[Literature Survey] Semantic Bug Seeding: A Learning-based Approach for Creating Realistic Bugs
Literature Survey

본 게시물은 Semantic Bug Seeding: A Learning-based Approach for Creating Realistic Bugs를 읽고 정리한 내용입니다.
1. Background
버그 시딩의 목적
- Evaluate bug detectors
- Evaluate mutation testing
- Train learning-based bug detectors
버그 탐지(bug detection)나 버그 수정(bug fixing), 버그 예방(bug prevention) 등에 버그 시딩(bug seeding)이 사용될 수 있습니다. 이는 버그 관련 도구를 비교 및 평가하는 데에 사용되는 벤치마크로 사용되며 이 경우에는 현실적인 버그(realistic bug)의 정확한 위치 정보가 필요합니다.
다음 경우인 학습 기반 버그 탐지 기술에 버그를 사용하기 위해서는 많은 양의 training data를 필요로 하며, 이는 과거에 관찰된 버그를 일반화하고 토큰 임베딩을 활용하여 코드의 의미를 추론합니다.
Prior work
- Difficulty of gathering a large number of real bugs
- Prior work often creates unrealistic bugs
- Many tool evaluations are limited to a small number of bugs
기존의 버그 시딩 기법은 세 가지 Issue가 있습니다. 먼저, 많은 양의 실제 버그를 모으기가 어렵고, 기존의 연구들도 비현실적인 버그를 생성합니다. 또한, 많은 도구에 대한 평가는 적은 양의 버그에 제한됩니다.
본 논문에서 구현한 버그 시딩 도구, SemSeed는 기존의 문제점들을 해결하고, 현실적인 버그를 시딩하는 기법을 제안합니다.
- C1 - Where
- C2 - How
- C3 - Unbound Token
버그 시딩 기술에 대해 해당 논문은 세 가지 조건에 대하여 명확히 하고자 합니다. 첫 번째는 버그가 시드되는 위치를 우리가 알고 있으며, 해당 위치에 버그를 시딩하는 것입니다. 두 번째는 identifier와 literal에 대해 버그를 의미적으로 적용시키는 것입니다. 세 번째는 Unbound Token에 대하여 임베딩 스페이스와 의미적으로 구현한 맵에 대하여 쿼리를 주고 알맞은 토큰을 매칭시키는 것입니다.
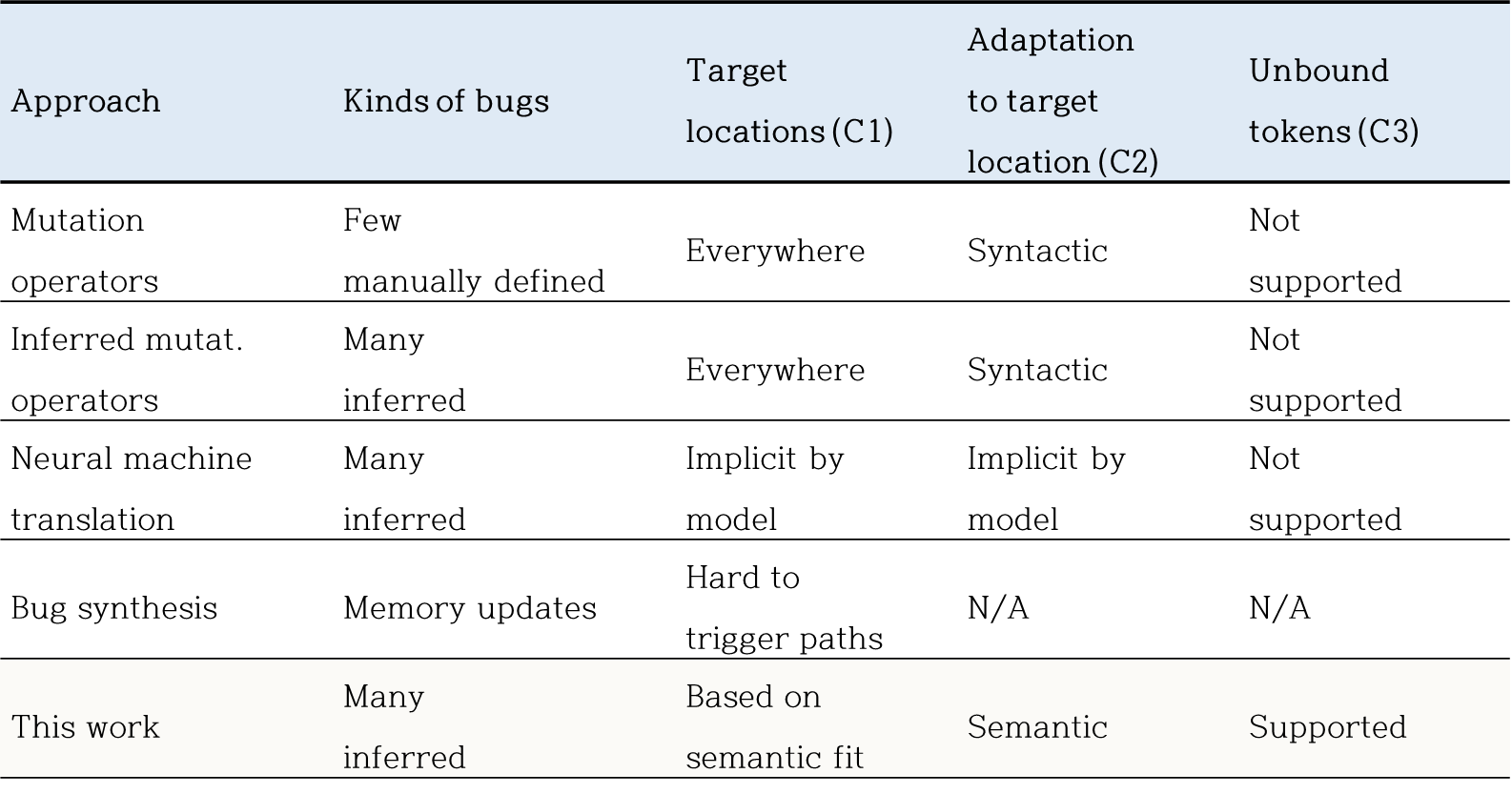
먼저 Mutation operator는 미리 정의된 코드 변환을 기반으로 버그를 시드합니다. 하지만 이는 realistic한 버그를 만들어내지 못합니다. 두 번째로 이전의 버그를 통해 유추하는 Mutation operator는 첫 번째 Mutation operator와 마찬가지로 버그 시딩이 의미적으로 해당 위치에 시딩하는 것이 적합한지와 적용하는 방법에 대하여 고려하지 않습니다. 세 번째로 Neural machine translation은 버그 수정으로부터 학습을 통해 버그를 시딩하지만 이에 대한 버그 시딩의 위치나 버그가 시딩되는 방법은 해당 모델에 숨겨져 있습니다. 마지막으로 fuzz 테스트 도구 평가를 목표로 하는 버그 시딩 기술은 비교적 현실적인 버그 시딩을 수행하지만 정적으로 탐지가 가능하기 때문에 bug detector를 평가하거나 training 시키기에 적합하지 않습니다.
해당 논문에서 제시하는 기술을 제외한 모든 선행 연구는 바운딩되지 않은 토큰이 존재하는 버그의 경우에는 시딩을 수행하지 못합니다.
결과적으로 해당 논문에서 제시하는 버그 시딩은 semantic을 기반으로 시딩 위치를 선정하고, Unbound 토큰에 대하여 토큰 임베딩 기술을 활용함으로써 보다 다양한 버그를 시딩할 수 있습니다.
2. Approach
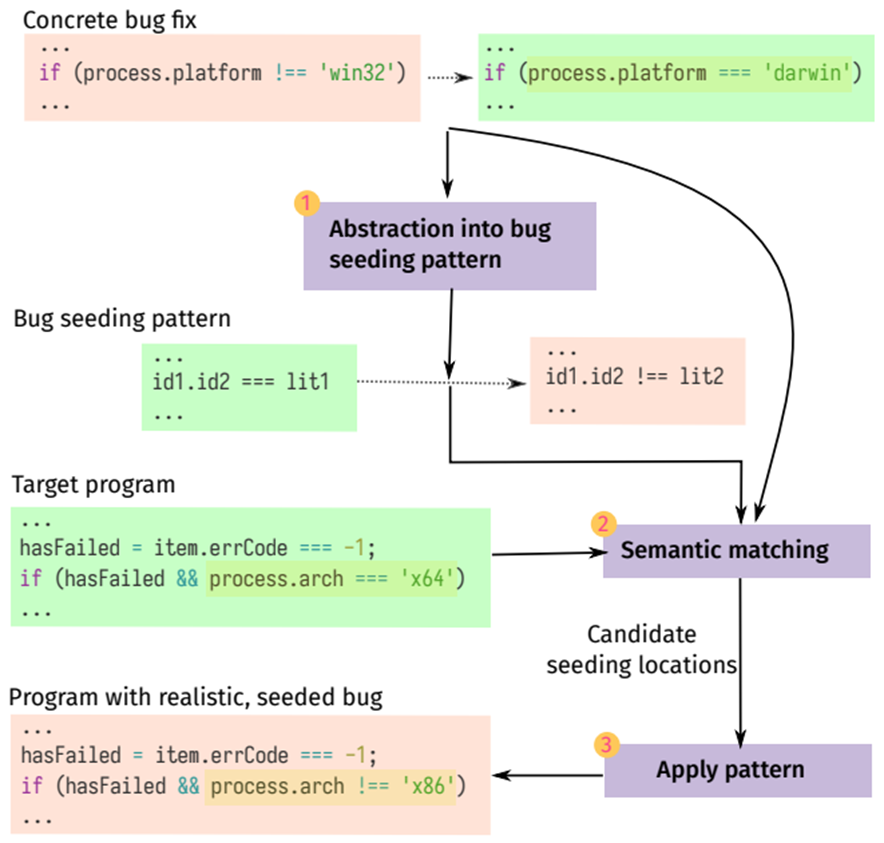
해당 논문에서 제시하는 버그 시딩 기술인 SemSeed는 다음 세 가지 과정을 거치게 됩니다.
- Abstraction
- Semantic matching
- Pattern Application
첫 번째 단계는 버전 기록에서 버그 수정에 필요한 정보를 추출하는 것입니다. 이는 새로운 버그를 시딩하기 위해 버그 시딩 패턴의 구문적인 변환을 위해 시딩 패턴과 토큰 정보를 추출하는 과정입니다.
두 번째 단계는 의미적으로 유사한 위치에만 버그 시딩 패턴을 적용하도록 Target 프로그램의 시딩 위치를 찾습니다.
세 번째 단계는 실제 패턴을 적용하는 단계입니다.
1. Abstraction
첫 번째 단계로 버그 시딩 패턴을 추출하기 위한 단계입니다.
이는 또한 크게 세 가지 단계를 거치게 됩니다.
- Selecting Bug-Fixing Commits (One-line bugs)
- Extracting Concrete Changes From Commits
- From Concrete Fixes to Bug Seeding Patterns
첫 번째로 버그 수정 커밋을 수집하는 과정으로 이 때 SemSeed는 “bug”, “fix”, “error”, “issue”, “problem”, “correct” 중의 하나를 커밋 메시지로 포함하는 버그 수정 커밋을 찾습니다. 병합된 커밋을 가져오는 것을 방지하기 위해 상위 커밋이 하나인 커밋만을 수집하며, 변경된 파일 수가 1개 보다 많은 경우는 포함하지 않습니다. 마지막으로 One-line bug에 대해서만 수집을 하게 됩니다.
두 번째로 커밋으로부터 실제 버그 수정 변화를 추출하는 것으로 일부 컨텍스트와 함께 변경된 토큰을 고려합니다.
세 번째로 버그 시딩을 위해 버그 수정을 일반화하고, identifier와 literal 토큰으로 버그 패턴을 추출합니다.
버그 코드와 수정 코드의 시퀀스

버그 수정은 다음과 같이 버그가 있는 코드의 토큰 시퀀스와 버그가 수정된 코드의 토큰 시퀀스로 추출되며, 이는 Abstract Syntax Tree로 표현됩니다.
버그 시딩 패턴 추출

버그 시딩 패턴을 이전에 추출한 토큰 시퀀스를 통해 구할 수 있으며, 토큰은 identifier나 literal로 표현 가능합니다. 여기서 패턴이 한 번만 발생하고, 40개 이상의 토큰을 가지는 패턴은 모호한 패턴 교육을 피하기 위해 무시합니다.
2. Semantic Matching
버그 시딩의 위치를 찾기 위해서 추출한 패턴의 P correct와 타겟 프로그램의 토큰 시퀀스가 일치하는 위치를 탐색합니다. 이를 통해 우리는 C1에 대한 조건을 만족할 수 있습니다.
시맨틱 매칭은 크게 세 가지 단계로 나누어집니다.
- Extracting Token Sequences from Target Program
- Syntactic Matching
- Semantic Matching
토큰 시퀀스 추출
먼저, 타겟 프로그램의 토큰 시퀀스를 추출하고, 이를 구문적으로 접근한 후에 의미적으로 접근하게 됩니다. 대상 프로그램에 대하여 추출한 토큰 시퀀스는 다음과 같이 나타낼 수 있습니다.
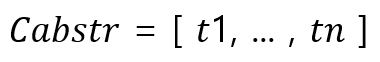
구문적 패턴 매칭

해당 토큰 시퀀스를 첫 번째 과정에서 추출한 버그 시딩 패턴과 구문적으로 매칭합니다.
의미적 패턴 매칭
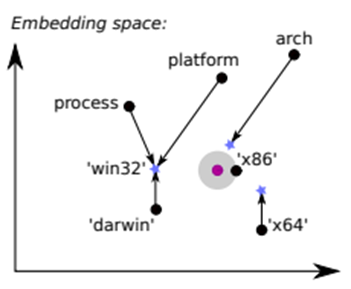
Realistic한 버그 시딩을 보장하기 위해서 의미적으로 유사한 버그 수정에 초점을 맞춥니다. 의미적으로 유사한 버그 수정을 위해서는 임베딩 맵을 사용하게 되며, 각 토큰을 벡터로 표현해 맵에 표현하게 됩니다.
3. Pattern Application
세 번째 단계로 실제 추출한 패턴을 적용시키는 과정입니다. 우리가 주목해야 할 부분은 시딩 패턴에서 새로 만들어줘야 할 리터럴 부분입니다.
이 부분에 대하여 버그를 시딩할 때 새로운 토큰을 만들어줘야 하기 때문에 이를 주목할 필요가 있습니다.
또한, 이 접근법에서 임베딩 스페이스로부터 구하고자 하는 토큰을 유사성에 따라 기존의 데이터를 통해 찾게 됩니다. 이 때 유추를 위한 쿼리를 임베딩 스페이스에 날려 해당 토큰을 구하게 됩니다.
3. Experimental Results
해당 논문에서는 해당 접근법이 얼마나 효과적인지 확인하기 위해 다음 6가지 질문에 대하여 실험 결과를 논합니다.
- RQ1: How effective is SemSeed in reproducing real-world bugs?
- RQ2: How does SemSeed compare to a semantics-unaware variant of the approach?
- RQ3: What is the impact of the configuration parameters of the approach?
- RQ4: How useful are the seeded bugs for training a learningbased bug detector?
- RQ5: How do the seeded bugs compare to bugs created with traditional mutation operators?
- RQ6: How efficient is SemSeed in seeding bugs?
RQ1: Effectiveness in Reproducing Real-World Bugs

첫 번째 실험은 이 접근법이 얼마나 기존 버그를 재현하는지에 대한 실험입니다.
실제 버그 수정 커밋을 추출한 결과 151개의 결과를 도출할 수 있었으며, 해당 버그의 Unbound Token을 포함하는 토큰 셋을 가지는 경우는 53개의 결과를 도출하였습니다.
이에 대하여 선행 연구인 추론을 통한 Mutation operator는 16개의 버그를 재현했으며, 이는 Unbound Token을 대체하지 못하기 때문에 재현하지 못하는 버그가 있음을 확인했습니다. SemSeed는 6개를 제외한 나머지 버그를 모두 재현하는 것으로 확인했습니다.
RQ2: Comparison with Semantics-Unaware Bug Seeding

두 번째 실험은 시맨틱을 판단해 시딩하는 것의 중요성을 나타내기 위한 실험입니다.
시맨틱을 파악하지 않은 SemSeed는 유사한 Unbound Token을 대체하지 못하기 때문에 16개의 버그만을 재현했습니다.
RQ3: Impact of Configuration Parameters
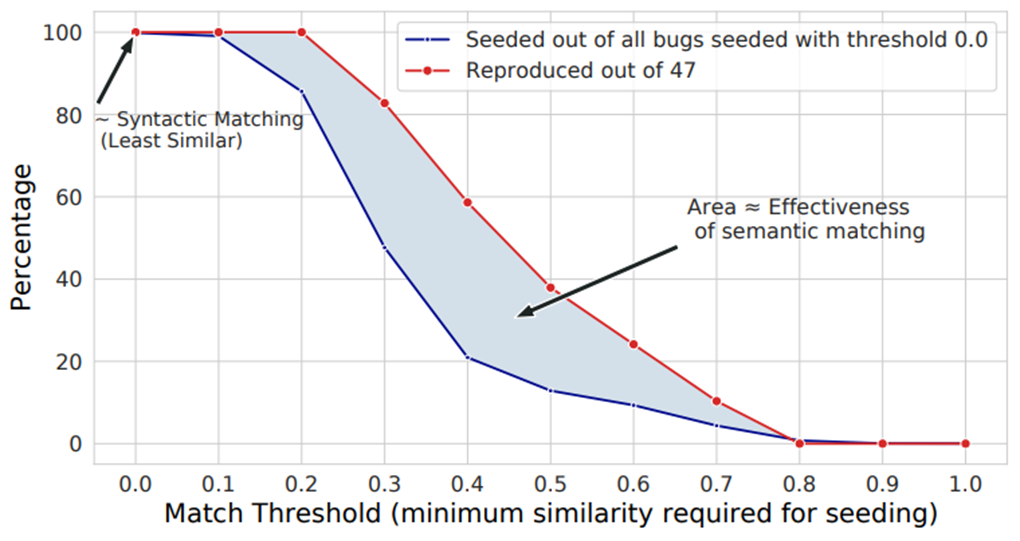
세 번째 실험은 버그 패턴을 적용하기 위해서 시맨틱 유사성을 파악하고 버그 시딩 위치를 결정하게 되는 이를 조절하는 임계값에 따른 접근법의 효과를 나타내는 실험입니다.
파란색 선은 구문적으로만 접근했을 때의 결과이며, 빨간색 선은 시맨틱 관점에서의 고려를 한 접근법입니다. 임계값이 0.4인 경우 모든 위치 중 약 20%를 재현하는 구문적으로만 접근한 결과와 달리 논문에서 제시하는 접근법은 60%를 재현하고 있습니다.
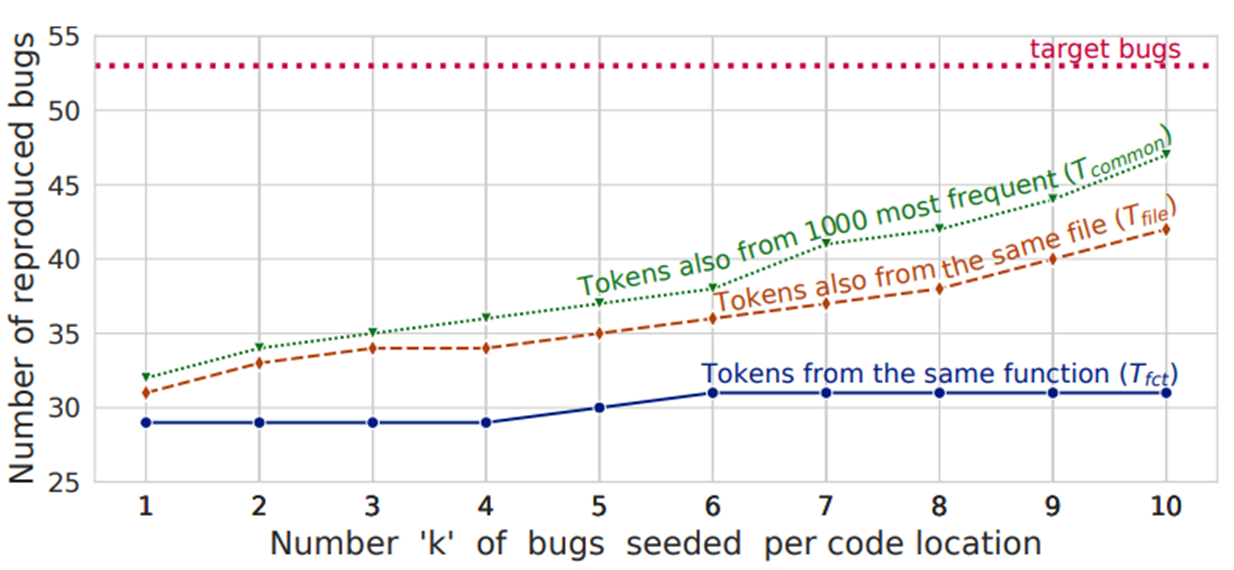
파란색 선은 버그가 시드되는 함수에서만 Unbound Token을 검색했을 때의 재현한 결과이며, 주황색 선은 버그가 시드된 파일의 모든 토큰을 검색했을 때의 재현한 결과입니다.
초록색 선은 파일 뿐만 아니라 1000개의 자주 사용되는 토큰을 검색했을 때 재현한 결과로 많은 토큰셋을 포함할 수록 재현율이 높아지는 모습을 확인할 수 있습니다.
RQ4: Usefulness for Training a Learning-Based Bug Detector
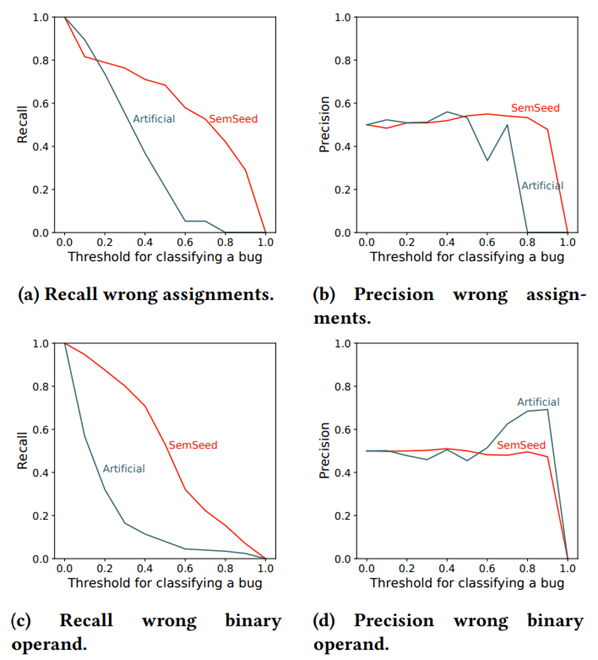
네 번째 실험은 학습 기반의 버그 디텍터에 대항 유용성 실험으로 Semseed를 활용해 생성한 버그를 통해 학습한 버그 디텍터가 더 많은 버그를 발견하는 것으로 확인할 수 있습니다.
RQ5: Comparison with Traditional Mutation Operators
SemSeed가 생성한 버그의 대부분은 기존 mutation operator로 생성된 버그에 비해 훨씬 많은 양을 도출할 수 있었습니다. SemSeed는 1,000개의 파일로부터 677,217개의 버그를 생성할 수 있었습니다.
RQ6: Efficiency
- 1,000 files -> 677,217 bugs
- 140 minutes for seeding 677,217 bugs
- 100 Bugs/sec.
48 Intel Xeon E5-2650 CPU cores and 64GB의 환경에서 실험한 결과는 다음과 같이 도출할 수 있었습니다. Unbound를 찾기 위해 임베딩 스페이스로 쿼리를 날리는 시간이 시간 효율성에 많은 영향을 줍니다.
4. Conclusions
Contributions
- Generating realistic bugs
- Semantically matching seeding location
- Binding unbound tokens based on token embedding map
해당 접근법의 기여로는 의미적으로 시딩 위치를 찾고, 토큰 임베딩을 적용한 최초의 버그 시딩 기술로써 보다 현실적인 버그를 많이 생성할 수 있습니다.
Limitations
- Only focus on single-line bugs
- Only focus on static bug seeding
- Unidentified target program work
- Unidentified in other programming languages
하지만 이 접근법은 한 줄 버그만을 수집하기 때문에 여러 줄로 이루어진 버그를 시딩하지는 못합니다.
또한, 해당 논문에서는 정적 버그 시딩만을 비교했으며, 타겟 프로그램의 실행 결과는 확인하지 않았습니다.
마지막으로 해당 논문에서는 많이 사용하는 JavaScript 언어로만 확인했기 때문에 다른 언어에서도 잘 동작할지에 대한 확인을 필요로 합니다.
