SLA내에서 성능을 발휘하지 못하는 구간을 병목 구간이라고 부른다. 개발자는 병목 구간을 우선적으로 개선해야한다. (처리량(Throughput)의 경우 가장 낮은 구간이 전체 시스템의 처리량 성능이 되므로 병목 구간을 개선하는 것이 특히 중요하다.)
병목 현상은 하드웨어 리소스 제한, 소프트웨어 리소스 제한, 심지어 잘못 작성된 코드 등 무엇이든 병목 현상이 될 수 있다. 병목 현상을 어떻게 잘 식별하고, 개선할 수 있을까?
현재 Grafana를 통해 성능 테스트 메트릭을 모니터링하고 있다. 그런데 성능 테스트를 해본 경험이 없어서 메트릭의 어느 부분을 비교하면서 병목 현상을 해결해야할지 잘 감이 오지 않았다.(그래프... 너무 많다. 뭘 중점적으로 봐야할지 아찔하다.) 어떻게 병목 현상을 식별하면 좋을 지 검색하던 중 좋은 포스팅을 발견하였다. 해당 포스팅에서 언급한 예제들을 보면서 어떻게 병목 현상을 식별해야하는 지를 연습해보려한다.
Trending
Trending은 성능 문제의 동작과 빈도를 살펴보는 기법이다. Trending은 user metrics(ex. response time)과 server metrics(ex. CPU utilization)에 대해 수행할 수 있다.
문제가 얼마나 자주 발생하는지, 일관적인지, 일회성인지를 파악해야한다.
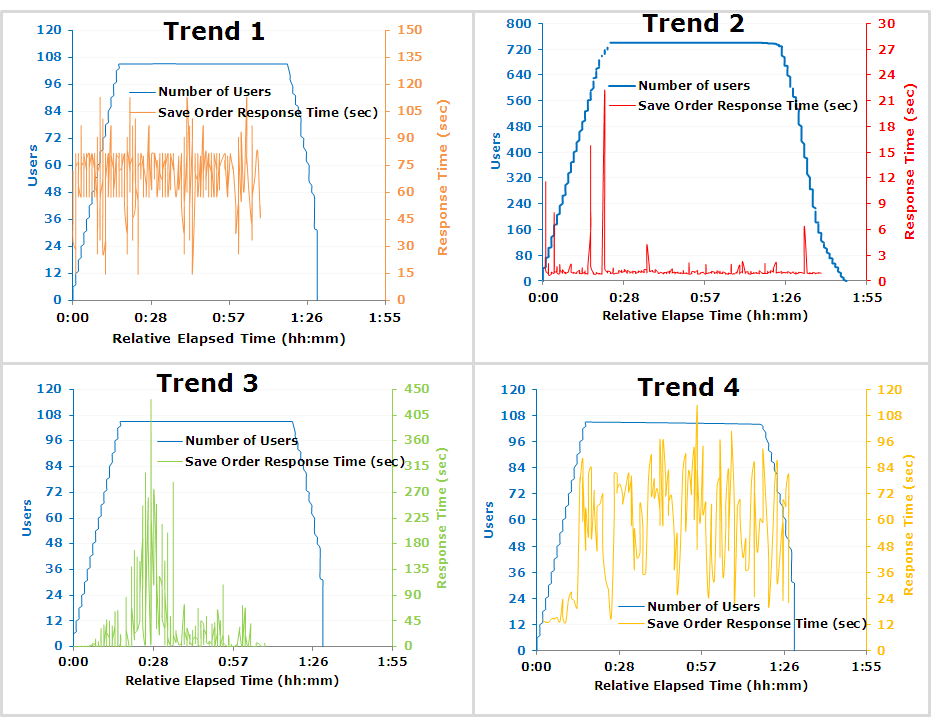
예시를 봐보자. 주문 저장 API에 대한 사용자 부하와 응답시간에 대한 그래프 예시이다. 응답 시간 SLA는 5초라고 가정하겠다.
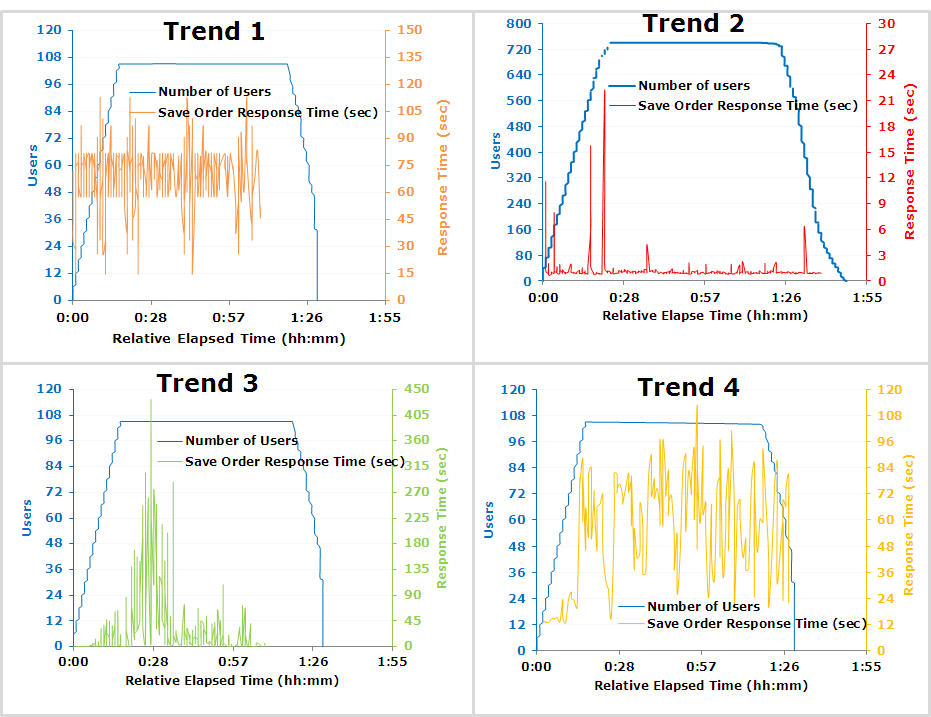
Trend 1의 경우, 부하로 인해 응답 시간이 낮아졌지만 일관된 응답 시간을 보이는 것을 알 수 있다. 변동이 있긴 하지만 장기간에 걸쳐 비교적 일관적인 그래프를 보인다. 이는 사용자 부하가 응답 시간에 큰 영향을 미치지 않는다고 판단할 수 있다. 즉, 사용자 부하가 없어도 응답 시간은 SLA내에 있지않으며 다른 곳에서 병목 현상이 일어나고 있다는 것을 알 수 있다.
Trend 2의 경우, 아주 짧은 급증 구간외에는 전부 SLA내에 있다. 부하가 높은 상황에서도 5초 미만의 응답시간을 보인다. (개선 우선도가 낮다는 것을 의미하는 듯)
Trend 3의 경우, 사용자 부하가 10-120명인 구간을 제외하고는 일정한 응답시간을 가진다. 이 그래프는 잠재적으로 리소스 병목 현상을 가리킨다. (thread size를 의미하는 듯)
Trend 4의 경우, 사용자 부하가 증가함에 따라 응답 시간이 증가하는 추세를 보여줍니다. 사용자 부하가 적을 때는 응답 시간이 허용 가능한 수준 내에 있지만 사용자가 약 70명이 되면 응답 시간이 급격하게 증가하는 것을 볼 수 있다. 이 시스템은 성능 저하 없이 최대 70명의 사용자까지 확장할 수 있다는 결론을 내릴 수 있다. 70명의 사용자가 로드된 후에는 응답 시간 저하 없이 시스템을 더 이상 확장할 수 없음을 의미한다.
상관 관계(Correlation)
두 번째는 당연하지만, 사용자 메트릭 성능과 서버측 메트릭 성능의 추세를 비교해야 한다. 응답 시간(사용자)과 같은 지표를 웹 서버 CPU 사용률(서버)과 같은 다른 지표와 비교하는 것을 의미한다.

사용자 부하가 점진적으로 일어날 때, 응답시간에 spike가 발생하는 것을 볼 수 있다. 왜 이런 일이 발생했는 지 알기 위해서 서버 메트릭 추세와 비교해보면 된다.
응답시간과 그래프가 비슷한 서버 메트릭을 찾는다. 위 예시에서는 WebContainer Queue Length가 해당된다. 아래 그래프를 보면 Queue의 Length는 thread count를 키워줄 때마다 해소되는 것을 볼 수 있다.
따라서 응답 시간 급증의 원인은 사용자 부하 증가로 인해 애플리케이션 서버의 일시적인 스레드 부족임을 알 수 있다.
비교 (Comparison)
SLA 내(허용 가능한) 성능 그래프와 SLA 외(허용되지 않는 )성능 그래프를 비교하는 것을 의미한다. SLA내의 성능 동안 수집된 클라이언트 및 서버 성능 데이터는 시스템 및 리소스에 대한 허용 임계값을 이해할 수 있는 좋은 기준선을 제공한다. SLA 외의 성능 추세에서 나온 동일한 메트릭을 SLA 내에서 나온 메트릭과 비교하면 병목 현상의 원인을 찾기 수월하다.
예시를 보자. Test 1은 SLA 내의 성능이고 Test2는 SLA 외의 성능이다.

Test2의 14초부터 ResponseTime이 급격하게 증가하는 것을 볼 수 있다.
Test1의 Queue Length는 ResponseTime의 추세와 일치하지 않지만, Test2의 Queue Length는 Test2의 ResponseTime이 급격하게 증가하는 순간이 14초부터 동일하게 급증하는 것을 볼 수 있다.
Test2의 CPU Utilization을 보면 Test1보다 사용량이 떨어졌다. 병목 현상으로 인해 애플리케이션이 느리게 작동하고 있고, 이로 인해 Queue Length에서 대기중인 백로그가 크게 상승한 것이다.
왜 병목 현상이 일어났을까? Database CPU Utilization을 보면 알 수 있다. CPU와 반대로 DB는 Test1과 비교했을 때 Test2때 사용량이 크게 증가했다. 즉, 병목 현상은 Database 서버에 의해 발생했으며 자세한 원인을 찾기 위해 가장 오래 걸리는 SQL 쿼리 분석 등 DB 사용량에 대한 분석이 필요하다는 것을 알 수 있다.
제거 (Elimination)
병목 현상이 발생한 시스템 구조에서 특정 구조만 제거하는 방법이다. 하드웨어 리소스를 제거하고, 소프트웨어 리소스만 사용해서 다시 테스트하거나, DB서버를 제거하고 애플리케이션단만 테스트하는 것과 같다. 병목현상의 정확한 원인을 파악하기 어려울 때 하면 좋은 방법인 것 같다.
예시는 B2B/EDI 애플리케이션에 OR(Reporting) 스레드와 Archival 스레드, Translation 스레드가 동작할 때 병목 현상이 일어난 상황이다. (EDI는 표준화된 방식으로 전자문서를 만들어 교환하는 것이라고 한다. 국가간 무역 서비스에서 사용되는 것인듯. OR은 거래를 기록하고 데이터를 분석하는 Job, Archival는 데이터를 저장, Translation은 문서를 번역하는 비즈니스 로직이라고 생각하면 될 것 같다.)
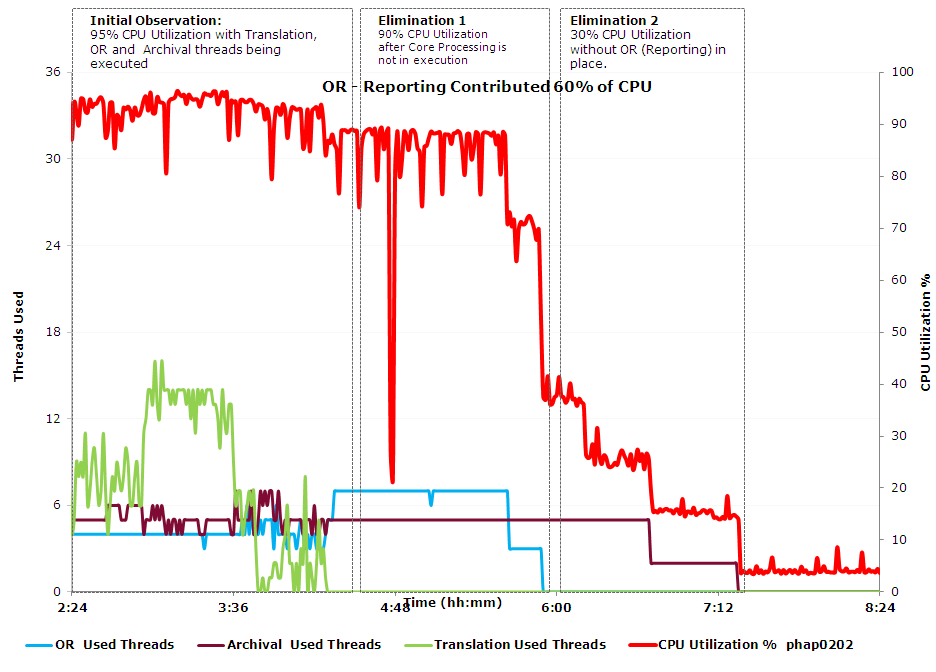
그래프를 보면 Translation -> OR -> Archival 순으로 스레드를 종료시키는 것을 볼 수 있다. CPU 사용량이 떨어지는 지점이 OR Thread가 전부 종료되는 지점과 동일하므로, 이 병목현상은 OR Thread를 처리하는 중 일어난 것임을 알 수 있다.
패턴 매칭 (Pattern Matching)
일반적으로 자주 발생하는 문제와 패턴이 일치하는 지를 검사한다. 자주 발생하는 성능 문제의 예시로는 로드 밸런싱 환경에서 웹 서버가 제대로 구성되지 않아 응답 시간이 주기적으로 급증하는 경우, 웹 서버 캐시 새로 고침으로 인해 응답 시간이 급격히 증가하는 경우, 메모리 누수로 인해 응답 시간이 점진적으로 증가하는 경우 등이 있다.
아래 예시는 Java 기반의 주문 관리 시스템이 48시간동안 1500건의 주문을 처리한 결과이다.

ResponseTime이 점진적으로 증가하는 것을 볼 수 있다. 처음에는 4초가 걸렸지만, 48시간후에는 그 두 배인 8초가 걸린다. 이 추세는 메모리 누수 문제의 추세와 유사하다고 한다. 메모리 그래프를 보면 사용중인 메모리가 200MB에서 1GB로 늘어난 것을 볼 수 있다. (결론 : 성능테스트 많이 해보고 경험 기반으로 맞춰라@@)
마무리
해당 포스팅에선 병목 현상 식별을 위한 간단한 가이드라인을 제공해주었다. 예시처럼 ResponseTime, Cpu utilization, DB utilization같이 각 서브 시스템의 리소스를 파악할 수 있는 큰 기준을 먼저 검사한 후, 비교를 통해 병목 현상의 원인으로 의심되는 서브 시스템을 찾아 깊게 분석하는 수 밖에 없는 것 같다!
참고


오 진짜 전문가영역의 내용이네요 👍🏻