파일과 파일시스템이란?
- File : 이름을 가진 정보 컬렉션
- File Attribute : 파일의 메타데이터. 파일의 이름, 위치, 사이즈, 접근권한 등을 저장한다.
- File System : OS에서 파일을 관리하는 영역. 파일을 저장하고, 파일 저장 방법등을 결정한다.
디렉토리와 파티션
- Directory : 파일들의 메타데이터 정보들을 저장하는 특별한 파일.(어떤 파일시스템이냐에 따라 디렉토리가 가지고 있는 메타데이터 정보가 다르다. Unix의 경우 파일 이름만 알고있음)
- Partition(=Logical Disk) : 물리적인 디스크를 논리적인 영역으로 구분한 것.(반대로 드물지만 여러 개의 물리 디스크를 합쳐 하나의 파티션으로 만들기도 함) 디스크를 파티션으로 나눈 후, 파티션을 파일 시스템이나 Swap area용도로 사용한다.
open()
디스크에 있는 파일 메타데이터를 메모리로 불러오는 시스템 콜이다. (파일 read/write전에 해줘야 함)
파일을 열고 fd(파일 디스크립터)를 반환한다.
왜 read/write와 별도로 open()을 수행할까?
디렉토리를 찾는데 시간이 오래 걸리기 때문에 한번 open한 파일에 다시 디렉토리 접근하는 것을 막기 위함
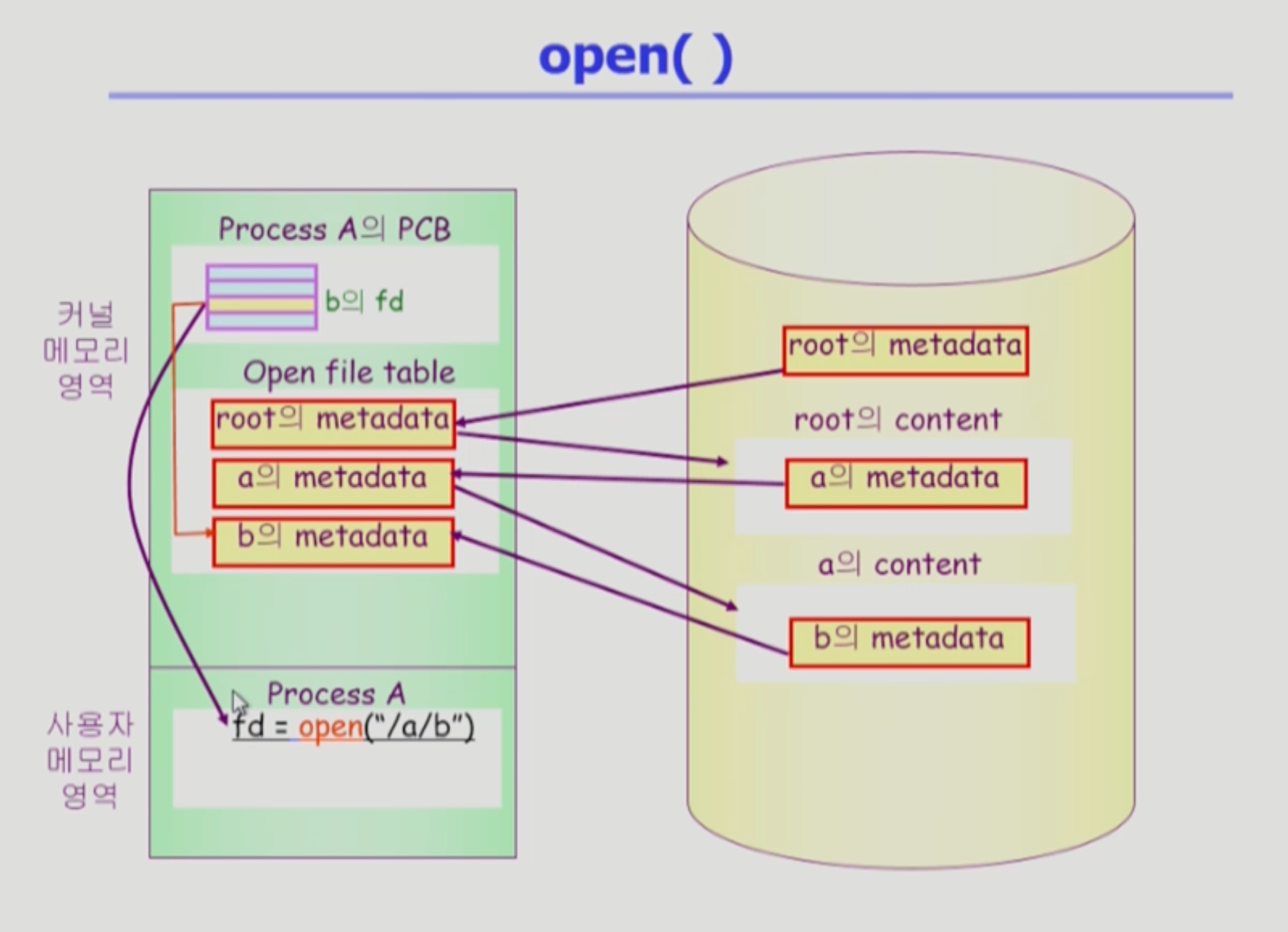
open("/a/b") 동작 예시보기
(http://www.kocw.net/home/search/kemView.do?kemId=1046323)
root → a → b 순으로 차례대로 디렉토리에 접근해 메타데이터 정보를 가져온다. b의 메타데이터를 Open File Table에 올려두면 read/write 시스템 콜이 호출될 때 메타데이터를 통해 파일로 접근이 가능해진다.
Open File Table: 오픈된 파일 메타데이터를 저장한다. 디스크의 파일 메타데이터와는 다르게 현재 해당 파일을 오픈한 프로세스의 개수와 프로세스별 파일 오프셋등을 저장하기도 한다.(파일 오프셋 : 프로세스가 현재 파일의 어느 위치에 접근중인지) 모든 프로세스가 글로벌하게 접근할 수 있다.fd (File Descriptor): Open File Table에 있는 메타데이터 위치를 가리킨다. 프로세스마다 자신의 PCB에서 저장하고 있다. (PCB는 프로세스가 오픈하고 있는 모든 파일들에 대한 정보를 저장한다.)
read/write 호출시
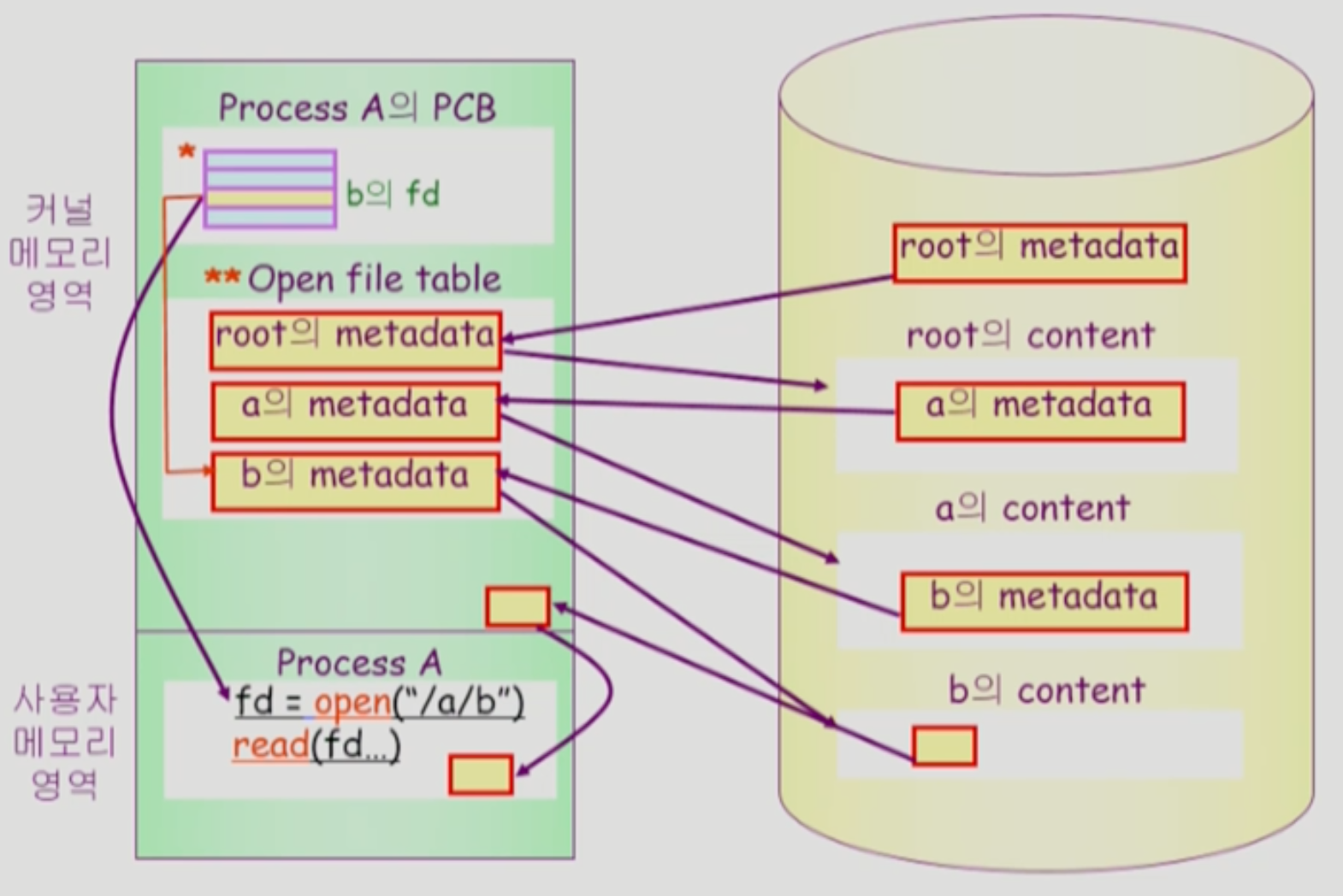
- read/write가 호출되면, open()으로 반환받은 fd를 통해
Open File Table에 위치한 메타데이터를 찾아간다. - 메타데이터를 통해 실제 파일이 존재하는 디스크에 접근해서 OS 버퍼 캐시에 파일 내용을 저장한다.
- read/write는 버퍼 캐시에 저장된 파일을 사용한다.
File Protection
파일별로 접근 권한을 관리한다.
권한의 종류는 read/write/execute가 존재한다.
read와 execute의 차이
read 권한:
- 파일 내용을 읽을 수 있다.
- 디렉터리 내용을 열람할 수 있다. (하위 디렉터리/파일 목록 확인 가능)
execute(x) 권한:
- 실행 파일(바이너리, 스크립트 등)을 실행할 수 있다.
- 디렉터리로 이동(cd)할 수 있다.
- 디렉터리 내용을 열람할 수는 있지만, r 권한이 없으면 파일 내용을 읽을 수 없다.
즉, r 권한은 파일 내용을 읽는 것을 허용하고, x 권한은 실행 파일을 실행하거나 디렉터리로 이동하는 것을 허용.
Access Control

ACM, ACL등을 통해 파일별 유저의 권한을 저장한다.
ACM은 행렬, ACL은 파일별로 유저를 연결리스트로 관리(Capability는 유저별 접근 가능한 파일을 연결리스트로 관리)
Grouping
모든 유저에 대해 일일이 저장하는 것은 그만큼 공간 낭비.
모든 유저를 owner, group, public 세 그룹으로 구분하고 그룹별로 권한을 줄 수도 있다.
각 그룹에 대한 권한을 3bit로 표한하여(rwx) 총 9bit로 파일에 대한 권한을 설정 가능하다.
Password
파일별로 패스워드를 등록이 가능하다.
파일시스템의 마운팅
물리적인 디스크는 논리적인 디스크 단위로 나누어져있다.
각 디스크에는 파일시스템이 생길 수 있는데, 특정 경로를 root경로로 두는 식으로 파일 시스템들을 구성할 수 있다. 이를 마운팅이라고 함.
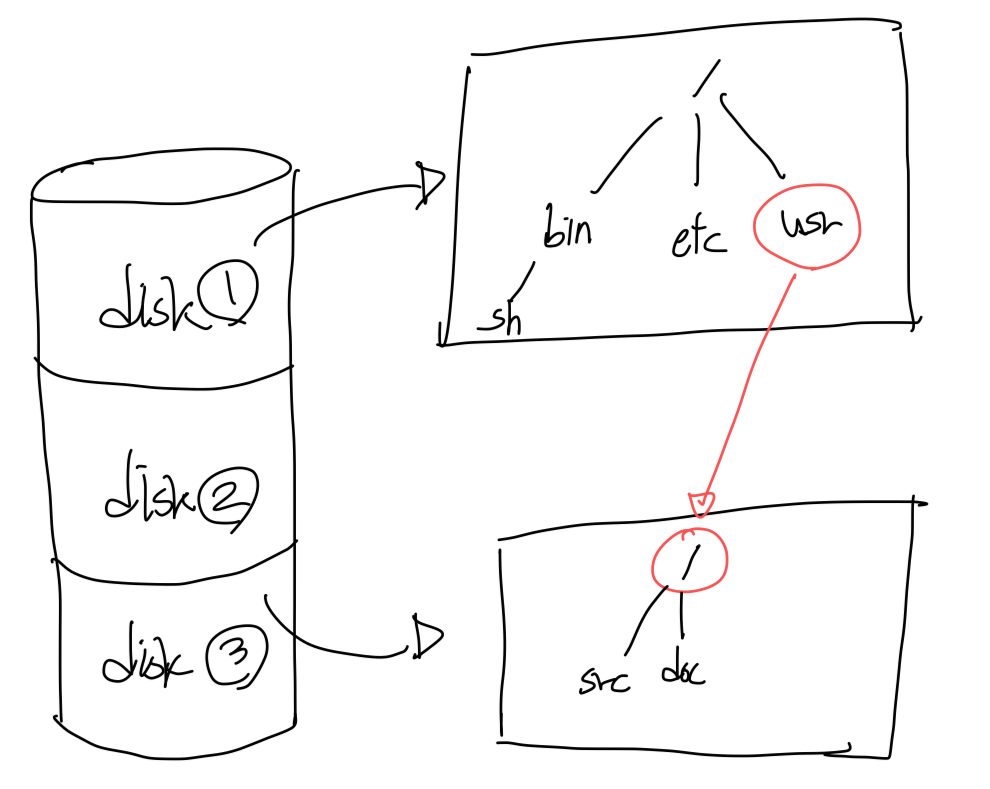
- disk3의 파일시스템 root는 usr을 가리킨다.
파일 Access Method
순차 접근
처음부터 끝까지 차례대로 접근.
카세트 테이프 처럼 순서대로 읽고, 뒤로 돌아가고 싶으면 되감아야함.
직접 접근
원하는 부분에 바로 접근할 수 있음.
A->B->C로 되어있을 때, A만보고 C로 바로 건너 뛰는 것이 가능함.
디스크에 있는 파일에 접근하는 방법
디스크에 파일을 저장할 때는 동일한 크기의 sector단위로 저장한다.
저장하는 방식은 여러 방법이 있다.
연속 할당(Contiguous Allocation)
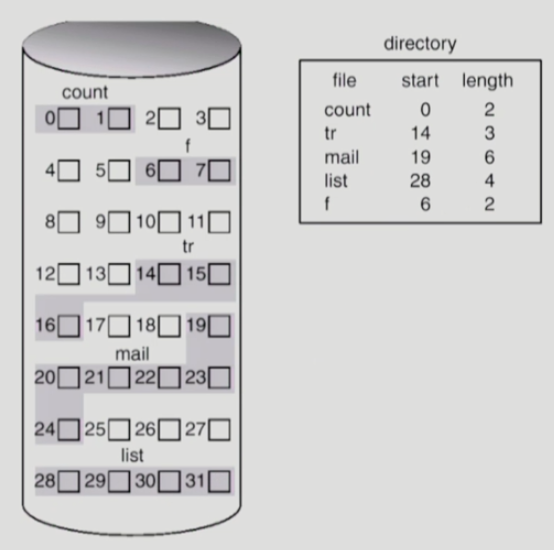{kind=link}
-
장점
- 빠른 I/O가 가능하다. -> 보통 파일시스템 용도가 아니라 Swap area용도로 자주 사용(Swap용은 빨리 빨리 나가니까 단점인 단편화가 발생할 확률이 적기에 적합하다.)
- 직접 접근이 가능하다.
-
단점
- 외부 단편화가 발생한다.
- 파일 길이는 가변적이므로, 연속적으로 전부 할당해두었을 때 대응이 어렵다. 뒤에 추가적인 빈 공간을 할당하는 대안이 있으나 내부 단편화가 발생하고, 빈 공간 이상으로 파일이 늘어날 확률도 있다.
LinkedAllocation
파일의 각 부분들을 포인터로 연결해서 저장한다.
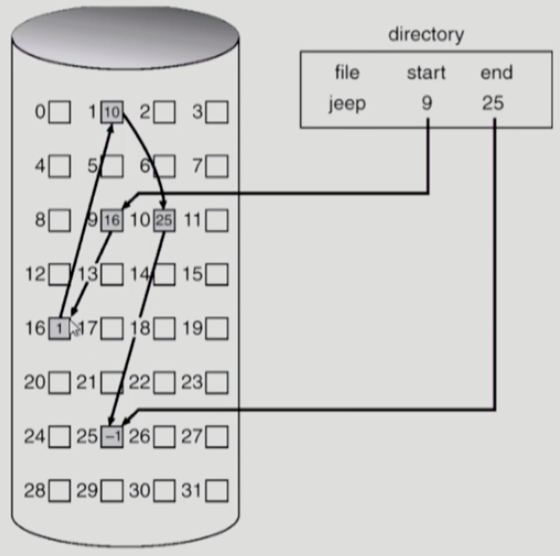
- 장점
- 외부 단편화 X
- 단점
- 직접 접근이 불가능하다. 포인터를 쭉~ 따라가면서 접근해야함.
- 앞에 sector가 잘못되면 뒤에 sector도 못찾아간다.(Reliability)
- 포인터만큼의 공간을 차지한다.(약 4byte?)
| FAT(File-Allication-Table) : LinkedAllocation의 단점인 Reliability와 포인터 공간 차지 문제를 해결한 파일 시스템)
Indexed Allocation
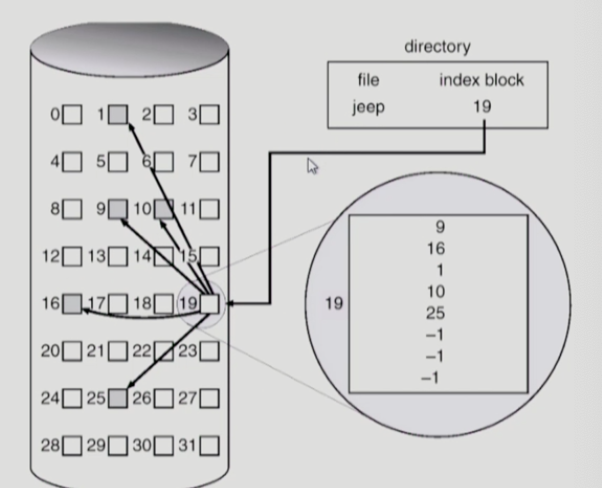
- 장점
- 외부 단편화 X
- 직접 접근 가능
- 단점
- 인덱스 저장용 공간 필요(작은 파일의 경우 공간 낭비)
파일이 커서 한 파일에 인덱스를 전부 저장할 수 없는 경우 Linked Scheme방식 또는 Multi Level Index 방식을 사용할 수 있다.
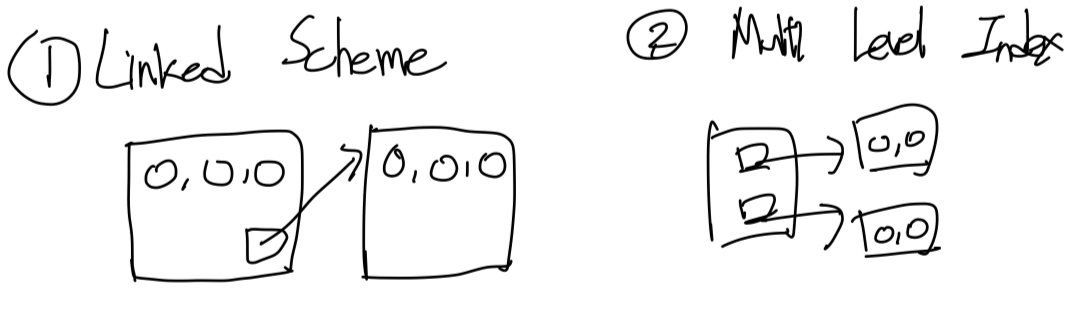
-
Linked Scheme: 인덱스 파일의 마지막 인덱스가 다음 인덱스 파일을 가리킴 -
Multi Level Index: 2단계 페이징처럼 첫 번째 인덱스 파일을 실제 인덱스가 저장된 파일들을 가리키는 용도로 사용.
Unix 파일 시스템
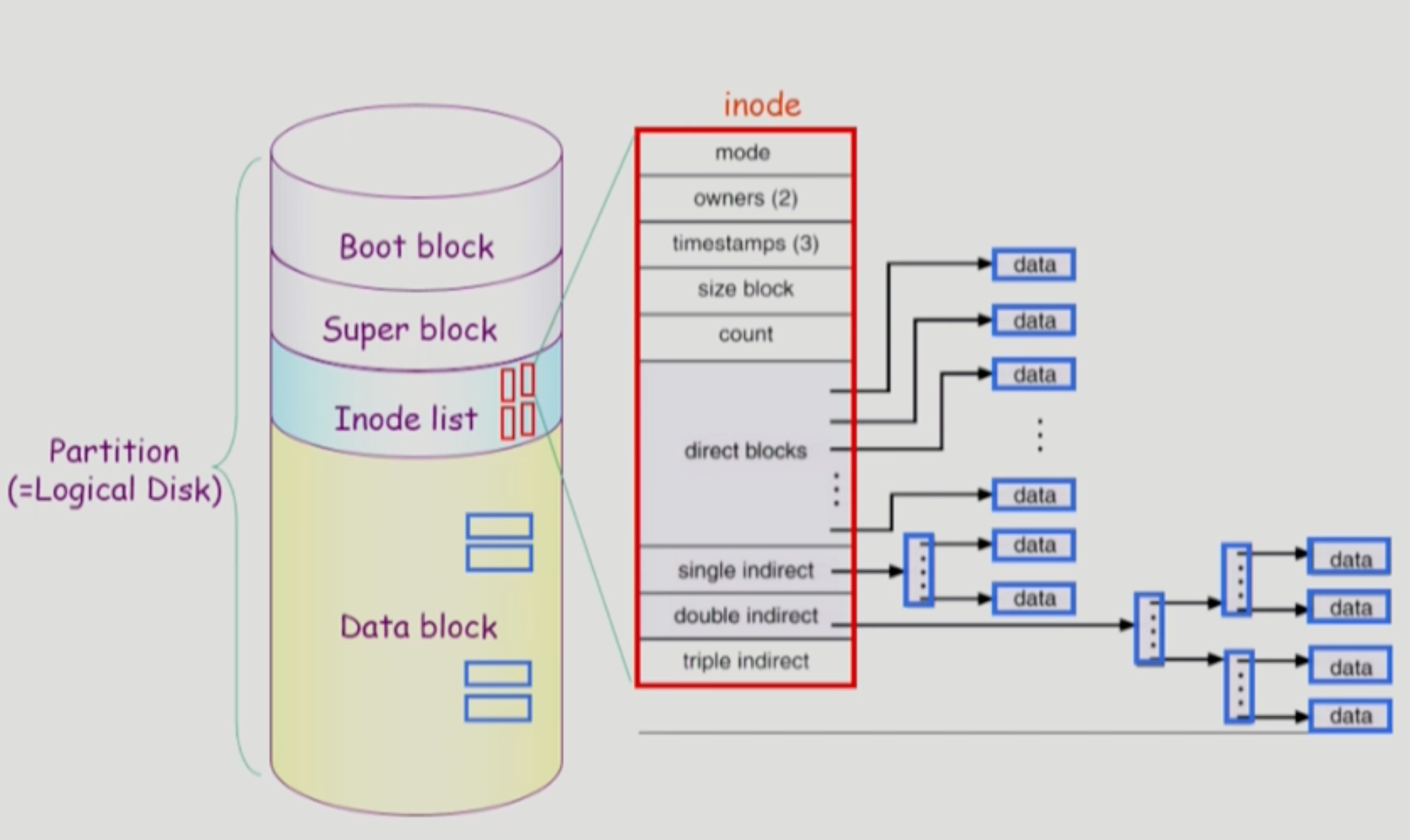
(어떤 파일 시스템이든 항상 0번 블럭에 부트 블럭이 존재한다.)
Unix는 Indexed Allocation을 사용하고 있어서 Inode에 인덱스들을 저장함. (direct blocks, single indirect, double indirect, triple indirect : 작은 파일들은 direct blocks만 사용)
Boot block: 부팅에 필요한 코드 모음(부트스트랩 로더라고 부름)Super block: 파일 시스템에 대한 전체적인 정보를 관리. (Inode들이 저장되는 위치, 현재 어느 영역의 Inode가 사용되고 있는지 등을 저장)Inode List: 파일 이름을 제외한 파일의 모든 메타데이터 저장. 파일하나당 Inode가 하나씩 할당됨. (파일 이름은 아래 Data block의 Directory 파일에서 저장)Data block: 파일의 실제 내용 저장 (Directory파일은 파일 이름과 Inode주소를 가지고 있음)
FAT 파일 시스템
마이크로소프트에서 만듦
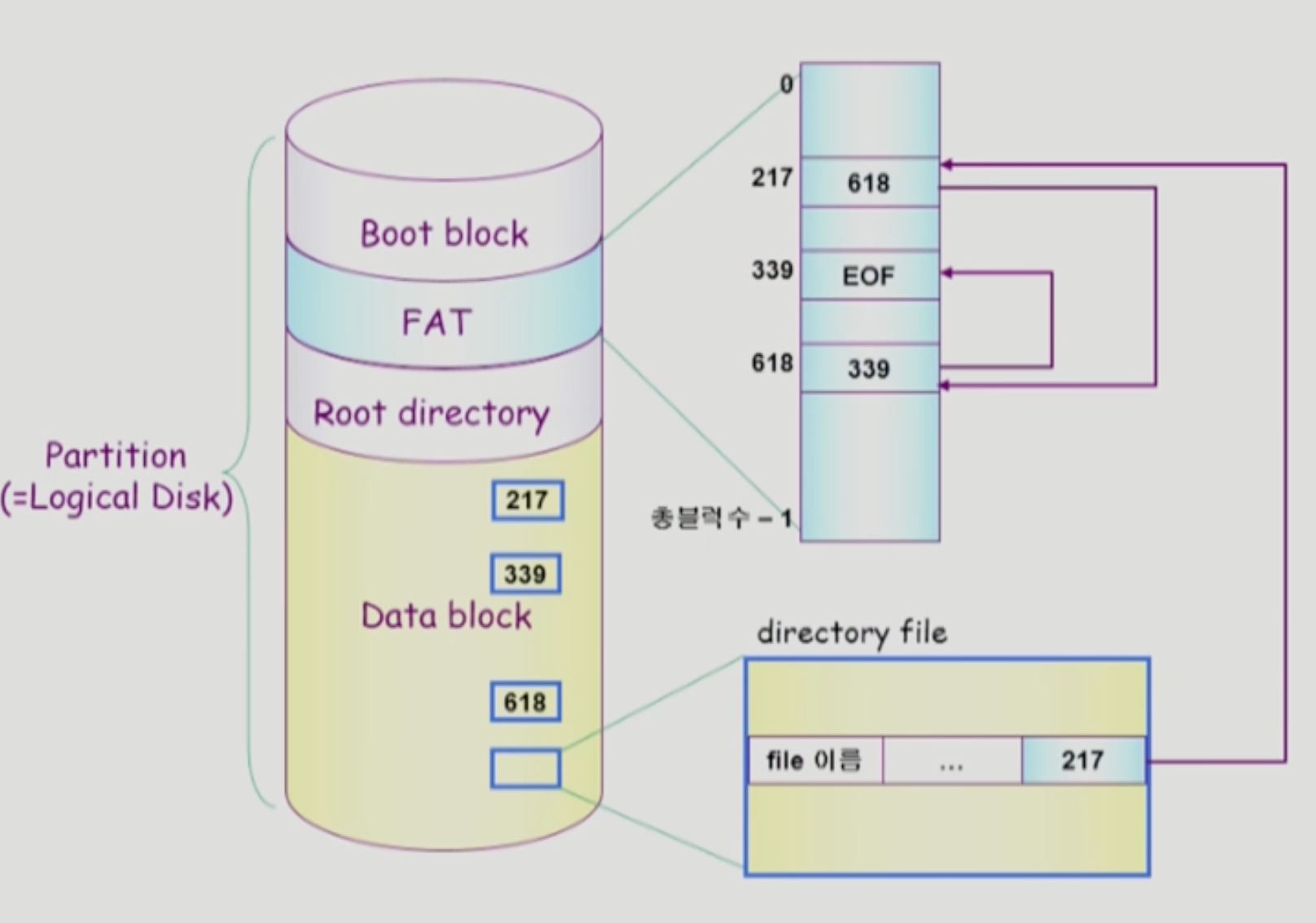
LinkedAllocation 방식을 사용함. FAT에서 주소를 연결리스트로 관리중.
FAT: 파일 위치 정보를 저장.(위치 정보만 FAT에 저장하고 나머지 메타데이터는 Directory가 가짐. Directory에서 첫 번째 위치를 가리키는 FAT주소도 가지고 있음) FAT의 크기는 Data block에서 사용중인 블럭 개수와 동일.(당연함. 블럭 위치정보라서)
앞서 나왔던 Linked Allocation의 단점을 전부 해결했다고 봄
- 단점
- 직접 접근이 불가능하다. 포인터를 쭉~ 따라가면서 접근해야함.
- 앞에 sector가 잘못되면 뒤에 sector도 못찾아간다.(Reliability)
- 포인터만큼의 공간을 차지한다.(약 4byte?)
- 장점
- 디스크 입장에서 직접 접근임. (FAT은 연결리스트라 차례대로 순회해야하지만 보통 FAT은 메모리에 올려둬서 빠르게 접근하고, 디스크 블록을 차례대로 접근하진 않기 때문에 직접 접근이라고 봄.)
- Reliability제거 - FAT만 안고장나면 disk는 Reliablility없음. FAT은 보통 복사본을 2개 이상 만들어놔서 안전하다고 함. 무적의 논리
Free-Space Management
할당이 안된 빈 블럭들을 어떻게 관리할까?
비트맵 & 비트벡터
블럭 개수 만큼 비트맵을 만들어서 비트로 상태 관리
- 연속적인 n개의 빈 블럭을 찾는데 효과적이다. 연속 할당 편리
- 비트맵을 만들 부가적인 공간이 필요
Linked List
빈 블럭들을 연결리스트로 저장
- 공간의 낭비가 없다. (라기엔 포인터가 차지하는 공간이 있지 않나? 비트맵이 오히려 공간 더 적을 것 같은데. 할당된 블럭에는 포인터가 없으니까 필요한 블럭에만 포인터를 저장한다는 점에서 공간 낭비가 없다는 겅가)
- 연속적인 빈 블럭들을 찾기 어려움
Grouping
Indexed Allocation과 유사한 방법.
free block의 마지막 포인터가 다음 free block을 가리키는 모양새
- 연속적인 블럭을 찾기 어려움
Counting
빈 블럭들의 위치와, 해당 위치에서 몇 개의 블럭이 연속적으로 비어져 있는지를 저장.
(1, 3) -> 1번 위치에서 3개의 블럭이 비어져있다.
- 연속적인 블럭을 찾기 쉬움
Directory 구현

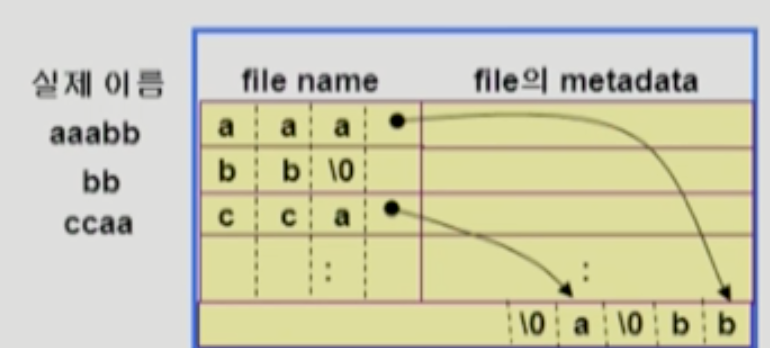
- 긴 파일 이름을 저장하는 방식 : file name크기를 초과하는 부분은 directory의 나머지 영역에 저장. file name에서 해당 부분을 가리키는 포인터를 가지고 있음.
VFS와 NFS
-
VFS(Virtual File System): 하나의 컴퓨터에서 여러 개의 파일시스템을 사용할 수 있다. 동일한 시스템콜로 다양한 파일시스템에 접근할 수 있게 해주는 layer. -
NFS(Network File System): 로컬에 저장된 파일 시스템을 사용할 수도 있지만 원격으로 다른 서버에 있는 파일 시스템을 사용할 수도 있음. 분산 시스템에서 네트워크를 통해 파일을 공유하는 방법. (예시 사진에선 RPC를 사용해서 접근)
Page Cache와 Buffer Cache
Page Cache:- VM의 페이징 시스템에서 사용하는 페이지 프레임을 캐싱.
- Memory-Mapped I/O를 쓰는 경우 파일 I/O에서도 페이지 캐시 사용
- 운영체제에게 주어지는 정보가 제한적. 정확한 페이지 접근 시간을 알 수 없어서 클락 알고리즘 사용.
- Memory-Mapped I/O : 버퍼를 프로세스의 가상 메모리 영역과 매핑해서 사용. 완전 매핑이므로 레이스 컨디션 발생 가능. 반면에 파일 시스템에서 사용하는 read()/write()를 사용한 I/O는 버퍼의 내용을 메모리로 복사해서 사용하기 때문에 프로세스간 레이스 컨디션 발생하지 않음.
보통 프로세스의 code영역을 memory-mapped해서 사용한다고 한다.(read-only이라 수정할 일이 없기 때문)
-
Buffer Cache:- 파일 시스템을 통한 I/O연산은 버퍼 캐시 사용.
- 모든 프로세스가 공용으로 사용함.
- 파일을 접근할 때 시스템 콜을 하기 때문에 운영체제가 파일의 요청이 언제 일어났는 지 알 수 있음-> LRU 알고리즘 사용 가능.
-
Unified Buffer Cache: 버퍼 캐시가 페이지 캐시에 통합됨. 버퍼 캐시도 페이지 단위로 관리. (512byte -> 4KB)
Unified Buffer Cache 여부에 따른 비교
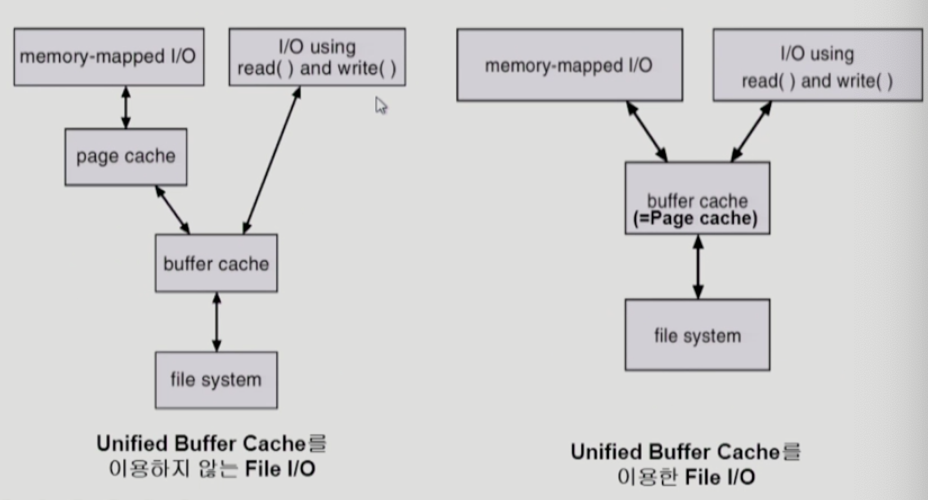
Unifed Buffer Cache를 사용하지 않을 때는 page cache에 저장한 내용을 한 번 더 buffer cache에 저장해야 한다는 단점이 존재.
