activation function, 활성함수는 왜 필요한가
아래는 활성함수가 사용된 코드 한 부분이다.
# ...
model = Sequential()
model.add(Flatten(input_shape = (28, 28))) # in:(28, 28), out:784
model.add(Dense(128, activation='relu')) # in:784, out:128
model.add(Dense(num_classes, activation='softmax')) # in:128, out:10
# ...tensorflow keras를 이용하여 간단하게 구현한 sequential model이다. 먼저 input을 flatten 하고 fc layer를 이용하여 output과 완전 연결 계층을 생성한다. 이때, 입력으로 들어온 데이터(784)가 ReLU와 softmax라는 활성함수를 거치며 출력은 10으로 줄어든다.
여기서 활성함수의 역할을 알 수 있는데, input으로 들어온 feature 중에 어떤 것은 일정값 이상이 되어 통과하고 어떤 것은 통과하지 못하게 되어 그 결과가 output으로 나타난다.
활성함수는 input의 총합이 활성화를 일으킬 정도인지를 정하는 역할이라고 할 수 있다.
일정값 이상이 되지 못하면 탈락! 이런 느낌이다.
수학적으로 접근해보면 활성함수는 비선형 함수로, input에 대한 output의 출력을 비선형으로 만듦으로써 모델의 복잡도를 올리는 중요한 역할을 한다. 비선형 함수가 없다면, 아무리 많은 층을 쌓아도 결국 하나의 선형함수로 표현 가능하기에 층을 깊게 쌓는 것에 대한 의미가 없기 때문이다. (중간에 끊어주는 것이 필요!)
활성함수에는 대표적으로 ReLU, sigmoid, softmax 등이 있다.
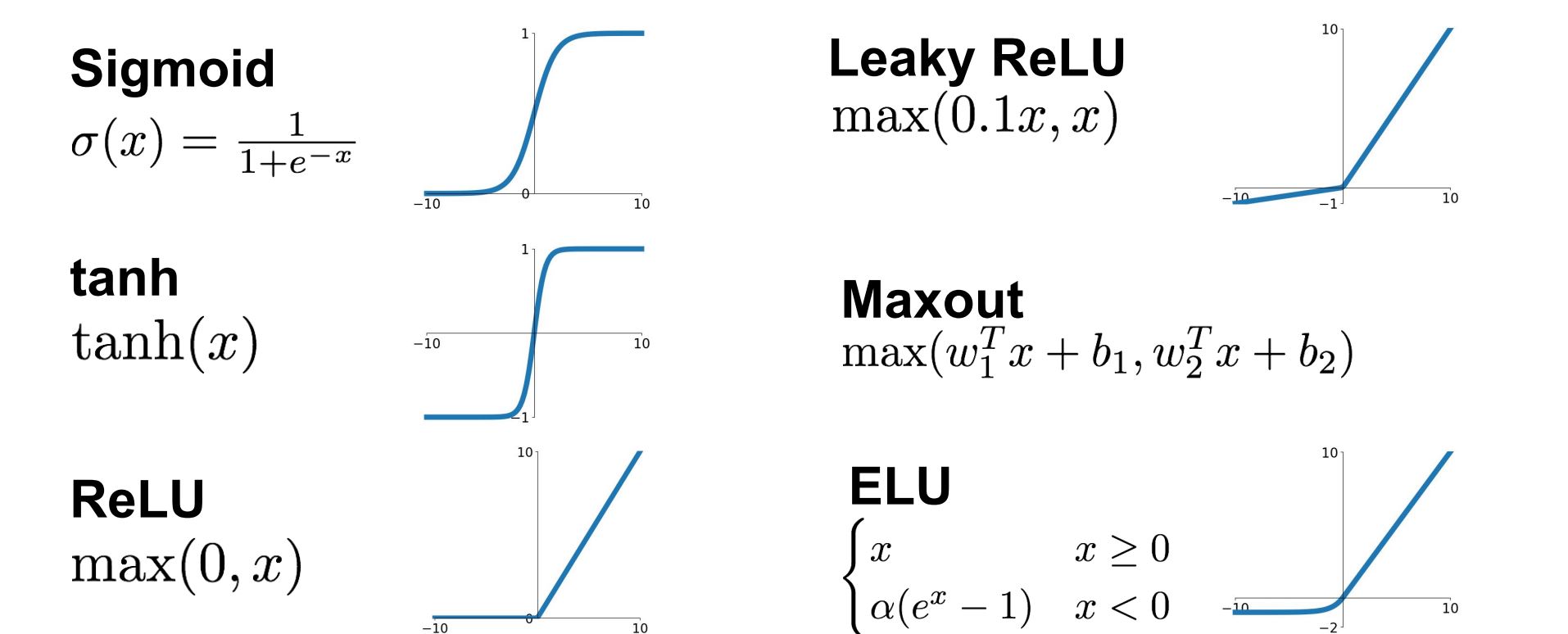
그림출처 : cs231n lecture 6 slide 15
① sigmoid
기존의 step function에서 조금 부드러워진 모양으로, 출력을 0~1 사이로 주는 비선형 함수이다.
문제는 1) 출력 범위가 너무 작고
2) 이 함수의 도함수를 살펴보면 양 끝이 0으로 saturation + 도함수의 최댓값(0.25)도 그리 크지 않아서, sigmoid를 사용한 신경망이 깊어질수록 최소 1/4씩 gradient가 소실된다.
3) 이는 gradient vanishing 문제를 야기하여 제대로 된 값을 다음 layer로 전달할 수 없게 된다.
-> 학습이 잘 되지 않는다.
② ReLU
위의 gradient vanishing 문제를 반 정도 해결해줄 Rectified Linear Unit, reLU 함수는 양극단에 포화되지 않고 exp 함수가 포함되지 않아, 그 계산도 더 효율적이기에 많이 사용되고 있다. 하지만 여기도 음수의 경우 항상 0을 출력한다는 점 때문에 이를 해결하고자 만든 Leaky ReLU, ELU(exponential LU)도 있다.
③ softmax
다중분류에 많이 사용되는 softmax는 1) 입력값을 0~1 사이로, 2) 그 값들의 총합은 1이 되게 하는 함수이다. 이런 특징때문에 여러 분류의 확률로 표현이 가능하여 마지막 출력노드의 활성함수로 많이 사용된다.
비선형 함수는 이정도로 정리하려고 한다. 다 아는 내용이라고 생각했는데 막상 정리하니 더 도움이 많이 되는 것 같다. 생각이 정리된 느낌? 다음에는 optimizer의 종류와 정규화 기법도 정리해봐야겠다.
