[Tensorflow] 3. Natural Language Processing in TensorFlow (1 week Sequence models and literature) : lecture
Tensorflow_certification(텐서플로우 자격증)
[Tensorflow] 3. Natural Language Processing in TensorFlow (1 week Sequence models and literature) : lecture
신경망은 일반적으로 숫자를 다루기 때문에 텍스트를 다뤄야할 때 어떻게 해야하는 지에 대한 처리 방법을 학습하게 된다.
고양이('cat')과 같은 텍스트들을 신경망에 학습시키는 방법 등은 tensorflow를 사용할 수 있다.
Introduction
텍스트 및 텍스트 모델을 기반으로 분류기를 만드는 방법에 대해 학습한다.
감성 분석을 진행하는데 레이블이 있는 텍스트를 이해하는 모델을 만들고, 그것을 바탕으로 새로운 텍스트를 분류하는 방법에 대해 학습한다.
우리가 사진을 다룰 때 화소 값은 이미 숫자여서 신경망 네트워크로 그것을 학습시키기에는 수월했다.
또한 신경망은 클래스를 레이블에 맞추는데 사용할 수 있는 함수의 매개변수들을 언급했었다.
반면 텍스트는 어떻게 다룰 수 있을까?
Word based encodings
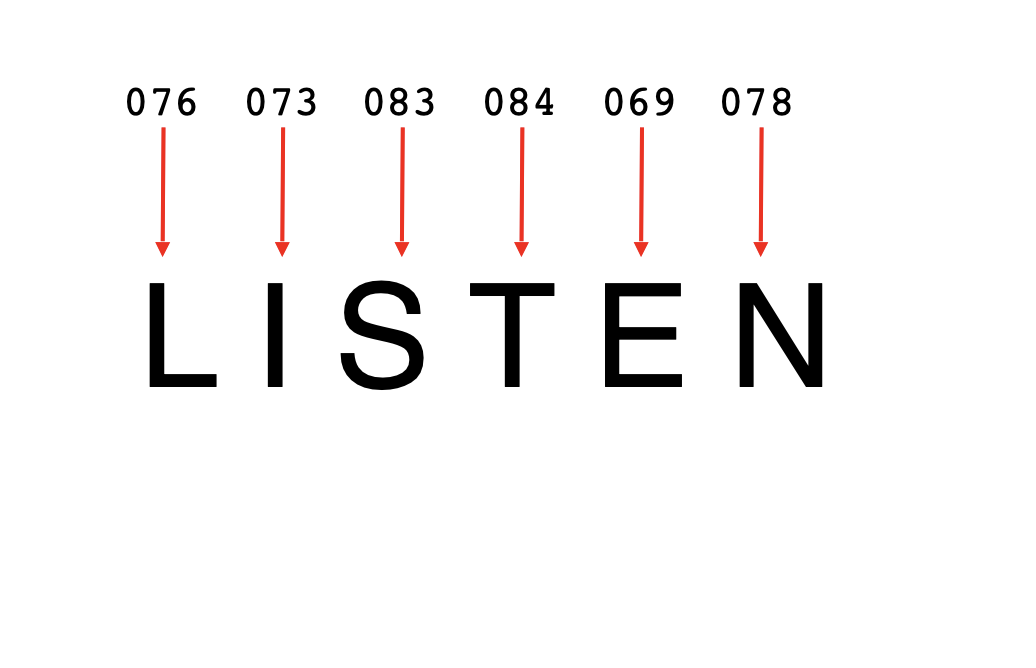
각 문자에 대한 문자 인코딩은 ASCII 값으로 가능하다. 예를 들어 "LISTEN" 단어의 간단한 인코딩은 아래와 같다.

이 값들을 이용해 LISTEN으로 인코딩 된 단어를 가질 수 있다고 생각할 수 있다.
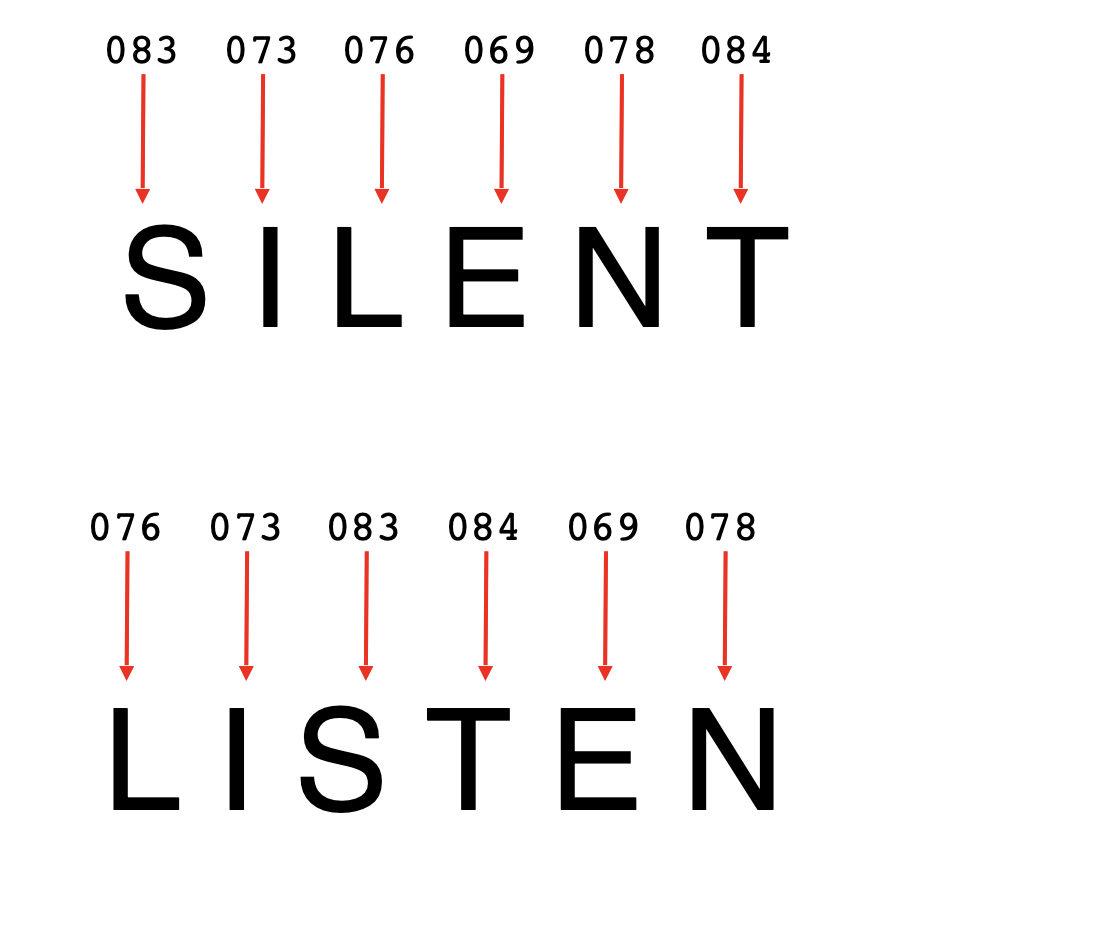
하지만 여기서 문제는 단어의 의미는 문자로 인코딩되지 않는 다는 점이다.
"SILENT"와 "LISTEN" 이라는 단어는 다르고 반대되는 의미를 갖지만 같은 아스키 코드를 통해 'LISTEN', 'SILENT" 를 나타낼 수 있다.
단지 글자로 신경망을 훈련시키는 일은 어려운 일이 될 수 있다.
만약 단어를 고려해서 단어에 가치를 부여하고 이러한 가치를 신경망 학습에 이용한다면 어떨까?
예를 들어 "I love my dog" 라는 문장이 있다고 할 때, 각 단어에 가치를 부여해보자.
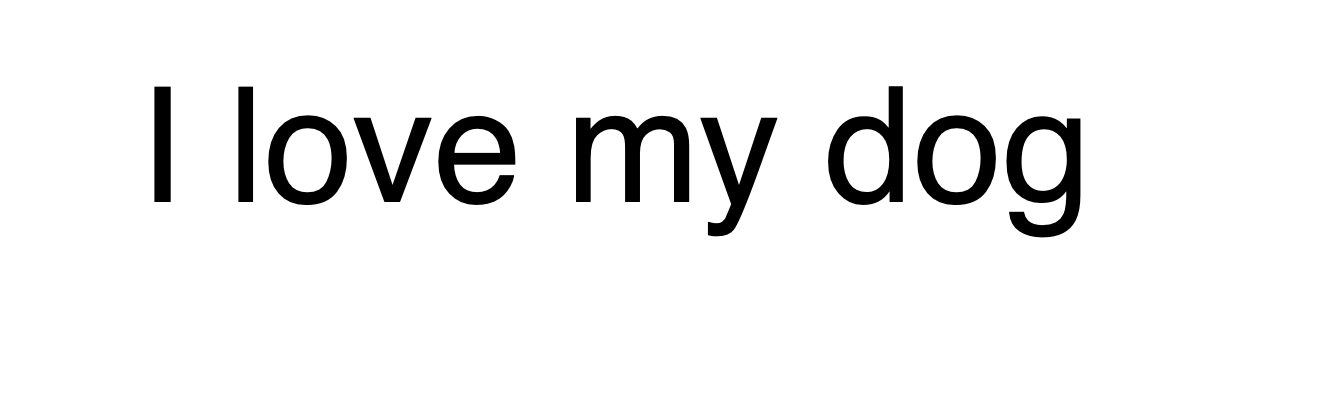
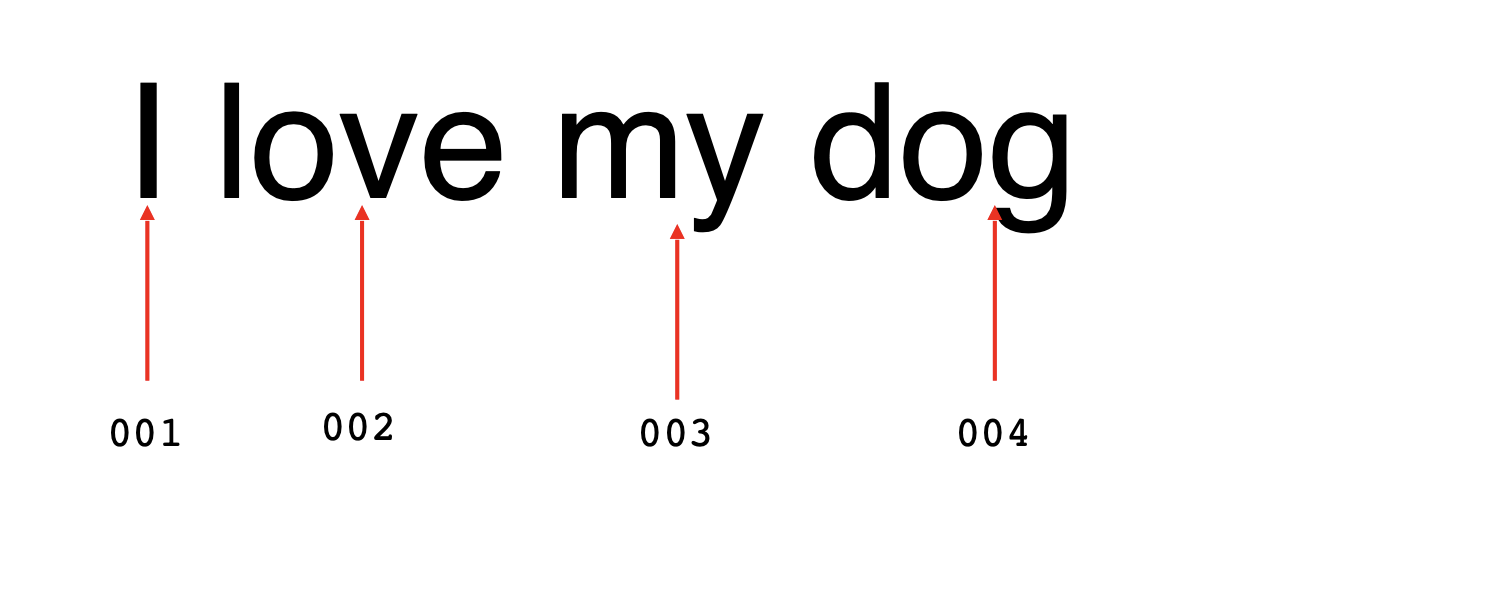
그 가치가 무엇인지는 중요하지 않고 단지 우리는 단어당 그 가치를 가지고 있고 그 가치는 매번 같은 단어에 따라 같은 것이다.
예를 들어 문장의 단순한 인코딩은 'I' 라는 단어를 1로 지정하는 것이다.

이어서 각 love를 2, my 를 3 등으로 해서 문장을 1,2,3,4 로 인코딩하는 것이다.
이제 'I love my cat' 이 나온다면, I, Love, my는 각 1,2,3 이고 cat은 5로 인코딩해본다.

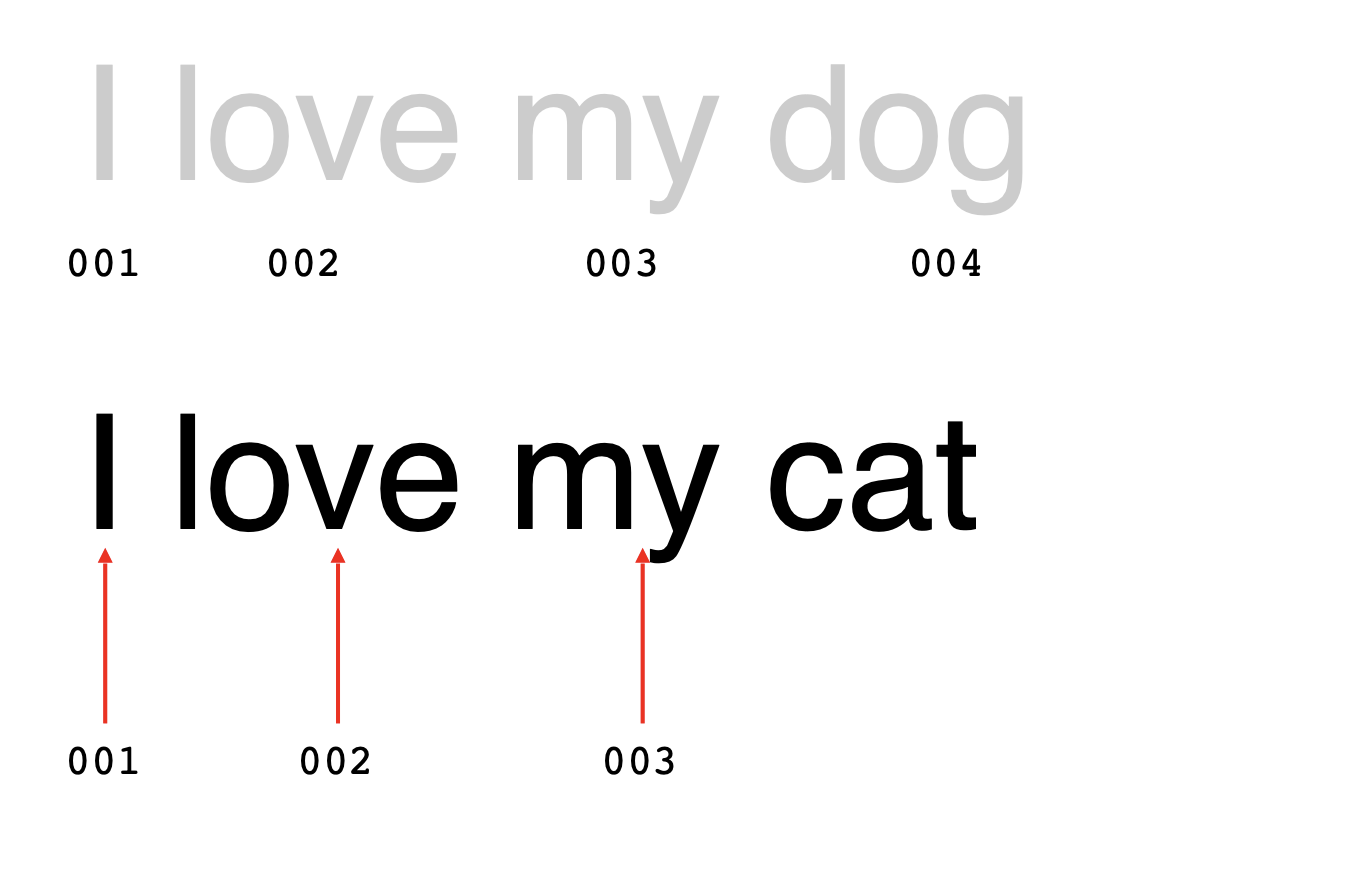
위의 문장에 대한 두 가지 인코딩을 살펴보면 비슷한 점이 있다.

1,2,3,4 는 I love my dog
1,2,3,5 는 I love my cat 이다.

단어를 바탕으로 신경망을 훈련 시키는 방법의 시작이다.
tensorflow 에서는 이러한 작업을 쉽게 할 수 있는 API를 제공한다.
Using APIs
아까 말한 문장을 인코딩하는 코드이다.
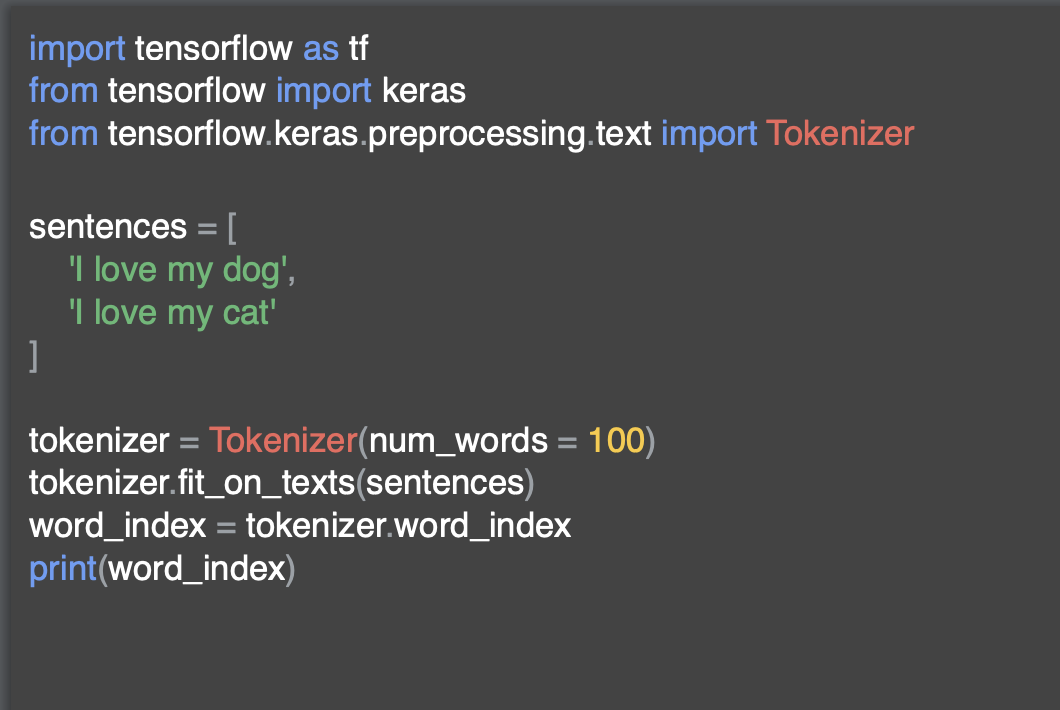
tensorflow와 keras는 단어를 인코딩하는 여러 가지 방법을 제공한다.
여기서는 Tokenizer를 사용한다.
이렇게 하면 단어 인코딩의 사전을 생성하고 문장에서 벡터를 만드는 등의 작업을 처리할 수 있다.

해당 문장을 배열안에 넣고, 문장의 맨 앞에 있는 'I'를 이미 대문자로 사용했다.

그런 다음 토크나이저의 인스턴스를 만든다.
여기서는 다섯 개의 단어만 있지만 num_words를 100으로 두었다.
많은 텍스트를 기반으로 하는 학습 세트를 만드는 경우 해당 텍스트에 고유한 단어 수가 얼마나 많은지 모르기 때문에 hyperparameter 중 하나로 num_words를 상위 100개의 단어를 빈도 벼로 가져와서 그냥 인코딩 하는 것이다.
많은 데이터를 다룰 때 효율적인 방법이고, 실제 데이터를 가지고 조절하는 하이퍼파라미터이다.
단어가 적을 수록 훈련 정확도에 미치는 영향은 최소화하지만 훈련 시간에 영향을 주기 때문에 신중하게 선정해야 한다.
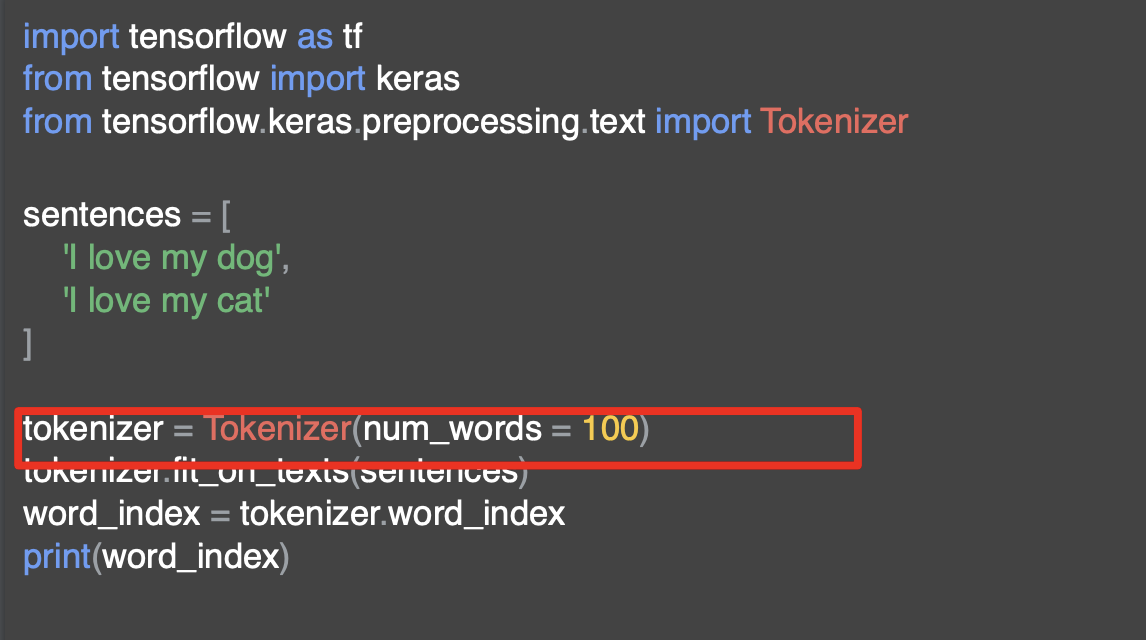
그런 다음 토크나이저를 가져와 인코딩 한다.
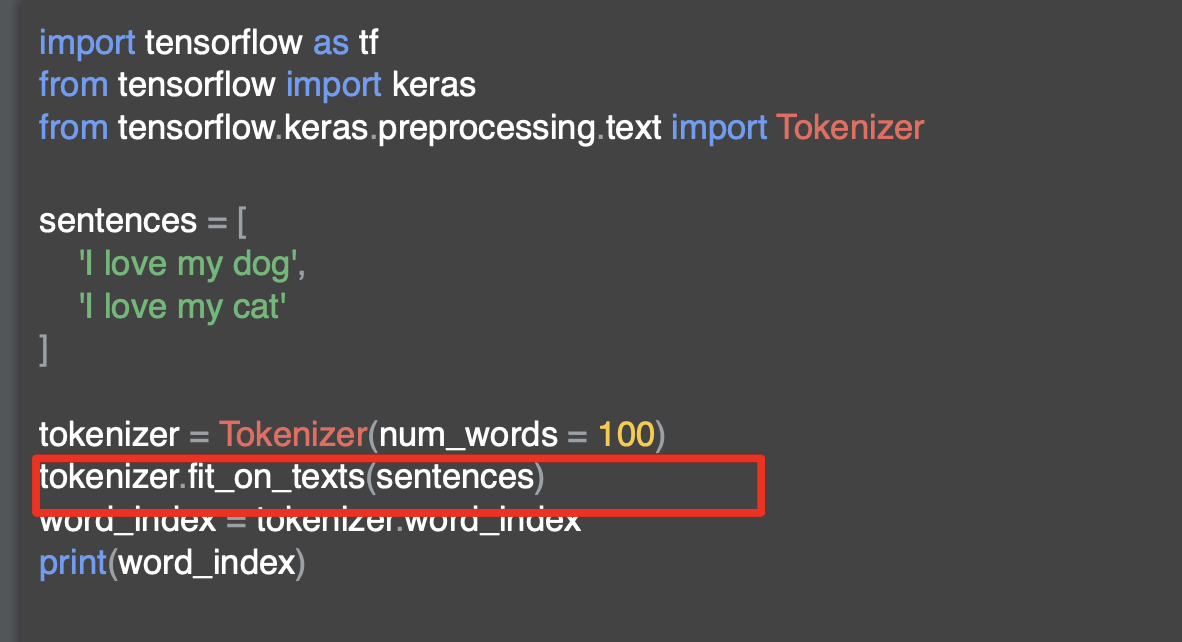
토크나이저는 키 값 쌍이 포함된 사전을 반환하는 단어 인덱스 속성을 제공한다. 키는 단어이고 값은 해당 단어에 대한 토큰이다.
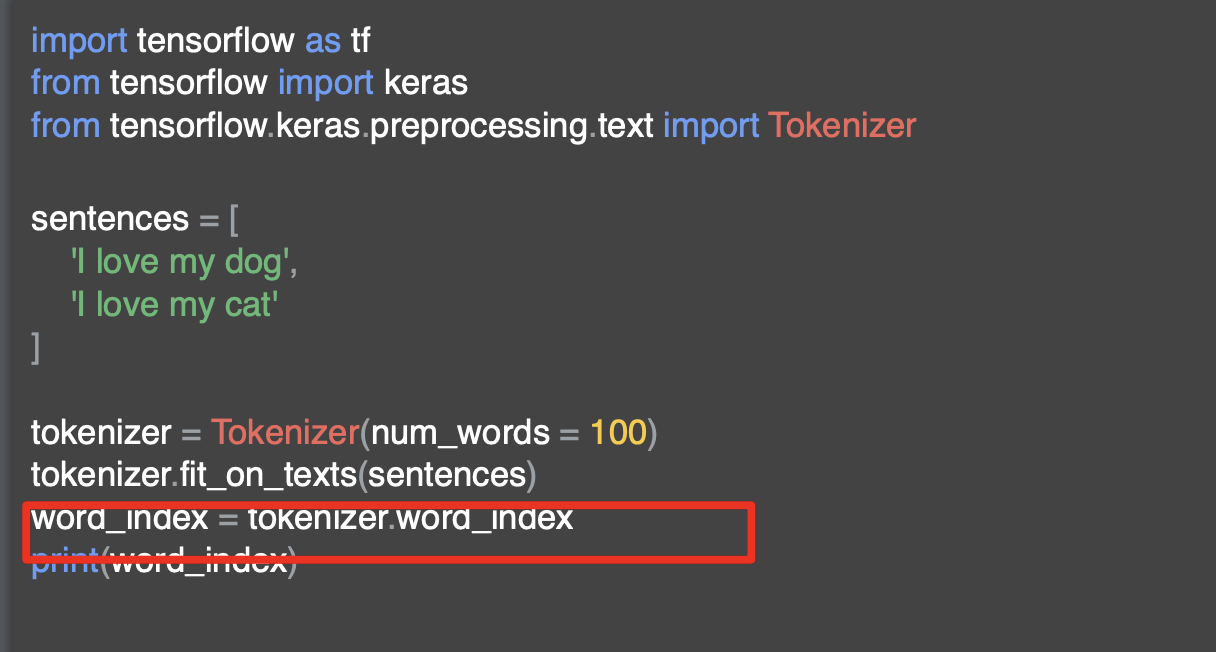
이 토큰은 단순히 출력해서 확인할 수 있다.
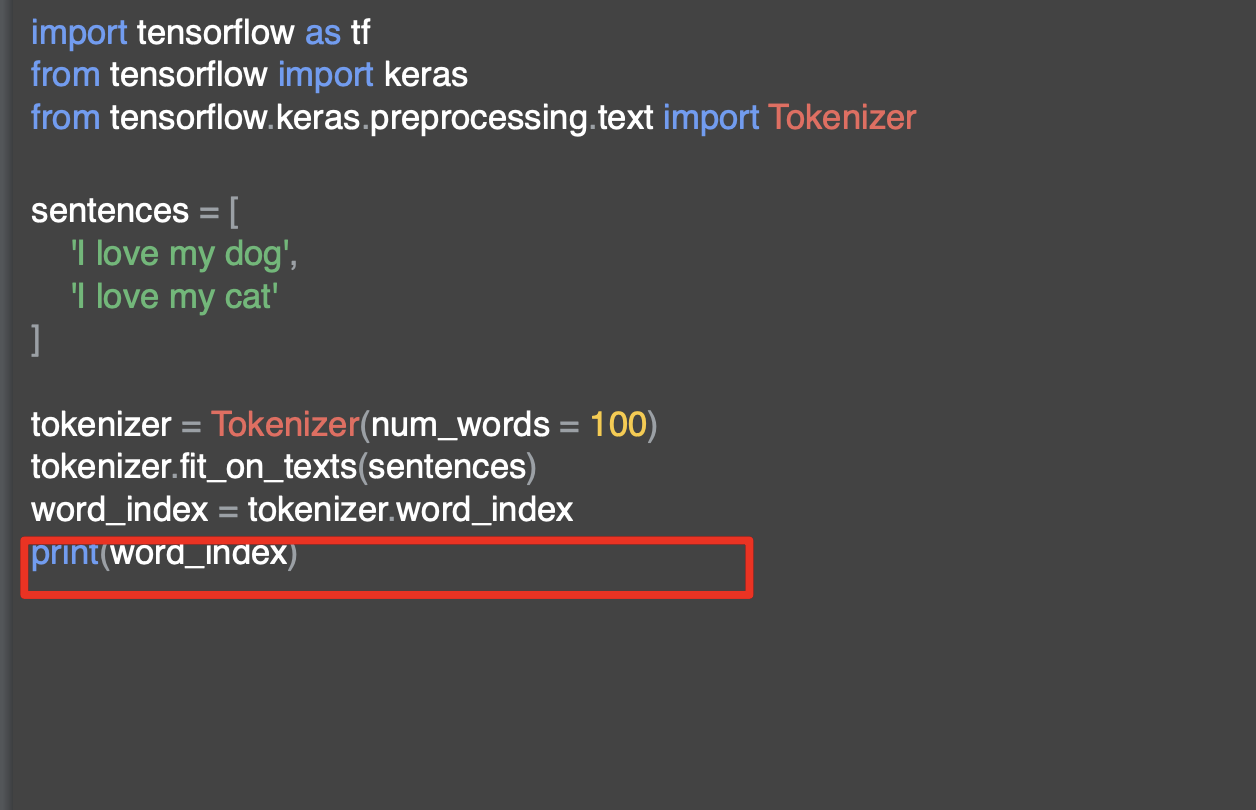
여기서는 단어 사전을 볼 수있는데 모든 단어가 소문자로 되어 있는 것을 볼 수 있다.

여기서 토크나이저는 구두점을 제거한다.

여기서 또다른 문장을 추가해보자.
'dog' 다음에 느낌표를 추가했다.

그래도 단어 사전은 그대로 'dog' 을 키로 가지고 있다.

느낌표는 영향을 주지 않았다. 물론 검색된 단어 'you' 에 대한 새로운 키가 존재한다.
지금 문자를 다루었고, 그 텍스트의 단어 기반 인코딩을 만들어봤다.

Notebook for lesson 1
토크나이저 클래스를 사용해서, 문장을 토큰 스트림으로 바꾸는 등 토큰을 관리하는 일들을 처리한다.
토크나이저가 할일은 인스턴스를 만들 때 단어사전에 들어갈 수 있는 최대 항목 수로 만들 수 있는 여러 단어를 전달하는 것이다.
위 코드에서는 단어가 5개 밖에 없는데, 더 많은 텍스트를 해서 분류하려는 문장이 수천 개라면 모든 문장에서의 고유한 단어 수를 알아내기 어렵다.
그래서 해당 매개변수 (num_words)를 전달해서 전체 코퍼스에서 가장 흔한 단어 100개, 혹은 가장 일반적인 단어 1,000개 등으로 설정하는 것이다.
그런 다음 토크나이저의 fit_on_text에 배열을 전달해서 단어의 색인을 생성한다.
여기서 단어 색인은 키 값 쌍의 목록인 경우
키 단어가이고 값이 해당 단어의 토큰일 경우 출력이 가능하다.
추후에는 단어의 색인을 이용해서 문장을 토큰 목록으로 바꾸는 일들을 하게 된다.
여기까지가 신경망 훈련에 사용할 텍스트 기반 데이터를 준비하는 첫 번째 단계이다. 이것은 다음에 임베딩과 함께 사용될 것이다.
그 전에 문장을 토큰 기반 목록에 넣고 목록을 모두 같은 크기로 만드는 방법을 살펴보자
Text to sequence
위에서 단어와 문장을 토큰화하는 방법을 언급했고, 코퍼스를 만들기 위해 모든 단어의 사전을 구축했다.
다음은 이러한 토큰을 기반으로 문장을 값 목록으로 바꾸는 것이다.
값 목록으로 바꾼 후에 모든 문장을 같은 길이로 만들기 위해 해당 배열을 조작해야 한다.
그렇지 않으면 신경망을 연결하기 어렵다.
이전의 이미지를 다룰 때 신경망에 투입되는 이미지의 크기로 입력층을 정의했다. 이미지의 크기가 다른 경우에는 크기에 맞게 크기를 조정했다. 텍스트 또한 이러한 과정이 필요하다.
tensorflow의 api를 활용해서 텍스트의 길이를 조정한다.
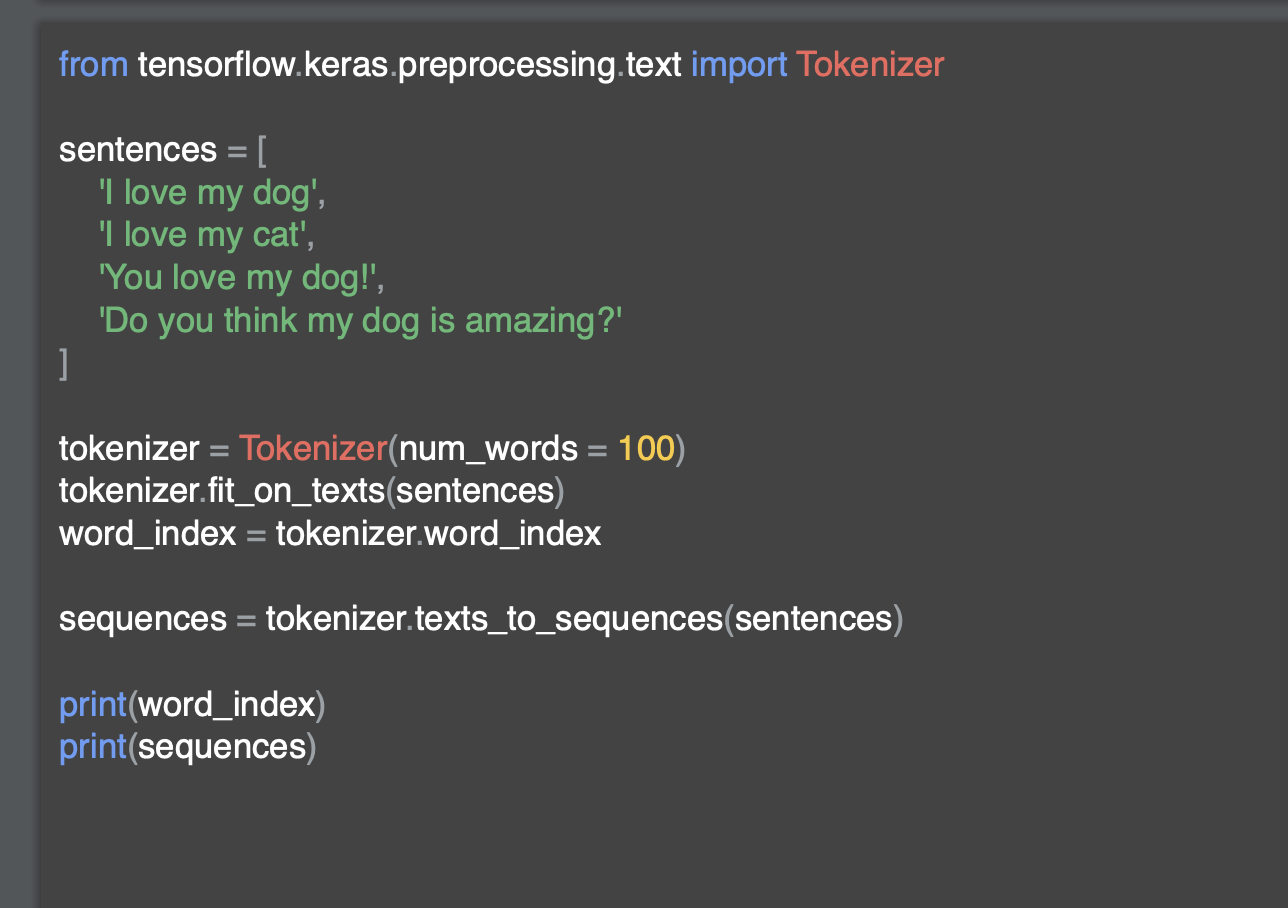
우리가 생성한 토큰으로 문장을 인코딩한다.

문장의 배열은 총 4개이고, 이전의 모든 문장에는 4 개의 단어가 포함되어 있었지만 마지막 단어는 조금 길다.
'
해당 코드는 토크나이저를 호출해서 시퀀스에 대한 텍스트를 가져오고, 해당 문장을 시퀀스로 변환한다.
이 코드를 실행해 출력하면 아래와 같다.
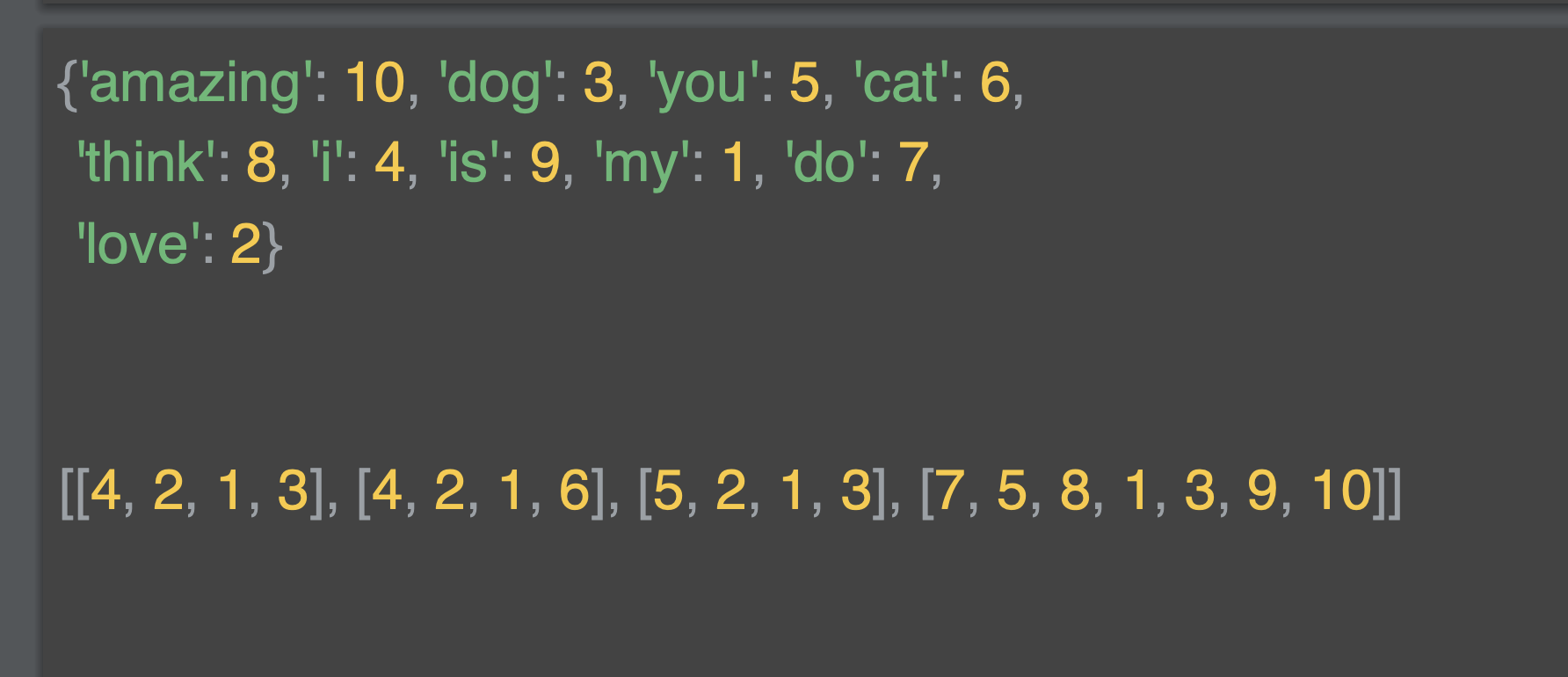
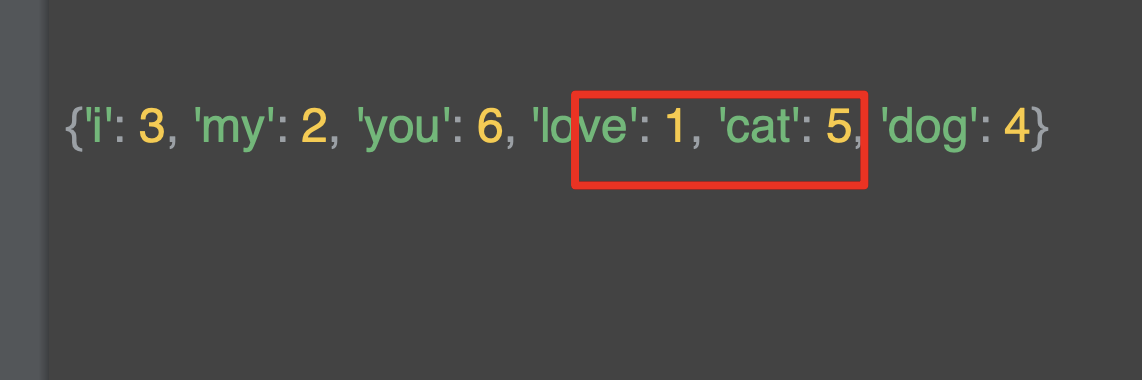
위는 단어 사전이고, 각 단어에 따른 인데긋가 부여되어 있꼬 새로운 단어들의 토큰을 의미한다.
아래는 정수 목록으로 인코딩 된 문장 목록인다. 해당 토큰은 단어를 대체한다.

예를 들어 I love my dog은 4,2,1,3 값 목록으로 변환된 것이다.
이것에 대해 나중에 유용하게 사용할 수 있는 것은 시퀀스로 호출된 텍스트는 어떤 문장이든 쓸 수 있다는 것이다. 그래서 문자를 인코딩 가능하다.
문자에 맞게 전달된 단어로 부터 배운 단어들을 기반으로 인코딩 가능하다는 말이다.
신경망은 텍스트에서 생성되는 단어 색인을 가지고 코퍼스를 통해 신경망을 학습한다.
그렇기 때문에 훈련 모델로 추론을 하고 싶다면 원하는 텍스트를 인코딩해야 한다.
같은 단어 사전으로 추론하지 않으면 의미가 없다.

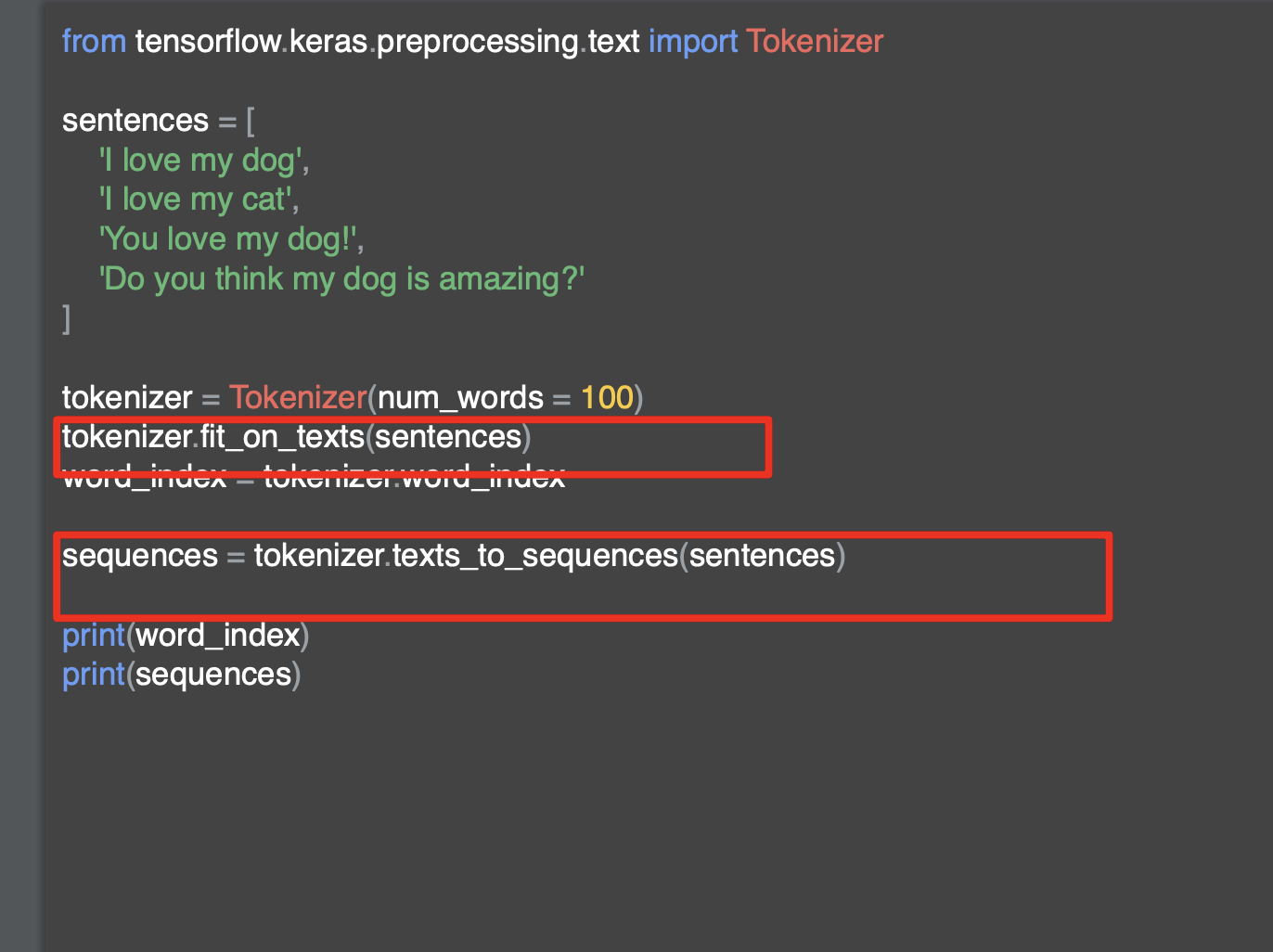
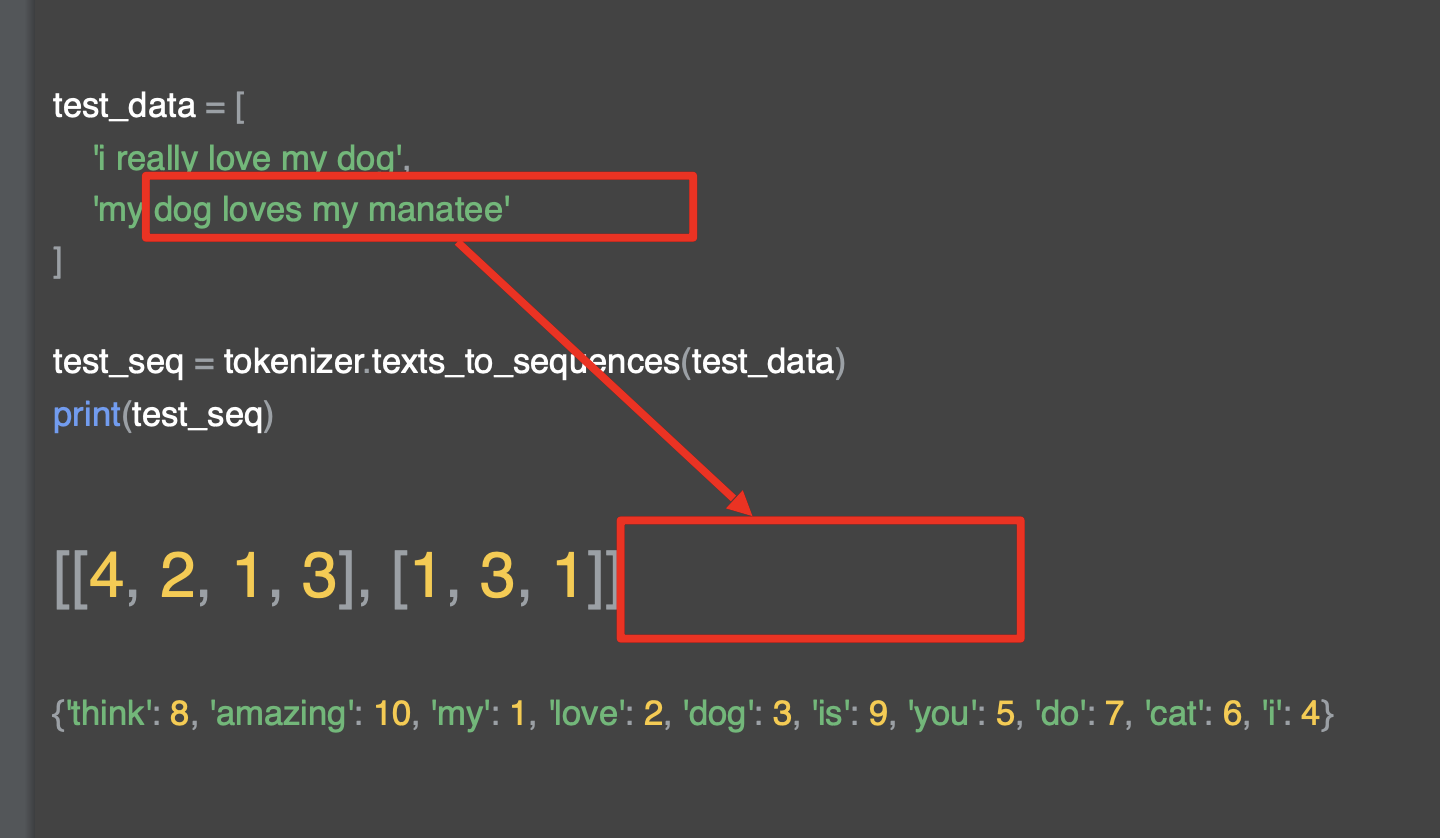
해당 코드를 고려하면 위에 익숙한 단어들인 love, my, dog, i 등이 있고 언급하지 않았던 단어들도 보인다.

i really love my dog은 [4,2,1,3] 으로
i love my dog 로 변환되었고 'rellay'는 빠져있다. 또한 my dog loves my manatee 또한 [1,3,1] 로 단어 사전에 있는 my dog my로 인코딩 되어 있다.
Looking more at the Tokenizer
이러한 과정을 통해서 우리는 광범위한 어휘를 얻기 위해 실제로 많은 훈련 데이터가 필요하다.
또한 대부분의 경우 보이지 않는 단어들을 그냥 무시하는 대신에, 해당 단어가 등장할 때 특별한 가치를 부여하는 것이 낫다.
여기에 원본 문장과 테스트 데이터를 모두 보여주는 코드가 있다.

속성 oov_token 옵션에 <OOV> 를 토크나이저에 추가했다.
단어 인덱스에 없는 단어에 외부 어휘에 대한 토큰 OOV를 사용하도록 지정한 것이다.
해당 값은 실제 단어와 혼동되지 않는 독특하고 독창적인 단어여야 한다.
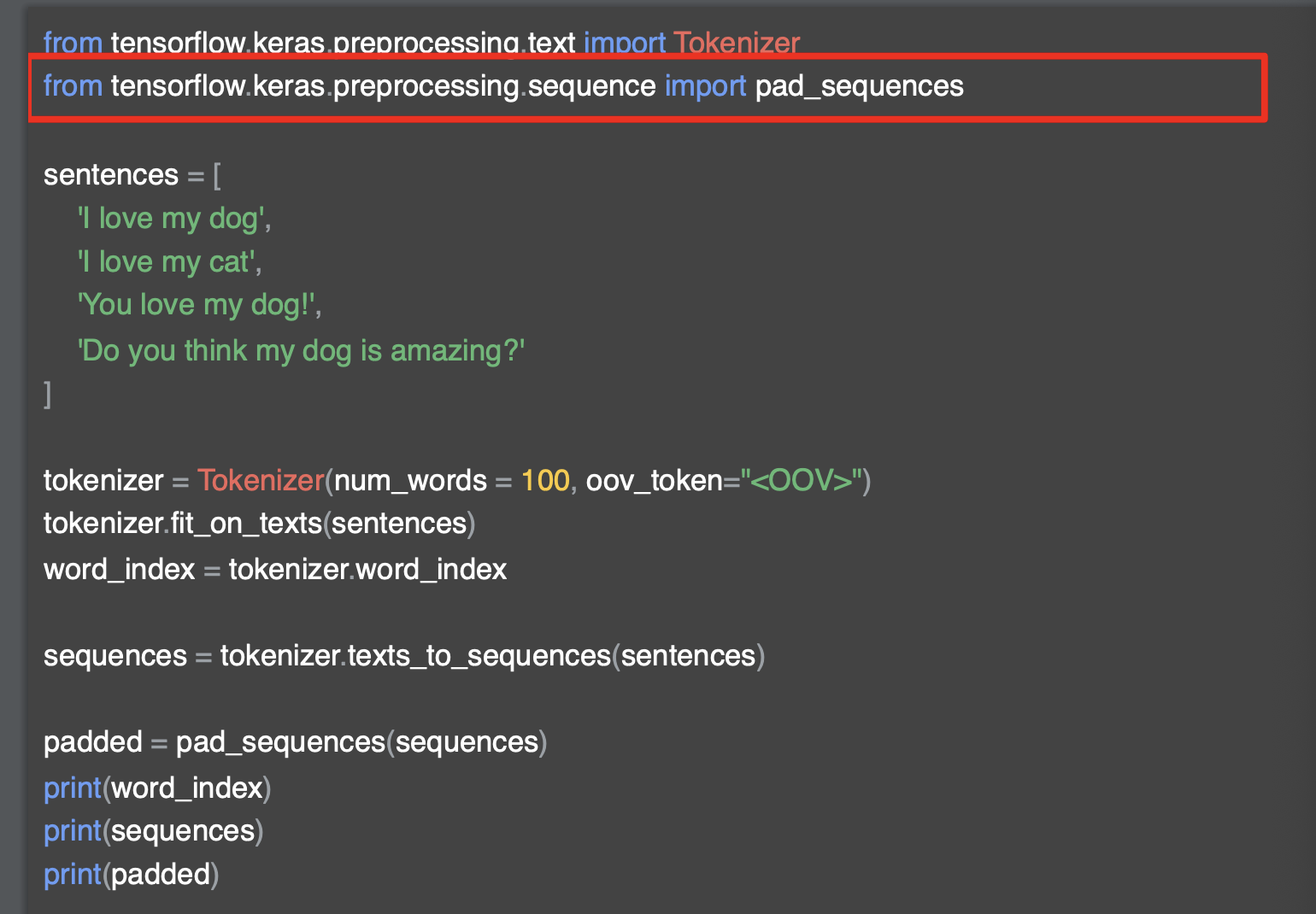
해당 코드를 실행하면 테스트 시퀀스가 다음과 같이 나타난다. 아래는 단어 색인이다.

첫 번째 배열은I <OOV> love my dog 으로,
두 번째 배열은 my dog <OOV> my <OOV> 이다.
문법적으로 훈련하지는 않지만 더 나아지고 있다.
말뭉치가 커지면 색인에 더 많은 단어가 존재하게 되고, 이전에 보이지 않는 문장이 더 나은 적용 범위를 가지게 된다.
다음은 패딩인데, 이전에 이미지를 처리하기 위해 신경망을 구축할 때 크기 면에서 통일 시켰다. 예를 들어 이미지 크기를 조정하는 것과 같이 텍스트도 훈련하기 전에 비슷한 요구 사항을 충족해야 한다.
크기의 균일성이 일정해야 하므로 여백을 주는 것이다.
padding
안쪽 여백을 처리하기 위한 코드를 살펴보자.

패딩 함수를 사용하기 위해서는 tensorflow.kears.preprocess.sequence 에서 pad_sequence를 가져온다.
그런 다음 토크나이저가 시퀀스를 생성하면, 이 시퀀스를 패딩 시퀀스로 전달하여 패딩을 진행한다.

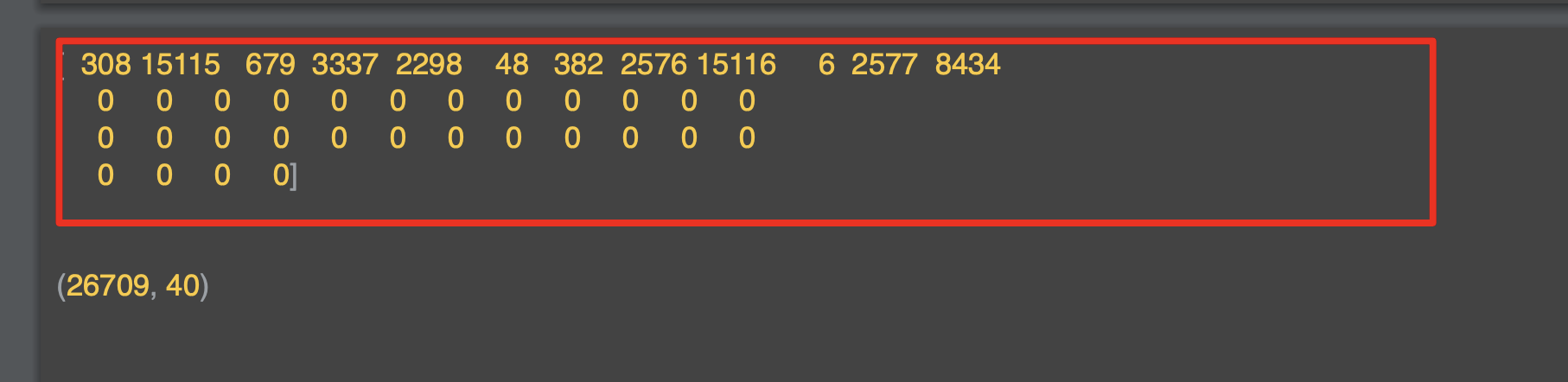
결과는 아래와 같은데, 이제 문장의 목록이 행렬로 채워지고 각 행렬의 각 행의 길이가 동일하다.
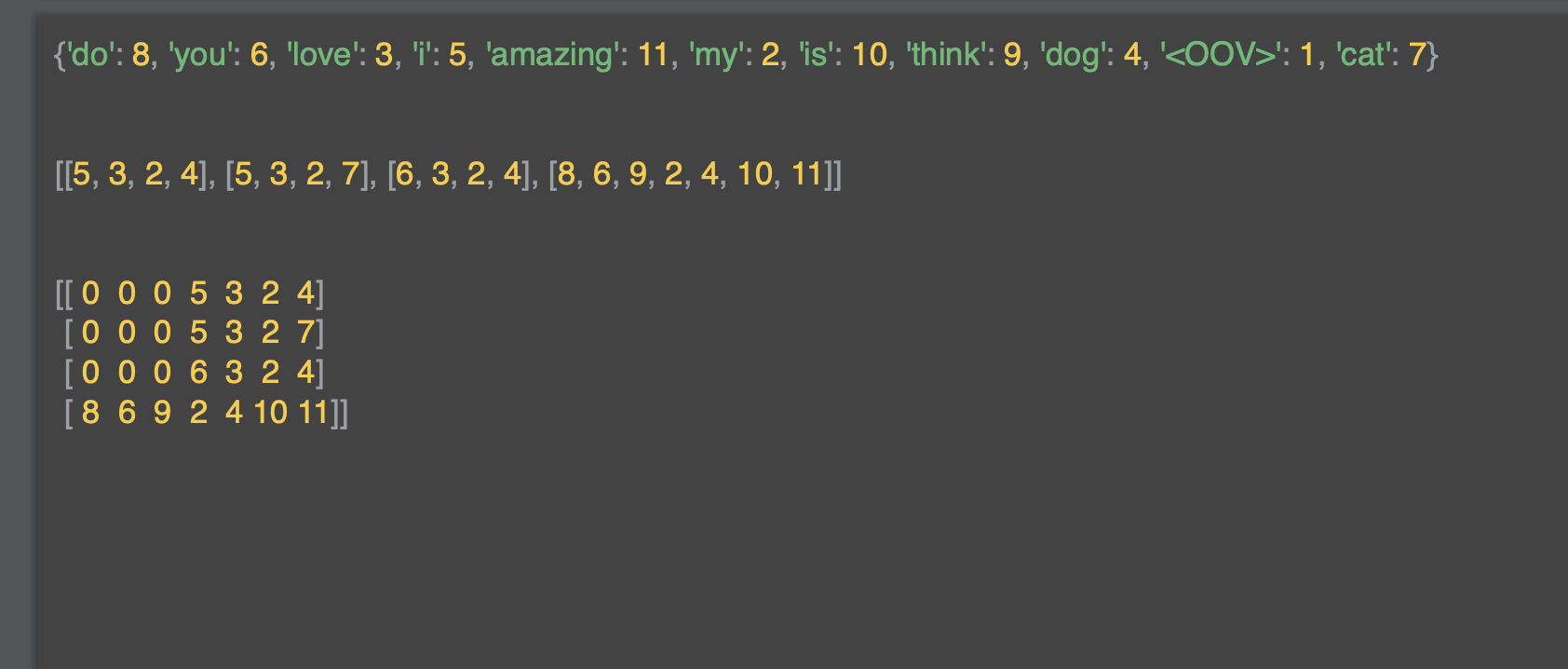
문장 앞에 0을 적는 방식으로 이러한 문제가 해결됐다.
문장 5,3,2,4 의 경우 0,0,0,5,3,2,4가 되었다.
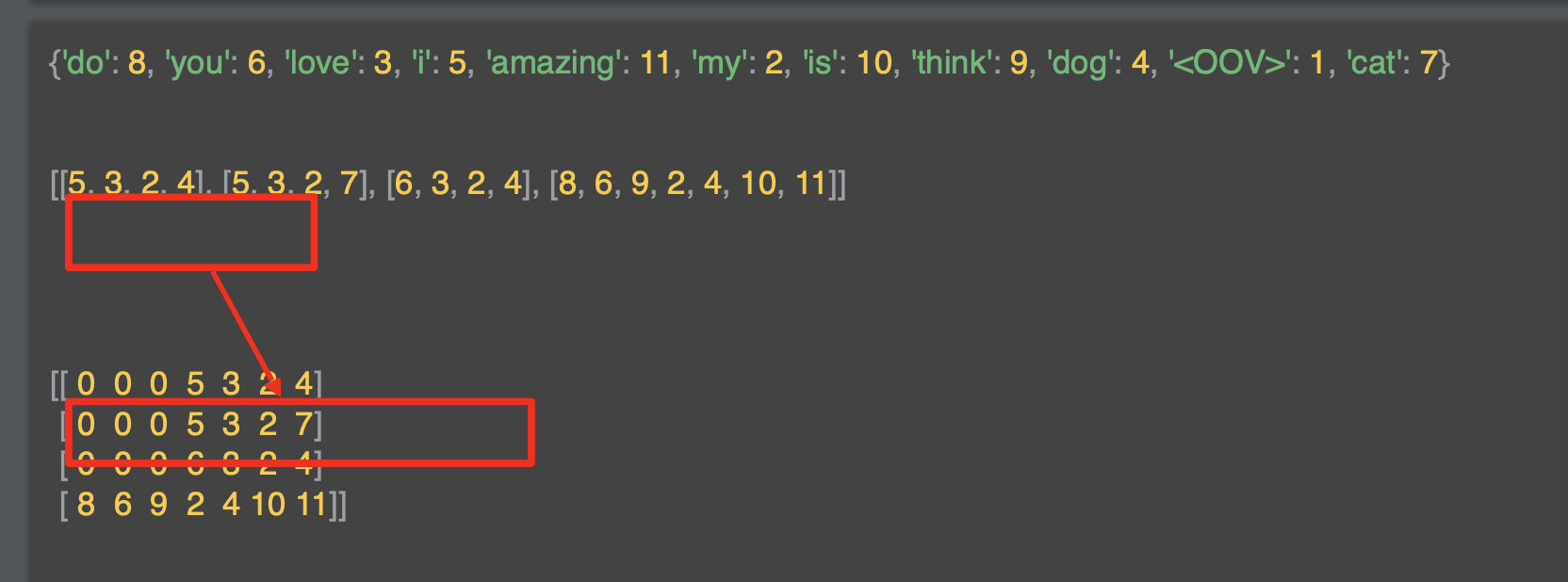
더 긴 문장의 경우에는 아무 것도 할 필요가 없다.
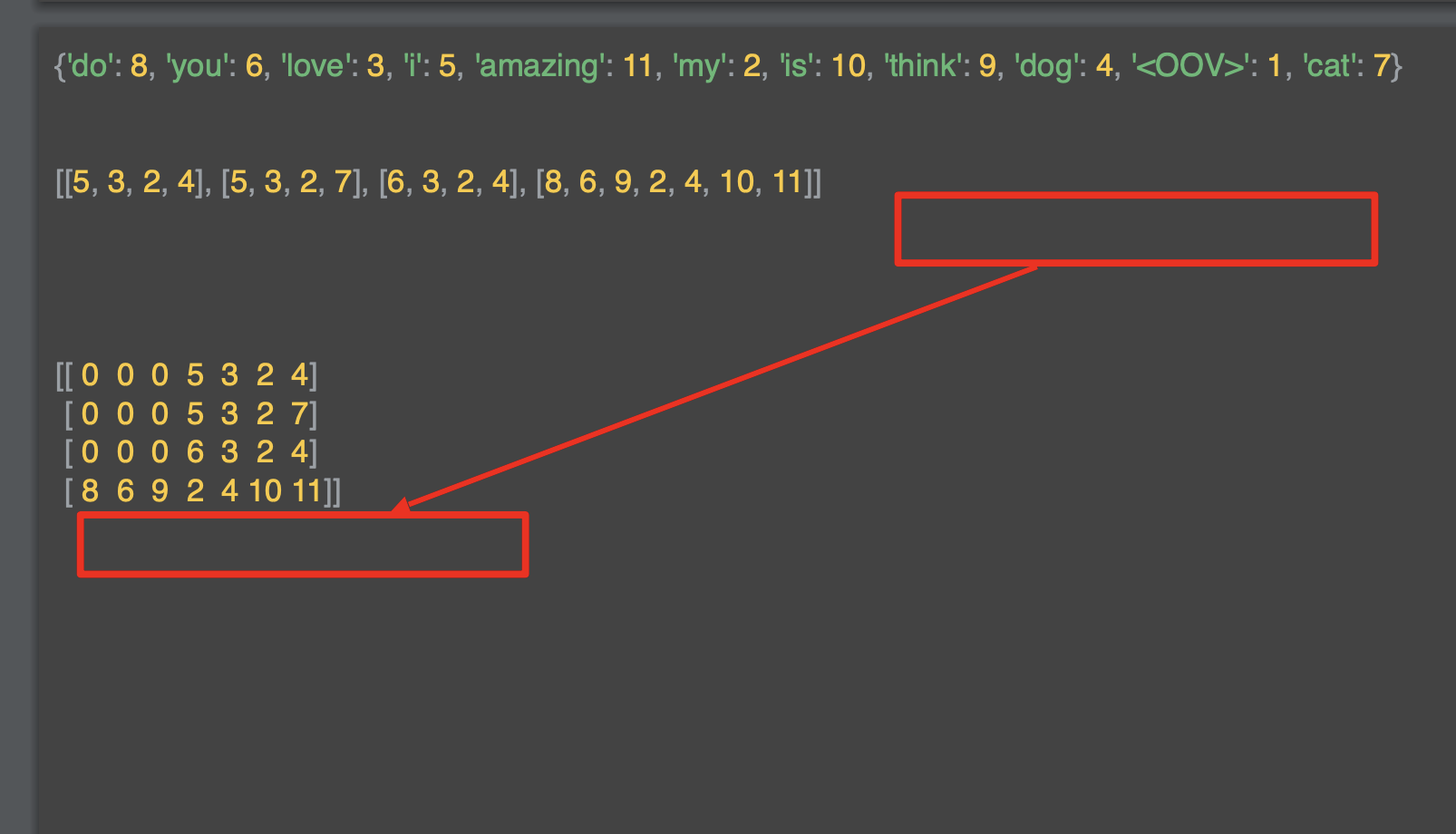
문장의 안쪽의 여백은 문장의 앞에 있는 예를 종종 볼 수 있다.

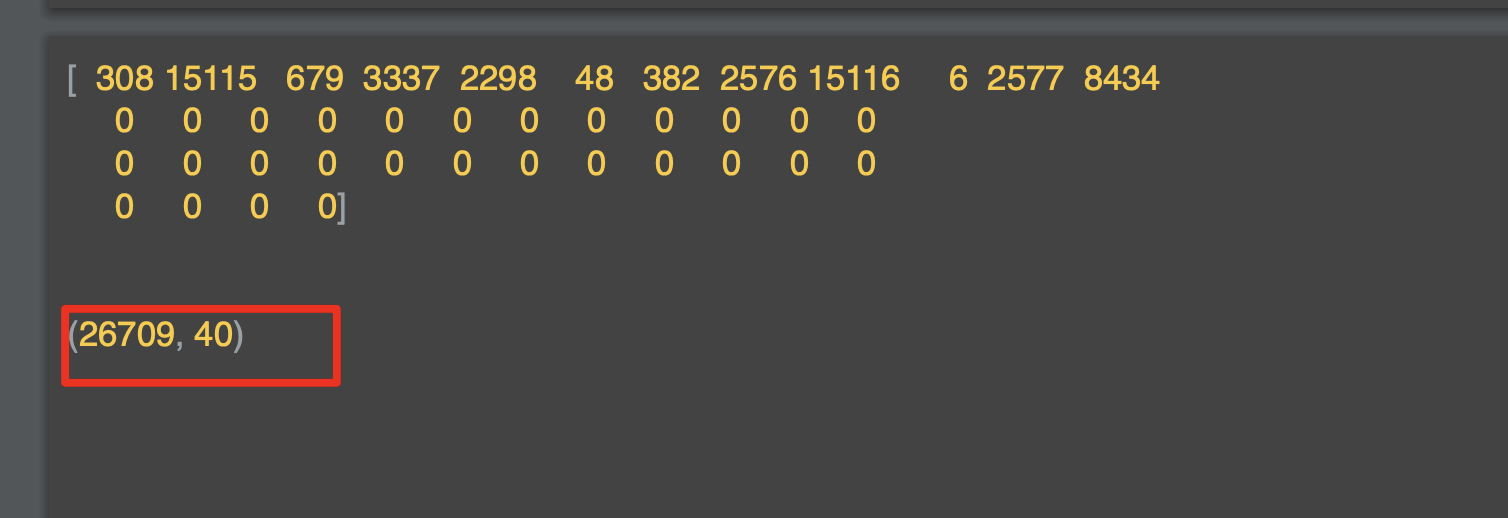
해당 옵션을 변경해서 'post'로 변경하면 앞에 패딩을 줄 수 있다.

또한 행렬의 너비가 가장 긴 문장과 동일했는데, 해당 길이는 maxlen 매개 변수를 조정해서 조절 가능하다.
최대 5의 길이를 가지기를 희망하면 maxlen을 5로 지정하면 된다.

만약 문장이 최대 길이보다 길다면, 정보는 손실 되지만 위치는 조정이 되는데 문장의 처음부터 잃게 된다.
만약 문장의 마지막을 잃게 하고 싶다면 'truncating'에 post 옵션을 주면 된다.
이제 문장을 인코딩하고 패딩하고 인코딩 했다.
Notebook for lesson 2
지금까지 수행한 몇 가지 텍스트 처리를 위해서Tokenizer와 pad_sequence를 이용하면 된다.
문장 목록들을 가지고 토크나이저를 인스턴스화 한다.
코퍼스의 최대 단어는 100으로 지정하고, 어휘가 없는 토큰은 <OOV>를 주는 옵션을 주었다.
다음으로 고유한 키 값 세트를 만들어 토크나이저의 단어 색인을 만든다. (word_index)
word_index property를 호출하는 것만으로 토크나이저에서 단어를 꺼낼 수 있고, 단어 인덱스 변수를알 수 있다.
다음으로 토크나이저에서 시퀀스를 사용할 수 있도록 텍스트 문장을 시퀀스로 변환한다. (texts_to_sequences)
각 문장을 특정 단어의 키 값으로 변환하는 것이다.
다음으로 pad_sequences로 모든 시퀀스를 동일한 길이로 맞춘다. 신경망을 훈련할 때는 모든 데이터의 크기가 같아야 한다.
pad_sequence를 사용할 때 padding은 뒤의 패딩을 의미하는 'post'로 truncating은 뒤를 잘라내는 'post'로 둔다.
사용할 배열의 너비를 지정하기로 한 경우는 maxlen 파라미터를 이용하면 된다.
기본값은 padding과 truncating의 기본 값은'pre'이다.


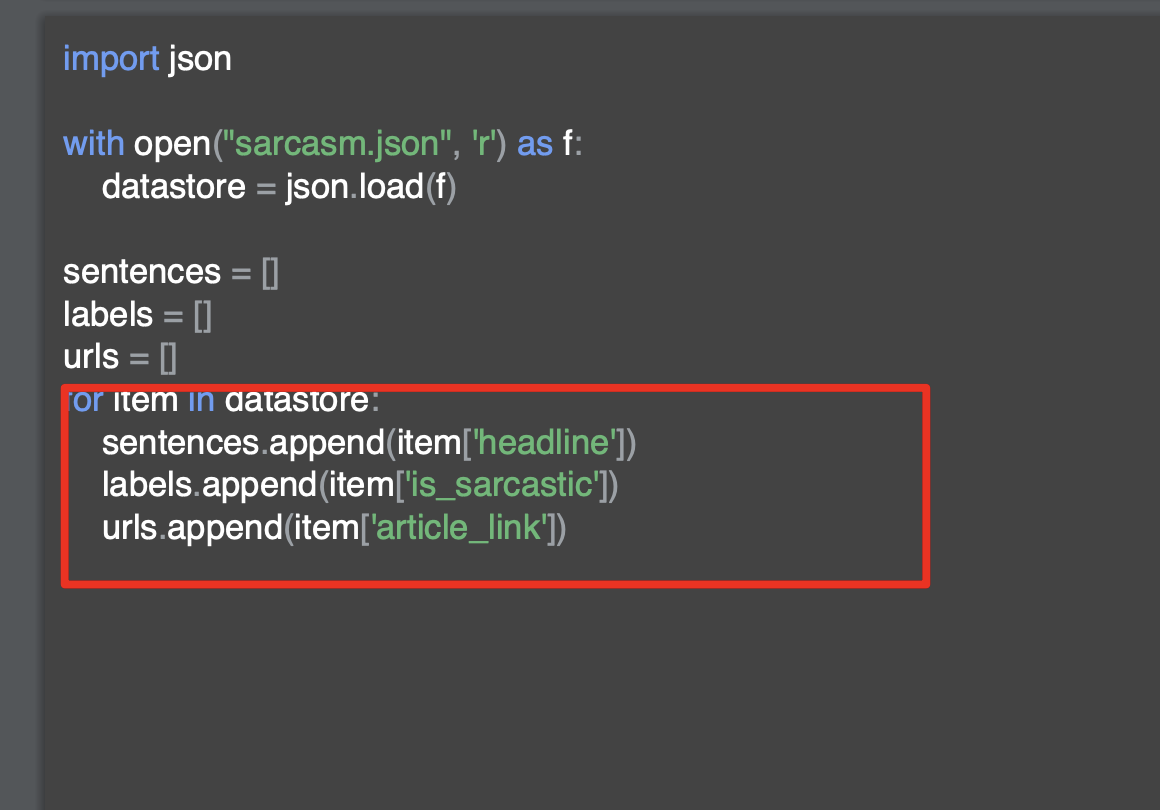


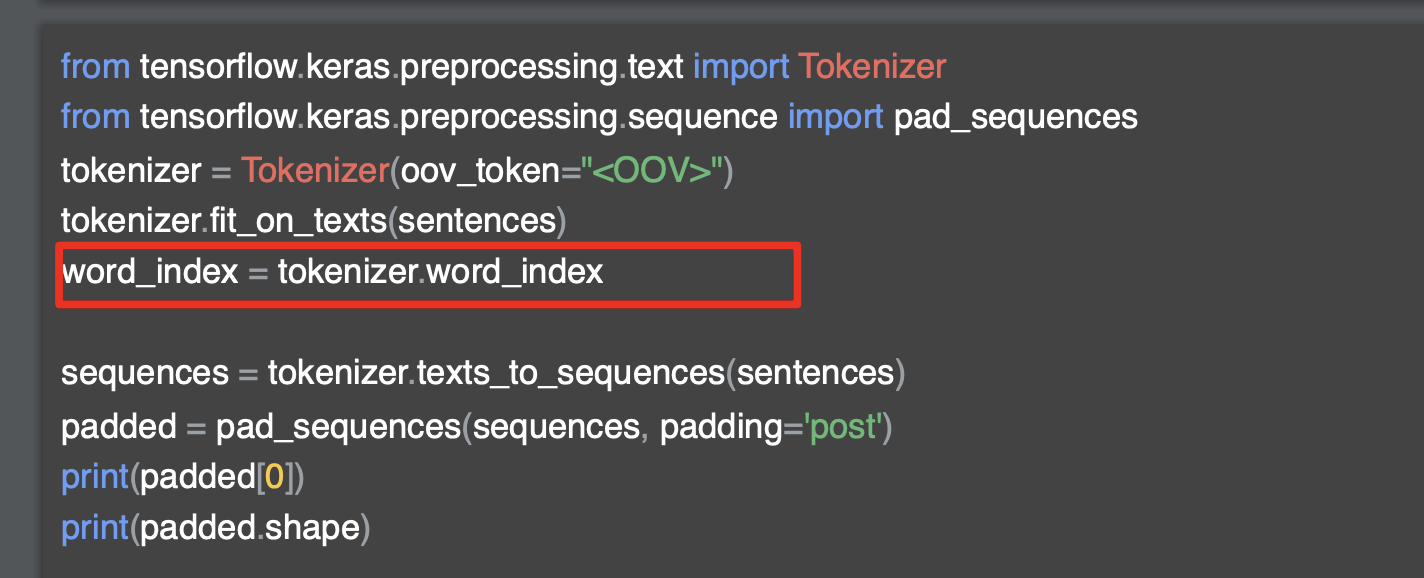


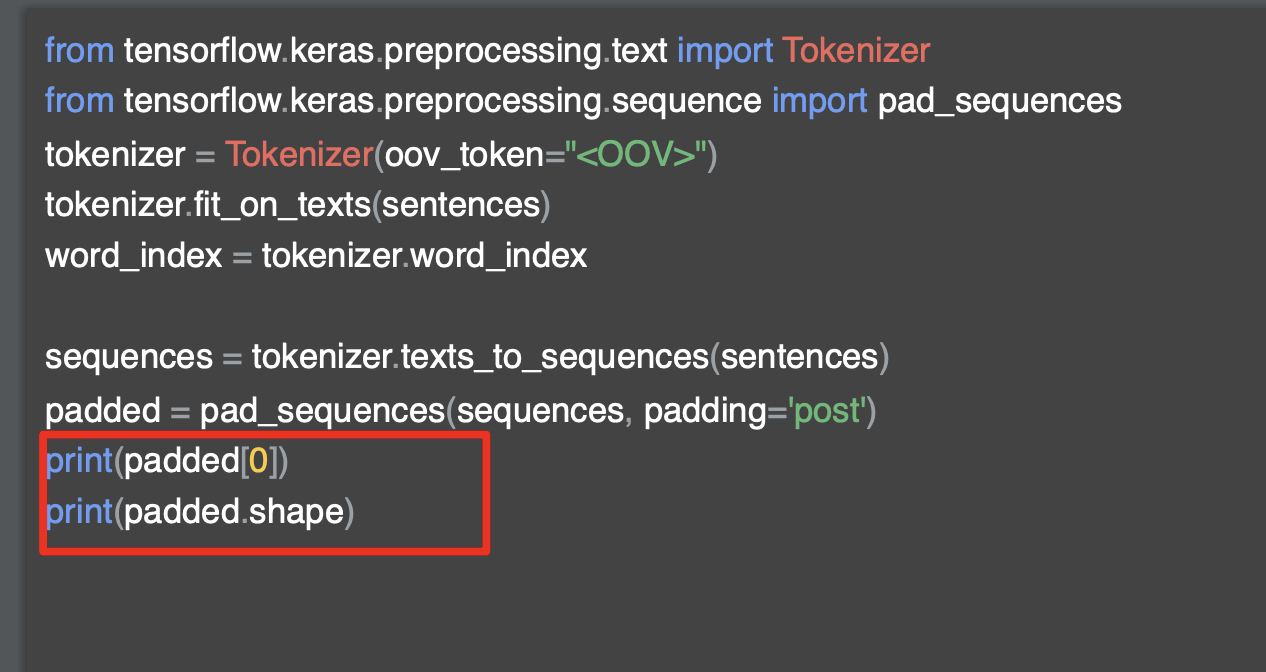
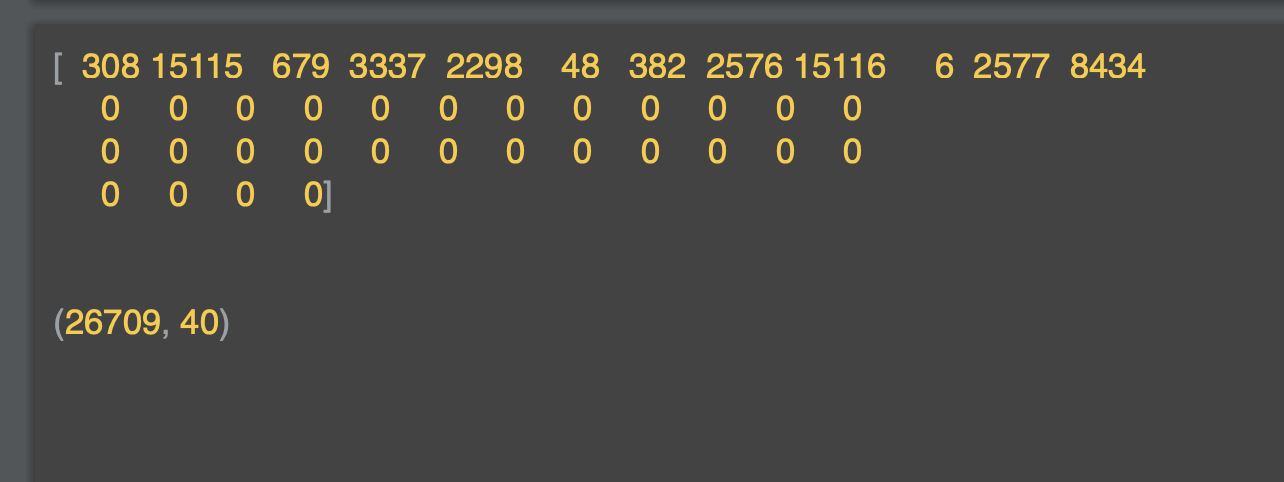
[6] RNN(순환신경망)과 pre-padding
대부분 자연어 처리에서 패딩을 수행할 때 post-padding을 수행하지만,
모델 및 데이터의 특성에 따라 pre-padding을 수행할 경우가 있다.
대표적으로 RNN과 같은 순환신경망은 pre-pading이 더 효율적이라고 한다.
간단하게 그 이유를 정리하자면
(1) Gradient Vanishing/Exploding 방지
- RNN은 입력 시퀀스를 순차적으로 처리하면서 각 시점의 출력을 계산한다.
이때 역전파 알고리즘을 사용하여 그래디언트를 계산하는데, RNN은 긴 시퀀스에 대해 학습하기 어려운 경향이 있다.
특히 역전파 과정에서 그래디언트가 시간에 따라 지수적으로 증가하거나 감소할 수 있는데, 우리가 자주 들어본 기울기 소실 혹은 폭주가 나타난다.(gradient vanishing 과 gradient exploding) - pre-padding을 사용하면 실제 데이터가 나중에 등장하므로 RNN이 초기에 패딩된 부분에 집중하여 gradient vanishing 문제를 완화할 수 있다.
(2) Long-term Dependency 처리
- RNN은 시퀀스의 이전 상태를 기억하여 현재 상태를 예측하는 데 사용된다. 따라서 긴 시퀀스에 대해 더 긴 상태를 유지하기 위해서는 장기 의존성(long-term dependency)을 처리할 수 있어야 한다.
- pre-padding을 사용하면 실제 데이터가 나중에 등장하므로 RNN이 초기에 패딩된 부분에 집중하여 장기 의존성을 더 잘 처리할 수 있다.
(3) Computational Efficiency
- RNN은 입력 시퀀스의 각 요소를 순차적으로 처리하기 때문에, pre-padding을 사용하면 입력 데이터를 반대로 처리할 필요가 없기 때문에 이는 계산의 효율성을 높일 수 있.
(4) Attention 메커니즘을 고려할 때
- attention 메커니즘은 입력 시퀀스의 각 요소에 가중치를 할당하여 모델이 특정 부분에 더 집중하도록 한다.
- pre-padding을 사용하면 실제 데이터가 나중에 등장하므로 모델이 입력 시퀀스의 중요한 부분에 더 집중할 수 있다.
즉, 정리하자면 긴 시퀀스를 처리하거나 장기 의존성을 처리해야 하는 경우에 pre-padding이 유용할 수 있고, 실제 데이터가 나중에 등장해야 하는 경우에 더 적합하므로 이때 pre-padding 을 사용한다고 보면 되겠다.
