[Kotlin 200제] 도서를 읽고 정리한 내용
객체 (Object)
- 소프트웨어 관점에서 객체란, 서로 연관 있는 변수(속성) 들을 묶어놓은 데이터 덩어리를 뜻한다. object에 포함된 변수들은 Property 라고 부른다.
메모리 힙(Heap) 영역
- Stack 영역은 컴파일 시점에 크기가 결정되는 영역 (매개변수, 지역변수 등),
- Heap 영역은 런타임에 크기가 결정되는 영역이다. (동적할당, 객체 등)
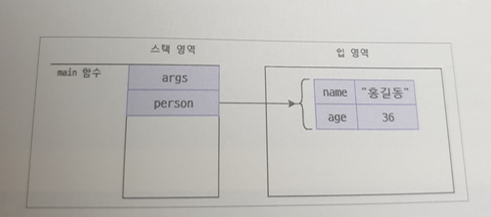
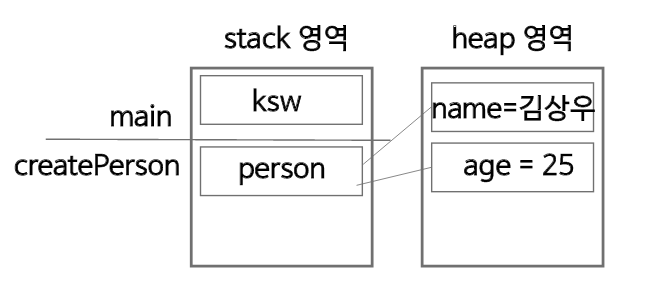
위 코드에서 person 이라는 객체의 좌표를 저장하기 위한 공간 데이터는 stack 영역에, name = "김상우", age = 26의 데이터는 heap 영역에 저장된다.
-> 이 사실이 중요 !
클래스 (Class)
- 클래스를 활용하면 객체를 만드는 틀을 정해서 대량의 객체를 찍어낼 수 있다. 컴공 1학년 때 객체지향 프로그래밍 수업 들으면, 클래스는 붕어빵 틀, 객체는 붕어빵이라는 그닥 와닿지 않는 비유..
- 클래스는 객체를 찍어내기 위한 설계도이다.
- 클래스로부터 생성된 객체는 특별히 Instance(인스턴스)라고 부르기도 한다. Instance는 '구체적인 것'이라는 뜻이다.
- 자바에서 public 클래스는 파일 당 한 개만 존재할 수 있다. 하지만, 코틀린에서는 한 파일 내에 여러 개의 public 클래스를 선언할 수 있다.
- 객체를 생성할 때 사용되는 키워드인 new는 코틀린에서 삭제되었다.
- 코틀린의 기본 접근지정자는, 기본 값이 default인 자바와 달리 public이다. 정보은닉을 중시하는 객체지향 관점에서 보면 조금 의아한 부분이다. 기본 값이 public으로 만들어진 이유는 단순하게도 자바의 수많은 클래스와 메서드들이 public으로 선언 되어있다는 점 때문이었다. 간결한 코드를 중시하는 코틀린의 정신을 엿볼 수 있는 부분이다.
힙 영역의 존재 이유
- 예시를 통해 왜 객체 데이터를 힙 영역에 저장하는지 알아보기
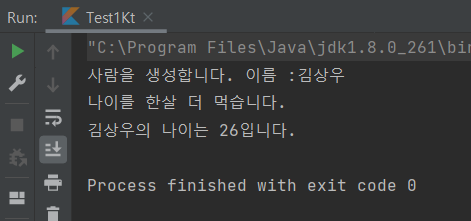
class Person { var name = "" var age = 0 } fun main() { val ksw: Person = createPerson() aging(ksw) howOld(ksw) } fun createPerson():Person { val person = Person() person.name = "김상우" person.age = 25 println("사람을 생성합니다. 이름 :${person.name}") return person } fun aging(person:Person) { person.age += 1 println("나이를 한살 더 먹습니다.") } fun howOld(person:Person) { println("${person.name}의 나이는 ${person.age}입니다.") }
- 먼저, ksw 라는 객체 참조 변수가 stack 영역에 저장된다.
- createPerson 함수를 통해 객체를 생성한다.
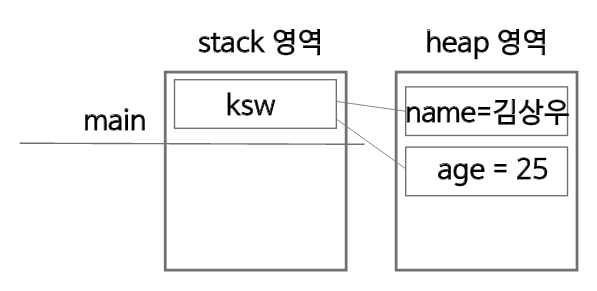
- createPerson 함수가 return 문을 만나며 stack에서 pop된다.
하지만 heap 영역의 객체 데이터는 그대로 남게 된다.
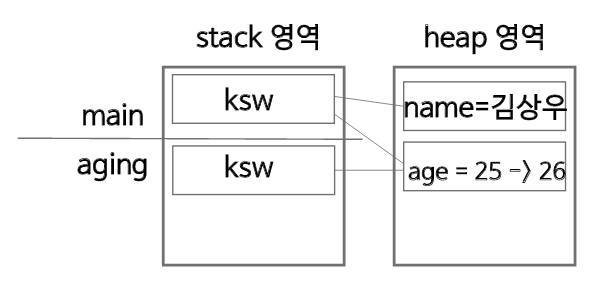
- 그 다음엔 aging 함수가 스택에 쌓이고, 데이터를 처리한다.
후에, 같은 방식으로 aging 함수가 스택에서 pop되고, howOld 함수가 스택에 append 된다.
- 이렇게 함수와 매개 변수가 stack에서 append와 pop을 반복하기 때문에, 객체의 데이터를 따로 보관하기 위해서 별도의 heap 영역을 두는 것이다.

안녕하세요, iOS 와 알고리즘에 대한 글을 씁니다.