Python #11
파일 입출력
파일 입출력의 흐름
- 파일 열기
상자를 열 듯 파일을 열어야 한다. open() 함수 사용
파일 객체 = open(파일명, 파일 열기 모드)
첫 번째 전달인자는 오픈할 파일명을 입력
두 번째 전달인자는 파일 열기 모드를 입력
| 파일 열기 모드 | 설명 |
|---|---|
| r | 파일을 읽기만 할 때 사용합니다. |
| w | 파일에 내용을 쓸 때 사용합니다. 기존에 파일이 있으면 덮어 씁니다. |
| a | 파일에 내용을 쓸 때 사용합니다. 기존에 파일이 있으면 이어서 씁니다. |
| b | 바이너리(이진) 파일을 처리합니다. |
| t | 텍스트 파일을 처리합니다. |
-
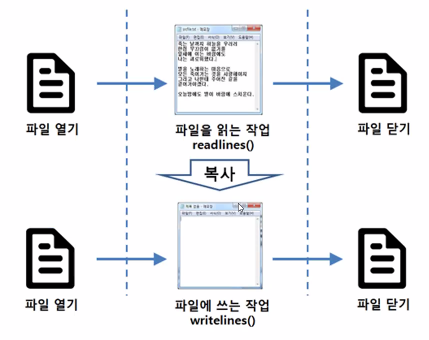
파일에 읽고 쓰기
상자에 물건을 넣고 빼듯이 파일에 데이터를 읽고 쓸 수 있다.
읽은 문자열 = 파일 객체.read()
파일 객체.write(저장할 문자열) -
파일 닫기
상자에 물건을 넣고 뺐으면 상자를 닫아야 하듯이 파일 또한 사용이 끝났으면 파일을 정상적으로 닫아야 한다.
파일객체.close()
fName = 'poem.txt'
fp = open(fName, 'r')
strRead = fp.read()
print(strRead)
fp.close()텍스트 파일 입출력
텍스트 파일에 데이터 저장하기
- 파일을 사용하는 목적은 무엇일까?
- 데이터를 한 번 사용하고 버리는 것이 아니라 저장해서 필요할 때 다시 꺼내 쓰기 위함.
- 간단한 데이터 입력은 문제 없지만 1-2페이지 분량이면 매번 입력은 비효율적.
- file.txt 이름으로 파일 저장
텍스트 파일에서 한 라인씩 읽기
한 라인 문자열 = 파일 객체.readline()
fName = 'poem.txt'
fp = open(fName, 'r')
# strRead = fp.read() # 내용 전체
while True:
strRead = fp.readline()
if strRead == '' :
break
print(strRead)
fp.close() 출력결과
서로 사랑하라
허나 사랑에 속박되지는 말라
함께 노래하고 춤추며 즐거워하되
그대들 각자는 고독하게 하라
텍스트 파일에서 통째로 읽기
전체 문자열 리스트 = 파일 객체.readlines()
##############
# 2022.09.27 #
##############
fName = 'poem.txt'
fp = open(fName, 'r')
# 텍스트 전체 읽을 때, 전체 문자열 리스트로 리턴
listRead = fp.readlines()
#print(listRead)
for strlist in listRead :
print(strlist)
fp.close()지정한 경로의 파일이 존재하는지 체크하기
-
만약 파일을 open() 함수로 열 때 해당 파일이 존재하지 않는다면?

-
파일이 존재하지 않는 경우 처리하기 위해 파일 체크 함수를 제공
반환값 = os.path.exists(파일명) -
파일이 존재하는 경우 True, 존재하지 않으면 False
왜 os라는 컴포넌트에서 경로를 관리할까?
파일시스템을 관리하는 시스템은 os이기 때문이다.
import os
fName = input('파일명을 입력하세요 : ')
print()
if os.path.exists(fName):
fp = open(fName, 'r')
listRead = fp.readlines()
for strlist in listRead :
print(strlist)
fp.close()
else:
print('%s 파일은 존재 하지 않습니다.' % fName)출력결과
파일명을 입력하세요 : (poem.txt)
서로 사랑하라
허나 사랑에 속박되지는 말라
함께 노래하고 춤추며 즐거워하되
그대들 각자는 고독하게 하라
with문 사용하기
- 파일의 open() close() 구조가 불편하다.
- 파일을 열었는데, 실수로 파일을 닫지 않을 수도 있다.
- with를 사용하면 close() 함수로 파일을 닫지 않고 자동으로 닫아주게 된다.
with open(파일명, 파일 열기 모드) as 파일객체
import os
fName = input('파일명을 입력하세요 : ')
print()
if os.path.exists(fName):
with open(fName, 'r') as fp:
listRead = fp.readlines()
for strlist in listRead :
print(strlist)
else:
print('%s 파일은 존재 하지 않습니다.' % fName)텍스트 파일에 데이터 쓰기
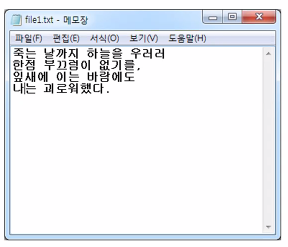
- 메모장 파일인 file1.txt에 코드를 사용하여 데이터를 쓰도록 하겠다.
파일객체.write(입력 문자열)
파일객체.writelines(리스트 문자열)
fName = input('파일명을 입력하세요 : ')
print()
with open(fName, 'w') as fp:
instr = input('데이터 입력 : ')
fp.writelines(instr + '\n')출력결과
파일명을 입력하세요 : (test.txt)
데이터 입력 : 죽는날까지 하늘을 우러러
fName = input('파일명을 입력하세요 : ')
print()
with open(fName, 'w') as fp:
while True:
instr = input('데이터 입력 : ')
fp.writelines(instr + '\n')출력결과
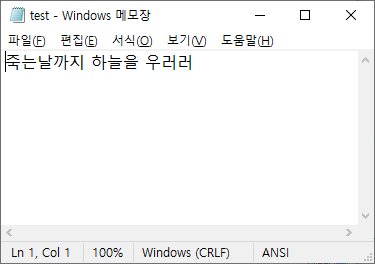
파일명을 입력하세요 : (test.txt)
데이터 입력 : 죽는날까지 하늘을 우러러
데이터 입력 : 한 점 부끄럼 없기를
데이터 입력 : 잎새에 이는 바람에도
데이터 입력 : 나는 괴로워했다
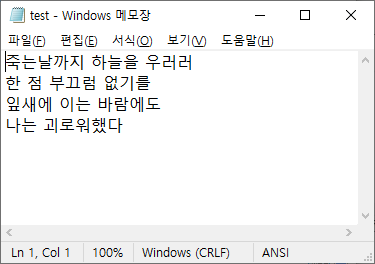
이미 있는 파일에 덮어쓰기가 됐다.
fName = input('파일명을 입력하세요 : ')
print()
with open(fName, 'w') as fp:
while True:
instr = input('데이터 입력 : ')
if instr == '\q':
break
fp.writelines(instr + '\n')출력결과
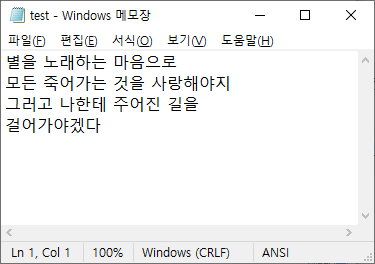
파일명을 입력하세요 : (test.txt)
데이터 입력 : 별을 노래하는 마음으로
데이터 입력 : 모든 죽어가는 것을 사랑해야지
데이터 입력 : 그러고 나한테 주어진 길을
데이터 입력 : 걸어가야겠다
데이터 입력 : \q
파일 vs 파일 복사하기
- 파일로부터 데이터를 읽고 쓸 수 있다면 파일 복사가 가능하다.
- 원본 파일과 복사 대상 파일 2개를 생성한다.
import os
srcfile = input('원본 파일명을 입력하세요 : ')
destfile = input('대상 파일명을 입력하세요 : ')
print()
if os.path.exists(srcfile):
sfp = open(srcfile, 'r')
dfp = open(destfile, 'w')
slist = sfp.readlines() # 리스트를 리턴
for str in slist :
dfp.writelines(str)
sfp.close()
dfp.close()
print('복사 완료 하였습니다.')
else:
print('원본 파일이 존재하지 않습니다.')출력결과
원본 파일명을 입력하세요 : (poem.txt)
대상 파일명을 입력하세요 : (poem2.txt)
복사 완료 하였습니다.

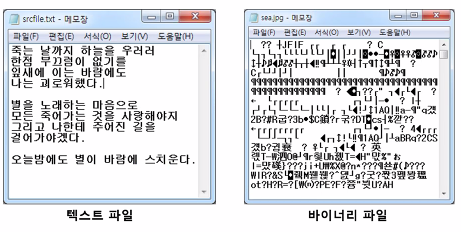
바이너리 파일 입출력
바이너라 파일이란
-
바이너리는 이진수로 0과 1로만 구성된 데이터이다.
-
텍스트 데이터는 사람이 읽을 수 있는 글자로 되어있어 이를 텍스트 파일이라고 한다.
-
데이터 저장과 처리 목적으로 0과 1의 이진 형식으로 구성된 파일을 바이너리 파일이라고 한다.
-
실행파일, 이미지 파일, 음악 파일 등이 대표적인 바이너리이다.
-
바이너리 파일은 별도의 소프트웨어를 통해 열어서 사용할 수 있다.
-
메모장에 바이너리 형태로 연 sea.jpg 파일도 이미지 뷰어 상에서 이미지 파일이다.
바이너리 파일을 읽기 위해서는 별도의 소프트웨어가 필요하다.
바이너리 파일 복사하기
- 바이너리 파일은 어떤 것이든 복사 가능하다.
- 이미지 sea.jpg 파일을 복사해보자.
- 대상 파일을 열고 옵션을 'rb'와 'wb'로 설정한다.
- 바이트 단위 처리 함수인 read(), write() 함수를 사용한다.
import os
srcfile = 'sea.jpg'
destfile = input('대상 파일명을 입력하세요 : ')
print()
if os.path.exists(srcfile):
sfp = open(srcfile, 'rb')
dfp = open(destfile, 'wb')
while True :
sbyte = sfp.read()
if not sbyte :
break
dfp.write(sbyte)
sfp.close()
dfp.close()
print('복사 완료 하였습니다.')
else:
print('원본 파일이 존재하지 않습니다.')대상 파일명을 입력하세요 : (dest.jpg)
복사 완료 하였습니다.

바이너리 파일에서 데이터 얻어오기
- MP3 파일을 열어서 데이터를 얻어오는 코드를 작성해보자.
- MP3 파일은 128바이트에 곡의 제목, 가수, 이름, 음반 출시 년도와 같은 데이터를 담고 있다.
- 파일에 담고 있는 데이터를 메타데이터라고 한다.
- ID3v1 포멧을 간단하게 살펴보자.
| 오프셋 | 길이 | 설명 |
|---|---|---|
| 0 | 3 | "Tag" 인식 문자열 |
| 3 | 30 | 음악 제목 문자열 |
| 33 | 30 | 가수(음악가) 문자열 |
| 63 | 30 | 음반 문자열 |
| 93 | 4 | 음반 출시년도 문자열 |
| 97 | 30 | 비고 문자열 |
| 127 | 1 | 장르 바이트 |
-
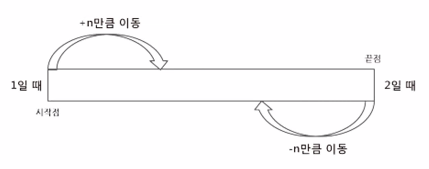
파일의 원하는 바이트 위치로 이동하는 함수 seek()
파일객체.seek(n)
파일객체.seek(n, 1)
파일객체.seek(n, 2) -
seek 함수에 전달인자 n만 사용되면 파일의 n번째 바이트로 이동
-
전달인자가 1인 경우 현재 위치에서 n바이트만큼 이동
-
전달인자가 2인 경우 맨 마지막 위치에서 n바이트만큼 이동
-
read()함수는 전달인자가 없는 경우에 전체 파일을 읽어들이게 된다.
파일객체.read(size) -
read() 함수에 전달인자로 읽기 원하는 바이트 수를 입력하면 파일에서 지정한 바이트 수만큼만 데이터를 읽어온다.
-
바이트 데이터를 그대로 출력하면 16진수 데이터가 나타난다.
-
바이트 데이터를 문자열 데이터로 변환해주는 과정을 디코딩(decoding)
-
문자열 데이터를 바이트 데이터로 변환해주는 과정을 인코딩(encoding)
바이트 = 문자열.encode()
문자열 = 바이트.decode()
import os
srcfile = "Sleep Away.mp3"
if os.path.exists(srcfile):
sfp = open(srcfile, 'rb')
# 음원 데이터를 읽어오기
sfp.seek(-128,2)
tdata = sfp.read(128)
title = tdata[3:33].decode() # 바이트 데이터를 디코딩해서 문자열로 바꾸기
print('제목 : ' + title)
artist = tdata[33:63].decode()
print('음악가 : ' + artist)
mdate = tdata[93:97].decode()
print('출시년도 : ' + artist)
etc = tdata[97:127].decode()
print('기타 정보 : ' + etc)
sfp.close()
print('음악 파일 정보를 정상적으로 출력하였습니다.')
else:
print(srcfile + '파일은 존재하지 않습니다.')출력결과
제목 : Sleep Away
음악가 : Bob Acri
출시년도 : Bob Acri
기타 정보 : Blujazz Productions
음악 파일 정보를 정상적으로 출력하였습니다.
데이터베이스
데이터베이스란 무엇인가
-
웹이나 앱을 통해 대량의 데이터가 매우 다양하게 수집, 활용, 공유되고 있다. 이러한 막대한 데이터를 빅데이터라고 부른다.
-
빅데이터를 이용한 분석결과를 인공지능에 활용하기도 한다.
-
기존 프로그램들은 데이터를 상요하지만 저장하지는 않았다.
파일 입출력을 통해서 간단한 데이터를 관리할 수 있었다. 파일은 사용이 간단하지만 보안에 취약하고 구조화되어있지 않아 관리에 한계가 있다. -
이러한 파일의 단점을 극복하기 위한 소프트웨어가 데이터베이스이다.
데이터베이스는 구조화 된 형태로 안전하고, 빠르게 보관하고 사용할 수 있다.

- 우리가 검색하는 온라인 쇼핑, 결제, 신용카드 내역, 대중교통카드 내역, 사원증, 편의점이나 마트의 구매내역 등 모두 데이터베이스로 저장되고 활용된다.
- 이러한 막대한 정보를 체계적으로 관리하기 위해 고안된 것이 바로 데이터베이스 관리 시스템(DBMS)이다.
데이터베이스 관리 시스템(DBMS)
-
데이터베이스를 사용하려면 데이터베이스 소프트웨어를 설치해야 한다.
-
데이터베이스 소프트웨어를 데이터베이스 관리 시스템(Database Management System: DBMS)라고 한다.
-
DBMS에는 대표적으로 오라클, SQL Server, MYSQL, MS-Acess, SQLite 등이 있다.
-
관계형 데이터베이스는 데이터의 X와 Y의 상관관계를 갖는 2차원 구조를 말한다.
-
데이터 구조는 2차원 배열과 같은 표(Table)의 형태가 기본이다.
데이터베이스 관리 시스템(DBMS)의 사용구조
-
데이터베이스는 파일처럼 데이터를 무조건 저장하는 것이 아니라 체계적으로 사용하기 위한 데이터베이스를 설계해야 한다.
-
데이터베이스를 설계하는 과정을 데이터베이스 모델링이라고 한다.
-
예를 들어 서점의 경우 도서 목록을 관리하는 데이터베이스가 있다.
도서에 대한 이름, 저자명, 출판사, 재고 등의 대표적인 정보들을 DBMS에 저장해야 한다.
이러한 정보들은 구조화된 형태로 저장해야 하는데, 기본적으로 테이블(Table)이라는 요소에 표 형식의 틀을 맞추어 저장하고 읽을 수 있다. -
테이블(Table)의 구성
데이터가 표 형태로 표현된 것을 말한다.
Ex) 도서 목록 테이블
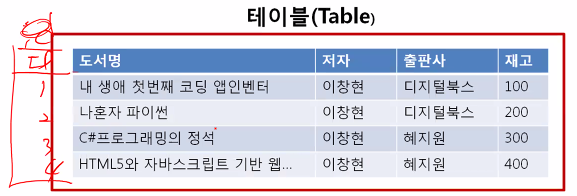
테이블은 데이터로 구성되어있고, '나혼자 파이썬', '이창현', '디지털북스', '200'과 같은 하나하나의 데이터를 말한다.
데이터베이스에서는 테이블에서 데이터를 읽는 방향에 따라 필드(field) 또는 열(column)과 레코드(record) 또는 행(row)라는 용어를 사용한다.
도서 목록 테이블의경우는 도서명, 저자, 출판사, 재고 등의 4개의 열로 구성되어 있다. 이러한 해당 열을 필드(field)라고도 한다.
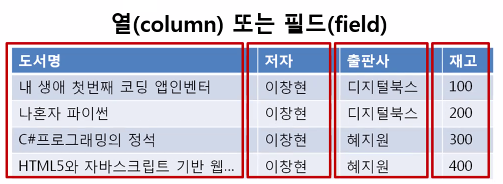
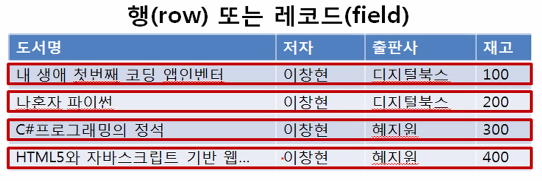
-
데이터베이스(Database)의 구성
하나의 폴더에 여러 개의 파일이 존재하듯이 데이터베이스는 여러 개의 테이블로 구성되어있다.
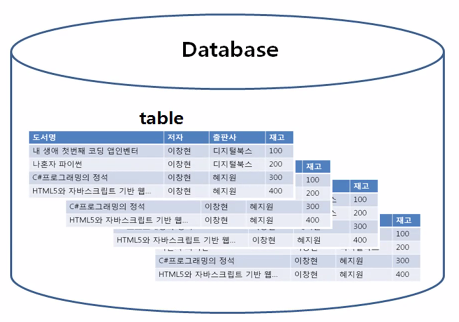
여러개의 데이터베이스가 모인 것을 하나의 스키마 라고 한다.
-
DBMS의 구성
여러 개의 데이터베이스가 모인 것을 DBMS라고 한다.
데이터베이스의 이름은 중복될 수 없다. A 데이터베이스, B 데이터베이스, C 데이터베이스 등으로 구분되어야 한다.

SQL(Structed Query Language)란 무엇인가
-
데이터베이스에 데이터를 입력하고 출력할 수 있어야 한다.
데이터베이스를 조작할 수 있는 공통적인 데이터베이스 전용 언어가 바로 SQL(Structed Query Language)이다. -
'구조화된 질의 언어'의 의미이며, DBMS와 소통하기 위한 언어라고 할 수 있다.
-
기본적인 기능은 생성(Create), 수정(Update), 삭제(Delete), 읽기(Read)가 있다. 이를 CRUD라고 부르기도 한다.
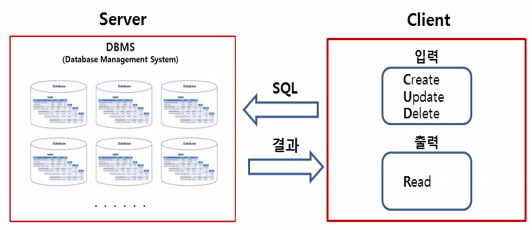
-
데이터베이스 사용은 CRUD가 전부라고 해도 과언이 아닐만큼 중요하다.
| 기능 | 설명 | SQL 명령문 |
|---|---|---|
| Create | 데이터를 생성합니다. | INSERT |
| Read | 데이터를 읽어옵니다. | SELECT |
| Update | 데이터를 갱신합니다. | UPDATE |
| Delete | 데이터를 삭제합니다. | DELETE |
sqlite> .open bookStore
sqlite> create table bookItem(id int, item char(100), author char(50), publisher char(50), stock int);
sqlite>
sqlite>
sqlite> .table
bookItem
sqlite> .schema bookItem
CREATE TABLE bookItem(id int, item char(100), author char(50), publisher char(50), stock int);
sqlite>
sqlite> insert into bookItem values(1, 'python', 'lch', 'digitalbooks', 100);
sqlite> insert into bookItem values(2, 'javascript', 'kim', 'digitalbooks', 200);
sqlite> insert into bookItem values(3, 'c#', 'lch', 'hyejiwon', 300);
sqlite> insert into bookItem values(4, 'C++', 'lch', 'hyejiwon', 400);
sqlite>
sqlite>
sqlite> select * from bookItem;
1|python|lch|digitalbooks|100
2|javascript|kim|digitalbooks|200
3|c#|lch|hyejiwon|300
4|C++|lch|hyejiwon|400
sqlite>
sqlite>
sqlite> .header on
sqlite> .mode column
sqlite> select * from bookItem;
id item author publisher stock
-- ---------- ------ ------------ -----
1 python lch digitalbooks 100
2 javascript kim digitalbooks 200
3 c# lch hyejiwon 300
4 C++ lch hyejiwon 400
sqlite> select item from bookItem;
item
----------
python
javascript
c#
C++
sqlite> select author from bookitem;
author
------
lch
kim
lch
lch
sqlite> select item, author from bookitem;
item author
---------- ------
python lch
javascript kim
c# lch
C++ lch