using Python - anaconda & jupyter notebook
📌 fb-Prophet
- Python으로 forecast(시계열 분석) 하는 모듈
- facebook https://facebook.github.io/prophet/
window 환경에서 설치할 때, Visual C++ Build Tool 이 설치된 가정하에 진행된다.
prompt나 termianl 에서
conda install pandas-datareader 를 먼저 하고,
conda install -c conda-forge fbprophet
설치가 완료되었는데
import fbprophet 를 해서 오류가 난다면,
pip install --upgrade plotly 를 해서 해결할 수 있다.
📚 기초
분석 결과를 그래프로 나타내기 위해 matplotlib도 함께 import 해줘야한다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from fbprophet import Prophet
%matplotlib inline먼저 fbprophet에 맞는 데이터가 필요하니, 시계열 형태로 삼각함수 그래프를 그려보자.
time = np.linspace(0, 1, 365*2)
result = np.sin(2*np.pi*12*time)
ds = pd.date_range("2018-01-01", periods=365*2, freq="D")
df = pd.DataFrame({"ds":ds, "y":result})
df["y"].plot(figsize=(10,6));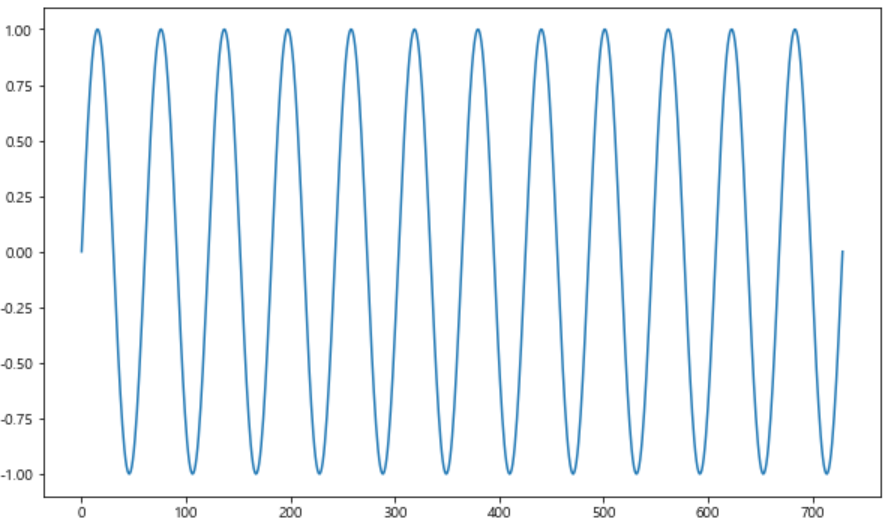
기본 그래프가 이렇게 생긴 상태에서 이후 30일간의 데이터를 예측해보고 그래프에 나타내보자.
# 학습
m = Prophet(yearly_seasonality=True, daily_seasonality=True)
m.fit(df);
# 이후 30일간의 데이터 예측
future = m.make_future_dataframe(periods=30)
forecast = m.predict(future)
m.plot(forecast);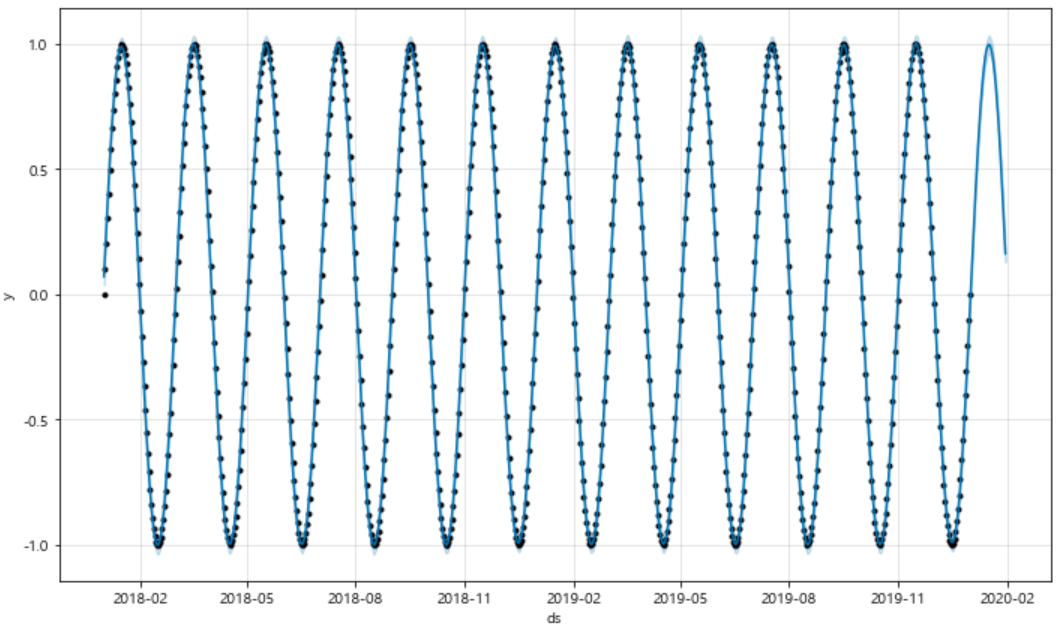
위에서 검은색 점으로 표현된 부분은 실제 학습에 이용된 데이터이고, 점이 사라진 시점부터는 예측된 데이터의 그래프이다.
앞선 데이터에 기반해 그려진 내용처럼 잘 그려진 것을 확인할 수 있다.
bias 넣어서 예측해보기
위의 코드와 같은데 처음에 df의 result에 bias를 붙여서 바꿨다.
result = np.sin(2*np.pi*12*time) + time + np.random.randn(365*2)/4
학습하고 그래프 그리는 코드는 모두 같다.
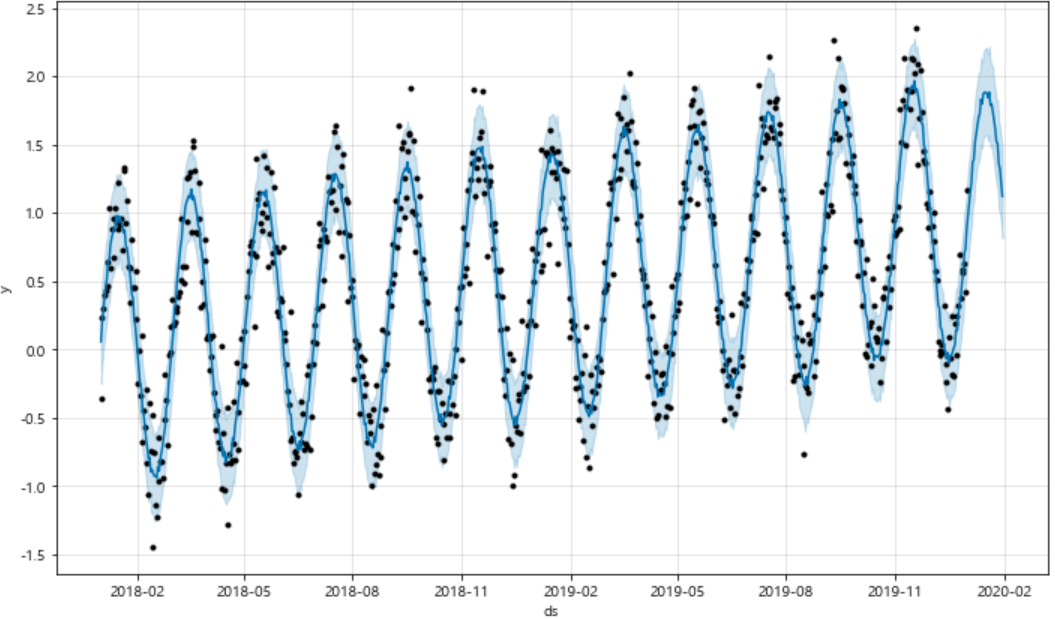
흐리게 하늘색으로 표현된 부분은 저 범위 내에 값이 포함될 수 있다는 오차범위로 생각하면 된다.
📌 주식 데이터 fbprophet 분석
- yahoo finance 주식 데이터 forecast
- https://finance.yahoo.com/quote/035420.KS/history?p=035420.KS&guccounter=1
- 크롤링해 데이터 확보
yahoo finance 주식 데이터 크롤링
from bs4 import BeautifulSoup
from urllib.request import urlopen, Request
url = "https://finance.yahoo.com/quote/035420.KS/history?p=035420.KS&guccounter=1"
req = Request(url, headers={"User-Agent":"Chrome"})
page = urlopen(req).read()
soup = BeautifulSoup(page, "html.parser")
table = soup.find("table")
df_raw = pd.read_html(str(table))[0]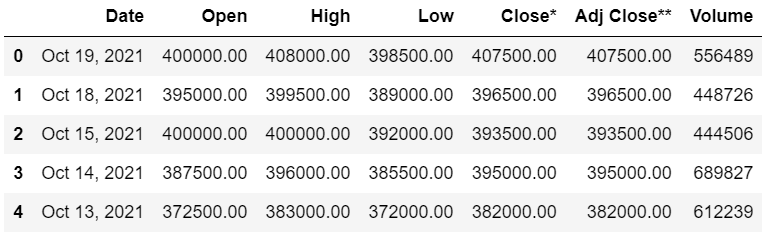
이렇게 생긴 데이터 프레임에서 종가 데이터를 활용해 forecast를 진행한다.
fbprophet 사용 형식에 맞추기
df_tmp = pd.DataFrame({"ds":df_raw["Date"], "y":df_raw["Close*"]})
df_target = df_tmp[:-1] # 끝에 NaN 값을 제거함
# 혹시 모를 데이터 손실 보호를 위해 hardcopy
# 날짜 형태 변경
df = df_target.copy()
df["ds"] = pd.to_datetime(df_target["ds"], format="%b %d, %Y")
# .info()로 확인하면 object이기 때문에 숫자로 바꿔줌
df["y"] = df["y"].astype("float")prophet 적용 & 예측
m = Prophet(yearly_seasonality=True, daily_seasonality=True)
m.fit(df);
future = m.make_future_dataframe(periods=30)
forecast = m.predict(future)
forecast[["ds", "yhat", "yhat_lower", "yhat_upper"]].tail()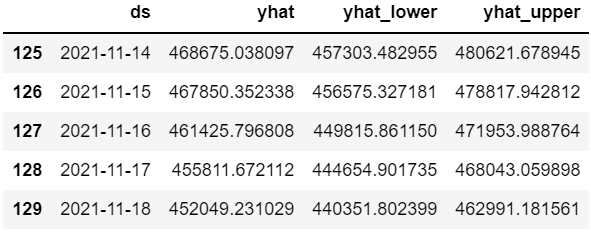
원래 총 100개의 데이터가 있었는데, 이후 30일 예측 데이터가 추가되어 총 130개의 데이터가 저장된 것을 확인할 수 있다.
시각화
plt.figure(figsize=(12,6))
plt.plot(df["ds"], df["y"], label="real")
plt.grid(True)
plt.show()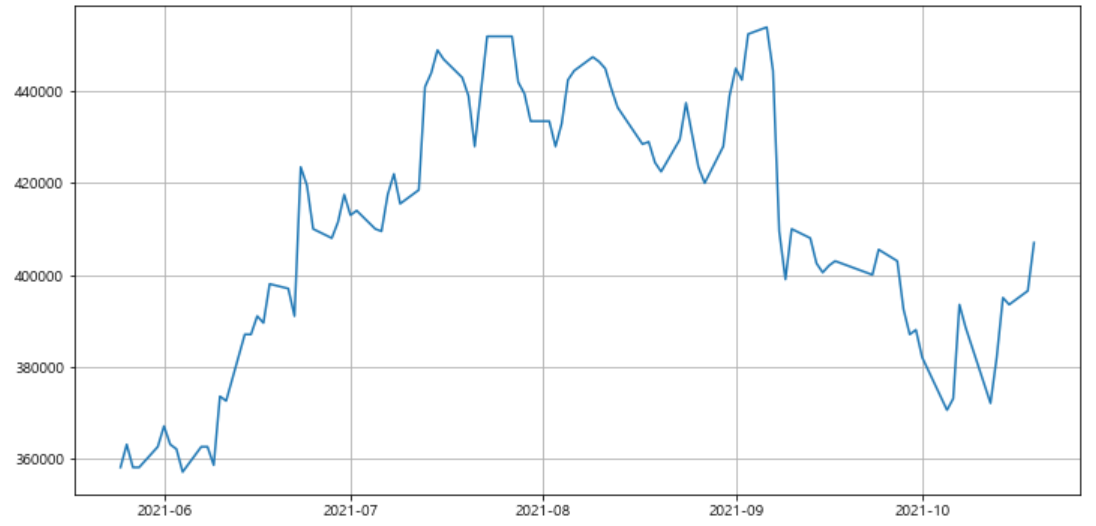
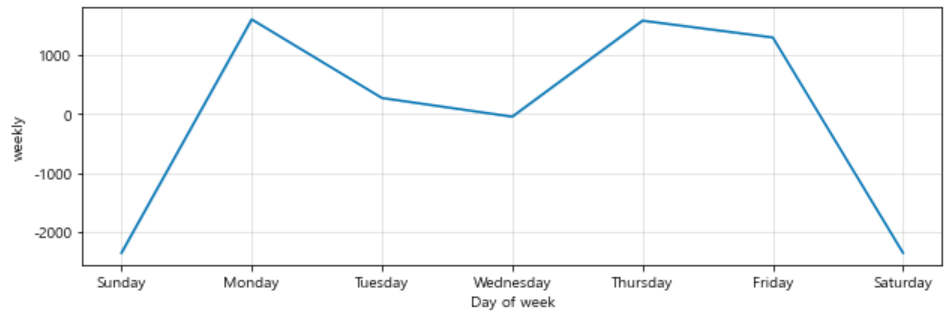
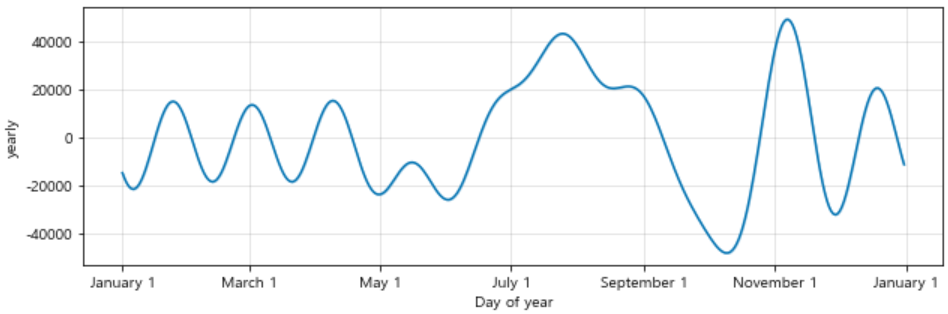
이번에는 forecast component별 시각화를 해보자.
- trend, weekly, yearly
m.plot_components(forecast);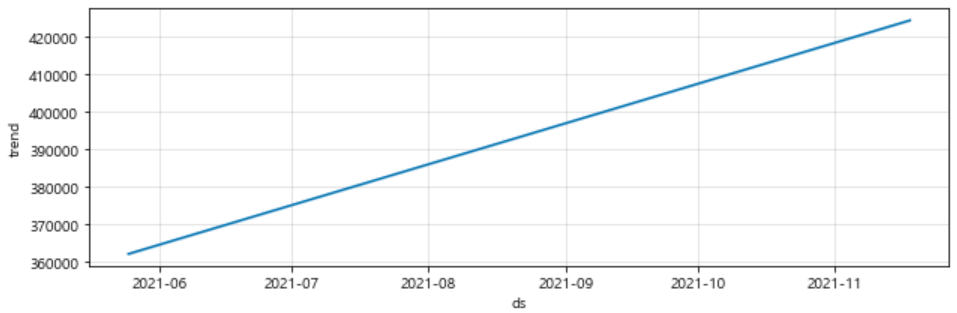
📚 yfinance 활용
- 기존의 pandas data_reader의 주가 정보 읽어오는 기능
- 우회적으로 활용할 수 있는 임시 모듈
pip install yfinance설치
기아 자동차 종목 코드를 넣어 데이터 가져오기
import yfinance as yf
from pandas_datareader import data
yf.pdr_override()
start_date = "2010-03-01"
end_date = "2018-02-28"
# get_data_yahoo(종목코드, 시작일, 마감일)
KIA = data.get_data_yahoo("000270.KS", start_date, end_date)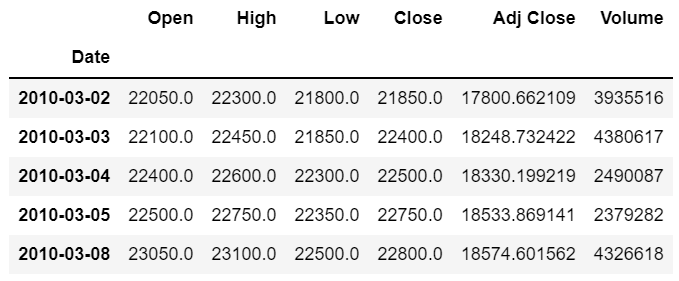
위에서 야후 크롤링 한 것처럼 데이터가 가져와졌다.
이번에도 "Close" 종가 데이터 기준으로 진행한다.
fbprophet 사용 형식에 맞추기
# accuracy 확인을 위한 데이터
KIA_trunc = KIA[:"2017-11-30"]
df = pd.DataFrame({"ds":KIA_trunc.index, "y":KIA_trunc["Close"]})
df.reset_index(inplace=True)
del df ["Date"]prophet 적용 & 예측
m = Prophet(yearly_seasonality=True, daily_seasonality=True)
m.fit(df);
future = m.make_future_dataframe(periods=90)
forecast = m.predict(future)
forecast[["ds", "yhat", "yhat_lower", "yhat_upper"]].tail()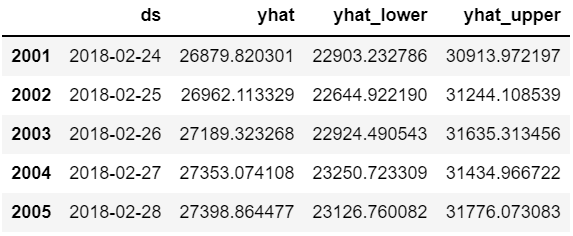
이번에도 예측값 90개의 데이터가 추가되어 forecast 변수에 담겨졌다.
시각화
# 예측 그래프
m.plot(forecast);
# component 별 그래프 (이미지 생략)
m.plot_components(forecast);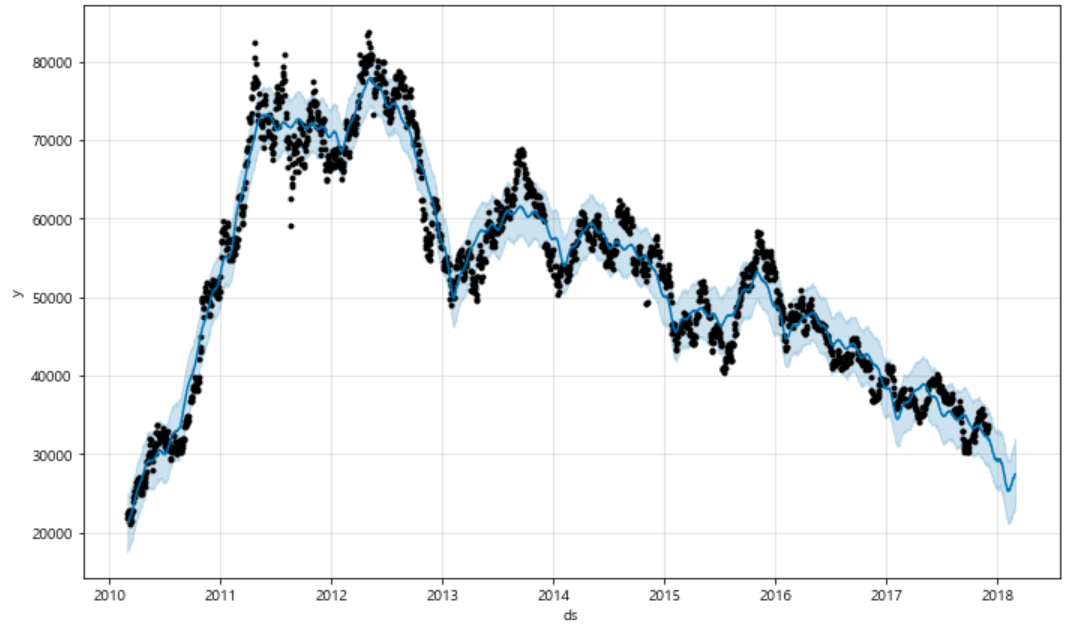
이때도 뒤의 파란색 선 그래프가 예측한 값들에 대한 그래프이다.
이번에는 추가로 실제 데이터와 시계열 예측 데이터를 그래프로 그려 잘 예측했는지 파악해보자.
plt.figure(figsize=(12,6))
plt.plot(KIA.index, KIA["Close"], label="real")
plt.plot(forecast["ds"], forecast["yhat"], label="forecast")
plt.grid(True)
plt.legend()
plt.show()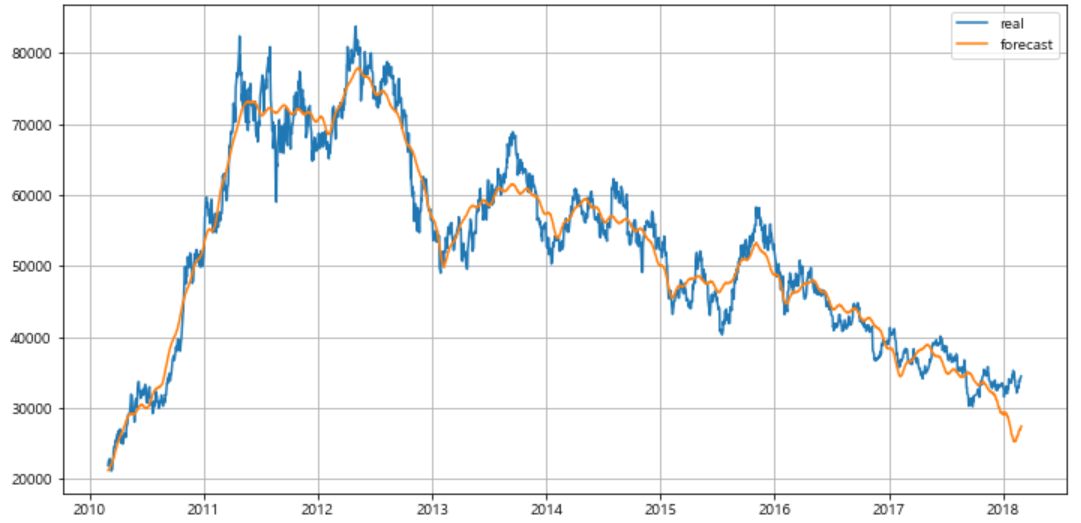
처음에 데이터를 가져올 때 종목코드를 변경하면 다양한 주가 데이터를 확보할 수 있으니, 변경하면서 확인해보는 것도 좋다.
