타입과 타입 변환
C++ 엄격한 타입시스템 언어이기 때문에 매번 타입(type)을 설정해줘야 한다.
또한 매개변수의 수나 타입 등에 따라 함수를 다르게 인식한다. 예를 들어 func(int a, int b)와 func(int a)는 매개변수의 수만이 다르지만 엄하게 다른 함수로 인식된다.
타입
다음은 알고리즘에서 자주 나오는 타입 8개.
void, char, string, bool, int, long long, double, unsigned long long1. void : 리턴값이 없음
#include <bits/stdc++.h>
using namespace std;
int ret=1;
void a(){
ret=2;
cout << ret << "\n";
return;
}
int main(){
a();
return 0;
}예를 들어 아무것도 반환하지 않는 void가 아닌 double 타입을 반환하는 함수는 어떻게 정의할까?
#include <bits/stdc++.h>
using namespace std;
double a(){
return 1.2333;
}
int main(){
double ret = a();
cout << ret << "\n";
return 0;
}또한 함수 선언할 때는 항상 호출되는 위쪽 부분에 선언을 해야 한다. 타입과 인자만 선언해놓고 아래쪽에 함수를 정의하기도 한다.
#include <bits/stdc++.h>
using namespace std;
double a();
int main(){
double ret = a();
cout << ret << "\n";
return 0;
}
double a(){
return 1.2333;
}그러나 알고리즘은 시간 싸움. 두번째 처럼 적으면 시간 낭비임. 그냥 위에다 선언과 정의를 한꺼번에 하는 게 편하다고 한다. 의외였다. 이때까진 선언 후 밑에 정의를 했어서 ㅋㅋ
2. char, 문자
작음 따옴표''로 선언해야 하고 1바이트의 크기를 가진다.
한 문자만 들어간다.(문자열X)
#include <bits/stdc++.h>
using namespace std;
int main(){
char a = 'a';
cout << a << "\n";
return 0;
}char을 리턴하는 함수는 어떻게 정의?
#include <bits/stdc++.h>
using namespace std;
char b(){
char a = 'a';
return a; }
int main(){
char a = b();
cout << a << "\n";
return 0;
}3. string, 문자열
char을 char[] 배열로 선언하거나 그냥 string으로 선언하면 된다.
char s[10];
string a;string으로 선언하고, 배열처럼 a[0]으로 접근하거나 통째로 a로 출력 가능하다.
#include <bits/stdc++.h>
using namespace std;
int main(){
string a = "나는야";
cout << a[0] << "\n";
cout << a[0] << a[1] << a[2] << '\n';
cout << a << "\n";
string b = "abc";
cout << b[0] << "\n";
cout << b << "\n";
return 0;
}
/*
?
나
나는야
a
abc */한글로 선언한 a의 경우 출력했을 때 이상한 문자가 나타난다. a[0], a[1]로 접근한다는 것은 1바이트씩 출력한다는 의미인데, 영어는 한 글자당 1바이트지만 한글은 한 글자당 3바이트이다. 그래서 이상한 문자가 출력된다.
다음은 string에서 많이 사용하는 메서드를 사용한 코드이다.
#include <bits/stdc++.h>
using namespace std;
int main(){
string a = "love is";
a += " pain!";
a.pop_back();
cout << a << " : " << a.size() << "\n";
cout << char(* a.begin()) << '\n';
cout << char(* (a.end() - 1)) << '\n';
// string& insert (size_t pos, const string& str);
a.insert(0, "test ");
cout << a << " : " << a.size() << "\n";
// string& erase (size_t pos = 0, size_t len = npos);
a.erase(0, 5);
cout << a << " : " << a.size() << "\n";
// size_t find (const string& str, size_t pos = 0);
auto it = a.find("love");
if (it != string::npos){
cout << "포함되어 있다." << '\n';
}
cout << it << '\n';
cout << string::npos << '\n';
// string substr (size_t pos = 0, size_t len = npos) const;
cout << a.substr(5, 2) << '\n';
return 0;
}
/*
love is pain : 12
l
n
test love is pain : 17
love is pain : 12
포함되어 있다.
0
18446744073709551615
is
*/+=
메서드는 아니며 문자열에서 문자열을 더할 때 보통 += 를 써서 문자열 또는 문자를 더한다. push_back()이라는 메서드가 있지만 이는 문자하나씩밖에 더하지 못해 보통은 += 를 씀.
이 때 +를 쓰게 되면 시간이 더 든다. +=의 경우 해당 문자열을 뒤에 추가해서 확장하는 것이지만 +를 쓰게 되면 새로운 문자열을 만들어 재할당하는 것이기 때문에 미묘한 시간차이가 있다. 문자열을 뒤에 추가할 때는 + 보다는 += 를 쓰는게 좋다.
#include<bits/stdc++.h>
using namespace std;
int main() {
string a = "abc";
// good
a += "d";
// bad
a = a + "d";
}begin()
문자열의 첫번째 요소를 가리키는 이터레이터를 반환한다. 이 이터레이터를 기반으로 *를 통해 해당 위치의 값을 가져올 수 있다.
end()
문자열의 마지막 요소 그 다음을 가리키는 이터레이터를 반환한다.
참고로 begin()과 end()는 자료구조인 vector, Array, 연결리스트, 맵, 셋에서도 존재하며 똑같은 의미를 지닌다.
size()
문자열의 사이즈를 반환한다. 의 시간복잡도를 가진다.
insert(위치, 문자열)
특정위치에 문자열을 삽입한다. 의 시간복잡도를 가진다.
erase(위치, 크기)
특정위치에 크기만큼 문자열을 지운다. 의 시간복잡도를 가진다.
pop_back()
문자열 끝을 지운다. 의 시간복잡도를 가진다.
find(문자열)
특정 문자열을 찾아 위치를 반환한다. 만약 해당 문자열을 못 찾을 경우 string::npos를 반환하며 의 시간복잡도를 가진다.
string::npos는 size_t 타입의 최대값을 의미한다. size_t 타입의 최대값은 OS에 따라 달라지며 64비트 운영체제라면 64비트 부호가 없는 최대정수, 32비트 운영체제라면 32비트 부호가 없는 최대 정수값을 가진다. 내 컴퓨터는 64비트 운영체제이기 때문에 18446744073709551615라는 값을 가짐!
substr(위치, 크기)
특정 위치에서 크기만큼의 문자열을 추출한다. 의 시간복잡도를 가진다.
아스키코드와 문자열
숫자로 된 문자에서 ++ 증감 연산자를 통해 1을 더해준다면? 바로 아스키코드에서 +1한 값이 된다.
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
string s = "123";
s[0]++;
cout << s << "\n"; // 223
return 0;
}앞의 코드를 보면 123에서 s[0]에 1을 더해 223이 되었는데 이는 아스키코드 49에서 1을 더한 값인 50이 가리키는 값이 2이기 때문에 123 에서 223이 되는 것이다. 즉, 문자열에서 + 하는 연산은 “아스키(ASCII)코드”를 기반으로 수행된다.
문자열을 이루는 문자는 아스키코드 값(0에서 127 사이의 정수)으로 저장되어 구현된다. 예를 들어 'A'의 아스키코드 값은 65이다. 이것이 의미하는 바는 문자 변수에 'A'를 할당하면 'A' 자체가 아니라 65라는 숫자가 해당 변수에 저장된다는 뜻.
아스키코드
아스키코드는 1963년 미국 ANSI에서 표준화한 정보교환용 7비트 부호체계이며 000(0x00)부터 127(0x7F)까지 총 128개의 부호가 사용된다. 1바이트를 구성하는 8비트 중에서 7비트만 쓰도록 제정된 이유는 나머지 1비트를 통신 에러 검출을 위한 용도로 비워두었기 때문이다.
이는 영문 키보드로 입력할 수 있는 모든 기호들이 할당되어 있는 가장 기본적인 부호 체계이다.
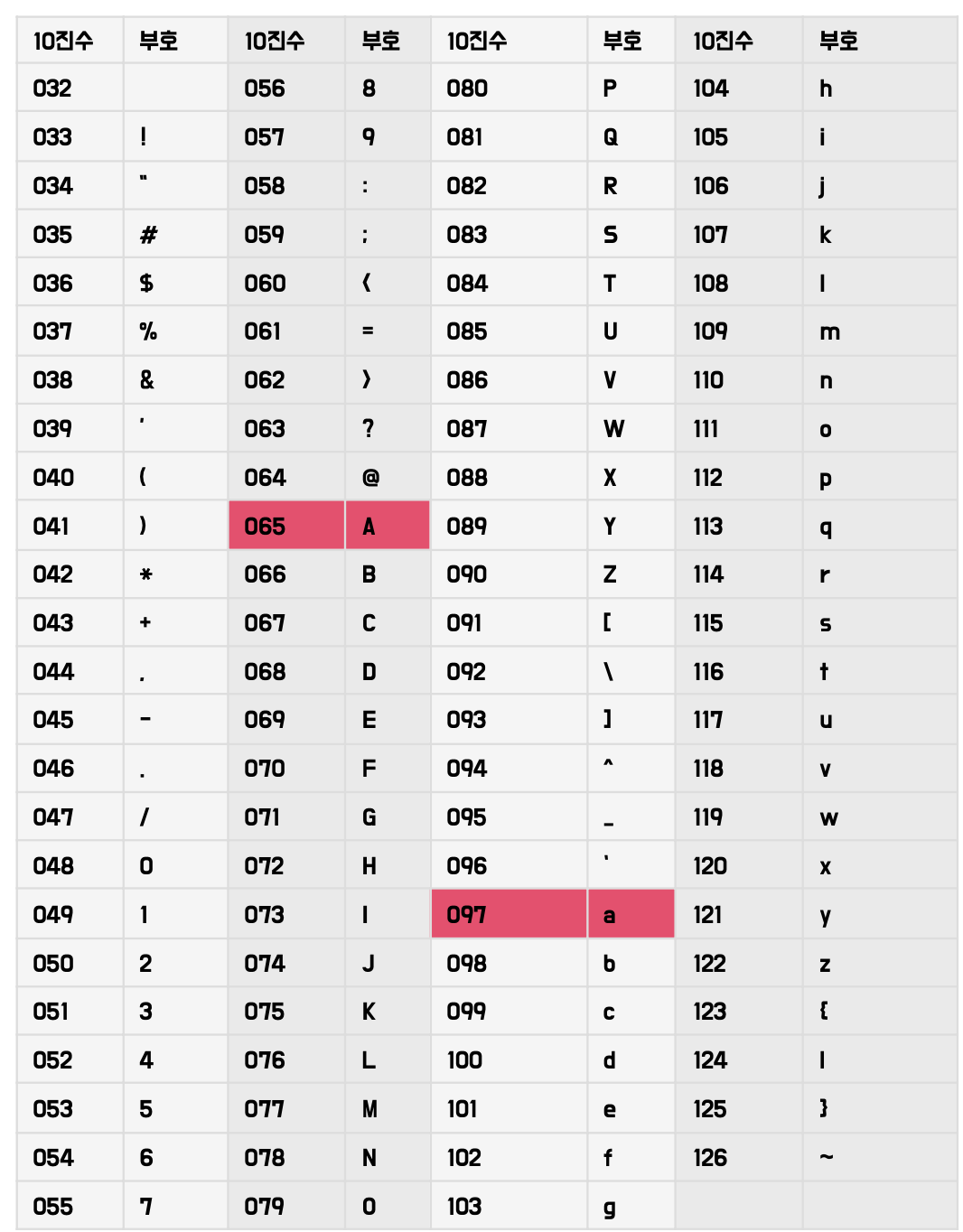
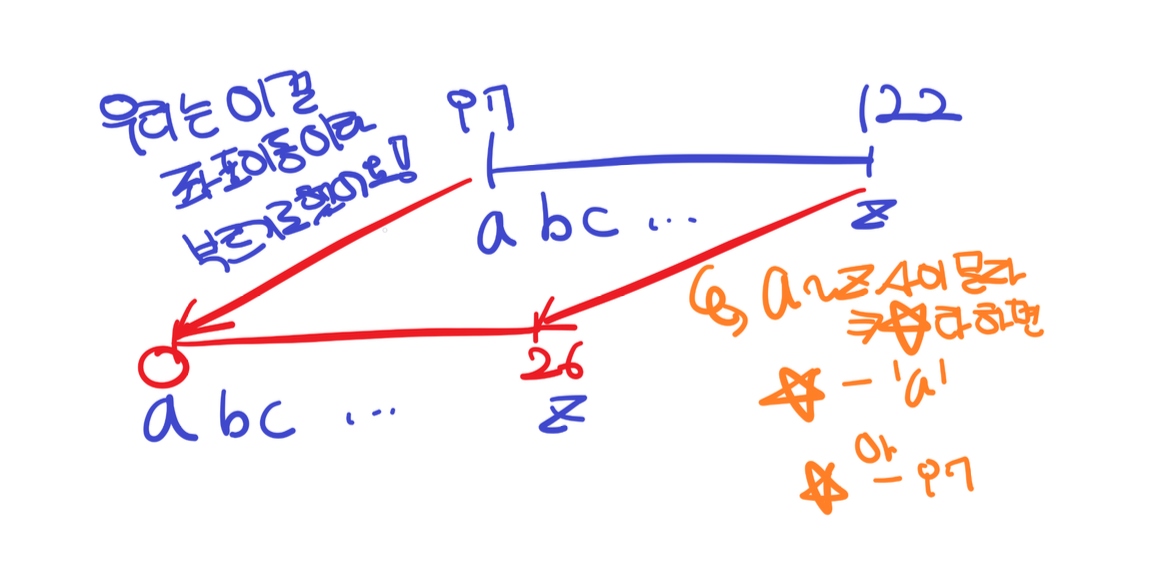
빨강으로 설정한 2가지 97 : a / 65 : A 정도만 외워두자!
그러면 d는 a부터 시작해 3번째이니 97 + 3 = 100의 아스키코드값을 가지는 것을 알 수 있다.
문자 a는 어떻게 저장이 될까?
a는 아스키코드에서 봤듯이 97로 저장이 된다. 이를 확인하고 싶다면 타입 변환을 하면 됨.
(int)a를 통해 문자 char을 정수 int로 변환할 수 있는데 이를 하게 되면 다음코드처럼 97로 변환된다.
#include<bits/stdc++.h>
using namespace std;
int main(){
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
char a = 'a';
cout << (int)a << '\n';
return 0;
}
// 97reverse()
string은 reverse()라는 메서드를 지원하지 않는다. 문자열을 거꾸로 뒤집고 싶다면 STL에서 지원하는 함수인 reverse()를 쓰면 된다.
void reverse (BidirectionalIterator first, BidirectionalIterator last);reverse() 함수는 void 타입으로 아무것도 반환하지 않는다. 그리고 원본 문자열도 바꿔버린다.
다 코드처럼 구축이 가능하며, a.begin() + 3처럼 시작 위치를 바꿔 뒤집고 싶은 부분만 바꿀 수 있다.
#include <bits/stdc++.h>
using namespace std;
int main(){
string a = "It's hard to have a sore leg";
reverse(a.begin(), a.end());
cout << a << '\n';
reverse(a.begin(), a.end());
cout << a << '\n';
reverse(a.begin() + 3, a.end());
cout << a << '\n';
return 0;
}split() : 강의 참고✔️
split이란?
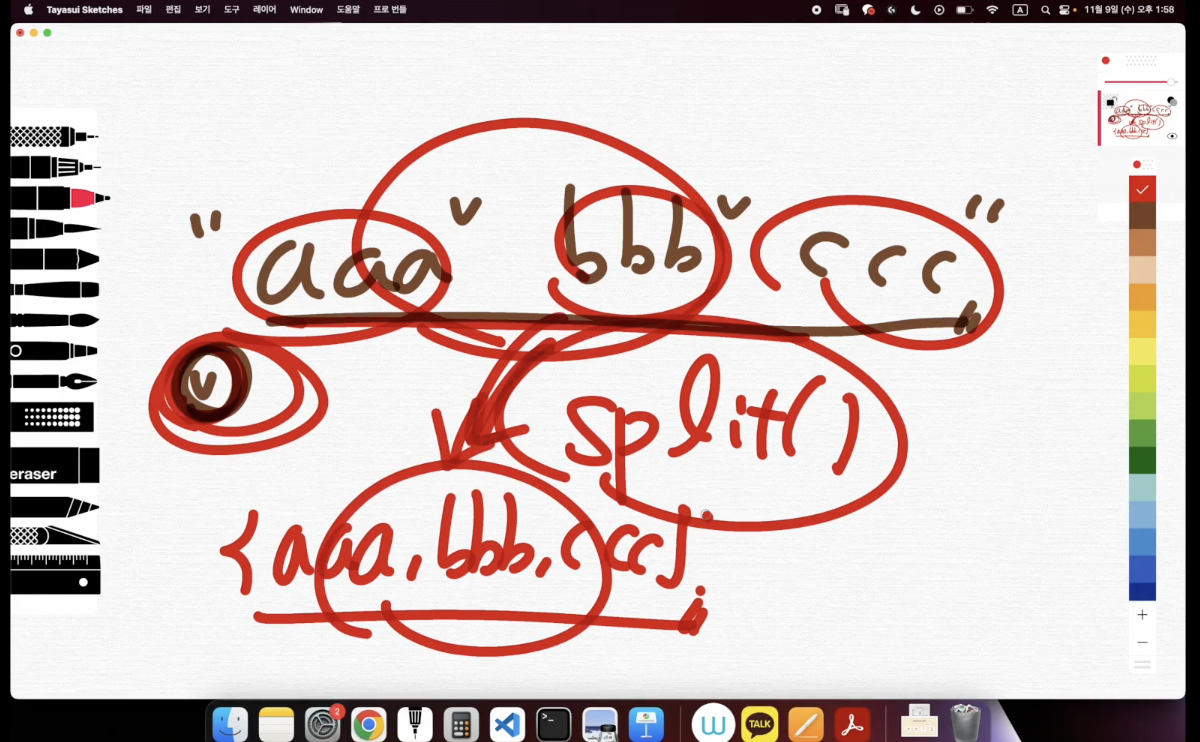
보통 어떠한 문자열에서 특정 문자열을 기준으로 나눠 읽고 싶을 때. 그리고 나눠서 배열에 저장하고 싶을 때 사용하는 게split이다!
코딩테스트에서는 문자열을 split() 하는 로직이 많이 등장한다. split()함수란 다른 프로그래밍 언어에서도 문자열을 특정 문자열을 기준으로 쪼개어서 배열화시키는 함수라는 의미로 사용되는데 C++에서는 STL에서 split() 함수를 지원하지 않는다. 그래서 만들어야 함!
보통 다음과 같이 구현한다. 시간복잡도는 을 갖는다.
#include <bits/stdc++.h>
using namespace std;
vector<string> split(string input, string delimiter) {
vector<string> ret;
long long pos = 0;
string token = "";
while ((pos = input.find(delimiter)) != string::npos) {
token = input.substr(0, pos);
ret.push_back(token);
input.erase(0, pos + delimiter.length());
}
ret.push_back(input);
return ret;
}
int main() {
string s = "안녕하세요 김혜주 입니다", d = " ";
vector<string> a = split(s, d);
for(string b : a) cout << b << "\n";
return 0;
}
/*
안녕하세요
김혜주
입니다
*/복잡해보이지만 다음 코드처럼 3줄만 외워두기.
while ((pos = input.find(delimiter)) != string::npos) {
token = input.substr(0, pos);
ret.push_back(token);
input.erase(0, pos + delimiter.length());
}input에서delimiter을 찾는다. 못 찾을 때까진 이 루프 반복.
delimeter는 구분자를 의미(ex-띄어쓰기)
while ((pos = input.find(delimiter)) != string::npos)- 찾았다면
pos까지 해당 부분 문자열을 추출한다. 예를 들어 abcd에서 d를 찾았다면pos는 3을 반환하게 되고 3만큼substr을 하기 때문에 abc를 추출하게 된다.
token = input.substr(0, pos);- 그 다음 추출한 문자열을
ret이란 배열에 집어넣는다.
ret.push_back(token);- 그리고 앞에서부터 문자열을 지운다. abcdabc에서 d가
delimiter라면pos = 3,delimiter의 사이즈는 1이기 때문에 앞에서부터 4 크기의 문자열을 제거해 abc만 남게 된다.
input.erase(0, pos + delimiter.length());⭐️ split() 코드 외우기!!
더 빠른 split()
앞서 설명한 split의 경우 매번 erase()를 하는 단점이 있습니다. 이를 제거해 좀 더 빠른 split() 코드는 다음과 같습니다. 만약 앞의 split()이 시간초과가 난다면 이 코드를 사용하시는게 좋습니다.
범위기반 for 루프
위의 코드를 보면 범위기반 for루프가 있는 것을 볼 수 있는데 C++11부터 범위기반 for 루프가 추가되어 사용 가능하다.
for ( range_declaration : range_expression )
loop_statement다음 코드처럼 vector 내의 요소들을 쉽게 순회할 수 있다. 1번코드와 2번코드는 같은 의미이다.
for({타입} {임시변수명} : {타입을 담은 컨테이너}) 이렇게 쓰인다.
#include<bits/stdc++.h>
using namespace std;
int main(){
vector<int> a = {1, 2, 3};
for(int b : a) cout << b << "\n"; // 1
for(int i = 0; i < a.size(); i++) cout << a[i] << "\n"; // 2
return 0;
}아래 코드는 배열 a의 범위인 0~9까지 탐색하며 0을 반환한다.
#include <bits/stdc++.h>
using namespace std;
int a[10], n;
int main() {
for(int i : a){
cout << i << " ";
}
return 0;
}#include <bits/stdc++.h>
using namespace std;
int n;
int main() {
cin >> n;
int a[n];
memset(a, 0, sizeof(a));
for(int i : a){
cout << i << " ";
}
return 0;
}하지만 앞의 코드처럼 Array a가 n을 입력을 받고 int a[n]로 선언하게 되면, 범위기반 for 루프를 쓸 때 에러가 발생된다. Array는 변수의 크기를 기반으로 런타임시기에 크기가 결정되는 VLA(Variable Length Array)가 되는데 이 VLA 를 기반으로 (for int i : a)을 할 때의 루프의 범위는 컴파일시기에 결정된다.
하지만 저 VLA의 크기자체가 컴파일시기에는 0이였다가 런타임에 크기가 결정되기 때문에 에러가 발생된다.
즉, Array는 컴파일에 결정된 크기로만 (for int i : a)를 쓸 수 있다고 보면 된다. Array를 쓸 것이라면 입력과는 무관하게 전역변수로 컴파일시기에 배열의 크기를 정해놓고 써야 하며, 만약 크기가 런타임시에 결정이 되고 범위기반 for루프를 쓰고 싶다면 vector를 쓰면 된다.
atoi(s.c_str())
문자열을 int로 바꿔야 할 상황이 있다. 예를 들어 입력이 “amumu” 또는 0 이렇게 온다라고 했을 때 문자열, string으로 입력을 받아 입력받은 글자가 문자열인지 숫자인지 확인해야 하는 로직이 필요하다.
다음 코드 처럼 입력받은 문자열 s를 기반으로 atoi(s.c_str())로 쓰입니다. 이렇게 보면 만약 입력받은 문자열이 문자라면 0을 반환하고 그게 아니라면 숫자를 반환합니다.
#include <bits/stdc++.h>
using namespace std;
int main(){
string s = "1";
string s2 = "amumu";
cout << atoi(s.c_str()) << '\n';
cout << atoi(s2.c_str()) << '\n';
return 0;
}
/* 1
0 */4. bool, 참과 거짓
1바이트, true또는 false이다. 1 또는 0으로 선언해도 무방하다.
참고로 C++에서는 0이면 false, 0이 아닌 값들은 모두 true가 되며 bool()을 통해 간단하게 bool형으로 형변환이 가능하다.
#include<bits/stdc++.h>
using namespace std;
int main(){
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int a = -1;
cout << bool(a) << "\n";
a = 0;
cout << bool(a) << "\n";
a = 3;
cout << bool(a) << "\n";
}
/*
1
0
1 */5. int, 4바이트 정수
4바이트짜리 정수를 사용할 때 쓰인다. 표현범위는 -2,147,483,648 ~ 2,147,483,647(약 20억까지 표현가능)
즉, 문제를 푸는 코드에 들어가있는 값들의 예상값이 20억을 넘어간다면 int가 아닌 long long을 써야 한다.
int a = 10;또한 문제를 풀 때는 이상한 문제가 아니라면 int의 최대값으로 20억까지가 아닌 987654321 또는 1e9를 쓴다.
const int INF = 987654321;
const int INF2 = 1e9;앞의 코드처럼 const int로 선언을 해서 쓴다.
왜냐하면 이 INF를 기반으로 INF + INF라는 연산이 일어날 수도 있고 INF*2, 그리고 INF + 다른 수 연산이 일어날 때 int의 최대값을 넘어가는 오버플로를 방지할 수 있는 장점이 있기 때문이다.
int 연산
int로 선언한 변수 끼리 연산을 하게 되었을 때 실수가 나온다면 소수점 아래에 있는 수는 모두 버림이 된다.
#include<bits/stdc++.h>
using namespace std;
int main(){
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int a = 3;
int b = 2;
cout << a / b << '\n'; // 1
double c = 3;
double d = 2;
cout << c / d << '\n'; // 1.5
}const 키워드
const 키워드는 수정할 수 없는 변수를 정할 때 쓰인다. 보통 INF 같은 것이나 방향벡터를 나타내는dy, dx에 const를 쓴다.
예를 들어 문제에서 주어진 맵의 크기가 10 10 이기 때문에 10 10 2차원 배열을 만들어야 할 경우가 있다.
const int mx = 10;
int a[mx][mx];어차피 10이라는 숫자는 변하지 않는 상수이기 때문에 “미리” 설정해놓고 이를 기반으로 맵의 크기를 설정하는 것. 이렇게 하면 갑자기 a[10][10]인데 a[10][1]으로 설정한다던가 등의 실수를 방지할 수 있다.
오버플로
오버플로(overflow)란 타입의 허용범위를 넘어갈 때 발생하는 에러를 뜻한다.
언더플로
오버플로와는 반대로 취급할 수 있는 결과값보다 작아지게 되면 언더플로가 발생된다.
6. long long, 8바이트 정수
8바이트짜리 정수이다. 범위는 –9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807
int로 표현이 안될 때 쓰면 된다.
보통은 아래와 같이 INF와 비슷한 이유로 1e18로 정의를 해놓고 쓰면 되나 이는 문제마다 다르니 참고만 하기.
typedef long long ll;
ll INF = 1e18;7. double, 실수 타입
실수 타입은 8바이트이며 소수점 아래로 15자리 까지 표현이 가능하다.
참고로 실수타입을 표현하는 타입은 float도 있는데 이는 4바이트, 소수점 아래로 7자리까지 표현이 가능하다. float과 double 중 double이 더 정확하게 표현이 가능하니 double을 쓰는게 더 좋다!
8. unsigned long long, 8바이트 양의 정수
부호가 없는 정수이다. long long에서 -로 표현할 범위를 몽땅 + 범위에 추가한 타입이다.
아주 가끔 쓰며 음수를 표현할 수 없다.
pair와 tuple
pair와 tuple은 타입이나 자료구조는 아니다. C++에서 제공하는 utility 라이브러리 헤더의 템플릿 클래스이며 자주 사용된다.
pair는 first와 second 라는 멤버변수를 가지는 클래스이며 두가지 값을 담아야 할 때 쓴다.
tuple은 세가지 이상의 값을 담을 때 쓰는 클래스이다.
tie 사용
아래는 tie를 써서 pair이나 tuple로부터 값을 끄집어내는 코드이다.
#include<bits/stdc++.h>
using namespace std;
pair<int, int> pi;
tuple<int, int, int> tl;
int a, b, c;
int main(){
pi = {1, 2};
tl = make_tuple(1, 2, 3);
tie(a, b) = pi;
cout << a << " : " << b << "\n";
tie(a, b, c) = tl;
cout << a << " : " << b << " : "<< c << "\n";
return 0;
}pair의 경우 {a, b} 또는 make_pair(a, b)로 만들 수 있다.
이 때 원래는 a = pi.first, b = pi.second 이런식으로 끄집어내야 하는데 tie를 쓰게 되면 tie(a, b) = pi 이렇게 끄집어 낼 수 있다. 물론 이 때 a와 b는 앞서서 변수로 선언되어야 한다.
tie 사용 X
다음 코드는 tie를 쓰지 않는 코드입니다.pair은 first, second로 값을 끄집어 내며,tuple의 경우 get<0>, get<int> .. 이런식으로 값을 꺼냄
#include<bits/stdc++.h>
using namespace std;
pair<int, int> pi;
tuple<int, int, int> ti;
int a, b, c;
int main(){
pi = {1, 2};
a = pi.first;
b = pi.second;
cout << a << " : " << b << "\n";
ti = make_tuple(1, 2, 3);
a = get<0>(ti);
b = get<1>(ti);
c = get<2>(ti);
cout << a << " : " << b << " : "<< c << "\n";
return 0;
}
/*
1:2
1:2:3
*/auto 타입
auto는 타입추론을 하여 결정되는 타입이다.
다음 코드처럼 b라는 변수를 auto로 선언했는데 rvalue가 1인 것을 통해 자동적으로 int 타입의 변수를 선언한 것처럼 쓸 수 있다.
#include <bits/stdc++.h>
using namespace std;
int a = 1; auto b = 1;
int main(){
cout << b << '\n';
}
/* 1 */auto 타입은 주로 복잡하고 긴 타입의 변수명을 대신할 때 쓰인다.
예를 들어 다음 코드처럼 pair<int, int> it가 아닌 auto it로 조금 더 짧게 선언할 수 있다.
#include<bits/stdc++.h>
using namespace std;
int main(){
vector<pair<int, int>> v;
for(int i = 1; i <= 5; i++){
v.push_back({i, i});
}
for(auto it : v){
cout << it.first << " : " << it.second << '\n';
}
for(pair<int, int> it : v){
cout << it.first << " : " << it.second << '\n';
}
return 0;
}타입 변환
만약 int타입인 것을double타입으로 변환해야한다면 어떻게?
(바꿀타입) 기존변수 이런식으로 하면 된다.
double을 int형으로 만들기
#include <bits/stdc++.h>
using namespace std;
int main(){
double ret = 2.12345;
int n=2;
int a = (int)round(ret / double(n));
cout << a << "\n";
return 0;
}같은 타입끼리 연산을 하는 것이 중요하다!
c.f
double은 double끼리 나눠야 한다. int를 double로 나누면 double 타입의 결과값이 나오는데 코딩테스트 때 신경쓰기란 어려움. 차라리 double은 double 끼리 연산하고 int는 int끼리 연산하게 타입변환을 해놓고 연산하는게 "맞왜틀"에 빠지지 않을 가능성을 높여줌!
c.f 암시적 형변환 우선순위 주의
산술표현식을 평가할 때 같은 타입을 가져야 하나 이게 맞지 않을 경우 암시적 형변환(Implicit type conversion)이 일어난다. 이 때 다음과 같은 우선순위를 거쳐 형변환이 일어난다. 예를 들어 double과 float끼리 연산이 일어난다면 double로 통일되어 값을 반환한다.
- 우선순위
long double (highest) - double - float - unsigned long long - long long - unsigned long - long - unsigned int - int (lowest)
이 때문에 vector의 size()를 기반으로 음수가 나올 수 있는 연산을 할 때 주의. vector의 size()라는 메서드는 unsigned int를 반환함. 따라서 v.size() - 10 이렇게 연산을 할 때 결과값은 음수가 나와야 하지만 unsigned int와 int와의 연산이기 때문에 unsigned int가 나오며 따라서 아주 큰 양수가 나오게 될 수 있다.
//Bad
#include <bits/stdc++.h>
using namespace std;
int main(){
vector<int> a = {1, 2, 3};
cout << a.size() - 10 << '\n'; // 18446744073709551609
return 0;
}//Good
#include <bits/stdc++.h>
using namespace std;
int main(){
vector<int> a = {1, 2, 3};
cout << (int)a.size() - 10 << '\n'; // -7
return 0;
}타입 변환시 주의할 점
int a=(int)p*100 //1
int a=(int)100*p //21번 코드만 타입변환이 된다. 순서에 주의!!!
문자를 숫자로, 숫자를 문자로
소문자로 된 문자를 숫자로 바꾸는 로직이 필요하다 생각해보자. ➡️ 아스키코드 이용!!
A~Z는 65~90, a~ z 는 97 ~ 122의 아스키 코드를 가지고 있다.
a부터 시작해 z부터 입력을 받는데 이를 정수 0 ~ 25까지 표현하고 싶다면 다음과 같이 작성한다.
#include <bits/stdc++.h>
using namespace std;
int main(){
char a = 'a';
cout << (int)a << '\n';
cout << (int)a - 97 << "\n";
cout << (int)a - 'a' << "\n";
return 0;
}
/*
97
0
0 */(int)a는 97이라는 값을 가진다. 여기서 97을 빼면 0이다. 또한 ‘a’를 빼게 되면 자동적으로 아스키코드에 매핑되어있는 97을 빼게 되서 0이 된다.
➡️ 일종의 좌표이동이다!
a ~ z를 표현하려면 123의 공간이 필요한데 이를 통해 26의 공간만으로 표현할 수 있다.