오늘은 train/validation/testset의 차이점을 써보려고 한다.
train dataset
모델 학습에 사용되는 train data는 모델이 공부를 할 때,
문제와 정답을 모두 보고 자기것으로 알아가는 과정에서 필요한 dataset이다.
validation dataset
이렇게 공부를 하고 나면 잘 공부했는지 확인하는 과정이 필요하다.
그때 사용하는 데이터가 validation data이다. 모델의 성능을 판단하고 튜닝을 통해 모델을 성능을 높이고자 할 때 사용한다. 즉 모델학습 결과의 feedback 역할이라고 할 수 있겠다.
예를 들면 train의 정확도와 validation의 정확도 차이가 크다고 할 때, 이 모델은 학습과정에서 overfitting 되었다고 판단할 수 있다. 그렇다면 epoch을 낮추거나 regularization을 통해 이를 해결할 것이고, 이를 판단하는 기준을 만드는 데이터가 validation data이다.
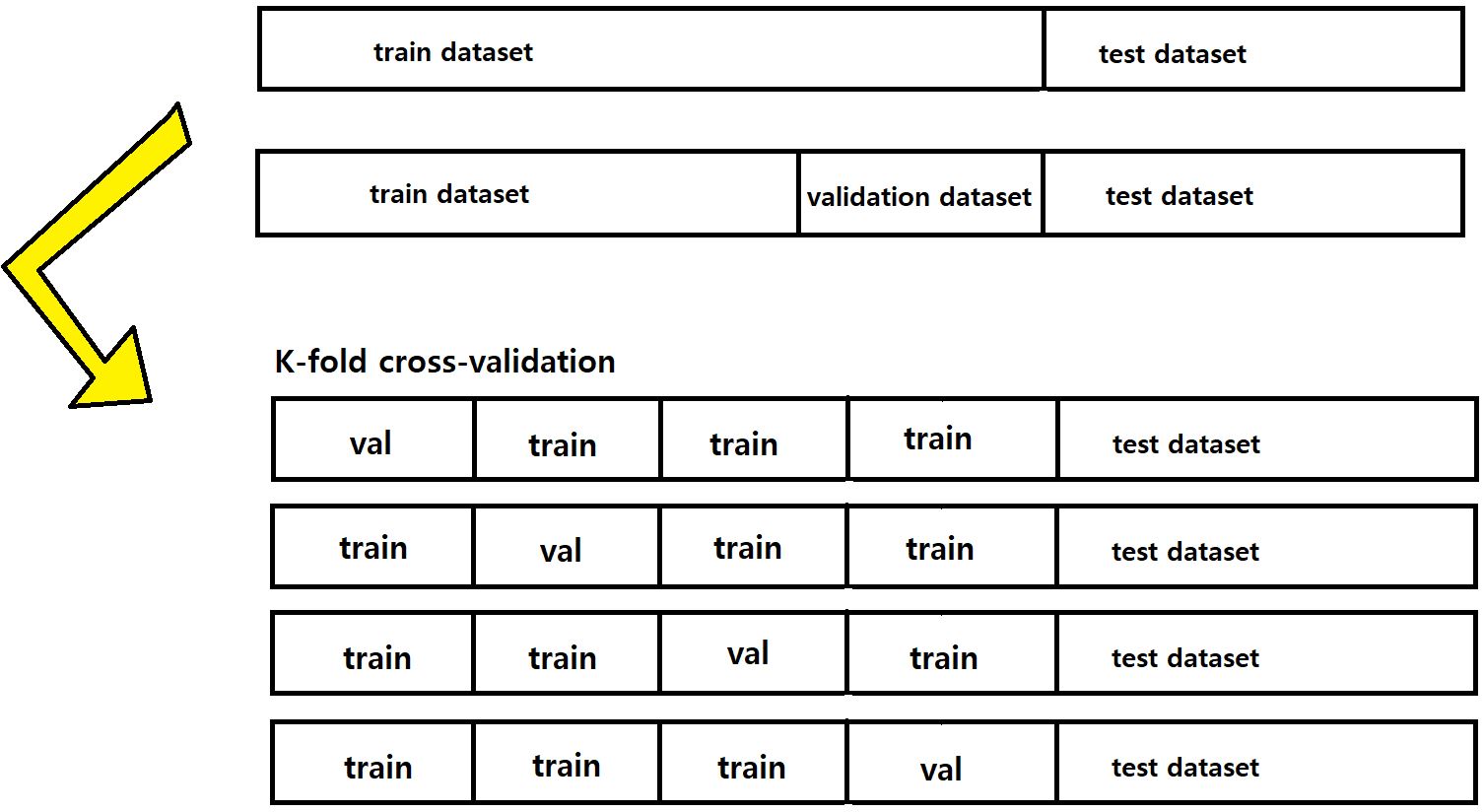
+ 데이터가 부족한 경우, cross-validation을 사용하기도 한다. 이 방법은 k-fold 방식을 통해 데이터를 k개로 나눠 모든 데이터를 train과 validation으로 사용할 수 있다. 보통 이렇게 나온 성능 평가지표 k개의 평균으로 모델의 성능을 평가한다.
test dataset
test data는 모델의 최종 성능을 평가하기 위해 사용한다. 여기서 validation과 다른 점은 학습에는 전혀 관여하지 않는다는 점이다. validation은 여러 평가를 통해 가장 좋은 성능을 뽑기 위해, 모델의 성능을 예측하기 위해 학습의 과정에서 사용된다. 하지만 test set은 모든 학습이 끝난 뒤에 최종적으로 모델의 성능을 평가하기 위해 사용된다.
이는 kaggle에 참가한 것과 비슷하다고 생각하는데, kaggle challenge에 가장 높은 성능의 모델을 제출하기 위해 우리는 학습하고 테스트하는 과정을 반복한다. 여기까지는 내가 갖고있는 데이터를 train과 validation으로 나눠 나름의 진행을 할 것이다. 그리고 제출한 뒤에는 kaggle이 갖고 있는 데이터를 통해 성능을 판단하기 때문에 우리는 제출 전까지 그 결과를 알 수 없다. 모델이 올바르게 학습되었다면 아마 validation에서 나온 결과와 크게 차이나지 않을 것이다.
