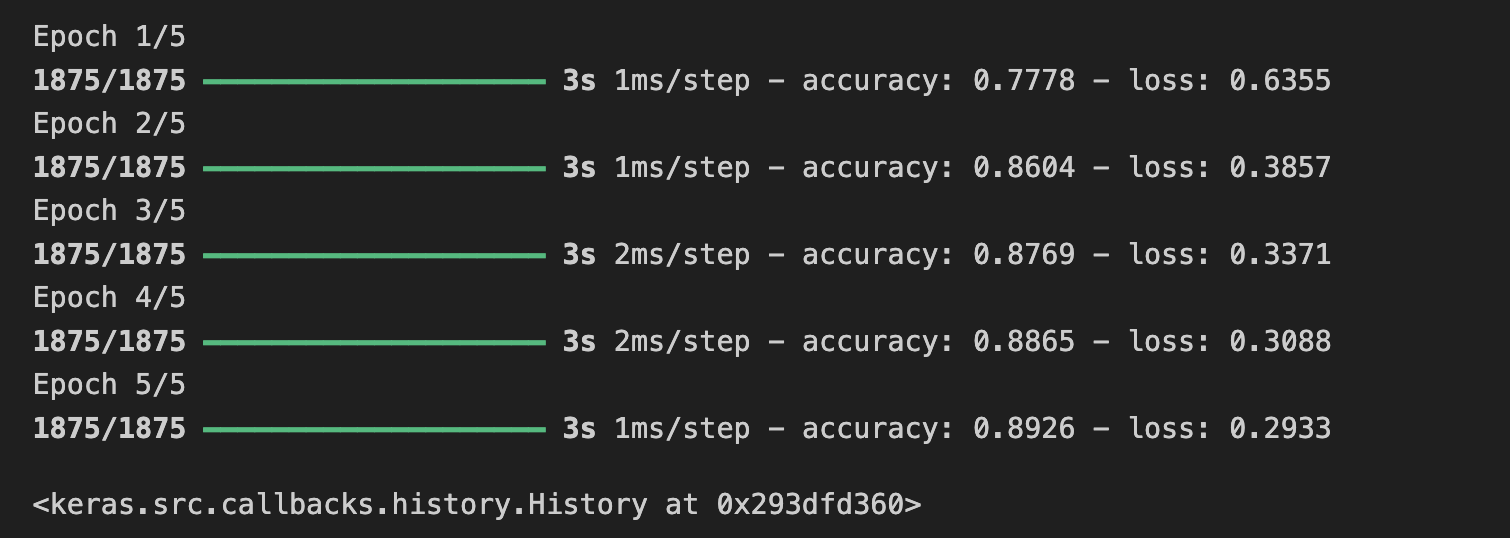
훈련이 완료되면 최종 에포크가 끝날 때 정확도 값이 표시된다.
0.9098처럼 보일 수도 있는데, 이는 신경망이 훈련 데이터를 분류하는 데 약 91% 정확하다는 것을 의미한ㄷ.
즉, 91%의 정확도로 시간 동안 작동하는 이미지와 레이블 간의 패턴 일치를 알아냈다. 훌륭하지는 않지만 5번의 에포크 동안만 훈련되었고 매우 빠르게 수행되었다는 점을 고려하면 나쁘지 않다.
하지만 보이지 않는 데이터에는 어떻게 작동할지 확인하기 위해 테스트 데이터를 사용해서 알아봐야한다. 이것에 테스트 이미지와 라벨이 있는 이유이다.
이 테스트 데이터 세트를 입력으로 사용하여 model.evaluate()를 호출하면 모델의 손실과 정확성을 확인할 수 있다.
model test
model.evaluate(test_images, test_labels)
#output
313/313 ━━━━━━━━━━━━━━━━━━━━ 0s 556us/step - accuracy: 0.8779 - loss: 0.3329
[0.33742761611938477, 0.878000020980835]여기서 정확도는 약 0.88 정도이다.
이는 전체 테스트 세트에서 88%의 정확도를 의미한다.
테스트 데이터의 정확도가 학습 데이터의 정확도보다 낮기 때문에, 이를 개선할 수 있는 방법을 살펴보자.
parameter 수정을 통한 model 개선
- 이제 신경망의 파라미터를 수정하고, epoch 수를 변경해보면서 훈련 데이터에 0.71 이상 테스트 데이터에서 0.66 이상을 달성할 수 있는지 진행해보자.
연습 1
모델을 사용해서 각 테스트 이미지에 대한 분류 예측을 생성하고,
모델이 예측한 첫 번째 항목을 출력해보자.
classifications = model.predict(test_images)
print(classification[0])
#output
array([1.5927902e-05, 2.6639412e-07, 1.3448829e-06, 5.1370461e-07, 2.0369289e-06, 1.2823188e-02, 1.2381415e-05, 8.4060863e-02, 1.0796425e-04, 9.0297550e-01], dtype=float32)print(test_labels[0])
#output
9위의 배열은 해당 아이템이 10개 클래스 각각에 해당될 확률이다.
모델의 출력은 10개의 숫자 목록으로 나타나는데, 이 숫자는 분류되는 값이 해당 값일 확률이다(https://github.com/zalandoresearch/fashion-mnist#labels).
즉, 목록의 첫 번째 값은 이미지가 '0'일 확률입니다. '(티셔츠/상의), 다음은 '1'(바지) 등입니다. 모두 매우 낮은 확률이라는 점을 확인할 수 있다.
인덱스 9(발목 부츠)의 경우 확률은 90으로, 즉 신경망은 이미지가 발목 부츠일 가능성이 가장 높다고 알려주는 것이다.
이 목록에 해당 품목이 앵클부츠라는 것을 알 수 있는 이유는 목록의 10번째 요소가 가장 크며, 발목 부츠에는 9라는 라벨이 붙어 있기 때문이다.
목록과 라벨 모두 0을 기준으로 하므로 라벨이 9인 앵클부츠는 10개 클래스 중 10번째라는 의미입니다. 10번째 요소가 가장 높은 값을 갖는 목록은 신경망이 분류 중인 항목이 발목 부츠일 가능성이 가장 높다고 예측했음을 의미한다.
연습 2
fmnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = fmnist.load_data()
training_iamges = training_images/255.0
test_images = test_images/255.0
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer = 'adam',
loss = 'sparse_categorical_crossentropy')
model.fit(training_images, training_labels, epochs=5)
model.evaluate(test_images, test_labels)
classifications = model.predict(test_images)
print(classifications[0])
print(test_labels[0])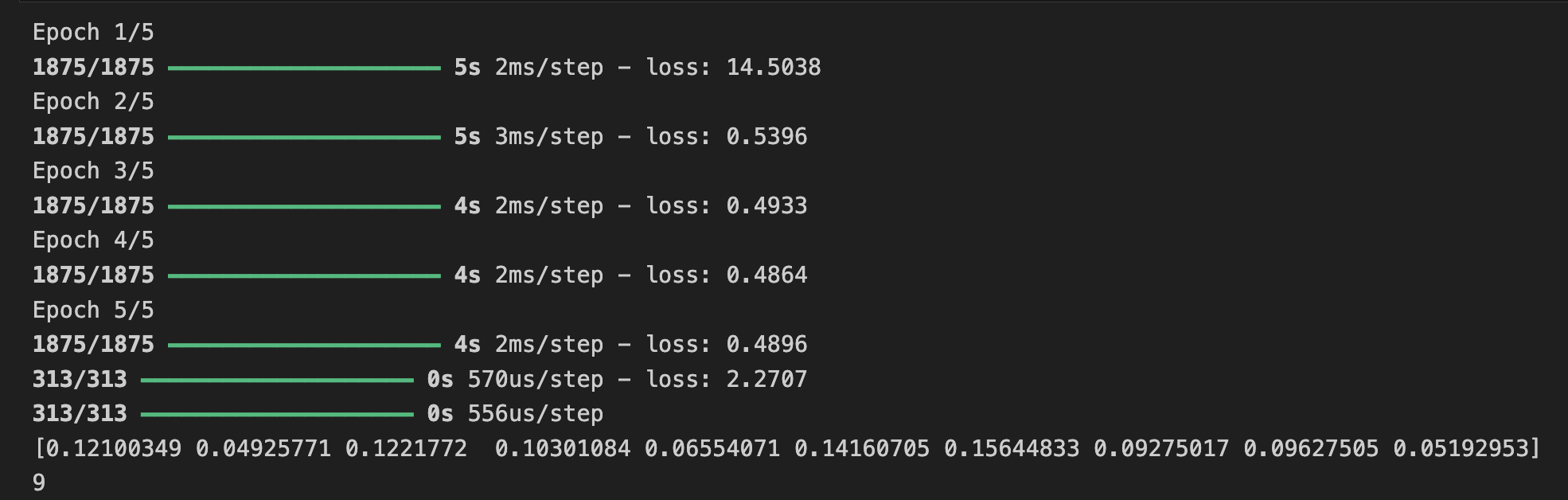
model.summary()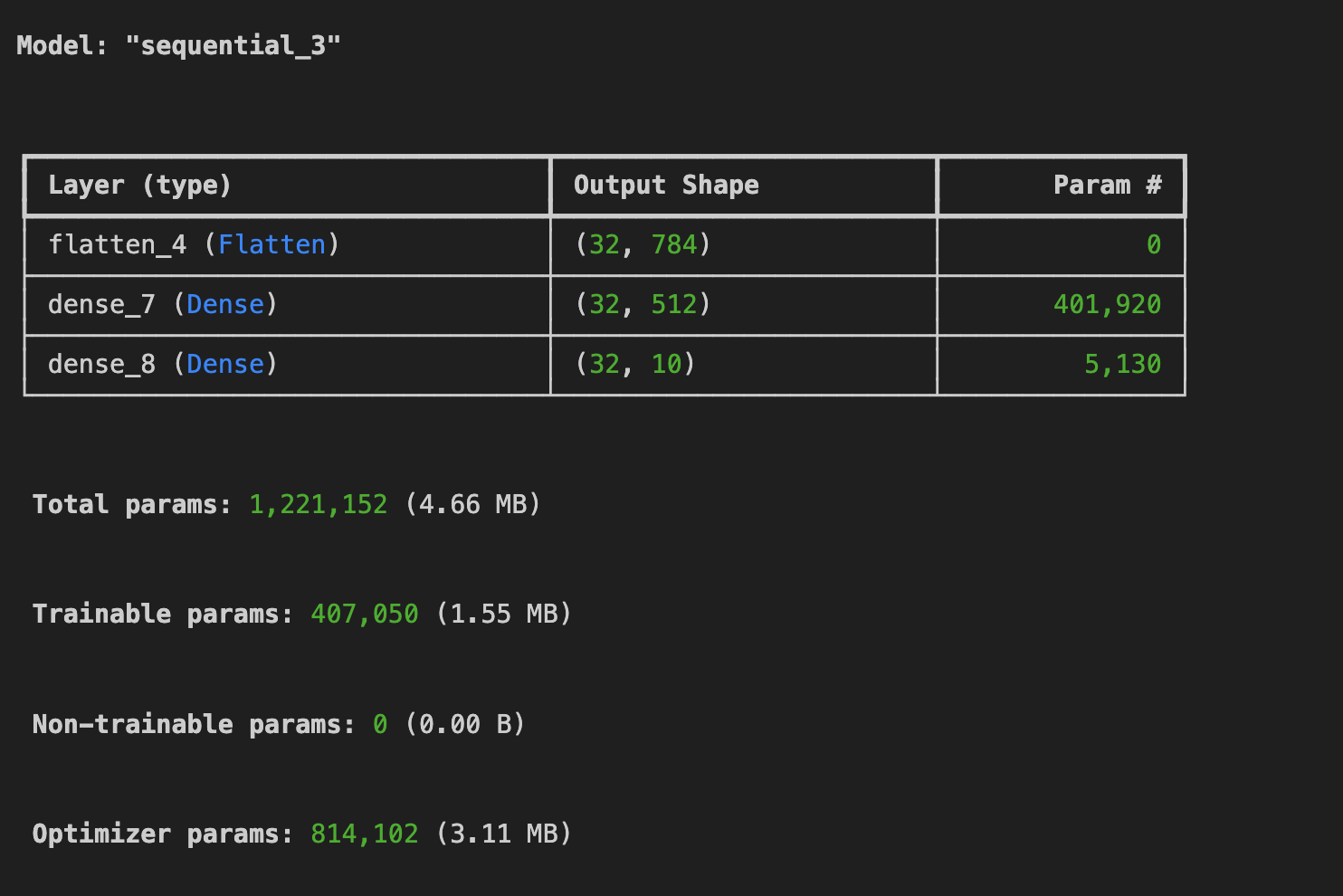
fmnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = fmnist.load_data()
training_images = training_images/255.0
test_imagees = test_images /255.0
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1024, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(loss='sparse_categorical_crossentropy',
optimizer= 'adam')
model.fit(training_images, training_labels, epochs=5)
model.evaluate(test_images, test_labels)
classifications = model.predict(test_images)
print(classifications[0])
print(test_labels[0])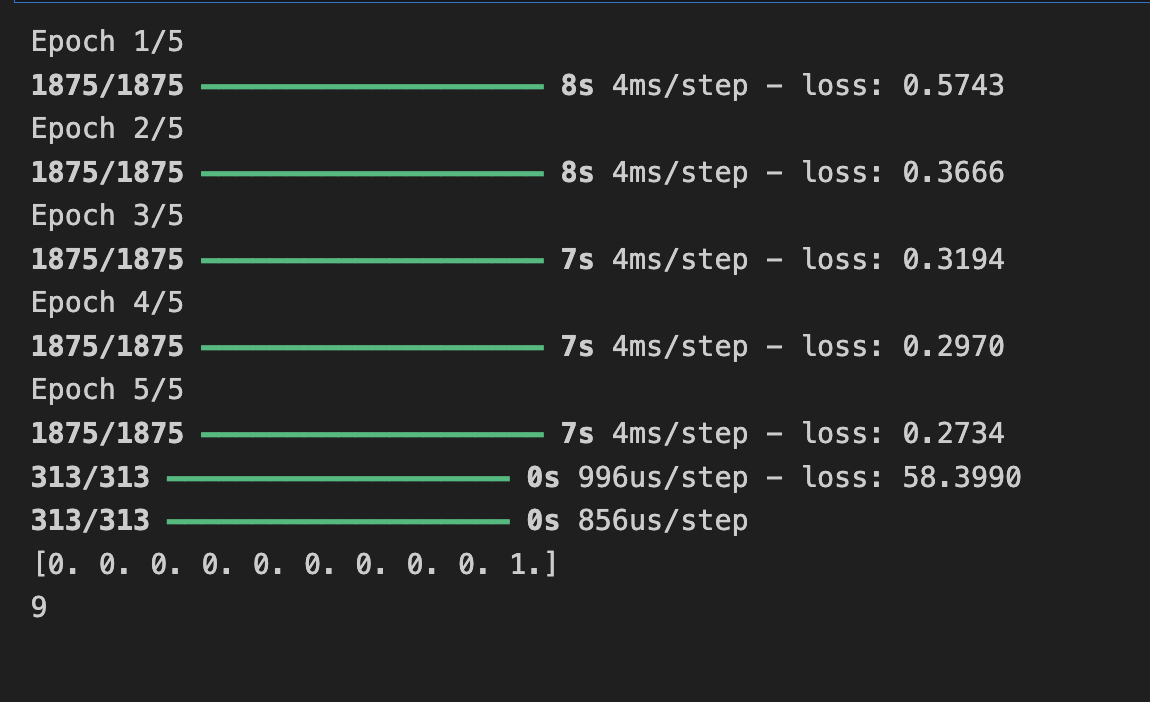
위에서는 뉴런을 512개를 사용했지만 1024개로 증가한다면 어떤 영향이 있을까?
학습 시간은 더 오래 걸리게 되지만 정확도가 높아지게 된다.
많은 뉴런을 추가하면 더 많은 계산을 수행해야 하므로 프로세스 속도가 느려지지만 이 경우에는 좋은 영향을 미치므로 더 정확해집니다. 그렇다고 해서 항상 '더 많을수록 좋다'는 의미는 아니다.
연습 3
Flatten() 레이어를 제거하면 어떻게 될까?
데이터 모양에 대한 오류가 발생하게 된다. 모델의 첫 번째 레이어를 우리가 가지고 있는 데이터의 모양이 28x28 이미지이고 28개의 뉴런으로 구성된 28개 레이어는 실행 불가능하므로 28,28을 784x1로 '평탄화'해야 한다.
이를 처리하기 위해 모든 코드를 직접 작성하는 대신 처음에 Flatten() 레이어를 추가하고 나중에 배열이 모델에 로드되면 자동으로 평면화 된다.
fmnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = fmnist.load_data()
training_images = training_images/255.0
test_images = test_images/255.0
model = tf.keras.Sequential([
# tf.keras.layers.Fatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam')
model.fit(training_images, training_labels, epochs=5)
model.evaluate(test_images, test_labels)
#output
ValueError: Argument `output` must have rank (ndim) `target.ndim - 1`. Received: target.shape=(32,), output.shape=(32, 28, 10)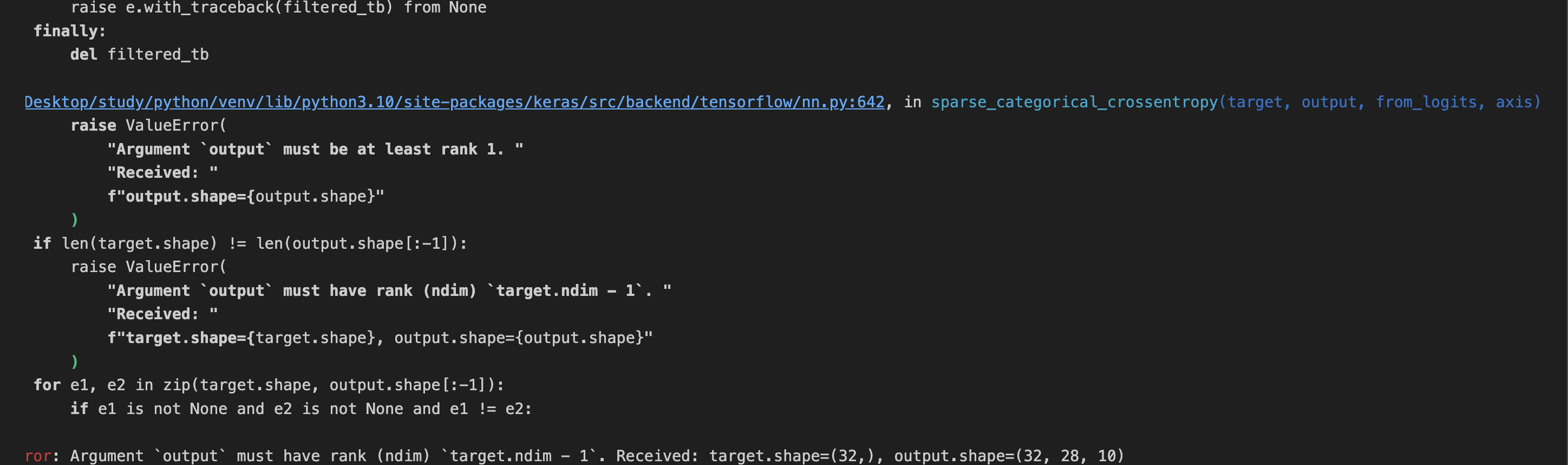
연습 4
연습 4:
최종(출력) 레이어가 10이 아닌 다르게 되어 있다면 예를 들어, 5를 사용하여 네트워크를 훈련한다면 어떻게 될까?
예상치 못한 값을 발견하자마자 오류가 발생한다.
마지막 레이어의 뉴런 수는 분류하려는 클래스 수와 일치해야 한다. 이 경우 숫자 0-9이므로 10개가 있으므로 최종 레이어에는 10개의 뉴런이 있어야 한다.
fmnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = fmnist.load_data()
training_images = training_images/255.0
test_imagees = test_images /255.0
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1024, activation=tf.nn.relu),
tf.keras.layers.Dense(5, activation=tf.nn.softmax),
])
model.compile(loss='sparse_categorical_crossentropy',
optimizer= 'adam')
model.fit(training_images, training_labels, epochs=5)
model.evaluate(test_images, test_labels)
classifications = model.predict(test_images)
print(classifications[0])
print(test_labels[0])
#output
Epoch 1/5
2024-04-13 15:43:54.893605: W tensorflow/core/framework/op_kernel.cc:1839] OP_REQUIRES failed at sparse_xent_op.cc:103 : INVALID_ARGUMENT: Received a label value of 9 which is outside the valid range of [0, 5). Label values: 0 7 1 6 3 4 0 8 3 1 2 6 7 9 9 3 6 6 6 3 2 2 6 3 3 2 0 0 9 5 0 1
2024-04-13 15:43:54.893626: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: INVALID_ARGUMENT: Received a label value of 9 which is outside the valid range of [0, 5). Label values: 0 7 1 6 3 4 0 8 3 1 2 6 7 9 9 3 6 6 6 3 2 2 6 3 3 2 0 0 9 5 0 1
[[{{function_node __inference_one_step_on_data_93115}}{{node compile_loss/sparse_categorical_crossentropy/SparseSoftmaxCrossEntropyWithLogits/SparseSoftmaxCrossEntropyWithLogits}}]]연습 5
연습 5:
네트워크의 추가 계층이 미치는 영향을 고려해보자.
512가 있는 레이어와 10이 있는 마지막 레이어 사이에 다른 레이어를 추가하면 어떻게 될까?
비교적 간단한 데이터이기 때문에 큰 영향은 없을 것이다. 훨씬 더 복잡한 데이터의 경우에는 추가 레이어가 필요한 경우가 많다.
fmnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels) , (test_images, test_labels) = fmnist.load_data()
training_images = training_images/255.0
test_images = test_images/255.0
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dense(64, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(optimizer = 'adam',
loss = 'sparse_categorical_crossentropy')
model.fit(training_images, training_labels, epochs=5)
model.evaluate(test_images, test_labels)
classifications = model.predict(test_images)
print(classifications[0])
print(test_labels[0])

연습 6
에포크에 대한 훈련의 영향을 고려해보자.
지금까지는 5번의 에포크를 시도 했으나, 15번의 에포크를 시도해본다면
아마도 5번의 에포크보다 손실이 훨씬 더 나은 모델을 얻게 될 것이다.
30번의 에포크를 시도해 보세요. 손실 값이 더 천천히 감소하고 때로는 증가하는 것을 볼 수 있다.
fmnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels) , (test_images, test_labels) = fmnist.load_data()
training_images = training_images/255.0
test_images = test_images/255.0
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
model.compile(optimizer = 'adam',
loss = 'sparse_categorical_crossentropy')
model.fit(training_images, training_labels, epochs=15)
model.evaluate(test_images, test_labels)
추가로 model.evaluate()의 결과가 크게 개선되지 않았다는 것을 알 수 있고, 약간 더 나쁠 수도 있다.
그 이유는 '과적합' 때문이며 신경망을 훈련할 때 주의해야 할 사항이다.
손실을 개선하지 않는다면 훈련에 시간을 낭비할 필요가 없다.
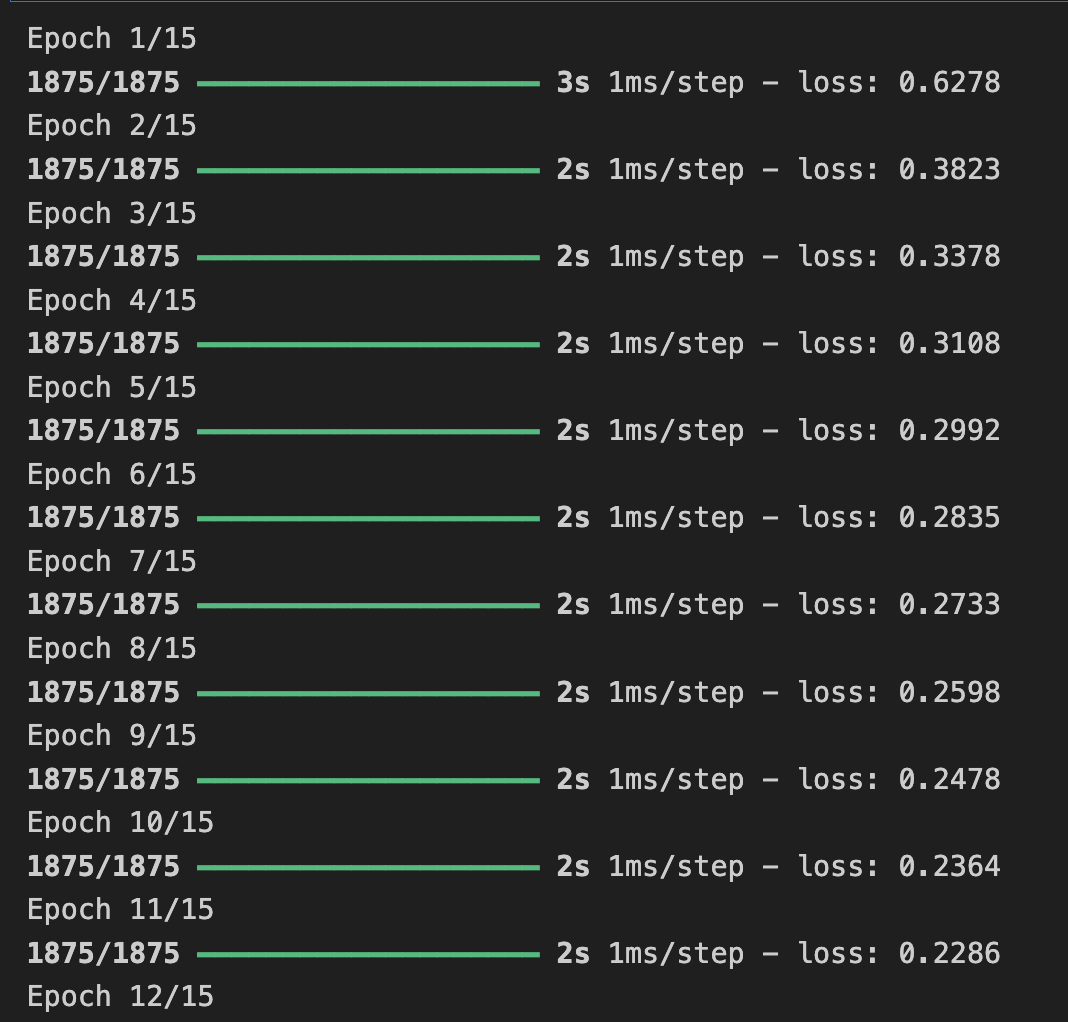
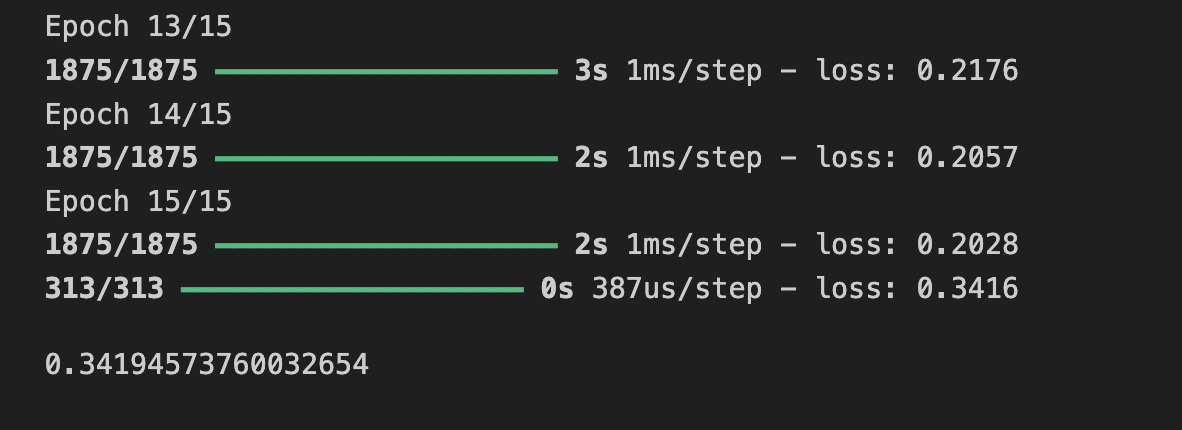
연습 7
훈련하기 전에 0-255 값에서 0-1 값으로 데이터를 정규화했다.
정규화를 하지 않으면 어떤 결과가 나오게 될까?
fmnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels) , (test_images, test_labels) = fmnist.load_data()
training_images=training_images/255.0 # Experiment with removing this line
test_images=test_images/255.0 # Experiment with removing this line
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
model.fit(training_images, training_labels, epochs=5)
model.evaluate(test_images, test_labels)
classifications = model.predict(test_images)
print(classifications[0])
print(test_labels[0])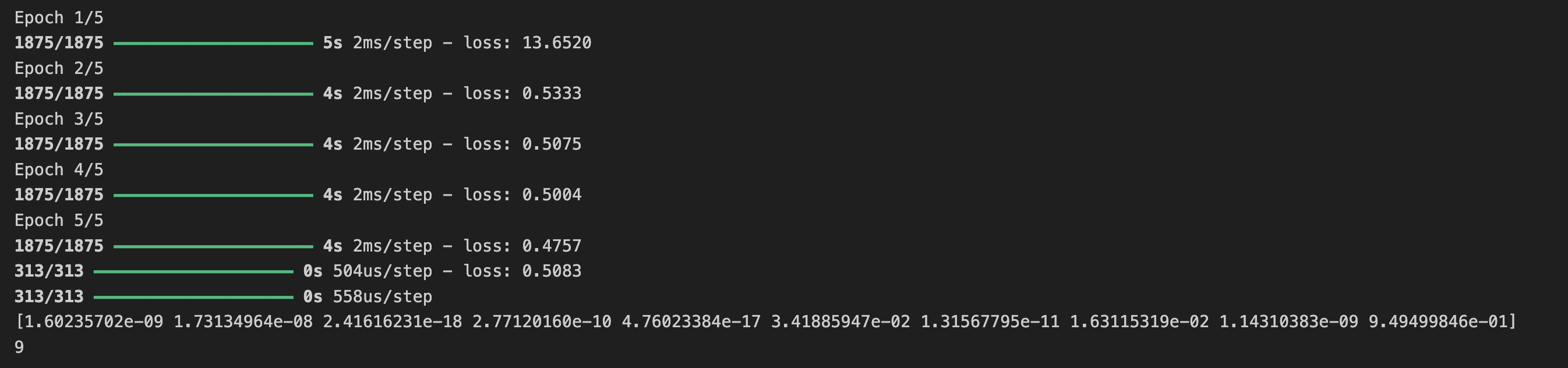
연습 8
이전에 추가 에포크에 대해 훈련할 때 손실이 변경될 수 있는 문제가 있었다.
그렇게 하기 위해 훈련을 기다리는 데는 약간의 시간이 걸렸을 수도 있고, '원하는 값에 도달하면 훈련을 멈출 수 있으면 좋지 않을까?'라고 생각할 수 도 있다.
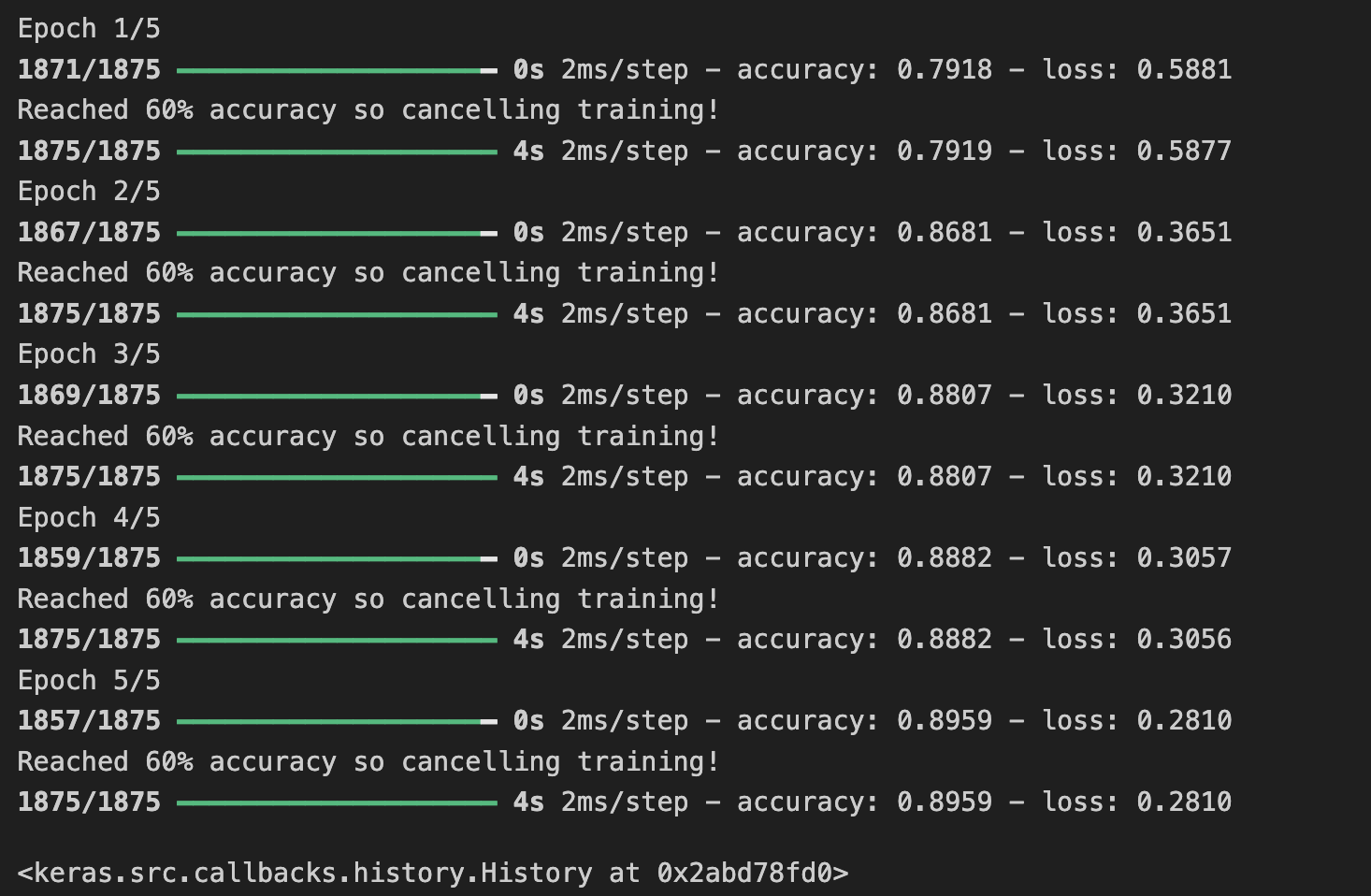
즉, 60%의 정확도이면 충분할 수 있으며, 3개의 에포크 이후에 정확도에 도달하면 왜 훨씬 더 많은 에포크가 끝날 때까지 기다리지 않을 수 있다.
callback 함수를 사용하면 된다.
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if (logs.get('accuracy') >=0.6):
print("\nReached 60% accuracy so cancelling training!")
self.model.stop_trainig=True
callbacks = myCallback()
fmnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels) , (test_images, test_labels) = fmnist.load_data()
training_images=training_images/255.0
test_images=test_images/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(training_images, training_labels,
epochs=5, callbacks=[callbacks])