트랜잭션 격리 수준
트랜잭션 격리 수준이란 여러 개의 트랜잭션이 실행 중일 때, 트랜잭션1에서 사용중인 데이터를 트랜잭션2가 볼 수 있게 허용할지 말지를 결정하는 것이다.
격리 수준은 크게 4가지로 나뉜다.
READ UNCOMMITTED(커밋되지 않은 읽기)READ COMMITTED(커밋된 읽기)REPEATABLE READ(반복 가능한 읽기)SERIALIZABLE(직렬화 가능)
위로 갈수록 동시 처리 성능이 높고, 아래로 내려갈수록 각 트랜잭션 간의 데이터 격리(고립)정도가 높아지며 데이터 부정합 문제가 발생할 확률이 줄어든다.
각 격리수준과 정합성 문제의 관계
각 격리수준에 의해 발생할 정합성 문제의 관계는 다음과 같다. 자세한 건 각 격리수준을 설명할 때 같이 설명하도록 하겠다!
| DIRTY READ | NON-REPEATABLE READ | PHANTOM READ | |
|---|---|---|---|
| READ UNCOMMITTED | 발생 | 발생 | 발생 |
| READ COMMITTED | 없음 | 발생 | 발생 |
| REPEATABLE READ | 없음 | 없음 | 발생(InnoDB는 없음) |
| SERIALIZABLE | 없음 | 없음 | 없음 |
READ UNCOMMITTED (커밋되지 않은 읽기)
READ UNCOMMITTED는 다른 트랜잭션에서 커밋하지 않은 데이터라도 볼 수 있다.
만약 트랜잭션1에서 어떤 데이터를 INSERT했다고 해보자. 이 시점에서 트랜잭션2는 데이터가 커밋되지 않았더라도 데이터를 읽어올 수 있다.
트랜잭션2가 데이터를 읽은 후에, 트랜잭션1이 데이터를 롤백했다고 해도, 트랜잭션2는 이전에 읽어온 데이터를 처리할 수 있다. 이처럼 READ UNCOMMITTED 롤백된 데이터를 정상적인 데이터로 보고 처리하는 문제가 생길 수도 있기에 잘 사용되지 않는 격리 수준이라고 한다.
어떤 트랜잭션에서 처리한 작업이 완료되지 않았는데도 다른 트랜잭션에서 볼 수 있는 현상을 Dirty Read라고 한다. READ UNCOMMITTED는 Dirty Read를 허용하는 격리 수준이다.
READ COMMITTED (커밋된 읽기)
READ COMMITTED은 커밋된 데이터만 읽어오는 격리 수준이다. 커밋되기 이전의 데이터는 Undo log에서 읽어오기에 Dirty Read 문제가 발생할 여지가 없다. 오라클 DBMS에서 기본으로 사용되는 격리 수준이며, 온라인 서비스에서 가장 많이 선택되는 격리 수준이라고 한다.
그러나 READ COMMITTED는 NON-REPEATABLE READ문제가 발생할 수 있다. 예시를 봐보자.
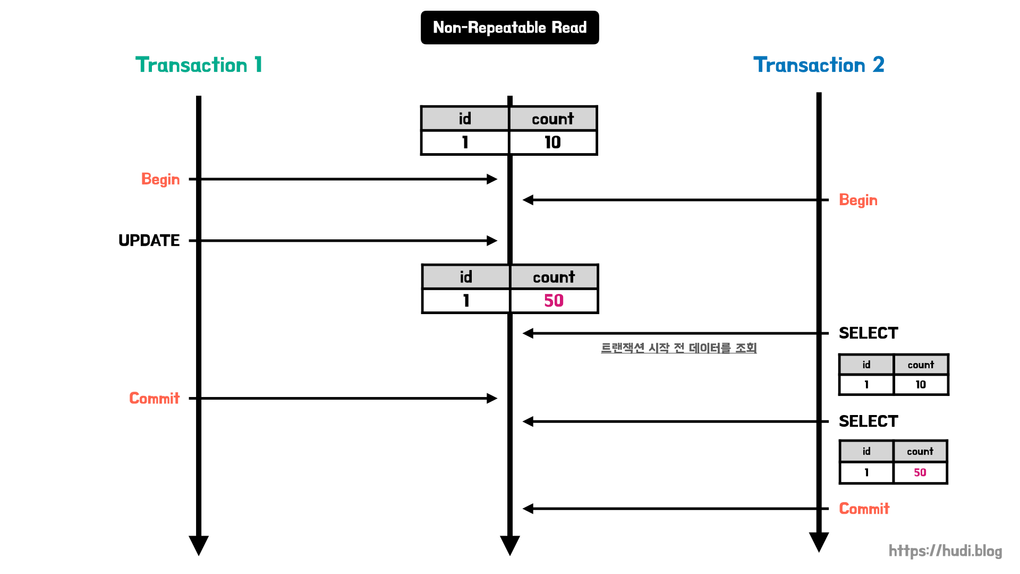
트랜잭션2는 두 번의 SELECT문을 실행하고 있다.
첫 번째 SELECT에서는 트랜잭션1의 UPDATE문이 커밋되지 않아 Undo log에 있는 값인 count : 10 을 불러온다.
두 번째 SELECT에서는 트랜잭션1이 커밋되었으므로, 변경된 값인 count : 50을 불러온다.
이처럼 하나의 트랜잭션에서 동일한 SELECT문을 수행했을 때 조회되는 값이 같지 않은 것을 NON-REPEATABLE READ라고 한다.
NON-REPEATABLE READ는 일반적인 웹 프로그램에서는 문제가 발생하지 않을 수도 있지만, 금전적인 처리와 연결되면 문제가 될 수도 있다. 트랜잭션1에서 입금과 출금 처리가 진행중일 때, 트랜잭션2에서 오늘 입금된 금액의 총합을 조회중이라면, 트랜잭션 2가 조회하는 시점에 따라 다른 값이 조회된다.
REPEATABLE READ (반복 가능한 읽기)
트랜잭션에서 조회를 했을 때 항상 같은 값을 조회해오는 것을 보장하는 격리 수준이다. 즉, NON-REPEATABLE READ 문제가 발생하지 않는다.
MySQL의 InnoDB 스토리지 엔진에서 기본으로 사용되는 격리 수준이다.
InnoDB의 경우, 트랜잭션은 고유한 트랜잭션 번호(순차적으로 증가하는 값)를 가지며, Undo log에 백업된 모든 레코드에는 변경을 발생시킨 트랜잭션의 번호가 포함되어 있다. (언두 영역에 백업된 데이터는 InnoDB 스토리지 엔진이 불필요하다고 판단하는 시점에 주기적으로 삭제한다고 한다. 어떤 기준인지 기회가 되면 다음에 찾아보자... 181p)
REPEATABLE READ가 어떻게 NON-REPEATABLE READ를 방지하는 지 예시를 봐보자.
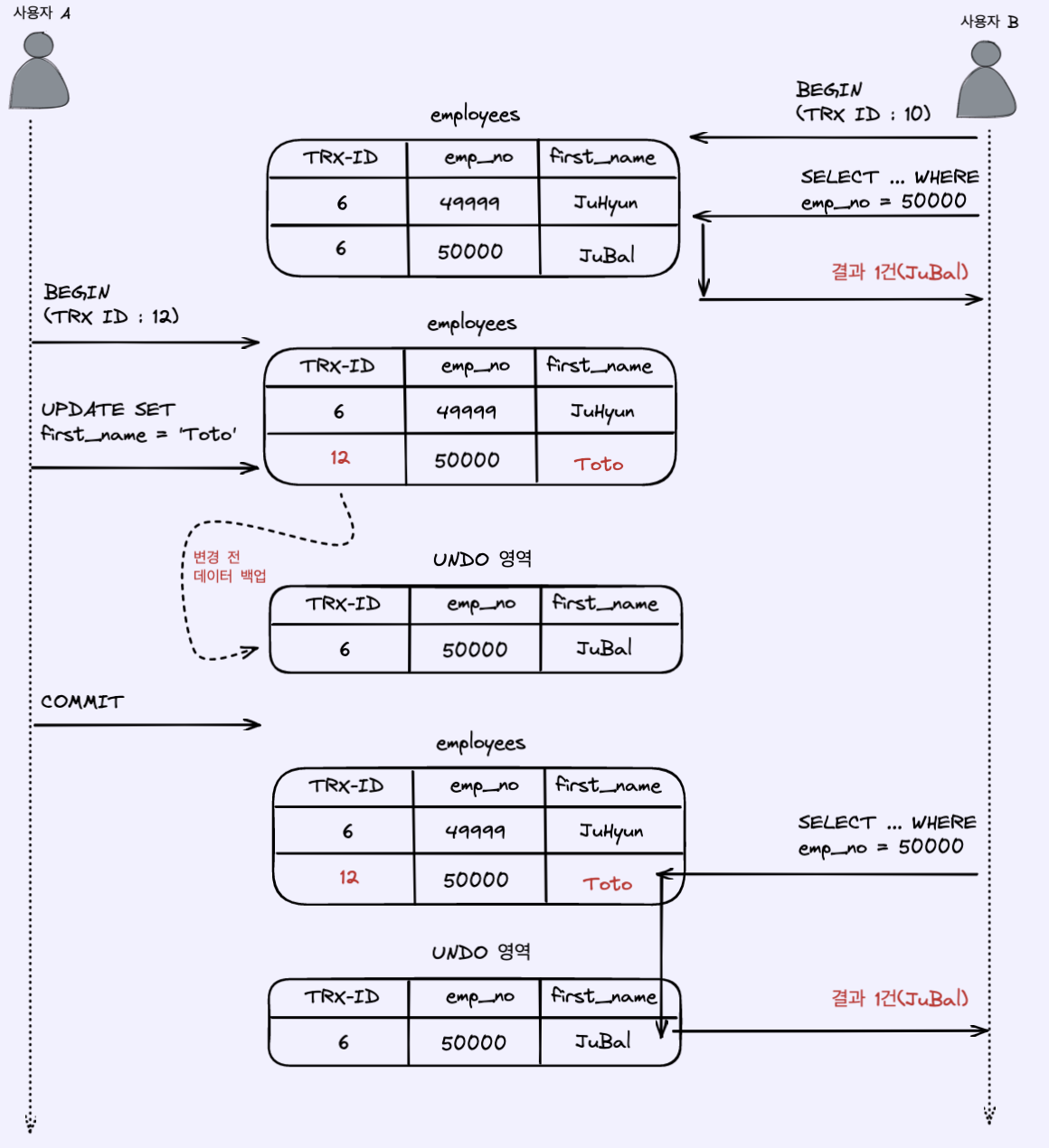
사용자 B의 트랜잭션은 시작할 때 트랜잭션 번호 10을 받는다. 이때 사용자 B의트랜잭션에서 emp_no가 50000인 데이터를 불러오면 first_name : JuBal을 받아온다.
이후 트랜잭션 번호가 12인 트랜잭션에서 emp_no가 50000인 데이터의 first_name을 변경한다. 테이블에는 변경이 반영되고, Undo log에 이전 데이터를 저장한다. 이 때 변경을 수행한 트랜잭션의 아이디도 저장한다.
변경된 데이터가 커밋된 후, 사용자 B의 트랜잭션에서 다시 emp_no가 50000인 데이터를 불러오려고 한다. 이 때 employees 테이블에서 emp_no가 50000인 데이터의 트랜잭션 아이디가 자신의 트랜잭션 ID보다 크다면, Undo log에서 데이터를 불러온다.
이처럼 REPEATABLE READ는 트랜잭션 아이디를 저장해 자신의 트랜잭션 아이디보다 이후에 반영된 트랜잭션의 결과값만을 가져오므로, NON-REPEATABLE READ문제를 방지할 수 있다.
하지만 REPEATABLE READ 도 데이터 부정합 문제가 발생할 수도 있다.
아래 예시 사진을 봐보자.
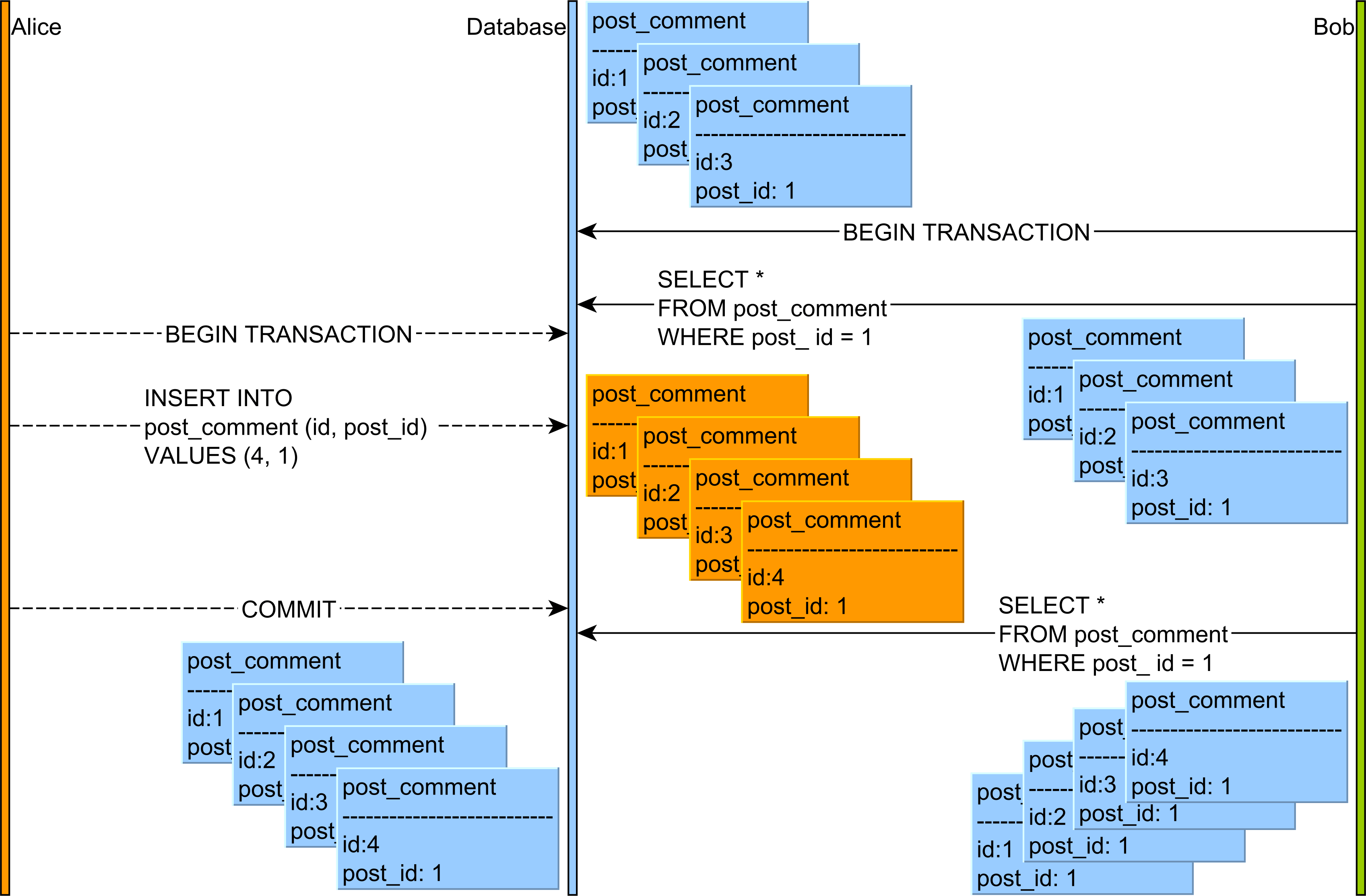
트랜잭션 B는 두 번의 SELECT문을 수행한다.
첫 번째 SELECT에서는 post_id가 1인 post_comment가 세 개 존재했다. 이후 트랜잭션 A가 post_id가 1인 post_comment를 하나 더 INSERT한 다음 커밋한다.
두 번째 SELECT에서는 트랜잭션 A가 새로 INSERT한 post_comment도 읽어들여 총 네 개의 post_comment를 읽어오는 것을 볼 수 있다.
하지만 InnoDB 스토리지 엔진은 갭 락과 넥스트 키 락 덕분에
REPEATABLE READ격리 수준에서도PHANTOM READ문제가 발생하지 않는다. 때문에 InnoDB를 사용한다면 이후 나올SERIALIZABLE격리 수준을 사용할 필요성은 없다고 한다.
NON-REPEATABLE READ vs PHANTOM READ
글을 읽다보니 NON-REPEATABLE READ 과 PHANTOM READ의 차이가 무엇인지 헷갈려 둘의 차이를 찾아보았다!
- Non-repeatable reads: read COMMITTED data from an
UPDATEquery from another transaction - Phantom reads: read COMMITTED data from an
INSERTorDELETEquery from another transaction
NON-REPEATABLE READ는 하나의 레코드에 초점된 문제로, 트랜잭션A에서 레코드의 값을 UPDATE했을 때, 트랜잭션 B가 UPDATE된 값을 읽어와 데이터 정합성이 깨지는 것을 의미한다.
PHANTOM READ는 레코드 집합에 초점된 문제로, 트랜잭션 A가 레코드를 INSERT하거나 DELETE했을 때, 트랜잭션 B가 해당 레코드가 포함된 집합을 읽어올 때 데이터 정합성이 깨지는 것을 의미한다.
즉, NON-REPEATABLE READ는 하나의 레코드를 UPDATE했을 때, 해당 레코드를 조회할 때 발생하는 문제이고, PHANTOM READ는 하나의 레코드를 INSERT or DELETE했을 때, 해당 레코드가 포함된 레코드 집합을 조회할 때 발생하는 문제이다.
PHANTOM READ는 트랜잭션 아이디를 저장하는 방법으로 해결할 수 없는건가?
아래는 챗지피티에게 물어본 내용이다. UPDATE와 달리 INSERT나 DELETE는 버전을 관리하는 바업이 더 까다로운 모양이다... 기회가 되면 나중에 추가적인 자료를 찾아 정리하겠다...ㅎㅎ
- 읽기 락 (Read Lock) 사용: 읽기 락은 다른 트랜잭션에서 해당 데이터를 수정하지 못하도록 막아주지만, 데이터를 추가하거나 삭제하는 것을 막지는 않습니다. 따라서 트랜잭션이 특정 범위의 데이터를 읽을 때, 다른 트랜잭션이 동일한 범위 내에 새로운 데이터를 추가하거나 삭제하면 Phantom Read가 발생할 수 있습니다.
- 스냅샷 격리 (Snapshot Isolation): 스냅샷 격리는 트랜잭션이 시작 시점의 데이터 스냅샷을 사용하여 읽기를 수행합니다. 하지만 스냅샷 격리에서도 데이터의 추가나 삭제는 해당 트랜잭션의 스냅샷에 반영되지 않습니다. 따라서 다른 트랜잭션이 데이터를 추가하거나 삭제하면, 해당 트랜잭션의 결과에는 Phantom Read 문제가 발생할 수 있습니다.
- 버전 관리 (Versioning): 버전 관리도 읽기 시 특정 시점의 데이터 버전을 참조합니다. 하지만 데이터의 추가나 삭제에 대해서는 버전이 생성되지 않습니다. 따라서 다른 트랜잭션이 데이터를 추가하거나 삭제하면, 해당 트랜잭션의 결과에 Phantom Read 문제가 발생할 수 있습니다.
SERIALIZABLE (직렬화 가능)
가장 단순한 격리 수준이면서 가장 엄격한 격리 수준이다. 그만큼 동시 처리 성능도 다른 트랜잭션 격리 수준보다 떨어진다. InnoDB의 경우 기본적으로 순수한 SELECT작업에는 아무런 레코드 잠금도 설정하지 않는다. 하지만 SERIALIZABLE의 경우 읽기 작업도 공유 잠금을 획득해야만 하며, 동시에 다른 트랜잭션은 그러한 레코드를 변경하지 못하게 된다. 즉, 한 트랜잭션에서 읽고 쓰는 레코드를 다른 트랜잭션에서 접근할 수 없게 된다.
SERIALIZABLE 은 트랜잭션을 직렬화할 수 있다. 트랜잭션간의 순서가 보장된다.
참고
