DB Replication 적용해보자
행록 프로젝트를 진행하면서 DB 서버가 날아가는 일 발생...!
물론 dev용 DB라서 괜찮았지만, prod용이었다면... 🥲
DB를 실수로 날리더라도, 금방 복구할 수 있게 DB Replication을 적용해보기로 했다!
(복제하는 김에 read/write 여부에 따라 가리키는 DB를 다르게 해보려고 한다! write는 source DB를 사용하고, read는 replica DB를 사용하게 해서 DB 부하를 낮추려고 한다. 물론 사용자가 적어서 분산안해도 되지만... 이번 기회 아니면 언제 함~~)
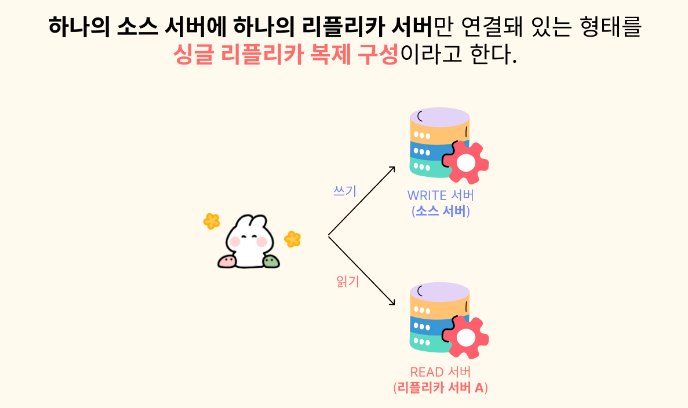
복제 구성은 싱글 레플리카 복제 구성으로 하려고 한다.
DB 서버 생성
AWS에서 t4g.micro 10GiB로 인스턴스 두 개를 만들었다. 각각의 인스턴스에 source DB와 replica DB를 구축할 예정이다.
EC2를 생성했다면, 안에서 MySQL을 설치하자.
$ sudo apt-get update
$ sudo apt-get install mysql-server
$ sudo systemctl start mysql
$ sudo systemctl enable mysql
# 설치 끝 접속
$ sudo /usr/bin/mysql -u root -p설치후, Database까지 만들어준다. 이 때 Source와 Replica의 DB명은 같아야 하므로 똑같은 이름으로 만들어주자. (달라도 설정을 추가하면 연결할 수 있는 방법이 있을 것 같지만, 딱히 다르게 할 이유를 모르겠어서 그냥 똑같은 이름으로 만들었다.)
DB Replication 적용
1) Source - Replica 접근 권한 추가
- Source와 Replica 두 서버에서 계정을 생성해 복제 권한을 준다.
create user 'hanglog-db-replica'@{replica_ip} identified by '{password}';
GRANT REPLICATION SLAVE ON *.* TO 'user'@'%';
FLUSH PRIVILEGES;create user 'hanglog-db-replica'@'%' 처럼 와일드 카드도 가능한듯
2) MySQL 외부에서 접속 가능하도록 변경
- MySQL은 기본적으로 127.0.0.1 즉, 로컬 호스트에서만 접속할 수 있음
/etc/mysql/mysql.conf.d/mysqld.cnf에 들어가서bind-address와mysqlx-bind-address설정을 주석처리해준다.
#bind-address = 127.0.0.1
#mysqlx-bind-address = 127.0.0.13) 기존 Source DB데이터를 Replica로 복사
현재 우리의 Source DB는 단일 DB로서 이미 사용중인 DB였다. 그래서 Source DB에 있는 데이터를 Replica로 전부 옮겨주는 과정이 필요했다.
# Source DB에서 데이터 Dump한 백업 sql 생성
$ mysqldump -u [사용자 계정] -p [원본 데이터베이스명] > [생성할 백업 파일명].sql
$ mysqldump -u root -p hanglog_dev > 2023_10_12_hanglog_dev_backup.sql
# Source 서버에서 scp를 사용해 Replica 서버로 파일 이동
$ scp -i {db pem 키} {이동시킬 파일} ubuntu@{이동시킬 서버 IP}:/home/ubuntu
$ scp -i hang-log-db.pem 2023_10_12_hanglog_dev_backup.sql ubuntu@{replica_ip}4:/home/ubuntu
# 복원 전에 Replica 서버에서 DB 생성
mysql> CREATE DATABASE hanglog_dev;
# Replica 서버에서 이동 받은 sql 파일을 사용해 데이터 복원
$ mysql -u [사용자 계정] -p [복원할 DB] < [백업된 DB].sql
$ mysql -u root -p hanglog_dev < 2023_10_12_hanglog_dev_backup.sql
4) Source 서버 설정
#/etc/mysql/mysql.conf.d/mysqld.cnf
server-id=1
log_bin = hanglog-bin
sync_binlog = 1
binlog_format = MIXED
replicate-do-db = hanglog_dev
replicate-do-db = hanglog_prod
- server-id : 서버의 ID. 레플리케이션 토폴로지 내의 서버는 각각 고유한 서버 ID를 가져야한다. 즉, 이 값은 레플리카 서버와 반드시 달라야한다.
- log-bin : 바이너리 로그 파일 이름 설정 (
/var/lib/mysql/mysql-bin.XXXXXX형식으로 저장됨) 디폴트 명은binlog- sync_binlog : N개의 트랜잭션 마다 바이너리 로그를 디스크에 동기화 시킬지 결정한다.
1은 가장 안정적이지만, 가장 느린 설정이다.- binlog_format : 바이너리 로그의 저장 형식을 지정한다.
STATEMENT,ROW,MIXED이 3가지 중 하나를 선택할 수 있다. 자세한 차이점은 공식문서를 확인하자. 여기도 쉽게 잘 정리해놨다- max_binlog_size : 바이너리 로그의 최대 크기
- expire-logs-days : 바이너리 로그가 만료되는 기간 설정
- binlog_do_db : 레플리케이션을 적용할 데이터베이스 이름 설정. 설정하지 않으면, 모든 데이터베이스 대상으로 레플리케이션이 진행된다.
- replicate-do-db : 복제할 db 지정
설정 후, Source 서버 상태를 조회해서 잘 적용이 되었는 지 확인한다.
mysql> SHOW MASTER STATUS;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| hanglog-bin.000092 | 15743 | | | |
+---------------+----------+--------------+------------------+-------------------+
설정이 잘 적용되었다면, Source DB를 재시작한다.
$ sudo systemctl restart mysql5) Replica 서버 설정
Source와 마찬가지로 설정을 추가한다.
# /etc/mysql/mysql.conf.d/mysqld.cnf
server-id= 2 # Source와 무조건 아이디가 달라야 한다.
relay_log=hanglog-relay-bin
relay_log_purge=ON
read_only=1
replicate-do-db = hanglog_dev
replicate-do-db = hanglog_prod
- relay_log: 릴레이 로그 파일 경로 설정
- relay_log_purge: 필요 없는 릴레이 로그 파일을 자동으로 삭제하는 옵션
- read_only: 읽기 전용 설정
마찬가지로 sudo systemctl restart mysql명령어를 사용해 DB를 재시작해준다. Source에서 확인한 binary log와 Position을 설정해준다. (근데 stop안하고 위에서 바로 해도 될 것 같긴한데, 일단 진행한 대로 기록해두겠다. 이후 수정하겠음 헷)
STOP REPLICA;
CHANGE REPLICATION SOURCE TO
SOURCE_HOST='{source_ip}',
SOURCE_USER='hanglog-db-replica',
SOURCE_PASSWORD='{password}',
SOURCE_LOG_FILE='hanglog-bin.000092',
SOURCE_LOG_POS=15743,
GET_SOURCE_PUBLIC_KEY=1;
START REPLICA;Replica에서도 mysql> SHOW REPLICA STATUS;를 통해 복제 설정 내용을 확인할 수 있다.
만약 이 과정에서 에러가 났다면, 상세한 에러 내용을 아래 명령어를 통해 볼 수 있다.
select * from performance_schema.replication_applier_status_by_worker;복제 에러났을 때, 에러를 고쳐도 계속 같은 에러가 나는 경우 :
mysql> stop replica; mysql> set global sql_replica_skip_counter=1; mysql> start replica;replica서버 stop한 다음 error 스킵하고 재실행하면 될 수도 있음
6) 적용 확인 테스트
Source서버에서 임의로 테스트용 table을 생성한 후, Replica 서버에서도 해당 table이 생성되었는 지 확인해보자.
이렇게 Source DB와 Replica DB 설정을 완료했다. 다음에는 SpringBoot에서 각 DB로 read, write 요청을 나눠보낼 수 있게 설정을 해보자.
Read/Write DB 분리
두 개의 DB가 생긴김에, Spring boot에서 write 작업을 하는 쿼리는 Source DB를 가리키고, read 작업을 하는 쿼리는 Replica DB를 가리키게 해서 부하를 낮춰보려고 한다!
source, repllica DB 설정
application.yml에서 두 개의 datasource를 등록한다.
spring:
datasource:
source:
username: user
password: password
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://172.1.2.3:3306/hanglog_dev
maximumPoolSize: 15
poolName: HikariCP
readOnly: false
replica:
username: user
password: password
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://172.1.2.4:3306/hanglog_dev
maximumPoolSize: 15
poolName: HikariCP
readOnly: trueDataSourceType 생성
두 DataSource를 가리키는 Enum 객체를 생성했다. 이 Enum객체는 나중에 DataSource객체를 가져오는 key로 사용할 것이다.
public enum DataSourceType {
SOURCE, REPLICA;
DataSourceType opposite() {
return this == SOURCE ? REPLICA : SOURCE;
}
}determineCurrentLookupKey() 오버라이드
스프링은 AbstractRoutingDataSource의 determineCurrentLookupKey() 메서드를 사용해서 어떤 datasource를 가져올지를 결정한다. RoutingDataSource는 private Map<Object, DataSource> resolvedDataSources; 다음과 같이 Map으로 관리되는데, determineCurrentLookupKey() 가 반환하는 key를 사용해서 Map에 저장된 DataSource를 설정한다.
우리는 위에서 생성한 Enum객체를 key로 사용할 것이다. 트랜잭션의 read-only여부에 따라 Read는 REPLICA를 반환하게, Write는 Source를 반환하게 설정한다.
처음 해보는 작업이라 잘 동작할지 불안해서 로깅을 추가했다.ㅎㅎㅎ
@Slf4j
public class RoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
final String currentTransactionName = TransactionSynchronizationManager.getCurrentTransactionName();
final boolean isReadOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
if (isReadOnly) {
log.info(currentTransactionName + " Transaction:" + "Replica 서버로 요청합니다.");
return REPLICA;
}
log.info(currentTransactionName + " Transaction:" + "Source 서버로 요청합니다.");
return SOURCE;
}
}
@Transactional에 인터셉트해서 read-only 설정 여부를 알아와야하는 건가?? 했는데TransactionSynchronizationManager.isCurrentTransactionReadOnly()로 read-only여부를 알 수 있다고 한다!
DatasourceConfig 설정
@Profile({"dev", "prod"})
@Configuration
public class DataSourceConfig {
private static final String SOURCE_SERVER = "SOURCE";
private static final String REPLICA_SERVER = "REPLICA";
// application.yml 설정을 통해 Source와 Replica의 DataSource 객체를 생성한다.
@Bean
@Qualifier(SOURCE_SERVER)
@ConfigurationProperties(prefix = "spring.datasource.source")
public DataSource sourceDataSource() {
return DataSourceBuilder.create().build();
}
@Bean
@Qualifier(REPLICA_SERVER)
@ConfigurationProperties(prefix = "spring.datasource.replica")
public DataSource replicaDataSource() {
return DataSourceBuilder.create().build();
}
// 위에서 만든 DataSource를 RoutingDataSource에 등록한다(key가 Enum객체인 Map을 만들어 저장)
@Bean
public DataSource routingDataSource(
@Qualifier(SOURCE_SERVER) final DataSource sourceDataSource,
@Qualifier(REPLICA_SERVER) final DataSource replicaDataSource
) {
final RoutingDataSource routingDataSource = new RoutingDataSource();
final HashMap<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(SOURCE, sourceDataSource);
dataSourceMap.put(REPLICA, replicaDataSource);
routingDataSource.setTargetDataSources(dataSourceMap);
routingDataSource.setDefaultTargetDataSource(sourceDataSource);
return routingDataSource;
}
@Bean
@Primary // dataSource빈 중 우선순위 가장 높게!
public DataSource dataSource() {
final DataSource determinedDataSource = routingDataSource(sourceDataSource(), replicaDataSource());
return new LazyConnectionDataSourceProxy(determinedDataSource);
}
}
LazyConnectionDataSourceProxy?
스프링은 @Transactional설정이 초기화되기전에 트랜잭션 정보를 읽어온다. 아래는 JpaTransactionManager의 트랜잭션을 시작하는 doBegin 메서드인데, 저기서 @Transactional(readOnly = true)을 읽기전에 트랜잭션 정보를 초기화한다. 디폴트 값으로 초기화하는 것 같은데 항상 readOnly=false로 초기화된 커넥션이 생성된다.
@Transactional(readOnly = true)설정은 이후에
TransactionSynchronizationManager.setCurrentTransactionReadOnly를 통해 설정된다.
@Override
protected void doBegin(Object transaction, TransactionDefinition definition) {
...
Object transactionData = getJpaDialect().beginTransaction(em,
new JpaTransactionDefinition(definition, timeoutToUse, txObject.isNewEntityManagerHolder()));
txObject.setTransactionData(transactionData);
txObject.setReadOnly(definition.isReadOnly());
}
즉, read-only여부를 결정하기 전에 트랜잭션을 수행할 커넥션을 생성해버리기 때문에 항상 read-only = false와 연결된 Source DB를 가리키게 된다.
하지만 LazyConnectionDataSourceProxy를 사용하면 실제 커넥션을 가져오는 순간을 늦춰, @Transactional(readOnly = true)가 반영된 이후 실제 커넥션을 사용해야하는 순간이 올 때 커넥션을 획득한다.
dataSource()메서드를 통해 DataSource를 반환할 때, LazyConnectionDataSourceProxy로 감싸 반환해주자.
실행하면 Read/Write여부에 따라 알맞은 DB에 연결하는 것을 볼 수 있다!
더 고민해볼 것
현재 Source가 다운될 경우 Replica가 승격된다거나, Replica가 다운될 경우 Source가 대신 요청을 받는 설정은 없다.
MySQL 설정으로 이를 구현하기는 어려울 것 같고, Spring boot에서 transaction이 DB 다운 서버로 인해 실패했을 경우, 다른 DataSource를 사용해서 재시도하는 로직을 추가해볼까? 하는 고민을 했었다.
그런데 AWS RDS를 사용하면 DB가 다운됐을 때, Replica를 알아서 승격시켜주는 등 설정이 잘 되어있다는 소리를 들어서 일단은 보류되었다 . . . !
우테코가 끝나면 우테코가 제공해주는 인스턴스를 반환하고, 다시 서버를 구축해야하니까 그 때는 RDS를 사용해보면 좋지않을까 ...
참고
-
행록 라온&이오의 집단지성 포스팅
-
https://hudi.blog/database-replication-with-springboot-and-mysql/
스페셜 땡스투

여기도 무뇽이가..!!! 레플리케이션 맛있네요 냐미