[Tensorflow] 4. Sequences, Time Series and Prediction(3. Recurrent Neural Networks for Time Series) : lecture
Tensorflow_certification(텐서플로우 자격증)
4. Sequences, Time Series and Prediction(3. Recurrent Neural Networks for Time Series)
순환 신경망(RNN)과 장단기 기억 네트워크(LSTM)는 순차 데이터를 분류하고 예측하는 데 유용하다. 시계열과 함께 사용하는 법을 살펴본다.
[0] Instruction
저번 장에서는 시계열에 DNN을 적용했지만, 시계열은 시간 관련 데이터로 RNN이나 LSTM 같은 시퀀스 모델을 적용해야 한다.
시계열의 데이터의 경우 30일이나 30개의 기간을 보면, 일부 시계열 데이터는 예측값과 비슷하게 나타나면서 데이터에 큰 영향을 줄 가능성이 높다.
그래서 RNN, LSTM으로 더욱 정확한 데이터를 예측할 수 있다.
큰 window size 로 멀리서부터 컨텍스트를 참고한다.
셀 상태를 통해 오랜 학습 기간 동안 컨텍스트를 유지해서 일부 시계열의 데이터의 경우 큰 영향을 줄 수 있다.
예를 들어 금융 데이터는 종가가 30일, 60일, 90전의 종가보다 내일의 종가에 더 큰 영향을 줄 것이다. RNN, LSTM 으로 계절성 데이터를 더 잘 예측할 수 있다.
추가로 lambda layer를 쌓늗네, lambda 함수는 기본적으로 이름이 없는 함수이지만 데이터를 재전송하고 스케일링하는 신경 내의 레이어로 도입된다.전처리 단계가 별개의 단계가 아니라 신경망으로 편입되는 것이다.
즉, 이번 장은 시퀀스 데이터에 RNN, LSTM을 적용하고 Lambda layer를 핸들링한다.
[1] Conceptual overview
예측 작업을 위한 RNN으로,
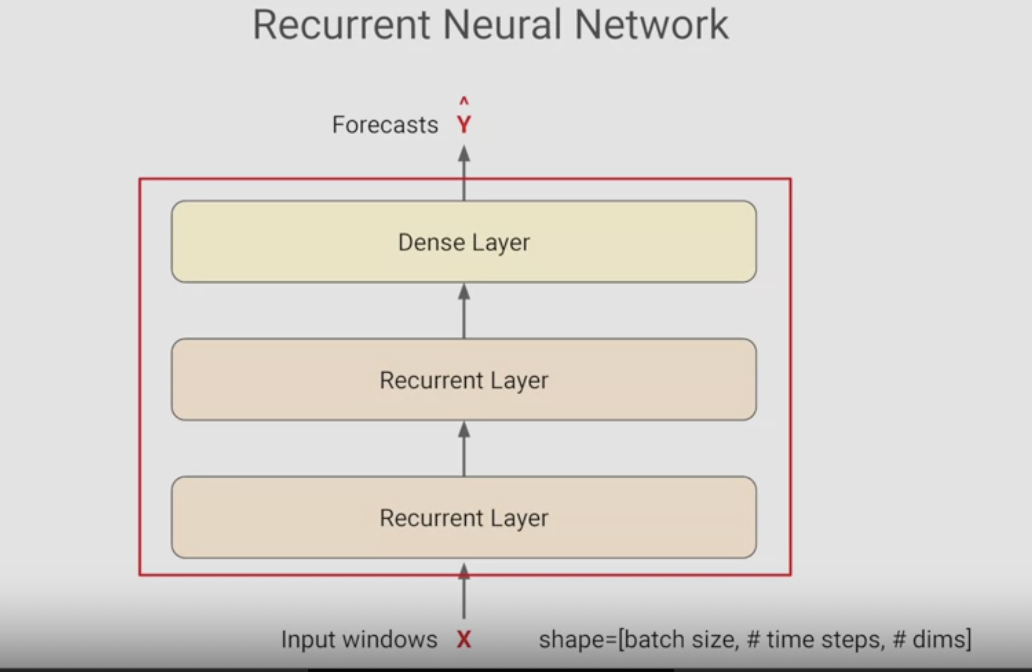
순환 레이어를 포함하는 신경망으로 시퀀스 입력값을 순차적으로 처리하도록 설계되어 있다. 굉장히 유연해서 모든 종류의 시퀀스 데이터를 처리할 수 있다. 텍스트 예측에도 사용가능하고 이번에는 시계열 데이터에 처리한다.
두 개의 순환 레이어와 출력값 역할을 수행하는 최종 Dense 레이어를 포함한 RNN을 구축해서, 시퀀스 배치를 넣어 출력값은 예측값 배치가 될 것이다.
한 가지 차이점은 RNN을 사용할 때의 전체 input_shape 는 3차원이다.
첫 번째 차원은 배치 크기, 두 번째는 시간, 세 번째는 각 시간 단계에서의 입력값 차원이다.
일변량 데이터는 dims가 1 다변량 데이터는 그 이상일 것이다.
지금까지 사용한 모델은 2차원 입력값으로 첫 번째가 배치 크기 두번째가 입력값 feature였다.
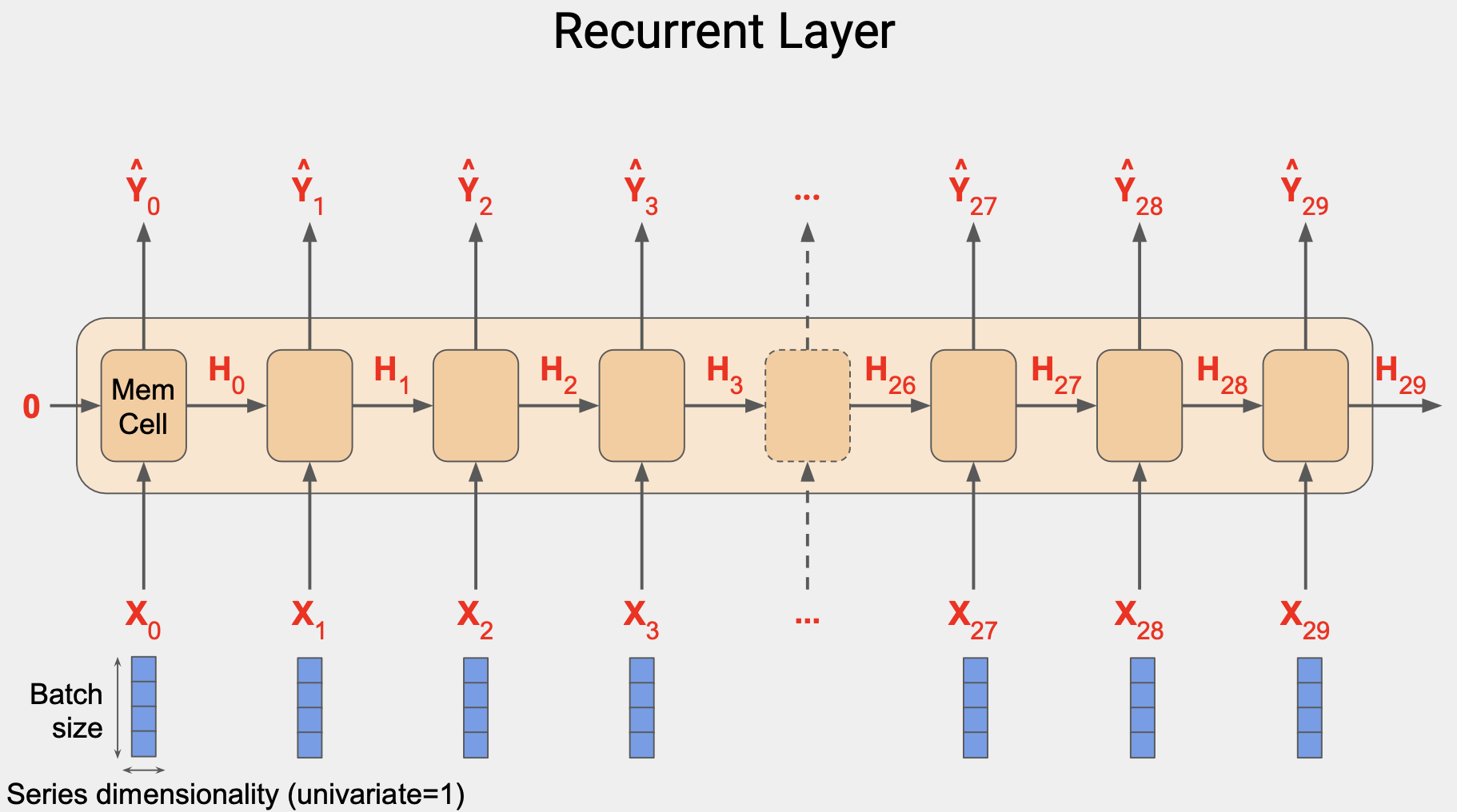
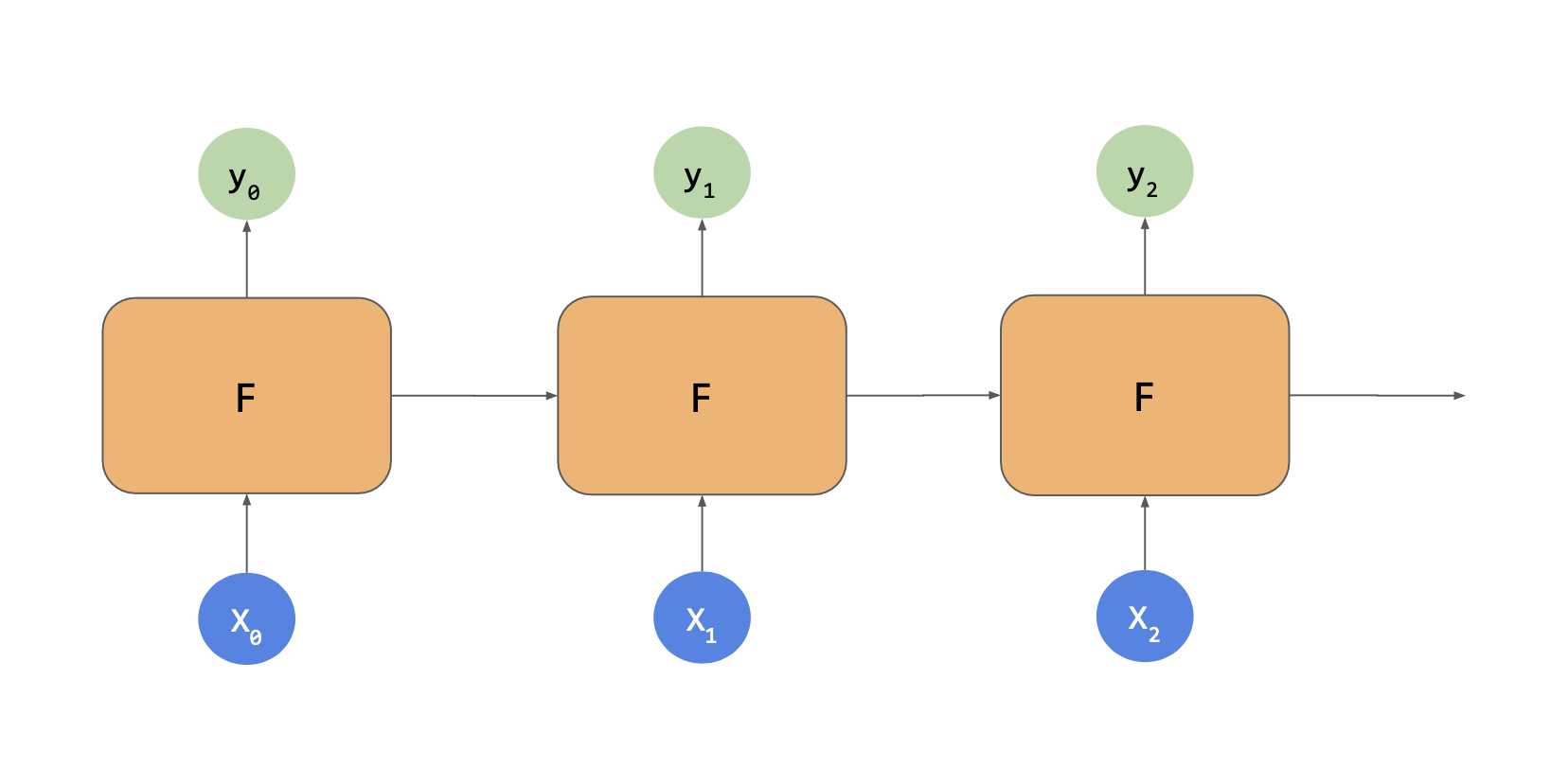
RNN 레이어의 작동 방식이다.
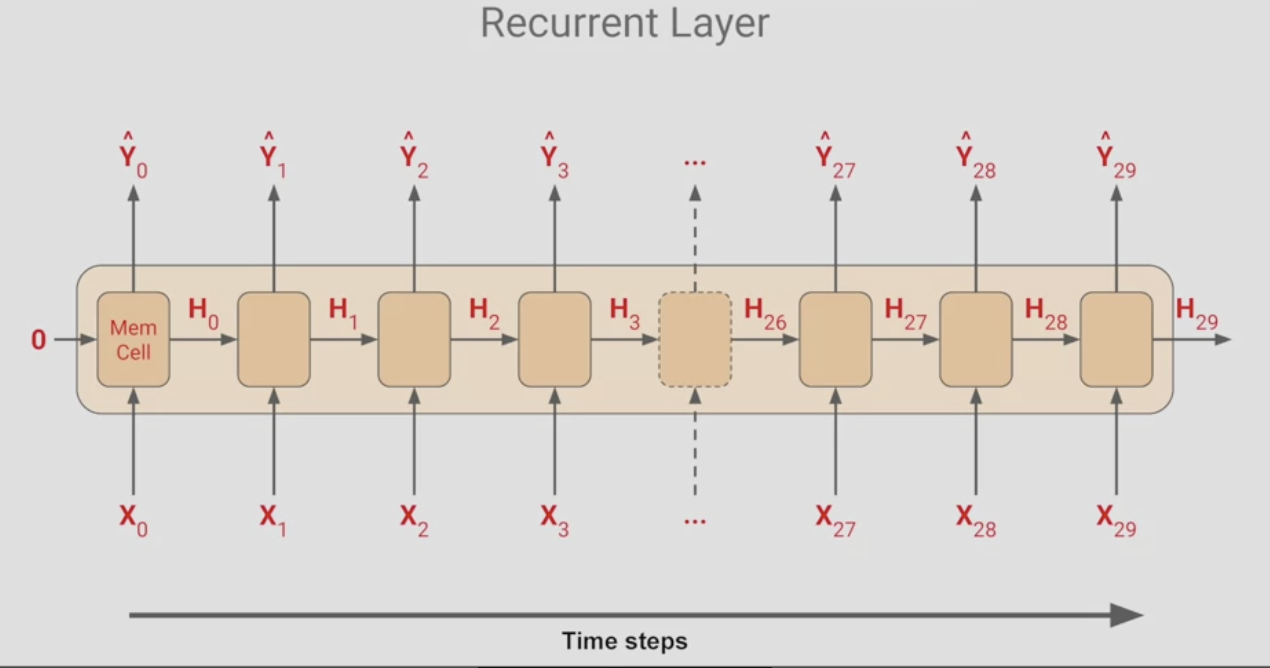
셀이 많은 것 같지만 실제로는 1개이고 이를 반복적으로 사용해서 출력값을 산출하는 것이다. 동일한 한 개의 값을 레이어로 여러 번 사용한다.
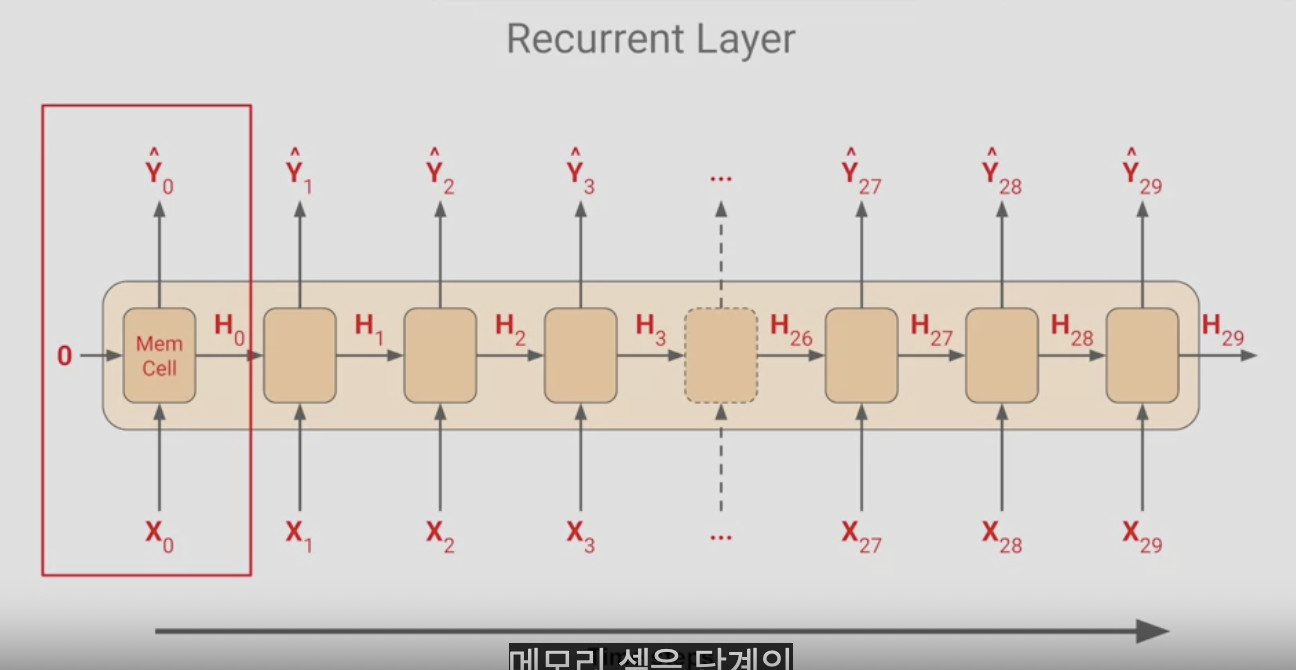
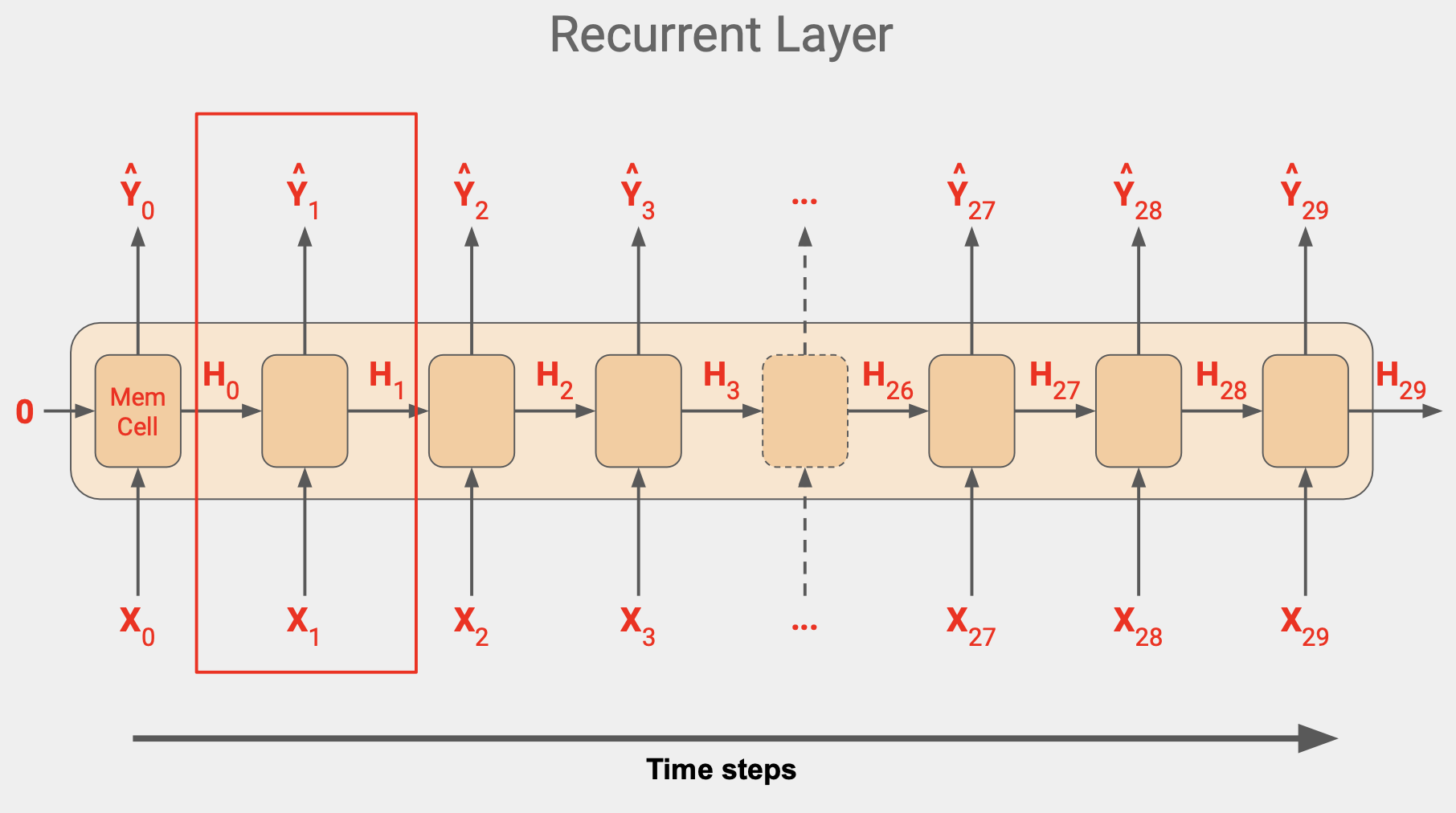
각 시간 단계에서 메모리 셀은 단계의 입력값을 사용한다. 시간이 0일때 0은 제로 상태의 입력값이다.이제 해당 단계의 출력값을 산출하는데 Y0와 상태 벡터 H0가 다음 단계로 가고, H0과 X1 이 함께 들어가서 Y1과 H1이 나오고 이 값이 다음 단계의 셀의 X2와 함께 들어가서 Y2, H2가 나온다.
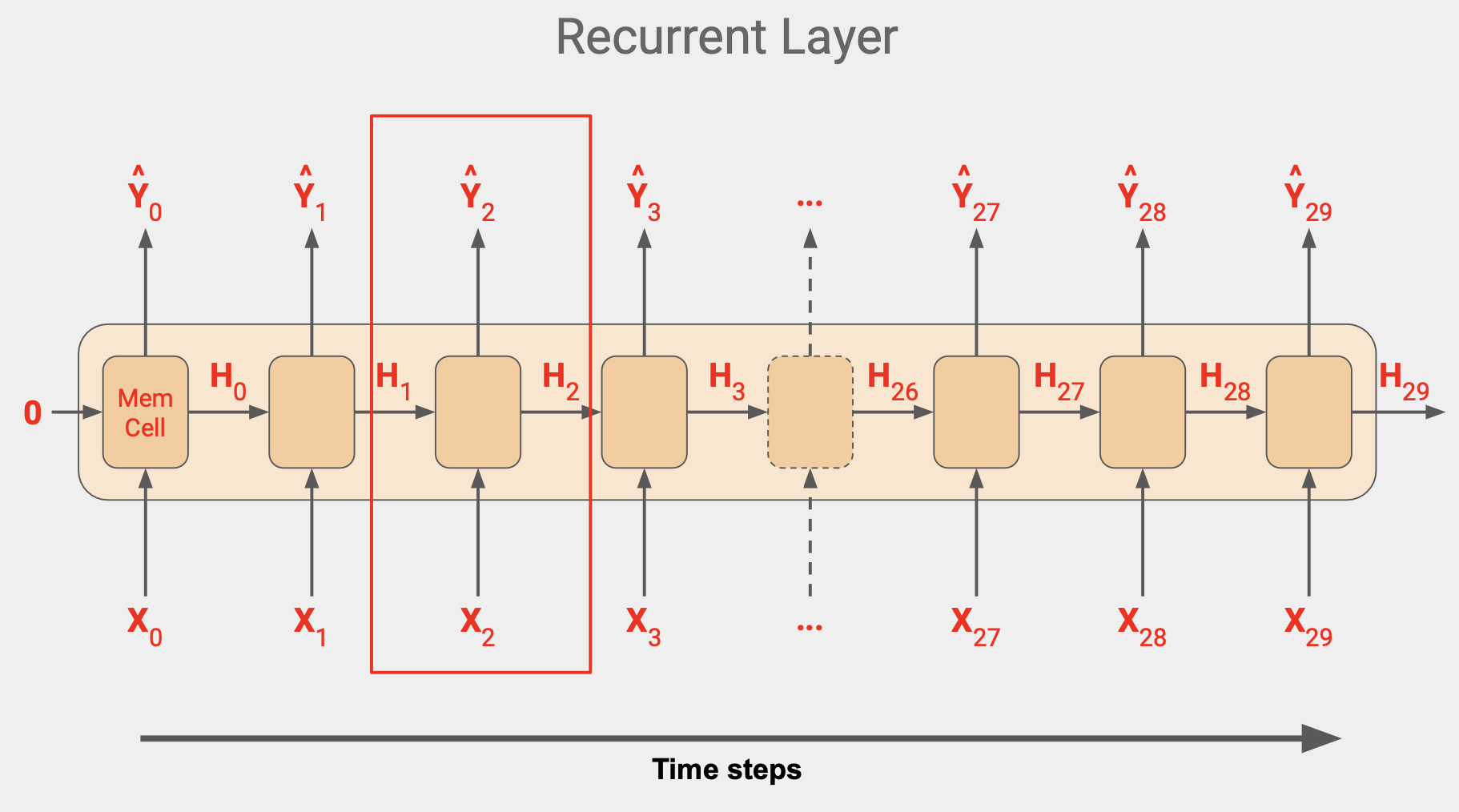
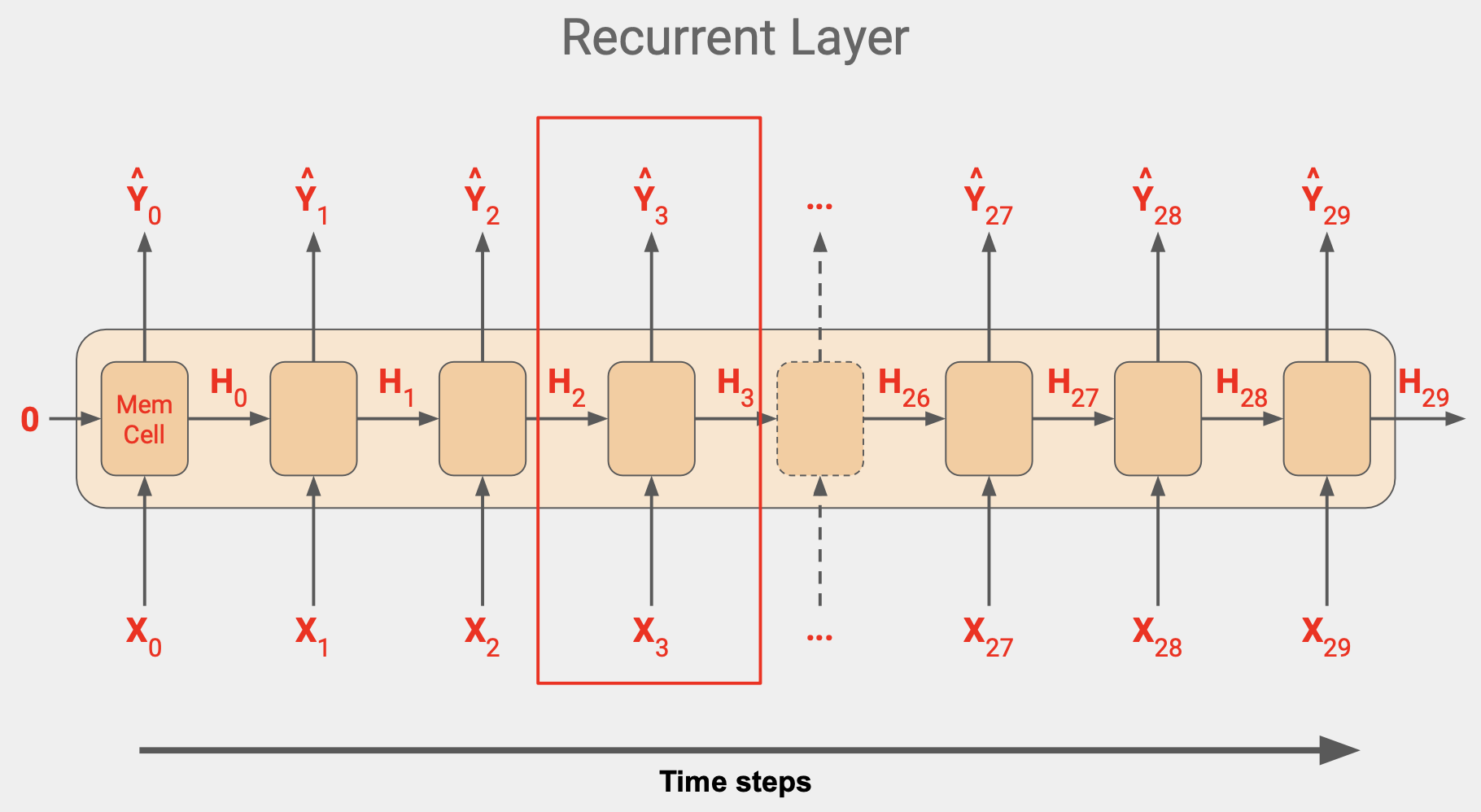
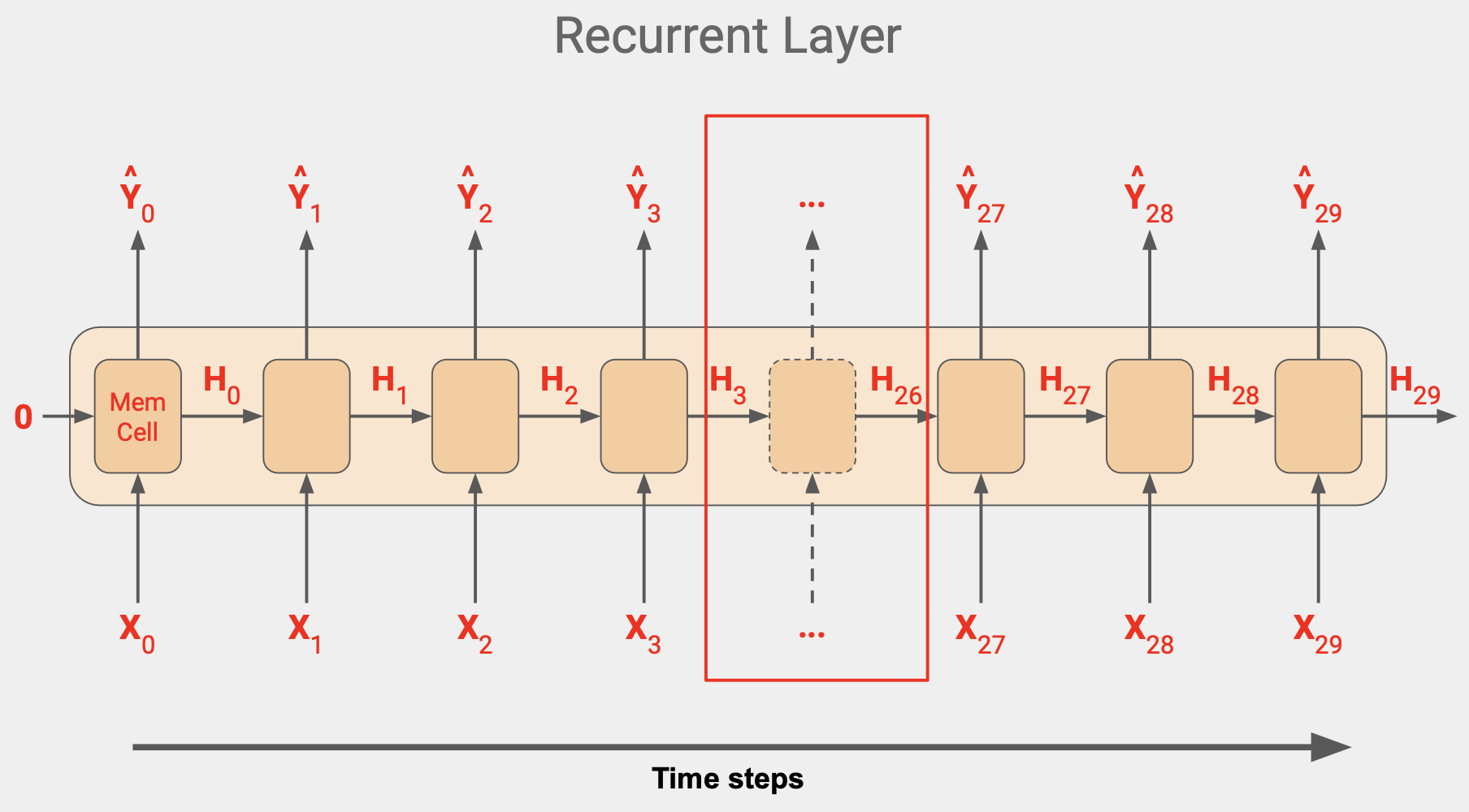
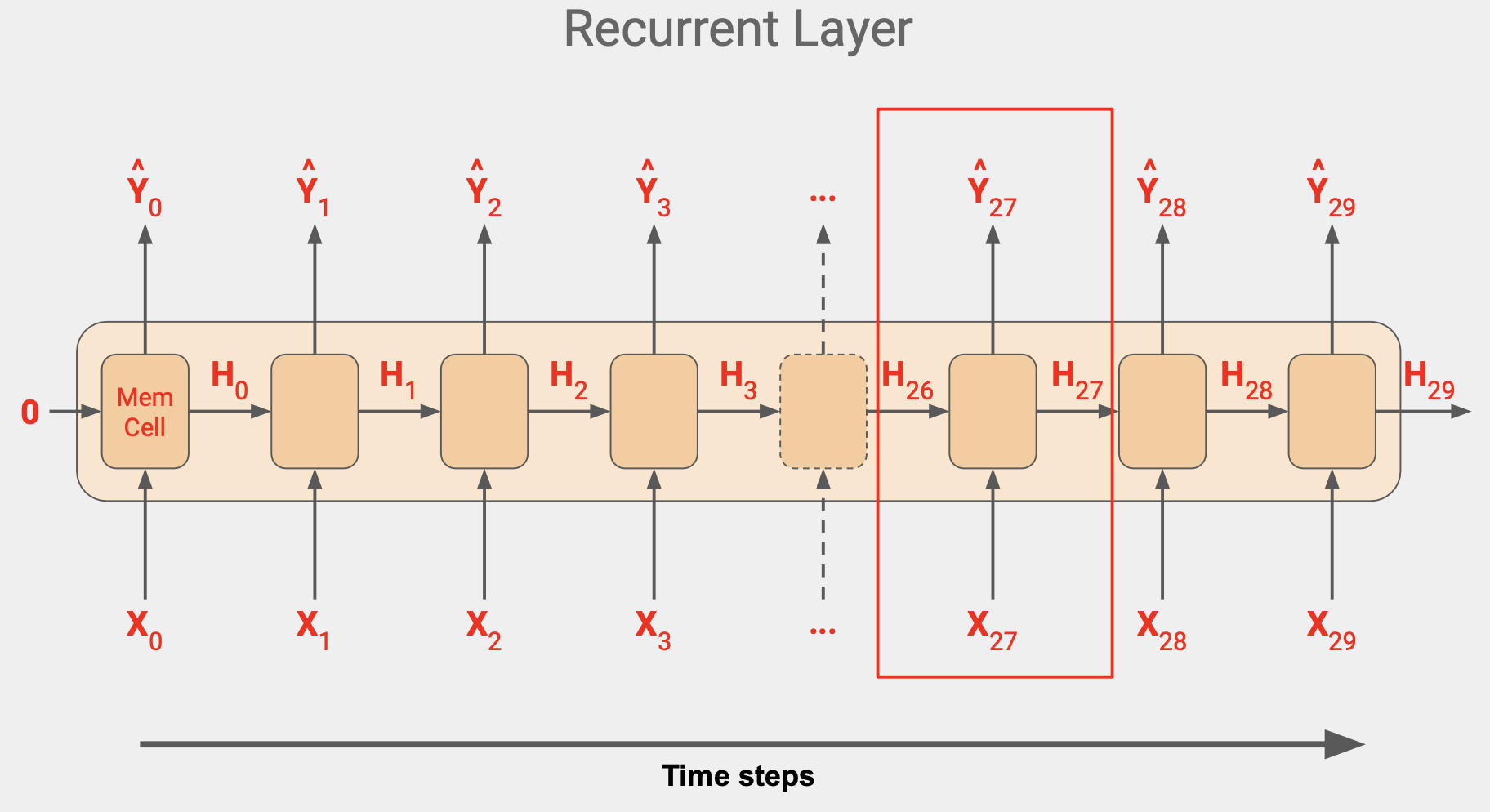
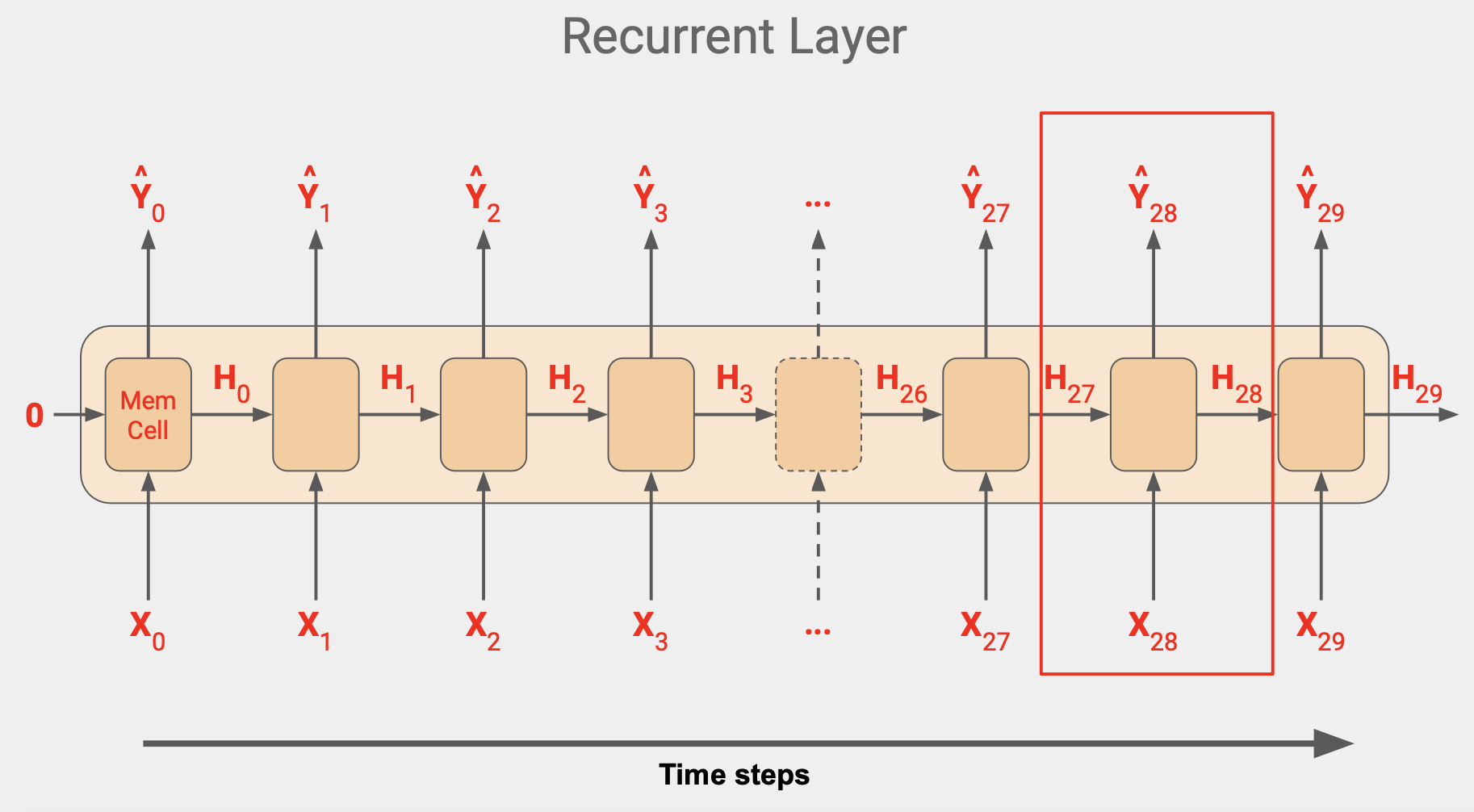

이 단계는 입력값 차원이 끝날 때 까지 계속되고, 위 그림에서는 값이 30이다.
이 유형의 아키텍처는 순환 신경망이라고 불리고, 셀의 출력값으로 인해 값이 순환하기 때문이다. 한 단계의 값이 다음 시간 단계로 그대로 들어간다.
이는 상태를 결정하는데 유용하다. 문장에서 한 단어의 위치는 의미를 결정하기 때문이다. 마찬가지라 시계열에서도 서로 근접해 있는 숫자는 목표값에서 멀어진 숫자보다 더 큰 영향을 줄 수 있다.
[2] Shape of the inputs to the RNN
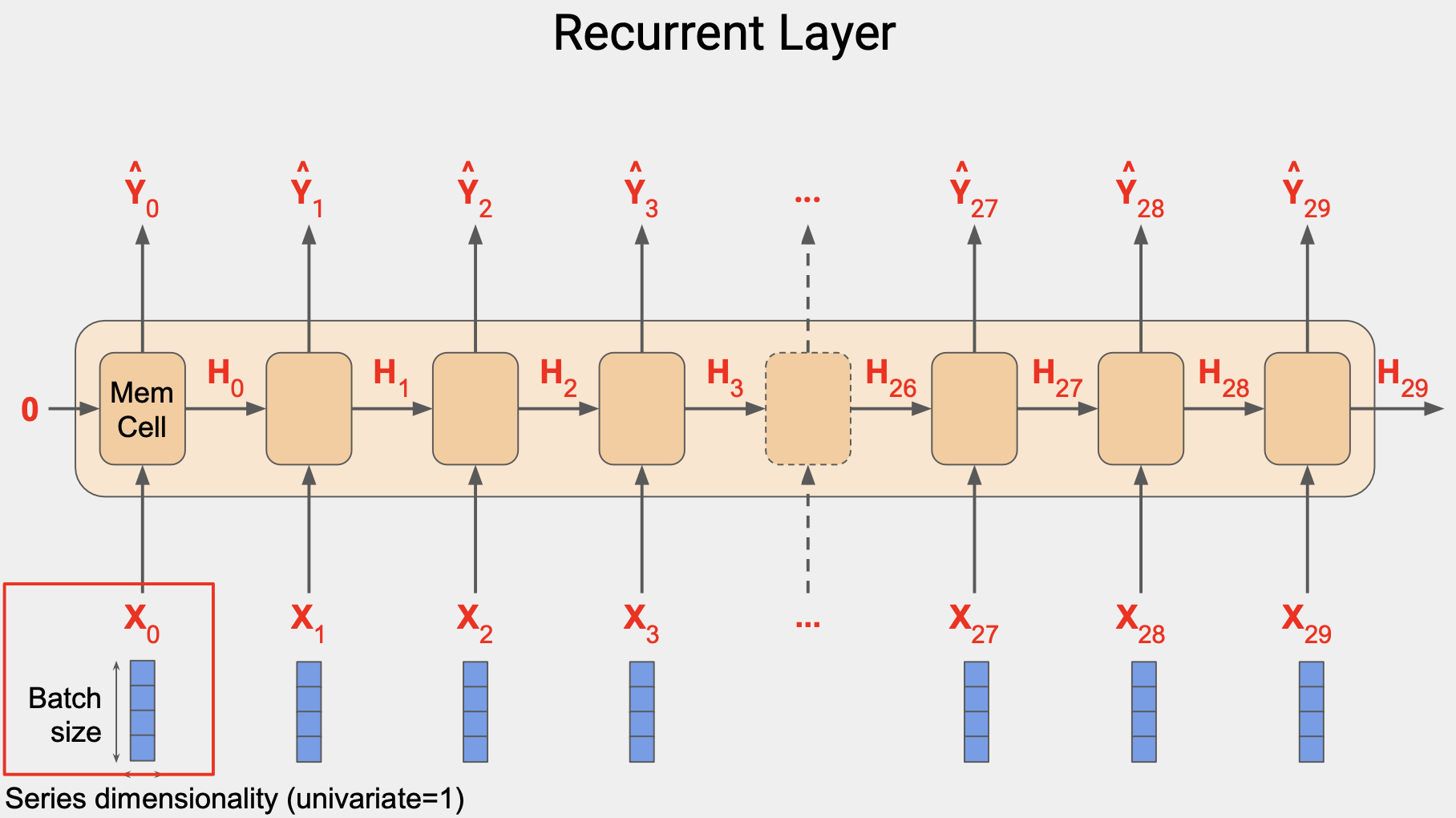
입력값은 3차원이다. 예를 들어 창 크기에서 시간 단계를 30이라고 하고, 4개로 일괄 처리한다면 형태는 4x30x1이다.
각 시간 단계에서 메모리 셀의 입력값은 4x1 행렬이다.
또한 셀에서는 이전 단계의 상태 행렬 입력값을 활용한다.
이 경우에는 첫 번쨰 단계는 0이다.
이후 단계는 메모리 셀에서 나온 출력값이 될 것이다.
하지만 상태 벡터를 제외하고 셀에서 Y값이 산출될 것이다.
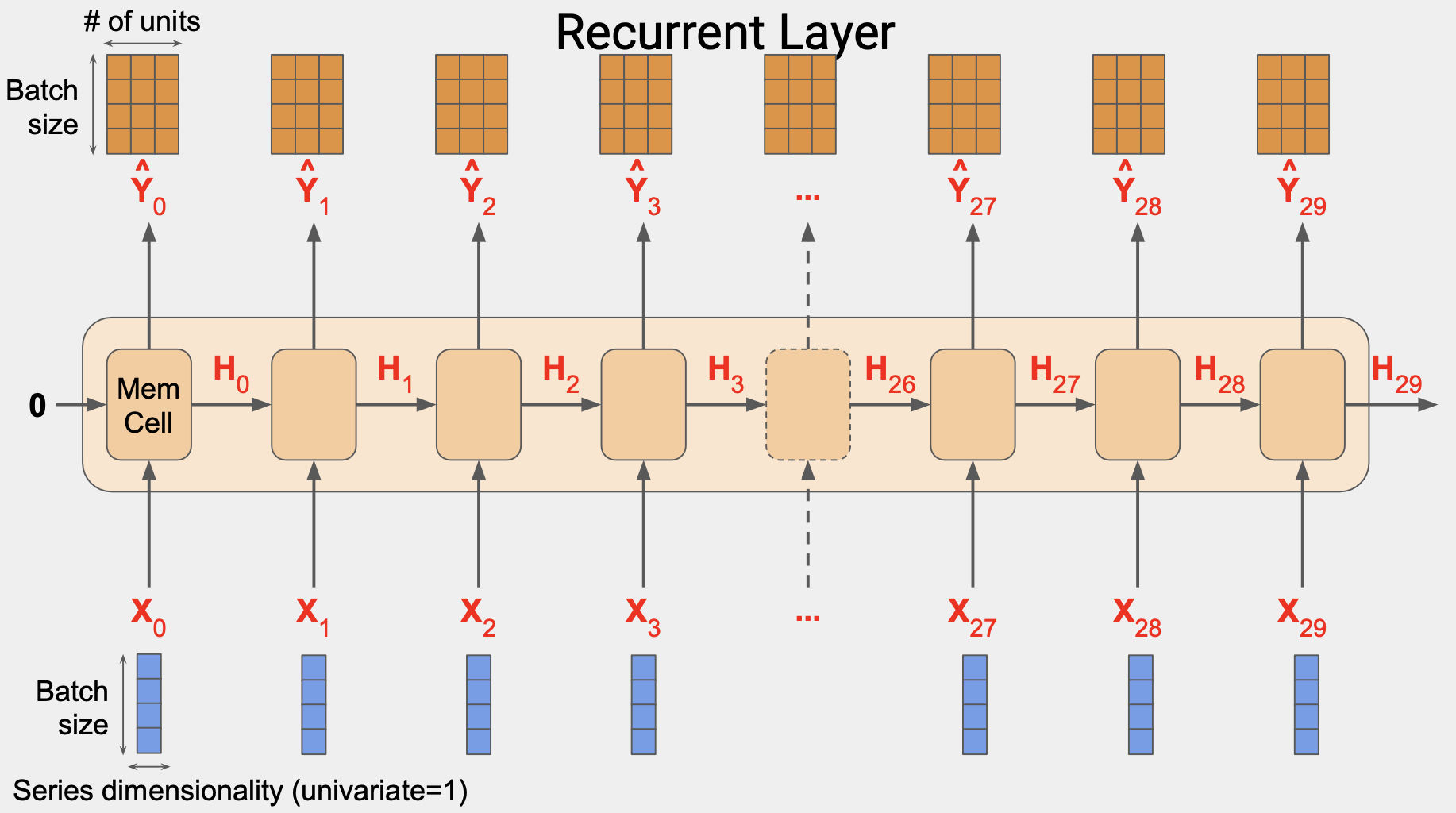
메모리 셀이 3개의 뉴런으로 구성된다면 출력값 행렬은 4x3이 될 것이다.
입력되는 배치 사이즈가 4이고 뉴런 개수가 3이기 때문이다.
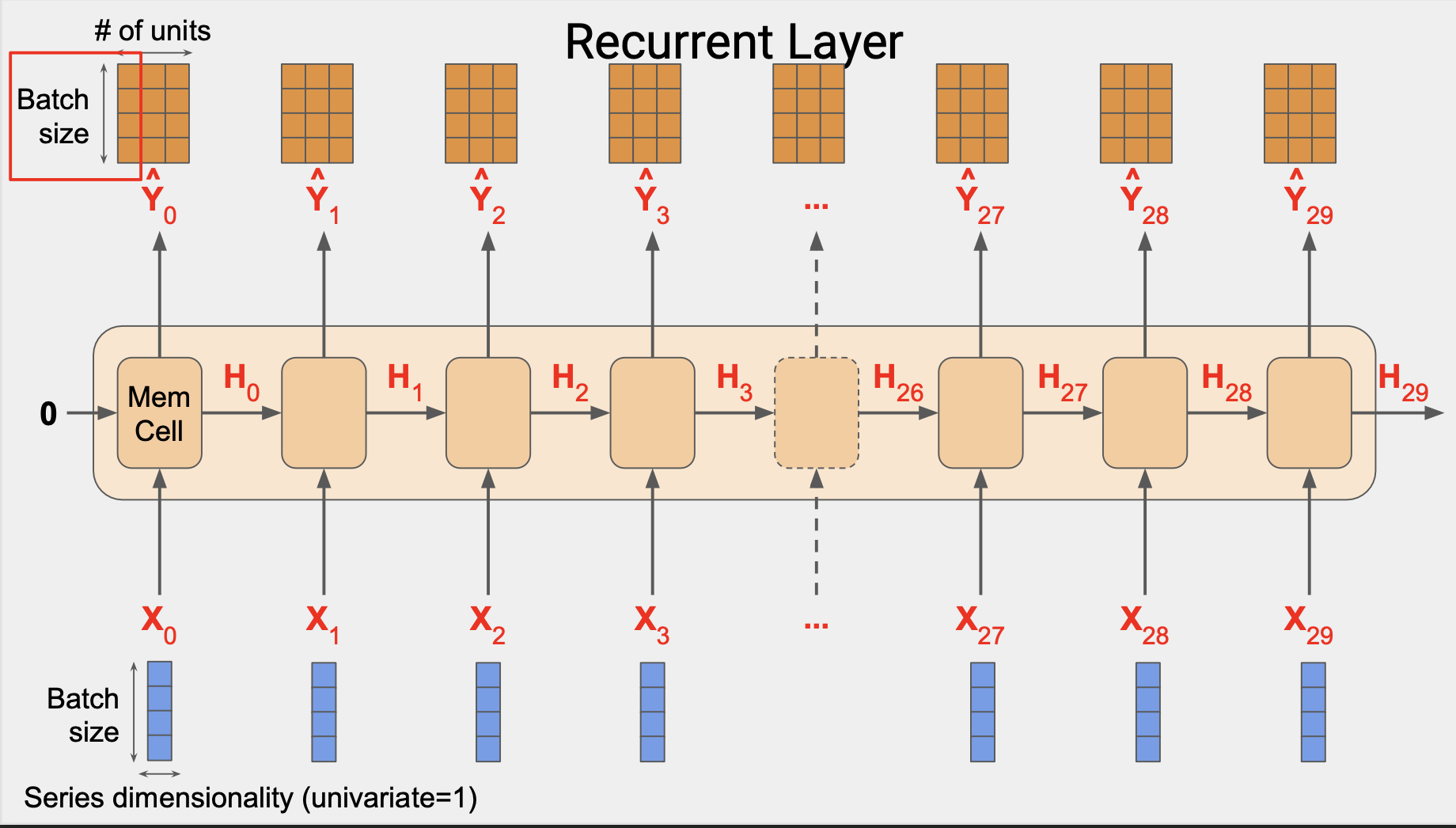
레이어의 전체 출력값은 3차원으로 구성된다.
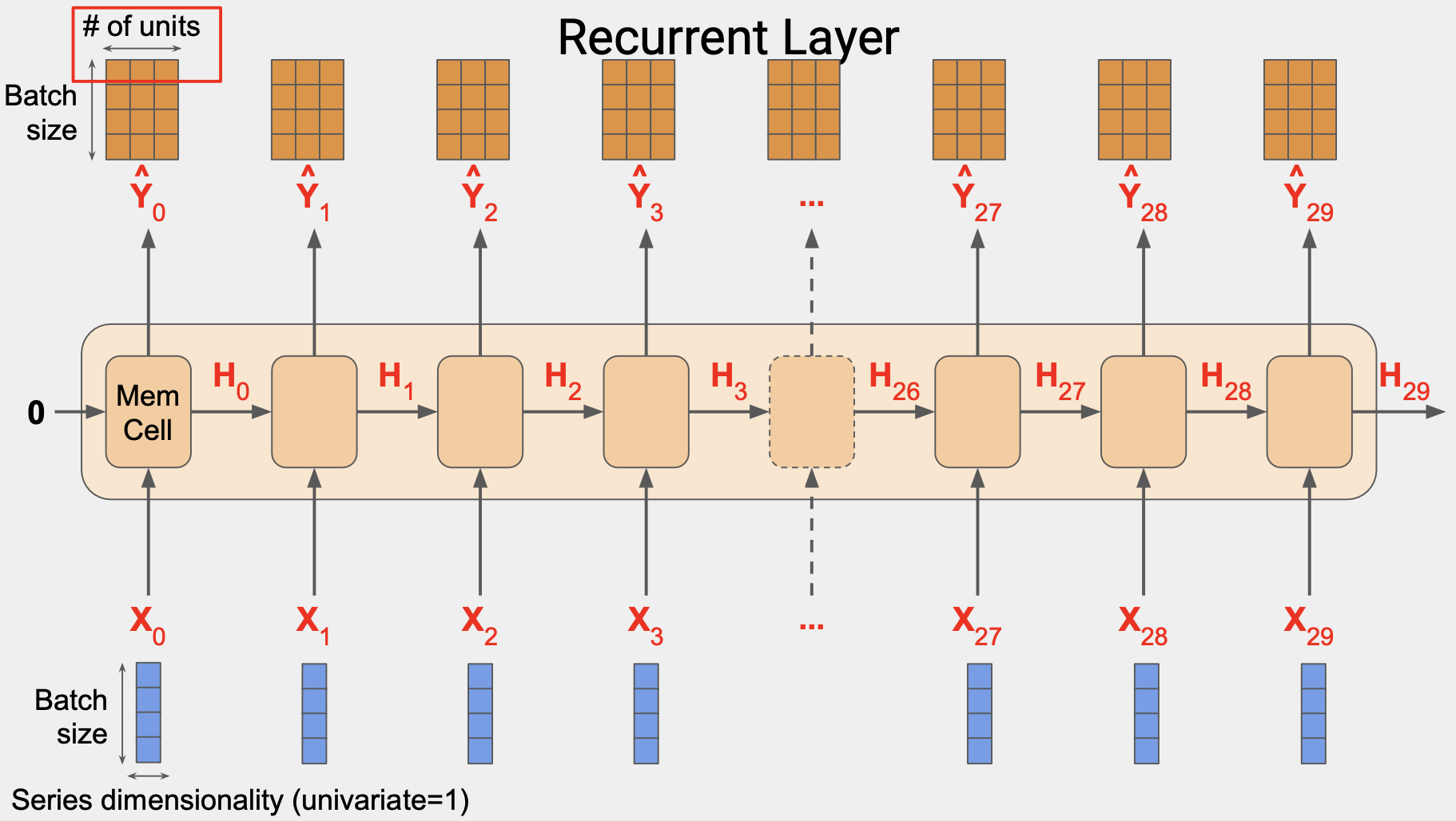
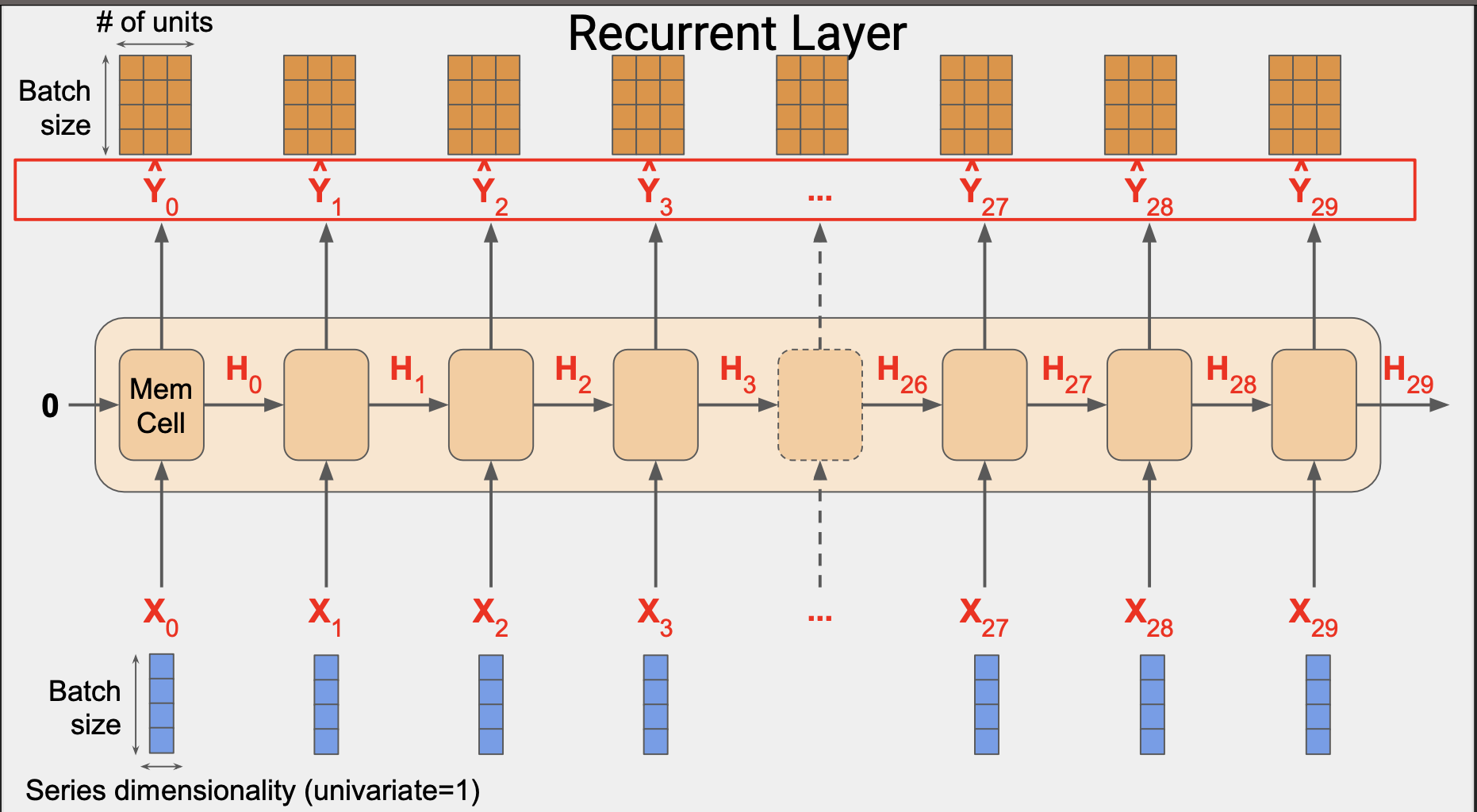
이 경우 4 x 30 x 3 이다. 4는 배치크기 3는 유닛 수, 30은 전체 단계의 숫자이다.

단순 RNN에서 상태 출력값 H는 출력값 행렬 Y와 동일하다.
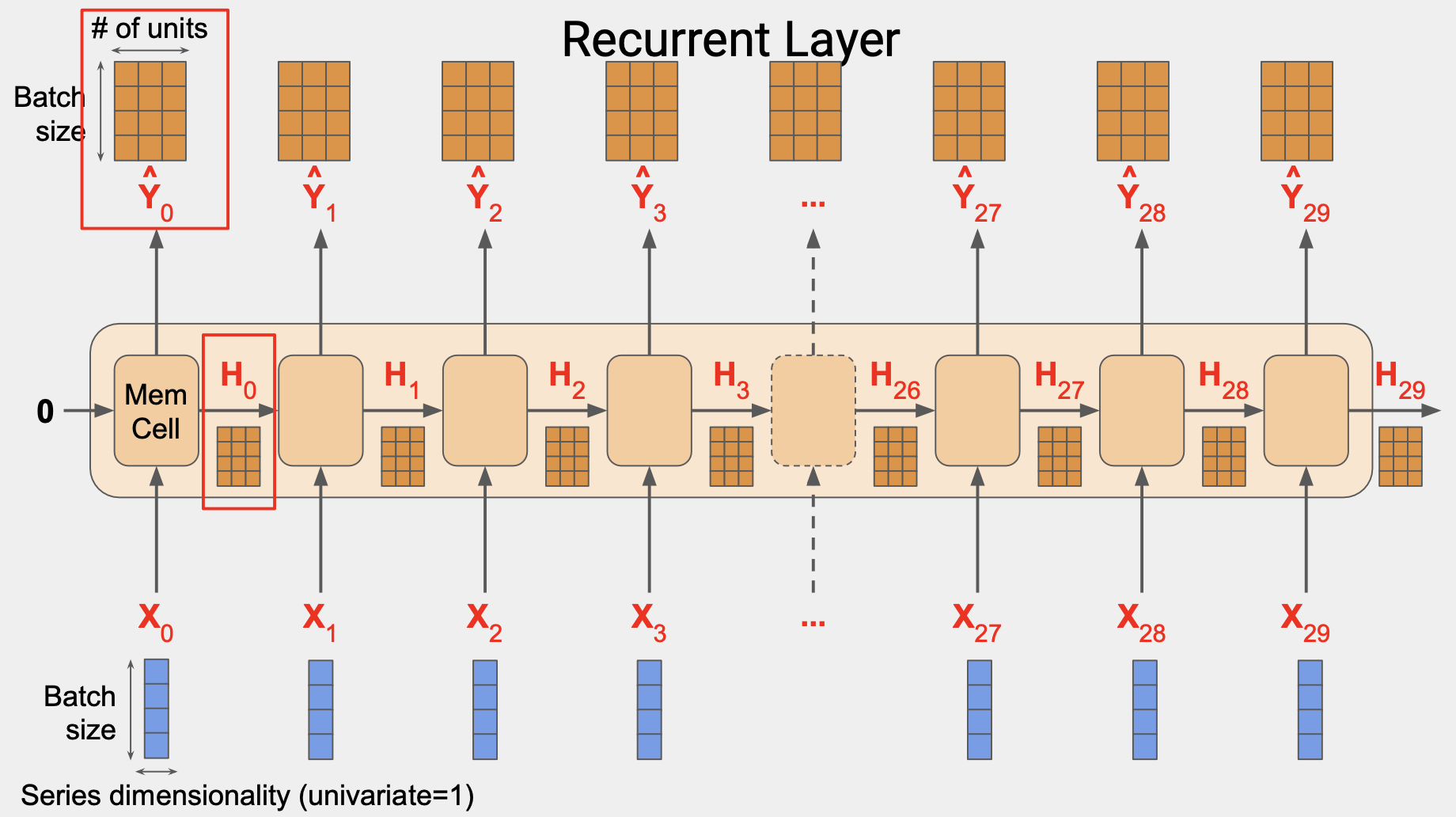
예를 들어 H0은 Y0의 복사본이고 H1은 Y1의 복사본이다.
각 시간 단계에서 메모리 셀은 현재 입력값와 이전 출력값을 활용한다.
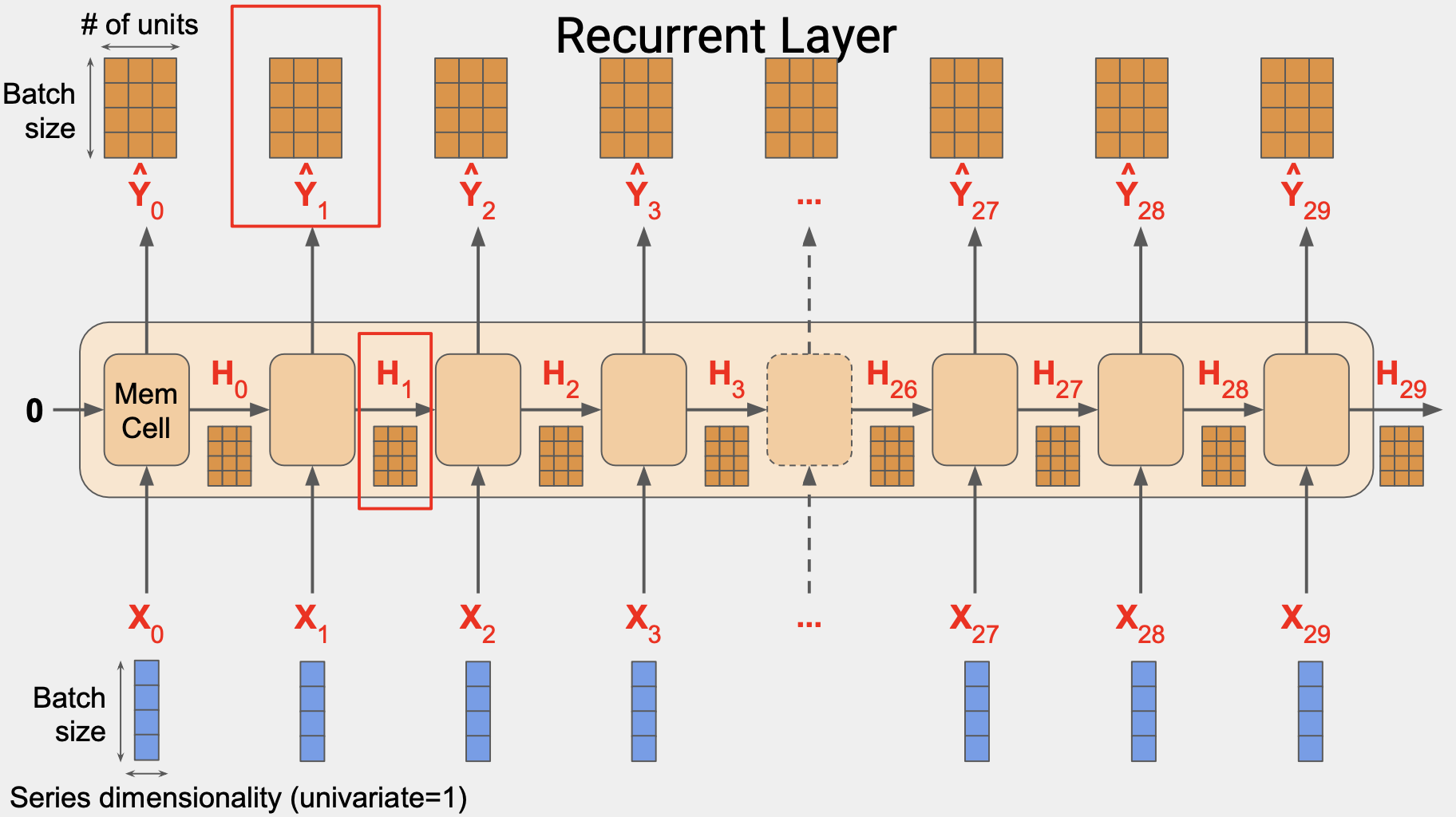
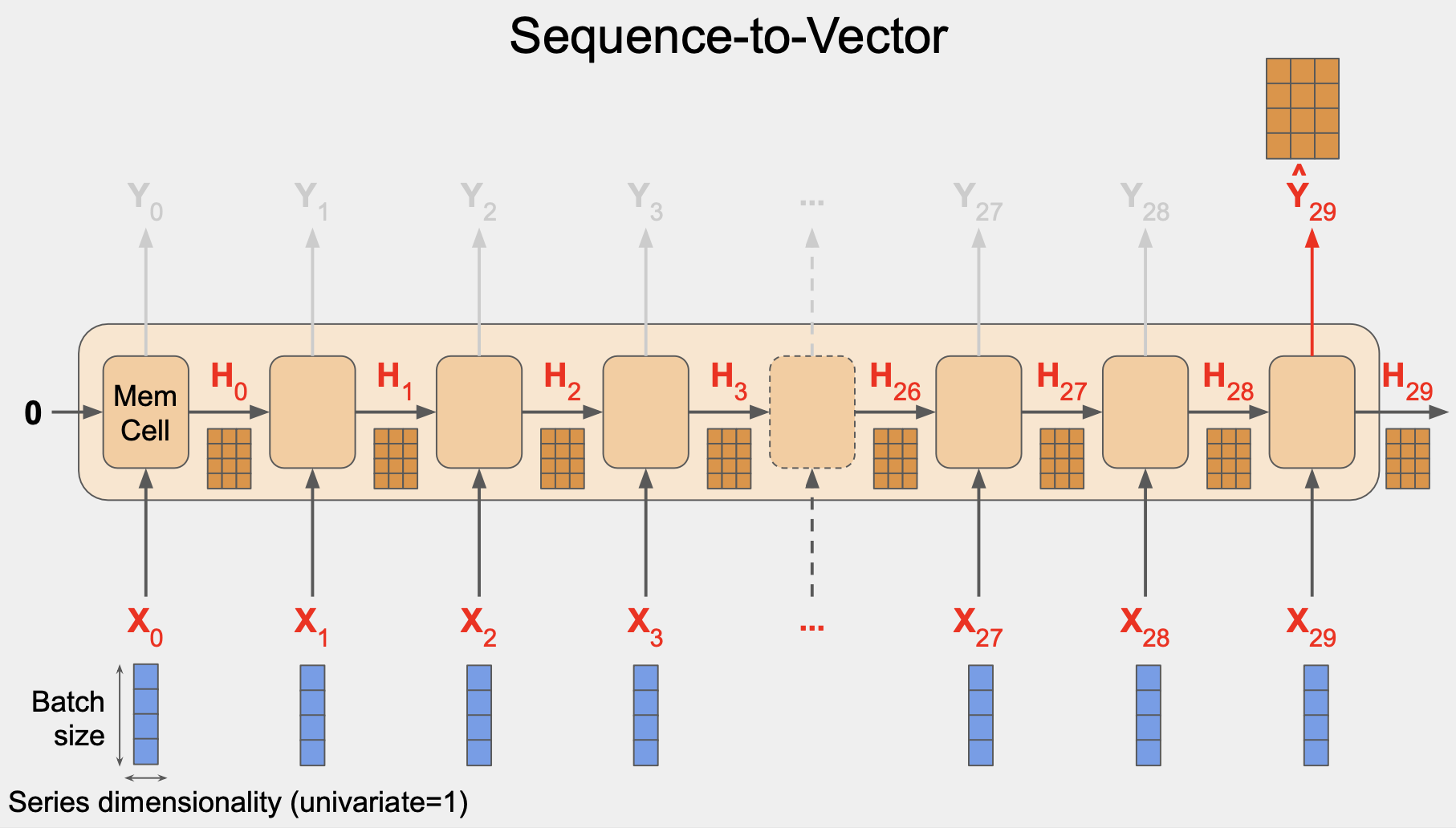
일부 경우에도 시퀀스를 입력하되 출력값의 경우에는 배치 내 각 인스턴스에 대한 단일 벡터를 얻고 싶을 수 있다. 통상 벡터 RNN에 대한 시퀀스라고 부른다.
실제로 하는 일은 마지막을 제외하고는 모든 출력값을 무시하는 것이다. Keras와 Tensorflow를 사용할 때는 이 행동이 기본 값이다.
순환 레이어에서 시퀀스 출력값을 도출하려면 레이어를 생성할 때 return_sequences 를 True로 지정해야 한다.
하나의 RNN 레이어를 다른 레이어 위에 스태킹할 때 이 작업이 꼭 필요하다.
[3] Outputting a sequence (시퀀스 출력)
이 RNN은 순환 레이어가 2개 있다.
첫 번째 설정은 return_sequences=True이다.
다음 레이어에 들어갈 시퀀스가 출력값으로 나오게된다.
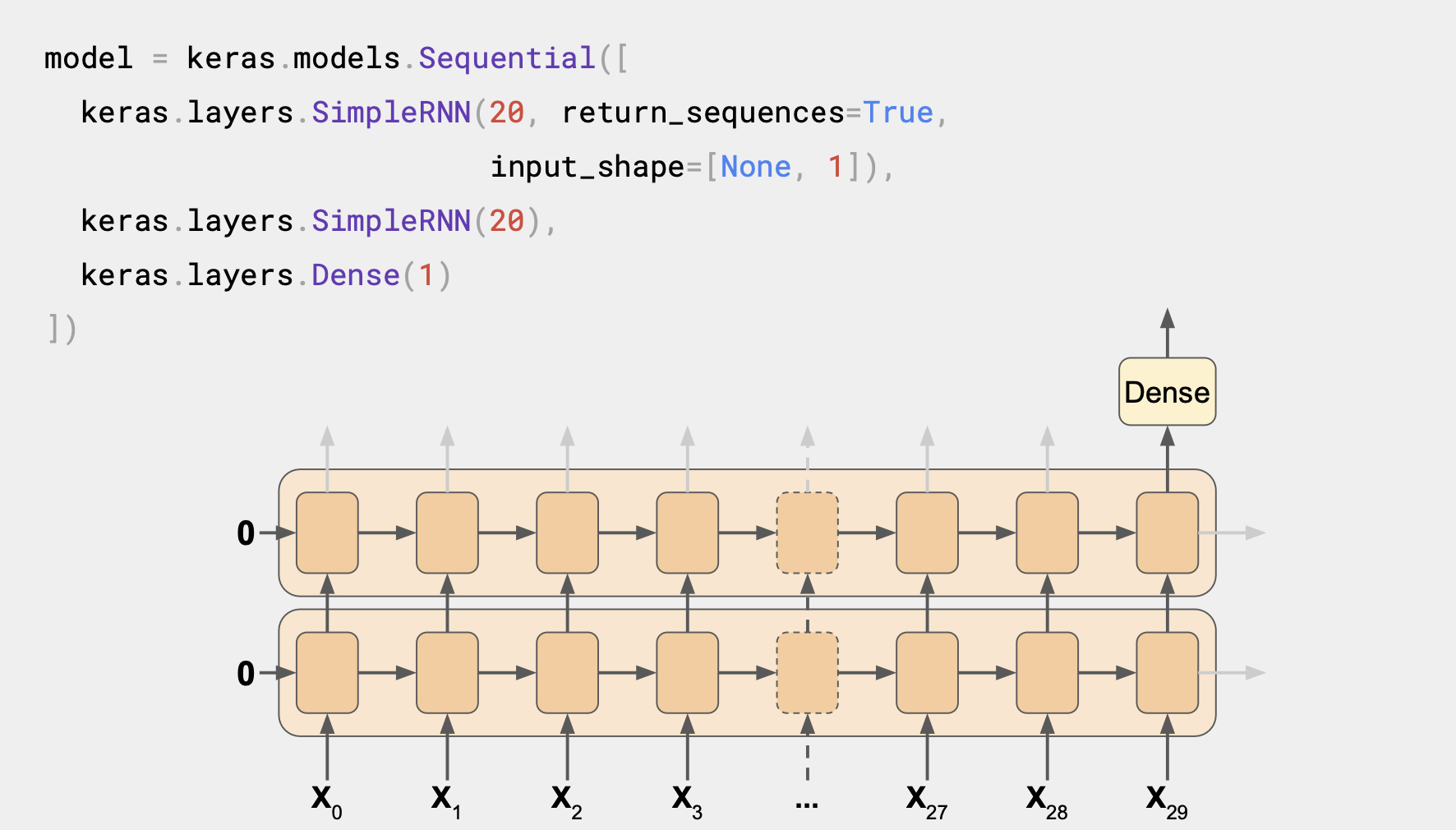
다음 레이어는 return_sequences가 True로 설정된 구문이 없어 마지막 단계의 출력값만 보여준다.
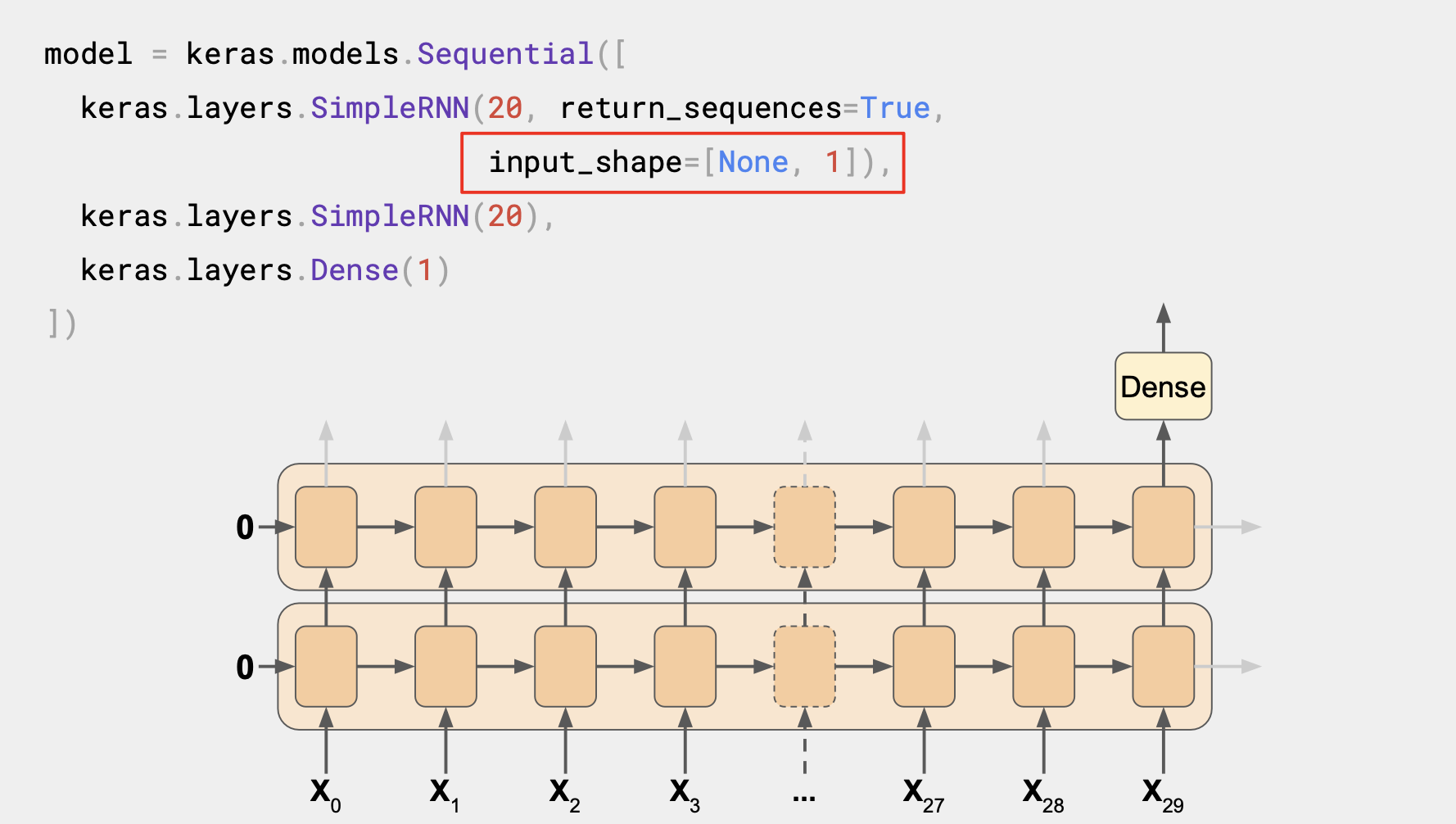
여기서 input_shape가 None과 1로 설정되어 있는데, Tensorflow는 첫 번째 차원을 배치 크기로 추정하는데 이는 어떤 크기든 상관없으니 정의할 필요가 없다.
다음 차원은 시간 단계의 수로 이를 None으로 설정하면, RNN에서 길이와 상관없이 어떤 시퀀스든 다를 수 있다.
마지막 차원이 1로 되어 있는 이유는 일변량 시계열을 다루기 때문이다.
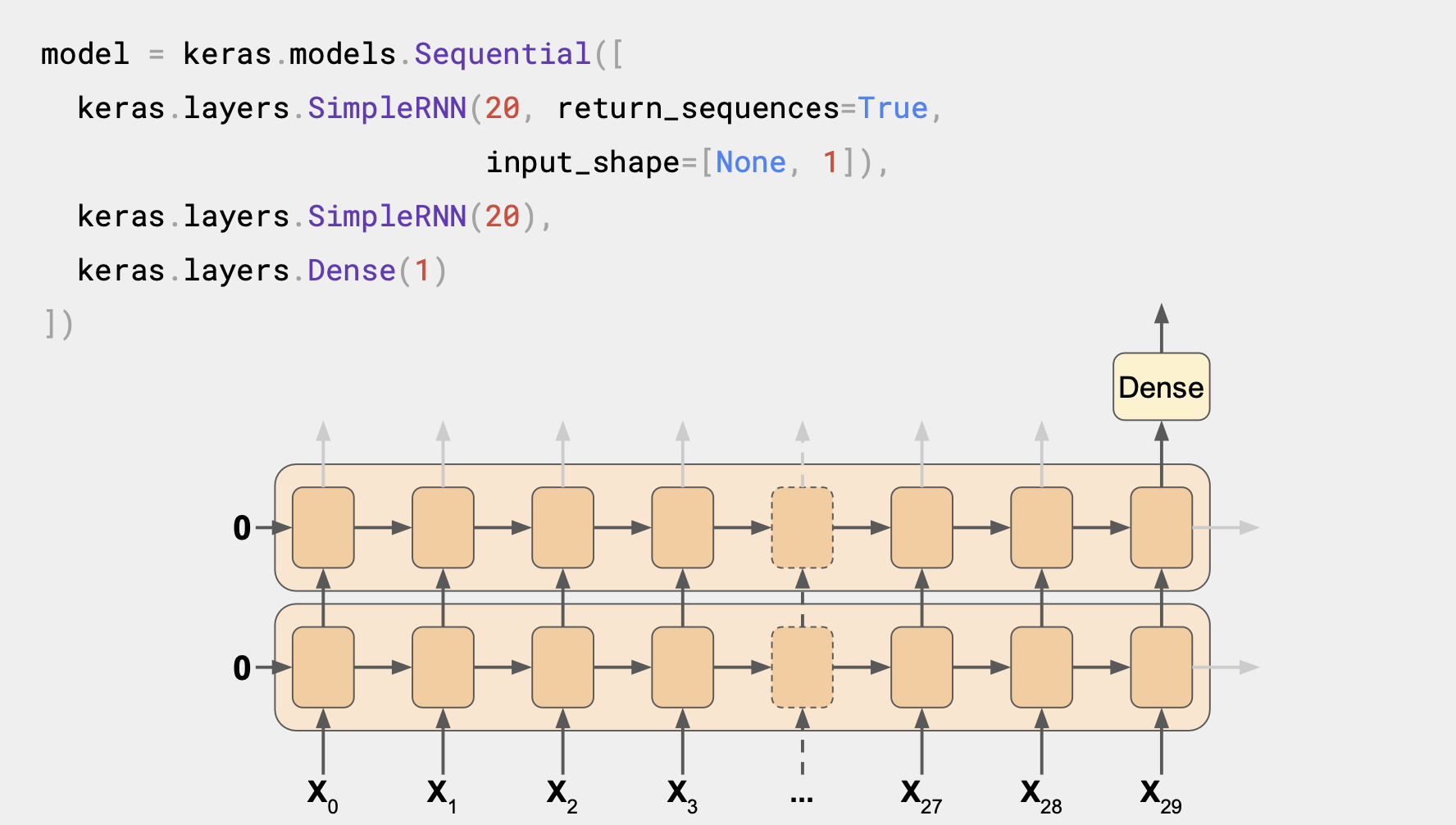
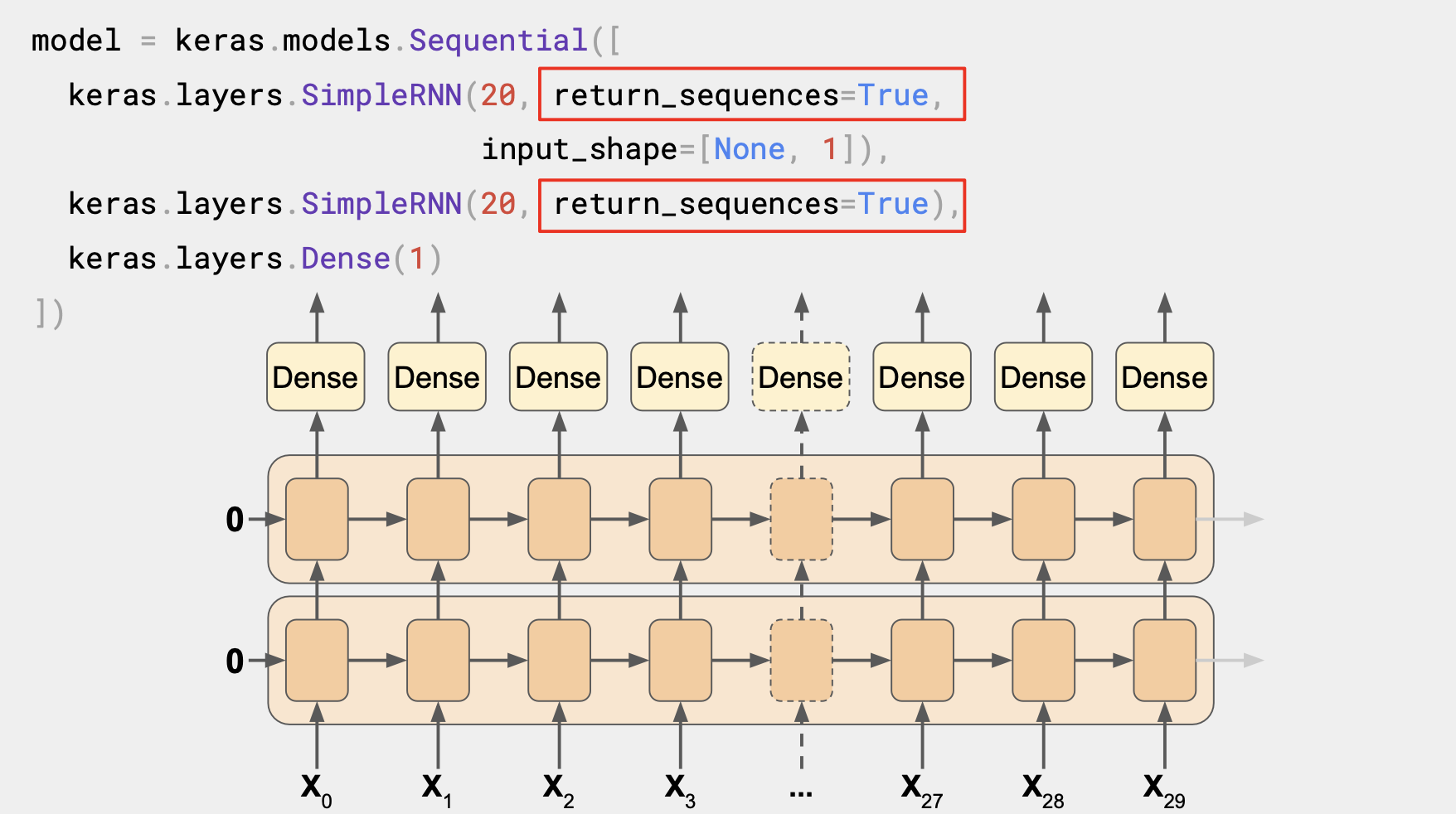
모든 순환 레이어에 return_sequences=True를 설정하면 모두 시퀀스를 출력하고 Dense 레이어에는 시퀀스가 입력된다. Keras는 각 시간 단계별로 동일한 Dense 레이어를 독립적으로 활용한다.
여기서는 여러 개 처럼 보이지만 각 시간 단계는 동일한 레이어가 사용된다. 그래서 시퀀스 투 시퀀스 RNN 이라고 불린다.
이는 시퀀스 배치에 입력되고 동일한 길이의 시퀀스 배치를 반환한다. 차원이 매번 일치하지는 않ㄴ는데, 메모리 셀 내부의 유닛 수에 따라 다르다.
두 번째 레이어에 return_sequences를 설정하지 않은 레이어 2개 RNN에서는 출력값이 단일 Dense 레이어로 나올 것이다.
[4] Lambda layers
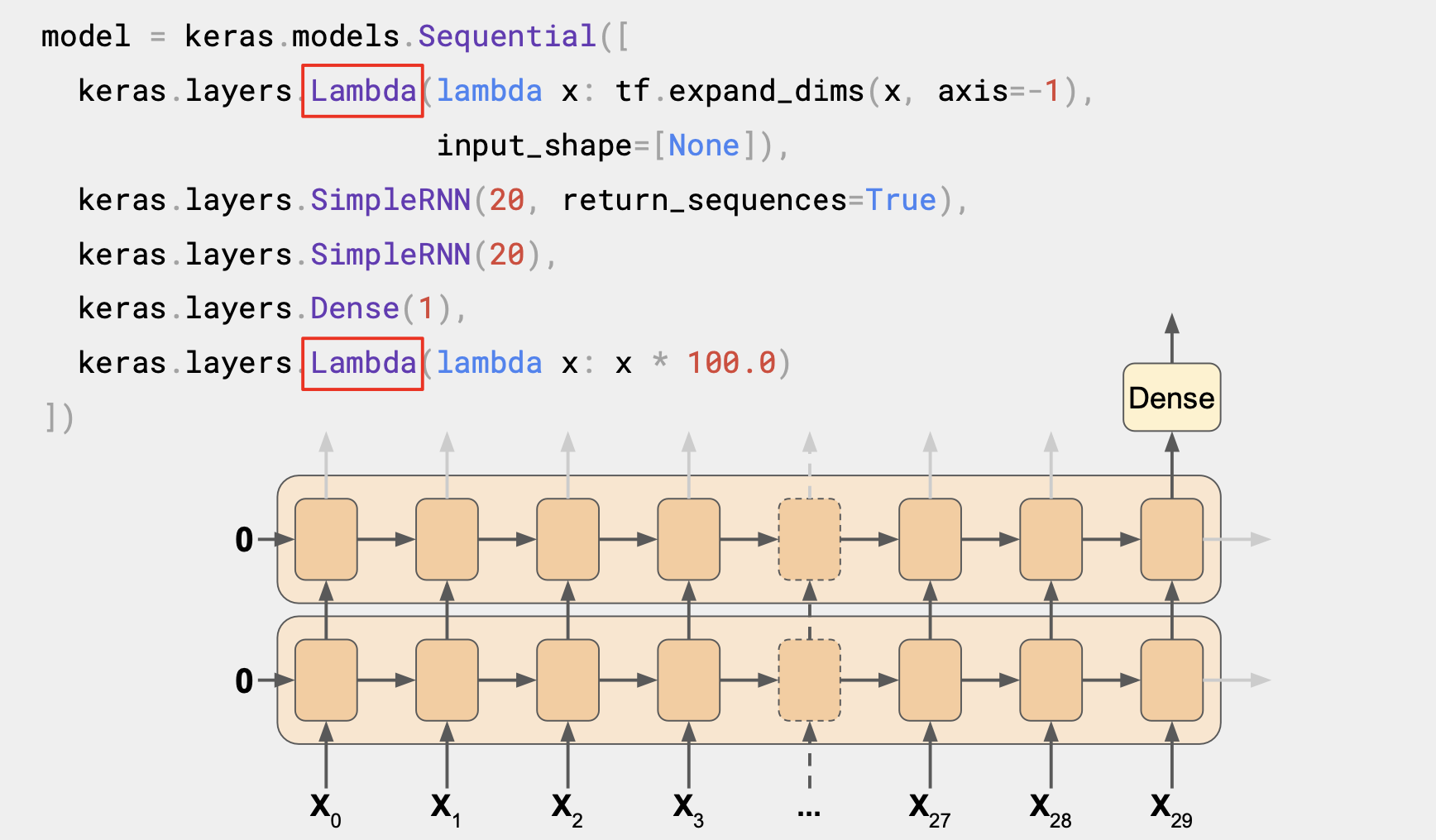
새로운 몇 개의 레이어인 Lambda 유형을 추가해보는데,
이 유형의 레이어는 임의의 운영을 수행할 수 있어서 Tensorflow내 keras의 기능을 확장한다.
모델 정의 자체에서 이를 활용할 수 있다.
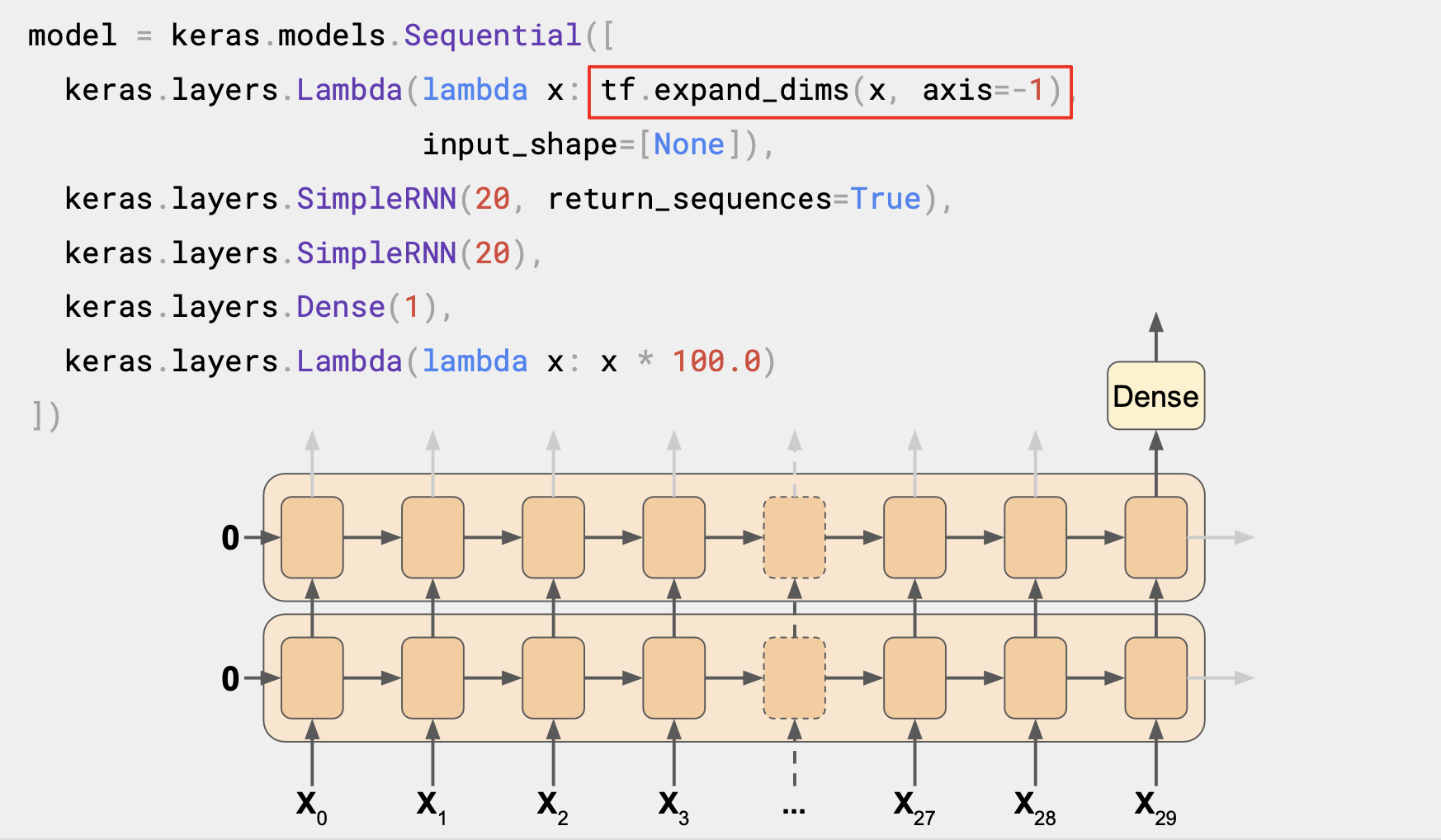
첫 번째 lambda 레이어는 차원 측면에서 도움을 준다.
windowed_dataset의 헬퍼 함수에서는 데이터의 창에 관한 2차원 배치를 반환하고, 첫 번째는 배치 크기 두 번째가 시간 단계의 수였다.
하지만 RNN 은 3차원으로 배치 크기, 시간 단계의 수, 시리즈 차원으로 구성된다.
lambda 레이어를 이용하면 windowed_dataset 헬퍼 함수 없이 배열을 1차원으로 확장할 수 있다.
input_shape 를 None으로 지정하면 이 모델이 길이에 상관없이 시퀀스를 활용할 수 있다.
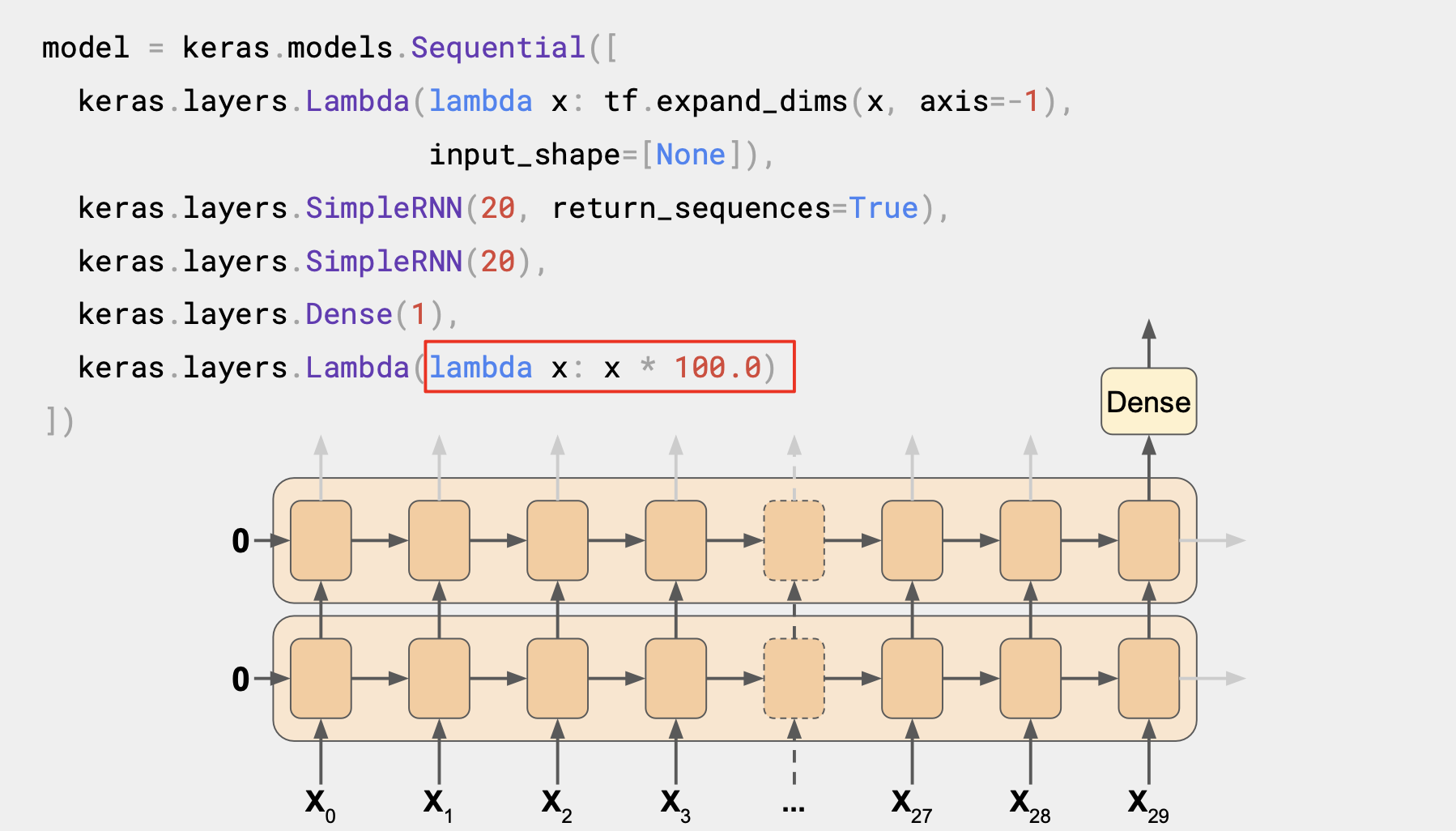
마찬가지로 출력값을 100까지 올리는 것도 훈련에 도움이 된다.
RNN 레이어의 기본 활성화함수는 tanh이다. 쌍곡선 탄젠트 활성화 함수는 출력값이 -1과 1사이이다.
시계열 값은 일반적으로 40, 50, 60, 70개 처럼 10개 단위로 구성되고 비슷한 값으로 출력값을 올리면 학습에 도움이 될 것이다.
lambda 레이어 역시 단순히 100을 곱하면 된다.
전체 RNN 을 구축하는 방법이었다.
[5] Adjusting the learning rate dynamically (학습 속도 동적으로 조정하기)

두 개의 레이어에 각각 40개의 셀이 있다.
학습률을 조정하려면 callback을 설정한다.
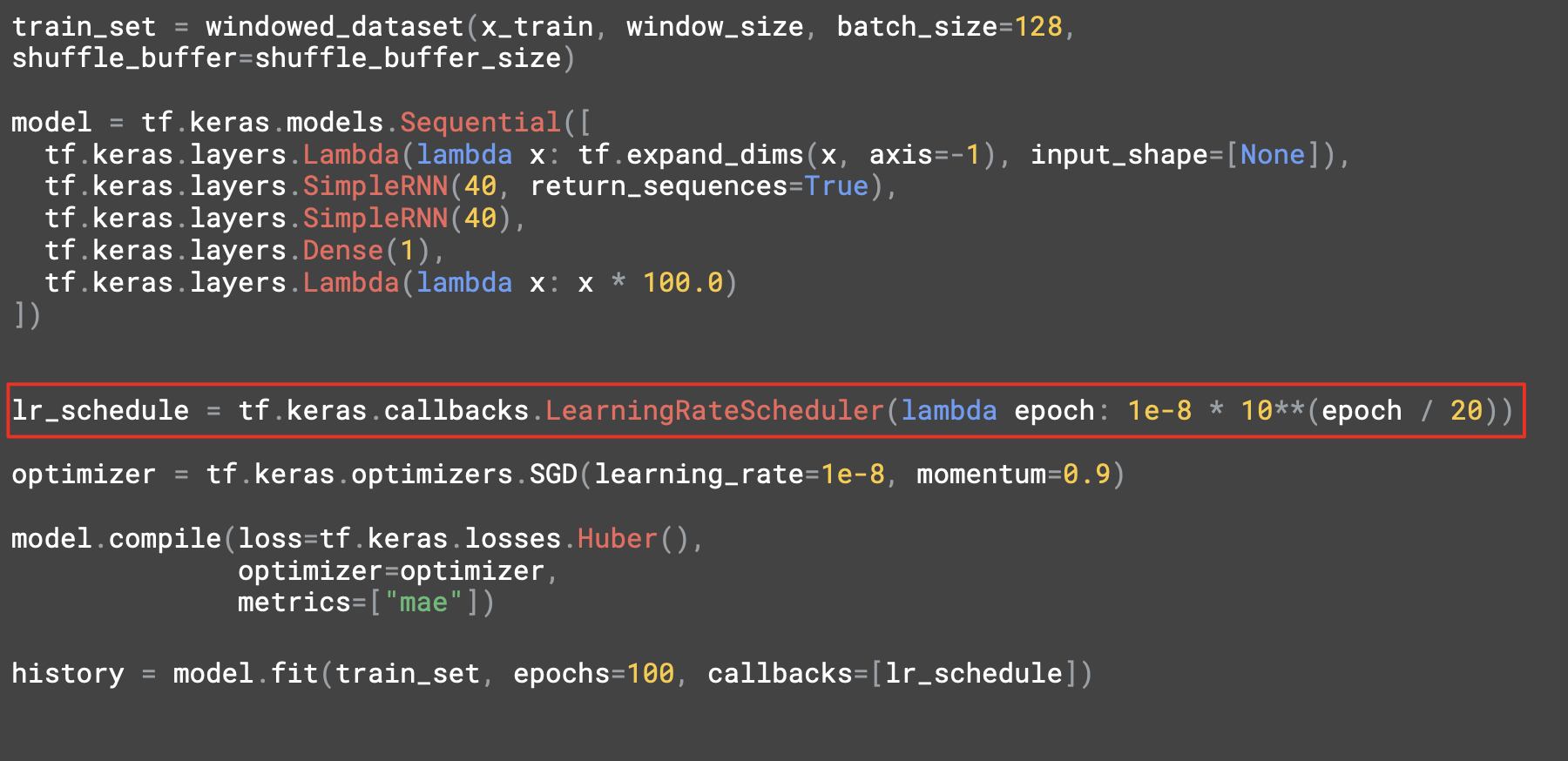
각각의 epoch는 학습률을 약간 변경한다.
훈련동안 그 설정을 확인할 수 있다.
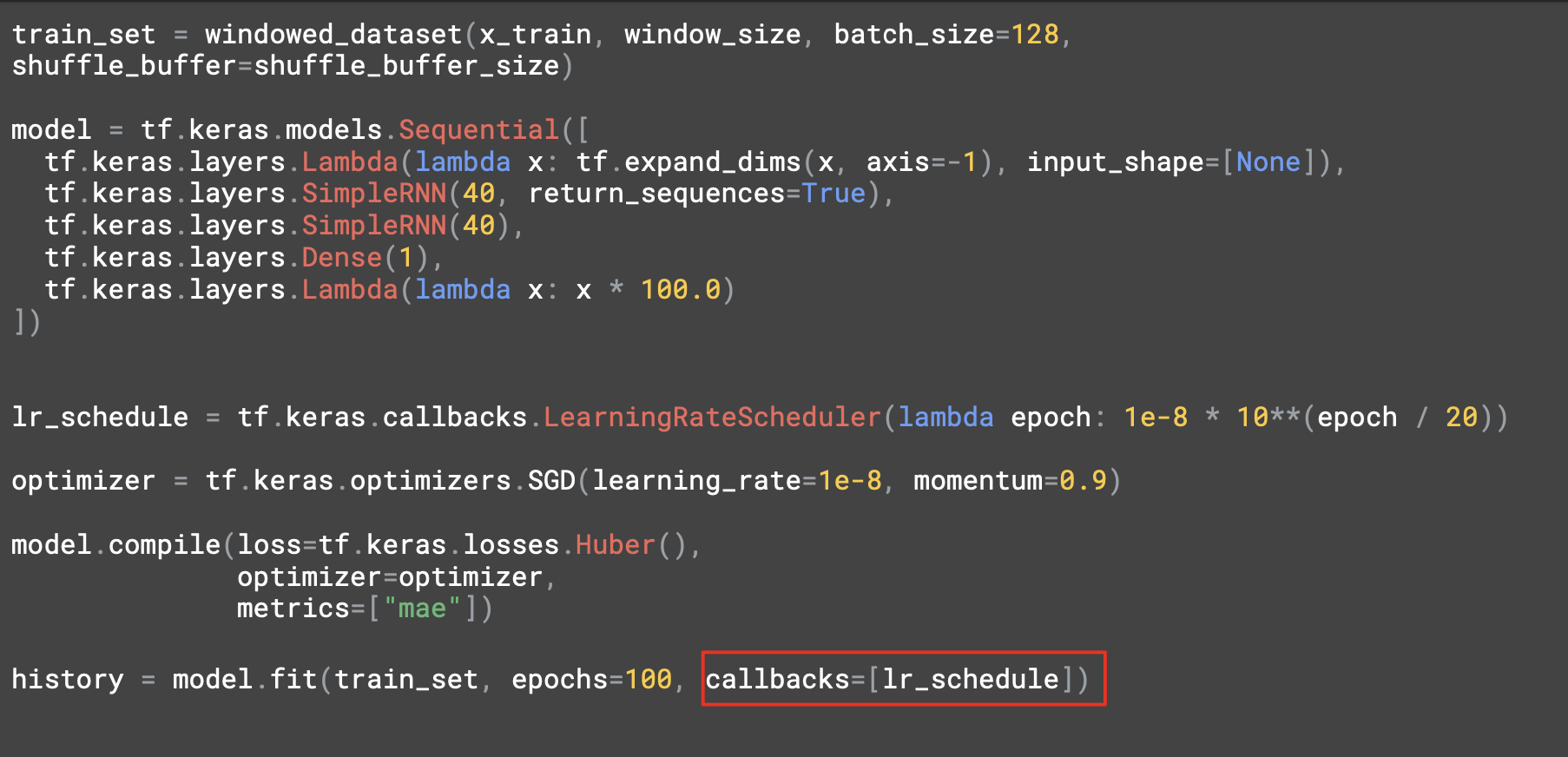
이와 함께 새로운 손실함수인 Huber를 사용하고 있다
Huber는 이상치에 덜 민감하게 반응하는 손실함수이고
이 데이터에 노이즈가 많이 섞여있을 수 있어서 시도해 볼만한다.
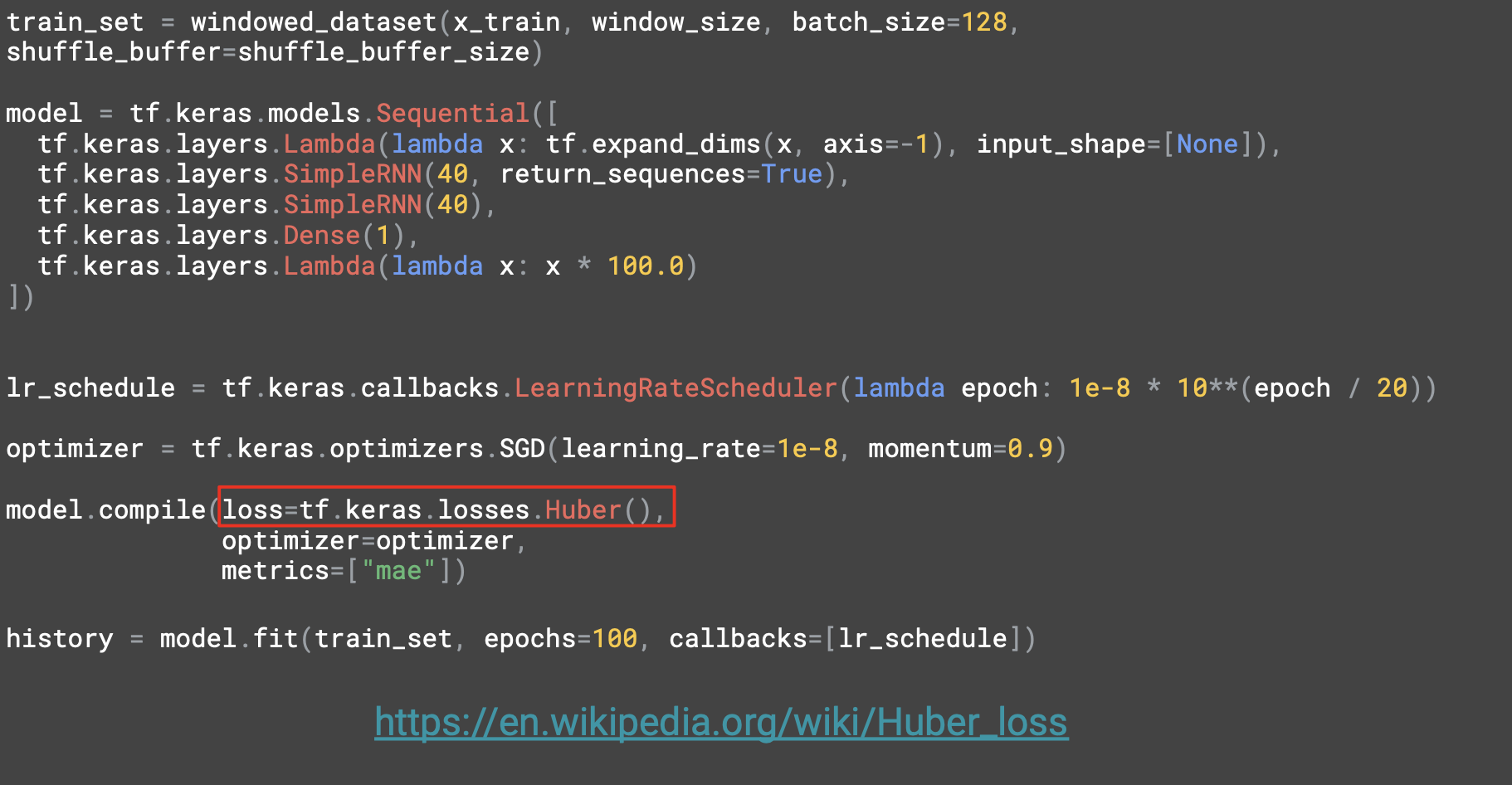
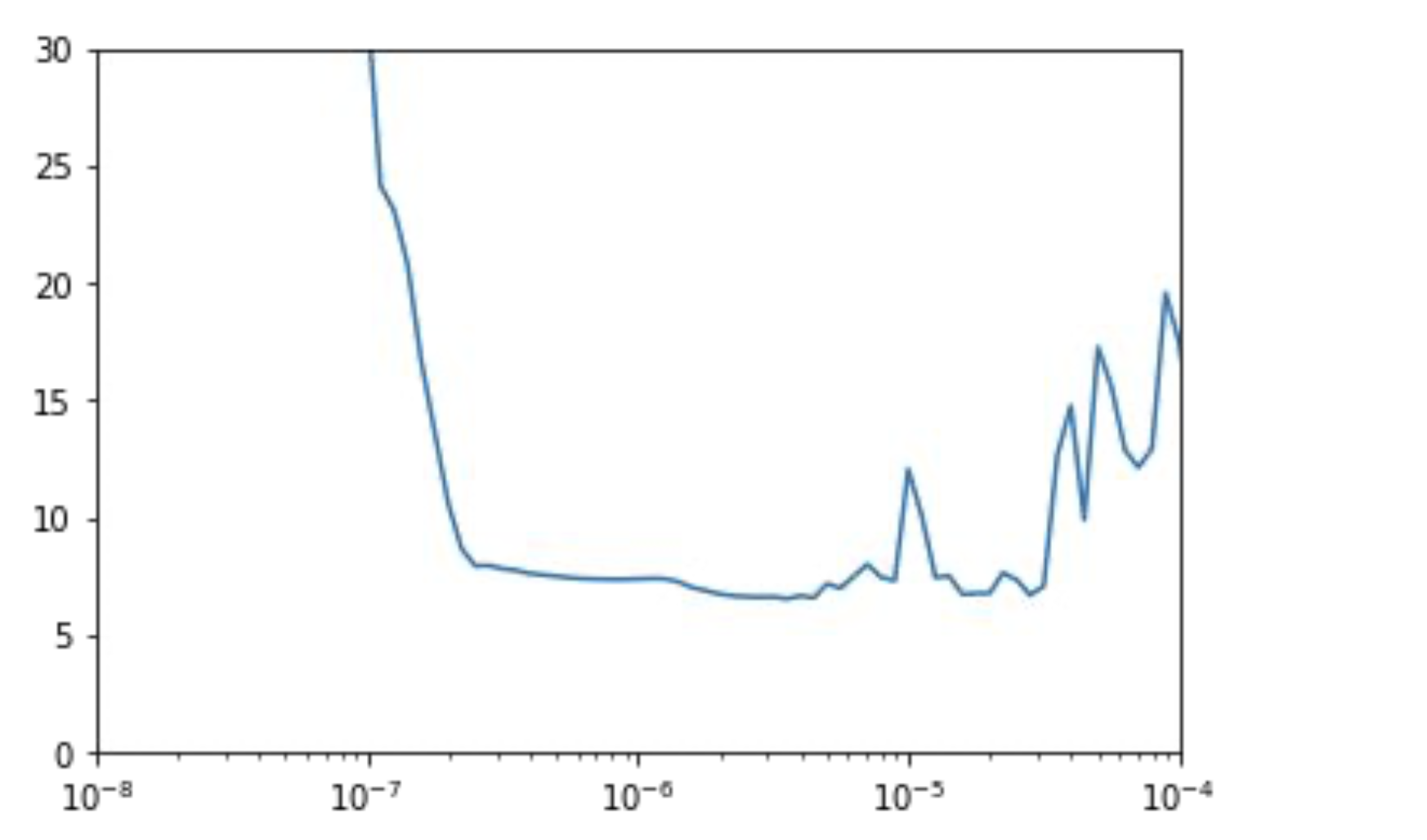
100 epoch 만큼 실행하고, 각 epoch마다 손실을 측정하면 확률적 경사하강법에 의해 최적 학습률은 10^-5 ~ 10^-6 이다.
이 학습률과 확률적 경사 하강법 옵티마이저로 컴파일한 모델을 설정해보자.
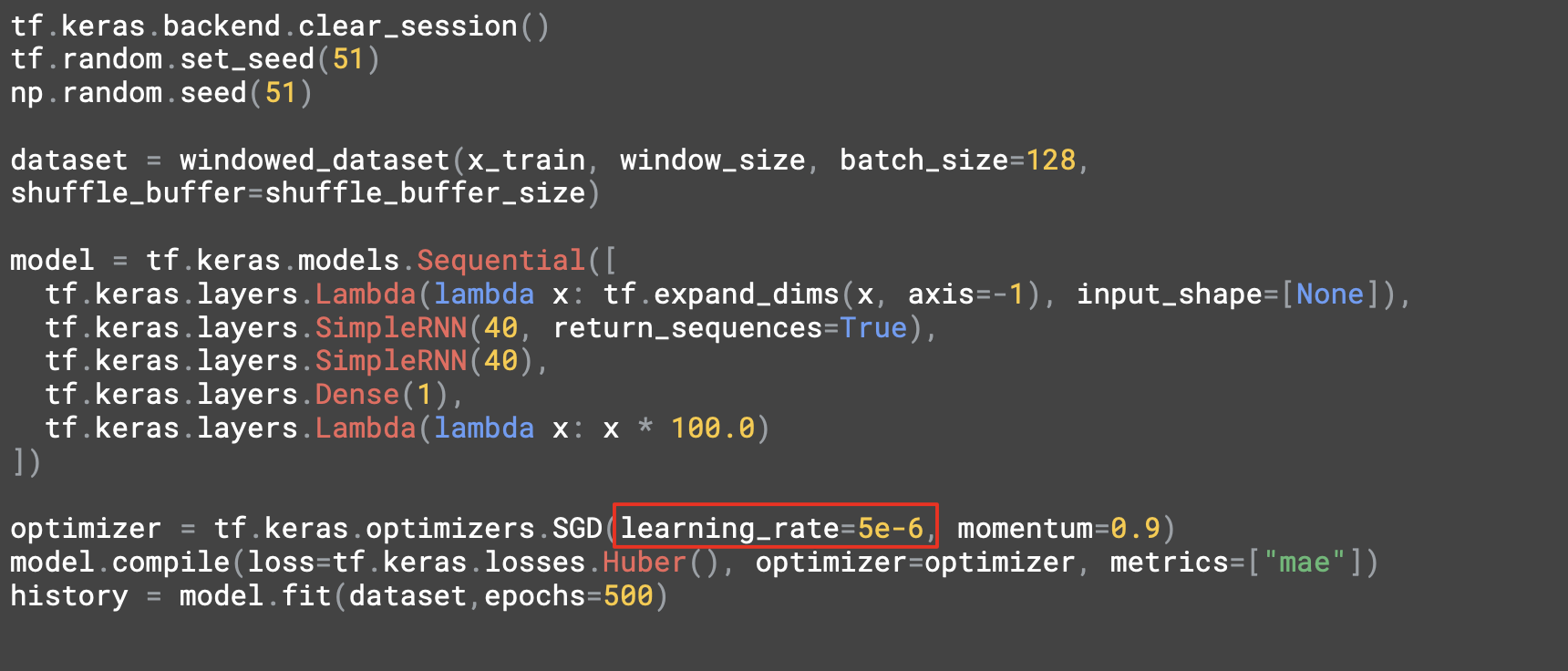
500 epoch 훈련 후에 이러한 차트가 나왔는데,
검증 세트에서의 MAE는 6.35가 나왔다.
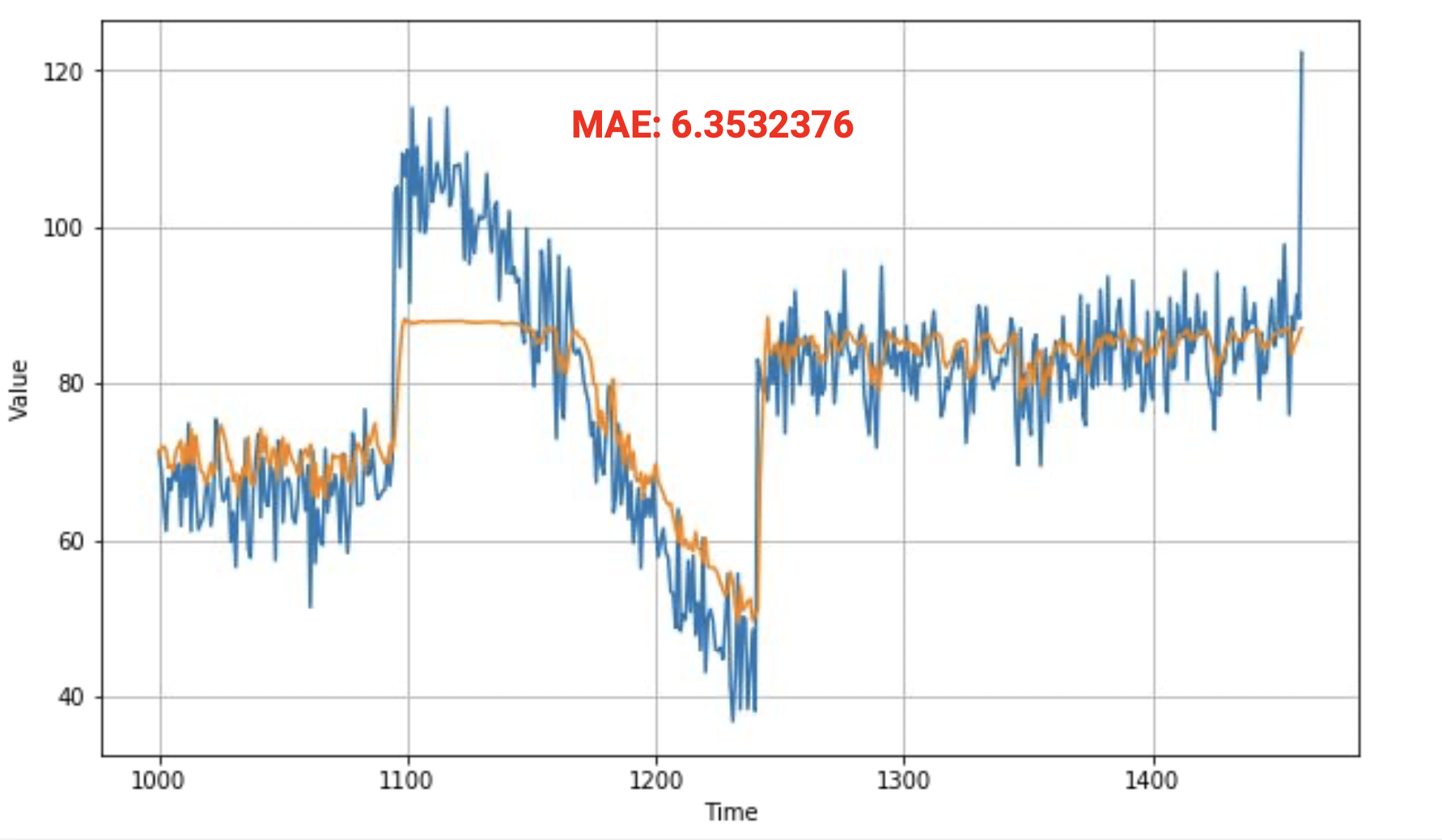
훈련 도중의 손실과 MAE는 다음과 같이 나타났는데 ,
오른쪽에 있는 차트는 마지막 몇 개의 epoch를 확대하는 것이다.
추세는 전반적으로 하강하다가 400 epoch에서 얼마지나지 않아 불안정해 지기 시작한다.
이 점을 감안하면 400 epoch만 훈련해도 될 것 이다.
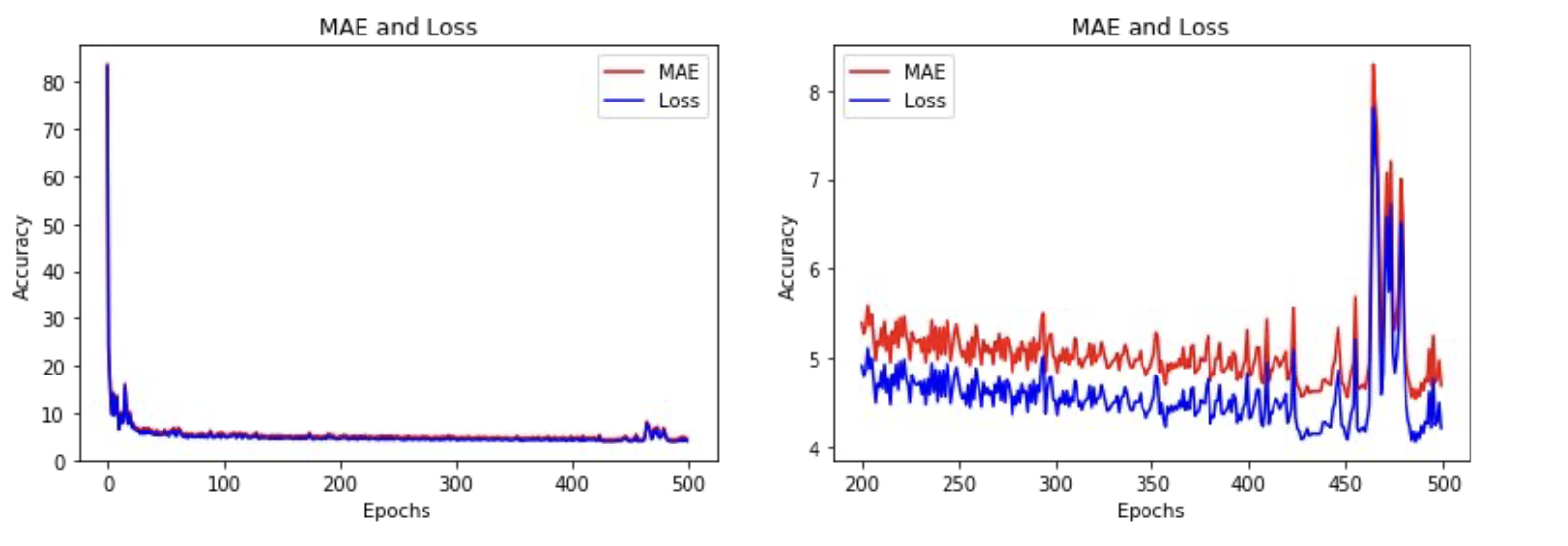
이렇게 400 epoch를 훈련하면 이러한 결과가 나오게 되고 MAE만 살짝 커졌다.
100 epoch를 더 훈련하지 않아도 같은 결과를 얻어냈으므로 마땅한 가치가 있다.
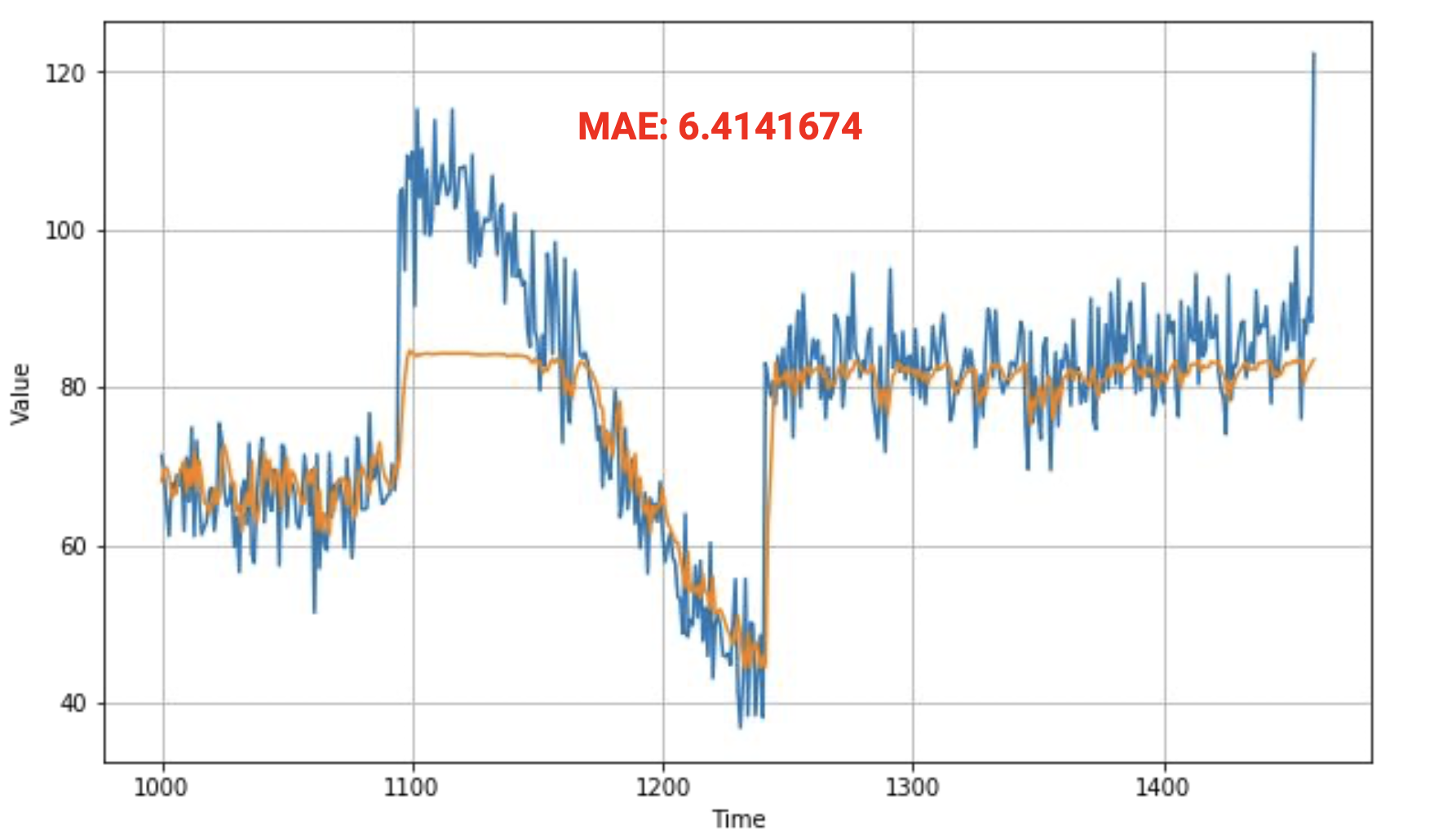
훈련 세트의 MAE 와 loss는 다음과 같다.
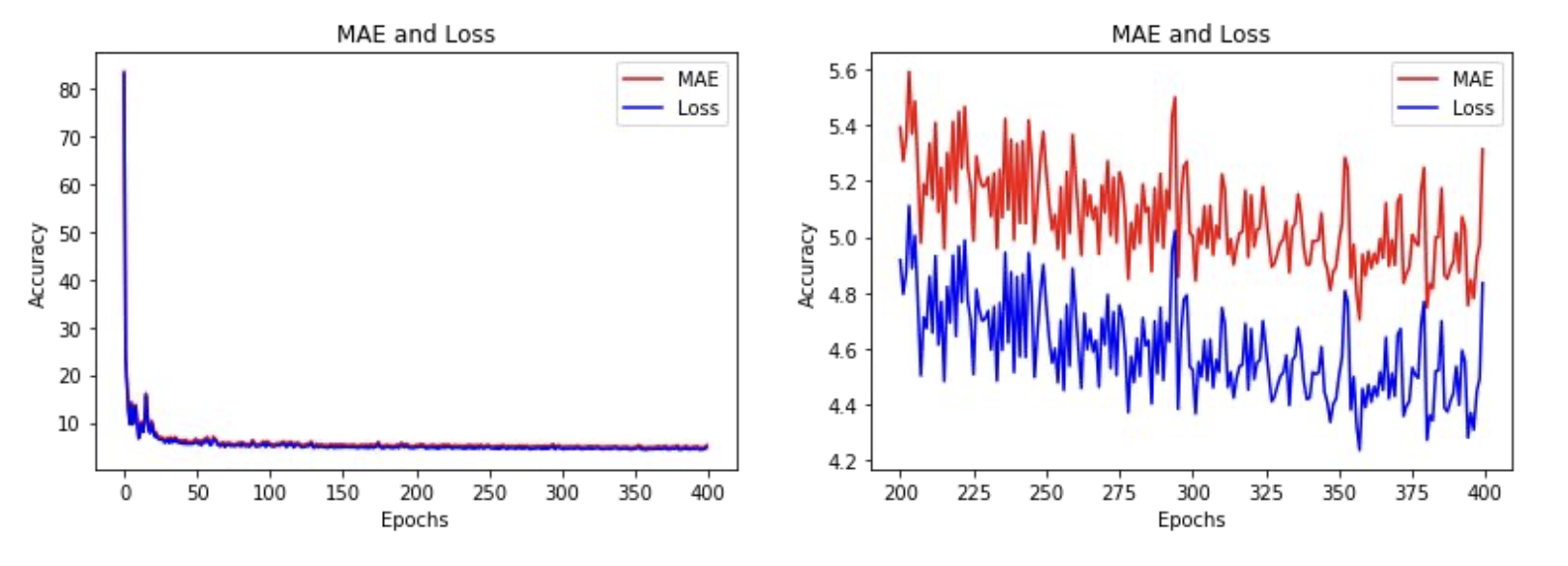
위는 간단한 RNN을 사용한 것이다.
[6] More info on Huber loss
https://en.wikipedia.org/wiki/Huber_loss
[7] LSTM
RNN대신 LSTM 을 사용하면 더 좋은 결과가 나올 수 있다.
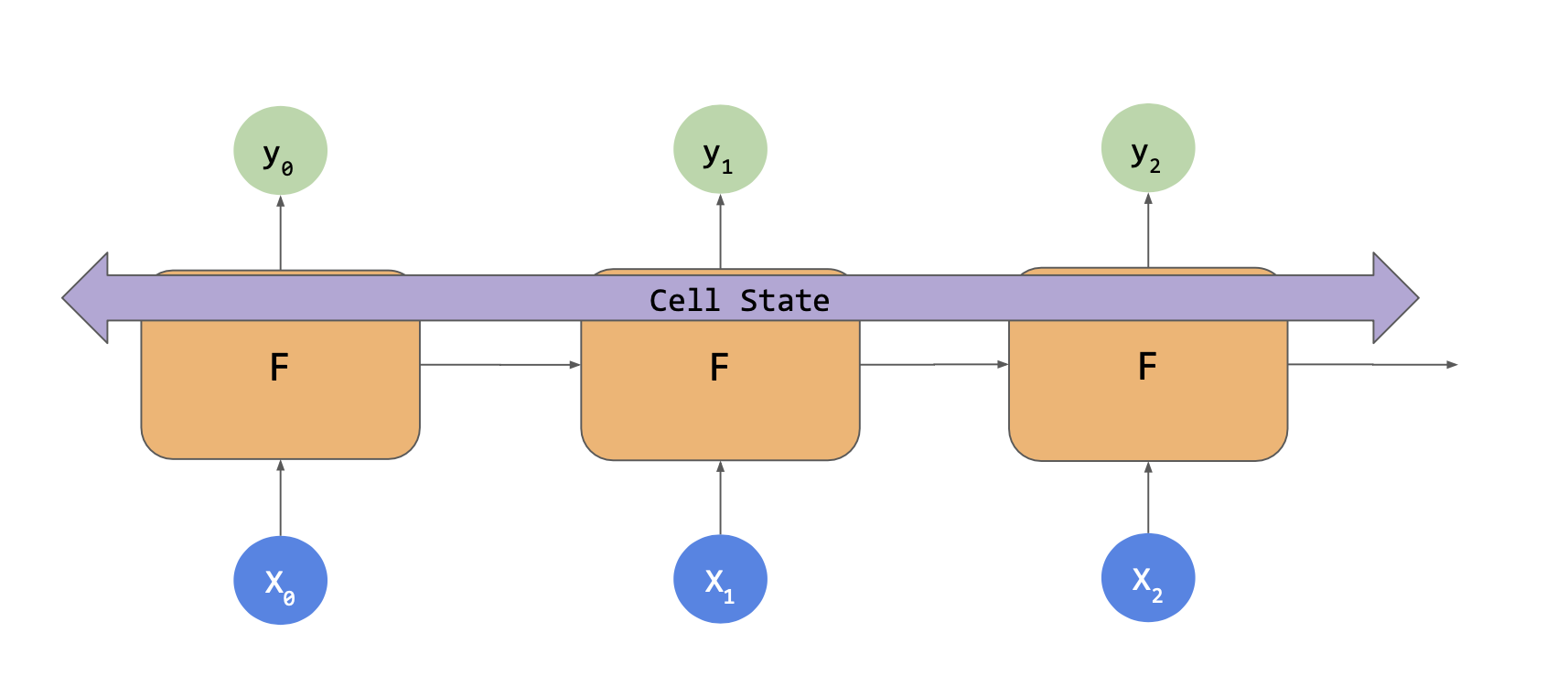
RNN을 사용했을 때를 생각하면 위와 같이 입력값이나 X로 매칭하는 셀이 있고, 여기서 출력값 Y와 상태 벡터를 계산한다.
다음 X와 함께 셀에 들어가서 Y가 나오고 상태 벡터가 나오는 식이다. 그 영향을 살펴보면 상태는 이후의 계산식에 들어가는 요인이지만 시간 단계가 지나면서 영향이 크게 줄어든다.

LSTM은 전체 훈련 기간 동안 이 상태를 유지해주는 셀 상태를 추가한다. 그래서 상태가 셀 간에 이동을 하고 시간 단계 사이를 이동하면서 더 잘 유지될 수 있다.
앞서 창에 있는 데이터가 RNN 보다 전체 추정치에 더 큰 영향을 미칠 수 있다는 뜻이다.
또한 상태는 양방향으로 움직일 수 있어서 앞과 뒤로 움직일 수 있다.
https://www.coursera.org/lecture/nlp-sequence-models/long-short-term-memory-lstm-KXoay
LSTM에 대한 강의
LSTM 관련 코드

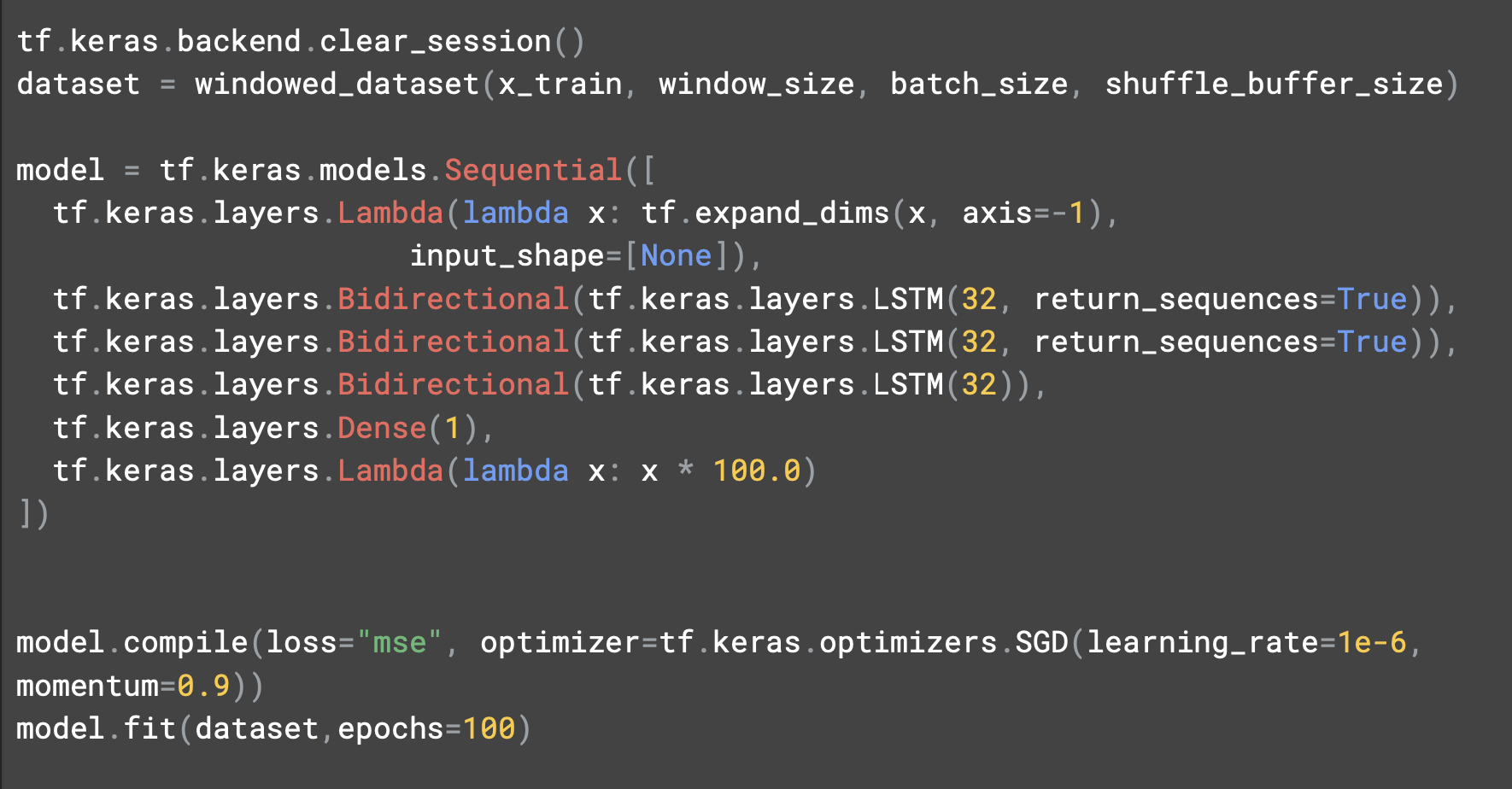
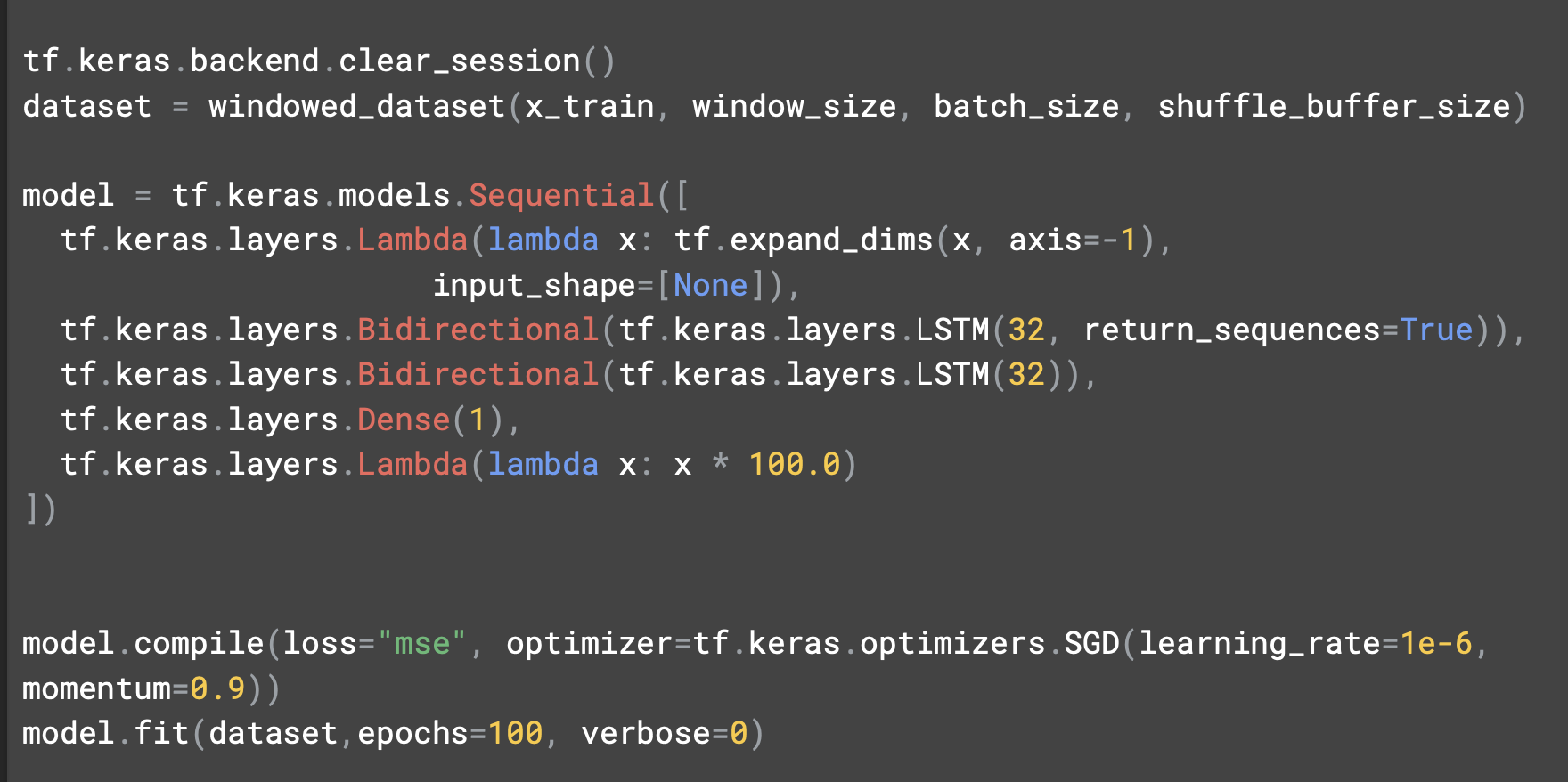
tf.keras.backend.clear_session은 내부 변수를 깔끔하게 초기화해주는 코드로, 이후 버전에 영향을 주지 않고 여러 모델을 시험해볼 수 있다.
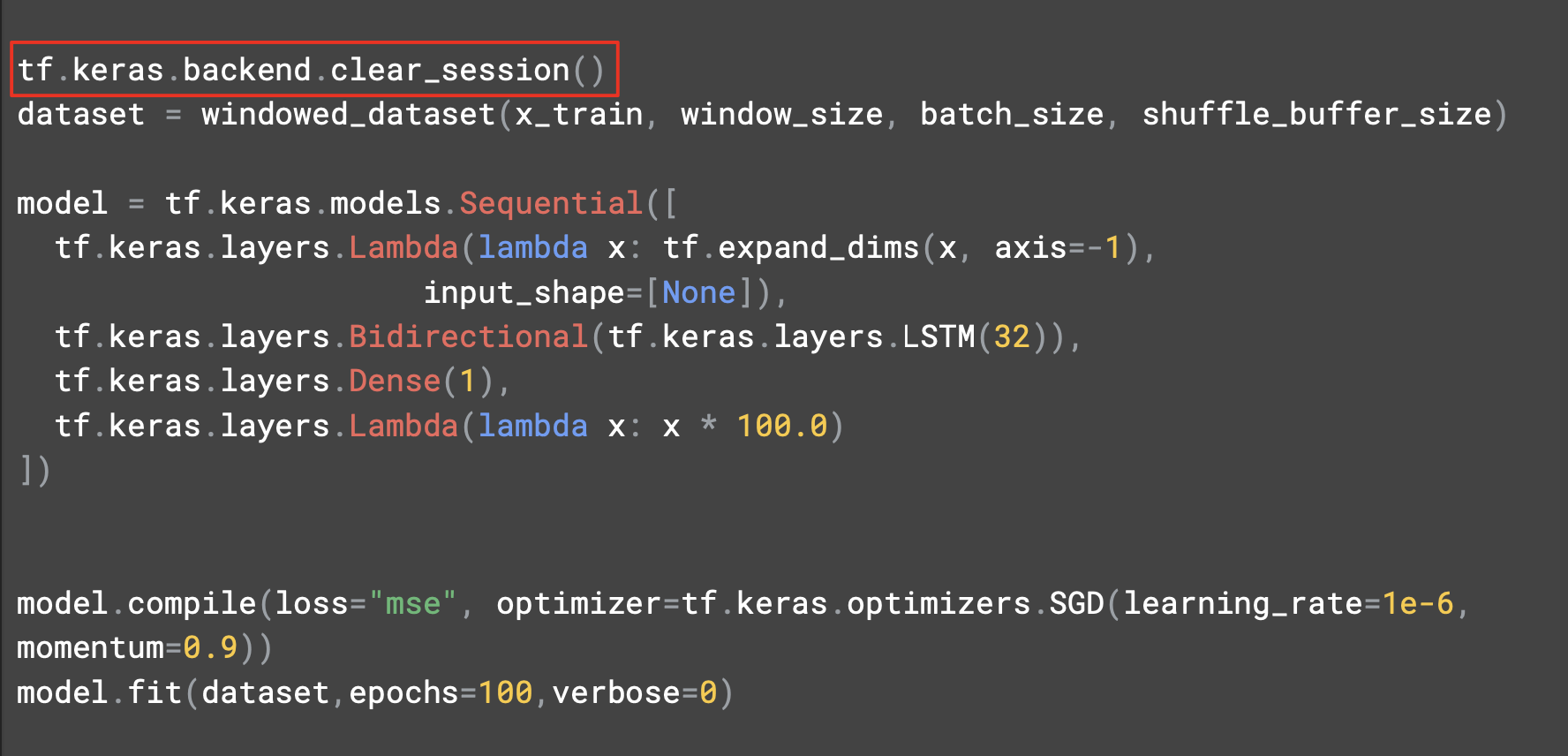
차원을 확장해주는 lambda 레이어 다음에는 32개의 셀을 갖춘 단일 LSTM레이어를 추가했다.
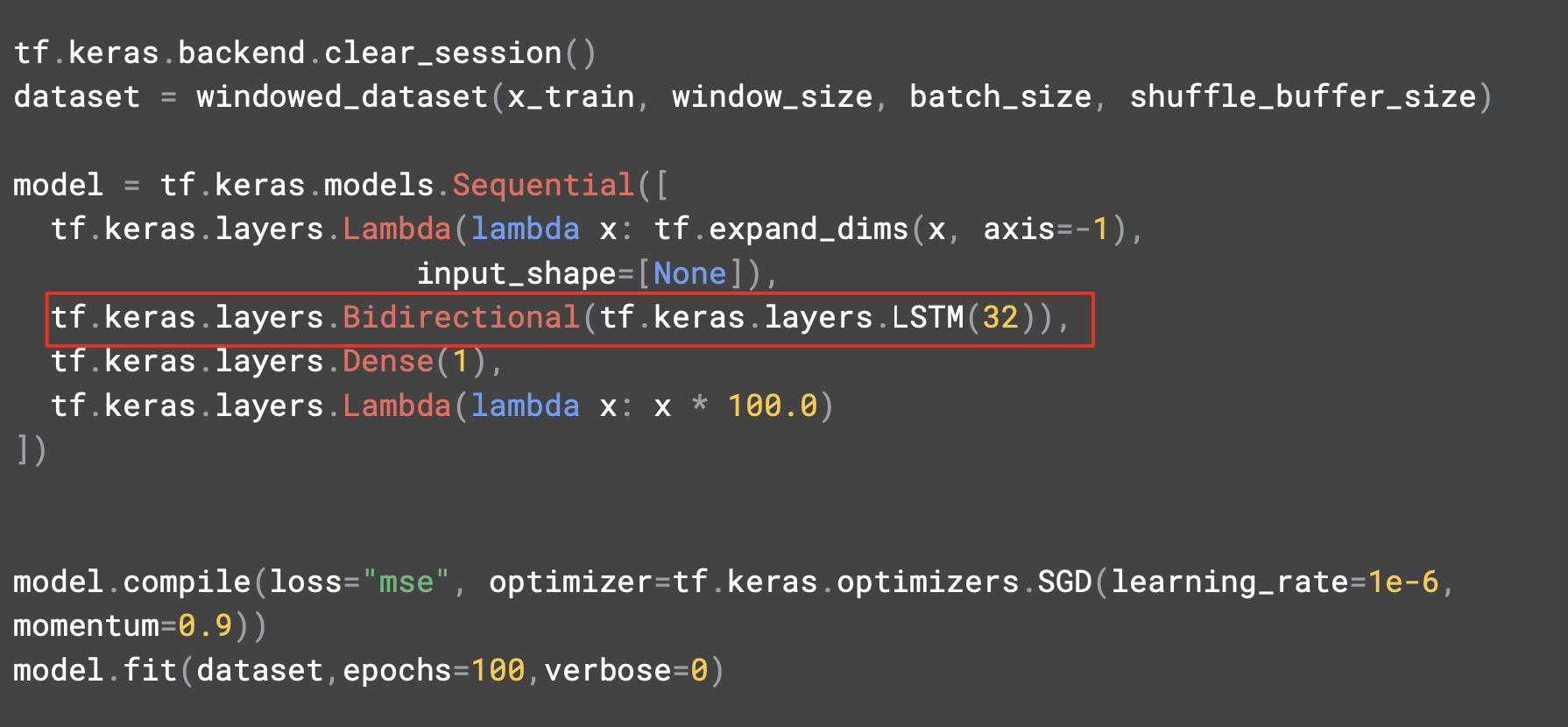
예측에 미치는 영향을 파악할 수 있도록 양방향으로 만들었다.
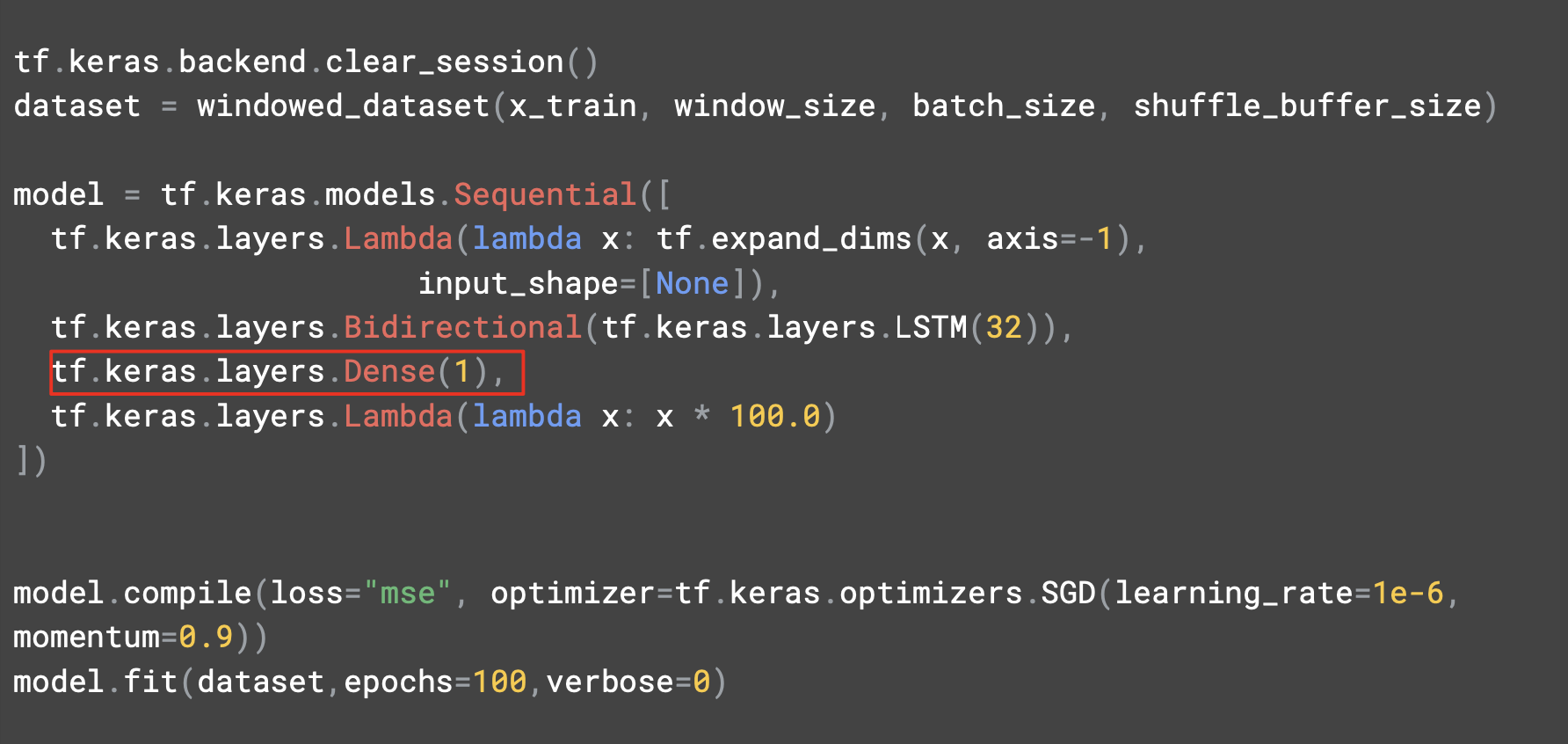
출력 뉴런이 예측값을 제시할 것이다.
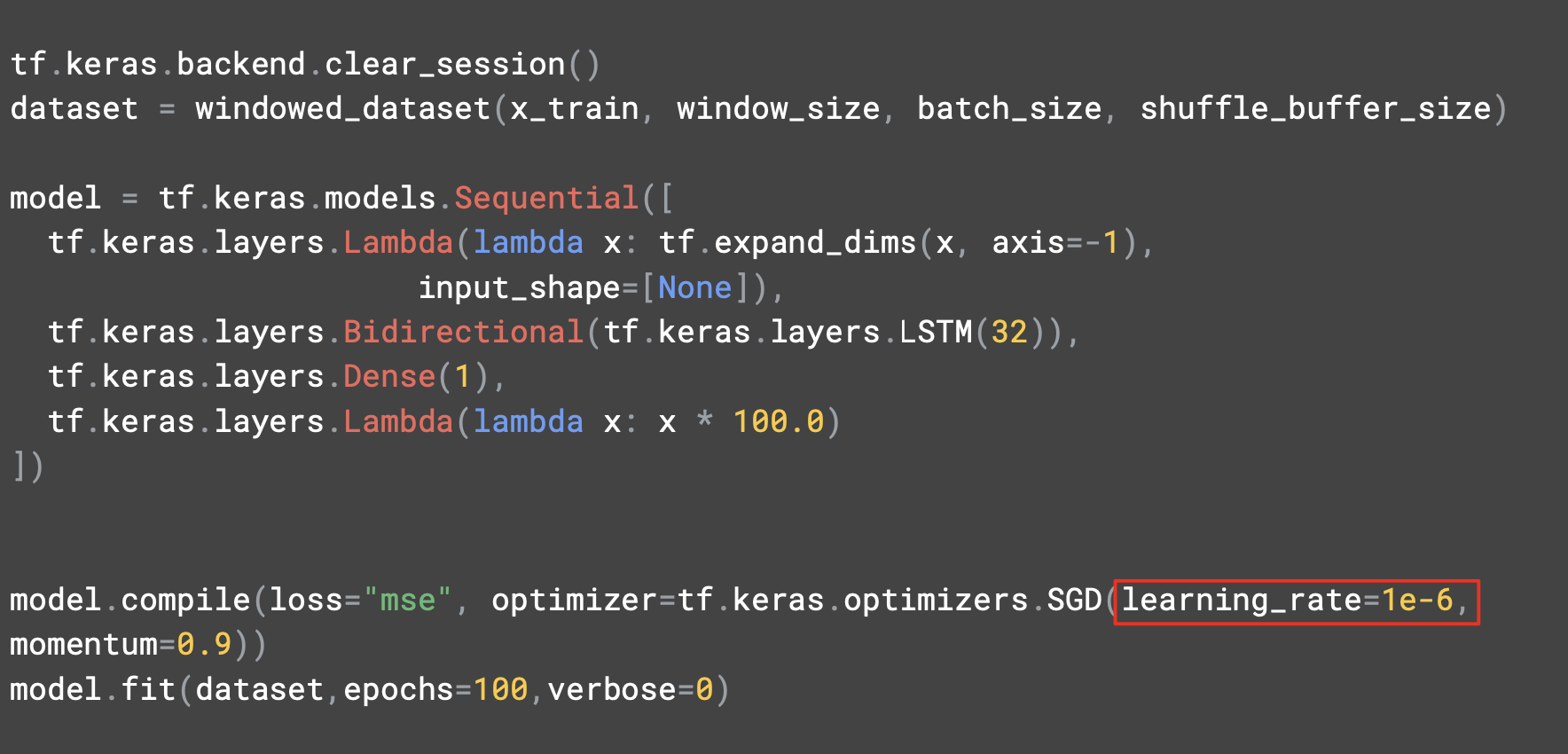
학습률은 1e^-6이다.
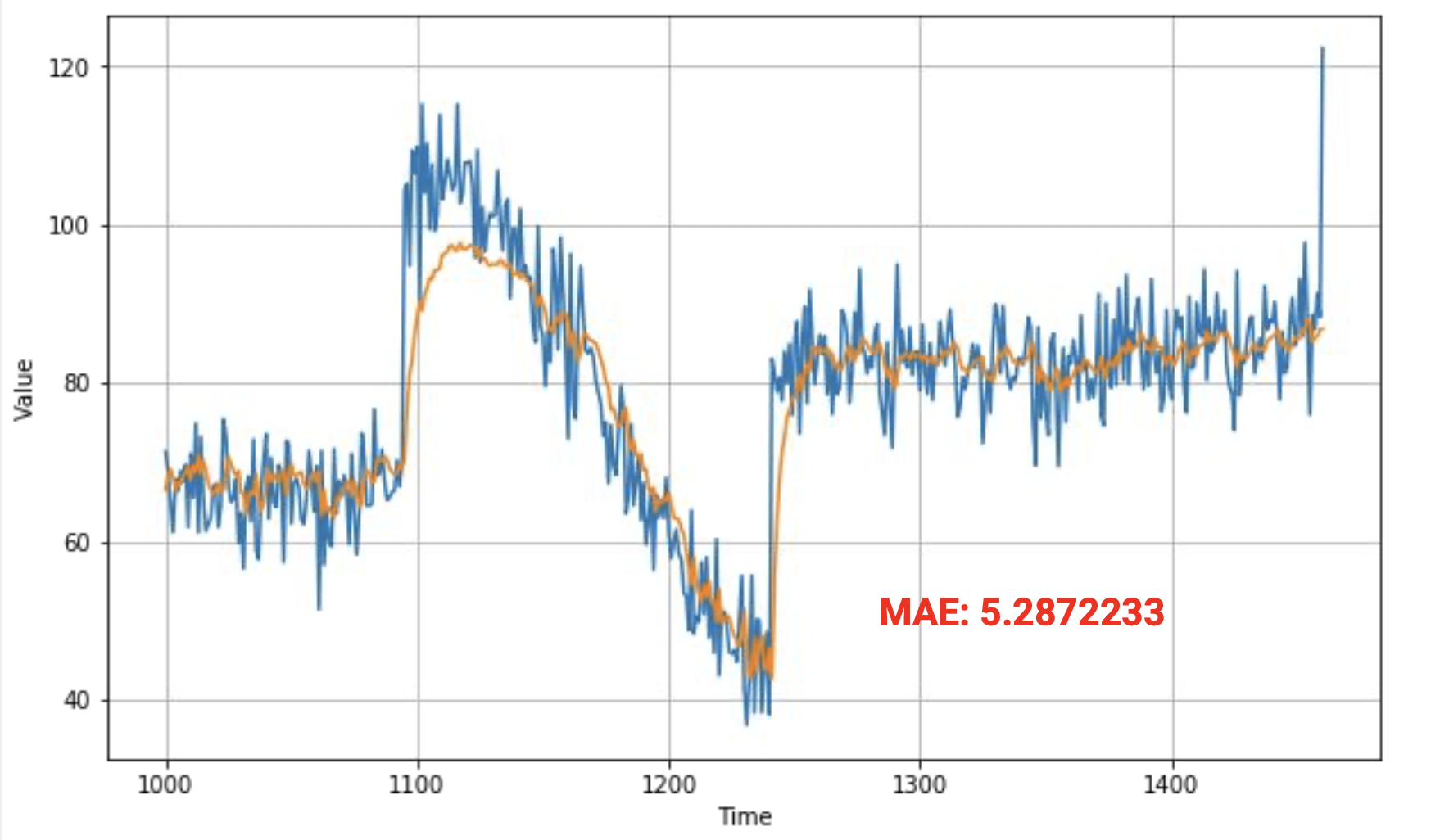
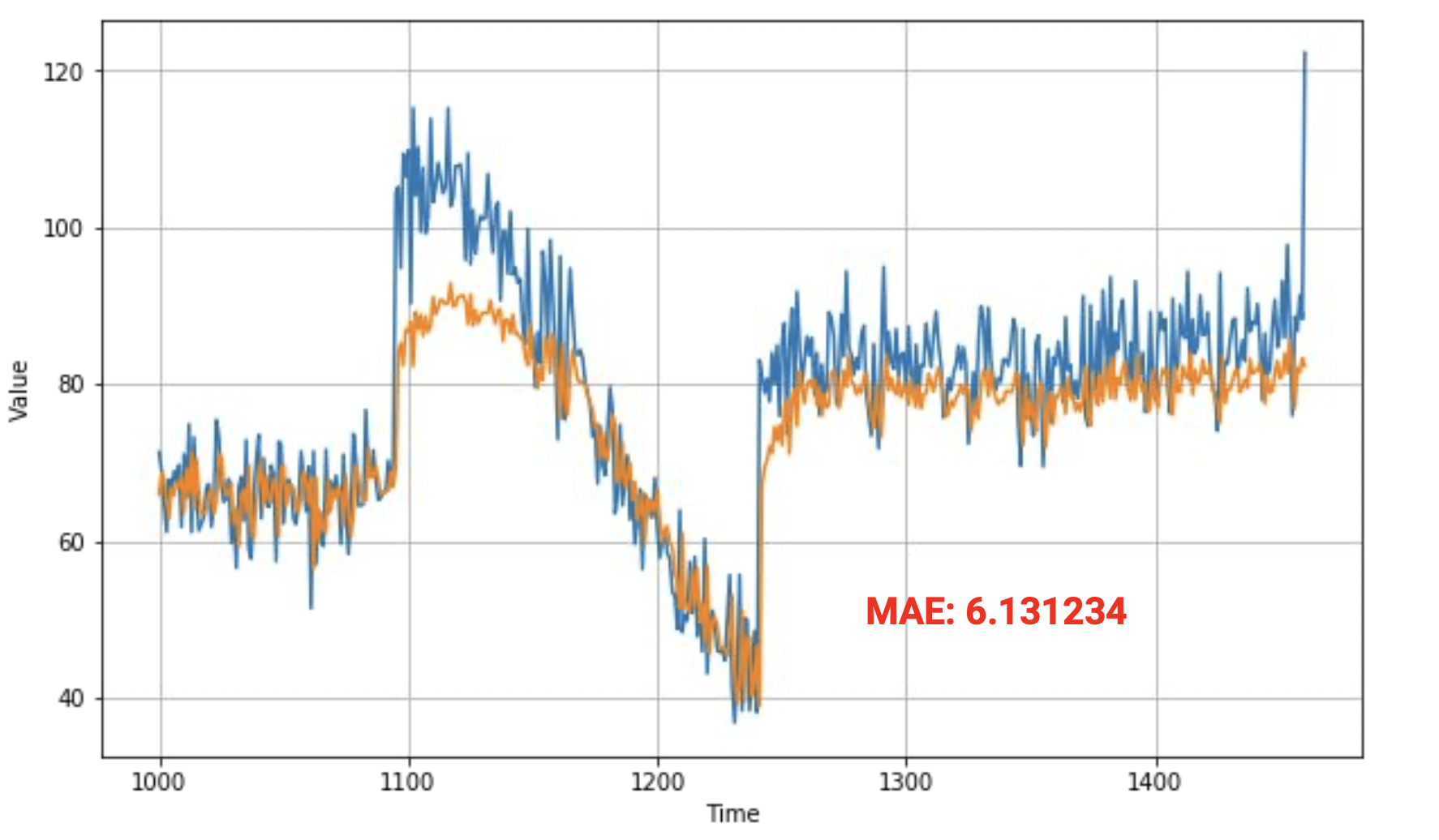
아래 그림에서 솟아오르는 부분이 있고 MAE도 6으로 좋지도 나쁘지도 않은 상태이다.
예측치를 보면 낮은 부분이 있어 보인다.
코드를 좀 더 수정해서 다른 LSTM의 영향을 살펴보자.
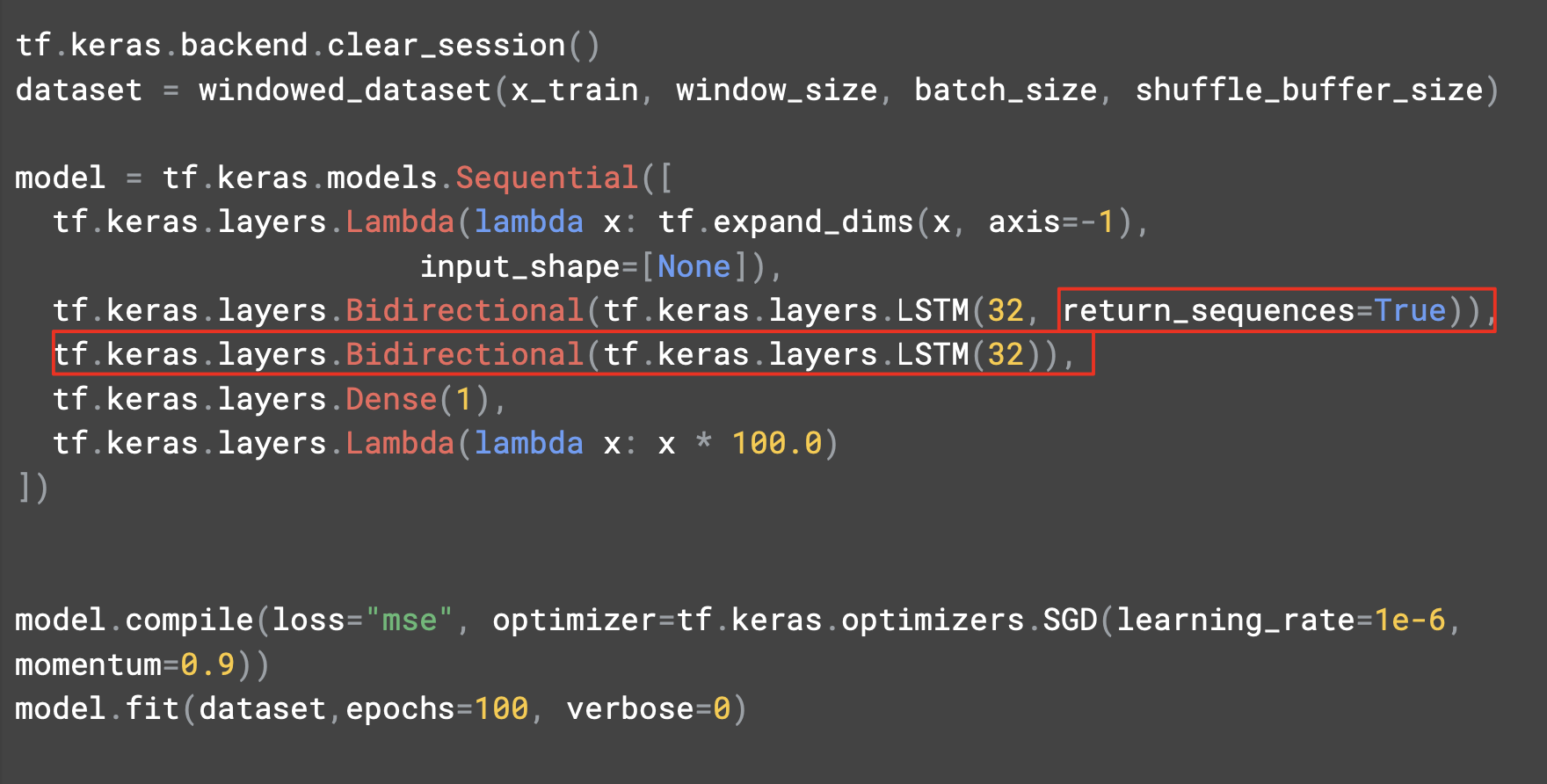
두 번째 레이어로 return_seqeunces를 True로 설정한다.
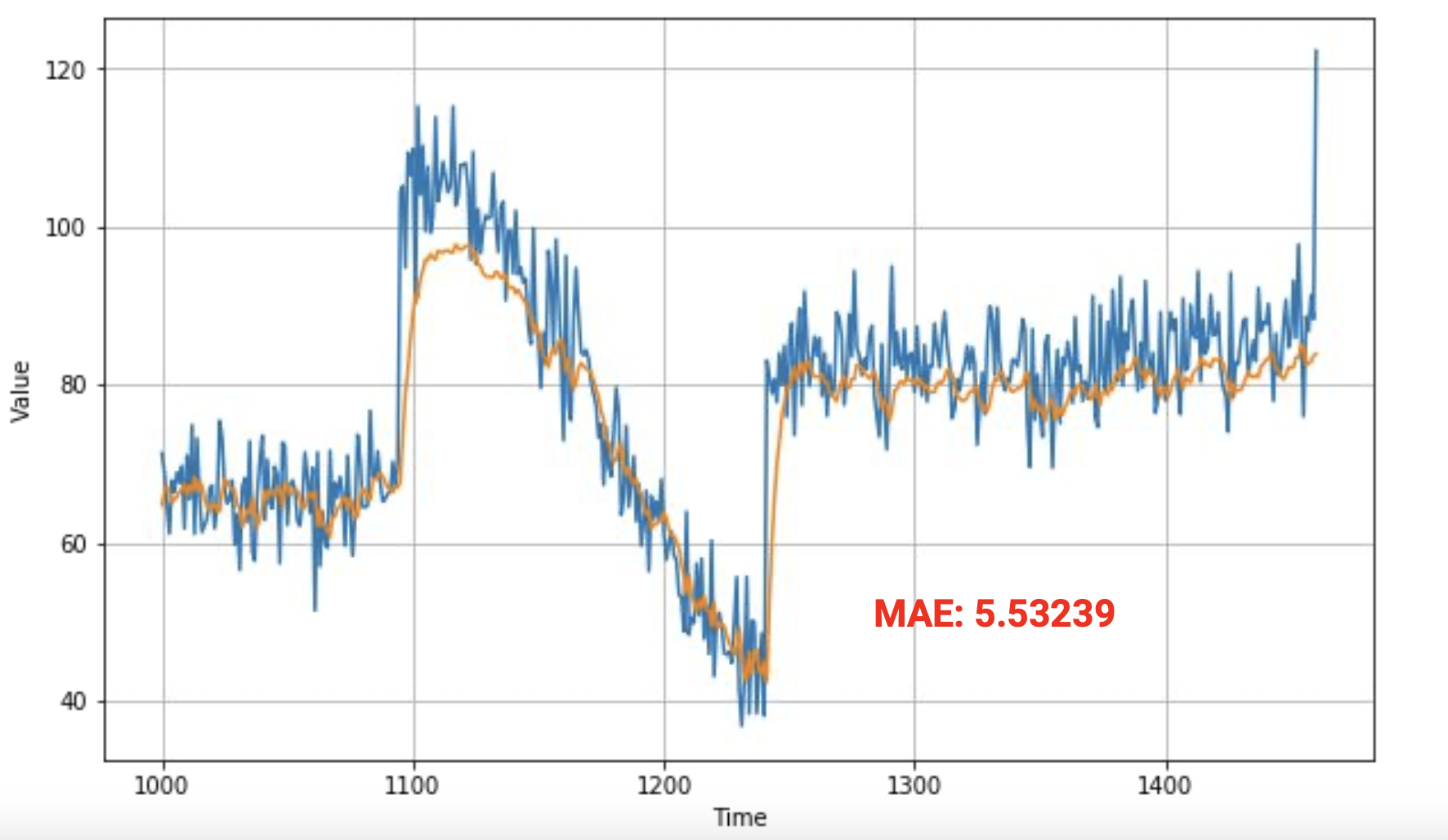
차트를 보면 원본 데이터보다 훨씬 우수하고 근접하게 추적하고 있다. 급격하게 솟은 부분을 동일하지 않지만 가까이 추적하고 있다.
훨씬 더 나은 평균 오차를 제공해서 올바른 방향으로 나아가고 있음을 보여준다.
소스를 좀 더 수정해서 세 번째 LSTM 레이어를 추가해본다.
레이어를 추가하고 두 번째 레이어의 return_sequences를 True로 두고 훈련한다.
그 후 출력값을 살펴본다.