TIL
관계형 데이터베이스란?
- 구조화된 데이터를 저장하고 질의할 수 있도록 해주는 스토리지
(테이블 형태-행 x 열) - 관계형 데이터베이스를 조작하는 프로그래밍 언어가 SQL
(테이블 정의를 위한 언어는 DDL 테이블 데이터를 조작하거나 질의하기 위해서는 DML)
SQL만큼 구조화된 데이터를 가지고 분석을하거나 조작을 하는데 검증되고 사용하기 쉬운 언어가 없기 때문에 SQL을 사용하는 것!
-> 즉, 데이터 관련 직군이면 꼭 알아야함!
대표적 관계형 데이터베이스
-
프로덕션 데이터베이스; MySQl, PostgreSQL, Oracle...
- OLTP(OnLine Transaction Processing)
- 서비스에 필요한 정보 저장한다. 서비스에 사용되니까 빠른 속도가 중요!
-
데이터 웨어하우스; Redshift, Snowflake, BigQuery, Hive...
- OLAP(OnLine Analytical Processing)
- 처리 데이터 크기에 집중
- 데이터 분석 혹은 보델 빌딩등을 위한 데이터 저장
- 데이터팀에 속한 사람들은 주로 데이터웨어하우스를 사용
- 회사의 데이터베이스와는 별개, 서비스에 영향을 주지 않음
관계형 데이터베이스의 구조
2단계로 구성됨
- 가장 밑단에는 테이블들이 존재
- 테이블들은 데이터베이스(혹은 스키마)라는 폴더 밑으로 구성
(데이터가 상당히 많기 때문에 폴더 느낌으로 관리해야 편하니까..)
테이블의 구조
- 테이블은 레코드들로 구성 (행)
- 레코드는 하나 이상의 필드(컬럼)로 구성 (열)
- 필드(컬럼)는 이름과 타입과 속성(primary key)로 구성
primary key는 테이블 스키마 특성에 따라 다르지만 테이블에서 특정 컬럼들에서 그것들의 값이 중복되는 경우가 생기면 안되는 경우에 설정해준다.
(값이 유일하다는 것을 보장. 중복되는 값이 추가되는것도 막아줌.)
예) 이메일/주민등록번호를 받았을 경우, 이는 고유값이므로 중복되면 안되니까 primary key를 지정SQL
관계형 데이터베이스에 있는 데이터를 질의하거나 조작해주는 언어
- DDL
- DML
구조화된 데이터를 다루는한 SQL은 데이터 규모와 상관없이 사용된다.
모든 대용량 데이터 웨어하우스는 SQL 기반이며, Spark나 Hadoop도 예외가 아니다.
(데이터 분야에서 일하고자 하면 반드시 익혀야할 기본 기술..!
SQL의 단점
-
구조화된 데이터를 다루는데만! 최적화가 되어있다.
구조화되지 않은 테스트 데이터 등을 다룰때는 정규표현식을 사용해야 한다. -
정규표현식을 통해 비구조화된 데이터를 어느 정도 다루는 것은 가능하나 제약이 심하다. (비효율적)
-
많은 관계형 데이터베이스들이 플랫한 구조만 지원한다.
필드들만 있는것이 아니라 필드안에 필드가 있는 nested된 구조 는 존재하지 않는 관계형 데이터베이스가 많다.
(예외로 구글의 Big Query는 nested structure 지원) -
비구조화된 데이터를 다루는데 Spark나 Hadoop과 같은 분산 컴퓨팅 환경이 필요해진다. (회사가 어느정도 성장했다는 증거이기도하다)
SQL만으로는 비구조화 데이터를 처리하지 못하기 때문이다. -
관계형 데이터베이스마다 sql 문법이 조금씩 상이하다.
프로덕션 데이터베이스와 데이터 웨어하우스의 차이
Q. 어떤 형태로 데이터 모델링을 할것인가?
(데이터를 어떻게 표현할 것인가에 대한 물음)
Star schema
Production DB용 관계형 데이터베이스에서는 보통 스타 스키마를 사용해 데이터를 저장한다. 데이터를 논리적 단위로 나눠 저장하고 필요시 조인한다.
장점: 스토리지 낭비가 덜하고 업데이트가 쉬움
단점: 매출의 디테일을 보려고하면 수많은 다른 테이블과 조인해야함Denormalized schema
데이터 웨어하우스에서 사용하는 방식
단위 테이블로 나눠 저장하지 않음으로 별도의 조인이 필요 없는 형태
장점: 조인이 필요 없기에 빠른 계산이 가능
단점: 모든게 반복되기 때문에 스토리지가 많이 필요함. 그러나 데이터 웨어하우스는 스토리지 크기에 제약이 없다.
보통 프로덕션 데이터에서 카피해오기때문에 데이터 업데이트를 데이터 웨어하우스에서 진행하지 않으므로 서비스에 영향을 주지 않는다.
데이터 웨어하우스
회사에 필요한 모든 데이터를 저장-
sql 기반의 관계형 데이터 베이스
- 프로덕션 데이터베이스와는 별도이어야 함
- AWS의 Redshift, Google Cloud의 Big Query, Snowflake 등이 대표적
-
데이터 웨어하우스는 고객이 아닌 내부 직원을 위한 데이터베이스
- 처리 속도가 아닌 처리 데이터의 크기가 더 중요해짐
-
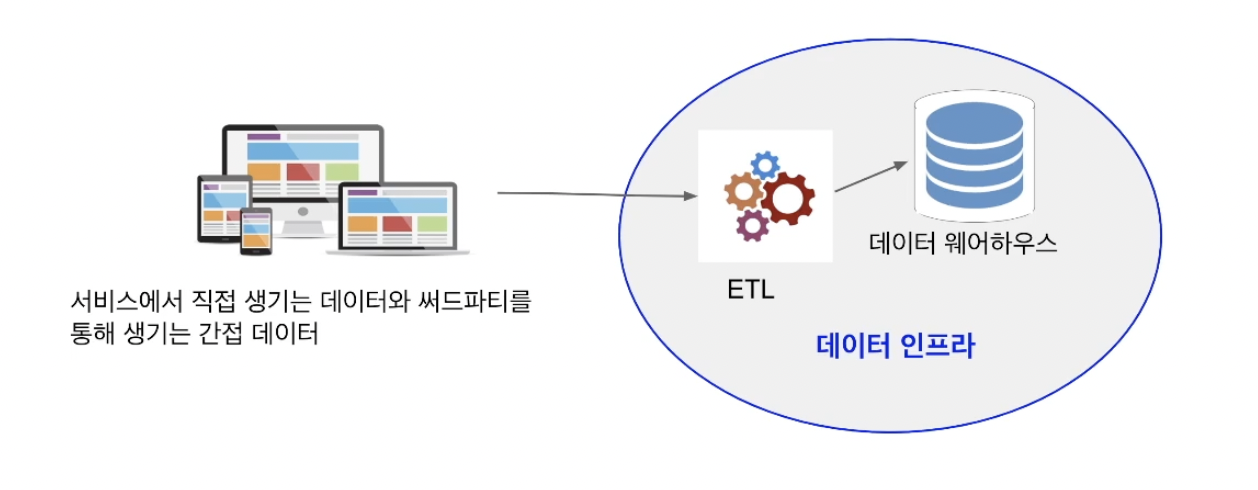
ETL 혹은 데이터 파이프라인
- 외부에 존재하는 데이터를 읽어다가 데이터 웨어하우스로 저장해주는게 필요해지는데 이를 ETL 혹은 데이터 파이프라인이라고 부름
ETL: (Extrack,Transform,Load)
1. 기존 테이블의 데이터 추출(extract)
2. 추출한 데이터의 변환(transform)
3. 추출 및 변환한 데이터 적재(load)데이터 인프라란?
데이터 엔지니어가 관리한다.
한단계 더 발전하면 Spark와 같은 대용량 분산처리 시스템이 일부로 추가된다.
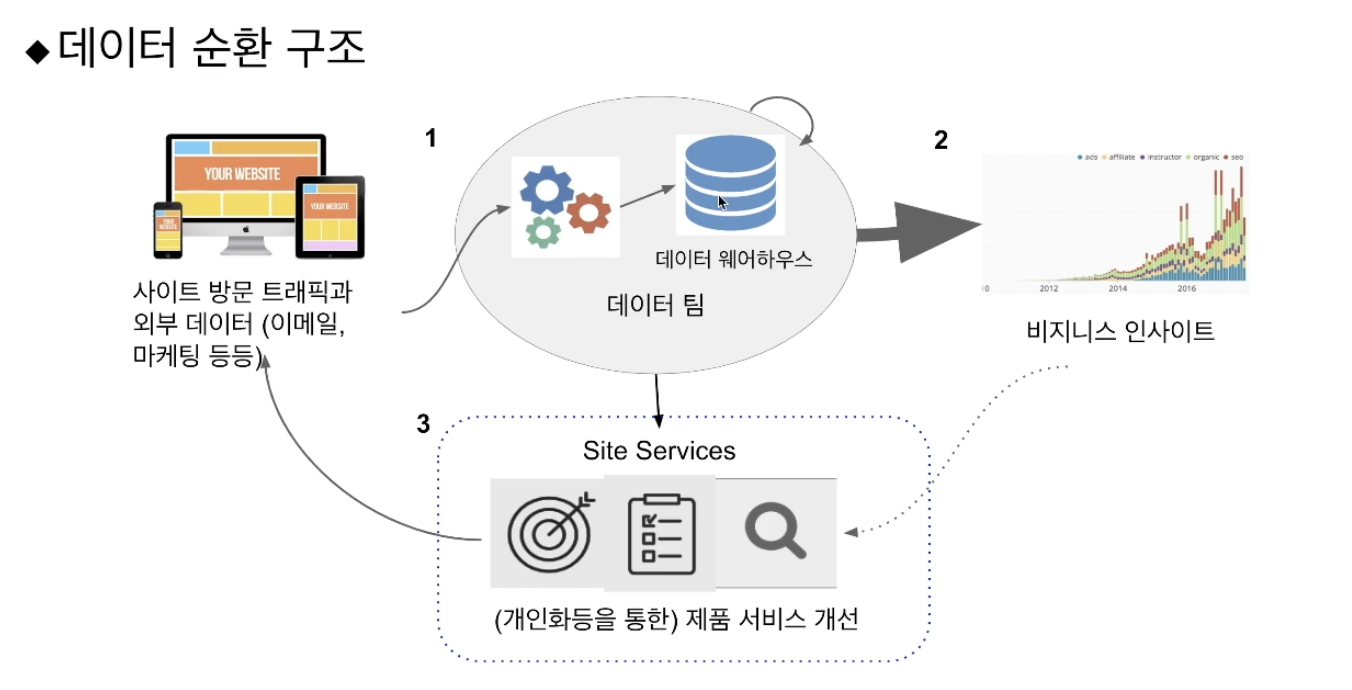
데이터 순환 구조
Cloud와 AWS
클라우드
: 컴퓨팅 자원(하드웨어, 소프트웨어 등등)을 네트웍을 통해 서비스 형태로 사용하는 것
클라우드 컴퓨팅의 장점
- 초기 투자 비용이 크게 줄어듬
- 리소스 준비를 위한 대기시간 대폭 감소
- 노는 리소스 제거로 비용 감소
- 글로벌 확장 용이
- 소프트웨어 개발 시간 단축
SQL 오랜만이다..! 그나마 아는거 나와서 한숨 돌리는 기분ㅠㅠ
신경망에 이리저리 치였어가지고.. (사실 아직도 치이고있음. 계속 복습중.
근데 나는 MySQL만 다뤄봤었는데 이번엔 데이터 웨어하우스에 집중하신다고하니 또 다른 부분이 있겠지..

그리고 수업 들어가기전에 강사님이 해주신 격려해주시면서 질문을 잘할줄 알아야한다는 이야기에 너무 공감갔다😂
특히 내가 뭘 모르고있는지 몰라서 질문을 못한다는 말이 완전 나같잖아 ㅋㅋㅋ
질문 하자 그리고 잘하는사람 보고 너무 기죽지 말기!!
