22일차 / Login, JWT토큰, useRecoilState
graphql의 기본값은 cache-first
캐시에 먼저 갔는데 데이터가 부족할 때 백엔드로 요청이 다시 들어가서 가져오게 됨
우리가 오해할 수 있는 부분이 있을 수 있는데,
글로벌 스테이트를 recoil로 사용을 하는데, recoil로 redux를 대신할 수는 없다.
recoil을 그렇게 사용하기엔 부족한 점이 있고, redux로 만든다고 하면 react query, apollo client로 직접 만들었다.
부족한 부분이 api부분. 추가적으로 같이 쓰자 하는게 recoil.
Login
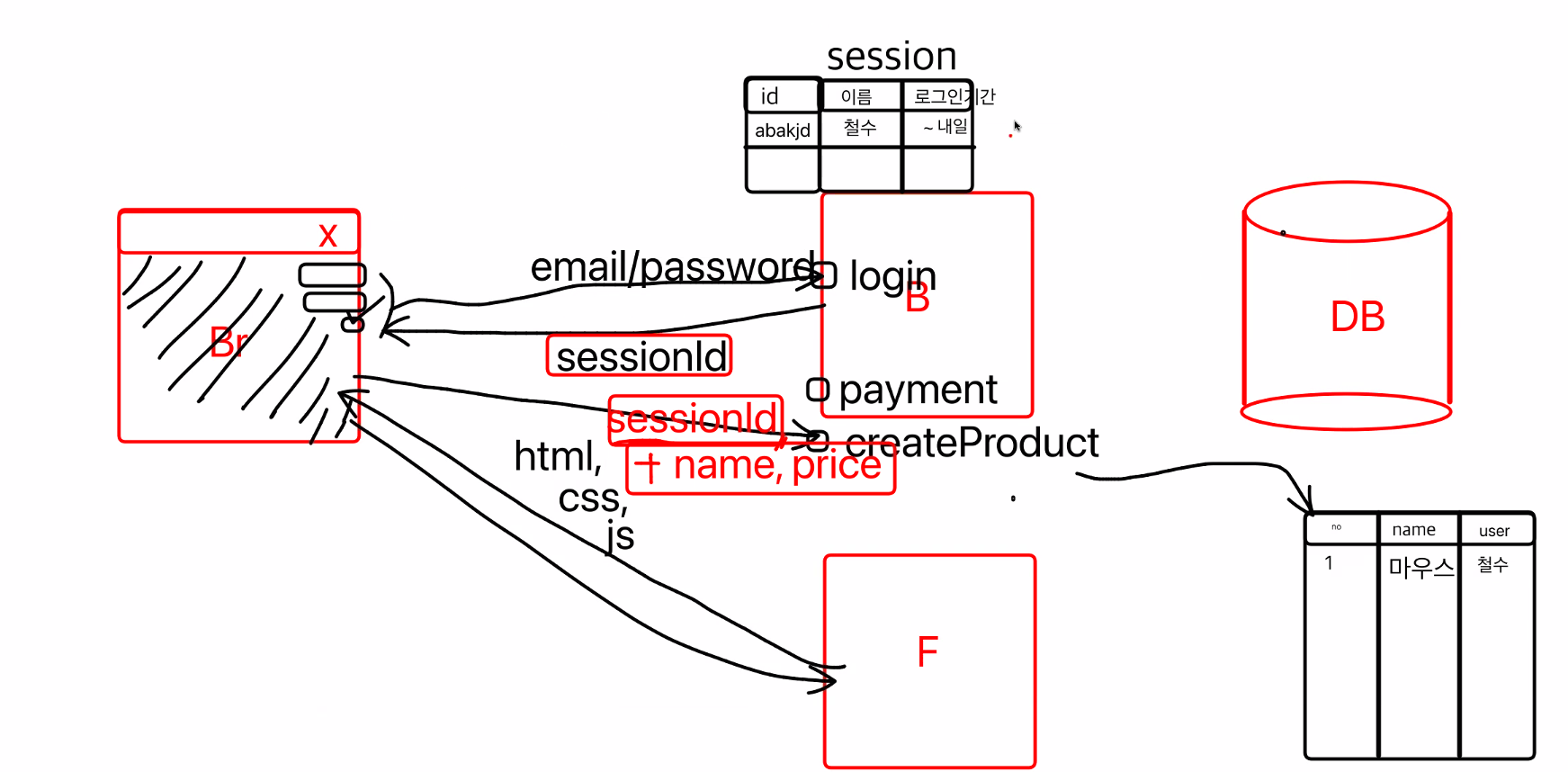
브라우저에 주소를 치고 엔터를 치면 프론트엔드에서 html,css,js를 다운받아서 온다.
브라우저에 그림이 그려지게 되고, 브라우저 안에서 로그인을 클릭하게 되면 백엔드로 api가 날아가게 된다.
로그인을 요청한 사람이 철수라고 하면, 철수임을 어떻게 구분할까?
이 때 이메일과 비밀번호를 받아서 백엔드 메모리에 저장을 한다. 이것을 메모리 session이라고 한다.
메모리, 아주 쉽게 말하면 변수.
컴퓨터에는 메모리와 디스크가 있는데 차이라고 하면 디스크는 저장하게 되면 날아가지 않는 것 (ex text파일), 메모리(Ram)에 저장하는 것들은 사라지게 되는 것 (껐다 키면 날아간다)
옛날에는 백엔드에 메모리 세션(변수)을 둬서 이름, 로그인기간이 저장이 되어있었다.
이것들을 구분하기 위한 id를 저장해 놓는데 이걸 세션 아이디라고 불렀다.
세션 아이디를 브라우저에 던져주면 브라우저에서 세션아이디를 가지고 있다가 다음에 결제를 한다.
payment라는 api 혹은 createProduct api가 있다고 가정, 로그인 한 사람만이 결제와 상품등록을 할 수 있기 때문에 브라우저에서 세션 아이디를 함께 넘겨준다.(세션아이디에 상품 이름, 상품 가격 등을 함께 보내준다.)
백엔드에서는 상품등록 요청이 오면 세션 아이디를 찾아서 검증하고 등록할 수 있게 해준다.
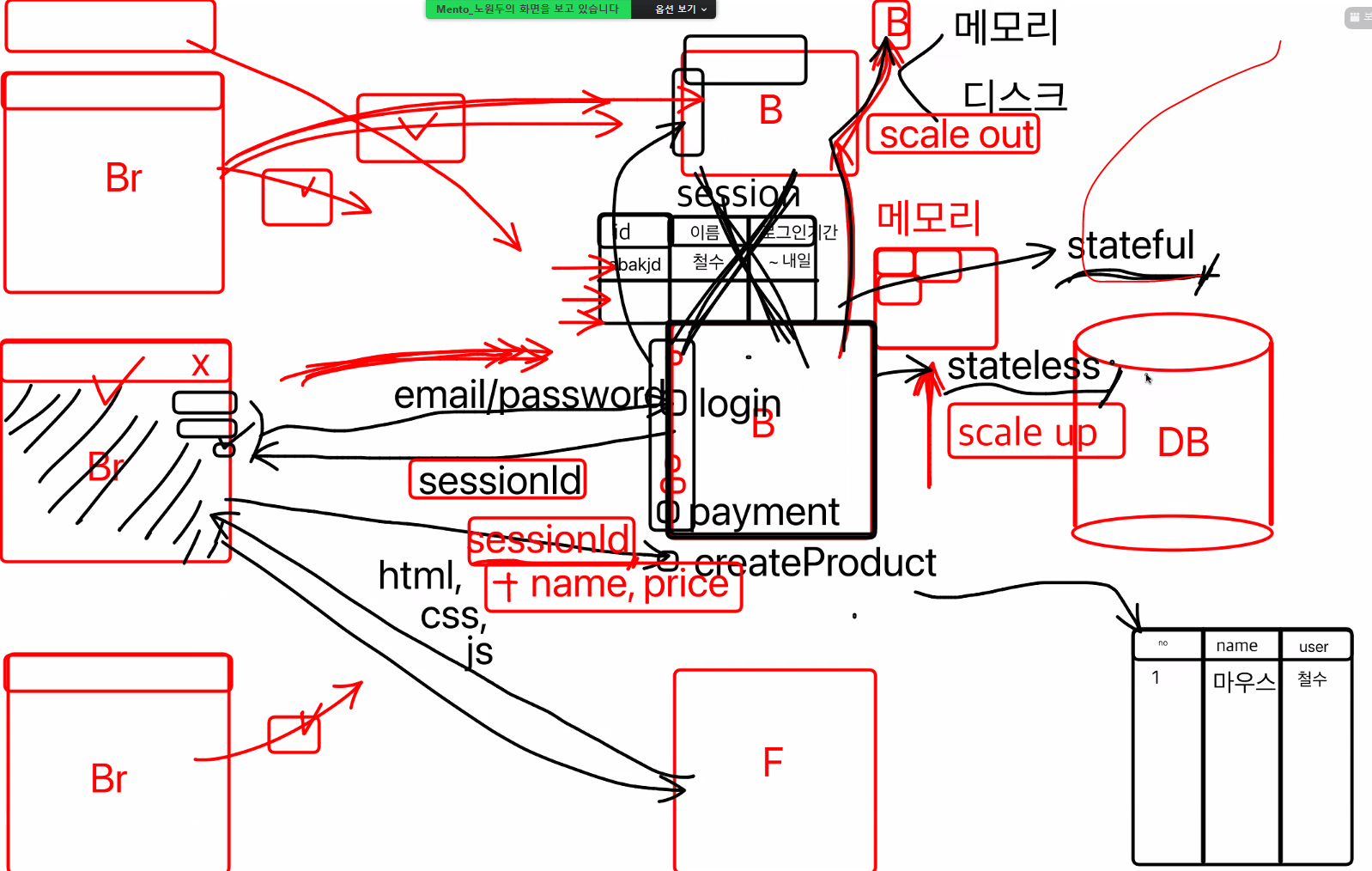
문제점이 있다면,
이후의 다른 브라우저에서도 로그인 요청을 하게 되면 세션에 로그인 데이터가 많이 쌓이게 된다.
사용자들이 api를 많이 요청하면 하나하나씩 순서대로 처리를 해야하는데 하나하나 처리하는 내용들을 어느 공간에 저장을 해놓아야한다.
임시저장공간(Ram)에 저장을 하게 되는데, 이것을 처리하기위한 메모리도 많이 필요하게 된다.
이 메모리를 늘리는 것을 scale up이라고 함.
컴퓨터를 한 대 더 구입하고 소스코드를 복사해서 백엔드 서버를 하나 더 열게 되면 (같은 api이기 때문에) 요청을 분산하게 되면서 문제가 해결이 된다.
이것을 scale out이라고 한다. (수평 확장, 트래픽 부하 분산)
scale out 했을 때 다른 컴퓨터에 로그인 세션이 있어서 다른 컴퓨터로 api를 요청했을 때 로그인을 안 한 상태로 인식할 수 있는 상황이 발생하는데,
세션을 포함하고 있는 상태을 stateful이라고 하고 세션을 포함하지 않는 상태를 stateless이라고 한다.
stateless일 때 어떻게 로그인을 하게 할까?
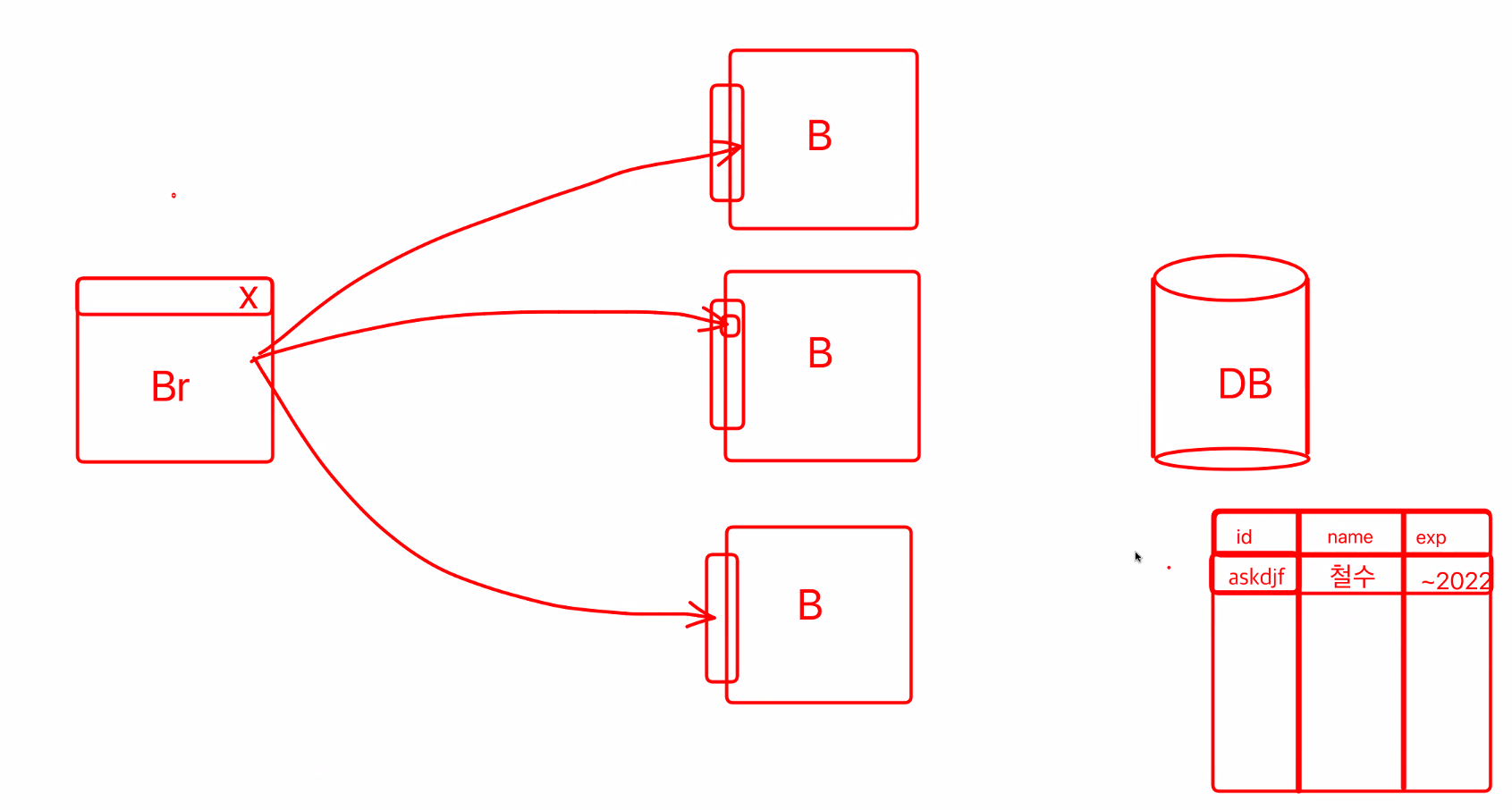
로그인 정보를 어디에 저장할까? DB에 저장을 해보자.
로그인 세션이 DB로 옮겨갔을 뿐이지 크게 바뀐점은 없다.
DB로 부하가 몰릴 뿐 완벽한 해결책으로 보기엔 어렵다.
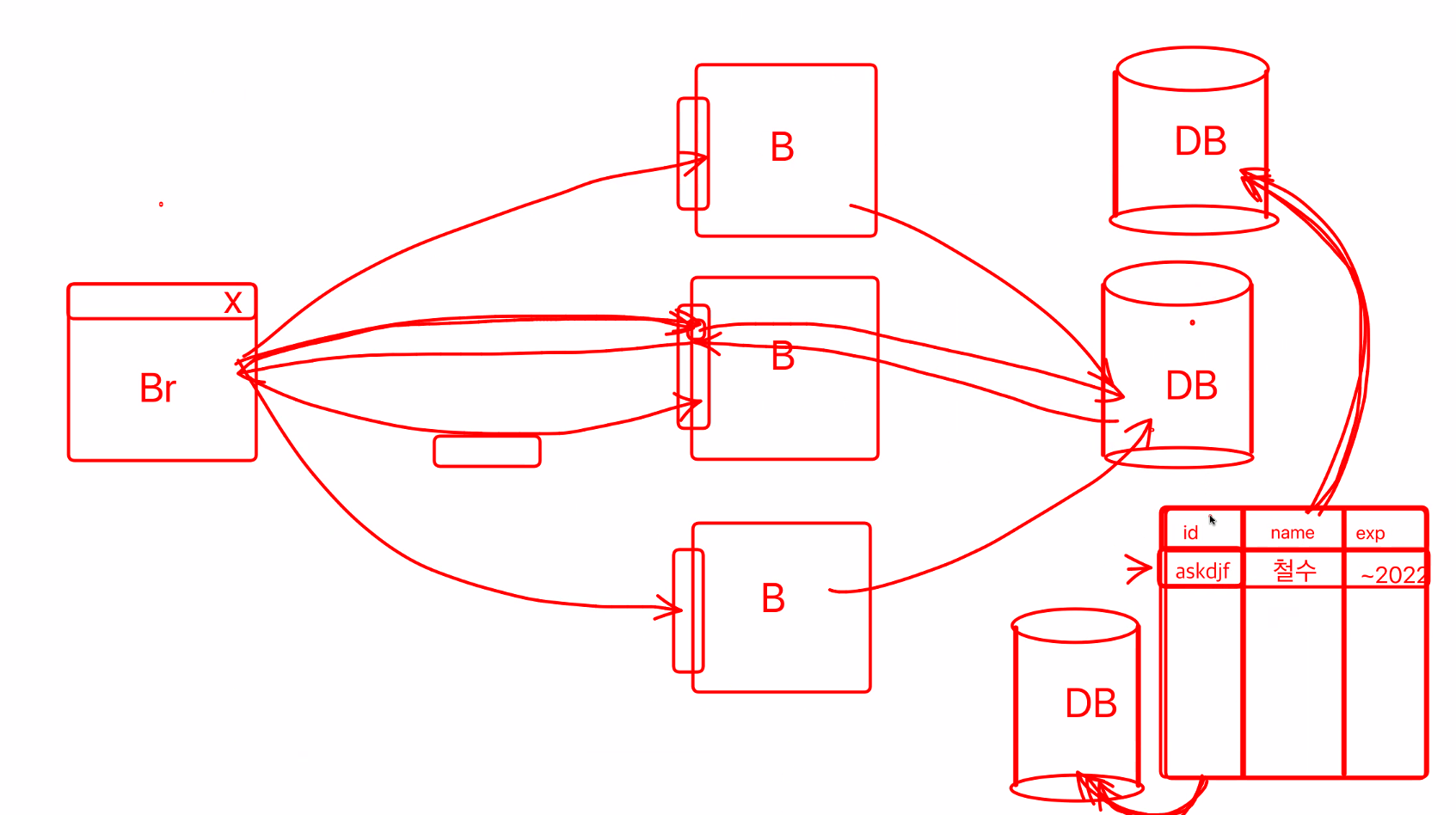
그러면 DB를 똑같이 늘리면 되지 않을까? DB를 똑같이 늘려보자.
그러면 DB의 데이터를 똑같이 가져가야하는거니까 수많은 데이터 등을 똑같이 옮겨야하므로 비효율적이다.
그러면 어떻게 DB를 효과적으로 나눌까?
DB의 테이블을 나누어 담자!
이 테이블을 한번 나눠보자!
나누는 방식은 크게 두개가 있다.
1. 수직으로 나누자 (수직 파티셔닝)

2. 수평으로 나누자 (수평 파티셔닝)
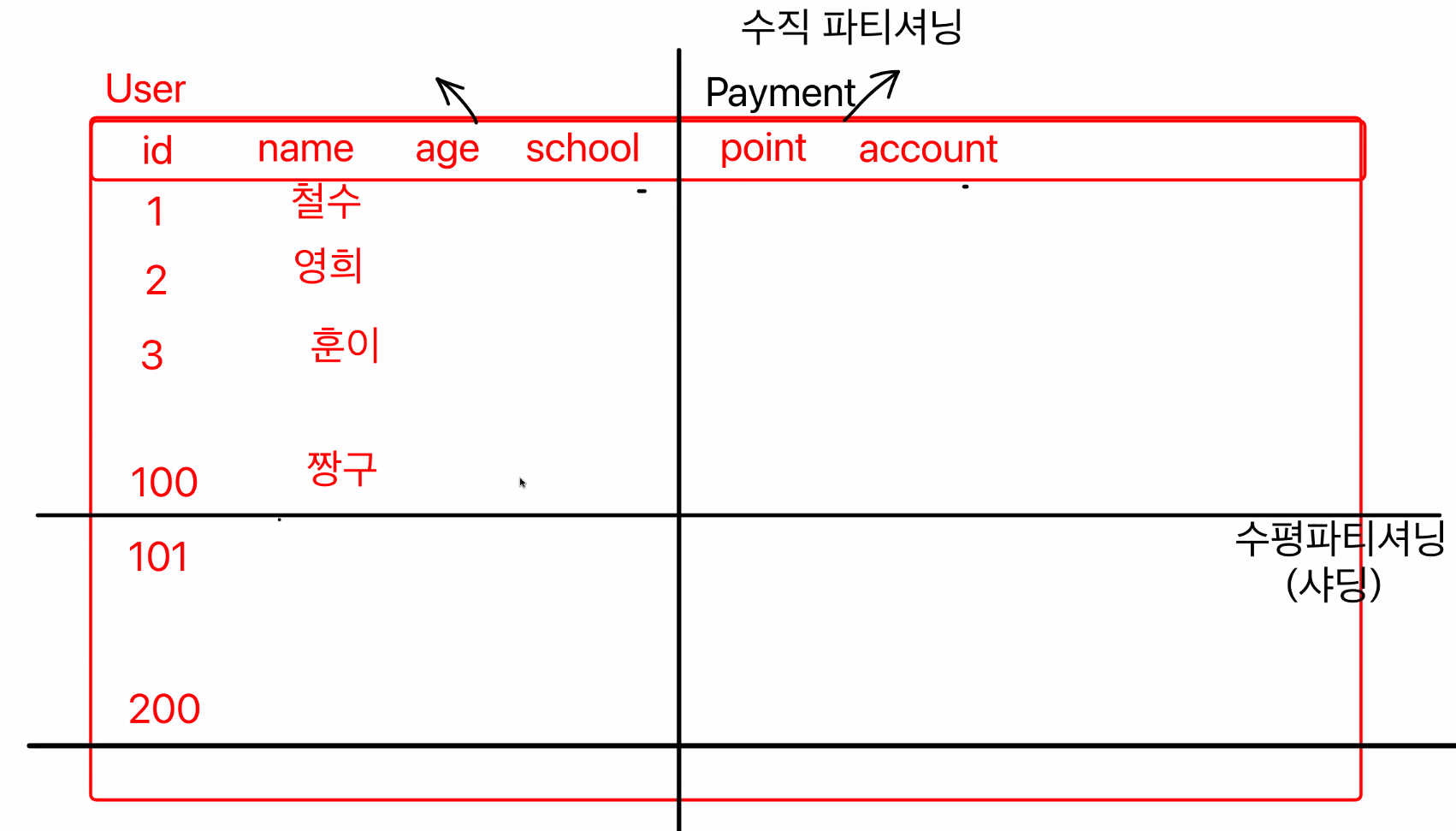
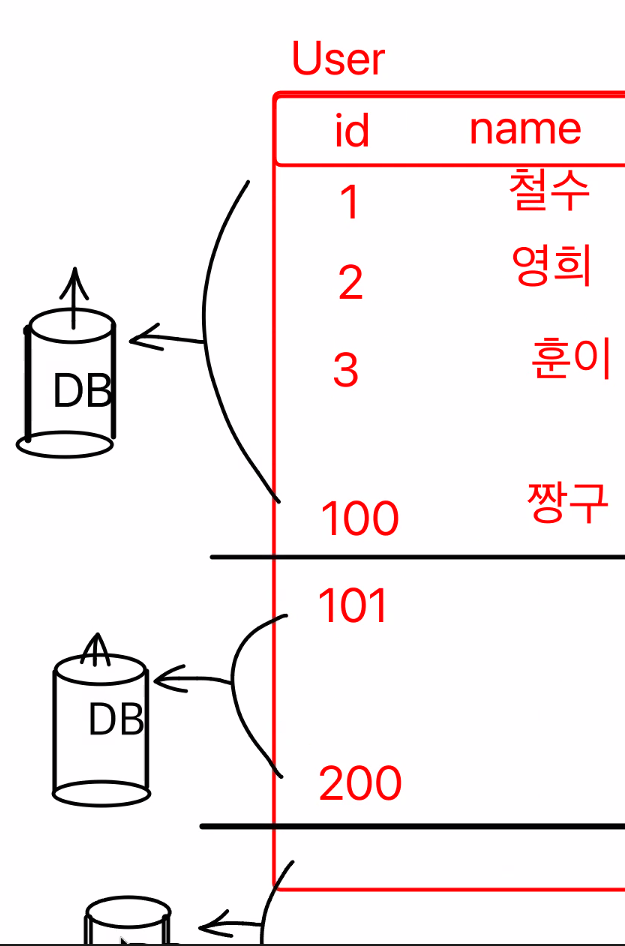
=데이터베이스 샤딩
이렇게 하면 데이터베이스까지 부하를 분산할 수 있다.
샤딩 방식을 통해서 부하를 분산할 수 있었다.
api하나하나 요청할 때마다 데이터베이스에 가서 누가 로그인 되어있는지 찾아와야한다.
인증이 필요한 api를 사용할 때 DB를 왔다갔다 헤야한다.
너무 당연한 얘기겠지만 발생하는 문제는, DB의 데이터는 디스크에 저장이 되어있는 것이다.
저장이 느리고, 찾아오는 것도 느리다.
다른 말로 DB를 긁는다 라고 한다.
부하를 분산한 것까지는 좋지만 DB를 긁어야하기 때문에 성능에 문제가 있을 수 있다.
디스크 말고 메모리에 저장할 수 있는 방법은 없나?
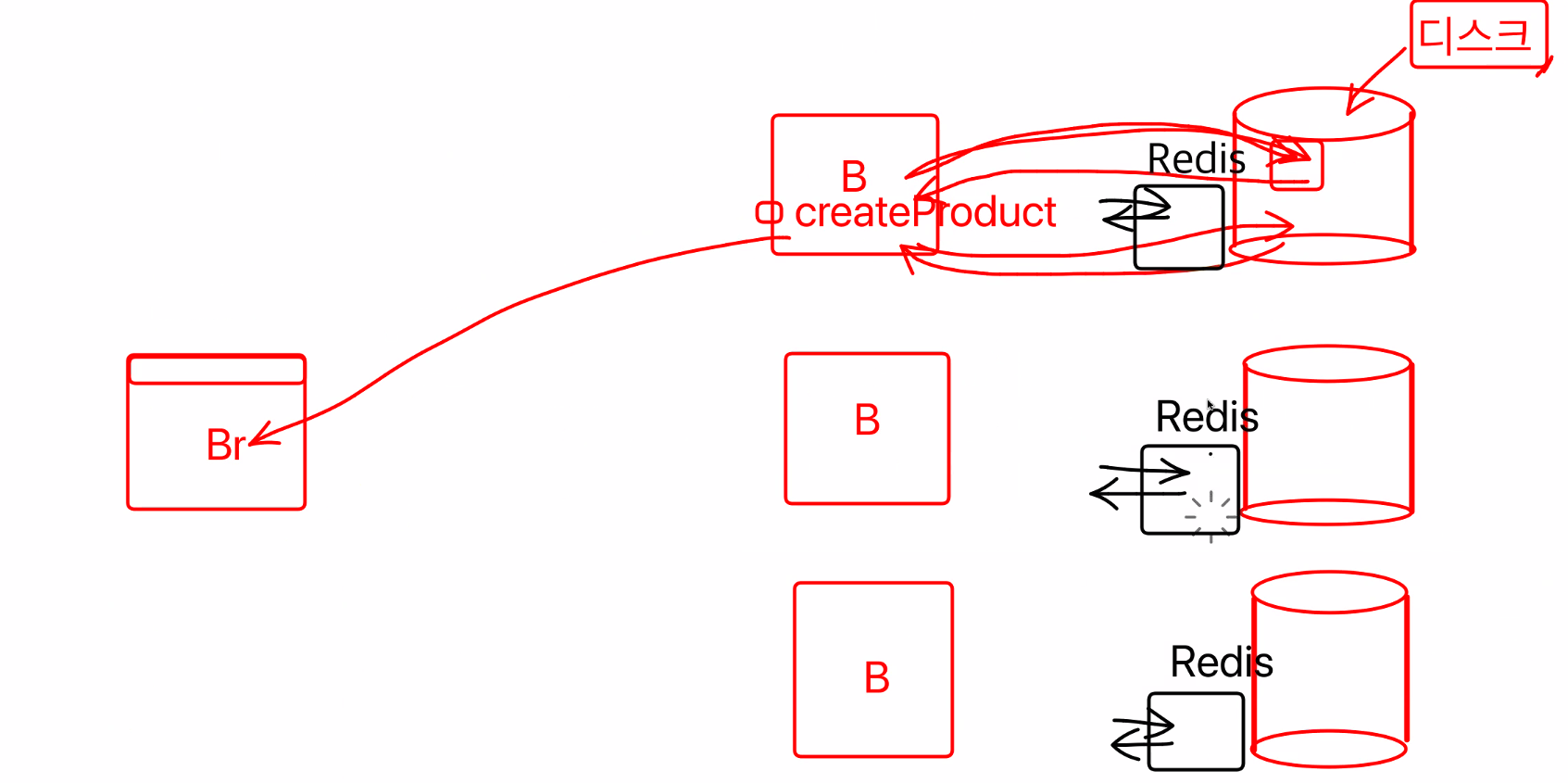
1. 메모리기반 DB(ex Redis...)에 저장
그래서 메모리기반 DB(ex Redis...)에 저장을 하게 되면 디스크에 저장을 하는 게 아니라 메모리에 저장을 하게 된다. 그렇기 때문에 매우 빠르다. 성능까지 잡은 방법.
이것이 2가지 방식 중 첫번째다.
JWT토큰
2. JWT 토큰
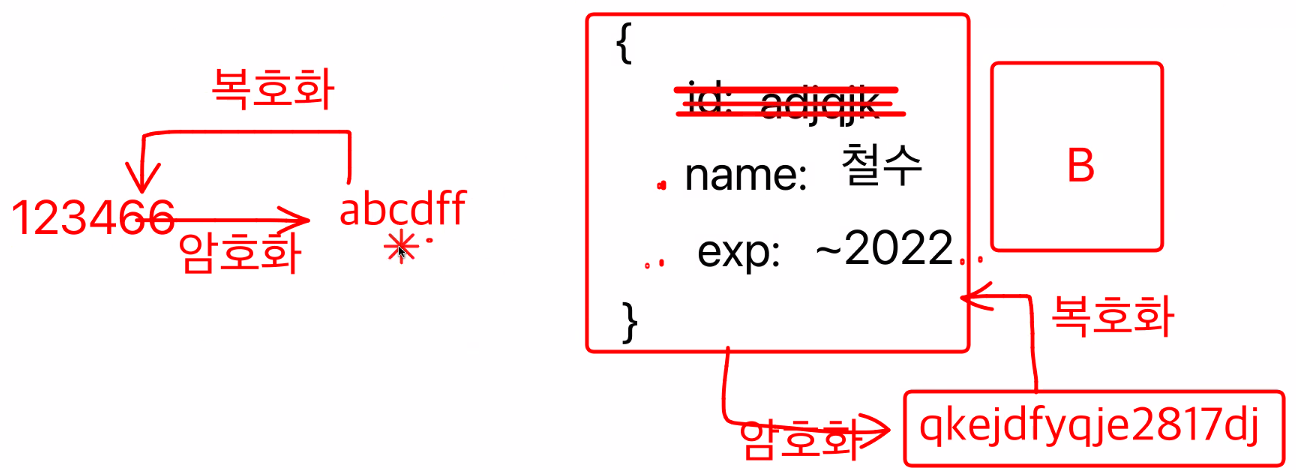
예를 들어서 객체를 하나 만들어놓고 객체에 이름, 로그인 만료시간을 만들어놓고 이 내용을 암호화 한다. (비밀번호처럼)
이게 알 수 없는 문자열로 바뀌게 되는데, 이 내용을 토큰아이디로 쓰자.
즉, 암호화했던 내용을 복호화하게 되면 원래 내용이 담겨있으므로 DB에 안 갔지만 간 것처럼 쓰자.
이 암호화 한 토큰을 Javascript Object Notation (JWT) 이라고 한다.
백엔드에서 객체형태의 토큰을 만들고 암호화하면 토큰이 튀어나온다.
토큰을 프론트엔드에 넘겨주면 브라우저 state에 토큰을 저장해놓게 되고,
백엔드에 api를 요청할 때 상품내용과 이름, 가격, 토큰아이디(JWT)를 함께 보내게 된다.
DB를 긁을 필요 없이 백엔드에서 바로 복호화를 해서 객체 내용을 확인할 수 있다.
굉장히 효율적인 방법.
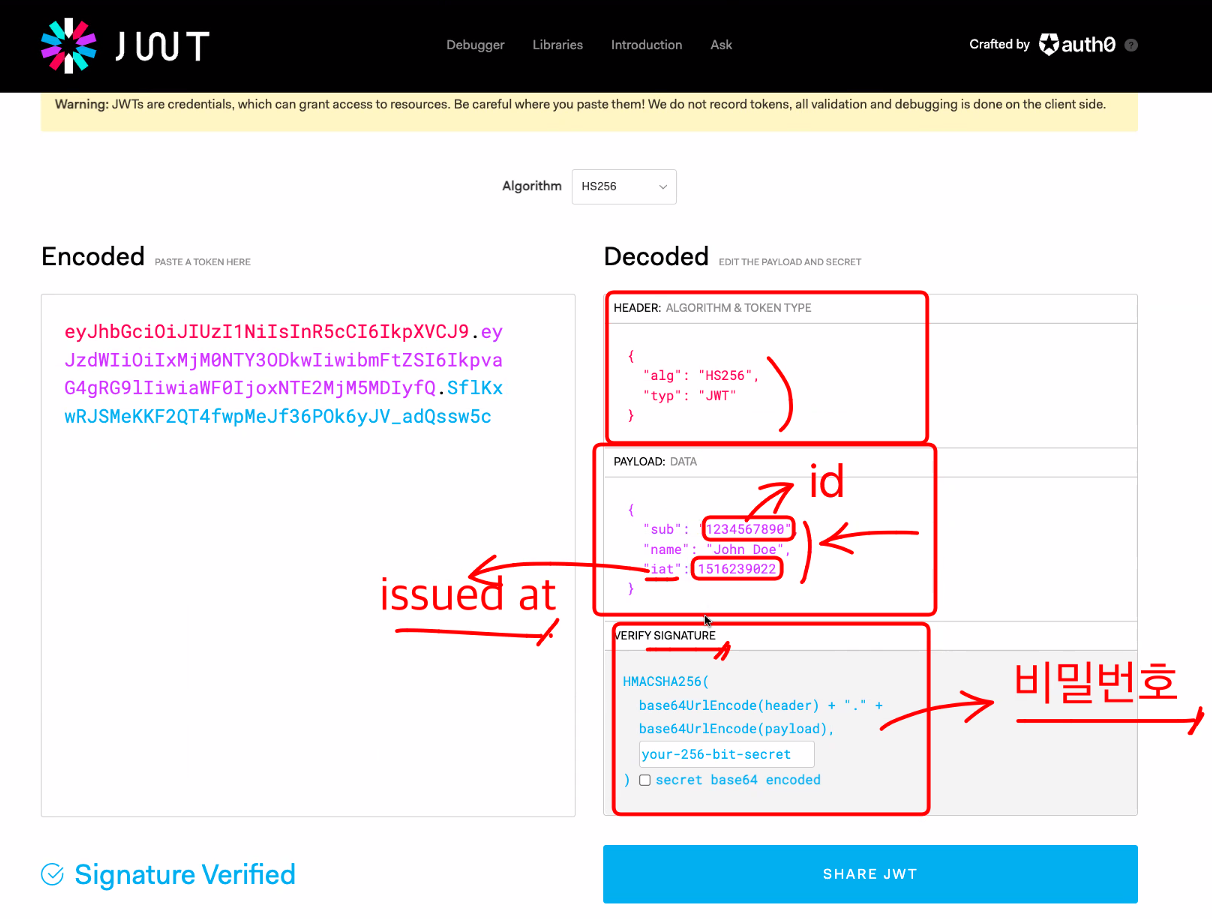
Encoded = 암호화
Decoded = 복호화
issued at = 언제 만들어졌는지
객체의 이름은 우리가 만들 수 있음.
JWT토큰은 누구든지 안의 내용을 열어볼 수 있으므로 중요한 정보는 적으면 안됨!
하지만 조작은 불가능하다.
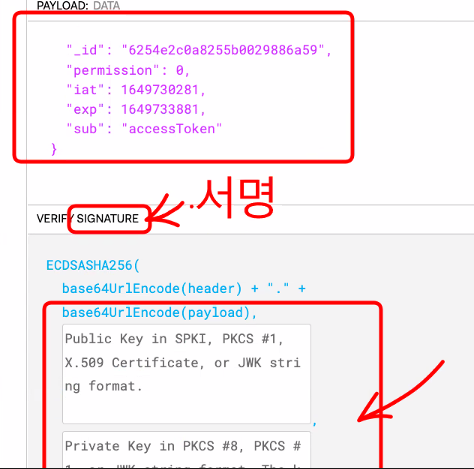
처음에 서명이 된 내용과 같은지 다른지 비교를 한다.
서명으로 조작이 됐는지 안됐는지 확인할 수 있다.
상식적으로 알면 좋은 암호화 내용
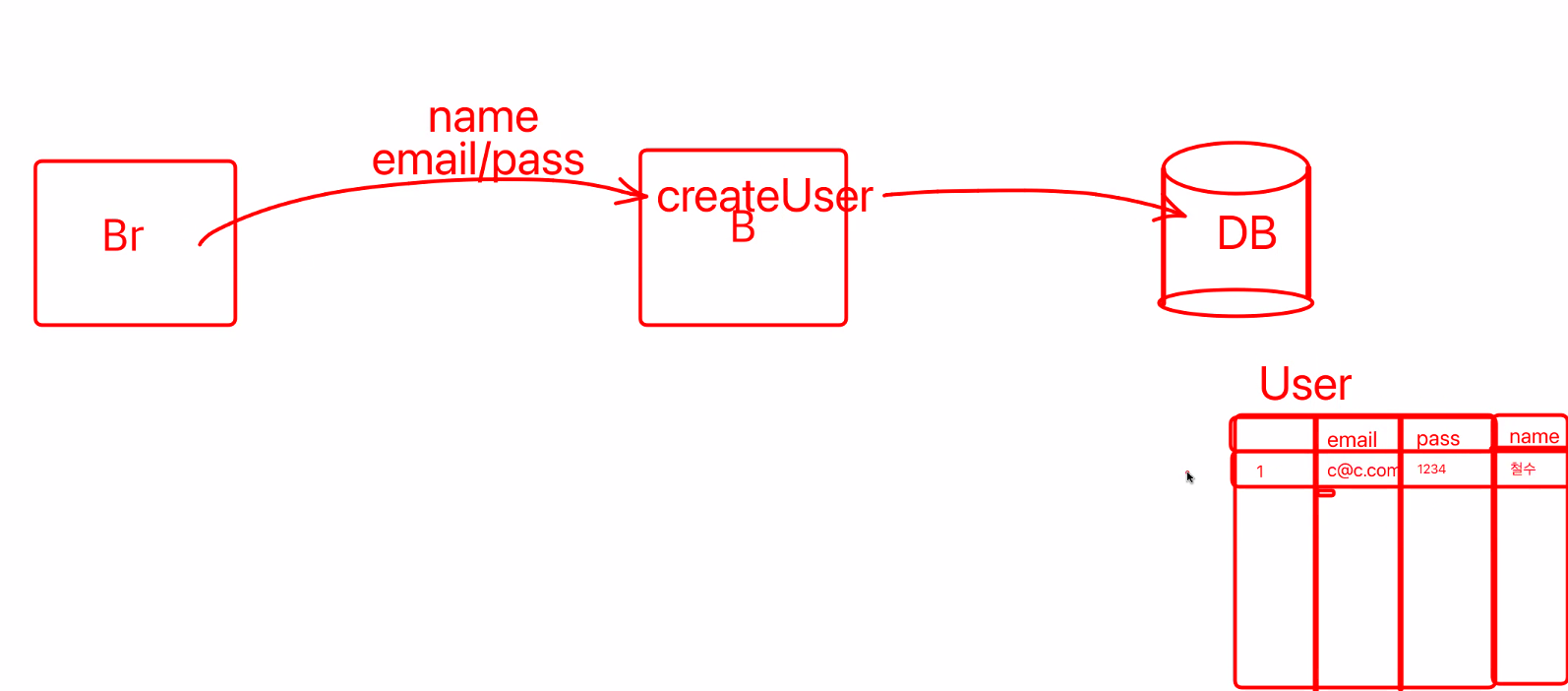
createUser Api ==== email/pass/name ====> createUser ====> DB (회원목록 테이블)
DB에 비밀번호가 1234로 저장되지 않음. 해킹하면 데이터를 다 볼 수 있기 때문이다.
일반적으로 하나의 사이트에 가입을 하면 다른 사이트에도 적용을 하는 사례가 많다.
특정 유저 테이블 하나를 빼내서 여러 사이트들에 무작위로 접속을 해보면 통과가 되는 부분이 있다.
그렇게 해킹을 당하게 된다.
그래서 DB에는 비밀번호 값을 암호화해서 알 수 없는 값으로 저장한다.
이 테이블을 가져와서 복호화
하다보면 되는 케이스가 있어서 암호화의 의미가 없어진다.
암호화에는 양방향 암호화, 단방향 암호화가 있다.
원상복구 가능한 암호화를 양방향 암호화라고 하고, (ex JWT토큰)
단방향 암호화는 특정 비밀번호를 암호화하게 되면 그 암호를 복호화 할 수 없는 것을 의미한다.
즉, 암호화는 가능하고 복호화는 불가능한 케이스를 말한다.
다른말로는 해시(Hash)라고 한다.
비밀번호는 단방향 암호화, 해시 방식으로 테이블에 저장이 된다!
올바른 사이트는 DB관리자도 비밀번호를 몰라야 한다.
또한 해킹을 위해 해시 복호화를 위한 예시들을 모아놓은 것을 레인보우 테이블이라고 한다.
결론 : 완벽한 보안은 없다.
<실습>
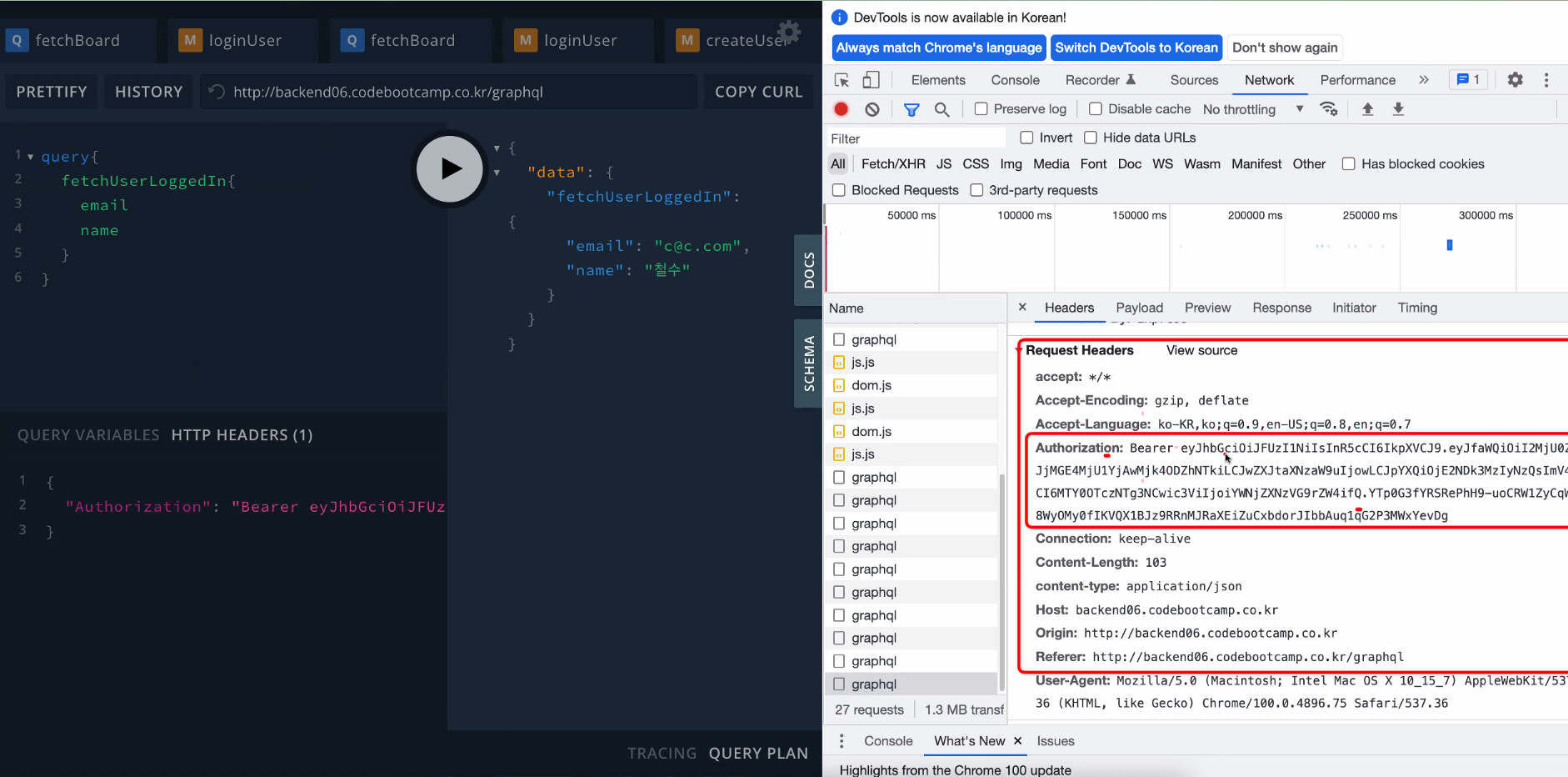
header에 accessToken을 넣어서 전송하면 로그인 된 유저 정보를 불러오는 것이 가능!
인증( Authentication )
로그인 할 때 email과 password를 넘겨주고 토큰을 받아올 때
토큰 만료 전까지 한 번만 해도 된다.
hadear 앞 Bearer를 붙인다. 관례상 토큰인증을 할 때 붙이게 되는 문자열
인가( Authorization )
이미 받은 토큰을 가지고 내 정보를 받아오는 api를 사용할 때마다 헤더에 넘겨주어야 하는 것
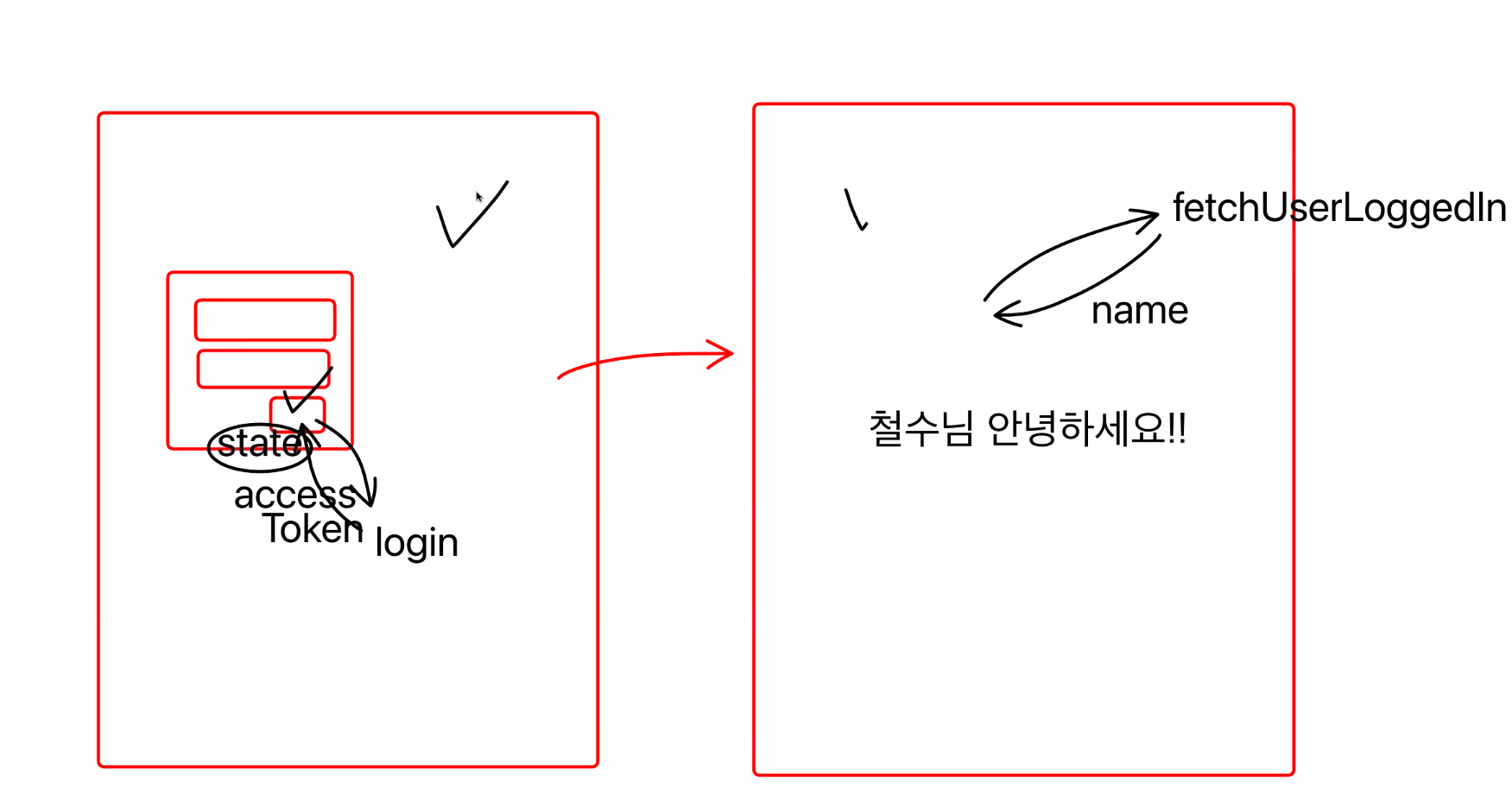
Recoil
우리가 useRecoilState를 사용하려면 내 윗쪽에 RecoilRoot가 있어야한다!
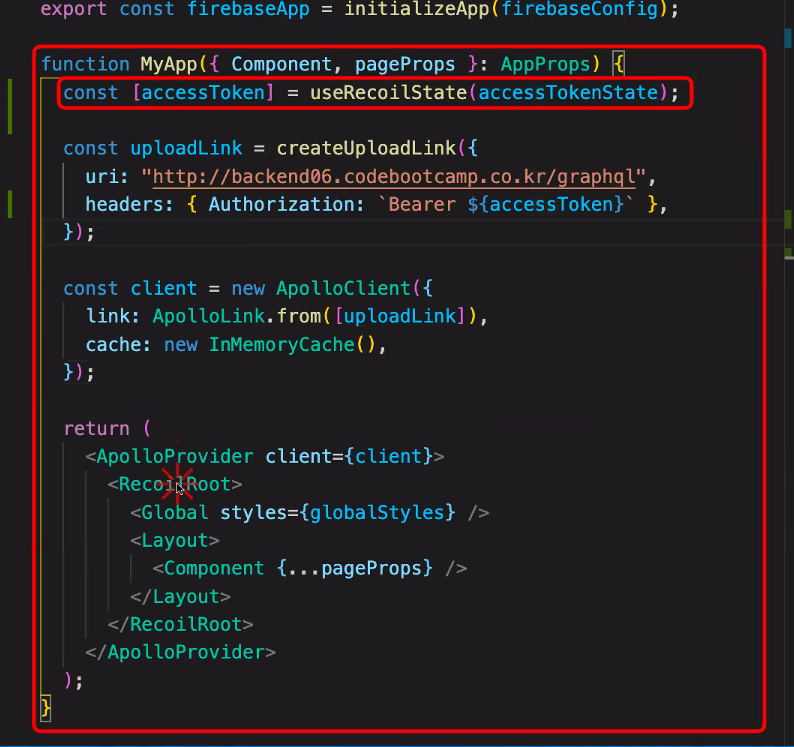
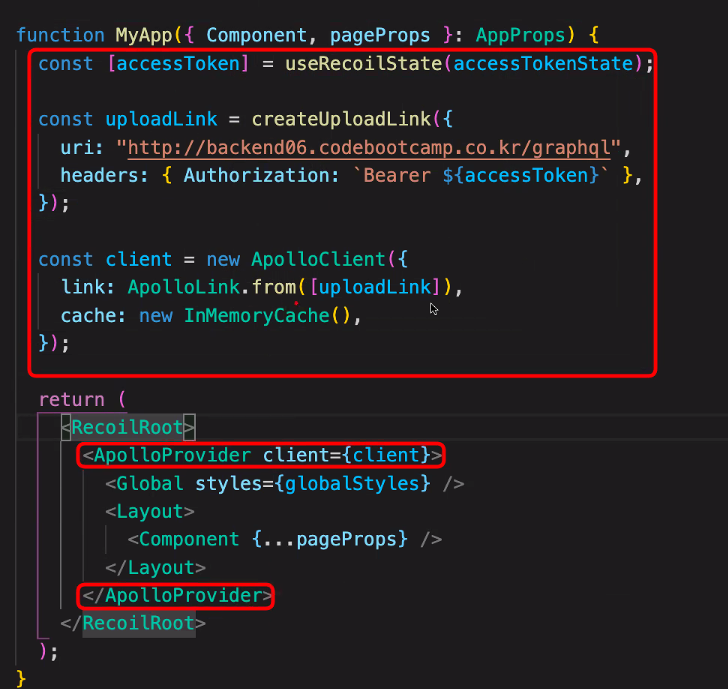
RecoilRoot의 위치를 바꿔주어야한다.
Apollo 세팅을 다른 컴포넌트로 빼준다!
