Beautiful Soup for web data
test.html
<!DOCTYPE html>
<html>
<head>
<title>Simple HTML code by hhaemin</title>
</head>
<body>
<div>
<p class="inner-text first item" id="first">
Happy Zerobase.
<a href="http://www.pinkwink.kr" id="pw-link">pinkwink</a>
</p>
<p class="inner-text second-item">
Happy Data Science.
<a href="https://www.python.org" target="_blink" id="py-link">python</a>
</p>
</div>
<p class="outer-text first item" id="second">
<b>
Data Science is funny.
</b>
</p>
<p ckass="outer-text">
<i>
All I need is Love.
</i>
</p>
</body>
</html>- HTML 태그는 웹 페이지를 표현
- HEAD 태그는 눈에 보이진 않지만 문서에 필요한 헤더 정보를 보관
- BODY 태그는 눈에 보이는 정보를 보관
install
!pip install beautifulsoup4
import
from bs4 import BeautifulSoup
page = open("../data/zerobase.html","r").read()
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())- 파일로 저장된 html 파일을 읽을 때
- open : 파일명과 함께 읽기(r) / 쓰기(w) 속성을 지정
- html.parser : Beautiful Soup의 html을 읽는 엔진 중 하나(lxml도 많이 사용)
- prettify() : html 출력을 이쁘게 만들어 주는 기능
soup.head : head 태그 확인
soup.p /soup.find("p") : p 태그 확인 (처음 발견한 p 태그만 출력)
# .text() : 안에 있는 text만 출력
# strip() : 양쪽의 공백을 생략하고 출력
soup.find("p",{"class":"outer-text first item"}).text.strip()'Data Science is funny.'
# 다중 조건
soup.find("p", {"class":"inner-text first item","id":"first"})>
<p class="inner-text first item" id="first">
Happy Zerobase.
<a href="http://www.pinkwink.kr" id="pw-link">pinkwink</a>
</p>
soup.find_all() : 지정된 태그를 모두 찾아준다. 리스트형태로 반환
soup.find_all(id="pw-link")[0].text
> 'pinkwink'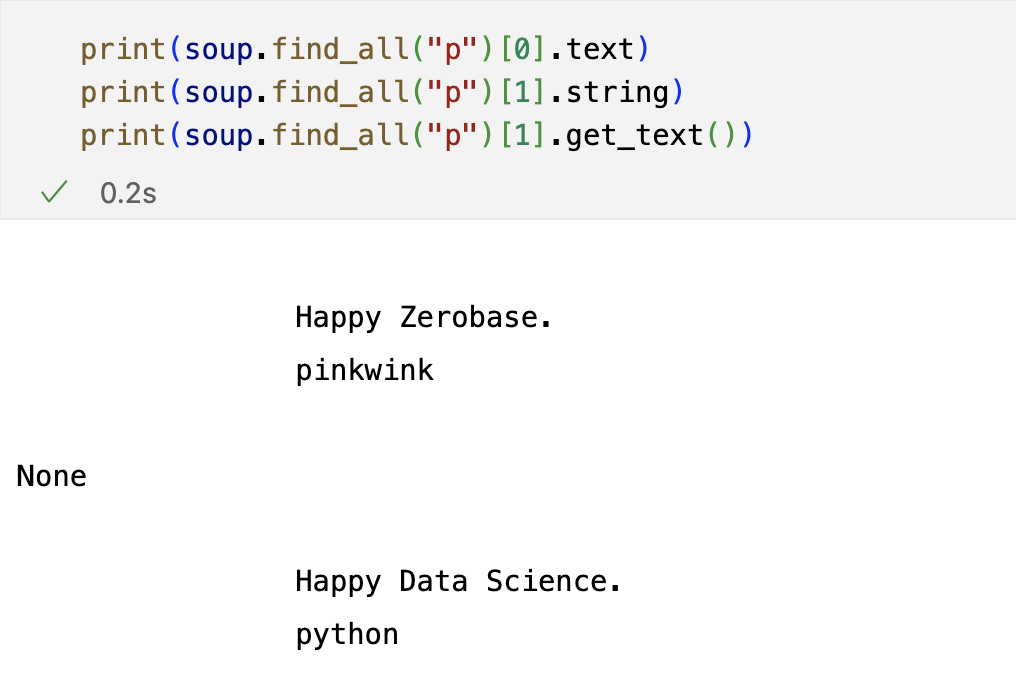
- soup.find_all(id="first")
- 이렇게 사용하는 경우가 더 많다.

- 외부로 연결되는 링크의 주소를 알아내는 방법
# a 태그에서 href 속성값에 있는 값 추출
links = soup.find_all("a")
links[0].get("href"),links[1]["href"]for each in links:
href = each.get("href") # each["href"]
text = each.get_text()
print(text + "=>" + href)pinkwink=>http://www.pinkwink.kr
python=>https://www.python.org
크롬 개발자 도구 - 환율정보 가져오기
# import
from urllib.request import urlopen
from bs4 import BeautifulSoupurl = "https://finance.naver.com/marketindex/index.naver"
page = urlopen(url)
response = urlopen(url)
response.status
soup = BeautifulSoup(page,"html.parser")
print(soup.prettify)- HTML 태그가 위치한 곳 찾기
- 3가지 방법
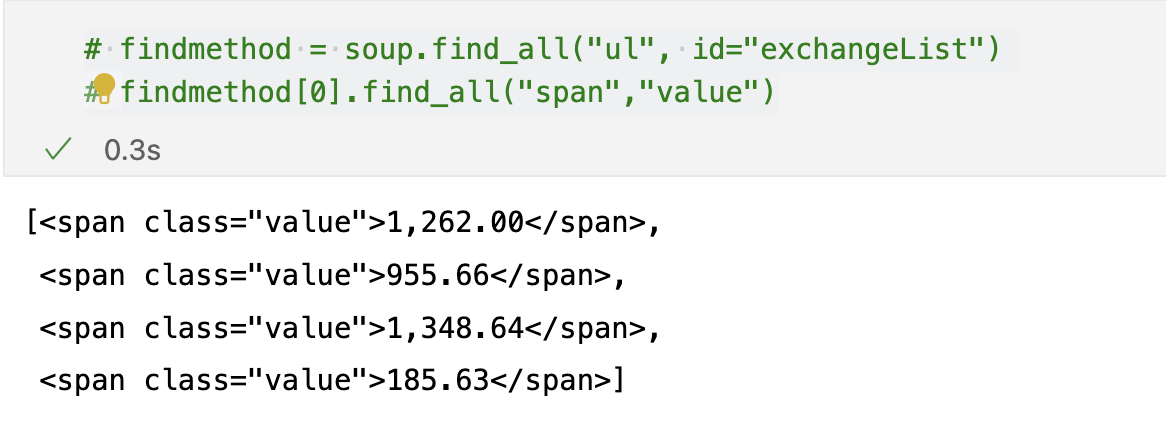
<span class = "value"># 1
soup.find_all("span","value"), len(soup.find_all("span","value"))
# 2
soup.find_all("span",class_="value"), len(soup.find_all("span","value"))
# 3
soup.find_all("span",{"class":"value"}),len(soup.find_all("span",{"class":"value"}))>
([<span class="value">1,262.00</span>,
<span class="value">955.66</span>,
<span class="value">1,348.64</span>,
<span class="value">185.63</span>,
<span class="value">132.5900</span>,
<span class="value">1.0744</span>,
<span class="value">1.2051</span>,
<span class="value">103.4900</span>,
<span class="value">74.11</span>,
<span class="value">1578.7</span>,
<span class="value">1879.5</span>,
<span class="value">75755.33</span>],
12)soup.find_all("span",{"class":"value"})[0].text, soup.find_all("span",{"class":"value"})[0].string, soup.find_all("span",{"class":"value"})[0].get_text()('1,262.00', '1,262.00', '1,262.00')
- 웹주소(URL)에 접근할 때는 urllib의 request 모듈이 필요하다
!pip install requests
import requests
# from urllib.request.Request
from bs4 import BeautifulSoup
url = "https://finance.naver.com/marketindex/index.naver"
response = requests.get(url)
# request.get(), request.post()
# response.text
soup = BeautifulSoup(response.text,"html.parser")
print(soup.prettify())# soup.find_all("li","on")
# id => #
# class => .
exchangeList = soup.select("#exchangeList > li")
len(exchangeList), exchangeList>
Output exceeds the size limit. Open the full output data in a text editor
(4,
[<li class="on">
<a class="head usd" href="/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW" onclick="clickcr(this, 'fr1.usdt', '', '', event);">
<h3 class="h_lst"><span class="blind">미국 USD</span></h3>
<div class="head_info point_up">
<span class="value">1,262.00</span>
<span class="txt_krw"><span class="blind">원</span></span>
<span class="change">4.00</span>
<span class="blind">상승</span>
</div>
</a>
<a class="graph_img" href="/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW" onclick="clickcr(this, 'fr1.usdc', '', '', event);">
<img alt="" height="153" src="https://ssl.pstatic.net/imgfinance/chart/marketindex/FX_USDKRW.png" width="295"/>
</a>
<div class="graph_info">
<span class="time">2023.02.07 22:36</span>
<span class="source">하나은행 기준</span>
<span class="count">고시회차<span class="num">593</span>회</span>
</div>
</li>,
<li class="">
<a class="head jpy" href="/marketindex/exchangeDetail.naver?marketindexCd=FX_JPYKRW" onclick="clickcr(this, 'fr1.jpyt', '', '', event);">
<h3 class="h_lst"><span class="blind">일본 JPY(100엔)</span></h3>
<div class="head_info point_up">
<span class="value">955.66</span>
...
<span class="time">2023.02.07 22:36</span>
<span class="source">하나은행 기준</span>
<span class="count">고시회차<span class="num">593</span>회</span>
</div>
</li>])title = exchangeList[0].select_one(".h_lst").text
exchange = exchangeList[0].select_one(".value").text
change = exchangeList[0].select_one(".change").text
updown = exchangeList[0].select_one("div.head_info.point_up > .blind").text
# 만약 태그에 띄워쓰기가 있다면 중간에 .을 찍어준다.
# >이 있다면 바로 밑 하위이고, >이 없다면 자손이다.
#link
title,exchange,updown('미국 USD', '1,262.00', '상승')
baseUrl = "https://finance.naver.com"
baseUrl + exchangeList[0].select_one("a").get("href")'https://finance.naver.com/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW'
# 4개 데이터 수집
import pandas as pd
import openpyxl
exchange_datas = []
baseUrl = "https://finance.naver.com"
for item in exchangeList:
try:
data = {
"title":item.select_one(".h_lst").text,
"exchange":item.select_one(".value").text,
"change":item.select_one(".change").text,
"updown":item.select_one("div.head_info.point_up > .blind").get_text(),
"link": baseUrl + item.select_one("a").get("href")
}
except:
data = {
"title":item.select_one(".h_lst").text,
"exchange":item.select_one(".value").text,
"change":item.select_one(".change").text,
"updown":"상승",
"link": baseUrl + item.select_one("a").get("href")
}
exchange_datas.append(data)
df = pd.DataFrame(exchange_datas)
df, df.to_excel("./naverFinance.xlsx", encoding="utf-8")
# 유럽의 updown값이 None으로 뜨는 오류가 발생해서 try~except 예외문 사용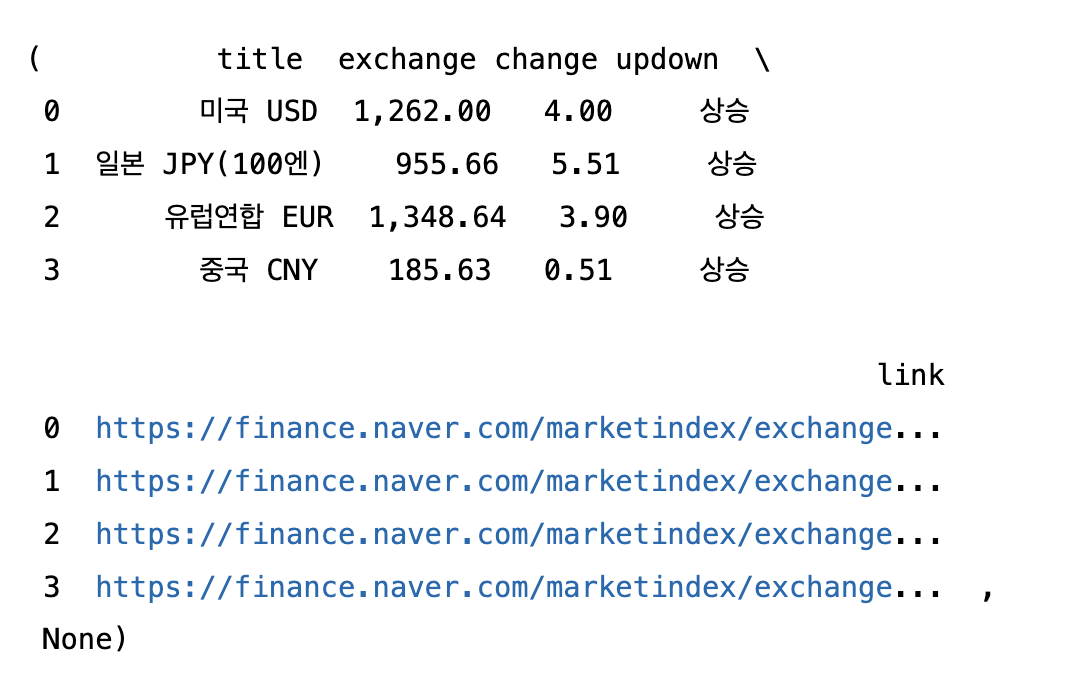
위키백과 데이터 가져오기
https://ko.wikipedia.org/wiki/%EC%97%AC%EB%AA%85%EC%9D%98_%EB%88%88%EB%8F%99%EC%9E%90
- 웹페이지를 복사하면 이상하게 바뀌어서 나타난다.
- 웹주소는 utf-8로 인코딩 되어야 한다.
- url decode 사이트에서 디코더한다.
- https://ko.wikipedia.org/wiki/여명의_눈동자
import urllib
from urllib.request import urlopen, Request
html = "https://ko.wikipedia.org/wiki/{search_words}"
# https://ko.wikipedia.org/wiki/여명의_눈동자
req = Request(html.format(search_words=urllib.parse.quote("여명의_눈동자")))
# 글자를 URL로 인코딩
response = urlopen(req)
soup = BeautifulSoup(response,"html.parser")
print(soup.prettify())n = 0
# 구분하기 위해서 n 변수를 줌
for each in soup.find_all("ul"):
print("=>" + str(n)+ "====================")
print(each.get_text())
n += 1
- 32번째에 등장인물이 있다.

soup.find_all("ul")[32].text.strip().replace("\xa0","").replace("\n","")- \xa0을 없애주기 위해서 replace() 사용
Python List 데이터형
list형은 대괄호로 생성


- copy()를 사용하면 리스트를 변경하여도 그때만 변경되지 다시 출력한다면 원래의 값으로 돌아옴
반복문(for) 적용
for color in colors:
print(color)red
black
green
in 명령으로 조건문(if)에 적용

append()
- list 제일 뒤에 값을 하나 추가
movies = ["라라랜드","먼 훗날 우리","어벤져스","다크나이트"]
movies.append("타이타닉")['라라랜드', '먼 훗날 우리', '어벤져스', '다크나이트', '타이타닉']
pop()
- 리스트 제일 뒤부터 자료를 하나씩 삭제
movies.pop()'타이타닉'

extend()
- 제일 뒤에 자료 추가
movies.extend(["위대한 쇼맨","인셉션"])
movies['라라랜드', '먼 훗날 우리', '어벤져스', '다크나이트', '위대한 쇼맨', '인셉션']
remove()
- 자료를 삭제
movies.remove("어벤져스")['라라랜드', '먼 훗날 우리', '다크나이트', '위대한 쇼맨', '인셉션']
슬라이싱
- [n:m] n번째 부터 m-1까지
movies[2:4]['다크나이트', '위대한 쇼맨']
favorite_movies = movies[2:4]
favorite_movies['다크나이트', '위대한 쇼맨']
insert()
- 원하는 위치에 자료를 삽입
favorite_movies.insert(1,9.60)
favorite_movies['다크나이트', 9.6, '위대한 쇼맨']
favorite_movies.insert(3,9.50)
favorite_movies['다크나이트', 9.6, '위대한 쇼맨', 9.5]
리스트 안에 리스트
favorite_movies.insert(5,["레오나르도 디카프리오","조용하"])
favorite_movies['다크나이트', 9.6, '위대한 쇼맨', 9.5, ['레오나르도 디카프리오', '조용하']]
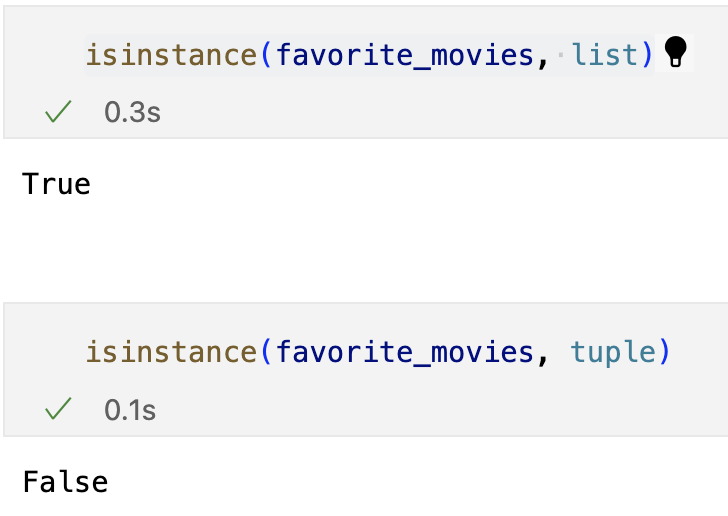
isinstance
- 자료형 True/False
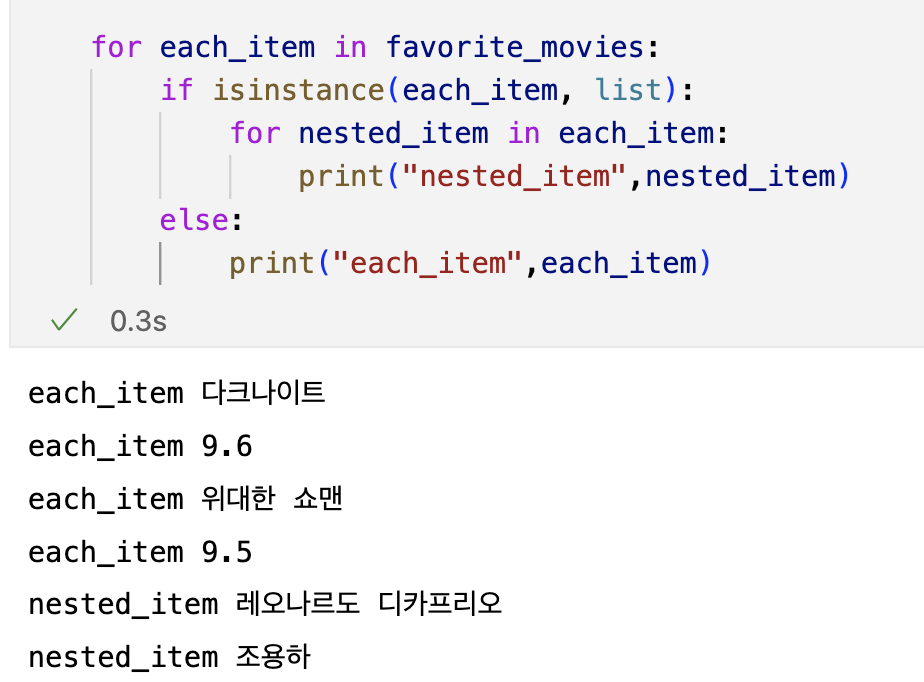
시카고 맛집 데이터 분석 - 개요
최종목표
- 총 51개 페이지에서 각 가게의 정보를 가져온다.
- 가게이름
- 대표메뉴
- 대표메뉴의 가격
- 가게주소
pip install fake_useragent
from urllib.request import Request, urlopen
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
url_base = "https://www.chicagomag.com/"
url_sub = "chicago-magazine/november-2012/best-sandwiches-chicago/"
url = url_base + url_sub
ua = UserAgent()
# ua.ie
req = Request(url, headers={"user-agent": ua.ie})
html = urlopen(req)
soup = BeautifulSoup(html,"html.parser")
print(soup.prettify())메뉴 이름 가져오기
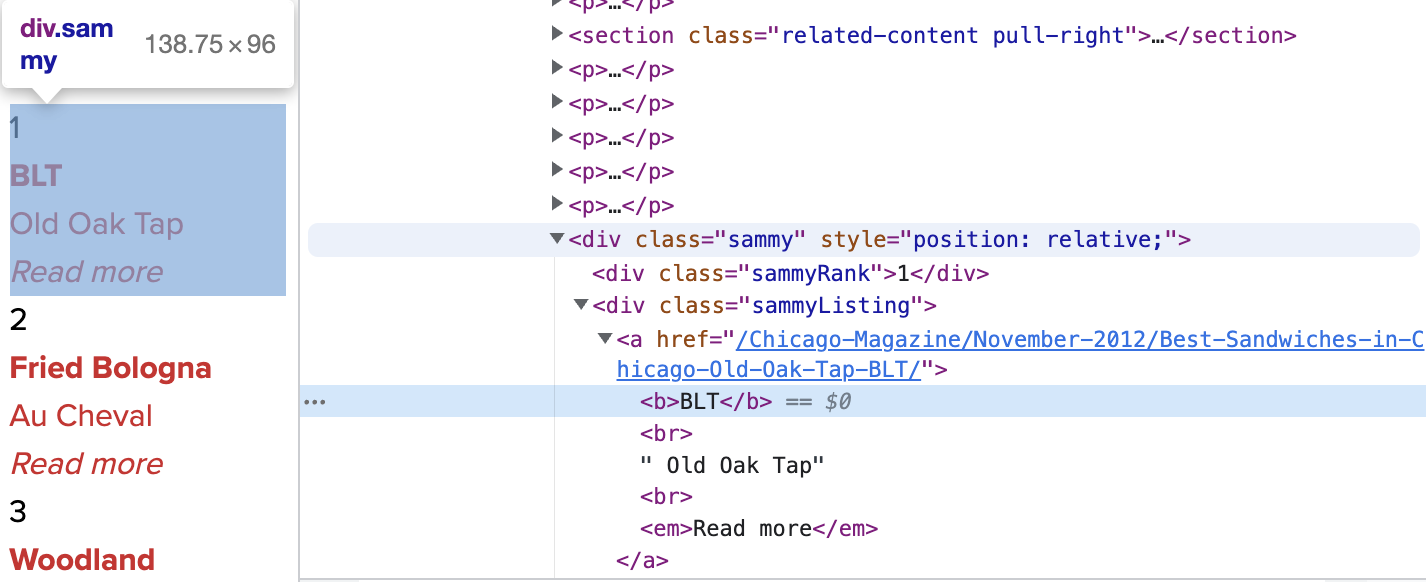
soup.find_all("div","sammy"), len(soup.find_all("div","sammy"))
# soup.select(".sammy"), len(soup.select(".sammy"))순위 가져오기

tmp_one.find(class_="sammyRank").get_text()
# tmp_one.select_one(".sammyRank").text'1'
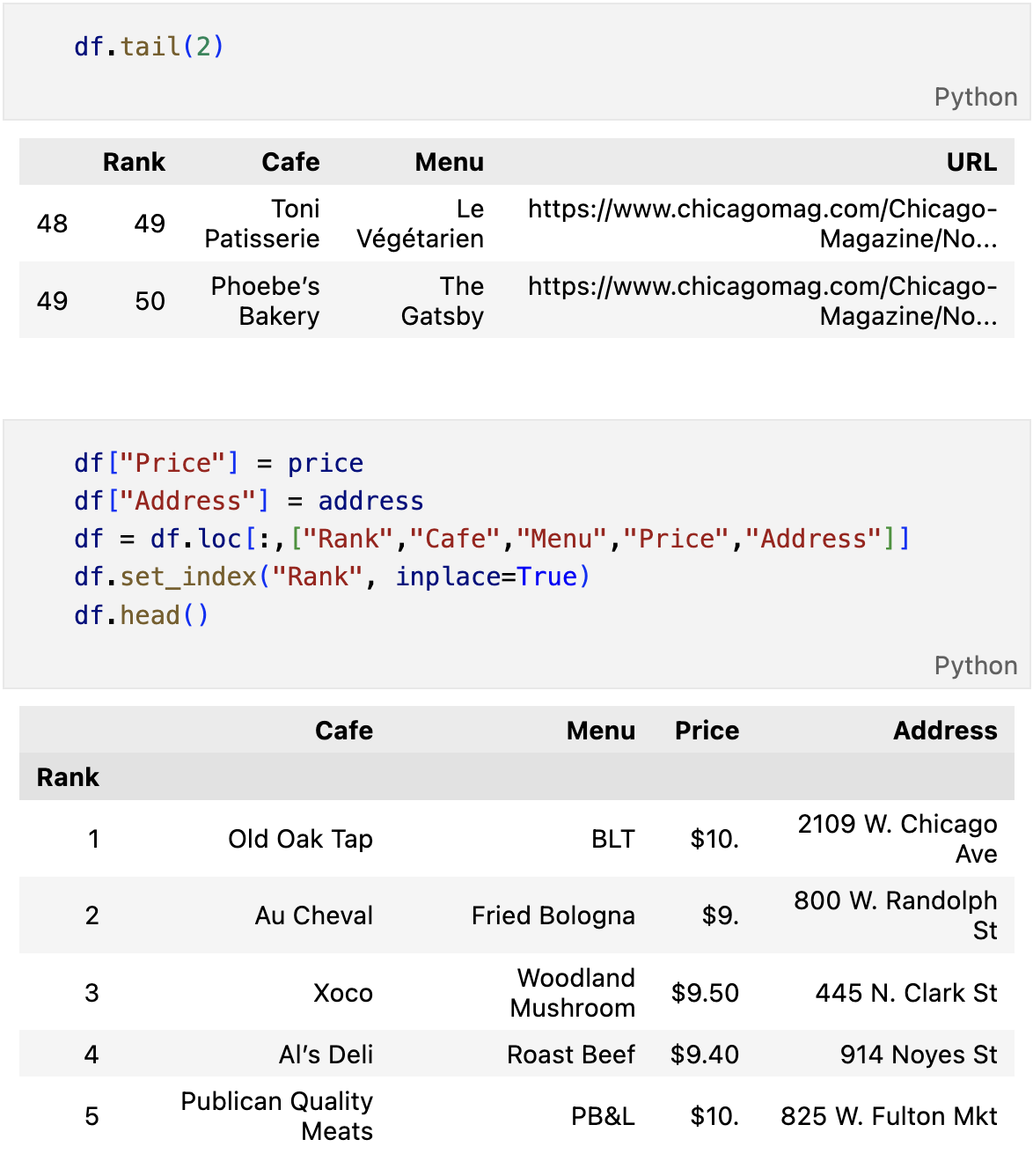
메뉴이름, 가게이름

from urllib.parse import urljoin
url_base = "https://www.chicagomag.com/"
# 필요한 내용을 담을 빈 리스트
# 리스트로 하나씩 컬럼을 만들고, DataFrame으로 합칠 예정
rank = []
main_menu = []
cafe_name = []
url_add = []
list_soup = soup.find_all("div","sammy")
for item in list_soup:
rank.append(item.find(class_="sammyRank").get_text())
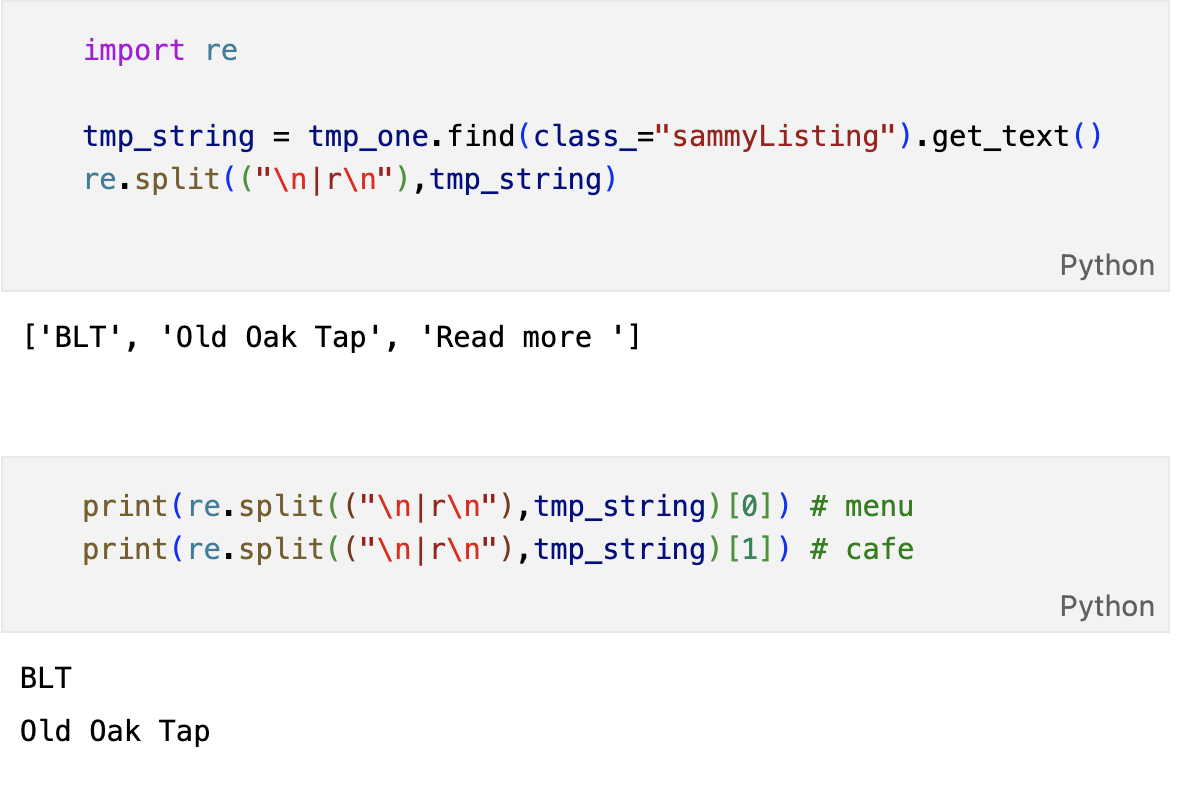
tmp_string = item.find(class_="sammyListing").get_text()
main_menu.append(re.split(("\n|r\n"),tmp_string)[0])
cafe_name.append(re.split(("\n|r\n"),tmp_string)[1])
url_add.append(urljoin(url_base, item.find("a")["href"]))
- 갯수가 50개 맞는지 확인
- 순위, 메뉴, 가게, url 모두 갯수가 같아야 한다

가게주소, 가격

from tqdm import tqdm
price = []
address = []
for idx,row in df.iterrows():
req = Request(row["URL"], headers={"user-agent":"Mozilla/5.0"})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html,"html.parser")
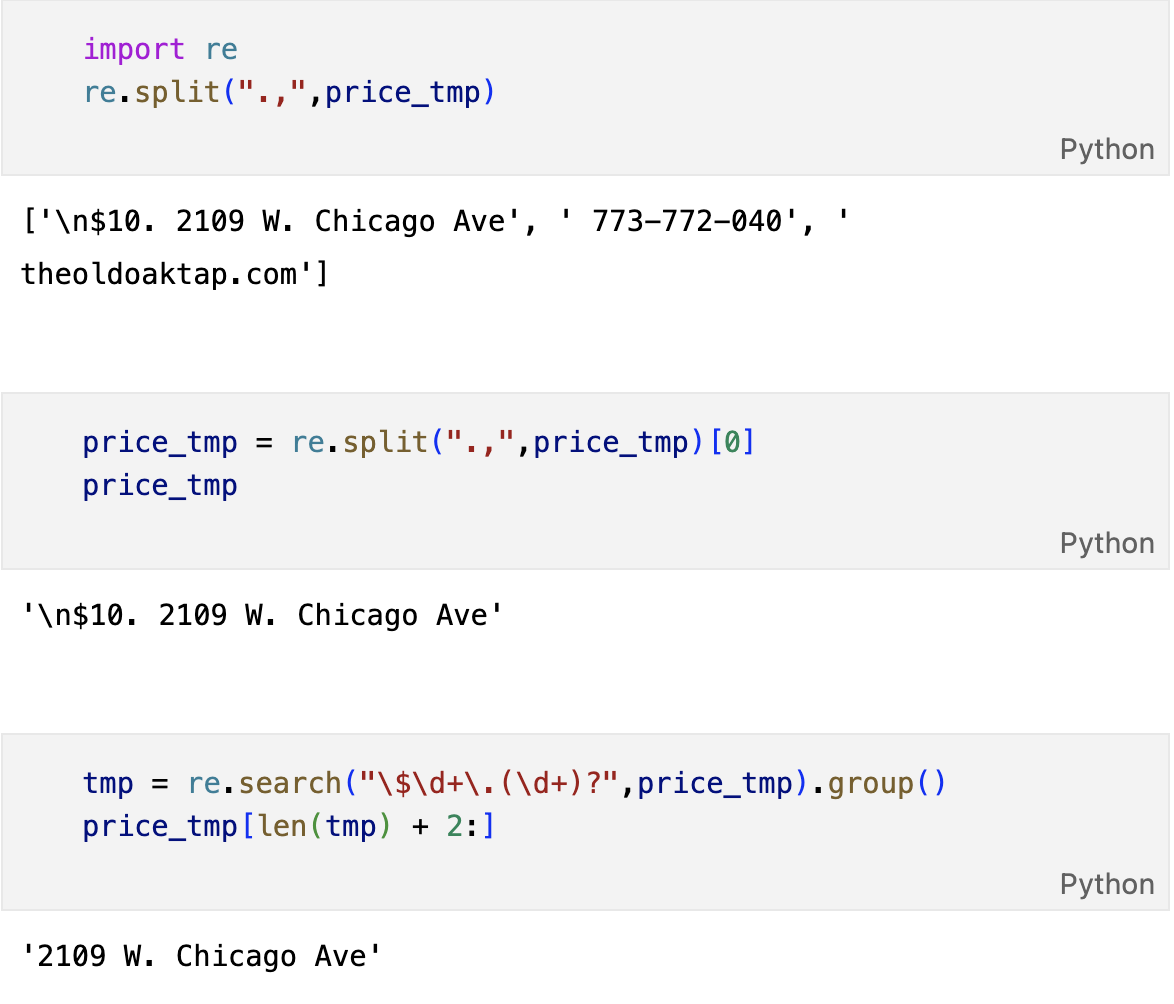
gettings = soup_tmp.find("p","addy").get_text()
price_tmp = re.split(".,",gettings)[0]
tmp = re.search("\$\d+\.(\d+)?",price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp)+2:])
print(idx)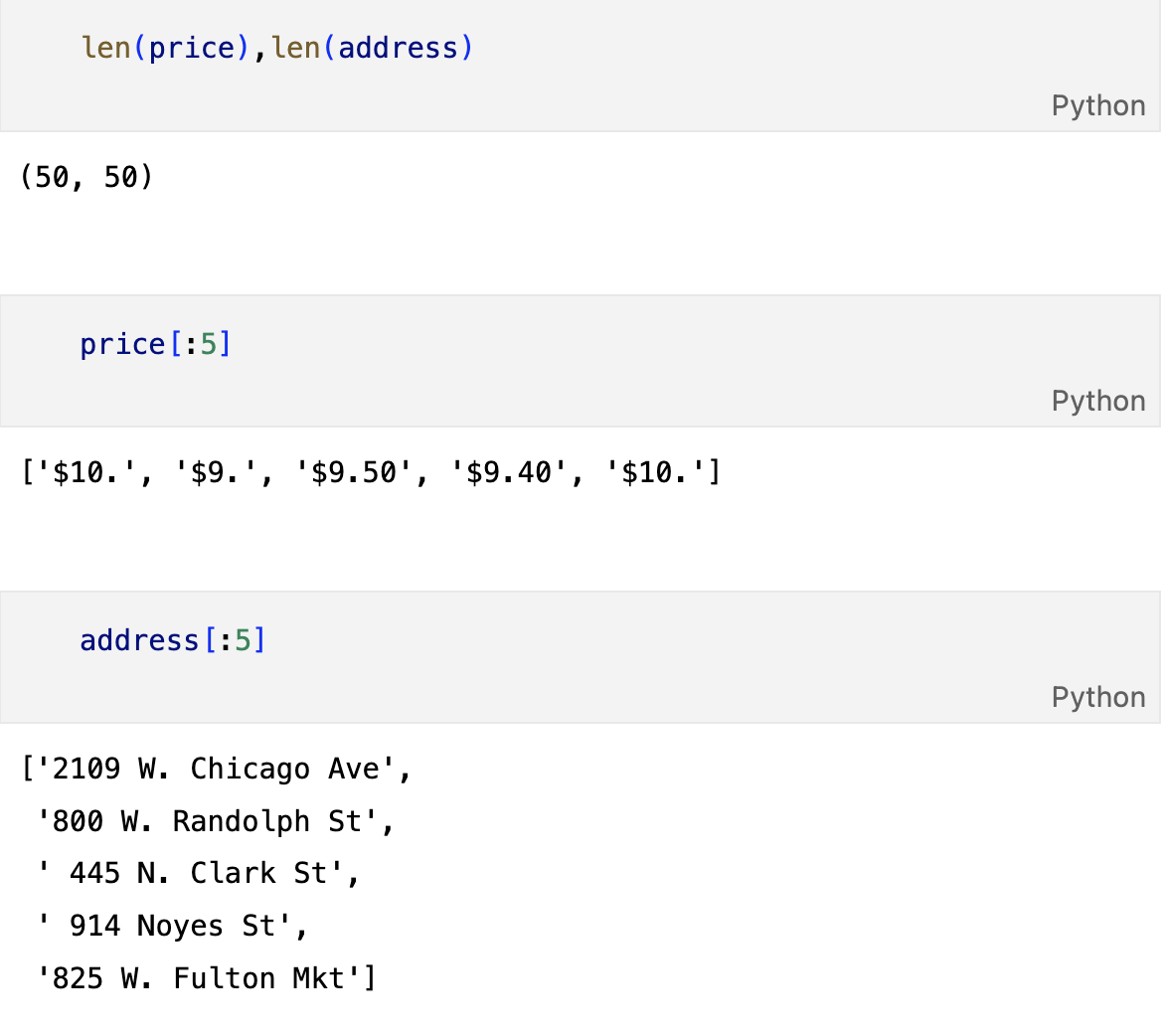
시카고 맛집 데이터 지도 시각화
# requirements
import folium
import pandas as pd
import numpy as np
import googlemaps
from tqdm import tqdmgmaps_key = ""
gmaps = googlemaps.Client(key=gamps_key)lat = []
lng = []
for idx, row in tqdm(df.iterrows()):
if not row["Address"]=="Multiple location":
target_name = row["Address"] + "," + "Chicago"
# print(target_name)
gmaps_output = gmaps.geocode(target_name)
location_output = gmaps_output[0].get("geometry")
lat.append(location_output["location"]["lat"])
lng.append(location_output["location"]["lng"])
# location_output = gmaps_output[0]
else:
lat.append(np.nan)
lng.append(np.nan)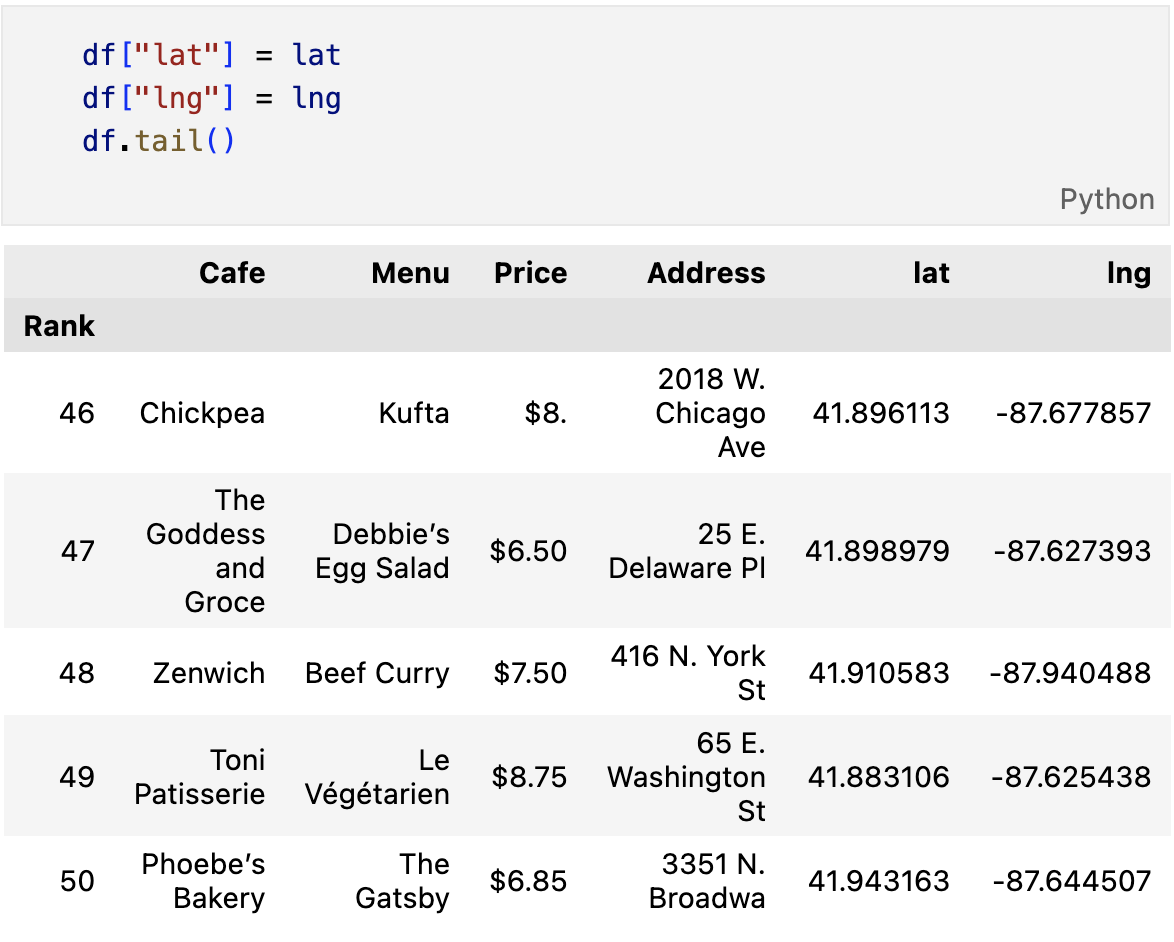
mapping = folium.Map(location=[41.896113,-87.677857],zoom_start=11)
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
folium.Marker(
location=[row["lat"],row["lng"]],
popup=row["Cafe"],
tooltip=row["Menu"],
icon=folium.Icon(
icon="coffee",
prefix="fa"
)
).add_to(mapping)
mapping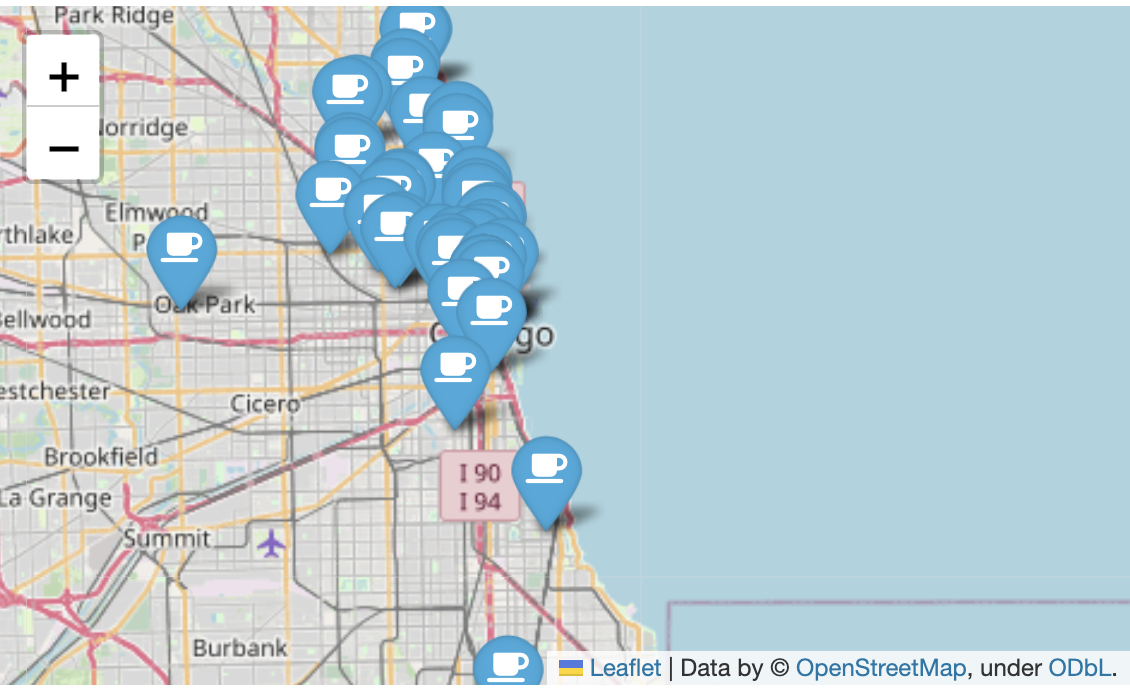

데이터분석가