[Tensorflow] 1. TensorFlow for Artificial Intelligence, Machine Learning, and Deep Learning Paradigm(4 week Using Real-world Images) : lecture
Tensorflow_certification(텐서플로우 자격증)
1. TensorFlow for Artificial Intelligence, Machine Learning, and Deep Learning Paradigm(4 week Using Real-world Images)
모든 이미지가 28x28이고 대상이 중심에 있는 것은 학습하기에 좋은 데이터셋이지만 현실적인 이미지와 복잡한 이미지를 다뤄본다.
컨볼루션 네트워크의 핵심 아이디어를 통해 알고리즘을 구현해서 이미지 정중앙에 있는 것이아니라 이미지 상의 위치에 상관없이, 또한
1메가 픽셀 1,000x1,000 이라던지 그레이 스케일이 아닌 컬러이미지 등의 데이터셋에서의 분류기를 만들어본다.
즉, 실제 시나리오와 유사한 데이터를 가지고 분류기를 만들어본다.
여기서 사용하는 이미지는 말과 인간 데이터이다.
여러 성별과 인종으로 구성된 다양한 인간과 여러 말의 사진을 통해서 분류기를 만든다.
컨볼루션 신경망을 더 크고 복잡한 데이터를 다룰 때 사용해본다.
Understading ImageDataGenerator
지금까지 심층 신경망을 이용한 이미지 분류기를 구축하고, 컨볼루션을 추가해 성능을 향상하는 것을 진행했다.
한 가지 제한은 매우 균일한 데이터 세트를 사용했다는 것이다.
옷의 이미지를 28x28 프레임으로 규정했다.
하지만 더 큰 사이즈의 이미지나 다양한 위치에 특성이 존재할 때는 어떻게 해야 할까? 예를 들어 사람과 말의 이미지를 보면 사이즈도 다르고 대상이 다양한 위치에 존재하고 있다.
어떤 경우는 대상이 여러 개일 수 있다. 게다가 앞서 살펴본 패션 데이터는 내장된 데이터 세트였다.
모든 데이터가 훈련과 테스트 세트를 위해 편리하게 분류되어 있고 레이블도 존재했다.
여러 시나리오에는 이런 경우 없이 스스로 진행해야 한다.
이번 섹션에서는 이를 쉽게 만들 수 있도록하는 API를 살펴본다.
특히 Tensorflow의 ImageGenerator이다.

ImageGenerator의 특징 중 하나는 하나의 디렉토리에 지정해 놓으면 하위 디렉토리에서 자동으로 레이블을 생성한다는 것이다.
예를 들어서 해당 디렉토리 구조를 보면 이미지 디렉토리가 있고, 훈련과 검증을 위한 하위 디렉토리가 있다.
여기에 말과 사람 하위 디렉토리를 두고 필수 이미지를 저장하면
ImageGenerator 가 그 이미지에 대한 피드를 생성하고 자동으로 레이블을 지정한다.

예를 들어 ImageGenerator 에서 말과 사람 디렉토리가 있고, 각 디렉토리에서 모든 이미지를 불러오면서 이에 맞는 레이블을 지정한다.
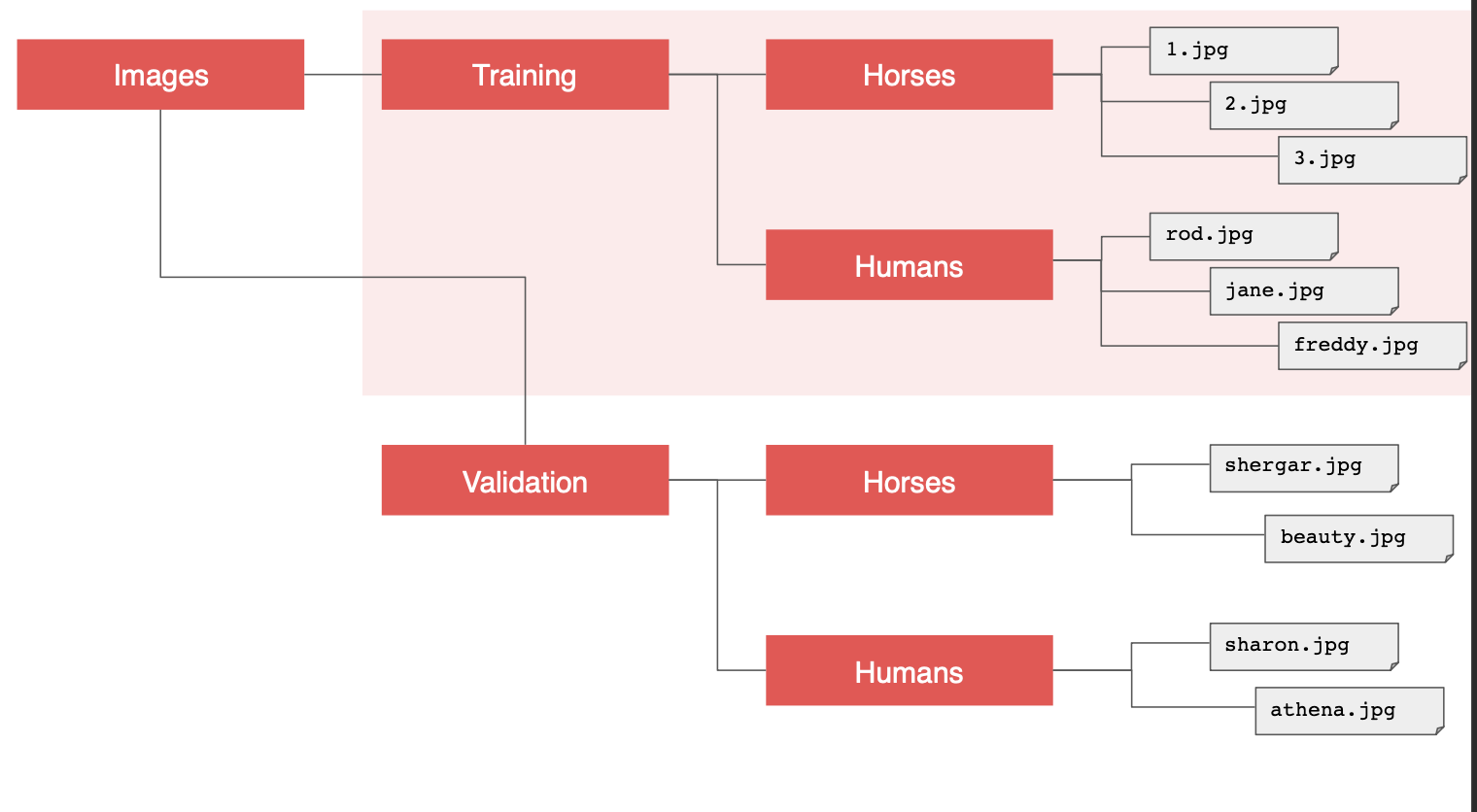
유사하게 검증 디렉토리를 가리키면 같은 일이 발생한다.
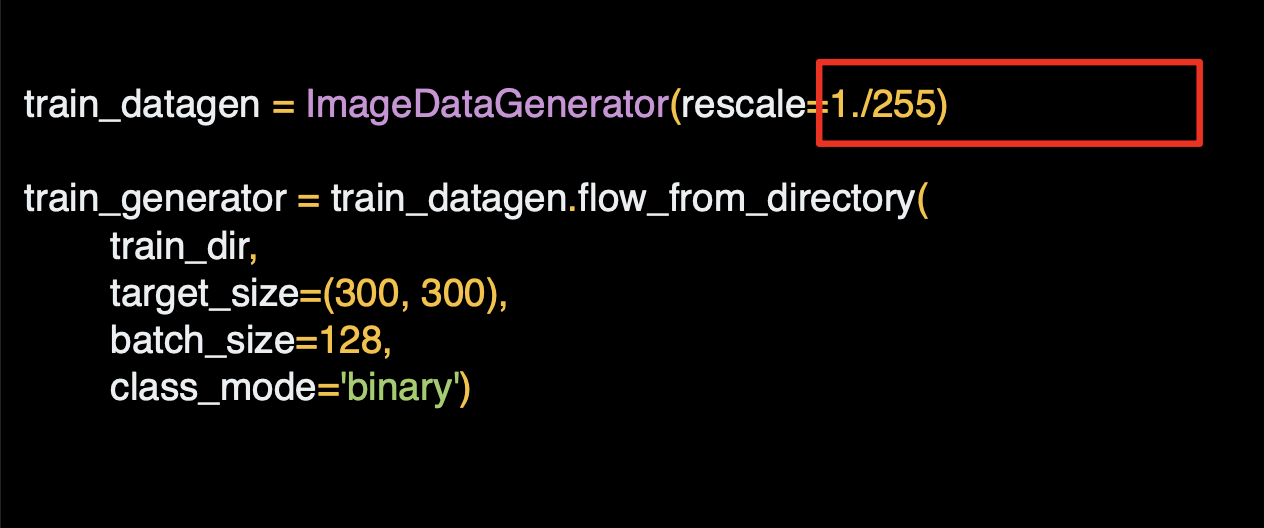
해당 코드를 살펴보면 ImageGenerator는 Keras.preprocessing.image로 사용이 가능하다.

그리고 이미지 생성기를 인스턴스화 할 수 있다.
리스케일로 데이터를 정규화한다.
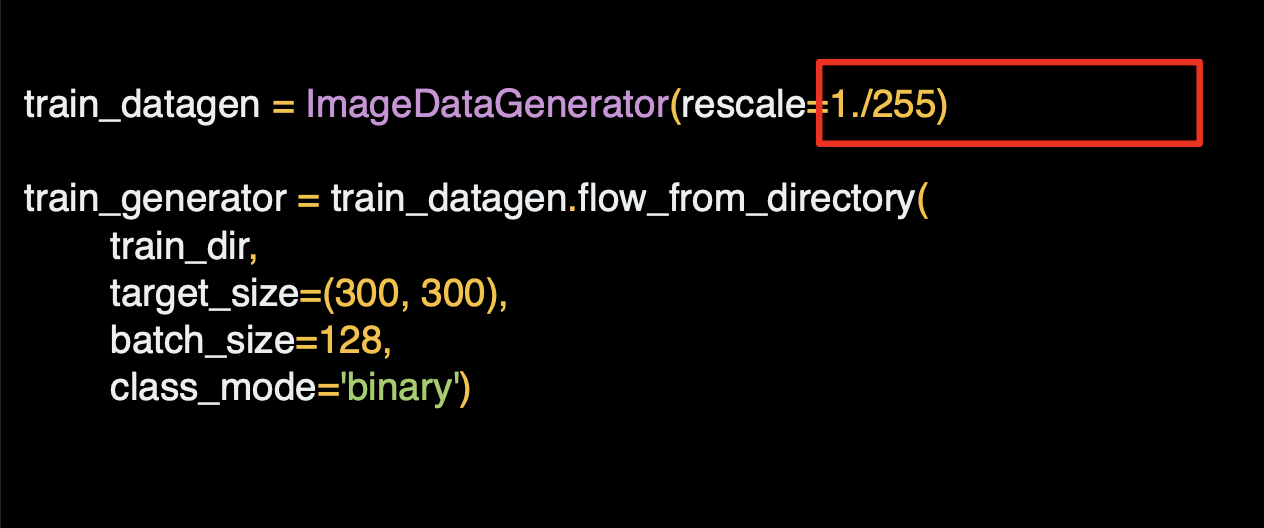
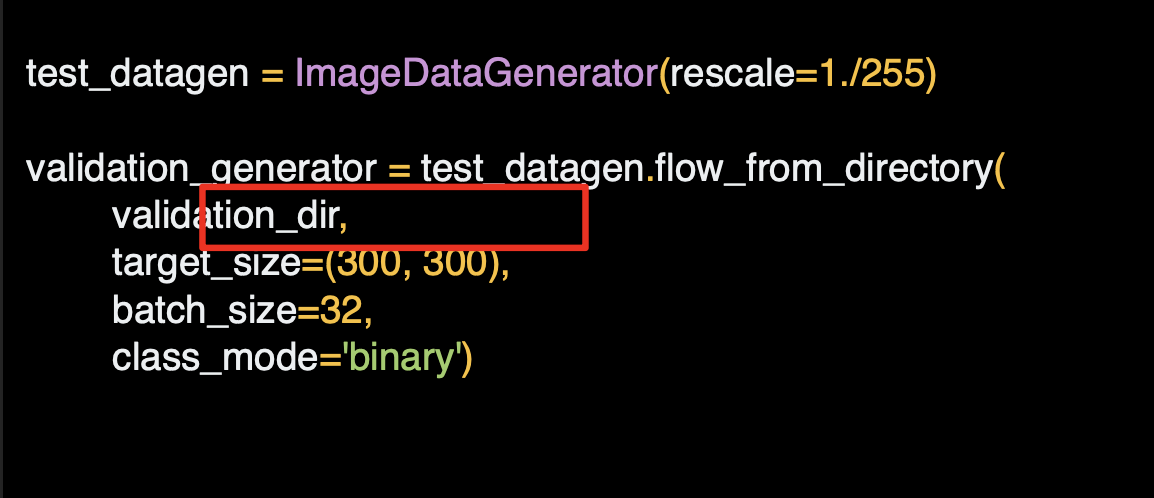
디렉토리 메서드에서 from_from_directory() 를 호출해서 해당 디렉토리 및 하위 디렉토리에서 이미지를 불러온다.
흔히 발생하는 실수는 하위 디렉토리에서 생성기를 가리키는 경우인데,
가리켜야 하는 디렉토리에는 언제나 이미지가 들어 있는 하위 디렉토리가 포함되어야 한다.
하위 디렉토리 이름은 그 속에 포함된 이미지의 레이블이 된다.
올바른 이미지 디렉토리를 가르켜야 한다.
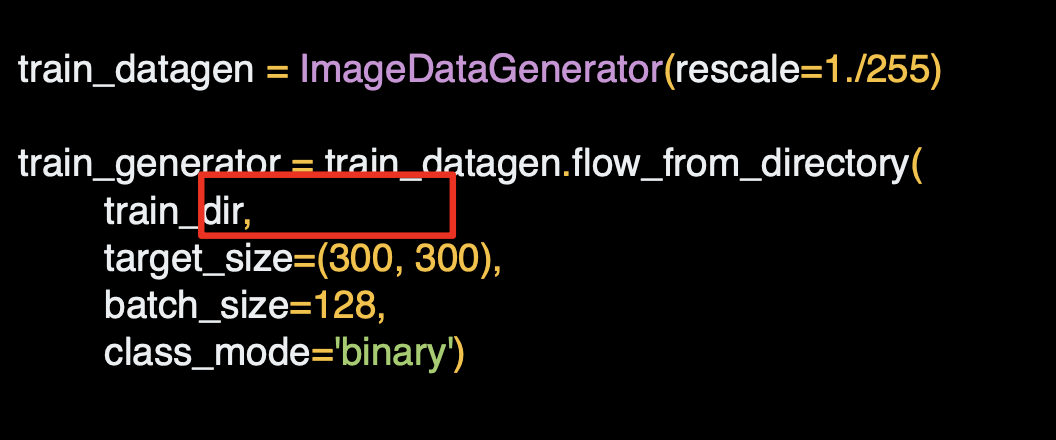
이미지는 다양한 형태와 사이즈로 나타낼 것이고, 훈련 신경망의 경우 입력값이 모두 동일한 사이즈여야 하므로 이미지 사이즈를 조정해서 일관성을 확보해야 한다.
해당 코드의 좋은 점은 이미지를 불러온 순간 사이즈가 조정된다는 것이다.
그래서 파일 시스템 내에서 수천 장의 이미지를 전처리 할 필요가 없다.
여기의 런타임에서 실행시는 바로 소스 데이터에 영향을 주지 않고 다양한 사이즈로 실험이 가능하다는 것이다.
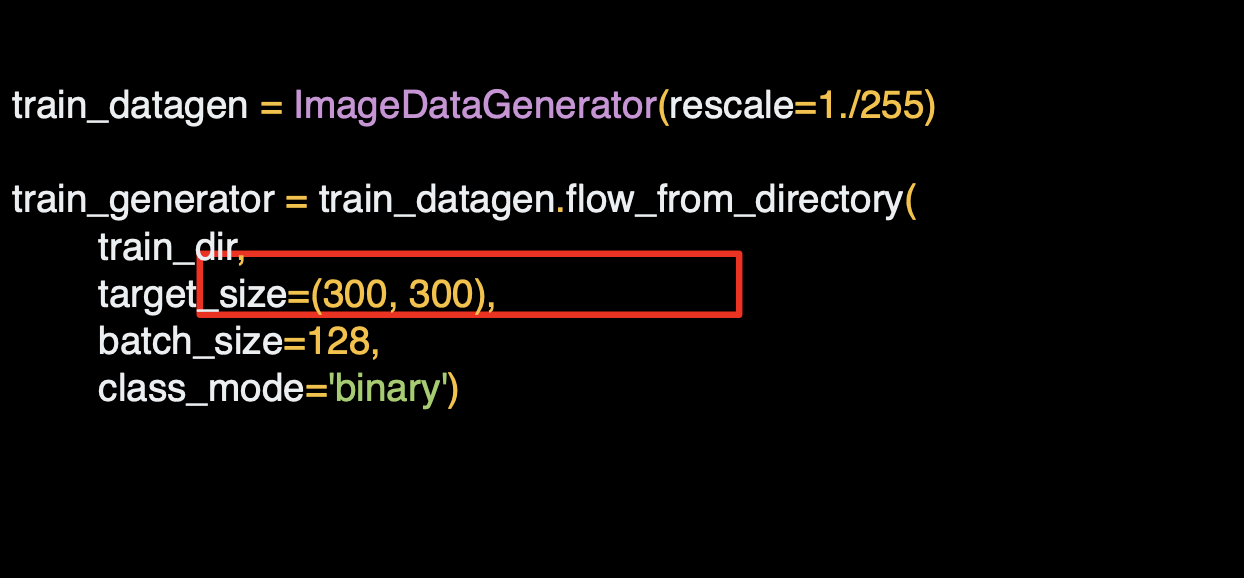
말과 사람 데이터 세트는 이미 300x300으로 지정되어 있는데,
다른 데이터를 사용하면 사이즈가 균일하지 않을 수 있다.
그렇기 때문에 해당 코드가 상당이 유용하다.
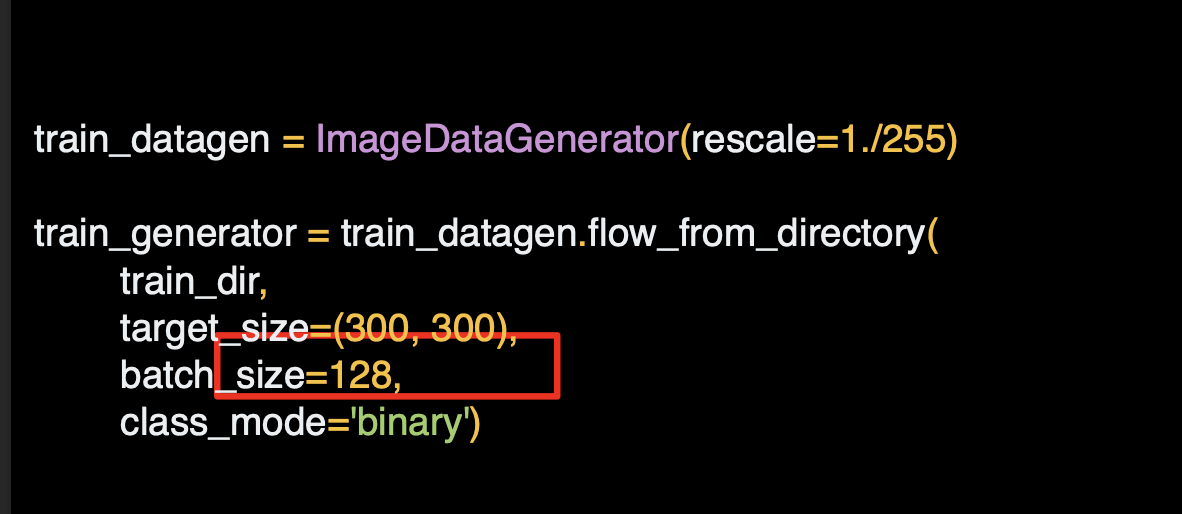
이미지는 훈련 및 검증 디렉토리에 배치 형태로 불러온다.
하나씩 작업하는 것보다 효율적이다.
배치 사이즈를 계산하는 것은 과학적 원리가 있다.
다양한 사이즈를 실험하면서 파라미터를 변경하면 결과가 어떻게 변하는지 살펴볼 수 있다.
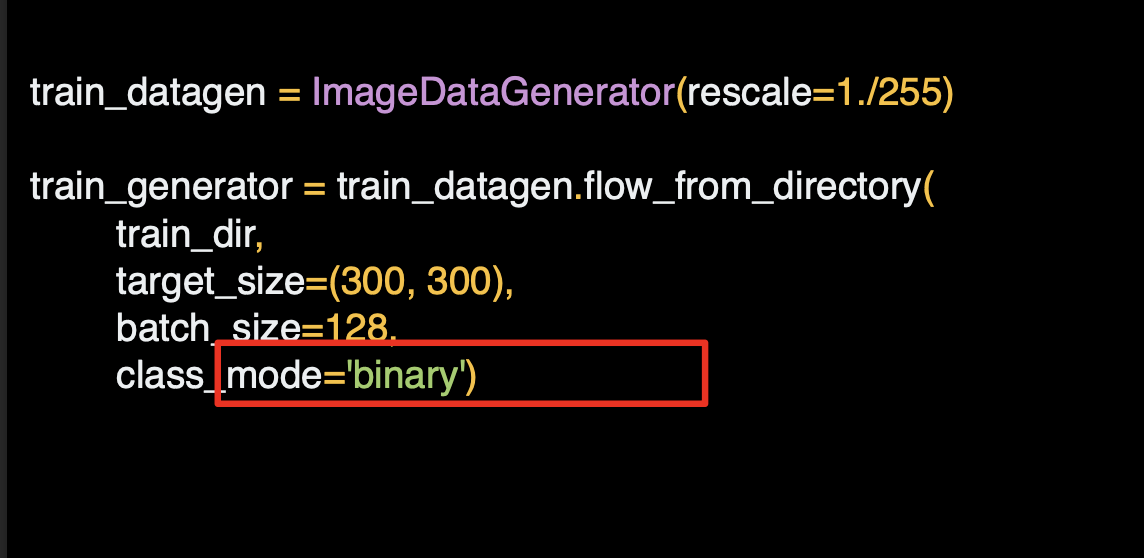
마지막으로 클래스 모드인데 이는 이진 분류기이다.
즉 서로 다른 두 가지 요소인 말과 사람 중 하나를 고르도록 명시하는 것이다.
두 개가 넘는 요소를 다루는 다른 옵션은 다른 옵션이 또 있다.
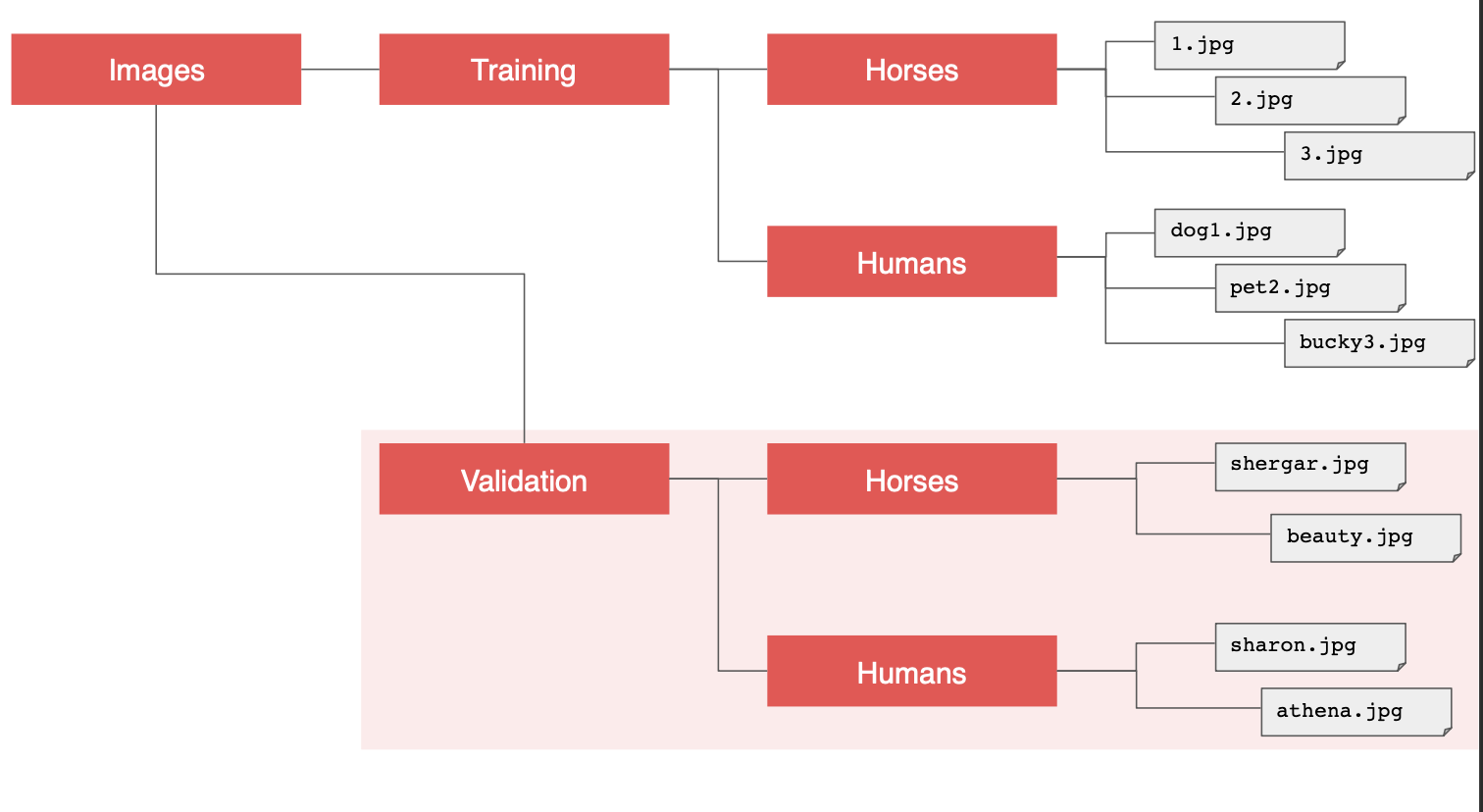
검증 생성기는 이와 동일하되, 다른 디렉토리를 지정한다.
테스트 이미지가 포함된 하위 디렉토리를 포함하고 있어야 한다.
Designing the neural network
ImageDataGenerator가 디렉터리에서 이미지를 전송하고 즉시 크기 조정과 같은 작업을 수행할 수 있다.
다음으로 해야 할 일은 이러한 보다 복잡한 이미지를 처리하도록 신경망을 설계하는 것이다.
Defining a ConvNet to use complex images
이제 부터 말과 사람을 구분할 수 있는 신경망을 정의해보자.
패션 아이템을 구분할 때 사용했던 것과 유사하지만 데이터 특성상 ImageDataGenerator를 사용한다는 점에서 몇 가지 사소한 차이가 있다.
일단 아래의 코드를 보면 아래쪽 Dense 레이어까지 가면서 이전에 사용했떤 컨볼루션과 풀링의 시퀀스를 따라가고 있다.

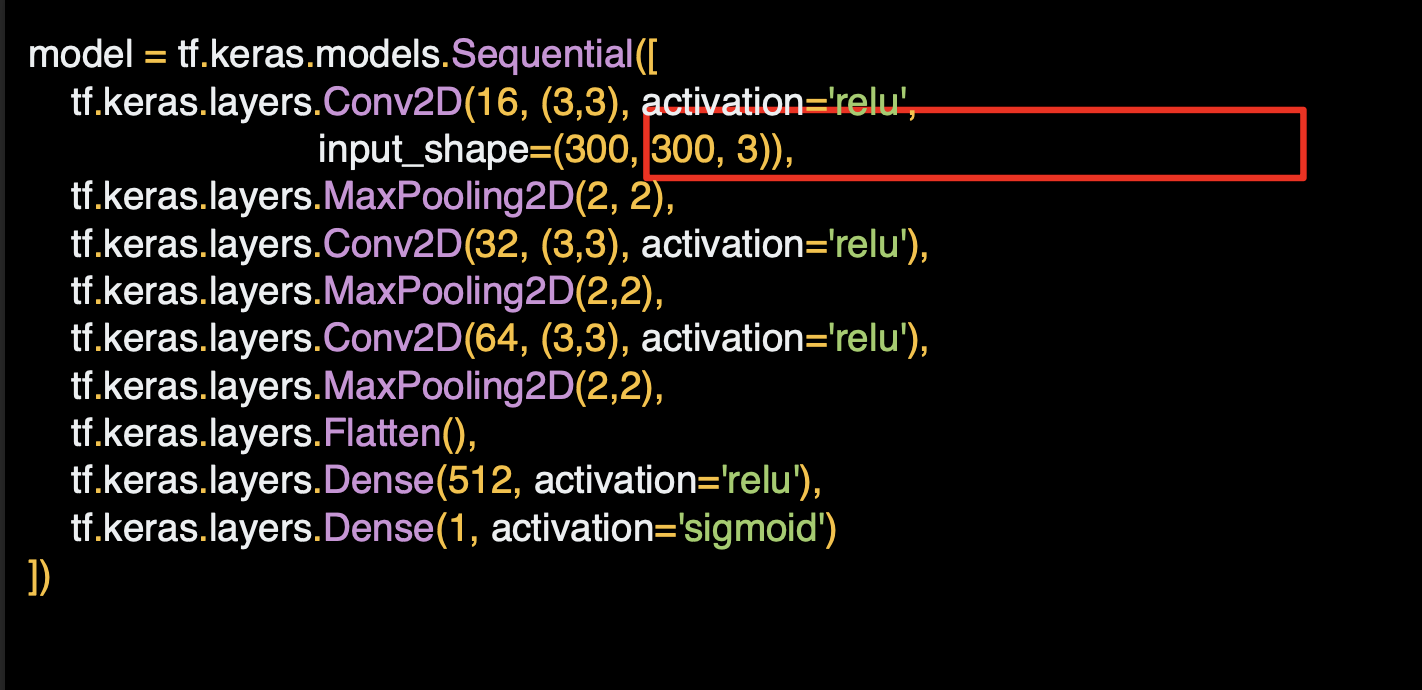
맨 위쪽을 보면 컨볼루션과 풀링 레이어가 3개씩 있는데, 이미지가 더 복잡하고 크기도 더 크다는 의미이다.
Flatten 함수를 쓰기 전에 28x28을 반으로 줄여서 13x13, 5x5로 만들었었는데, 이번에는 300x300으로 298x298로 시작해 계속 반으로 줄여나가는 것이다.
35x35에 도달할 때까지 진행한다.
이전처럼 넓은 사이즈를 원하면 몇 가지 레이어를 추가할 수 있다.
지금은 세 개의 레이어만 사용하낟.

input_shape도 본다면 이미지가 로드될 때 사이즈는 300x300이지만 컬러도 있다. 한 픽셀당 3바이트가 있는 것인데 평범한 24-bit 컬러 패턴인 빨강, 파랑, 초록이다.
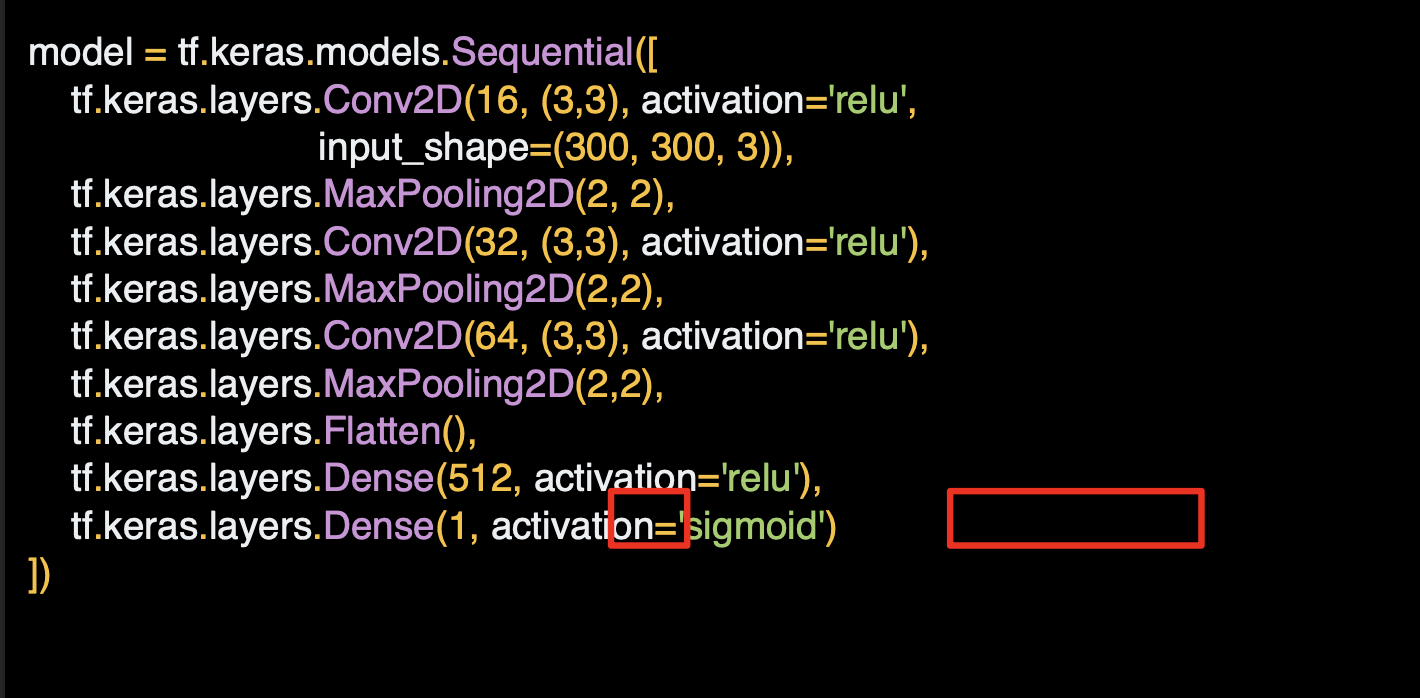
출력 레이어도 바뀌어 있는데 이전에 출력 레이어를 만들 때는 한 클래스에 한 신경망이 있었는데, 이제는 두 클래스에 한 신경망이 있다.
두 개를 분류하는 상황에서 아주 훌륭한 Sigmoid라는 다른 활성화 함수를 사용한다.
한 클래스는 0, 다른 클래스는 1로 향하게 된다.
원하면 두 개의 뉴런을 사용해서 softmax를 사용해도 되지만 두 개를 분류하는 상황에서는 sigmoid가 더 효율적이다.
모델 summary를 확인한다면,
3x3 필터를 통과하면서 300x300은 298x298이 되고
풀링함수를 통해 149x149에서 73x73이 되고 풀링 함수로 35x35가 된다.
이 35x35개의 64개 컨볼루션은 Flatten 함수에 의해 DNN에 적합한 형태가 된다.
35x35x64는 78,400이고 이것이 바로 컨볼루션에 나왔을 때의 데이터의 형태가 된다.
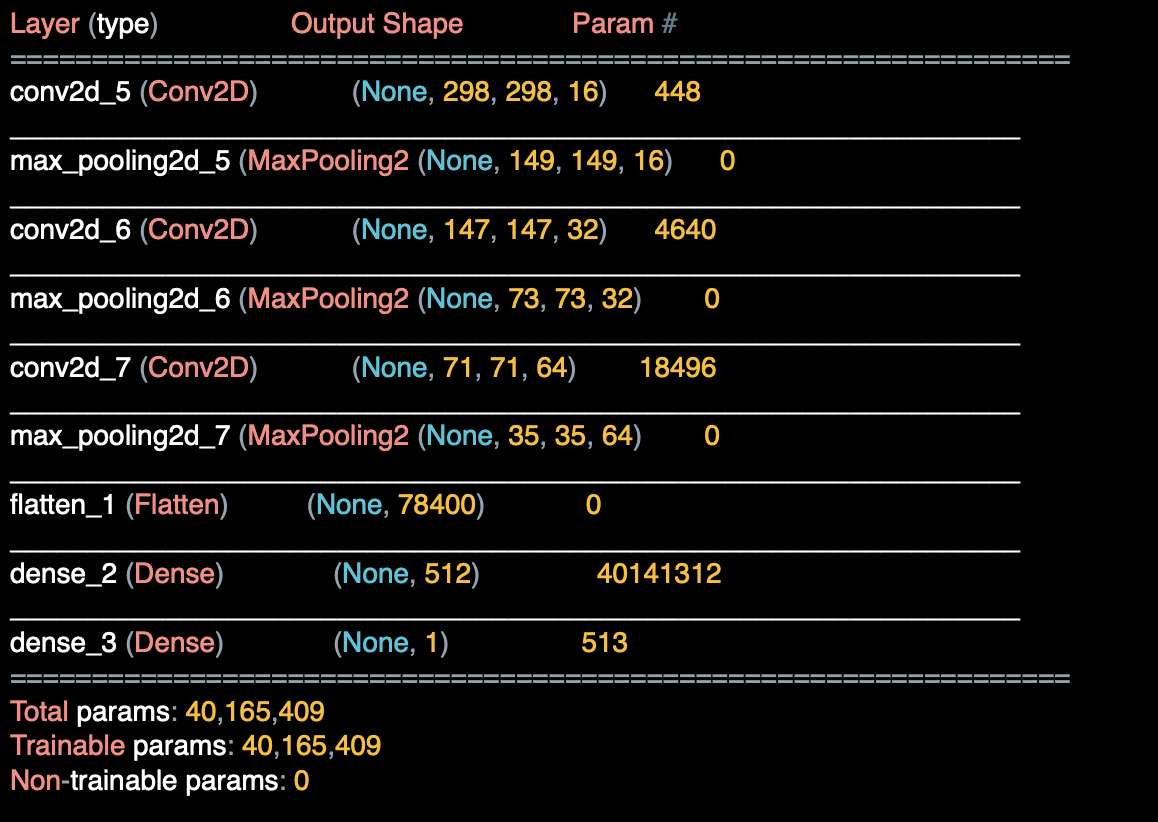
컨볼루션없이 300x300 원시 이미지를 사용했다면 900,000개의 값을 계산했어야 했다. 계산 과정을 많이 줄인 셈이다.
Train the ConvNet with ImageDataGenerator
이제 말 또는 인간을 분류하기 위한 신경망을 설계했으므로 다음 단계는 생성기가 읽을 수 있는 파일 시스템에 있는 데이터에서 신경망을 훈련시켜보자.
Training the ConvNet
모델을 컴파일하고 손실함수와 옵티마이저를 이용하낟.
패션에서 10개의 아이템을 분류했을 때 사용했던 손실함수는 Categorical cross entropy 였지만 여기서는 이진 분류를 하고 있으므로 binary_crossentropy를 사용한다.
그리고 패션에서는 adam 옵티마이저를 사용했지만 여기서는 RMSprop를 사용한다. 수행 과정에서 학습률을 실험에 적용할 수 있기 때문이다.
학습률에 대한 내용과 그것들이 어떻게 적용되는 지는 아래의 강의를 참고한다.


다음은 훈련 단계인데 기존의 model.fit과 조금 다르다 데이터 세트가 아니라 생성기를 사용하기 때문이다.
각 파라미터를 상세하게 확인해보자.

첫 번째 파라미터는 이전에 설정한 훈련 생성기이다.
이것이 훈련 디렉토리에서 이미지를 만들어낸다.
생성할 때 배치 사이즈를 사용했는데,
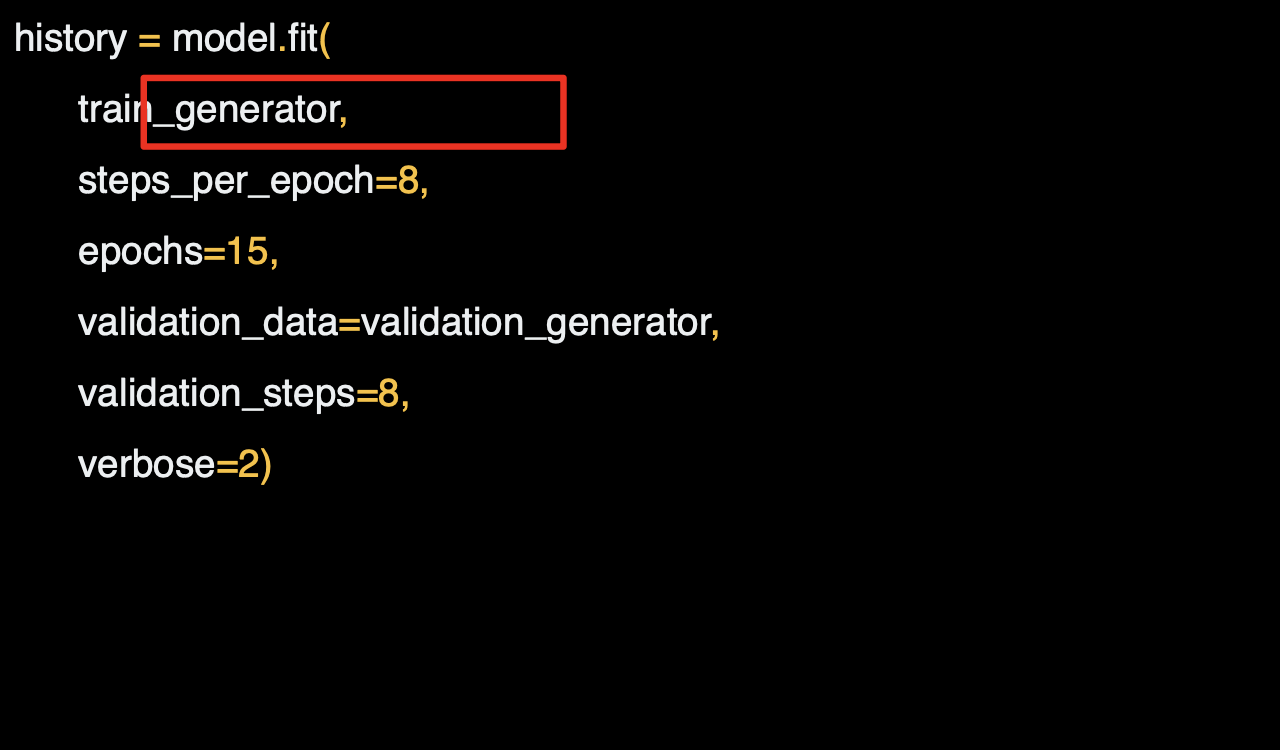
훈련 디렉토리에는 1,024개의 이미지가 있으므로 128개 이미지를 한번에 불러온다. 이들을 모두 불러오기 위해서는 8개의 배치가 필요하다.
위 조건을 만족시킬 수 있는 step_per_epoch를 설정한다.
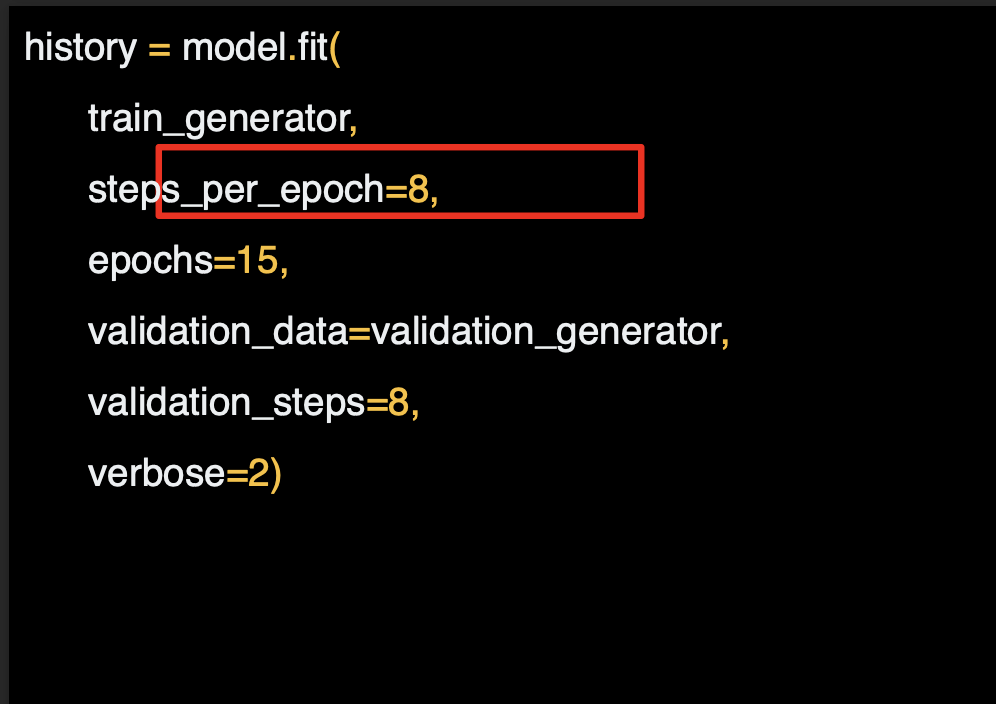
여기서는 훈련할 epoch 수를 설정하는데, 이 데이터는 복잡하므로 15번 정도는 적당할 것이라고 설정한다.
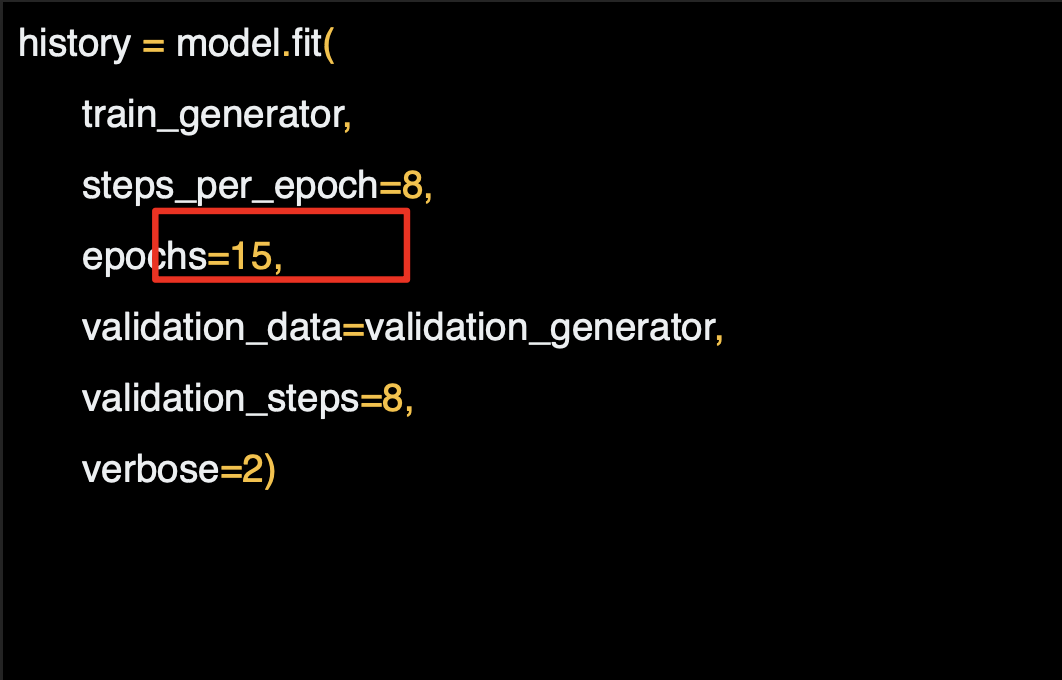
다음으로는 만들었던 validation_generator에서 검증 세트를 특정해보자.

256개의 이미지가 있고 배치 사이즈가 32였으면 하므로 step을 8로 한다.

verbose 파라미터는 훈련이 진행되는 동안 얼마나 많은 정보를 보여줄지 설정하는 것이다. 2라면 epoch 과정을 숨기는 움직임이 조금 줄어든다.
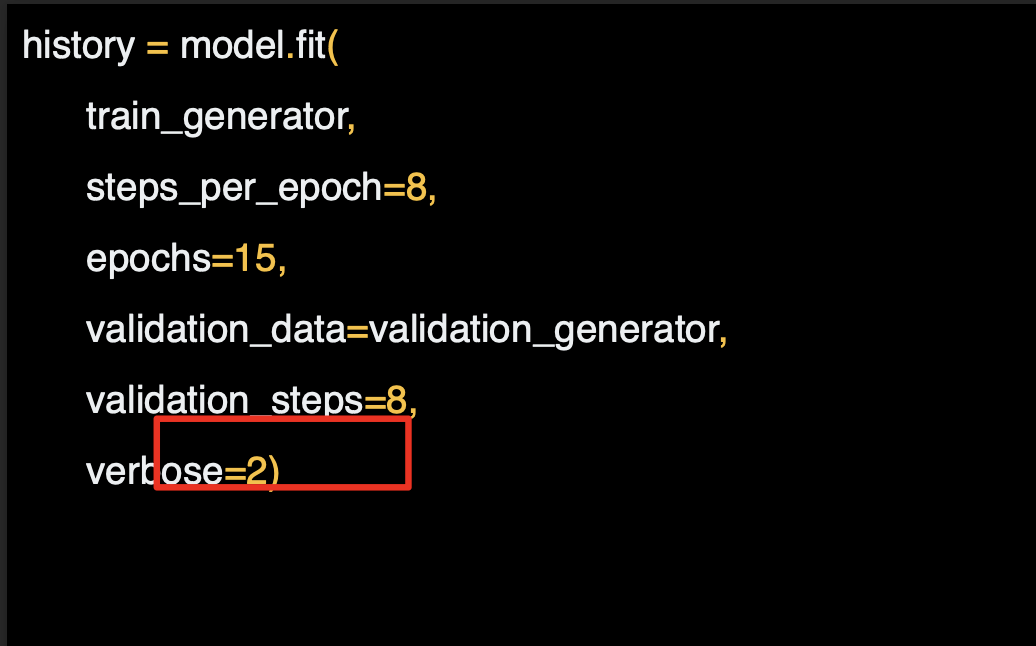
모멜이 훈련되면 모델에서 예측을 진행한다.
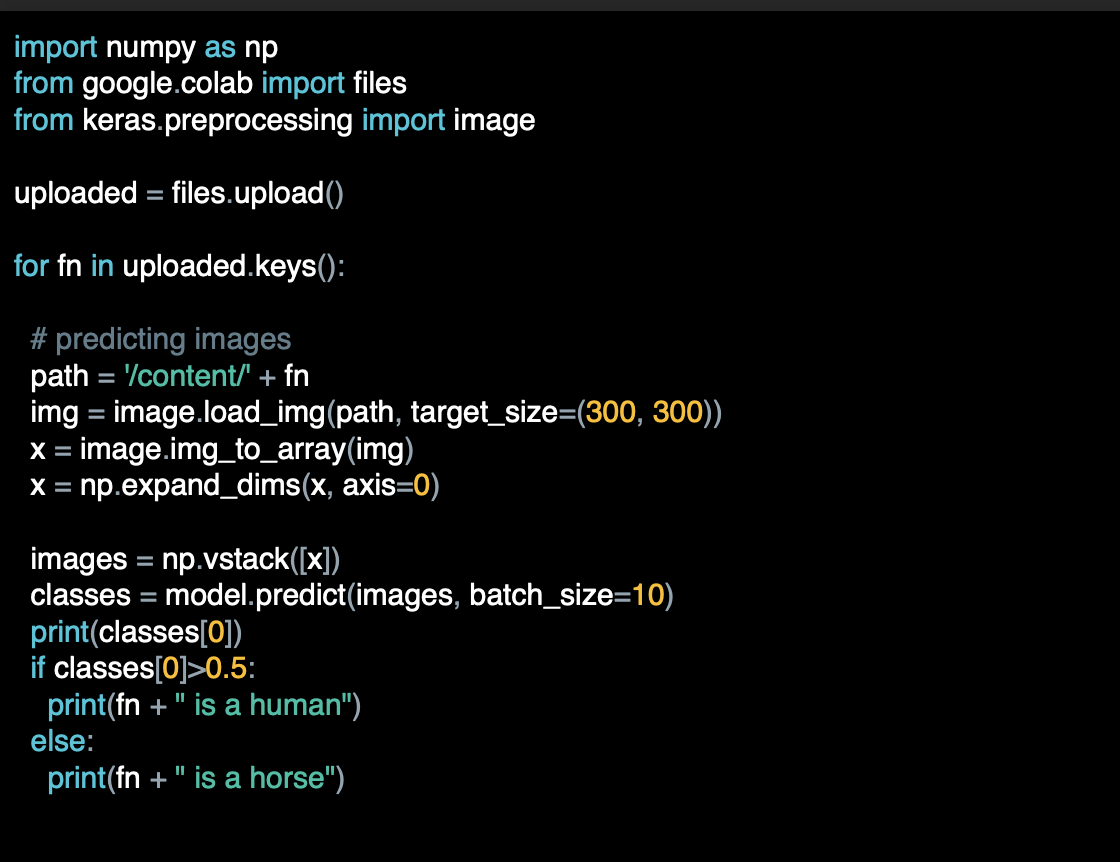
아래는 colab을 위한 코드 로 한 개 이상의 이미지를 업로드 할 수 있는 코드로 이미지가 upload목록에 들어가게 된다.
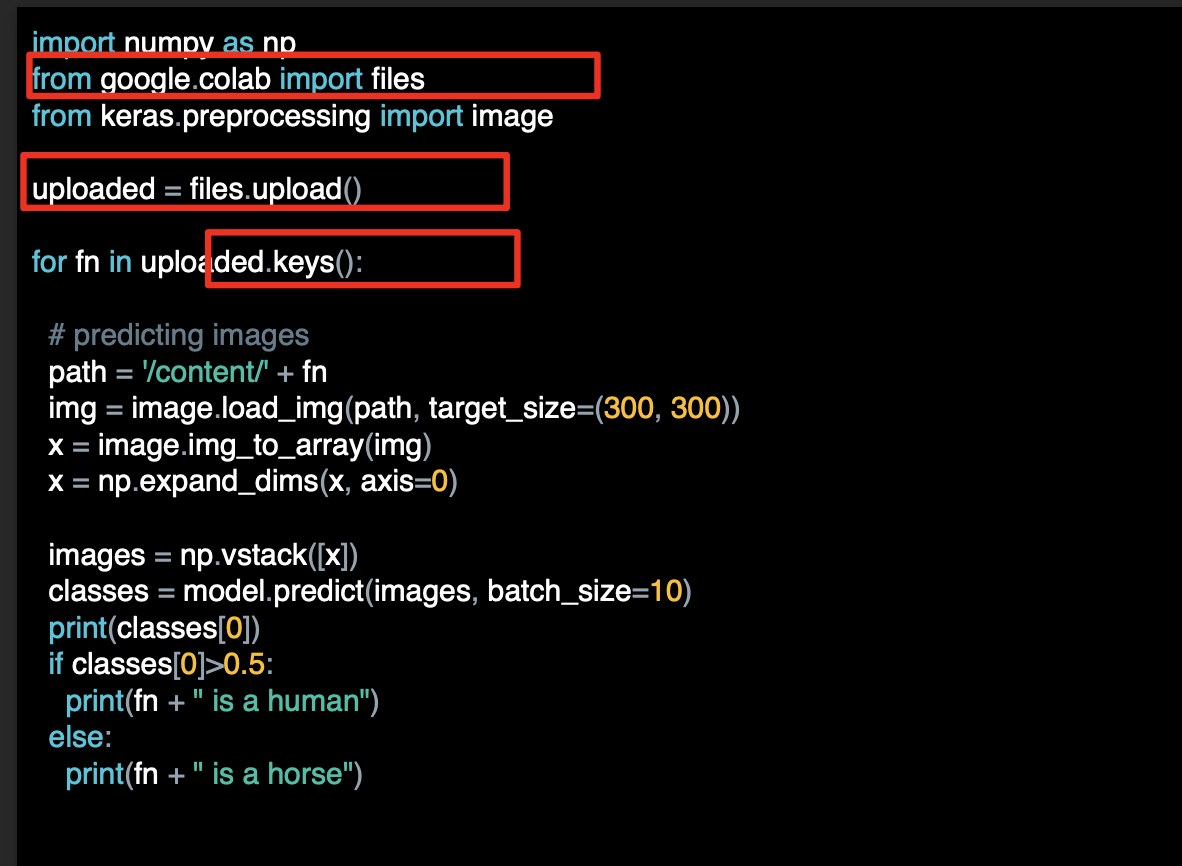
이 코드는 그 안의 이미지 모두와 상호작용한다.
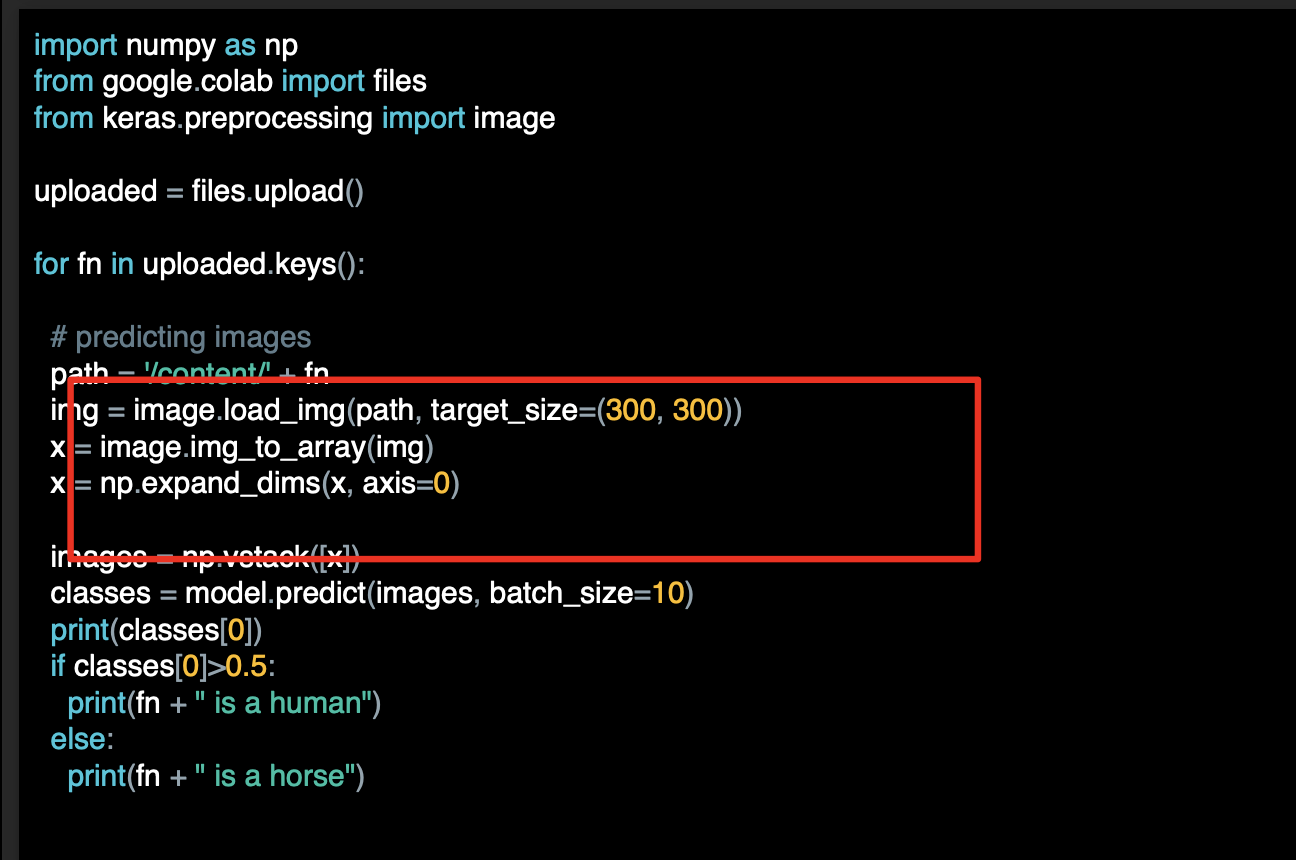
이미지를 불러와 모델에 입력할 수 있게 준비한다.
모델을 설계 할때 입력값의 차원과 여기서의 차원이 같아야 한다.
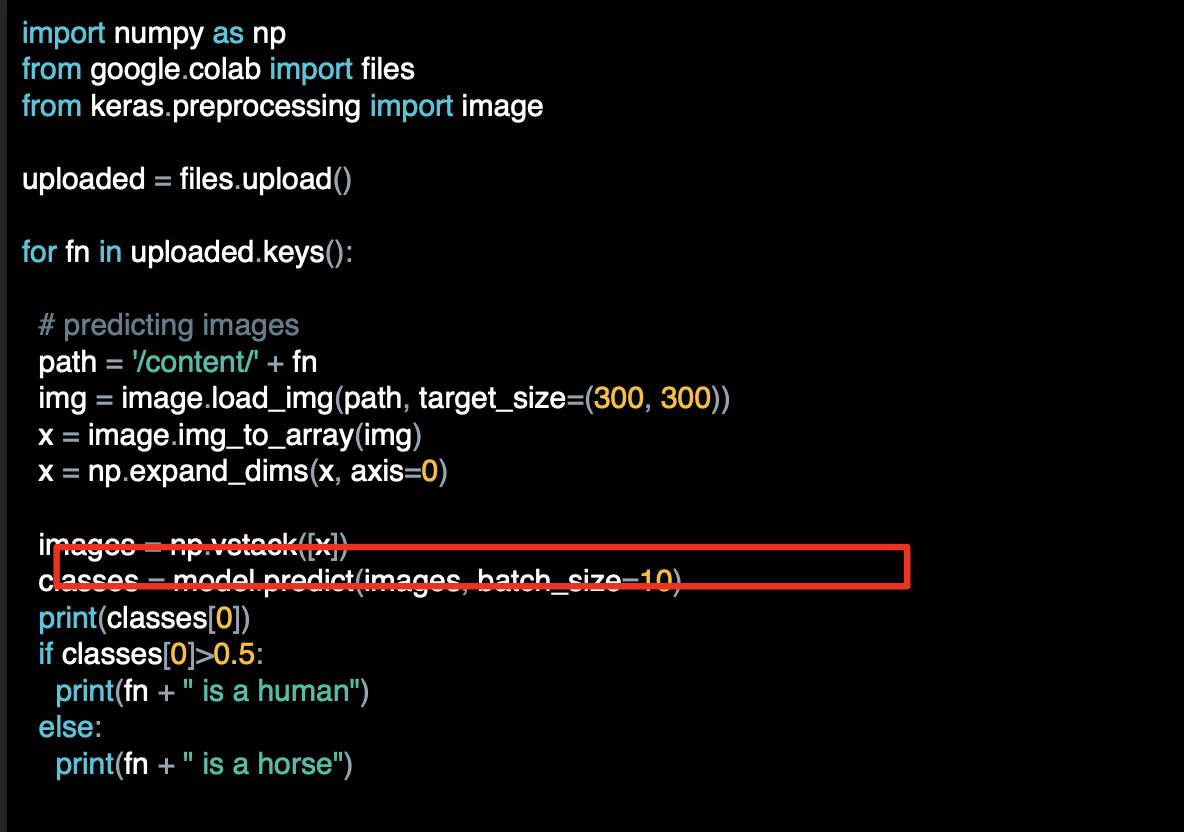
model.predict를 호출하고 세부 정보를 지정하면 클래스 배열이 반환된다.
이진 분류의 경우 하나의 항목에만 포함되며 값이 0과 가깝거나 1과 가까운 값으로 분류된다.
강좌 후반에는 softmax를 활용한 다중 클래스 분류를 살펴보게 된다.
softmax의 분류에서는 각 목록이 나타나는 값이 각 클래스에 속할 확률을 나타내고 확률값을 다 더하면 1이 되는 구조이다.
Exploring the solution
이제 코드를 통해 신경망을 정의하고, 온디스크 이미지로 훈련한 다음, 새 이미지의 값을 예측했으므로, 통합 문서에서 이를 실제로 확인해본다.
