혼공학습단 13기 5주차
혼자 공부하는 네트워크
2025.02.10 ~ 2025.02.16
- 진도: Chapter 05
- 기본 숙제(필수): Ch.05(05-1) 확인 문제 1번(p.271), (05-2) 확인 문제 2번(p.307), 풀고 설명하기
- 추가 숙제(선택): HTTP 요청 메시지 확인해 보기
숙제(과제)
기본숙제(필수)
- 기본 숙제(필수): Ch.05(05-1) 확인 문제 1번(p.271), (05-2) 확인 문제 2번(p.307), 풀고 설명하기
(05-1) 확인 문제 1번(p.271)

- (4) 의 루트 도메인은 '.' 이고, com은 최상위 도메인 (TLD)
(05-2) 확인 문제 2번(p.307)

- (1) 300번대 상태코드는 리다이렉션 관련 코드
추가숙제
- 추가 숙제(선택): HTTP 요청 메시지 확인해 보기
cURL 커맨드 라인으로 HTTP 요청 보내고 응답확인해보기 (HTTP GET 요청 확인함)
curl -v http://example.com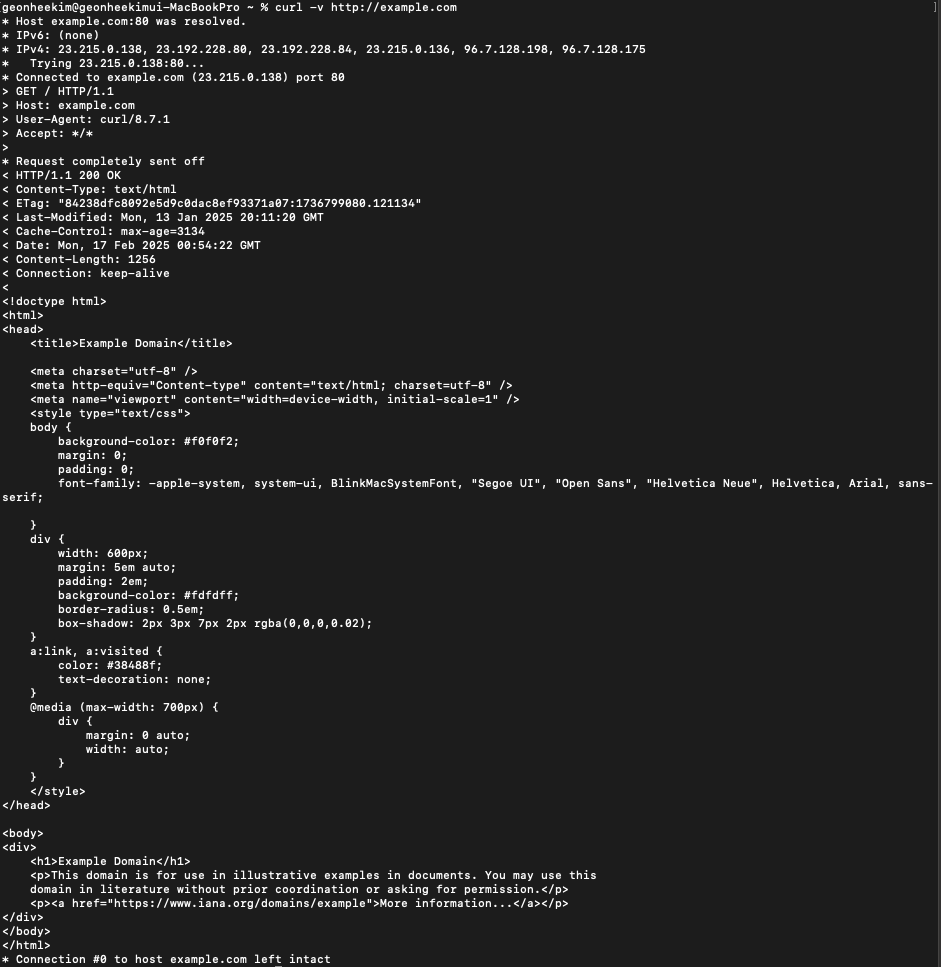
정리
05. 응용 계층
클라이언트는 서버에게 요청 메시지를 보내고 서버는 클라이언트에게 요청 메시지에 대한 응답 메시지를 보냄. 즉 서버와 클라이언트는 '메시지를 주고받고자 하는 대상'과 '송수신하고자 하는 정보'를 식별할 수 있어야 함
메시지를 주고받고자 하는 대상을 파악하기 위해 IP 주소 이외에 도메인 네임을 사용할 수 있고, 송수신하고자 하는 정보를 식별하기 위한 방법으로 위치 기반의 식별자인 URL 과 이름 기반의 식별자인 URN 이 있음
05-1. DNS와 자원
네트워크 상의 호스트를 특정하기 위해 IP 주소를 사용하지만, 통신하고자 하는 모든 호스트의 IP 주소를 기억하기도 어렵고, IP 주소는 언제든지 바뀔 수 있으므로 상대 호스트를 측정하기 위해 IP 주소 보다 도메인 네임(domain name)을 많이 사용함
도메인 네임은 IP 주소와 대응되는 문자열 형태의 호스트 특정 정보임
도메인 네임과 IP 주소는 네임 서버(name server) 에서 관리하고, 도메인 네임을 관리하는 네임 서버를 DNS 서버라고 부름
도메인 네임은 IP 주소에 비해 기억하기 쉽고 IP 주소가 바뀌더라도 바뀐 IP 주소에 도메인 네임을 다시 대응해서 IP 주소만으로 호스트를 특정하는 것보다 간편함
도메인 네임과 네임 서버
예를 들어 www.example.com. 이라는 도메인 네임이 있다고 가정할 때, 도메인 네임은 점(.)을 기준으로 계층적 으로 분류됨
최상단에 루트 도메인(root domain) 이 있고, 다음 단계로 최상위 도메인(TLD;Top-Level Domain) 다음 단계로 2단계 도메인(Second-Level Domain), 다음 단계로 일반적으로 3~5 단계 정도가 있다.
위의 예시에서 'www'는 3단계 도메인이고, 'eample'이 2단계 도메인 'com' 최상위 도메인, '.'은 루트 도메인 이다.
www.example.com 과 같이 도메인 네임을 모두 포함하면 전체 주소 도메인 네임(FQDN;Fully-Qualified Domain Nme) 이라고 한다.
총 3단계 도메인까지 고려하면 하나의 호스트를 식별할 수 있는 도메인 네임을 얻을 수 있고, 이러한 점에서 FQDN의 첫 번째 부분(www)을 호스트 네임(host name) 이라고 부르기도 한다.
도메인 네임이 계층적인 형태를 띄므로, 도메인 네임을 관리하는 네임 서버 또한 계층적인 형태로 이렇게 계층적이고 분산된 도메인 네임에 대한 관리 체계를 도메인 네임 시스템(Domain Name System) 줄여서 DNS 라고 한다.
- DNS는 호스트가 이러한 도메인 네임 시스템을 이용할 수 있도록 하는 애플리케이션 계층 프로토콜이다.
계층적 네임 서버
게층적인 네임 서버의 구성을 토대로 도메인 이름을 통해 IP 주소를 알아내는 과정인 즉 'IP 주소를 모르는 상태에서 도메인 네임에 대응되는 IP 주소를 알아내는 과정' 을 '도메인 네임을 풀이한다' 라고 표현하며 '리졸빙(resolving)' 한다는 표현을 사용한다.
네임 서버의 유형은 크게 네가지가 있는데 로컬 네임 서버, 루트 네임 서버, TLD(최상위 도메인) 네임 서버, 책임 네임 서버
로컬 네임 서버(local name sever) : 클라이언트와 맞닿아 있는 네임 서버. 클라이언트가 도메인 네임을 통해 IP를 알아내고자 할 때 가장 먼저 찾게 되는 네임 서버. 클라이언트가 로컬 네임 서버를 찾을 수 있으려면 로컬 네임 서버의 주소를 알고 있어야 하고, 일반적으로 ISP에서 할당해주는 경우가 많다. ISP에서 할당해 주는 로컬 네임 서버 주소가 아닌 공개 DNS 서버(public DNS server) 이용할 수 도 있다.
루트 네임 서버(root name server) : 로컬 네임 서버가 대응되는 IP 주소를 알고 있다면 클라이언트에게 그 IP 주소를 알려주면 되지만, 로컬 네임 서버가 대응되는 IP 주소를 모른다면 루트 네임 서버에게 해당 도메인 네임을 질의.
루트 네임 서버는 루트 도메임을 관장하느느 네임 서버로 질의에 대해 TLD 네임 서버의 IP 주소를 반환
TLD 네임 서버 : TLD를 관리하는 네임 서버. TLD의 하위 도메인 네임을 관리하는 네임 서버 주소를 반환함
책임 네임 서버(authoritative name sever) : 특정 도메인 영역을 관리하는 네임 서버. 자신이 관리하는 도메니 영역의 질의에 대해서는 다른 네임 서버에게 떠넘기지 않고 곧바로 답할 수 있는 네임 서버. 로컬 네임 서버가 마지막으로 질의하는 네임 서버.
로컬 네임 서버는 일반적으로 책임 네임 서버로부터 원하는 IP 주소를 얻어냄.
로컬 네임 서버가 네임 서버들에게 질의하는 방법
크게 재귀적 질의 와 반복적 질의 라는 두 가지 방법이 있다.
재귀적 질의(recursive query) : 클라이언트가 로컬 네임 서버에게 도메인 네임을 질의하면 로컬 네임 서버가 루트 네임 서버에게 질의하고, 루트 네임 서버가 TLD 네임 서버에게 질의하고, TLD 네임 서버가 다음 단계에 질의하는 과정을 반복하며 최종 응답 결과를 역순으로 전달받는 방식
반복적 질의(iterative query) : 클라이언트가 로컬 네임 서버에게 IP 주소를 알고 싶은 도메인 네임을 질의하면, 로컬 네임 서버는 루트 도메인 서버에게 질의해서 다음으로 질의할 네임 서버의 주소를 응답 받고, 다음으로 TLD 네임 서버에게 질의해서 다음으로 질의할 네임 서버의 주소를 응답 받는 과정을 반복하다가 최종 응답 결과를 클라이언트에게 알려주는 방식
이러한 도메인 네임의 리졸빙 과정에는 하나의 도메인 네임을 리졸빙 하기 위해 8단계를 거쳐야 하는 것처럼 시간이 오래 걸리고 네트워크 상의 메시지 수가 지나치게 늘어날 수 있다.
실제로는 네임 서버들이 기존에 응답받은 결과를 임시로 저장했다가 추후 같은 질의에 이를 활용하는 경우가 많은데 이를 DNS 캐시(DNS cache) 라고 한다.
DNS 캐시를 저장하는 용도로만 사용되는 서버도 있는데, 이 DNS 캐시는 캐시될 수 있는 시간인 TTL(TIem To Live)라는 값과 같이 저장된다.
자원을 식별하는 URI
송수신하고자 하는 정보를 식별하기 위한 방식인 URI, URI를 식별 정보 기준으로 분류한 개념인 URL, URN
위 개념을 이해하기 위해서 자원(resource)를 이해해야 하는데, 자원이란 네트워크상의 메시지를 통해 주고받는 대상이다.
오늘날 인터넷 환경을 이루는 대부분의 통신은 HTTP를 기반으로 이루어져서 자원이라는 용어는 'HTTP 요청 메시지의 대상'이라고도 표현한다.
네트워크 상엥서 자원을 주고 받으려면 자원을 식별할 수 있어야 한다.
자원을 식별할 수 있는 정보가 URI(Uniform Resource Identifier) 이고 자원을 식별하는 통일된 방식이 URI 이다.
URI는 위치를 이용해 자원을 식별하는 URL(Uniform Resource Locator) 이름을 이용해 자원을 식별하는 URN(Uniform Resource Name) 이 있다.
URL
오늘날 인터넷 환겨에서 자원 식별에 더 많이 사용되는 방식은 URL이고, 예시 URL이
foo://www.example.com:8042/over/there?name=ferret#nose
이라고 할 때, 첫 부분인 foo scheme 자원에 접근하는 방법, www.example.com 이 authority 호스트를 특정할 수 있는 정보, over/there? 이 path 자원이 위치한 경로, name=ferret 가 query로 쿼리 문자열(query string) 이나 쿼리 파라미터(query parameter)라고 한다. #nose는 fragment로 자원의 한 조각을 가르키기 위한 정보 이다.
URN
자원의 위치는 언제든 변할 수 있는데, 자원의 위치가 변하면 URL은 유효해지지 않을 수 있다. 자원의 위치가 변경되면 기존 URL로는 자원을 식별할 수 없게 되는데, 자원에 고유한 이름을 붙이는 이름 기반 식별자인 URN은 자원의 위치와 무관하게 자원을 식별할 수 있다.
05-2. HTTP
HTTP는 사용자와 밀접하게 맞닿아 있는 프로토콜로 오늘날 웹 세상의 기반을 이루는 중요한 역할이다.
HTTP에는 중요한 네 가지 특성이 있다.
(1) 요청과 응답을 기반으로 동작한다.
(2) 미디어 독립적이다.
(3) 상태를 유지하지 않는다.
(4) 지속 연결을 지원한다.
HTTP의 특성
HTTP(Hypertext Transfer Protocol) 은 응용 계층에서 정보를 주고받는 데 사용되는 프로토콜이다.
요청-응답 기반 프로토콜
HTTP는 '클라이언트-서버 구조 기반의 요청=응답 프로토콜'이다.
HTTP는 클라이언트와 서버가 서로 HTTP 요청 메시지와 HTTP 응답 메시지를 주고받는 구조로 동작한다.
같은 HTTP 메시지일지라도 HTTP 요청 메시지와 HTTP 응답 메시지 형태가 다르다.
미디어-독립적 프로토콜
'HTTP가 요청하는 대상을 자원이라고 한다. HTTP는 자원의 특성을 제한하지 않으며, 단지 자원과 상호 작용하는 데 사용할 수 있는 인터페이스를 정의할 뿐이다. 대부분의 자원은 URI로 식별된다.' 라고 HTTP는 공식 문서(RFC 9110)에 정의되어 있다.
HTTP는 주고받을 자원의 특성과 무관하게 그저 자원을 주고받을 수단(인터페이스) 역할 만을 수행한다.
HTTP에서 메시지로 주고 받는 자원의 종류를 미디어 타입(media type)이라 부른다. MIME 타입(Multipurpose Internet Mail Extensions Typte) 이라고도 부른다.
즉, HTTP는 주고받을 미디어 타입에 특별히 제한을 두지 않고 독립적으로 동작이 가능한 미디어 독립적인 프로토콜이다.
미디어 타입은 기본적으로 슬래시를 기준으로 하는 '타입/서브타입' 형식으로 구성되는데 타입은 데이터의 유형을 서브타입은 주어진 타입에 대한 세부 유형을 나타낸다.
스테이트리스 프로토콜
HTTP는 상태를 유지하지 않는 스테이트리스(stateless) 프로토콜이다. 이는 서버가 HTTP 요청을 보낸 클라이언트와 관련된 상태를 기억하지 않는다는 의미이다. 클라이언트의 모든 HTTP 요청은 기본적으로 독립적인 요청으로 간주된다.
HTTP의 가장 중요한 설계 목표는 확장성(scalability), 견고성(robustness) 이다.
지속 연결 프로토콜
HTTP는 지속해서 발전 중인 프로토콜로 여러 버전이 있다.
대중적으로 사용되는 HTTP 버전은 지속 연결(persistent connection)이라는 기술을 제공하고, 다른 표현으로는 킵 얼라이브(keep-alive)라고 부른다. 하나의 TCP 연결상에서 여러 개의 요청-응답을 주고받을 수 있는 기술이다.
HTTP 메시지 구조
HTTP 메시지는 시작 라인, 필드 라인, 메시지 분몬으로 이루어져 있다.
시작 라인
HTTP 메시지는 요청 메시지일 수도 있고, 응답 메시지일 수도 있는데 요청 메시지일 경우 시작 라인(start-line)은 '요청 라인'이 되고 응답 메시지일 경우 '상태 라인'이 된다.
HTTP 요청 메시지의 시작 라인인 요청 라인(request-line)은 다음과 같다.
요청 라인 = 메서드 (공백) 요청 대상 (공백) HTTP 버전 (줄바꿈)메서드 란 클라이언트가 서버의 자원에 대해 수행할 작업의 종류이다. (GET, POST, PUT, DELETE)
요청 대상 은 HTTP 요청을 보낼 서버의 자원이다.
보통 쿼리가 포함된 URI의 경로가 명시된다.
HTTP 버전은 HTTP 버전이다.
HTTP가 응답 메시지일 경우 시작 라인은 상태 라인(status-line)이 된다.
상태 라인 = HTTP 버전 (공백) 상태 코드(공백) 이유 구문* (줄바꿈)HTTP 버전은 HTTP의 버전
상태 코드는 요청에 대한 결과를 나타내는 세자리 정수
이유 구문 은 상태 코드에 대한 문자열 형태의 설명이다.
필드 라인
필드 라인에는 0개 이상의 HTTP 헤더가 명시되고, 그래서 이를 헤더 라인이라고 부른다. HTTP 헤더는 HTTP 통신에 필요한 부가 정보를 의미한다.
HTTP 헤더는 콜론(:)을 기준으로 헤더 이름과 하나 이상의 헤더 값으로 구성된다.
메시지 본문
HTTP 요청 혹은 응답 메시지에서 본문이 필요한 경우 이는 메시지 본문에 명시된다.
메시지 본문은 존재하지 않을 수 있고, 다양한 콘텐츠 타입이 사용될 수도 있다.
HTTP 메서드
HTTP 요청 메시지에서 사용할 수 있는 다양한 메서드는GET, HEAD, POST, PUT, PATCH, DELETE, CONNECT, OPTIONS, TRACE가 있다.
GET : 자원을 습득하기 위한 메서드
HEAD : GET과 동일하나, 헤더만을 응답받는 메서드
POST : 서버로 하여금 특정 작업을 처리하게금 하는 메서드
PUT : 자원을 대체하기 위한 메서드
PATCH : 자원에 대한 부분적 수정을 위한 메서드
DELETE : 자원을 삭제하기 위한 메서드
CONNECT : 자원에 대한 양방향 연결을 시작하는 메서드
OPTIONS : 사용 가능한 메서드 등 통신 옵션을 확인하는 메서드
TRACE : 자원에 대한 루프백 테스트를 수행하는 메서드
HTTP 상태 코드
상태 코드는 요청에 대한 결과를 나타내는 세 자리 정수이다.
백의 자리 수를 기준으로 유형을 구분할 수 있다.
유사한 상태 코드는 같은 백의 자리 수를 공유한다.
100번대(100~199) : 정보성 상태 코드
200번대(200~299) : 성공 상태 코드
300번대(300~399) : 리다이렉션 상태 코드
400번대(400~499) : 클라이언트 에러 상태 코드
500번대(500~599) : 서버 에러 상태 코드
05-3. HTTP 헤더와 HTTP 기반 기술
HTTP 메시지의 두 번재 줄인 필드 라인은 다양한 HTTP 헤더 들이 ㅁ여시된다.
HTTP 헤더에는 필드 이름(헤더 이름)과 필드 값(헤더 값)이 콜론(:)을 기준으로 구분되어 있다.
HTTP의 중요 헤더 중에는 특별한 사전 지식이 필요하지 않은 헤더가 있고, 사전 지식이 필요한 헤더가 있다.
예를 들어 쿠키, 콘텐츠 협상 관련 헤더를 이해하려면 먼저 캐시, 쿠키 ,콘텐츠 협상이 무엇인지 이해해야 한다.
HTTP 헤더
HTTP 헤더의 종류는 매우 많아, 자주 활용되는 중요한 HTTP 헤더인 HTTP 요청 시 주로 사용되는 헤더, HTTP 응답 시 주로 사용되는 헤더, HTTP 요청과 응답 모두에서 자주 활용되는 헤더 가 있다.
요청 시 활용되는 HTTP 헤더
HTTP 요청 시 주로 활용되는 대표적인 헤더는 Host, User-Agent, Referer, *Authorization 헤더가 있다.
응답 시 활용되는 HTTP 헤더
응답시 주로 활용되는 헤더는 Server, Allow, Retry-After, Location, WWW-Authenticate 헤더가 있다.
요청과 응답 모두에서 활용되는 HTTP 헤더
HTTP 요청과 응답 모두에서 공통으로 활용되는 헤더에는 Date, Connection, Content-Length, Content-Type, Conent-Languge, Content-Encoding이 있다.
캐시
캐시(Cache)란 불필요한 대역폭 낭비와 응답 지연을 방지하기 위해 정보의 사본을 임시로 저장하는 기술이다.
정보의 사본을 임시로 저장하는 것 자체를 '캐시한다', '캐싱한다'라고 표현한다.
캐시는 웹 브라우저에 저장되어 있는 개인 전용 캐시(private cache)와, 클라이언트와 서버 사이에 위치한 중간 서버에 저장되어 있는 공용 캐시(Public cache)가 있다.
쿠키
HTTP는 기본적으로 상태를 유지하지 안흔 스테이트리스 프로토콜이지만 클라이언트 상태를 알고 있어야 구현할 수 있는 구성들이 있다. HTTP 쿠키를 통해 이러한 기능을 구현할 수 있는데 쿠키(cookie) 란 서버에서 생성되어 클라이언트 측에 저장되는 데이터로 상태를 유지하지 않는 HTTP의 특성을 보완하기 위한 수단이다.
콘텐츠 협상과 표현
한국에서 접속하거나 한국어 계정으로 특정 URL에 접속하면 한국어로 된 웹 페이지를 보고, 다른 지역에서 접속하면 영어 계정으로 같은 URL에 접속하면 영어 웹 페이지를 볼 수 있는 상황을 예로 들어보자.
이는 HTTP의 콘텐츠 협상(content negotiation) 을 통해 이루어진다. 콘텐츠 협상이란 같은 URI에 대해 가장 적합한 '자원의 형태'를 제공하는 메커니즘이다.
'송수신 가능한 자원의 형태'를 자원의 표현(representation)이라고 하는데, 즉 콘텐츠 협상은 클라이언트에게 가장 적합한 표현을 제공하는 메커니즘이다.
마무리
5주차 오니까 또 런할뻔 왜이러지
돔황쳐, 아니 돔황치지마,, 돔황쳐,, 아니 돔황치지마

결론 : 했음
