스레드
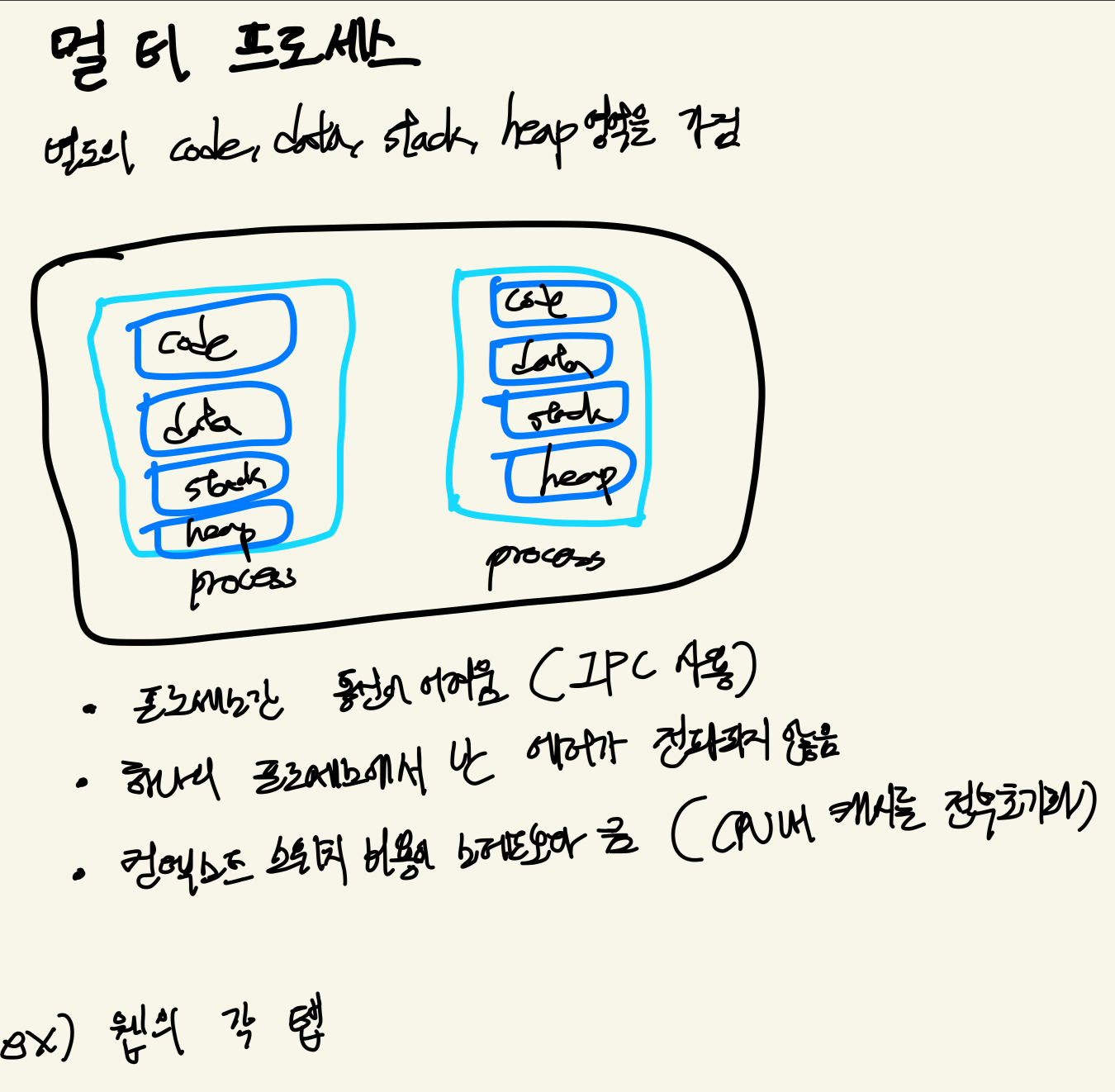
프로세스 : 시스템에서 수행되는 작업의 단위
스레드 : CPU를 이용하는 기본 단위
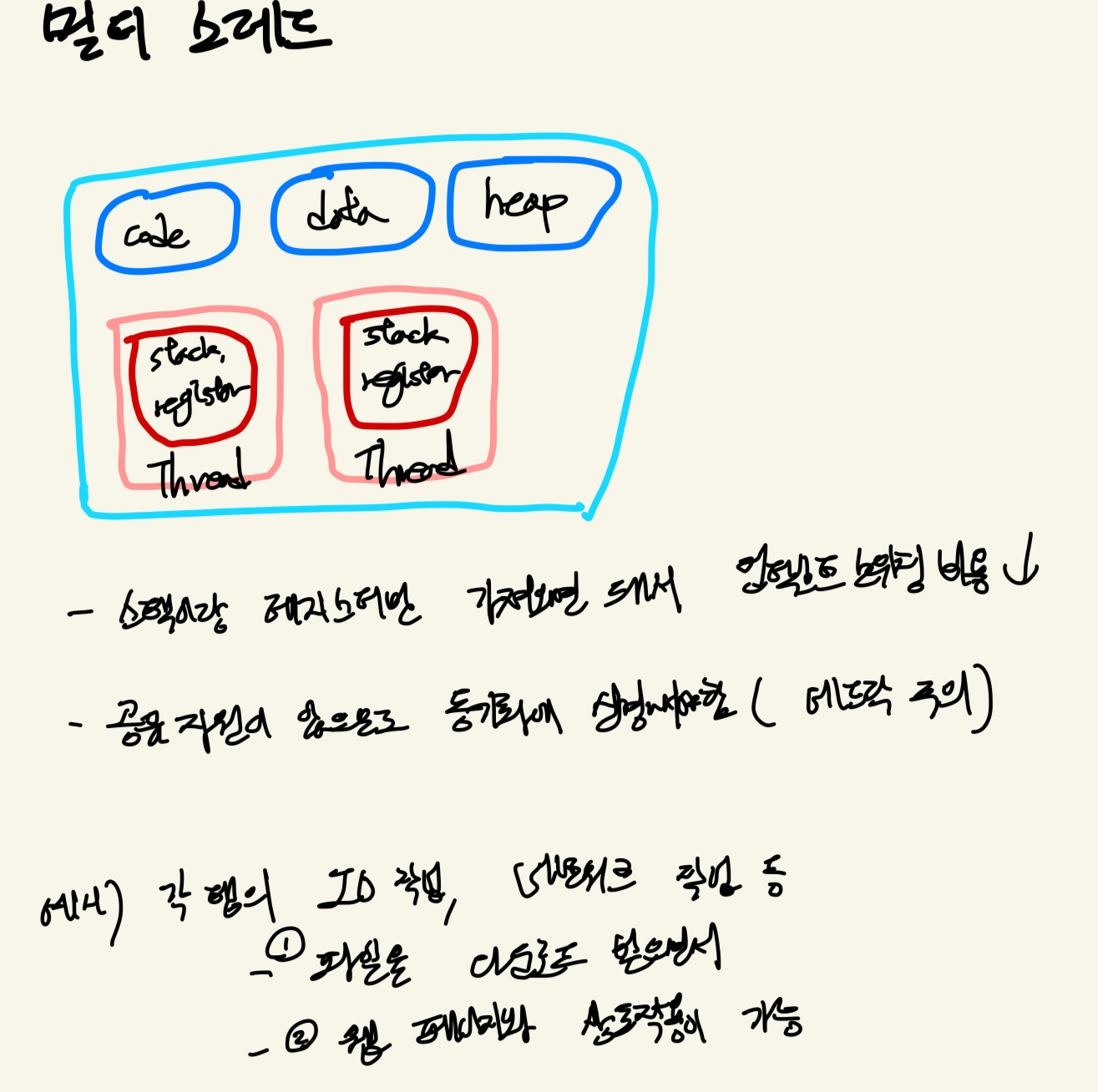
스레드는 자신만의 스레드 ID, PC, 레지스터 집합, 스택을 가진다.
- 코드, 데이터, 힙은 프로세스의 것을 공유한다.
멀티 프로세스는 코드, 데이터, 힙, 스택을 전부 새로 만들어야하지만, 멀티 스레드는 코드, 데이터, 힙을 새로 만들지 않아도 돼서 성능상으로 이득.
그럼 멀티 프로세스는 언제 쓰냐?
- 프로세스간 독립적인 메모리 공간을 써야할 경우 ex. 완전히 다른 프로그램
- 에러 전파를 막고싶은 경우 ex. 한 탭에서 에러난다고 다른 탭까지 에러 안남
웹서버에서 멀티 스레드 활용한 예시
서버가 요청을 받아들이는 하나의 프로세스로 동작하게 한다.
클라이언트가 서버에게 커넥션 요청을 할 때, 그 요청을 listen하는 스레드를 생성한다. 커넥션마다 새로 프로세스를 만든다면 성능 손해. (Nginx가 아파치보다 커넥션 생성 성능 좋은 이유)
스레드의 장점
- 응답성 : 응용 프로그램이 오래 걸리는 태스크를 수행중이어도, 사용자에게 다른 리소스를 제공할 수 있다. (영상 가져오는 데는 오래 걸려도 미리 텍스트는 제공 가능)
- 자원 공유 : 디폴트로 공유 메모리 적용
- 경제성 : 문맥 교환에서 이득
- 규모 적응성 : 각각의 스레드를 병렬로 수행할 수 있다.
멀티 코어 프로그래밍
병행 vs 병렬
- 병행은 유저에게 두 개의 작업을 동시에 제공할 수 있는 것을 의미. 근데 무조건 동시에 실행되는 건 아니고, cpu 왔다갔다하면서 동시에 제공하는 것처럼 보이는 걸 의미
- 병렬은 ㄹㅇ 동시 실행 (멀티 코어) 병령이 더 쎈 개념. 병렬없이 병행을 수행할 수 있다.
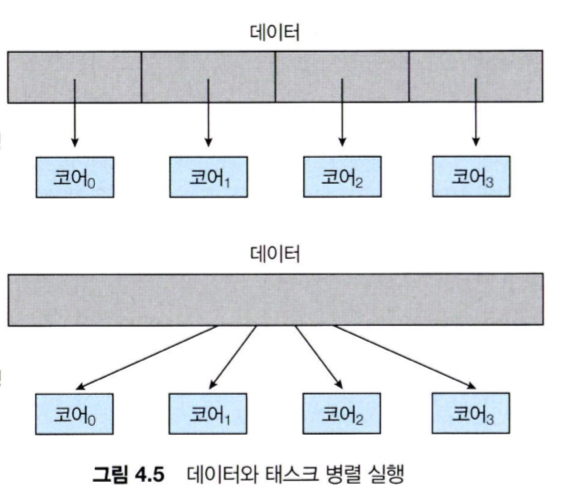
병렬 실행의 유형
- 데이터 병렬 실행 : 동일한 데이터의 부분집합을 다수의 코어에 분배. ex) 분할 정복으로 배열 원소들의 합 구하기
- 태스크 병렬 실행 : 데이터가 아니라 태스크를 다수의 코어에 분배. 각 스레드들은 동일한 데이터에 대해 연산을 싱핼 할 수도 있고, 서로 다른 데이터에 연산을 실행할 수도 있음.
다중 스레드 모델
사용자 스레드와 커널 스레드의 매핑 전략
다대일 모델
유저 스레드(다) - 커널 스레드(일)
한 번에 하나의 스레드만 커널 사용할 수 있기 때문에 별로임. 잘 안쓰임
일대일 모델
유저 스레드(일) - 커널 스레드(일)
사용자 스레드 만들려면 커널 스레드 무조건 만들어야함. 많은 수의 커널 스레드 필요.
그러나 일반적으로 사용되는 모델임. 코어 수가 늘어나면서 커널 스레드 수를 제한하는 것의 중요성이 줄어들었기 때문.
다대다 모델
유저 스레드(다) - 커널 스레드(다)
일대일 모델보다 적은 양의 커널 스레드를 생성할 수 있지만 구현이 까다롭다.
비동기 스레딩과 동기 스레딩
비동기 스레딩은 부모와 자식 스레드가 독립적으로 실행
스레드가 독립적이라서 스레드 사이 데이터 공유는 거의 없는 편
동기 스레딩은 부모 스레드가 자식 스레드가 모두 종료될 때까지 기다렸다가 조인함. 부모 스레드는 조인 후에 실행을 재개할 수 있음. ex. 분할 정복 알고리즘 - 포크 조인
암묵적 스레딩
스레드의 생성과 관리 책임을 개발자로부터 컴파일러와 라이브러리에게 넘겨버리는 것을 의미
개발자는 병렬로 수행할 작업만 식별하고, 라이브러리가 스레드를 생성하고 관리하거라~
스레드 풀
미리 스레드 만들어서 스레드 풀에 넣어둠. 스레드 필요할 때 스레드 풀에서 가져와서 씀.
- 미리 만들었으니 빠르죠?
- 존재하는 스레드 개수를 커스텀할 수 있다.
포크 조인
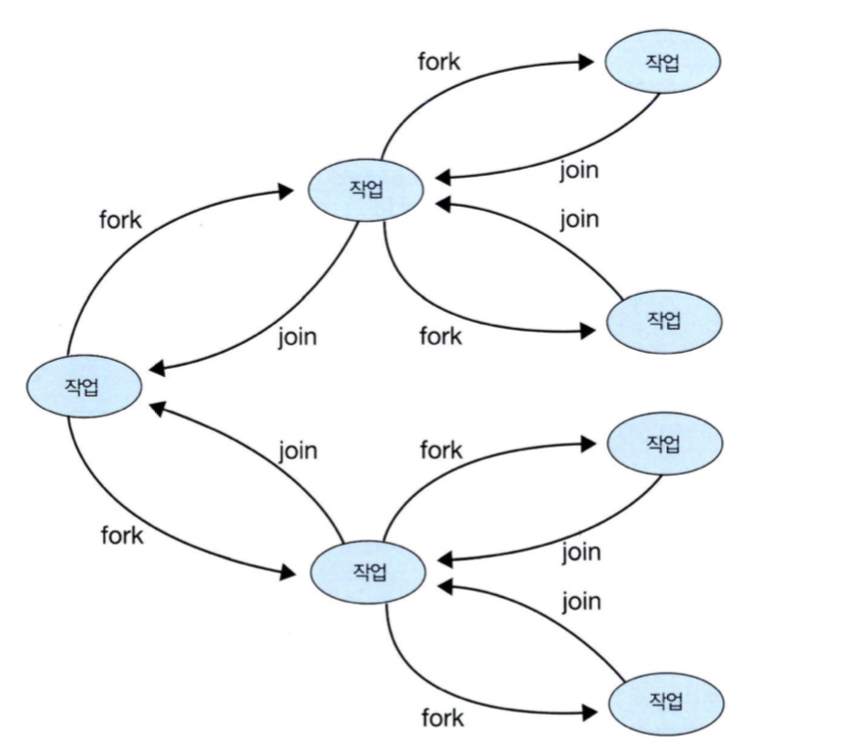
부모 프로세스가 자식 프로세스를 만들어 일 시키고, join해서 결과 반환.
포크 조인 구현할 때는 어느 시점까지 fork를 수행할 것인가 결정하는 게 중요. (재귀 함수니까 당연)

자바의 경우, 자료 구조마다 포크 기준을 정하는 인터페이스를 구현하고 있음.
자바의 스레드
자바에서 스레드를 명시적으로 생성하는 두 가지 방법
- Thread 클래스 상속
- Runnable 인터페이스 구현
Runnable은 익명 객체 및 람다로 사용할 수 있지만, Thread는 별도의 클래스를 만들어야 하고, 상속의 단점때문에 Runnable이 더 자주 쓰임.
얘네 둘은 저수준 API라 불편함이 존재함.
- 스레드 수행 후 값을 반환하는 게 불가능(전부 void)
- 매번 쓰레드 생성과 종료하는 오버헤드가 발생
- 쓰레드들의 관리가 어려움 (개발자가 직접 생성부터 종료까지 관리해야함)
Callable과 Future
Runnable은 스레드 수행 결과 반환 불가능.
Callable은 스레드 수행 결과를 Future 형태로 반환.
Executor, ExecutorService
스레드 객체를 명시적으로 생성하는 대신 Executor 인터페이스를 중심으로 스레드 생성을 구성 (new Thread(RunnableImpl)) 안해도 됨.
스레드 풀 생성 지원. 개발자는 스레드 풀 설정만 하면, 라이브러리가 알아서 스레드 생성 및 스케줄링.
스레드 생성을 실행에서 분리.
병행하게 실행되는 작업간의 통신 기법을 제공??? 뭔 소리지
