33일차 / Optimistic-UI, Open-Graph / SSR, SEO

Optimistic-UI
빠르게 할 수 없다면 속여보자
단지 숫자 1, 2 올리는 정도의 케이스의 경우에 사용자들에게 더 빠른 경험을 제공해 줄 수 있다.
실패하더라도 리스크가 크지 않고, 실패할 가능성도 적다.
99%의 성공확률이 있을 때만 사용하는 것을 권장
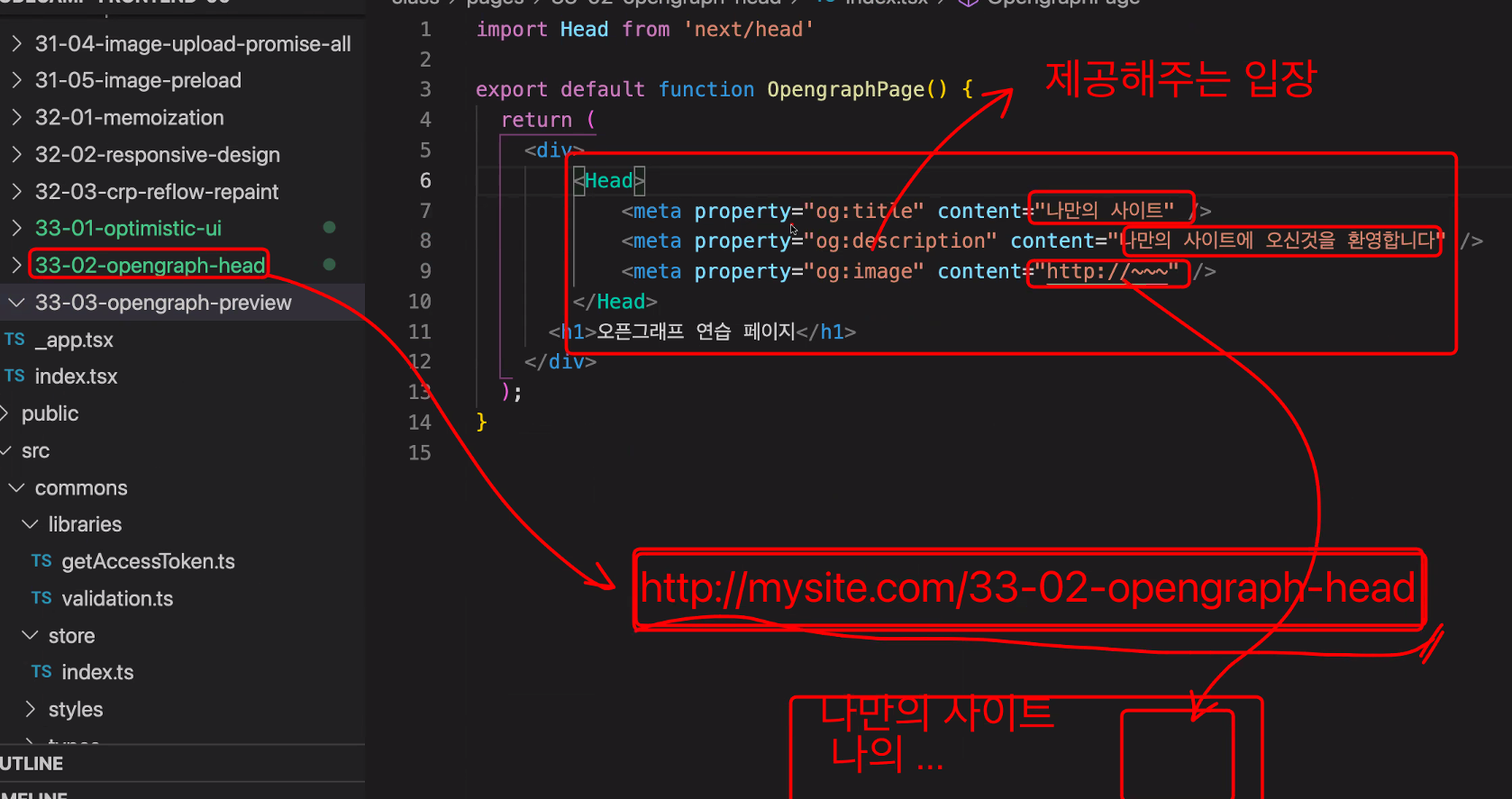
화면을 먼저 보여준 다음에 데이터와 비교하는 전략
뮤테이션을 받아오는 방법
1. result에 담기
2. refetchQueries : 쿼리 2번 요청
3. 캐시스테이트 직접 수정
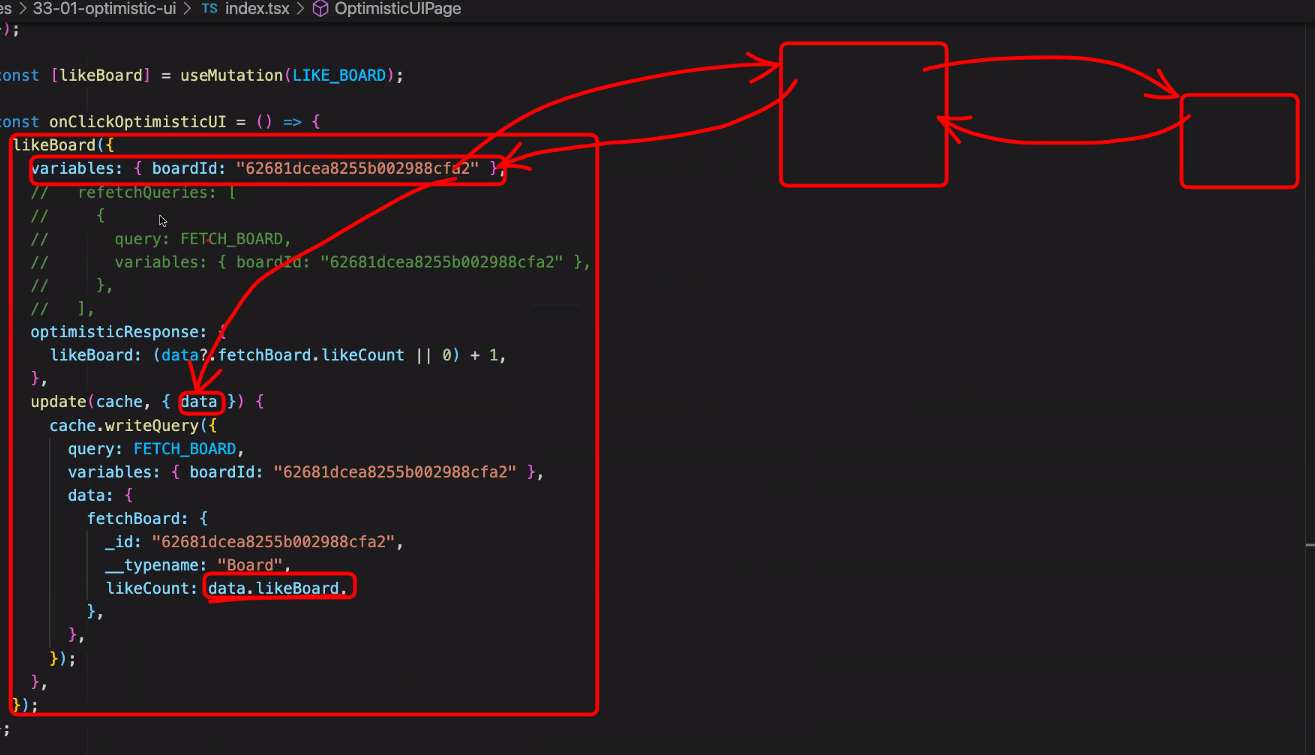
좋아요 버튼을 누르면 뮤테이션 실행
백엔드에서는 likeCount를 올리고 프론트로 응답을 주는데, 데이터가 들어와서 카운트를 조작해준다.
데이터가 오는데 시간이 걸리므로 화면에 먼저 보여주기 위해 optimistic-UI를 쓰는데 낙관적인 데이터를 먼저 받아보겠다.
데이터는 요청중인데 화면에는 미리 보여진다.(가짜 좋아요)
그 response가 돌아왔을때 진짜 좋아요가 가짜좋아요와 값이 다르면 다시 값을 되돌린다.
(reponse가 2번 실행)
실제로 작동해보면 작동이 굉장히 빠르지만 개발자 컴퓨터는 빠르고, 사용자 컴퓨터는 느린 경우가 있기 때문에 고려를 해주어야 하는 것.
네트워크 설정을 Slow 3G로 설정하고 보면 refetchQueries를 사용한 것과 optimistic-UI의 속도차이를 체감할 수 있다.
Open-Graph / SSR
미리보기랑 서버사이드렌더링이 관련?
이 HTML 데이터를 어떻게 가지고 올 것인가?
=> 라이브러리로는 Cheerio, Puppeteer을 사용한다
curl
rest-api의 get방식으로 보내진다
사이트의 html을 불러올 수 있다

Scraping
긁는다
Crawling
긁긴 긁는데 정기적으로 특정시간에 긁는다.
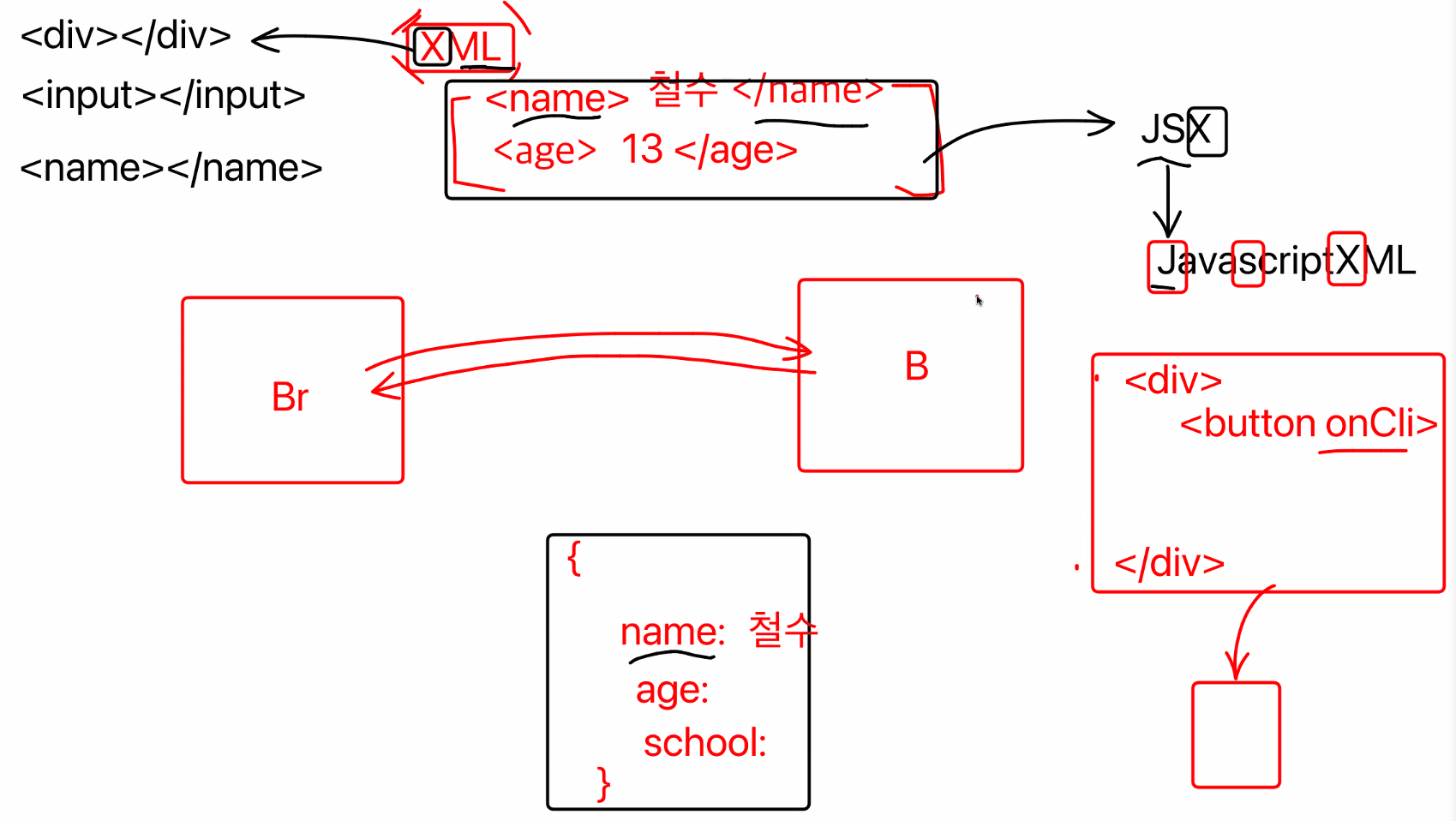
api를 요청하면 html을 받아올 수 있고 이 데이터를 JSON 형태를 쓰기 이전에, XML형태로 받아왔었다.
XML방식(확장 가능한 마크업 언어)
<name>철수</name>
<age>13</age>
<school>학교</school>XML에서 파생된 것이 JSX(JavascriptXML)
실제 HTML이 아니라 가짜 HTML
실제 실행될 때는 진짜 HTML형태로 바뀌어서 실행됨
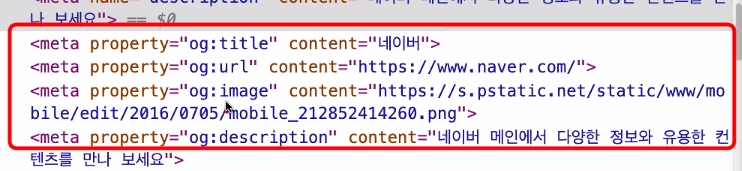
태그가 의미하는 것
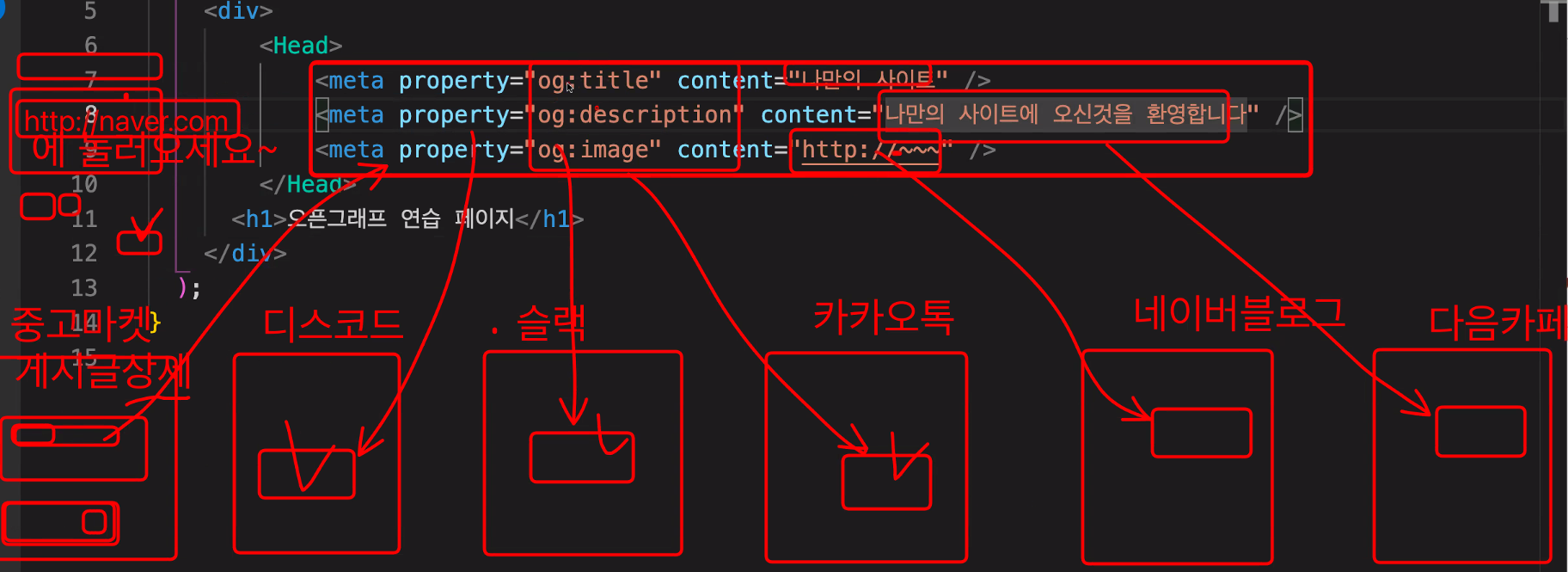
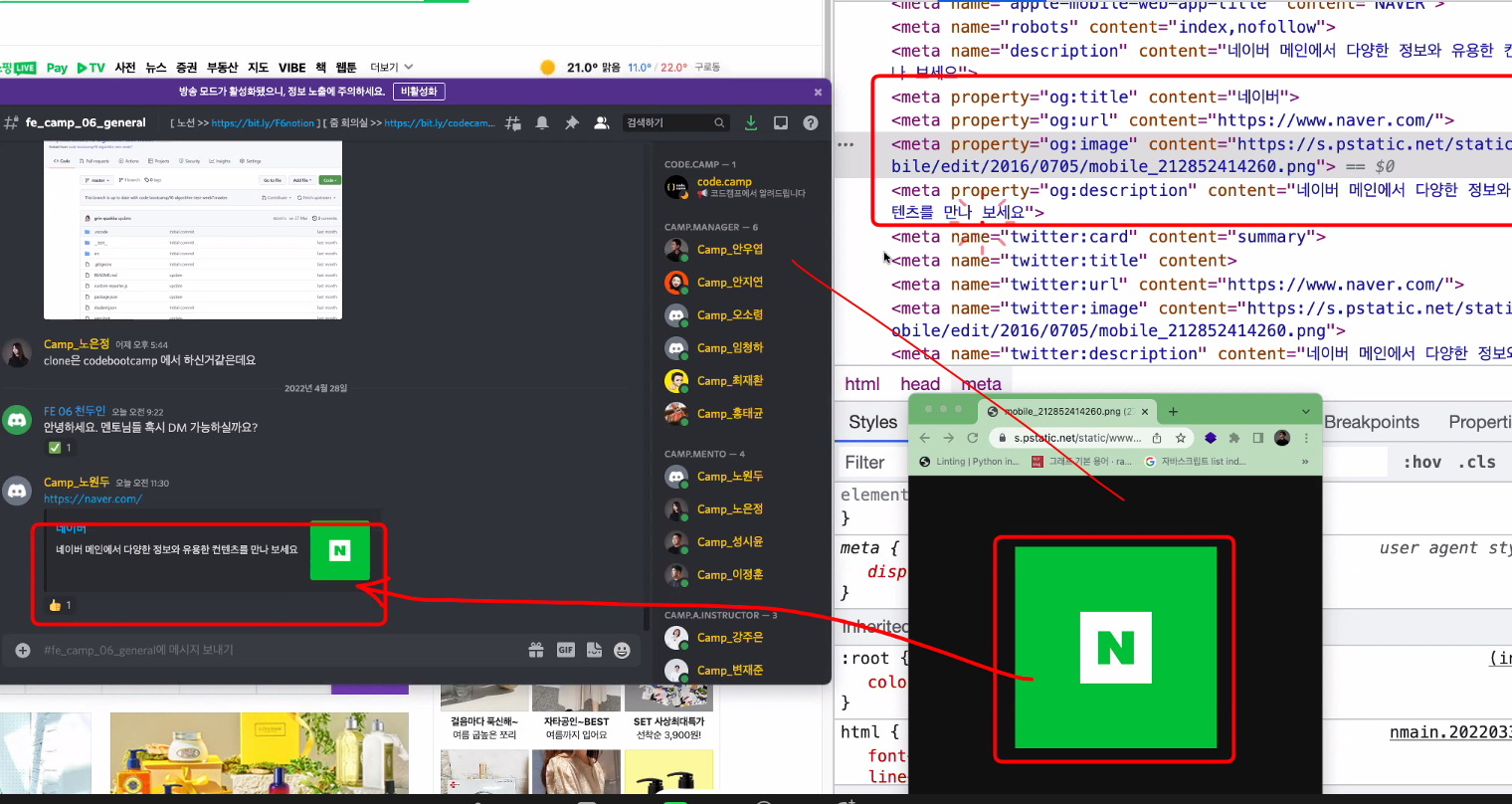
각각의 개발자들이 해당 html의 meta 태그를 스크래핑해서 가져와서 그려주는 것!
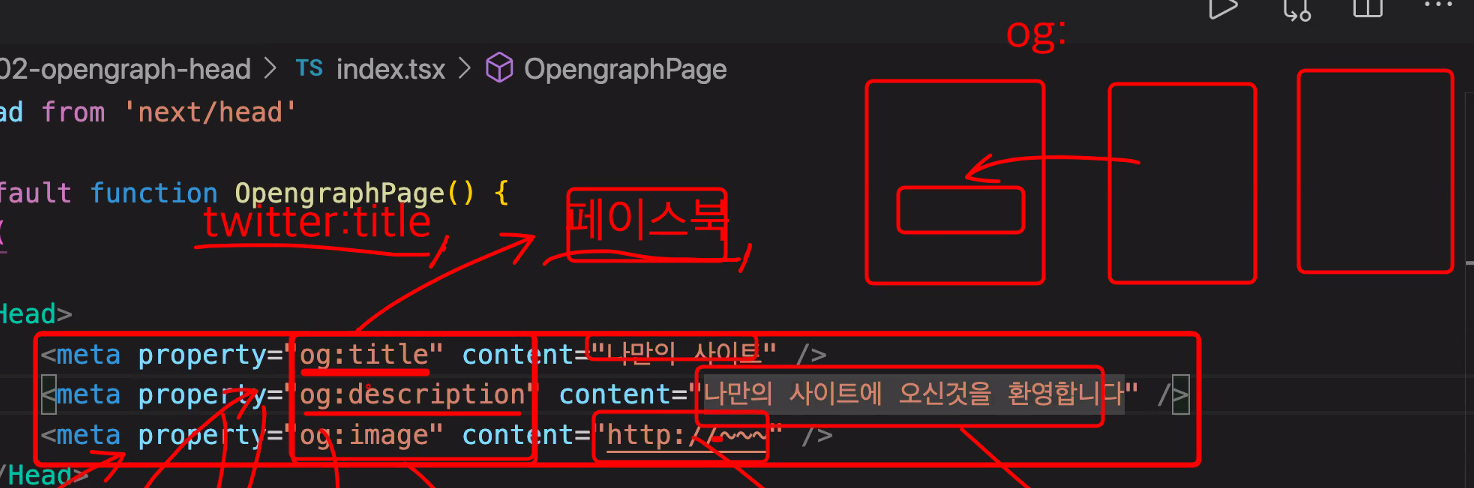
og라는 것은 다른 사람들의 페이지를 보여주게끔 하기 위해서 open graphic(og)으로 통일을 해서 스크래핑할 수 있게끔 하는 것. 페이스북에서 시작. twitter도 있다.
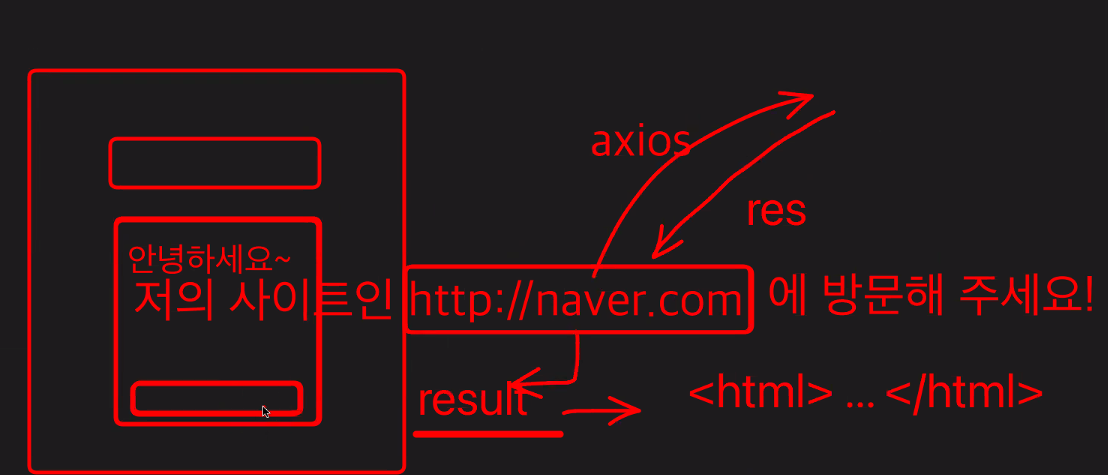
일반적으로 이 작업은 백엔드에서 진행이 된다.
왜 백엔드에서 진행이 될까?
=> CORS문제가 있다.
open-api를 사용할 때도 되는 페이지와 안되는 페이지가 있었다.
이걸 해결하기 위해서는 proxy서버를 활용해야한다고 했다. (proxy서버 = 백엔드)
브라우저에서 막는 것이다보니 모든 사이트를 스크래핑 할 수 없음. 그래서 백엔드에서 코드를 작성해야한다.
서버사이드렌더링과 무슨관계?
다이나믹 라우팅 되는 페이지에는 어떻게 적용시킬까?
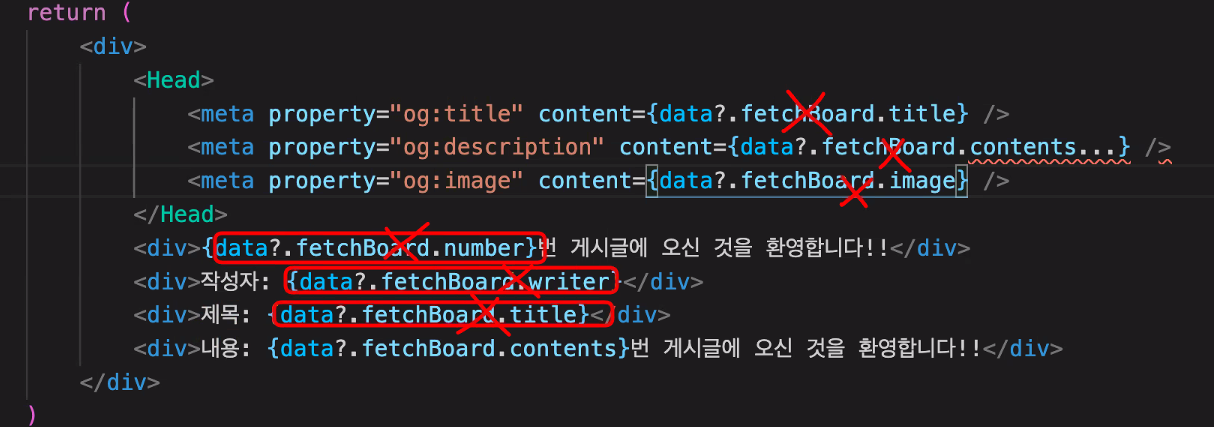
스크래핑을 할 때, 처음 접속해서 받아오는 html만 받아온다.
그 다음에 useQuery를 날려야하는데 axios, curl, postman이 날려주지는 않음.
스크래핑 단계에서 유즈쿼리를 받아오지 않는다.
동적 페이지에 대해서는 다이나믹 오픈그래프를 만들어주어야하는데 위 방법으로는 어렵고 불가능하다.
yarn dev를 하면 처음에 HTML,CSS,JS를 받아오고 2차적으로 유즈쿼리릅 받아오는데 이러면 데이터 값이 빈 값이다.
처음에 HTML의 값이 채워져 있어야 내용이 차있는 상태로 줄 수가 있다.
yarn dev하는 프로그램이 프론트엔드 서버 프로그램.
이 프로그램에서 useQuery까지 해와야 한다.
이 과정을 서버사이드렌더링이라고 한다.

페이지에서만 사용 가능
Next.js에서 지원하는 함수
이 페이지에서 서버사이드렌더링을 가능하게 한다.
이름 변경 불가능
순수 리액트를 썼으면 쉽지 않다.
Next.js 에서 하나의 함수로 서버사이드렌더링을 지원!
리액트에서도 지원을 하게 되었지만 아직은 지켜보는 추세
라이브러리란 기존 라이브러리가 문제가 있어서 해결하려고 나오는 것
내가 쓰던 것보다 더 좋고 트렌드가 좋은 것을 바꾸면서 적용하기
SEO
검색엔진 최적화도 서버사이드렌더링과 관련?
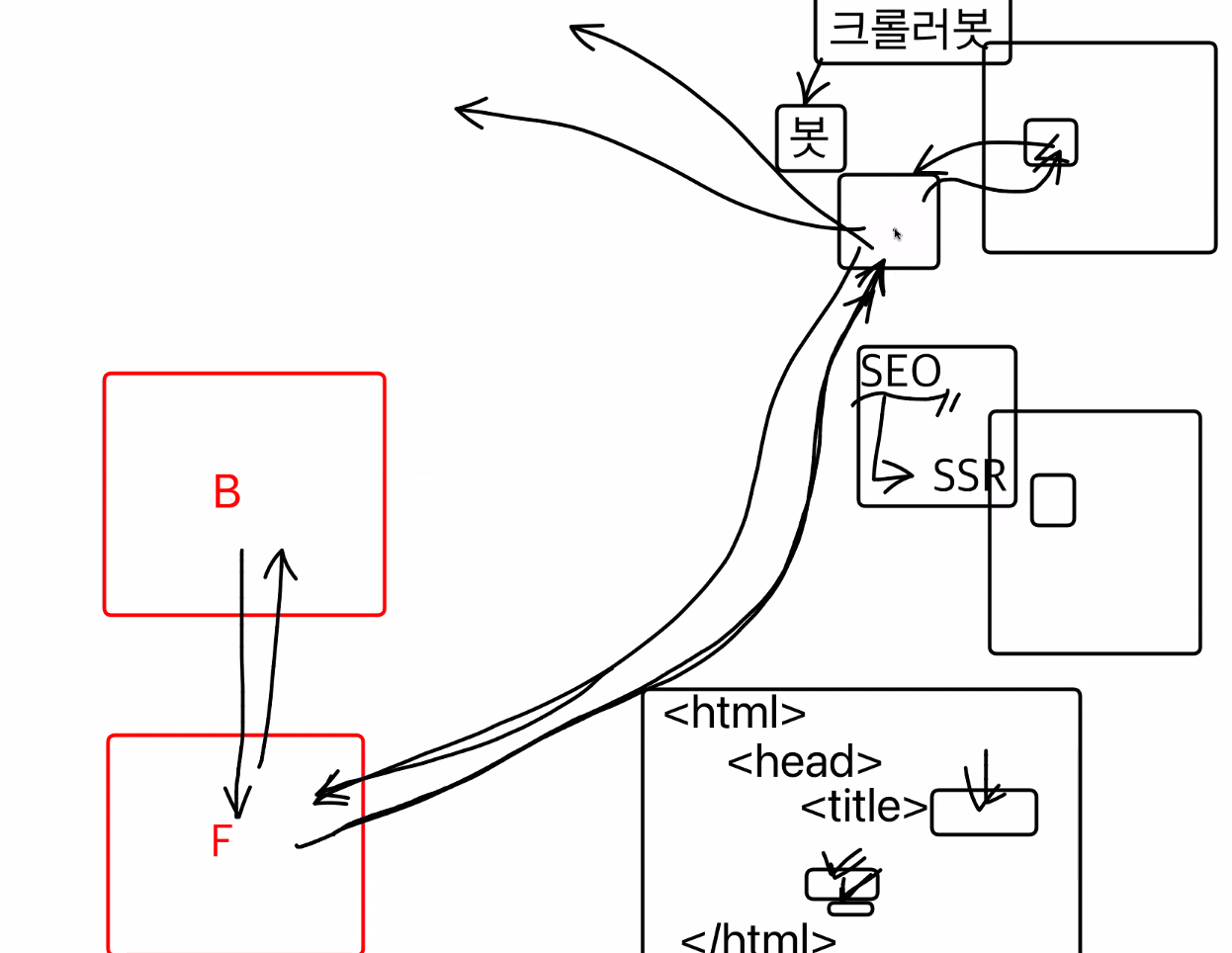
스크래핑 해오는 프로그램을 봇(크롤러봇)이라 함.
여기저기 사이트를 돌아다니면서 axios로 스크래핑을 한다
서버사이드렌더링이 안되면 값이 비어있기 때문에 평점을 불러와야하는 경우에서는 불리하다.
검색엔진에 최적화를 시켜주고 싶으면 크롤러봇이 데이터를 가져갈때 데이터를 채워주어야한다.
그래서 백엔드에서 데이터를 가지고 와서 프론트에서 데이터까지 합쳐진 값을 보내주어야 한다.
그래서 서버사이드렌더링이 필요하다.
검색엔진 사이트를 위해서는 이것이 진행이 되어야 함.
구글 같은 경우에는 업그레이드가 많이 되어서 유즈쿼리까지 받아오는 기능이 추가되어있다.
봇도 데이터를 기다려주기는 하지만 완벽하지 않기 때문에 서버사이드 렌더링을 권장한다.
모든 사이트를 서버사이드 렌더링을 해야할까?
특정 게시물을 조회하면 프론트 => 백엔드 => DB => 백엔드 => 프론트
과정이 너무 많다.
클릭할 때마다 다시 받아와야하므로 모든 페이지를 SSR하는 것은 옛날방식이다.
클라이언트 사이드 렌더링은 접속을 해서 받아오고 빈 내용을 빠르게 보여주고 유즈쿼리로 알맹이를 빠르게 채워주는 방식.
라우터 쿼리를 이용해서 프론트엔드 서버를 받아오지 않고 이미 있는 것을 보여줄 뿐
페이지 전환속도는 훨씬 빠르다.
모든 페이지가 서버사이드렌더링은 아니다.
구분을 나누어야 함.
메타가 바뀌어야 한다거나, 검색엔진에 등록이 되어야 한다거나, 일반적으로 게시글 상세내용에 서버사이드렌더링이 필요하다.
상품 메타태그...등
결국 상세페이지는 느릴 수밖에 없나?
프론트엔드 서버에서 상세페이지를 받아서 온 다음에 처음 실행은 좀 느릴 수 있지만 임시저장을 해서(캐싱) 다음에 다른 사람이 똑같은 주소에 대해서 요청을 하면 새로 안 받아오고 캐싱태그를 바로 주면 낫다.
그래도 클라이언트 사이드 렌더링은 느리지만 새로 받아오는 것보다는 빠르다.
