C++ #1
객체 지향이란
- 객체 : 영문으로 Object, '사물'을 나타내는 추상적인 개념
- 지향 : 영문으로 Oriented, '지향하는' 의미
'현실세계에 있는 모든 사물을 프로그램화 시키겠다'
구조적 프로그래밍과 객체 지향 프로그래밍
-
구조적 프로그래밍 방식
순차적 프로그래밍 방식 / 하향식 및 폭포수 방식이라고 한다.
기능적인 기본 단위는 함수이다.

-
객체 지향 프로그래밍 방식
기능 단위는 객체이다.
사용자의 요청에 의해 처리되는 구조이다.
대표적인 예는 모든 윈도우 프로그램이다.
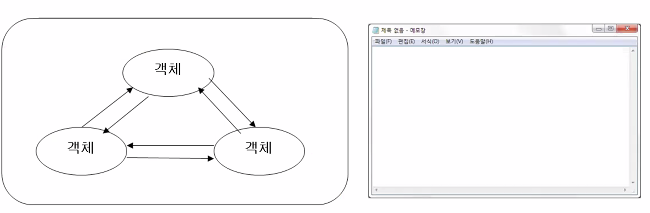
이벤트 기반 프로그램은 전부 다 객체 지향이다.
추상화(Abstraction)
추상화란 무엇인가
구조적 프로그래밍은 설계가 잘못되면 중간에 수정할 수 없다.
객체 지향 프로그래밍은 중간에 수정할 수 있는 구조를 지향한다.
처음에 자세하게 설계하지 않고 점차 구체화가 된다.
상속구조를 통해서 유연한 구조를 만든다.
- 추상 : 대상에서 특징만을 뽑아낸 것
- 우리 일상의 사물들은 관념적이고 추상적인 것들이 많다.

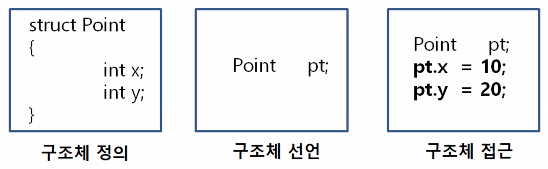
데이터 추상화(Data Abstraction)
사용자가 직접 사용자 정의 타입을 만들어 하나의 데이터 단위로 처리
가장 대표적인 예는 구조체 타입
플라톤의 이데아(Idea)
플라톤의 이데아는 추상화 개념과 일맥 상통한다.
- 플라톤과 제자의 대화

플라톤은 개를 본 적 있냐고 물어본 것이지 무슨 개를 본 적 있냐고 물어본 것은 아니다.
나무를 본 적 있냐고 물어본 것이지 무슨 나무를 본 적 있냐고 물어본 것은 아니다.
플라톤은 개라는 개, 나무라는 나무가 존재하고 있다고 말한다.
개의 본질 개의 원형은 이데아의 세계, 관념의 세계에 존재한다.
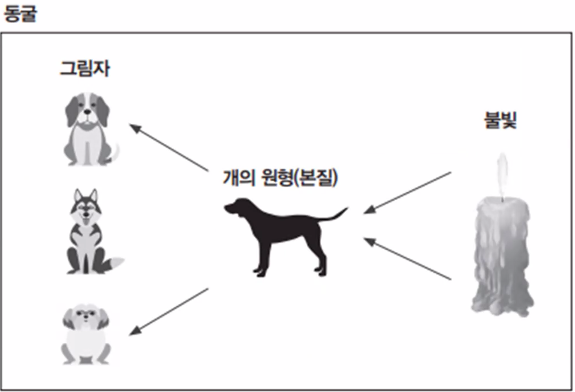
동굴에서 불빛으로 개를 비춰 그림자를 보면 개의 원형에 따라서 여러 종류의 개로 보인다.
"원형을 기반으로 해서 여러 자식 객체들이 만들어질 수 있다."
데이터 은닉(Encapsulation)
캡슐화
- 캡슐화 한다는 것은 외부에서 그 내부를 볼 수 없게 한다는 의미
- 은닉하다, 숨긴다는 의미
- 데이터를 외부로부터 숨긴다는 데이터 추상화와 일맥 상통
- 마냥 숨기기만 한다면 데이터는 무용지물임
- 외부로부터 데이터를 조작할 인터페이스가 필요
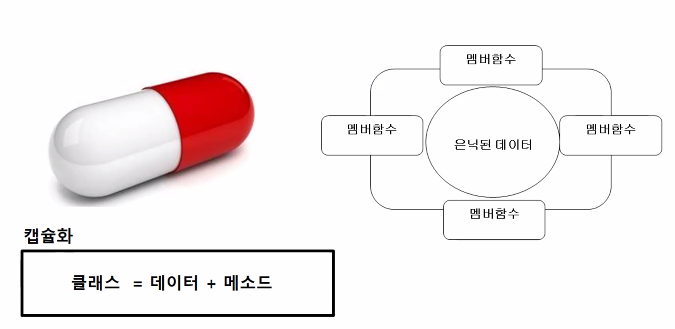
⇛ 데이터를 보호한다
① 객체 지향에서는 기본적으로 데이터는 숨긴다. 즉, 보안적으로 데이터를 은닉시킨다.
② 그 데이터를 조작할 수 있는 인터페이스가 필요하다.
클래스에 종속되어있는 함수를 클래스라고 부른다.
클래스는 데이터와 메소드로 이루어져 있고 데이터는 기본적으로 숨겨져있다.
이 데이터는 메소드를 통해서만 조작할 수 있어야 한다.
상속성(Inheritance)
대표적으로 부모가 자식에게 유산을 상속하는 경우의 예
-
생물 분류법으로써의 개념
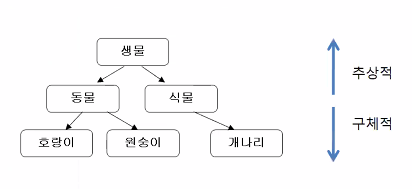
-
프로젝트 관점에서의 상속 개념
- A 프로젝트 (종료됨)
- B 프로젝트 (신규 과제)
- A 프로제그 기능이 B 프로젝트의 기능과 유사함.
- B 프로젝트는 A 프로젝트를 상속받고, 추가 기능만 구현하면 됨

다형성(Polymorphism)
- 함수의 이름이 같더라도 전달 인자 타입, 개수 등에 따라 구분
- C++에서는 오버로딩(overloading)과 오버라이딩(overriding)기법이 있음
오버로딩(overloading)
- 사전적 의미는 '과적하다, '적재하다'라는 의미를 가지고 있다.
- 겉모습이 똑같지만 내용이 다른 경우
- 이름이 같은 함수일지라도 전달인자 타입이나 개수가 다른 경우
- 스타크래프트의 오버로드 예
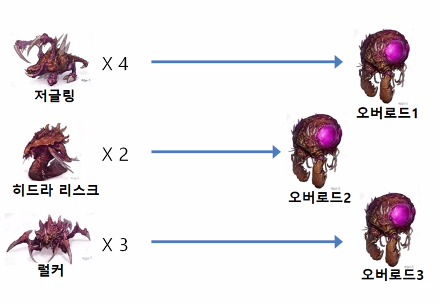
어떤 유닛이 탔느냐에 따라 각각 다른 오버로드로 인식
수평적으로 여러개가 겹쳐서 뜨는 현상.
int Add(int a)
int Add(char a, char b)오버라이딩(overriding)
- 오버라이딩은 '위로 올라탄다', '엎어친다'는 의미를 갖는다.
- 무언가에 올라타서 기존의 것을 덮어버린다는 개념
- 상속의 개념이 기반이 되어야 한다.
수직적이다.
기존의 기능을 덮어버린다.
C++프로그래밍의 기본 구조
#include <iostream>
void main()
{
std::cout << "Hello C++" << std::endl;
}출력결과
Hello C++
io : input output의 약자
stream : 흘러간다
'입력, 출력 값이 흘러가게 하는 라이브러리'
<< : cout이라는 객체의 방향으로 집어 넣는다.
cout : 모니터와 연관있는 객체
endl : endline, 개행
std : 이름 공간(name space)의 객체
:: : 스코프 연산자(영역 결정 연산자)
'std 안에 속해있는 cout'
'std안에 속해있는 endl'
#include <iostream>
void main()
{
int a = 10;
double b = 3.14;
char c = 'A';
std::cout << a << std::endl;
std::cout << b << std::endl;
std::cout << c << std::endl;
//std::cout << "Hello C++" << std::endl;
}출력 객체 cout
- 이름 공간(namespace)에 대하여
특정 공간에 이름을 지정해 준다는 의미
이름 공간 사용 유무에 따른 문제점과 해결점
같은 이름의 대상이 있다고 할 때는 호출의 대상이 명확하지 않음.
#include <iostream>
void func()
{
std::cout << "A학급 주성" << std::endl;
}
void func()
{
std::cout << "B학급 주성" << std::endl;
}
void main()
{
func();
}이런 코드를 실행시킨다고 했을 때, 이미 선언된 함수라는 오류가 난다.
오버로딩이 되려면 매개변수의 타입이나 개수가 달라야 함!
이런 상황을 namespace를 활용해 해결한다.
#include <iostream>
namespace A
{
void func()
{
std::cout << "A학급 주성" << std::endl;
}
}
namespace B
{
void func()
{
std::cout << "B학급 주성" << std::endl;
}
}
void main()
{
A::func();
B::func();
}출력결과
A학급 주성
B학급 주성
A영역에 속해있는 func()
B영역에 속해있는 func()라고 이해하면 된다.
결국 std::cout도 std라는 namespace 안에있는 cout을 사용하겠다는 의미이다.
using namespace std;
void main()
{
int a = 10;
cout << a << endl;
}using namespace를 사용하면 std 이름을 써주지 않아도 된다.
입력객체 cin
입력 객체, 입력 디바이스와 연결이 되어 있다.
cin >> a; // scanf'a에 입력을 받아서 a에 넘겨주겠다.'
C언어처럼 주소값을 입력해주지 않아도 알아서 찾아간다.
#include <iostream>
using namespace std;
void main()
{
int a = 0;
double b = 0;
cin >> a; // scanf
cout << "정수 출력 : " << a << endl;
cin >> b;
cout << "실수 출력 : " << b << endl;
}출력결과
100
정수 출력 : 100
3.14
실수 출력 : 3.14
변수의 선언 위치
C언어에서의 기존 규칙
- C언어에서는 코드의 시작 위치에서만 변수 선언이 가능
규칙 위반 시 컴파일 에러 발생
int a;
for(a = 0; a < 100; a++)
{
...
}C++언어에서의 새로운 규칙
- C++언어에서는 변수 사용 위치와 가까운 곳에 변수 선언이 가능
for(a = 0; a < 100; a++)
{
...
}참고: 변수 선언의 자유로움으로 인해 무분별하게 선언하면, 코드의 유지보수 시 관리가 제대로 안 될 수 있는 우려가 생긴다.
함수 전달의 기본값
C언어에서의 기존 규칙
- C언어에서는 함수 생성 시 필요한 요소가 함수의 선언부와 구현부이다.
C언어에서 함수를 호출 시 다음과 같이 선언부의 타입에 맞게 매개변수 값을 대입하여야 한다.
선언부
void func(int a, int b);호출부
func(10,20); // 매개변수 값은 각각 10과 20
C++언어에서의 새로운 규칙
- C++언어에서는 함수 선언부 매개변수에 기본값 설정이 가능
호출부에서 매개변수 값을 생략하면 기본값으로 적용
선언부
void func(int a = 10, int b = 20);호출부1
func(100,200);// 전달인자의 값은 각각 100과 200
호출부2
func(50);
func();// 첫 번째 전달인자 50, 두 번째 전달인자 생략 (50,20)
// 첫 번째, 두 번째 전달인자 모두 생략 (10,20)
예제
using namespace std;
void func(int a = 10, int b = 20);
void main()
{
func();
func(100);
func(100, 200);
}
void func(int a, int b)
{
cout << "두 전달인자 출력 : " << a << " " << b << endl;
}출력결과
두 전달인자 출력 : 10 20
두 전달인자 출력 : 100 20
두 전달인자 출력 : 100 200
영역 결정 연산자(스코프 연산자)
C언어에서의 기존 규칙
- C언어에서는 전역 변수와 지역 변수의 이름이 같을 시 지역 변수가 전역 변수보다 우선권을 가진다.
C++언어에서의 새로운 규칙
- C++언어에서는 전역 변수와 지역 변수 존재 시 지역 내에서 전역 변수를 출력할 수 없던 문제를 해결
⇛ 영역 결정 연산자(::)를 사용
#include <iostream>
using namespace std;
int nTemp = 10;
void main()
{
{
int nTemp = 20;
cout << "nTemp = " << nTemp << endl;
cout << "::nTempt = " << ::nTemp << endl;
}
cout << "nTemp = " << nTemp << endl;
}출력결과
nTemp = 20
::nTempt = 10
nTemp = 10
:: 앞에 아무것도 없으면 소속이 없는 '전역'을 의미한다.
인라인 함수(Inline Function)
-
인라인 함수란
코드 라인 자체가 호출부 안에 포함된다는 의미
#define 매크로의 단점을 보완하고, 일반 함수 호출의 부하를 덜어줌
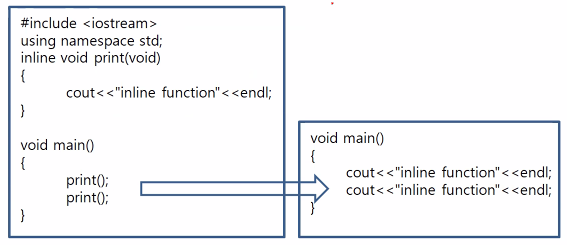
-
인라인 함수의 장점
- 인라인 함수의전달인자에 데이터형을 체크할 수 있다.
- 매크로가 갖는 부작용 없이 일반 함수처럼 사용이 가능하다.
- 디버깅이 가능하다. 즉, 현재 들어가 있는 변수의 값을 체크할 수 있다.
-
인라인 함수의 단점
- 실행 코드가 커진다.
- 인라인 함수는 구현을 짧게 작성해야 한다.
- 인라인 함수를 너무 남발하게 되면 코드 자체가 커진다.
#define을 사용하면 전처리, 즉 컴파일 전에 실행할 수 있다.
함수 오버로딩(Overloaded Function)
함수 오버로딩이란
-
개념: 스타크래프트의 오버로드처럼 똑같은 여러 개의 오버로드가 존재하지만 그 안에 탑승한 유닛들은 각각 다르다.
-
함수의 오버로딩이란 똑같은 이름의 함수들이 존재하지만 매개변수 타입이나 개수 차이에 의해서 서로 다른 함수로 구분된다.
-
C언어에서는 불가능하다.
⇛ 전달인자의 이름으로 보지않고 함수의 이름을 기준으로 보기 때문에 같은 함수이름이면 오류가 난다.
C언어에서의 규칙
- C언어에서 두 수를 입력 받아 더한 후 반환하는 기능을 가진 함수 작성
- 정수형 반환타입 함수 이름: Addl()
- 실수형 반환 타입 함수 이름: AddD()
- 문자형 반환 타입 함수 이름: AddC()
두 수를 더하는 기능으로서는 똑같은데 이름만 다른 모습은 바람직하지 않다.
C++언어에서의 새로운 규칙
- 각 반환 타입에 상관없이 Add()함수 이름으로 통일
#include <iostream>
using namespace std;
int Add(int a, int b);
double Add(double a, double b);
char Add(char a, char b);
void main()
{
int i;
double d;
char c, ch = 1;
i = Add(10, 20);
d = Add(3.14, 1.59);
c = Add('A', ch);
cout << "정수값 출력 : " << i << endl;
cout << "정수값 출력 : " << d << endl;
cout << "정수값 출력 : " << c << endl;
}
int Add(int a, int b)
{
return a + b;
}
double Add(double a, double b)
{
return a + b;
}
char Add(char a, char b)
{
return a + b;
}출력결과
정수값 출력 : 30
정수값 출력 : 4.73
정수값 출력 : B
전달인자는 반드시 달라야한다.
클래스
'클래스의 본질은 데이터 타입이다.'
구조체와 클래스의 큰 차이점은 구조체는 변수로 이루어져있지만, 클래스는 (멤버)변수와 (멤버)함수가 혼재되어있다는 점이다.
클래스란
- 사전적으로는 '학급'이라는 의미를 갖는다.
- 사용자가 정의한 추상적인 데이터형(Abstract Data Type)
클래스의 구성
- C언어의 구조체와 비슷한 형태이다.
- 멤버 변수와 멤버 함수로 구성된다.

구조체도 함수를 가질 수는 있지만 보안의 개념이 없어서 구조체 멤버에 바로 접근하면 된다. 함수가 필요가 없어서 쓰지 않는 것이다.
클래스는 멤버 변수에 접근하기 위한 메소드라고도 부르는 멤버함수가 있어야 한다. 객체지향에서는 기본적으로 보안때문에 데이터를 은닉하기 때문이다.
클래스의 정의 방법
- 구조체가 struct라는 예약어를 사용하였다면 클래스를 정의하기 위해 가용하는 예약어는 class이다.
- 정의 시 예약어 class 뒤에 클래스 이름을 지정한다.

접근 지정자 사용
-
클래스의 멤버 선언 시 접근 권한을 설정한다.
-
접근 권한에는 private, protected, public 3가지가 있다.
-
protected는 상속 개념 이후에 배우도록 하겠다.

현재 클래스: 나 -
private: 클래스 내에서만 접근 가능하고, 외부에서 절대 접근할 수 없는 권한이다. 캡슐화와 데이터 은닉 철학에 부합한다.
-
public: 클래스 내에서 뿐만 아니라 외부에서도 접근이 가능한 권한이다. 데이터의 은닉이 되지 않는다.
